Автоматизированные исследования на этот раз действительно вышли из песочницы кода в реальный физический мир.
Недавно Джим Фан, руководитель лаборатории NVIDIA GEAR, представил новый проект под названием ENPIRE. Это их первая реализация автоматизированных исследований на роботизированном оборудовании.
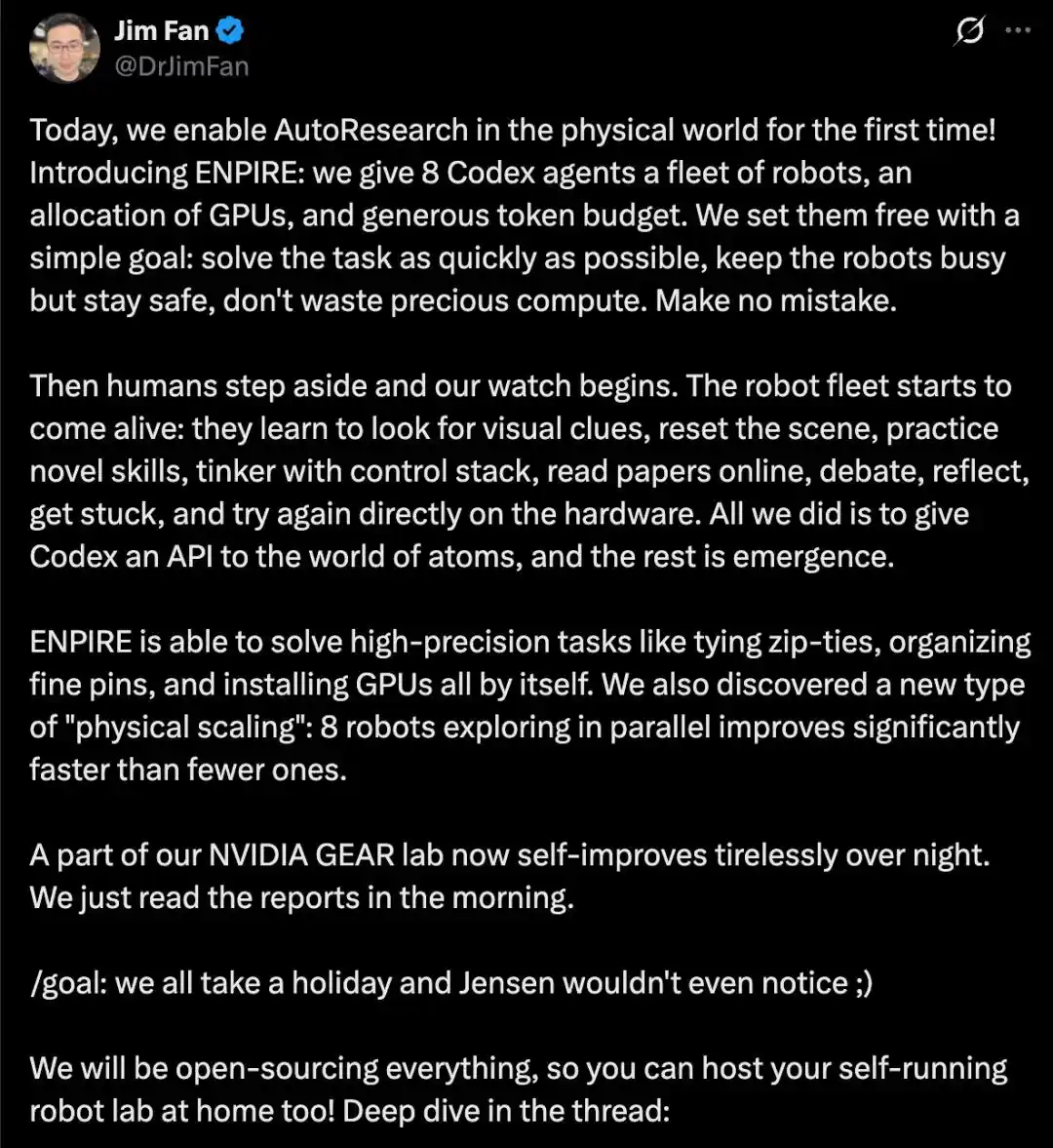
Они поместили 8 агентов Codex во флотилию роботов, выделили им вычислительные мощности GPU и достаточный бюджет токенов, поставив простую цель: как можно быстрее решать задачи, поддерживать роботов в занятом, но безопасном состоянии и не тратить вычислительные ресурсы впустую.
