Только что, DeepSeek V4 выпустил обновление.
Была представлена новая фреймворк спекулятивного декодирования (Speculative Decoding) DSpark, а также одновременно был открыт исходный код полного стека фреймворка спекулятивного декодирования DeepSpec, поддерживающего эту версию.
DeepSeek-V4-Pro-DSpark не является моделью с совершенно новой архитектурой, а представляет собой DeepSeek-V4-Pro с добавленным модулем спекулятивного декодирования. Основное внимание в этом обновлении уделено инженерной реализации, а не итерации самих возможностей модели.
DSpark уже развернут в реальном онлайн-трафике DeepSeek-V4 (Flash и Pro), что значительно ускорило скорость вывода (инференса) больших языковых моделей (LLM).

Технический отчет: «DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation»
Ссылка на технический отчет: https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
Основная цель DSpark — решить проблему узких мест в задержке и пропускной способности вывода LLM в производственных средах (особенно в сценариях с высокой параллельной нагрузкой). Проще говоря, DSpark успешно объединил высокопроизводительную «параллельную генерацию» с адаптивной «проверкой с учетом нагрузки».
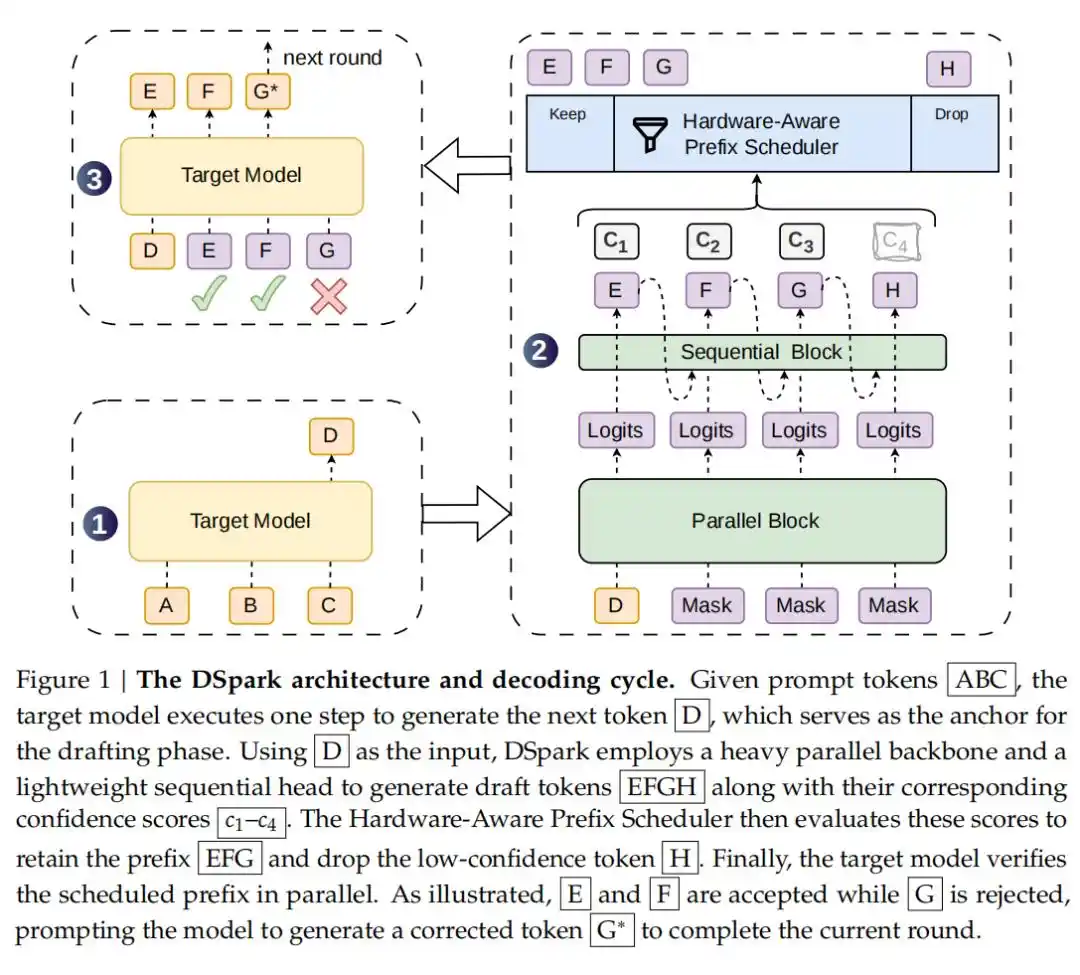
Спекулятивное декодирование — это техника ускорения вывода больших языковых моделей без изменения распределения их вывода. Основная идея заключается во внедрении легковесной «черновой модели» (draft model), которая предварительно генерирует несколько кандидатных токенов, а затем целевая модель (target model) выполняет пакетную проверку и принятие этих кандидатов. Это преобразует последовательную потокенную генерацию в параллельную пакетную проверку, значительно снижая сквозную задержку.
