Over the past five months, the MaaS revenue of Alibaba Cloud has grown 15 times, which is just one facet of Alibaba Cloud's self-reconstruction. At the summit, Alibaba Cloud announced the completion of a full-stack Agentization upgrade covering "chip-cloud-model-inference," simultaneously launching the new AI product official website "Qianwen Cloud," the hyper-node server equipped with the self-developed AI chip Zhenwu M890, and the latest flagship model Qwen3.7-Max.
In the words of Alibaba Cloud Senior Vice President Liu Weiguang, "We are building China's largest AI factory." The factory metaphor implies a complete production logic: chips are the raw materials, the cloud is the workshop, models are the machines, the inference platform is the assembly line, and the final commodity produced is the Token.
The essence of this reconstruction is to transform the entire system built over the past 17 years around "humans using the cloud" into a new system centered on "Agents consuming Tokens."
Why Play the Chip Card Now?
Alibaba Cloud rarely emphasized chips in public before. At this summit, it not only released the new-generation training-and-inference integrated AI chip Zhenwu M890 but also unprecedentedly disclosed its chip roadmap for the next two years, with successive generations of products, Zhenwu V900 and Zhenwu J900, progressing year by year.
The Zhenwu M890 is equipped with 144GB of video memory, an inter-chip interconnect bandwidth of 800GB/s, and performance three times that of the previous generation Zhenwu 810E. Paired with the self-developed ICN Switch interconnect chip, 128 AI chips can be combined into a single machine, with P2P latency compressed to within 150 nanoseconds.
But beyond the specifications, the more crucial information is scale. The Zhenwu series has cumulatively shipped 560,000 units and has already entered over 400 clients across more than 20 industries, including telecommunications, FAW, and SPDB.

Liu Weiguang repeatedly used Google as an analogy. The deep integration of Google's TPU and Gemini allowed Google to achieve optimal cost-effectiveness within its own framework. Alibaba Cloud certainly wants to follow the same path. He summarized the competitive logic in one sentence: "If the future competition is about every chip generating more high-quality Tokens than competitors, then we win."
Combined with the Yitian CPU, Panmai Smart NIC, and Zhenyue storage master control chip, T-Head's chip landscape has expanded from a single point to complete coverage of computing power, networking, and storage. When inference demand expands exponentially, only by holding chips in one's own hands can the marginal cost of each Token be controlled.
The reasoning is not complicated. Model companies can compete on parameters, but cloud providers ultimately compete on whose Tokens are cheaper, more stable, and faster. Chips are the starting point of this cost war.
The Cloud Itself Must Be Rewritten
Chips solve the problem of "being able to run," but Agents' demands on the cloud extend far beyond computing power.
The interaction logic of traditional cloud products is designed for humans: opening the console, looking at menus, configuring parameters, clicking buttons. This setup is completely unusable for Agents. Agents don't view web pages or click buttons; they need structured capability descriptions, standardized calling protocols, and predictable feedback.
Alibaba Cloud CTO Li Feifei used a set of comparisons to illustrate the problem: Traditional cloud workloads are steady-state; an ECS instance, once launched, might run for months or even years. But Agent workloads are characterized by "irregular elasticity, short lifecycles, and instant scaling up and down." After an Agent completes a task, its sandbox is destroyed. The next request might come in a few milliseconds, or it might not come for several hours.
To address this, Alibaba Cloud has done three things.
First, it made cloud products Skill-based, MCP-based, and CLI-based. Simply put, each cloud product is packaged into a standardized interface that Agents can directly call, using the cloud like calling functions.
Second, it built a dedicated runtime environment for Agents—lightweight sandboxes, multi-Agent collaboration, cross-task memory, and data flow channels.
Third, it rebuilt the scheduling logic, shifting from "resource scheduling" to "task scheduling," because traditional resource orchestration methods cannot withstand the concurrency of massive numbers of Agents.
Liu Weiguang stated that some AI applications, after going online, automatically provision cloud resources in the background—virtual machines, database instances, sandbox environments—without any human intervention. The volume of resources automatically provisioned for one customer in a single day is equivalent to two weeks of manual operations in the past.
