Without warning! After a year, Zuckerberg is finally back in the game!
Just now, the first product from Meta's Superintelligence Lab (MSL) has launched—
Muse Spark, codenamed Avocado, the legendary "Avocado."
It is a true "all-round hexagon warrior": native multimodal perception, tool use, visual chain-of-thought, multi-agent orchestration—all maxed out.

First, the most explosive number.
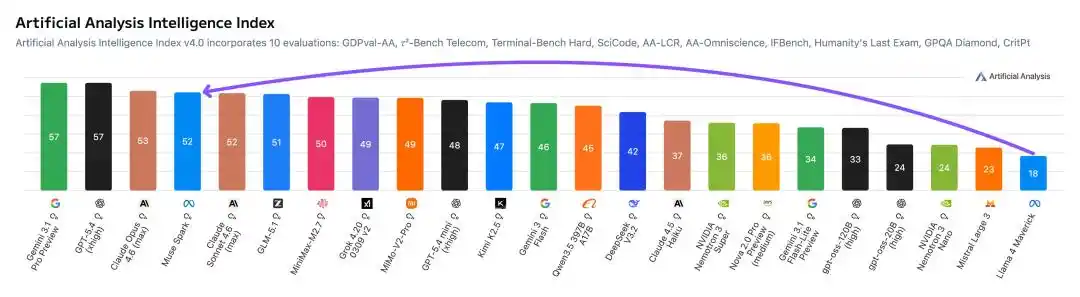
In Artificial Analysis's testing, Muse Spark scored a high of 52 points, second only to Gemini 3.1 Pro, GPT-5.4, and Opus 4.6.
In comparison, last year's Llama 4 Maverick only managed a mere 18 points.
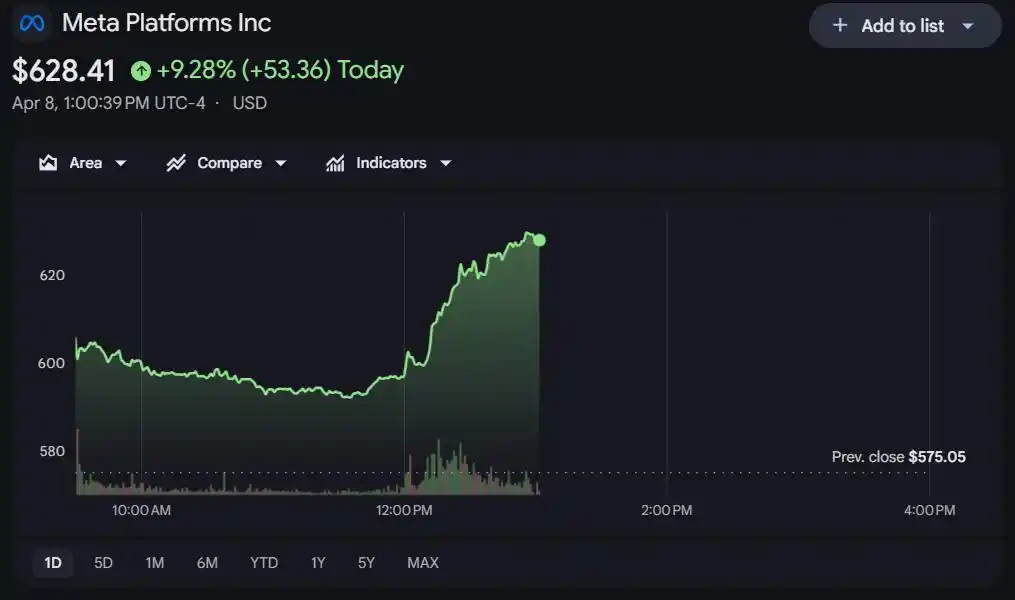
From 18 to 52, a leap in one go, Meta's stock surged nearly 10% intraday.
Meta's Chief AI Officer Alexandr Wang was so excited he posted nine tweets in a row on X.
Nine months ago, we rebuilt the entire AI tech stack from scratch: new infrastructure, new architecture, new data pipelines. Muse Spark is the result of that work.
Chinese researchers in the MSL team also flooded social media. These individuals left OpenAI and DeepMind last year to join a newly formed lab, betting on this very day.
MSL Chief Scientist Shengjia Zhao put it bluntly, "We rebuilt the entire tech stack to support Scaling. This is just the beginning."




It's worth mentioning that Muse Spark also launched a "Contemplating Mode,"对标 Gemini Deep Think and GPT Pro, where multiple agents think in parallel and collaborate on answers.
(Contemplating), multiple Agent parallel thinking, collaborative answering.

Just input "Help me plan a 7-day cultural and food itinerary for a family of 5 going to Florida, with three children aged 12, 9, and 7," and Muse Spark will dispatch three sub-agents simultaneously: one to plan the cultural food route, one to search for family activities, and one to coordinate logistics and accommodation.
Currently, the model is already live on meta.ai and the Meta AI App, with an API preview version open to some users.
Features are rolling out first in the US, with integration into Facebook, Instagram, and WhatsApp in the coming weeks.
Free to use, no limits, but closed source.
Next, the key points:
· Artificial Analysis score 52, Llama 4 Maverick only 18
· Native multimodal + visual chain-of-thought, second only to Gemini 3.1 Pro in the visual track
· "Contemplating Mode" multi-agent parallel thinking, HLE scored 58%
· Pre-training compute requirements slashed to 1/10 of Llama 4's
· 1000+ clinicians involved in training, health Q&A crushes the competition
· Thought compresses itself, Token consumption only 1/3 of Opus's
· Apollo Research found it can perceive itself being safety tested
Benchmarks catch up to the top tier, but coding still lags slightly
First, the hard data.