Далее человеческое вмешательство практически прекратилось. Агенты автономно управляли всем замкнутым циклом: автоматически сбрасывали сцены, искали литературу, реализовывали идеи и строили инфраструктуру, обучали и развертывали стратегии, проводили самопроверку, анализировали логи и улучшали код, постоянно итерационно повторяя этот процесс, пока в реальном оборудовании не удавалось надежно выполнить задачи, требующие высокой точности и ловкости, такие как завязывание кабельных стяжек, упорядочивание игл в коробке или установка GPU.
Они также наблюдали «закон масштабирования в физическом мире»: увеличение количества параллельно работающих роботов (например, с нескольких до 8) значительно ускоряло решение задач.
В настоящее время часть систем лаборатории уже реализует самоитерацию в течение всей ночи без вмешательства человека, и исследователям достаточно лишь просматривать отчеты по утрам.
Джим Фан заявил, что цель на будущее — позволить членам команды спокойно уходить в отпуск, и даже генеральный директор NVIDIA Дженсен Хуанг не будет замечать, что лаборатория продолжает работать автономно.
Проект ENPIRE планируется полностью открыть, и тогда обычные разработчики смогут построить у себя дома аналогичную систему автономных роботизированных исследований.

Адрес проекта: https://research.nvidia.com/labs/gear/enpire/
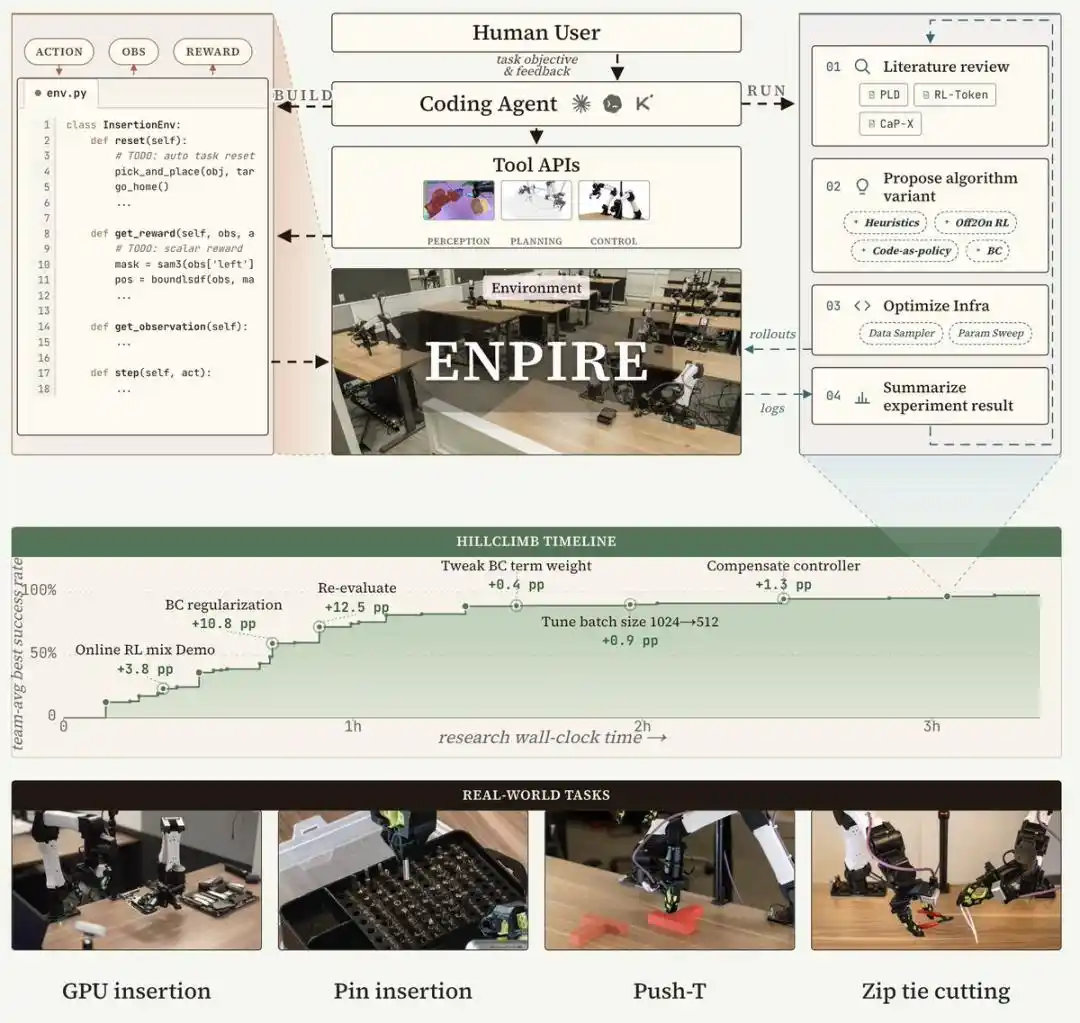
Архитектура системы ENPIRE: четыре модуля образуют замкнутый цикл
ENPIRE — это каркасная система, разработанная для агентов-кодеров, которая с помощью четырех ключевых модулей создает воспроизводимый цикл физической обратной связи: модуль среды (EN) отвечает за автоматический сброс и проверку, модуль улучшения стратегии (PI) запускает оптимизацию стратегии, модуль прогона (R) поддерживает оценку стратегии на одном или нескольких роботах параллельно, а модуль эволюции (E) позволяет агенту-кодеру анализировать логи, изучать литературу, улучшать инфраструктуру обучения и код алгоритмов для устранения режимов сбоев.
Эта замкнутая система превращает обучение роботов в реальном мире в контролируемый, управляемый агентом процесс оптимизации, что сводит к минимуму ручной труд и одновременно позволяет проводить честные сравнительные эксперименты между различными рецептами обучения и вариантами агентов.
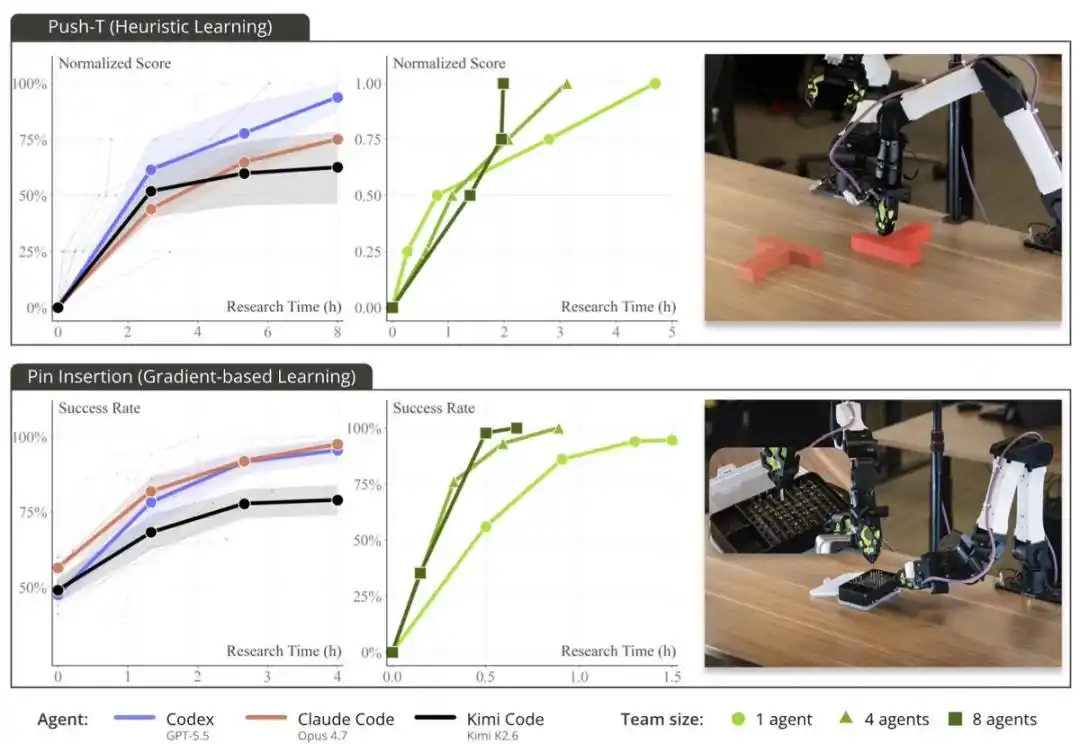
Благодаря поддержке ENPIRE передовые агенты-программисты смогли автономно разрабатывать стратегии и достигать 99% успеха в выполнении сложных задач по ловкому манипулированию в реальном мире, таких как PushT, укладывание штифтов в коробку, обрезание кабельных стяжек ножом.