"This essentially means Agents are using the cloud by themselves." Liu Weiguang provided an internal conversion formula: Token consumption can be proportionally converted into GPU usage, and each additional GPU card roughly drives a one-to-one increase in CPU. In other words, the growth in Token revenue is not cannibalizing traditional cloud revenue but is pulling it up, provided the cloud platform can handle the Agent workload.
Therefore, Alibaba Cloud is not merely adding a layer of AI capability to the original system. It is rewriting everything from interaction methods, scheduling logic, and billing models to product forms.
Models Are Not for Chatting
The third layer of the full-stack reconstruction is the model. Qwen3.7-Max ranked first among domestic models in the global Arena blind test overall leaderboard, surpassing Kimi-K2.6, DeepSeek-v4-pro, and GLM-5.1. The focus of this release is Alibaba's redefinition of the direction of model capabilities.
Alibaba Group's Tongyi large model leader Zhou Jingren said, "In the past, we pursued how well the model 'spoke.' Now we demand that the model 'gets things done.'"
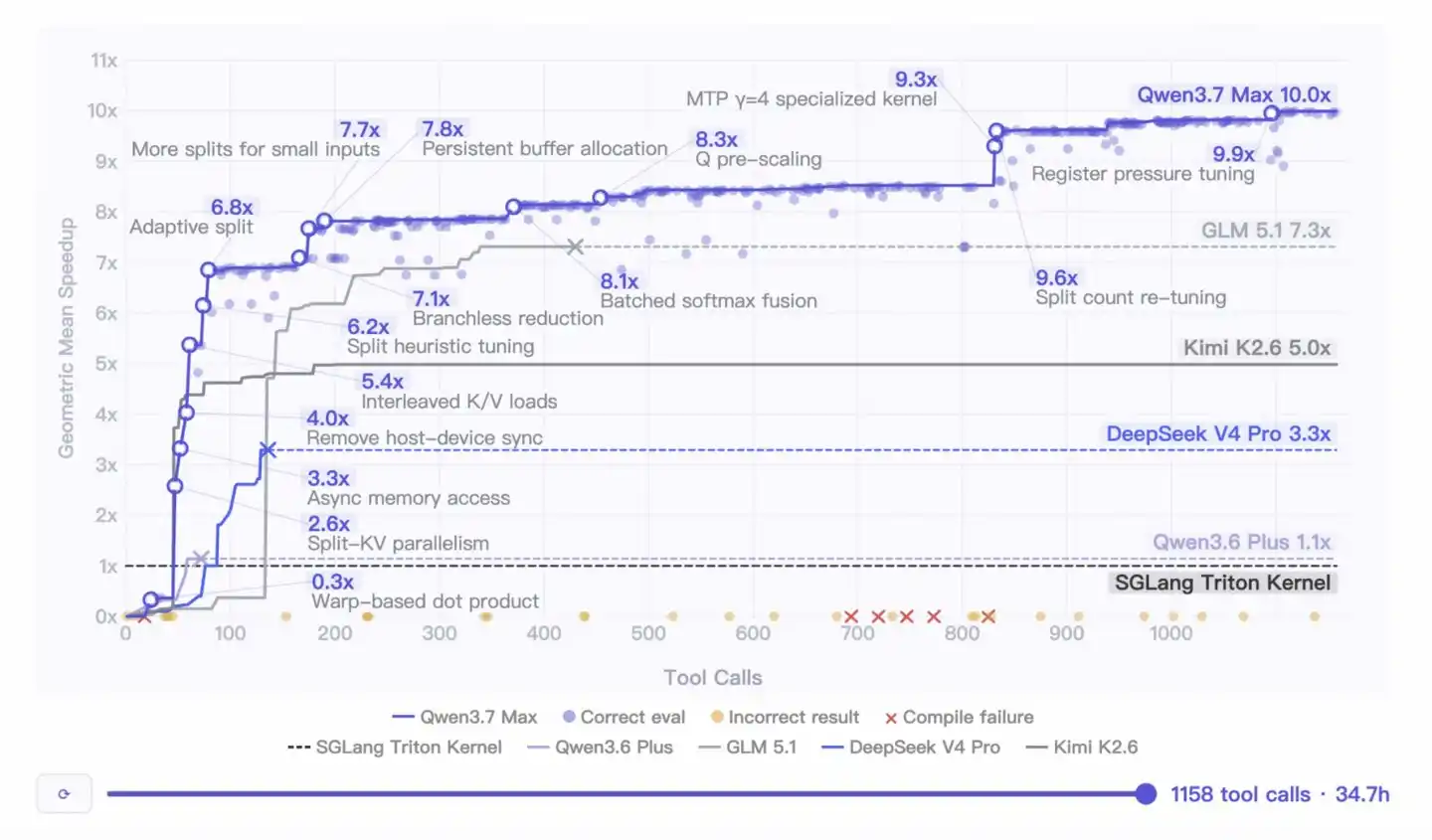
Taking Alibaba Cloud's practice in chips as an example, on the previously untrained Zhenwu M890 chip, Qwen3.7-Max, relying solely on a task description, autonomously worked for 35 hours from scratch, independently completing the writing and optimization of a production-grade AI computing kernel. The final performance was 10 times higher than the official version, with no human intervention or intermediate guidance throughout the entire process.