На этой основе инновация DSpark заключается во внедрении архитектуры полуавторегрессивной генерации (Semi-Autoregressive Generation): она сохраняет преимущества высокой пропускной способности параллельной черновой модели, одновременно добавляя легковесный последовательный модуль для моделирования зависимостей между токенами внутри блока, чтобы смягчить проблему снижения процента принятия (acceptance rate), которая часто возникает у параллельной черновой модели на последующих позициях.
Кроме того, используется аппаратно-зависимая проверка по расписанию на основе уверенности (Confidence-Scheduled Verification): в предыдущих реализациях спекулятивного декодирования обычно все сгенерированные черновые токены вслепую отправлялись на проверку. При высокой нагрузке на систему эти хвостовые токены, которые с высокой вероятностью будут отклонены, серьезно растрачивают ценную вычислительную мощность пакетной обработки. DSpark вводит голову уверенности (Confidence Head) для оценки вероятности «выживания» каждого токена. В сочетании с планировщиком префиксов, учитывающим аппаратное обеспечение, система может динамически определять оптимальную длину проверки для каждого запроса на основе характеристик текущей пропускной способности движка, выделяя вычислительные ресурсы только токенам с наивысшей ожидаемой отдачей.
Для развертывания в реальной онлайн-инфраструктуре планировщик DSpark использует асинхронный механизм для совместимости с планированием с нулевыми накладными расходами (ZOS) и непрерывным воспроизведением CUDA-графов. Он использует исторические прогнозы из предыдущих шагов для определения текущей динамической длины усечения, скрывая тем самым задержку планирования, предотвращая остановки конвейера GPU и гарантируя при этом полное и безошибочное восстановление выходного распределения целевой модели.
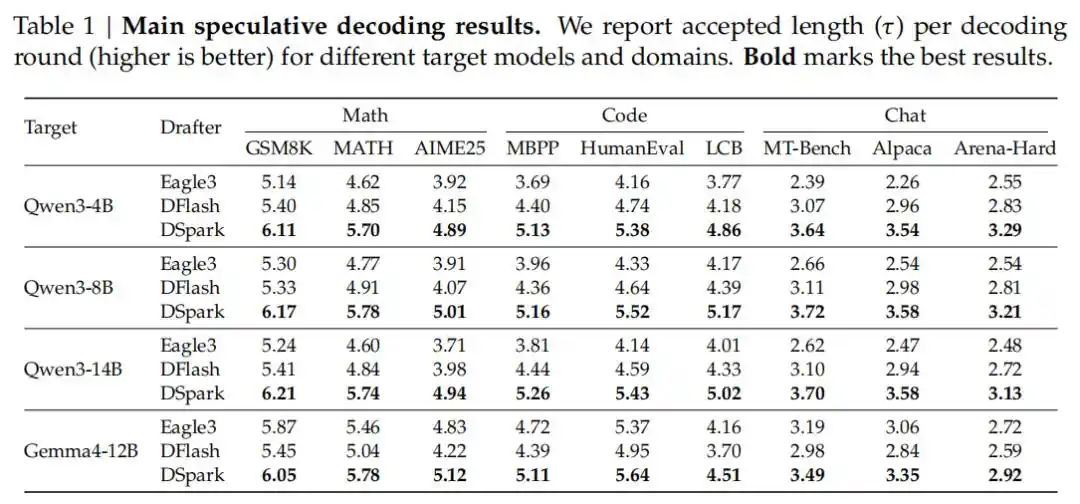
В тестах, охватывающих математические рассуждения, генерацию кода и повседневный диалог, DSpark значительно превзошел самые передовые авторегрессивные модели (Eagle3) и параллельные черновые модели (DFlash). Например, на целевых моделях серии Qwen3 (4B, 8B, 14B) средняя длина принятия увеличилась на 26,7%–30,9% по сравнению с Eagle3 и на 16,3%–18,4% по сравнению с DFlash.