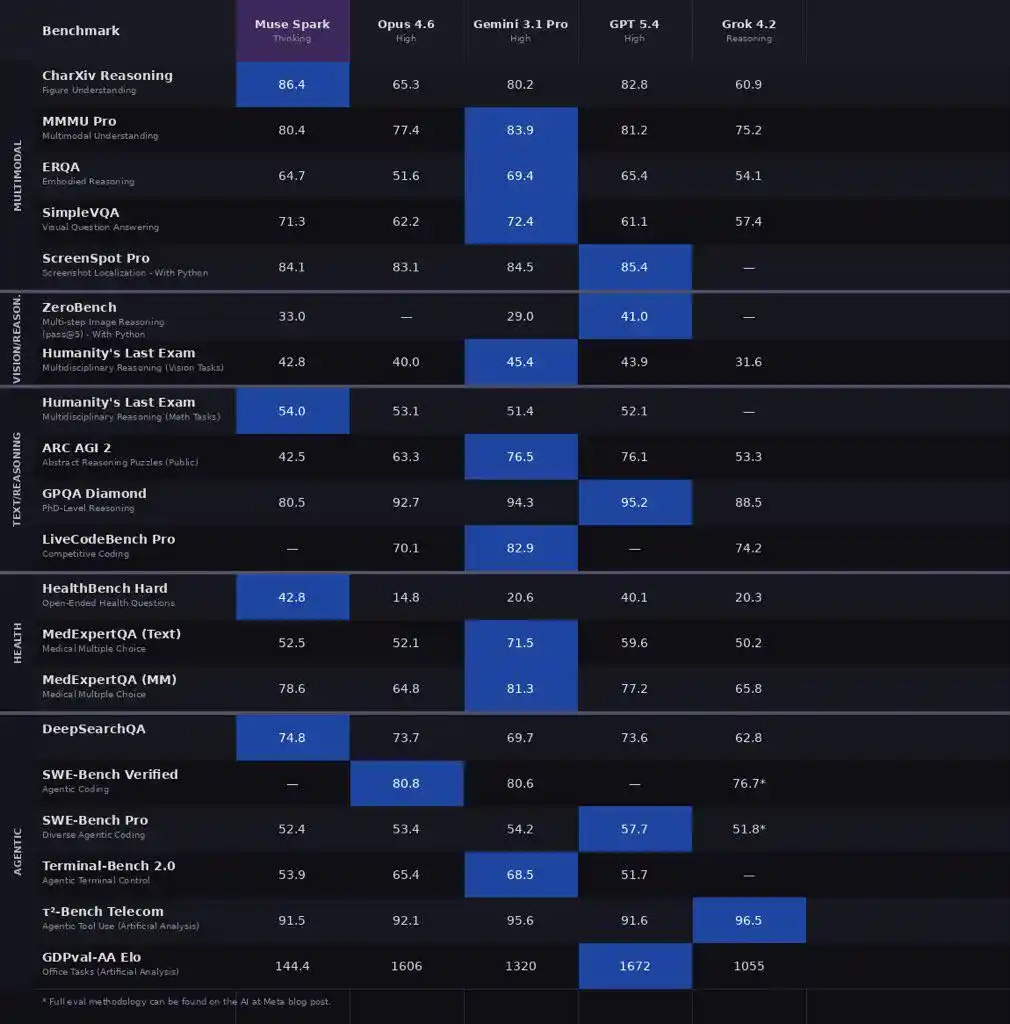
Meta compared Muse Spark (Thinking mode) against Opus 4.6, Gemini 3.1 Pro, GPT 5.4, and Grok 4.2 across more than 20 benchmarks covering multimodal, text reasoning, health, and agent dimensions.
Scores re-annotated by Reddit users
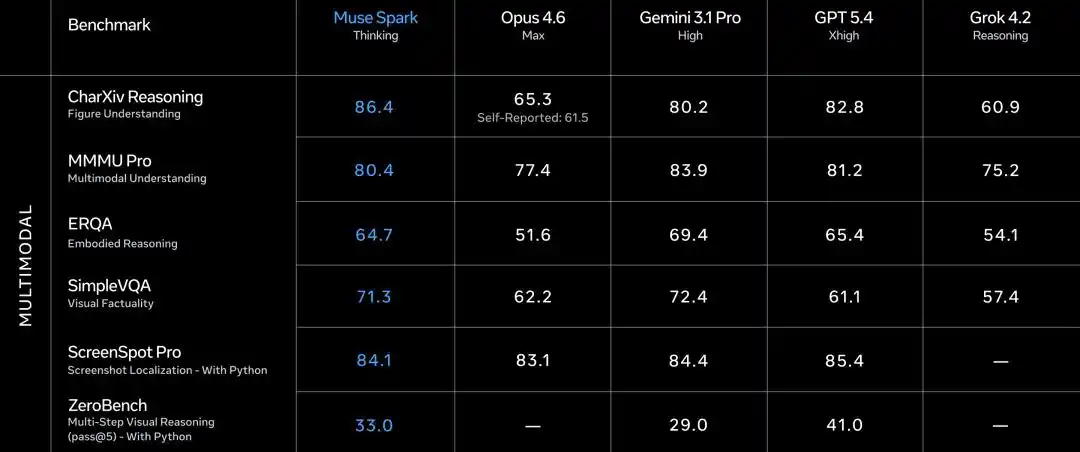
Multimodal is Muse Spark's brightest spot.
CharXiv understanding 86.4, surpassing GPT 5.4's 82.8 and Gemini 3.1 Pro's 80.2.
ScreenSpot Pro screenshot localization 84.1, slightly higher than Opus 4.6's 83.1.
ZeroBench multi-step vision 33.0, Gemini 3.1 Pro is 29.0.
On the text track, results are mixed.