This demonstrates the model's core capability in Agent scenarios: long-range autonomous execution. It takes a task, breaks it down, plans, writes code, debugs—working continuously for 35 hours without stopping.
To support this level of inference demand, the Bailian platform has also undergone corresponding upgrades: pooled scheduling to improve GPU utilization, context caching to eliminate redundant calculations, and elastic throughput scheduling to handle concurrency peaks.
In terms of ecosystem, Bailian remains open for access. Besides the Qianwen model matrix, it has also onboarded third-party models such as Zhipu's GLM-5.1, MiniMax's M2.7, and Moonshot AI's Kimi K2.6.
Liu Weiguang mentioned, "Clients in practice don't use just one model; they use a combination of multiple models. We provide the combinations; clients find the mix that best suits them on the platform." At the summit, executives from six leading domestic model companies collectively took the stage, creating a scene reminiscent of a "domestic AI alliance."
Within the last three months, the Qianwen flagship model has iterated through three versions: 3.5, 3.6, and 3.7. This release rhythm itself sends a signal: the competition in model capabilities is far from over, and Alibaba intends to establish a long-term advantage through the vertical integration of self-developed chips and self-developed models.
The Real Bet of This Reconstruction
Looking back, the underlying logic of Alibaba Cloud's full-stack reconstruction is simple and pure. When AI revenue growth far outpaces traditional cloud business, when Tokens might replace ECS as the largest product line, when Agents start automatically provisioning cloud resources without humans needing to log into the console, the entire technical system designed for humans has reached a point where it must be changed.
But the difficulty of execution is another matter. Liu Weiguang himself admitted that the transformation is "easy to talk about, very hard to do." In the past, the sales team interacted with clients' IT departments. Now, doing MaaS requires dialogue with business units or even the CEO.
"Your conversational ability, your experience, are requirements of a completely different level." Alibaba Cloud has already established dedicated MaaS sales roles for large enterprise clients, operating and being assessed separately from traditional IaaS sales.
Performance metrics are also changing, no longer just looking at call volume, but at "high-quality Tokens"—Tokens that solve real problems, not chit-chat Tokens. Three core metrics: daily growth in paying customers, the number of core business systems integrated with models, and the efficiency of Agents autonomously completing task loops.
These adjustments at the organizational and mechanism levels often indicate a company's true judgment more than technical announcements. Alibaba Cloud wants to rebuild its revenue structure, customer relationships, and sales system. Liu Weiguang stated, "When we were building the cloud before, the client's IT budget was calculable—how many servers offline, roughly how much to move them up—you could see the problem. But with MaaS, the answer to this problem is unknown; once you get in, it might exceed your imagination."
The problem statement can't be seen, and the answer is uncertain, but Alibaba Cloud has still decided to dismantle and rewrite its entire system because the only certainty is that AI is an opportunity ten or even a hundred times larger than any before.
This is probably the most noteworthy information from this summit: not which chip has more computing power, or which model ranks where, but that China's largest cloud provider is betting on a future it believes will come, with an aggressive posture approaching that of a startup. (Author: Zhang Shuai, Editor: Yang Lin)