Источник: LEGION (@legiondotcc)
Оригинальное название: What prediction markets reveal about ICOs
Компиляция и редактирование: BitpushNews
Рынки прогнозов в мире токенов
Рынки прогнозов на выпуск токенов Polymarket уже обработали почти 2,5 миллиарда долларов объема торгов. Платформа заявляет о поразительной точности прогнозов — 100% для прогноза объема привлеченных средств и более 90% для прогноза оценки. Однако глубокий анализ показывает, что эти данные серьезно вводят в заблуждение: истинный рыночный сигнал заключается не в «том, что угадали правильно», а в «том, насколько ошиблись».
Мы проанализировали данные 231 рынка прогнозов по 29 событиям выпуска токенов, сопоставив их с фактическими показателями токенов от CoinGecko, и обнаружили, что эти рынки не являются надежным прогностическим инструментом, а служат контр-индикатором, отражающим рыночные настроения.
Ключевой вывод:
За неделю до закрытия рынков прогнозов реальная точность прогнозов составила лишь 66,7%. В ключевые моменты толпа ошибалась 1 раз из 3, и ошибки прогнозов систематически проявлялись как излишний оптимизм.
Проблема 24-часовой волатильности: используя часовые данные CoinGecko, мы обнаружили, что ставки на рынках PM «FDV через 24 часа после листинга превысит X» делаются на экстремальную волатильность.
Среднее изменение за 24 часа: ±23% | Лучший случай: Monad +54,8% | Худший случай: Trove -38,7%.
75% токенов падали в цене в первые 24 часа после листинга. Точность 24-часовых прогнозов FDV на PM: всего 62,5%.
Заблуждение относительно точности
Когда мы отслеживаем изменение вероятностей на рынке с течением времени, а не просто смотрим на конечный результат, возникает иная картина. Рынки обещаний кажутся «на 100% точными», потому что по мере проведения продаж происходит утечка конечных данных. Инсайдеры и наблюдатели обновляют цены на основе этого, что является всего лишь ценовым открытием постфактум.

Ключевой вывод:
И рынки обещаний, и рынки FDV по мере закрытия стремятся к точности ~100%, потому что они рассчитываются уже после того, как результат известен. Рынки обещаний закрываются после окончания продаж; рынки FDV закрываются после окончания 24-часового периода после листинга. Единственным значимым прогностическим индикатором является точность за неделю до закрытия, когда и существует настоящая неопределенность. Точность обещаний в 66,7% показывает, что в ключевые моменты рынок ошибался в трети случаев.
Где ошибается суждение пользователей
Мы проверили каждый рынок, где пользователи проявляли более 60% уверенности в нереализованном результате. В каждом случае ошибка была однонаправленной: чрезмерный оптимизм. Толпа постоянно верила, что объем финансирования будет больше, а оценка — выше, чем на самом деле.
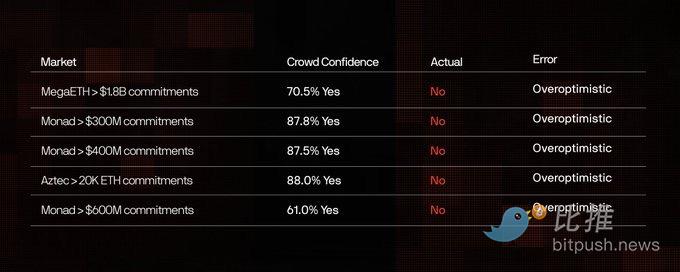
Эта систематическая ошибка указывает на то, что участники этих рынков — оптимистичные спекулянты, которых привлекла именно перспектива продажи токенов.
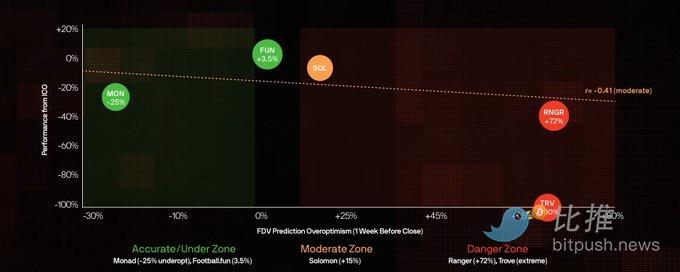
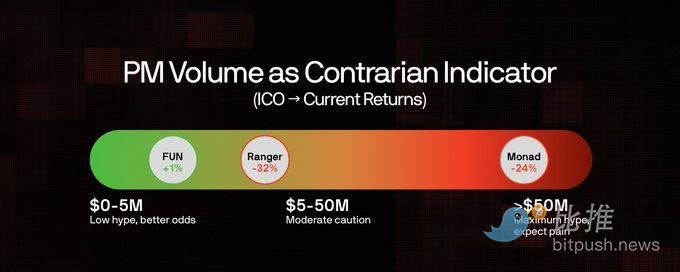
Чрезмерный оптимизм vs Показатели токена (с момента ICO)
Методология: этот анализ включает только те рынки, где проводилось публичное ICO и токен уже выпущен, с использованием коэффициентов PM за неделю до закрытия. Степень чрезмерного оптимизма = (Прогнозируемый PM FDV – Фактический 24-часовой FDV) / Фактический 24-часовой FDV. На оси Y показана доходность с момента ICO по настоящее время.
Данные показывают умеренную отрицательную корреляцию (r=-0,41) между степенью чрезмерного оптимизма и доходностью ICO. Monad был недооценен (-25%), но с момента ICO все равно упал на -24%. Ranger был самым переоцененным по прогнозам (+72%), с момента ICO упал на -32%. Только Football.fun остается выше цены ICO (+1%).