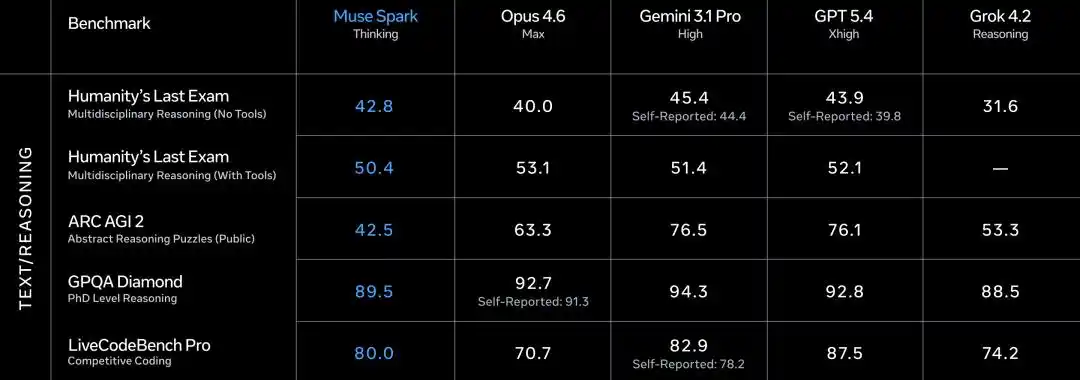
GPQA Diamond PhD-level难题 89.5, Opus 4.6 scored 92.7, Gemini 3.1 Pro is 94.3.
ARC AGI 2 abstract reasoning 42.5, left far behind by Opus 4.6's 63.3 and Gemini's 76.5.
LiveCodeBench Pro competition programming 80.0, Gemini 82.9, GPT 5.4 scored 87.5.
Meta itself admits that in code and long-duration agent tasks, Muse Spark still has a gap with the strongest models.
However, what shocked the entire internet was that Muse Spark can directly convert images into code, with stunning results!

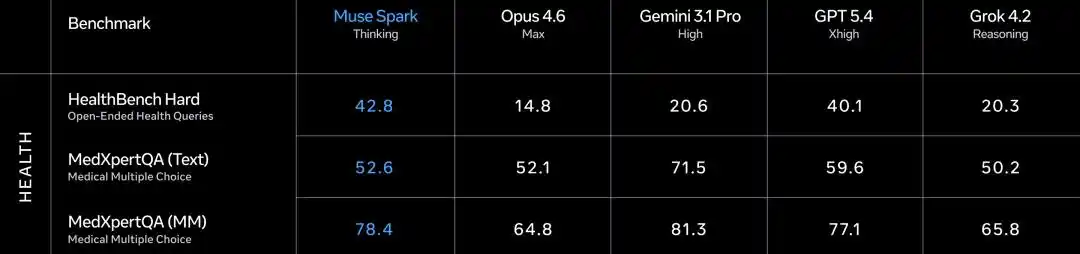
But in the medical health赛道, Muse Spark is fighting fiercely.
HealthBench Hard open-ended health Q&A 42.8, Gemini 3.1 Pro only 20.6, GPT 5.4 is 40.1.
MedXpertQA multimodal medical 78.4, also not far behind Gemini's 81.3 (Gemini slightly higher here), but far exceeding Opus 4.6's 64.8.
The data cleaning and筛选 involving over 1000 clinicians during training确实 brought tangible results.
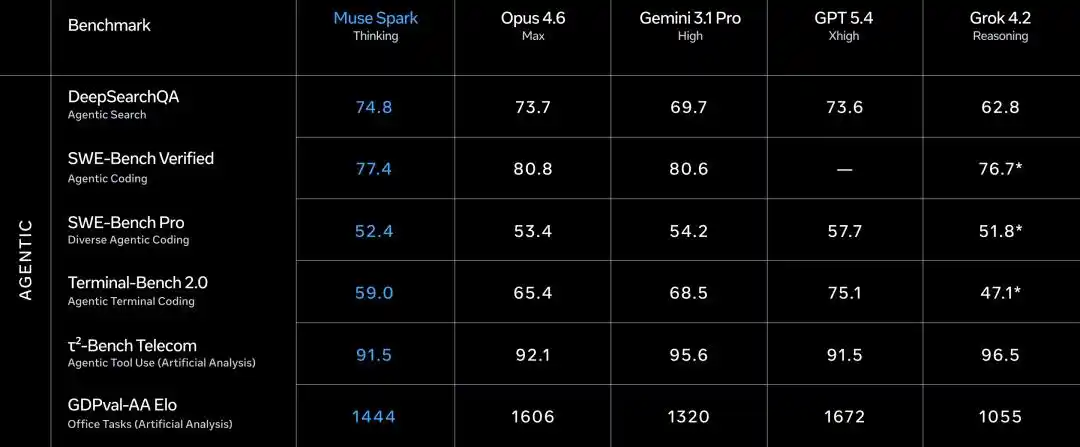
The agent赛道 is also noteworthy.
DeepSearchQA search agent scored 74.8, the highest among the five.
τ2-Bench tool use 91.5, tied with GPT 5.4.
GDPval-AA Elo office agent reached 1444, surpassing Gemini's 1320 but lower than Opus 4.6's 1606.
Significant gap in SWE-Bench, Verified 77.4 vs Opus 80.8 vs GPT 82.9 (reportedly 78.2), Pro 52.4 vs GPT 57.7.
In summary of the benchmarks: won in multimodal and health,持平 in reasoning, slightly behind in code and agent.