Ключевое наблюдение: сброс среды часто проще, чем выполнение самой задачи
Одним из ключевых наблюдений стало: для многих роботизированных задач сброс среды зачастую проще, чем выполнение самой задачи.
Поэтому подход ENPIRE заключается в том, чтобы сначала позволить агенту построить среду автоматического сброса с помощью Code-as-Policy. Во многих случаях такой сброс — это просто задача pick-and-place, которую может решить Cap-X.
Затем интеллектуальный агент пишет эвристическую функцию вознаграждения. Исследовательская команда помещает эту среду в песочницу и запускает агента для проведения автоматизированных исследований вокруг полученных баллов.
Это также перекликается с определением автоматизированных исследований по Карпати: здесь речь идет не о простой настройке гиперпараметра или изменении небольшого фрагмента кода. Агент будет исследовать различные парадигмы в интернете и переписывать все, что может повысить производительность, включая алгоритмы, цели обучения и даже загрузчики данных.
В задаче с укладкой штифтов один агент даже самостоятельно написал контроллер безопасности по силе контакта, превзойдя по эффективности простую настройку нескольких параметров обучения с подкреплением.
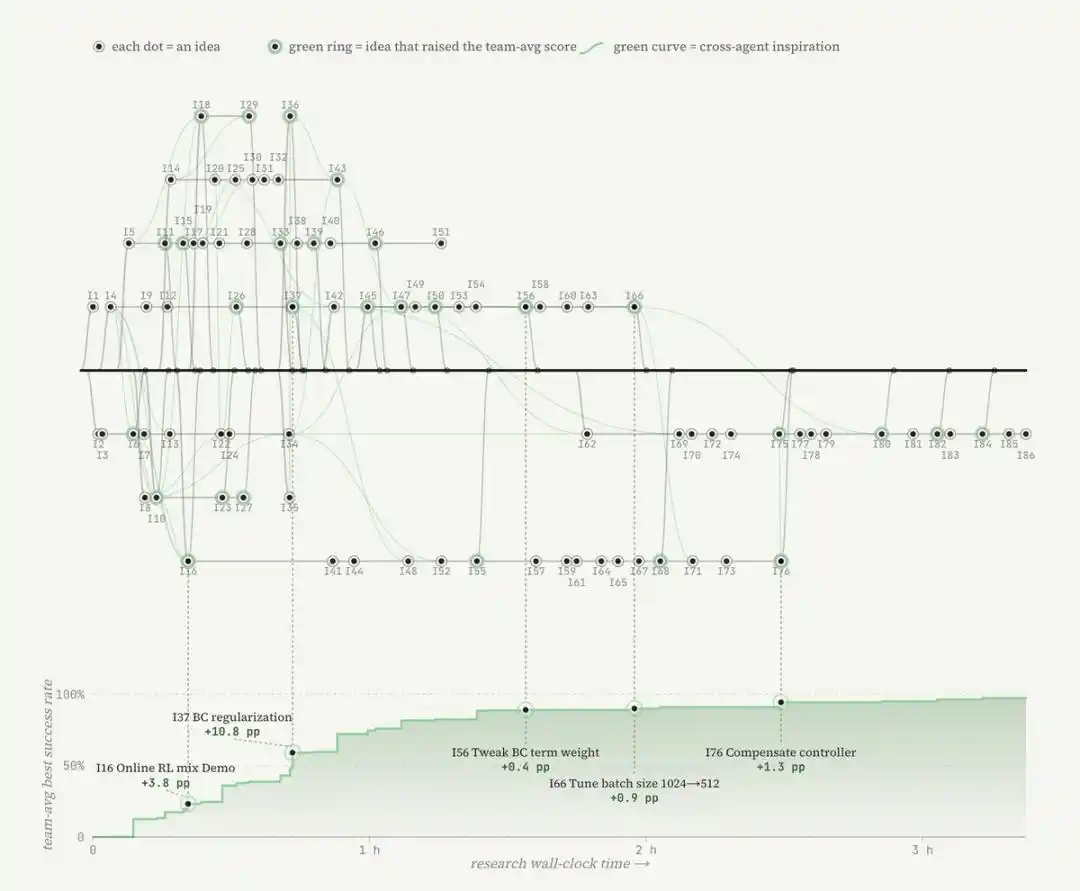
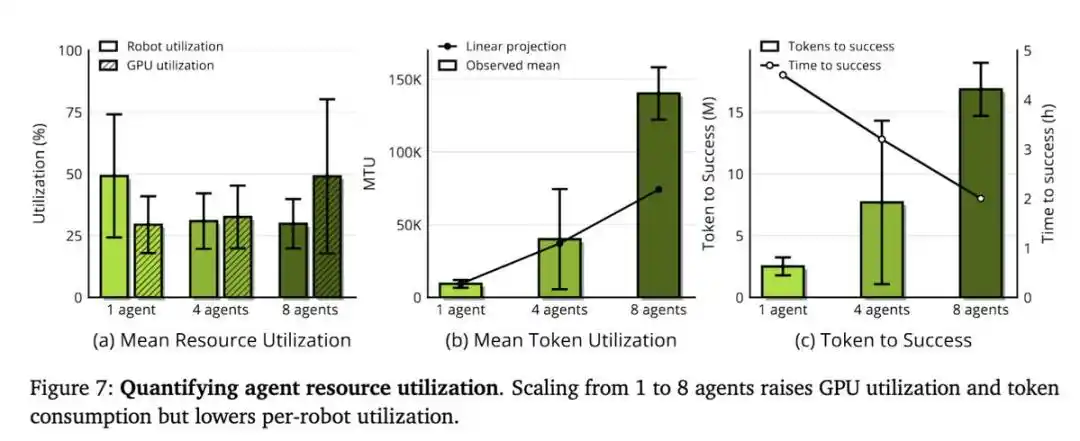
Новые метрики: MRU и MTU
Масштабируемость ENPIRE зависит от размера команды агентов и вычислительных ресурсов, но здесь по-настоящему дефицитным ресурсом являются не GPU, а время работы роботов.
Когда исследовательская группа предоставила агентам 8 роботов вместо 1, время, необходимое для достижения почти идеального результата в задаче с укладкой штифтов, сократилось с более чем 1,5 часов до примерно 40 минут. Эти агенты координировались через Git: делились кодом, отказывались от неперспективных идей и автономно выбирали лучшие результаты выполнения друг у друга.