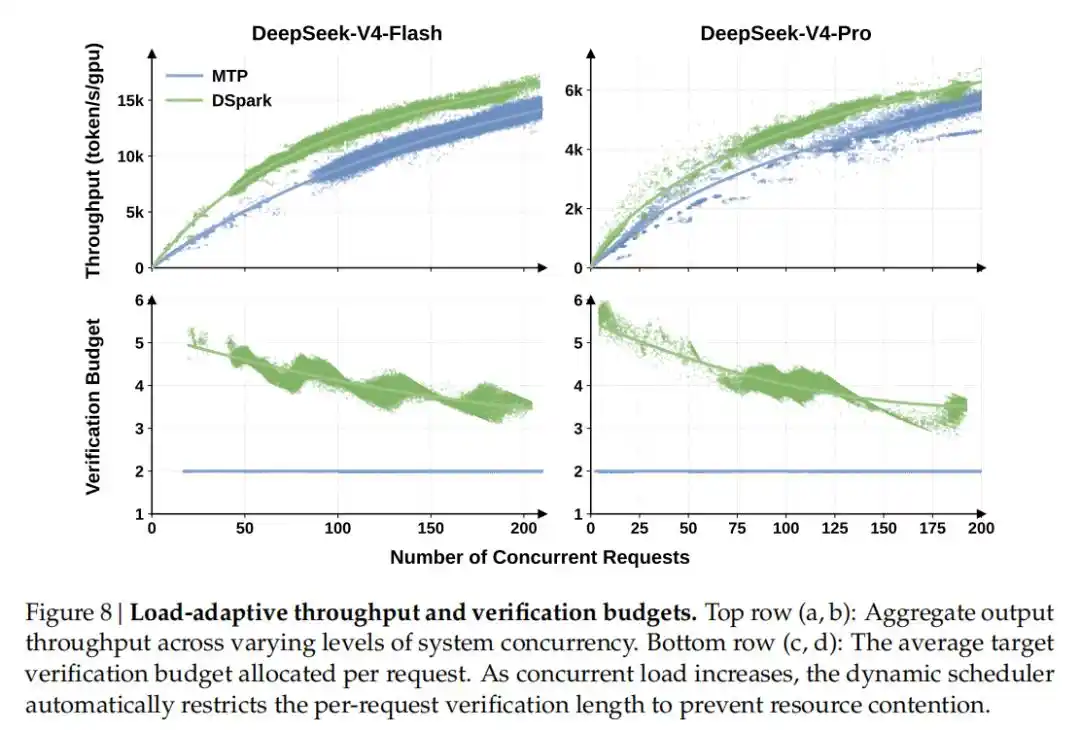
По сравнению с базовым однотокенным производством предыдущего поколения (MTP-1), при сохранении той же общей пропускной способности DSpark повысил скорость генерации для пользователей на 60%–85% (модель Flash) и 57%–78% (модель Pro).
Вместе с DSpark также был открыт исходный код DeepSpec — это полноценный стек кодовой базы для обучения и оценки черновых моделей спекулятивного декодирования. Это «открытая инфраструктура», на которой реализованы данное решение и другие передовые алгоритмы, включая инструменты подготовки данных, реализацию черновой модели, код обучения и скрипты оценки.
DeepSpec разбивает общий процесс на три этапа: подготовка данных, обучение и оценка. Эти этапы необходимо выполнять последовательно, выходные данные предыдущего этапа служат входными для последующего.
На этапе подготовки данных необходимо загрузить данные промптов, повторно сгенерировать ответы с помощью движка вывода для целевой модели и построить целевой кеш (target cache). Примечательно, что для конфигурации по умолчанию, например, Qwen/Qwen3-4B, объем целевого кеша может достигать около 38 ТБ, поэтому перед использованием необходимо тщательно оценить ресурсы хранения.
Этап обучения можно запустить с помощью bash scripts/train/train.sh. Этот скрипт вызовет train.py и запустит worker для каждого видимого GPU. Пользователи могут выбрать различные конфигурации алгоритмов и целевых моделей в каталоге config/, указав config_path. Проект также поддерживает изменение настроек обучения путем переопределения config_path, target_cache_dir, а также использования --opts для изменения отдельных полей конфигурации.
Что касается аппаратного обеспечения, конфигурация и скрипты DeepSpec по умолчанию ориентированы на среду с одним узлом и 8 GPU. Если количество GPU меньше, пользователям необходимо соответственно уменьшить количество видимых GPU в CUDA_VISIBLE_DEVICES.
Этап оценки запускается с помощью bash scripts/eval/eval.sh. Скрипт оценки будет использовать контрольную точку обученной черновой модели для измерения процента принятия на нескольких задачах бенчмарка спекулятивного декодирования. В проекте в настоящее время перечислены наборы данных для оценки: GSM8K, MATH500, AIME25, HumanEval, MBPP, LiveCodeBench, MT-Bench, Alpaca и Arena-Hard-v2, охватывающие различные типы задач, такие как математические рассуждения, генерация кода, диалоговые способности и комплексные вопросы и ответы.
Что касается алгоритмов, DeepSpec в настоящее время включает три черновые модели: DSpark, DFlash и Eagle3. Что касается семейств целевых моделей, проект в настоящее время поддерживает Qwen3 и Gemma.
Открытие исходного кода DeepSpec объединило практики спекулятивного декодирования, ранее разрозненные внутри различных исследовательских групп, в стандартизированный, воспроизводимый и расширяемый инструментарий. Для исследователей и инженеров, желающих ускорить вывод собственных больших моделей, это означает, что они могут напрямую обучать пользовательские черновые модели на зрелой платформе, пропуская множество повторяющихся работ по созданию базовой инфраструктуры.
Ссылки для справки:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
Эта статья из официального аккаунта WeChat «Машинный разум» (ID:almosthuman2014), авторы: Цзэнань, Ян Вэнь