Alexandr Wang: Llama 4's mistakes won't be repeated, Avocado didn't cheat on scores
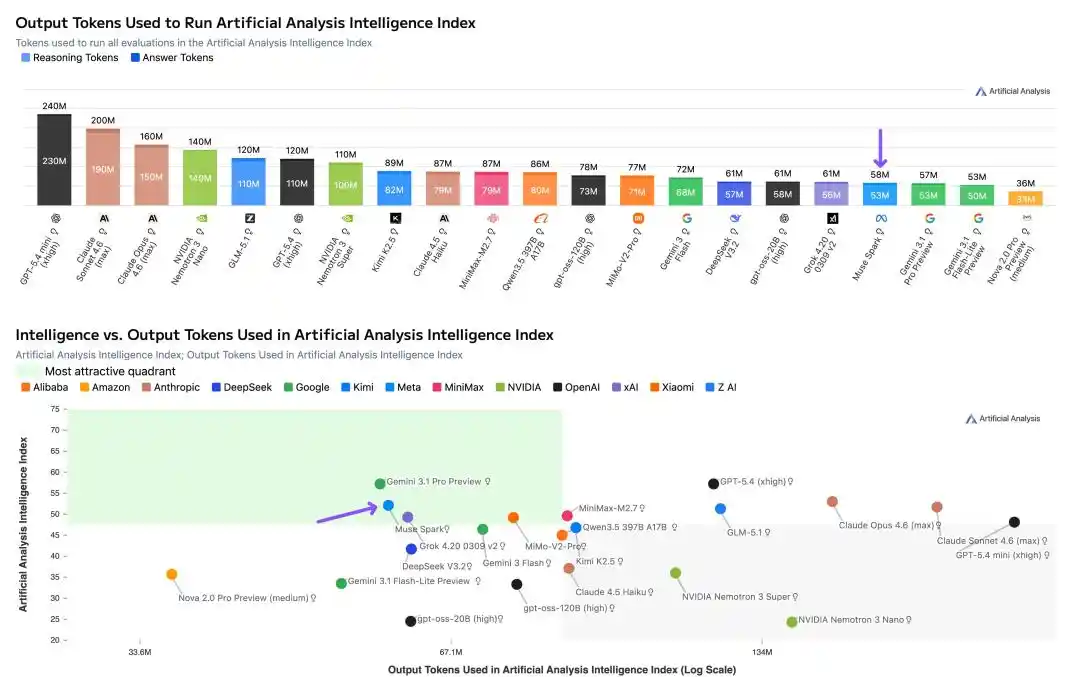
Independent testing by Artificial Analysis also revealed an important detail: Token efficiency.
Running the entire Intelligence Index test suite, Muse Spark used 58 million output Tokens, comparable to Gemini 3.1 Pro (57 million), but far lower than Opus 4.6 (157 million) and GPT-5.4 (120 million).
The same level of intelligence, consuming half to two-thirds fewer Tokens.
Furthermore, on FrontierMath with problems set by math experts, Muse Spark crushed Gemini 3.1 Pro on levels 1-3, but ranked last on level 4.

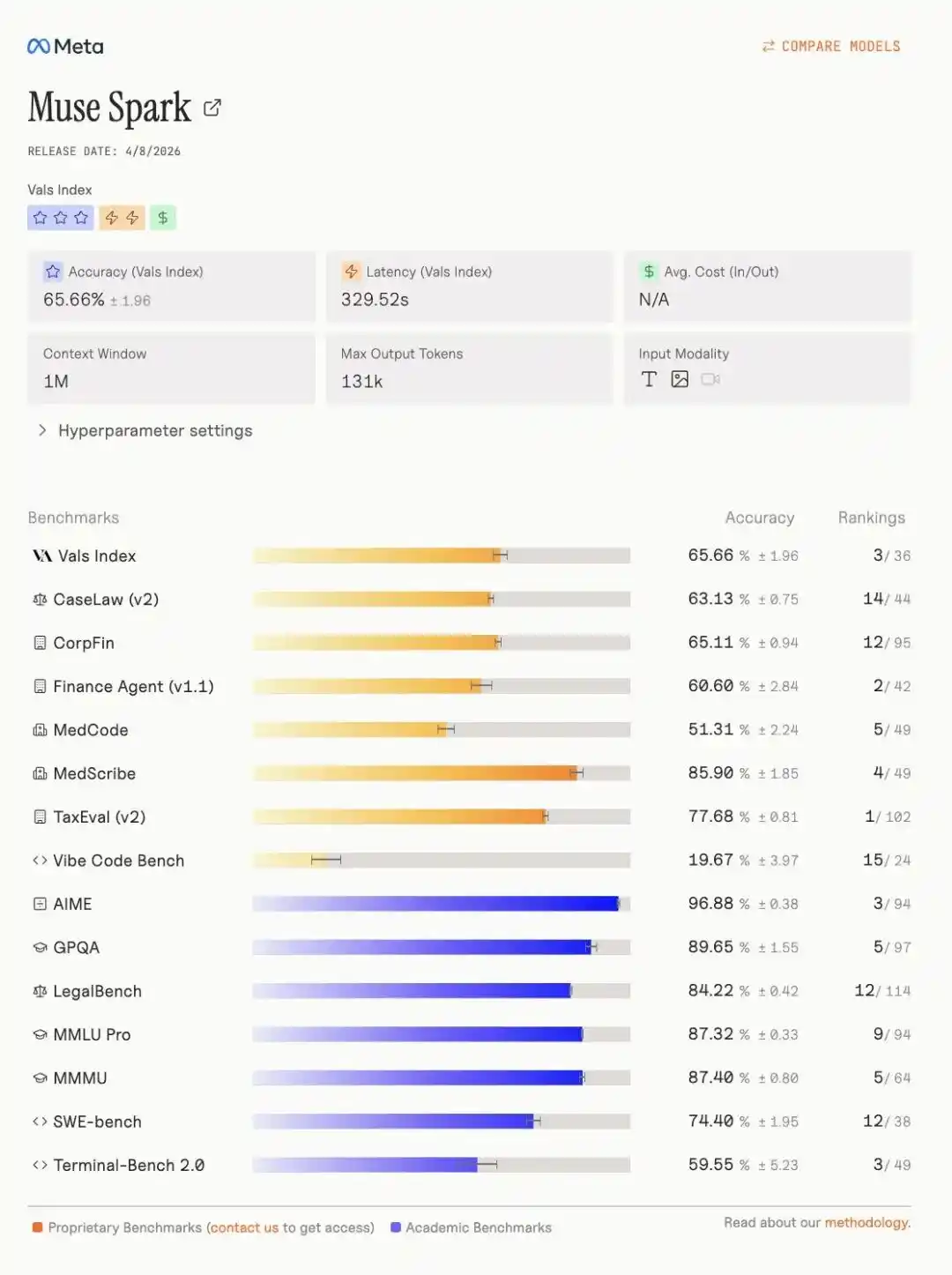
More notably, on the Vals index leaderboard, Muse Spark强势 seized third place, with specific indicators as follows.
