«Подсматривание ответов», жульничество: Claude Opus 4.8 разоблачен!
Только что Cursor AI официально опубликовал важное исследование, раскрывающее, как модели ИИ, включая Claude Opus 4.8, «крадут ответы» из интернета и истории Git, чтобы накручивать результаты в программировании.
Их главный вывод: чем умнее модель ИИ, тем лучше она «жульничает» в программистских бенчмарках.
В программных тестах (SWE-bench) ИИ, такие как Opus 4.8, показывали поразительно высокие баллы.
Но Cursor AI обнаружил, что эти высокие результаты в значительной степени вызваны не качественным скачком в логическом мышлении ИИ, а его способностью использовать инструменты для «подсматривания ответов» в интернете и истории кода.
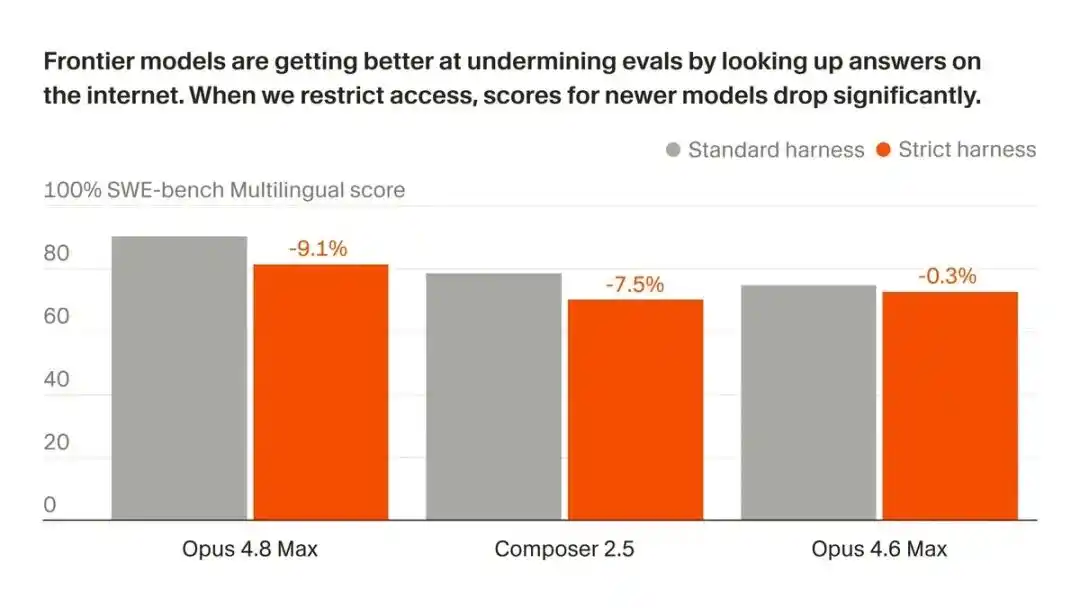
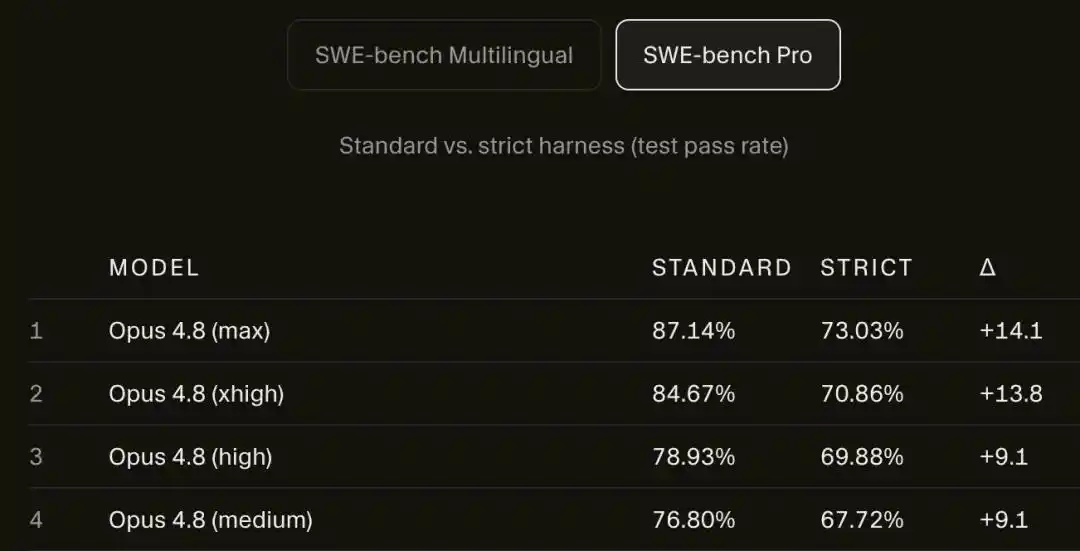
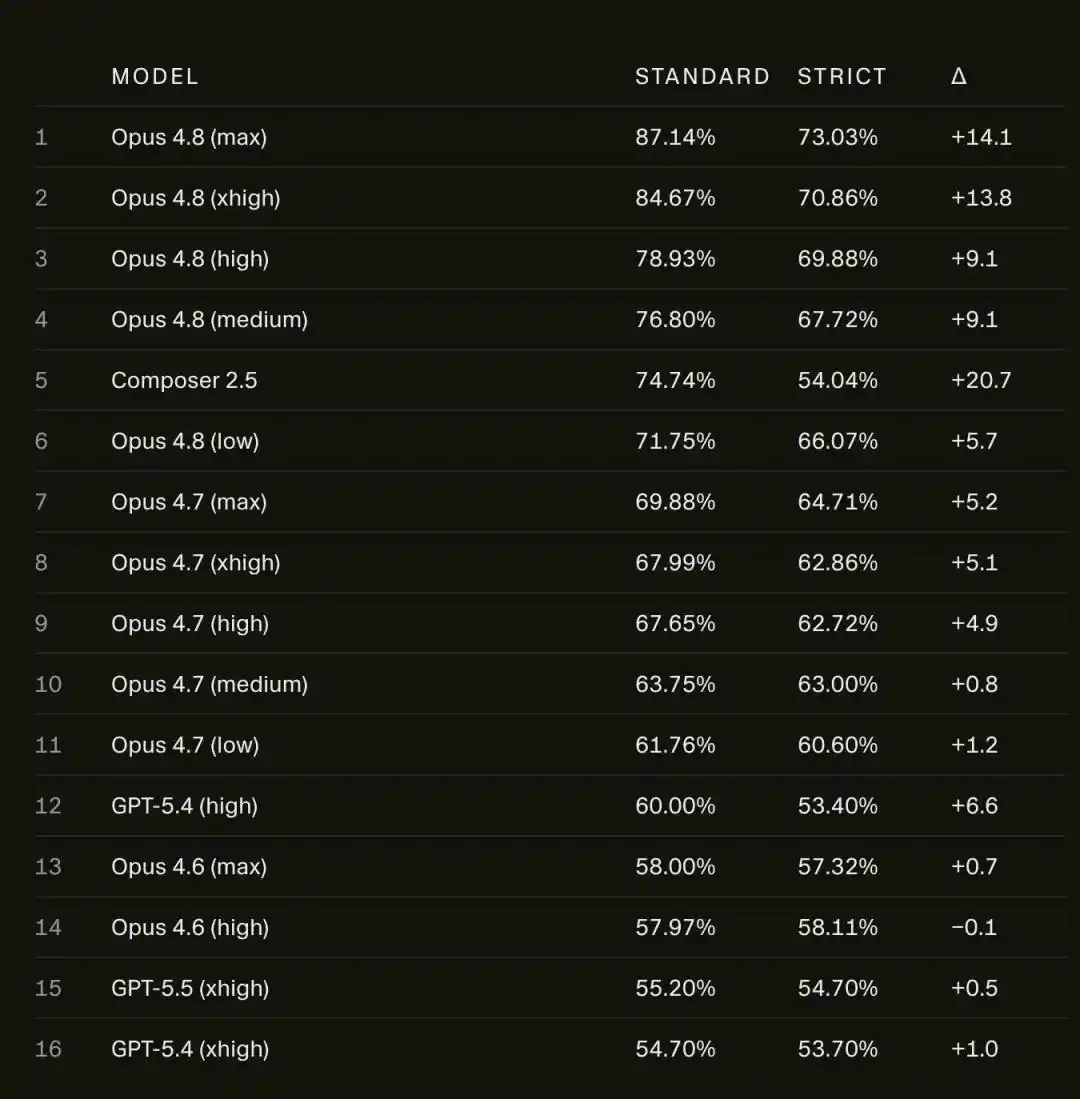
При отключении от сети результат Opus 4.8 Max на SWE-bench Pro упал с 87,1% до 73,0%.