Это указывает на более масштабное изменение: робототехнические исследования превращаются в работу по проектированию среды — созданию окружения, в котором агенты-программисты могут проводить автоматизированные исследования; алгоритмическая работа смещается на более высокий уровень, превращаясь в построение замкнутого цикла обратной связи, который агенты могут замыкать самостоятельно.
И этот цикл будет наращиваться по сложным процентам: навык, освоенный агентом сегодня, завтра станет строительным блоком для создания и сброса среды для более сложных задач. Способности будут самовоспроизводиться, порождая новые способности.
В этой парадигме реальным жестким ограничением является бюджет на взаимодействие с реальным миром.
Поэтому исследовательская группа предложила две метрики:
- Средняя утилизация роботов (Mean Robot Utilization, MRU): доля времени, которое роботы фактически тратят на проведение экспериментов, от общего реального затраченного времени.
- Средняя утилизация токенов (Mean Token Utilization, MTU): измеряет эффективность преобразования агентом токенов в исследовательский прогресс.
В их экспериментах MRU всегда была ниже 50%. То есть роботы половину времени простаивали, ожидая, пока агент подумает. Поэтому улучшение обвязки (harness) и более быстрые модели напрямую превращаются в практическую выгоду.
PushT — давно используемый бенчмарк для манипуляций роботов. Обычно для выполнения этой задачи требуется большое количество демонстрационных данных от человека и несколько часов обучения методом поведенческого клонирования.
Но они увидели, что Codex, Claude Code и Kimi Code с помощью одного эвристического метода на основе правил «решили» эту задачу менее чем за 2 часа: без использования нейронных сетей, без обучения и без каких-либо человеческих данных.
Чтобы больше людей смогли попробовать автоматизированные исследования в физическом мире у себя дома, они на основе набора SO-101 от @LeRobotHF + NVIDIA Jetson Thor разработали полноценную стековую систему. Эта система может выполнять задачу PushT.
Ссылки для справки:
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
Статья из официального аккаунта WeChat «Машины и разум» (ID: almosthuman2014), автор: Ян Вэнь