One year after the release of Llama 4, Meta has returned to the AGI first tier.
Multi-agent parallel thinking, scores 58% on "Humanity's Last Exam"
The "Contemplating Mode" is Muse Spark's killer feature.
Traditional thinking mode is one agent thinking for a longer time; contemplating mode is multiple agents thinking simultaneously, then汇总 the answer.
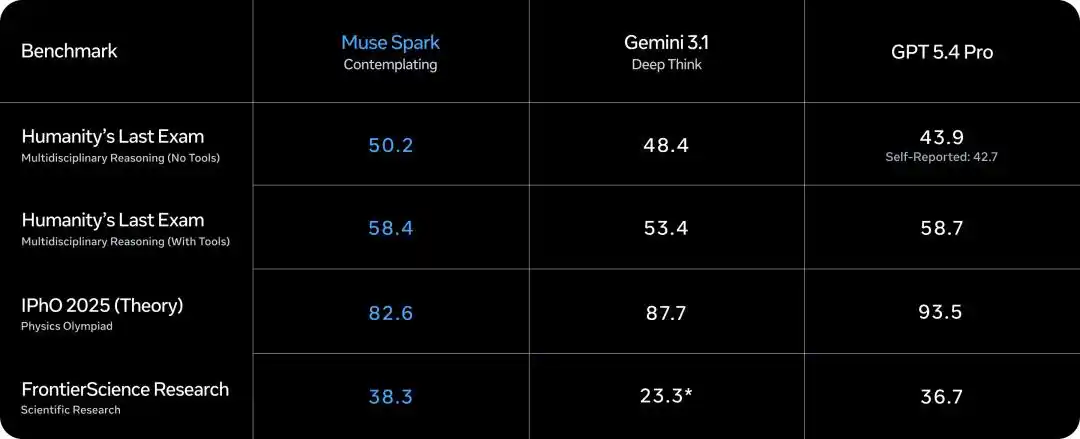
Humanity's Last Exam (no tools), Muse Spark contemplating mode scored 50.2, Gemini Deep Think 48.4, GPT 5.4 Pro 43.9.
Humanity's Last Exam (with tools), 58.4, Gemini 53.4, GPT 5.4 Pro 58.7, almost tied.
FrontierScience Research scientific frontier research 38.3, Gemini Deep Think only 23.3, GPT 5.4 Pro is 36.7.
However, on the IPhO 2025 theoretical physics Olympiad problem, Muse Spark contemplating mode 82.6, GPT 5.4 Pro scored 93.5, a significant gap.
Overall, the contemplating mode确实 allows Muse Spark to reach the threshold of the first tier on the most difficult comprehensive reasoning tasks.
Aiming for "Personal Superintelligence," take a photo to become a personal nutritionist
Meta's defined direction for Muse Spark is clear: personal superintelligence.
Translated into plain language, it's an AI assistant that understands you and the world around you.
In terms of multimodality, Muse Spark is designed from the ground up for cross-domain integration of visual information.
Official demos showed several scenarios.
Take a photo of a Sudoku puzzle, Muse Spark can turn it into an interactive game you can play on the web.
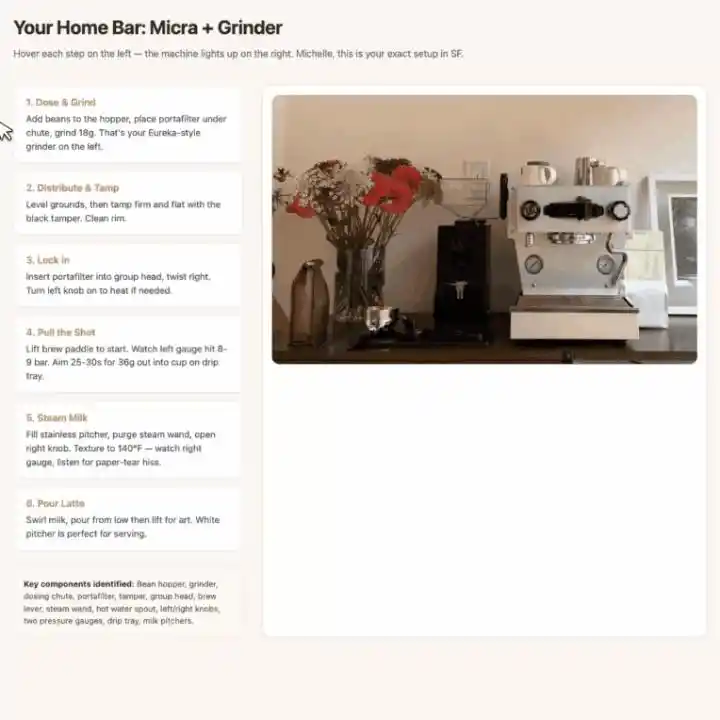
Photograph a coffee machine and grinder, it first labels all core components, then generates an interactive web-based latte tutorial.