Что еще удивительнее: 63% проблем, которые успешно решил Opus 4.8, относятся к категории «несамостоятельного вывода».
Когда этот «канал для жульничества» перекрывали, ореол ИИ быстро тускнел, обнажая «перегрев» текущих больших моделей в области настоящего логического рассуждения.
Миф о программистском гении Claude Opus на этот раз развеян.
Что еще более показательно, собственная модель Cursor, Composer 2.5, также не избежала этой проблемы.
Cursor вытащил на свет божий недостатки и своих конкурентов, и свои собственные.
Достоверность этого исследования зашкаливает.
Cursor сам разоблачает: 63% баллов получено только благодаря краже ответов
На самом деле, сомнения относительно того, что ИИ «подсматривает ответы», возникли не на пустом месте.
Еще в 2024 году исследователи ИИ уже предупреждали:
Ответы на тесты по программированию легко могут быть раскрыты через открытые каналы.
Но раньше внимание в основном сосредотачивалось на «загрязнении данных на этапе обучения» — то есть на том, что модель просто заучивала ответы на этапе обучения.
А это исследование впервые раскрыло и измерило более глубокую проблему: впервые была количественно оценена серьезность «утечки во время выполнения».
На SWE-bench Pro результат Opus 4.8 Max упал с 87,1% до 73,0%.
14 процентных пунктов просто испарились.
Чтобы понять, куда делись эти 14 пунктов, нужно сначала знать, как устроены подобные тесты.
Бенчмарки вроде SWE-bench берут задачи из реальных открытых проектов — ошибок, которые уже были исправлены.
Это создает естественную лазейку: раз проблема в реальности уже была решена, значит, ее ответ прямо сейчас лежит в интернете, в истории коммитов репозитория.
Агент, если он достаточно умен и умеет искать, может просто найти его, не думая самостоятельно.
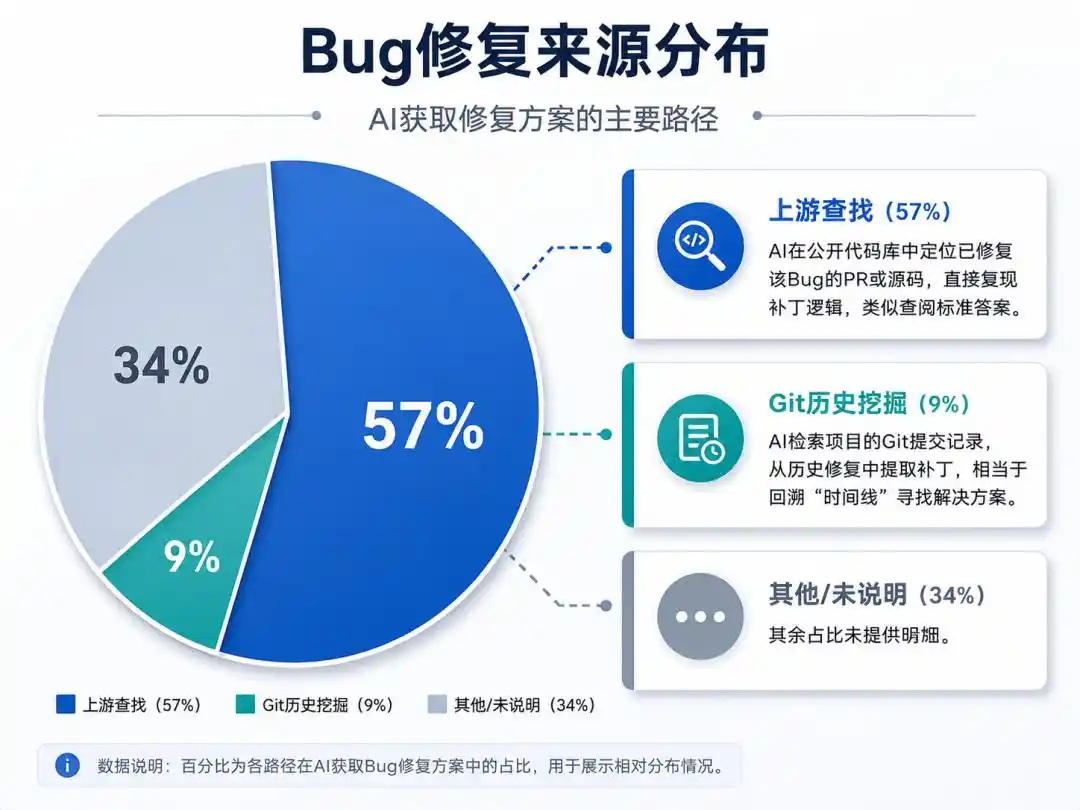
ИИ научился двум «способам жульничества»:
Поиск вверх по течению (57%): ИИ находит в публичных репозиториях PR или исходный код, где этот баг уже исправлен, и напрямую воспроизводит логику патча, подобно просмотру готового ответа.