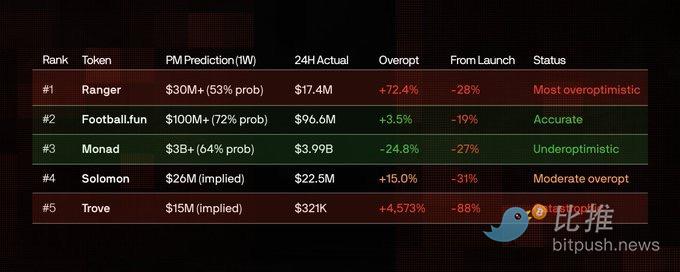
Рейтинг показателей токенов
В приведенной ниже таблице используются исторические коэффициенты PM за неделю до закрытия, что раскрывает реальную точность прогнозов.
Модель ясна: экстремальный чрезмерный оптимизм предвещает катастрофу, а высокий объем торгов на PM, даже когда его прогноз точен, является контр-индикатором.
ICO FDV vs Показатели листинга
Ключевой вывод: Среди токенов с данными ICO, 40% токенов вышли на биржу по цене ниже их ICO-оценки. Средняя доходность с момента ICO по настоящее время: -32,2%. Только Football.fun торгуется выше своей ICO-цены.
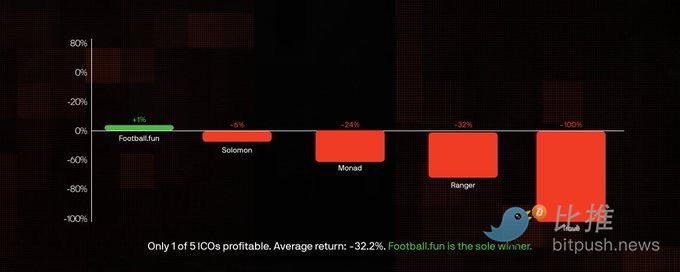
Модель очень очевидна: даже те токены, которые вышли на биржу с оценкой выше их ICO-оценки (Monad, Solomon), в конечном итоге упали ниже цены ICO. Из 5 токенов ICO в этом наборе данных только Football.fun в настоящее время торгуется выше своей ICO-цены (+1%), став единственным победителем.
Ключевые выводы
Проанализировав 231 рынок, объем торгов в 241,5 миллиона долларов и 8 выпущенных токенов с проверенными данными 24-часового FDV, можно четко выделить несколько выводов:
1. «Точность 100%» бессмысленна. Рынки закрываются после того, как результат известен (рынки обещаний — после продаж, рынки FDV — через 24 часа), поэтому точность на поздних этапах незначительно близка к ~100%. За неделю до закрытия реальная прогностическая точность рынков обещаний составляла всего 66,7%. В ключевые моменты толпа ошибалась в трети случаев.
2. Систематический чрезмерный оптимизм. Среди 15 лучших рынков на 5 рынках была уверенность более 60% в достижении порогов, которые не были достигнуты. Среднее завышение FDV: +35%.
3. Высокий объем торгов на PM является контр-индикатором. Monad (89 млн долларов) и MegaETH (67 млн долларов) показали наибольшую степень чрезмерного оптимизма. Чем больше денег вкладывает толпа, тем увереннее она становится и тем сильнее ошибается.
4. Консервативные прогнозы = лучшие результаты. Токены, по которым прогнозы PM были точны (Monad, Football.fun), упали меньше. Низкий ажиотаж и точные прогнозы, по-видимому, являются бычьим сигналом.
Торговые сигналы
На основе анализа мы можем извлечь действенные сигналы для оценки будущих продаж токенов. Они не являются абсолютно точными, но представляют собой закономерности, неоднократно появлявшиеся в нашем наборе данных.
Медвежьи сигналы
-
Объем торгов на PM > 50 миллионов долларов
-
Чрезмерный оптимизм по FDV > 50%
-
Все пороги FDV, вероятно, не будут достигнуты
-
Чрезмерный оптимизм по сумме обещаний > 30%
Бычьи сигналы (относительно)
-
Объем торгов на PM < 5 миллионов долларов
-
Ошибка прогноза FDV в пределах 20%
-
Будут достигнуты несколько порогов FDV
-
Ожидания толпы консервативны
Эта асимметрия крайне важна. Медвежьи сигналы являются сильным индикатором прогнозирования плохих результатов, а бычьи сигналы относительно слабы — они лишь намекают, что токен может «упасть не так сильно», как его раскрученные аналоги. На рынке, где цены токенов в целом откатились от исторических максимумов, «упасть меньше» — уже наилучший scenario.
В конечном счете: рынки продаж токенов Polymarket по своей сути являются измерителями ажиотажа. Истинный сигнал заключается не в самом прогнозе, а в степени его отклонения от фактических показателей. Когда массы скупаются, делая ставки на то, что оценки будут продолжать расти, благоразумнее всего сохранять бдительность.
История неоднократно доказывала: когда рыночный консенсус достигает пика, именно тогда инвесторы往往 испытывают наибольшую боль.
Источники данных в статье: Polymarket CLOB API, CoinGecko, CMC (перекрестная проверка), данные о ценах по состоянию на 27 января 2026 года.
Twitter:https://twitter.com/BitpushNewsCN
Группа общения в TG比推:https://t.me/BitPushCommunity
Подписка в TG比推: https://t.me/bitpush