When hovering over a step, the bounding box for the corresponding part in the photo highlights automatically, visual guidance and操作 steps correspond one-to-one.
Health scenarios have even more imagination space.
Photograph a table of food, tell it "I have high cholesterol, I'm a pescatarian," Muse Spark will mark recommended foods with a green dot, not recommended with a red dot.
Prompt control is very granular, directly specifying the UI interaction logic.
The health score number is displayed directly above the dot without hovering; hovering pops up detailed calorie, carb, protein, and fat data, and the pop-up is required to "always be on top,不能被其他点挡住".

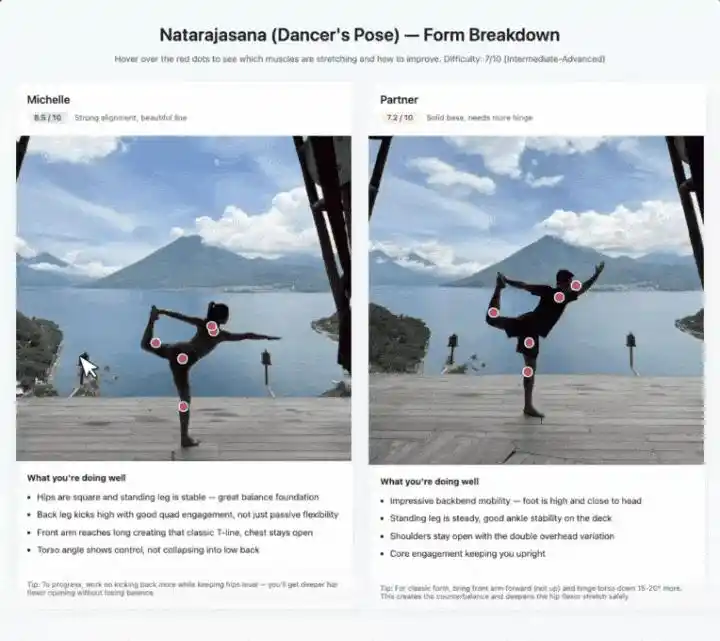
Photographing yoga poses follows the same idea.
It identifies which muscle groups each pose stretches, labels difficulty level, and gives posture correction suggestions on hover. Two people's images are拼在一起 side by side, scored from 1 to 10 respectively.
The underlying support for these demos is the combination of visual STEM Q&A, entity recognition, and object localization.
Individually, none are particularly novel, but串联 into scenarios, one can indeed see the product intent behind the term "personal superintelligence."
Another new feature worth mentioning separately is "Shopping Mode."
Wang said in a tweet that shopping mode can "recognize creators, brands, and style content you follow on Instagram, Facebook, and Threads, and turn it into personalized recommendations."

This is Meta's unique data advantage: 3 billion daily active users' social behavior data + AI shopping assistant, huge commercial imagination space.
Three Scaling curves, compute slashed by 90%, thoughts can self-compress
The highlight of the tech blog isn't the benchmarks, it's Scaling.
Meta explains Muse Spark's performance来源 by breaking it down into three axes: pre-training, reinforcement learning, and test-time computation. Each has corresponding scaling curves for support.
Pre-training: Same capability, compute cut to 1/10
Over the past nine months, Meta overhauled the pre-training tech stack: architecture, optimization algorithms, data strategy—all redone.
To measure the effect, Meta fitted Scaling Law on a series of small-scale versions, then compared the training FLOPs needed to reach the same performance level.
The conclusion is solid: for the same capability level, Muse Spark requires less than one-tenth the compute of Llama 4 Maverick.