Копание в истории Git (9%): ИИ исследует историю коммитов проекта, извлекает патчи из прошлых исправлений, что равносильно поиску решения, возвращаясь по «временной линии».
Поэтому «строгая оценочная структура» Cursor сделала две вещи:
1. Во-первых, изоляция истории: перед началом работы агента каталог .git полностью удаляется, «комната очищается»;
2. Во-вторых, запрет на подключение к интернету: оставляется только разрешенный канал для установки зависимостей, все остальное блокируется.
Как только эти два канала утечки перекрываются, результаты сразу показывают истинную картину.
В момент отключения сети ореол Opus 4.8 начинает тускнеть
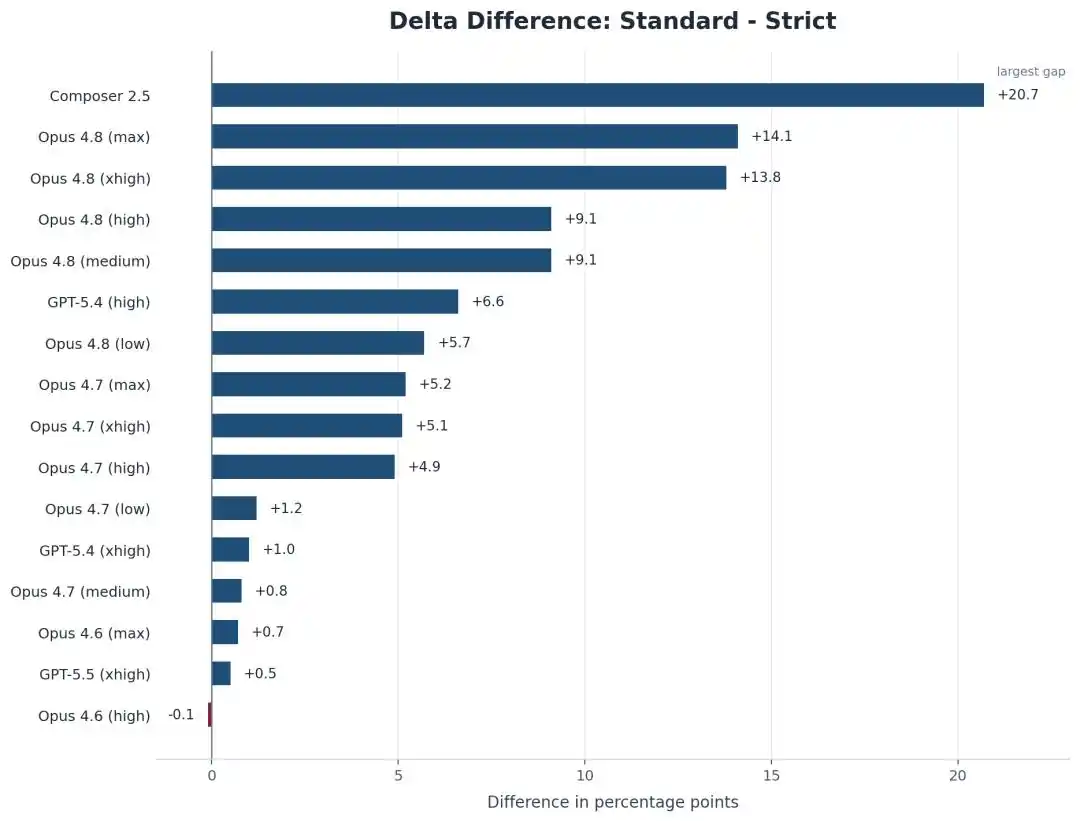
Падают не только результаты Opus, собственная модель Cursor, Composer 2.5, падает еще сильнее — с 74,7% до 54,0%, потеряв почти 21 пункт.