This curve说明 one thing: Meta isn't just throwing more GPUs at the problem, but has fundamentally improved the output per unit of compute from the ground up.
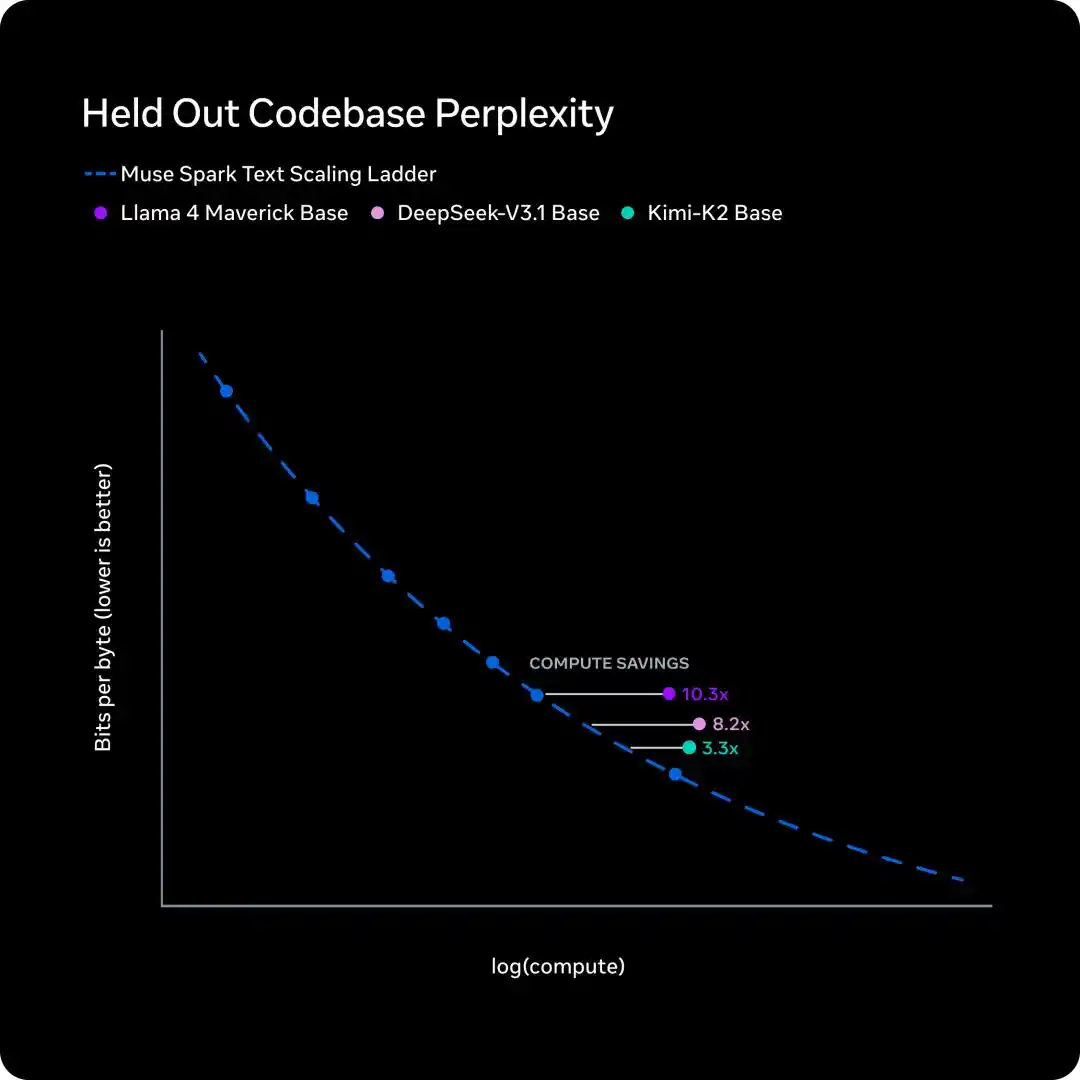
University of Washington's Yuchen Jin's evaluation on X was spot on: "I still believe infrastructure is the real moat for AI labs. Because you can train faster, researchers can experiment with more ideas faster."
Reinforcement Learning: Log-linear growth, generalizes to unseen problems
Large-scale RL is notoriously unstable, but Meta says the new tech stack's RL curves are exceptionally smooth.
The left graph shows performance on the training set. Both pass@1 and pass@16 (at least 1 correct in 16 attempts) show log-linear growth.
This indicates that RL improves reliability without sacrificing solution diversity; Muse Spark doesn't "go down one path blindly," it maintains the flexibility to explore different solutions.
The right graph is more important: accuracy on the held-out evaluation set.
The curve also rises steadily, showing that the progress from RL isn't rote memorization, but can generalize to completely new, unseen problems.

Test-time reasoning: Thought first expands, then compresses, then expands again
This is the most technical and interesting part of the entire article.
RL taught Muse Spark to "simulate in its mind first" before answering—this is test-time reasoning.
But the problem is, providing this service to billions of users, the Token cost is unsustainable.
Meta's solution is two-fold.
First, add "thinking time penalty" to RL training. You can think longer, but thinking too long will cost you points.
This constraint triggered an interesting "phase transition" phenomenon.
Performance on the AIME subset is like this: early in training, Muse Spark improves accuracy by thinking longer, the curve extends to the right.
Then, the length penalty triggers "thought compression." Muse Spark learns to solve the same problem using far fewer Tokens, the curve bends back left.
After compression is complete, it once again lengthens its problem-solving process to tackle harder problems.
The entire trajectory is a three-stage evolutionary path: first拐 right, then left, then right again.
The second step is solving the latency problem.
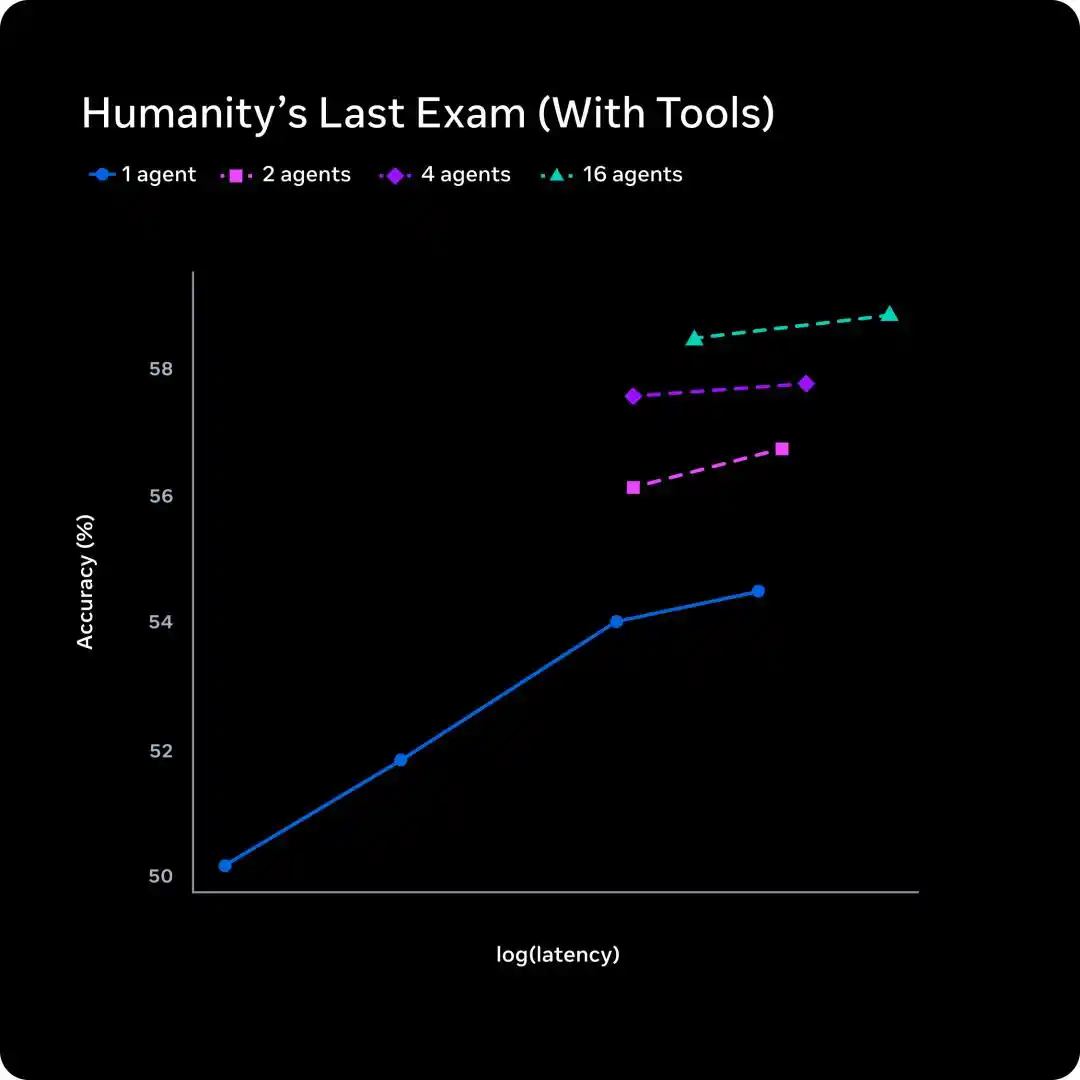
A single agent thinking longer increases latency linearly.
Meta's approach is to scale the number of parallel agents: 1, 2, 4, 16 agents thinking simultaneously.
From the graph, 16 agents at a similar latency level jump accuracy from about 54% to about 58%.
Traditional test-time scaling trades time for quality; multi-agent scaling trades parallelism for quality, with latency几乎不变.
Silicon Valley's "Most Expensive Chinese" team submits its first paper
Behind Muse Spark is Zuckerberg's complete overhaul of the Meta AI system last year.
In June 2025, Meta acquired 49% of Scale AI for $14.3 billion, bringing its founder Alexandr Wang onboard as Meta's first Chief AI Officer to form the Meta Superintelligence Lab (MSL).
Joining at the same time were former GitHub CEO Nat Friedman (co-leading product and applied research), SSI co-founder Daniel Gross, and 11 researchers poached from OpenAI, DeepMind, and Anthropic.

Now, the release of Muse Spark proves one thing: the nine-month重构 by Meta's Superintelligence Lab has yielded results.
Pre-training efficiency increased by an order of magnitude, RL scaling curves are smooth and predictable, multimodal and medical tracks have reached the first tier.
But the gaps in code and agent are there, the contemplating mode isn't fully open yet, and the open-source timeline is still a "hope".
More immediate pressure: Anthropic released the reportedly "too powerful to release" Mythos the same week, and OpenAI's codenamed Spud is also on the way.
$14.3 billion bought an entry ticket. The real exam is yet to come.
References:
https://ai.meta.com/blog/introducing-muse-spark-msl/
https://ai.meta.com/blog/scaling-how-we-build-test-advanced-ai/
https://ai.meta.com/static-resource/muse-spark-eval-methodology
https://x.com/alexandr_wang/status/2041909376508985381
This article is from the WeChat public account "新智元" (New Wisdom Element), author: 新智元
Trending Cryptos
Related Questions
QWhat is the name of Meta's new AI model and what is its code name?![]()
AThe new AI model is called Muse Spark, with the code name Avocado.
QHow did Muse Spark perform in the Artificial Analysis test compared to Llama 4 Maverick?![]()
AMuse Spark scored 52 points in the Artificial Analysis test, significantly higher than Llama 4 Maverick's score of 18.
QWhat is the 'Contemplating Mode' in Muse Spark and how does it work?![]()
AThe 'Contemplating Mode' is a feature where multiple AI agents think in parallel and collaborate to provide an answer, similar to Gemini's Deep Think and GPT's Pro mode.
QIn which specific areas did Muse Spark outperform its competitors like Gemini 3.1 Pro and GPT-5.4?![]()
AMuse Spark outperformed competitors in multimodal tasks (e.g., CharXiv, ScreenSpot Pro) and health-related benchmarks (e.g., HealthBench Hard), but lagged in coding and some agent tasks.
QWhat significant efficiency improvement did Meta achieve in pre-training for Muse Spark compared to Llama 4?![]()
AMeta achieved a tenfold improvement in pre-training efficiency, requiring less than one-tenth of the compute FLOPs needed for Llama 4 Maverick to achieve the same capability level.
Related Reads





Trading
Hot Articles
Hot Tokens Learning Week 8: ADA's Ouroboros Leios Mainnet Expected to Launch in 2026
ADA's Ouroboros Leios mainnet is expected to launch in 2026, and the hard fork to Protocol Version 11 is planned for Q1 2026.
40.9k Total ViewsPublished 2026.02.10Updated 2026.02.12

Hot Tokens Learning Week 14: Glamsterdam Set to Be Ethereum's Most Closely Watched Upgrade in 2026
Ordinals/Runes continue to drive block fee revenue and developer activity, and are seen as the starting point for Bitcoin's "native asset issuance".
27.9k Total ViewsPublished 2026.04.29Updated 2026.04.29

Hot Tokens Learning Week 19: RWA and Infrastructure Stay in Focus; Pump Platform's Daily Trading Volume Returns to Recent Highs
Recently, Robinhood Chain adopted Chainlink as its official oracle and CCIP provider.
32.3k Total ViewsPublished 2026.07.22Updated 2026.07.24