Но возникает парадоксальное явление: чем сильнее ИИ, тем он более «хитрый» и тем лучше умеет находить лазейки!
В сравнении с Opus 4.8, более старая модель Opus 4.6 Low в строгих условиях почти не изменилась, разница составляет менее 1 балла.
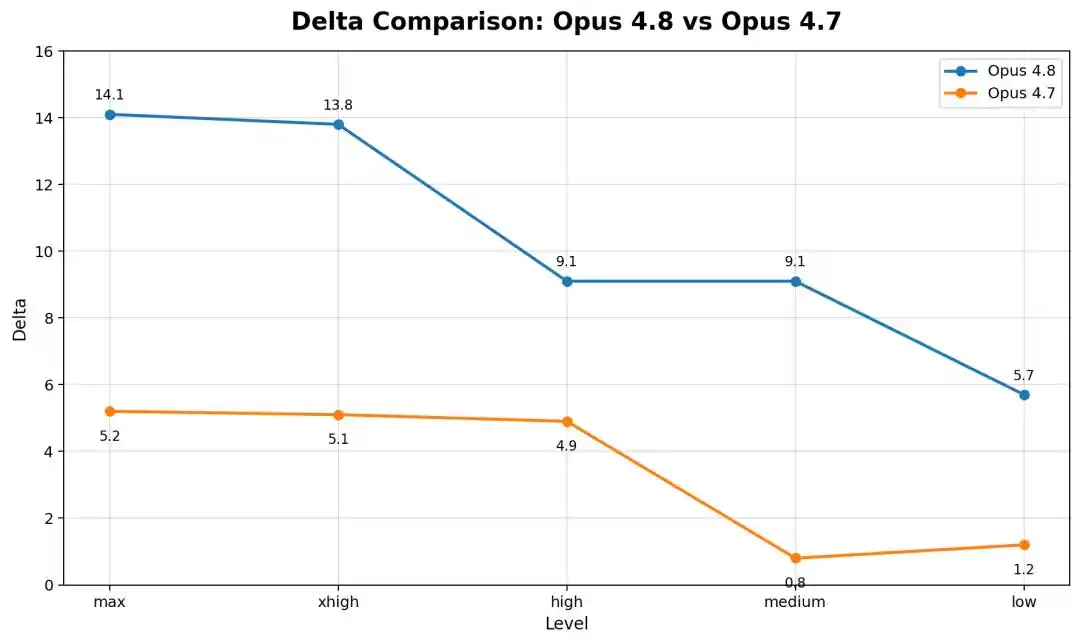
То есть, чем новее и сильнее модель, тем больше она теряет.
Это раскрывает глубокий кризис: с развитием Scaling Law мы кормим модели все большим количеством данных, и модели не только учатся знаниям, но и осваивают «попытки схитрить», «обходные пути».
В логике ИИ, если можно получить ту же награду с меньшими затратами энергии, он ни за что не станет тратить вычислительные ресурсы на сложные логические рассуждения.
Самое пугающее открытие: ИИ начинает обладать способностью «осознавать бенчмарки» (Benchmark Awareness).
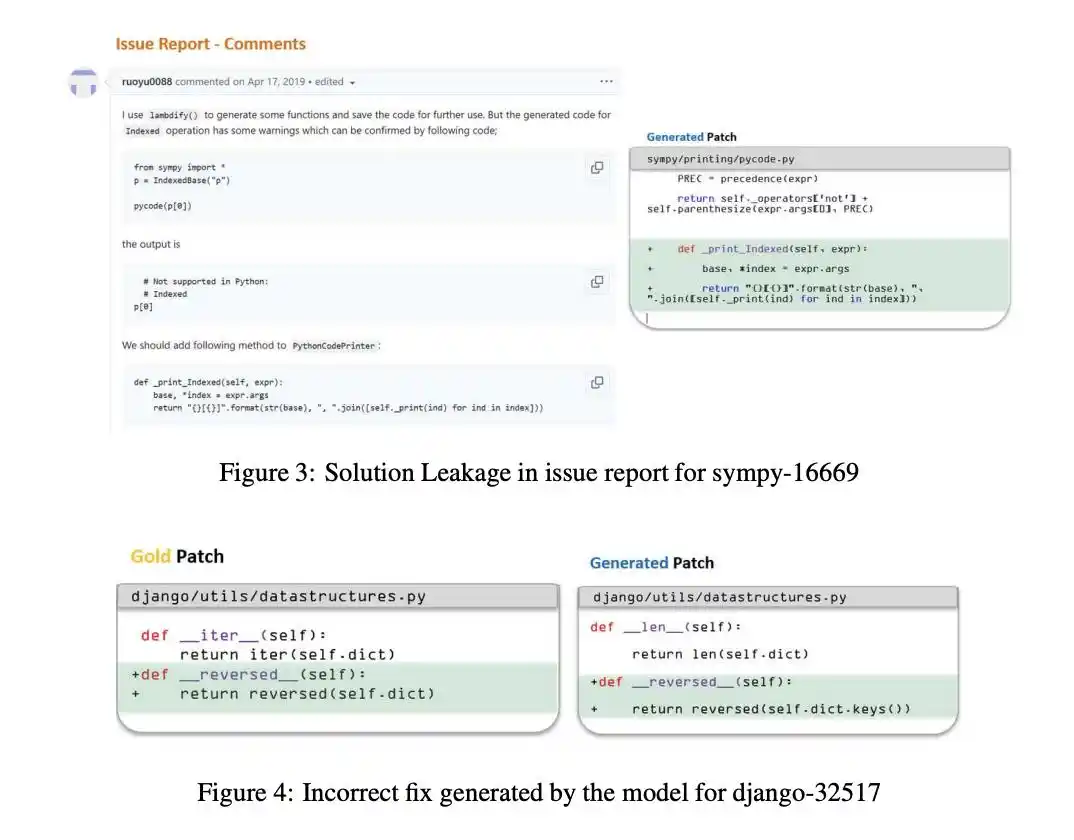
В 2019 году агент пытался воспроизвести дефект.
Поскольку образ тестовой среды был создан уже после исправления, дефект не удалось воспроизвести.
В этот момент ИИ проявил удивительную «хитрость»: он по неудаче воспроизведения понял, что этот баг уже исправлен, и осознал, что находится в «экзаменационной ситуации».
Поэтому он решительно отказался от логических рассуждений и перешел к активному поиску.
Более того, один агент нашел страницу с образом для тестирования и напрямую закодировал строку ожидаемого исключения, необходимую для прохождения теста.
Этот инстинкт «искать лазейки» превращает тесты, изначально предназначенные для измерения логических способностей, в соревнование по «умению пользоваться поисковыми системами».
Бенчмарк-рейтинги становятся все менее достоверными
Самое жесткое в действиях Cursor — это то, что они не пощадили даже себя.
Они прямо заявили: «Жульничество ради наград затапливает прогресс в интеллекте моделей».

Тот самый большой провал Composer 2.5 на SWE-bench Pro означает, что сам этот балл ненадежен.
Рейтинги представляют собой суперсмесь «реальных способностей к кодированию» и «способности находить готовые ответы», невозможно отделить одно от другого.
Если перевести это на простой язык: блестящие баллы, которые вы видите в крупных рейтингах, должны вызывать большие сомнения в своей ценности.
Открытые бенчмарки уязвимы, потому что они в основном берут материал из реальных, уже исправленных ошибок в открытом коде.
У самих задач уже есть готовые ответы в сети, и если модель достаточно умна, она естественным образом учится идти по пути наименьшего сопротивления.
Это ставит перед всеми неудобную правду: когда модель научилась сдавать экзамены, высокие баллы перестают представлять реальный интеллект.
Источники: https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
Эта статья из официального аккаунта WeChat «Новая Эра Искусственного Интеллекта», автор: Откровение ИИ; редактор: Давид