Prompts are dead, long live loops.
This is the new focus for AI trends recently hyped online and highlighted by Jensen Huang:
Nobody writes prompts anymore. The new job is to write and handle loops.
What is a loop? Translated literally, it means 'cycle,' but in AI circles, it means:
You no longer manually give instructions to the AI. Instead, you design a system where the system gives instructions on your behalf, checks the results, and retries if they are unsatisfactory until the job is done.
Huh? Isn't this what Agents do nowadays? Why coin a new term?
Let's set this question aside for a moment. Looking around, I found this 'loop' concept is indeed hot—
Besides Jensen Huang, big names like Peter Thiel, 'Claude Code father' Boris Cherny, and Andrew Ng are all talking about and strongly promoting loops.
(Peter) Stop writing prompts for programming Agents. Design loops instead, letting the loops prompt the Agent for you.
(Boris) I don't write prompts for Claude anymore. I have a bunch of loops running; they are the ones giving Claude instructions and deciding what to do next. My job is to write loops.
Now that 'writing loops' has replaced 'writing prompts' as the new daily routine for these big names, loops have clearly moved beyond just being 'another new concept.'
The remaining questions are only:
What exactly is a loop? And why has it suddenly become so popular?
What exactly is a loop?
To understand this new thing called a loop, we must first review the old paradigm.
The standard practice for AI programming in the past two years was like this:
You write a prompt, the AI spits out some code. If you're not satisfied, you write another prompt, the AI modifies it, you review it again... Back and forth, with you supervising the entire process.
Karpathy indirectly criticized this 'human as the bottleneck' issue and advised:
You can't sit there waiting to write a prompt for every step. You have to remove yourself from the loop.
Removing the human from the loop is precisely what loops aim to solve.
The core logic is simply one sentence:
You define a goal. The AI runs by itself, checks its own work upon completion, and if it fails, it takes the error report and starts another round. It stops only when it passes or hits the budget limit.
At this point, the human's role shifts from being a 'messenger' to a 'rule designer.'
So, back to the initial question: How is this different from an Agent?
Obviously, an Agent is the worker, while a loop is the management mechanism that allows this worker to keep working without you watching over it.
An Agent without a loop moves only when you give a command, essentially remaining an obedient tool.
An Agent equipped with a loop truly becomes a self-sustaining system.

The principle sounds simple, but it might still seem a bit abstract.
Don't worry. I looked into the current practical implementations of loops and found they are already embedded in systems we are familiar with.
Regarding product implementation, a 'duopoly' situation has emerged around loops.
One is Claude Code, which everyone uses daily. It has built a loop suite around three commands:
/loop handles scheduled cycles, /goal handles goal-driven tasks (running until acceptance criteria are met), and /schedule handles cloud-based scheduled tasks (they can run even with your laptop closed).
The most ingenious design is /goal, which embodies the most crucial principle of loops—you can't grade your own paper.
Claude Code has directly built this principle into its product architecture:
A large model writes the code, and an independent smaller model, Haiku, does the validation. The two models have separate responsibilities.
This way, the Agent doesn't give itself an easy high score, ensuring the validation has real constraint power.

The other is OpenAI Codex.
Codex's approach is closer to a combination of 'automated pipeline + goal-driven + multiple sub-agents.' In the practical experience of some developers, you can see up to 8 agents running simultaneously in their respective cloud sandboxes, each doing its own job and finally aggregating the results.
Interestingly, although the two companies' implementation paths are different, the final forms are highly similar—
Both break down complex tasks, assign them to multiple agents to run in parallel, and then aggregate the results.
In public evaluations and community reputation, their performance is already very close.
This also illustrates a point: the models themselves can't differentiate much anymore; the real gap lies in the upper-layer loop orchestration.
At this point, just look at how 'Claude Code father' Boris Cherny works every day, and it all becomes clear.
He said he uninstalled his IDE last November, didn't open it for a month, and simply deleted it.
Now he has hundreds of small agents running simultaneously. Some scan GitHub issues, some read user feedback on Slack, some monitor CI failures. Each agent works in its isolated code branch, with one writing code and another running tests for validation.
Only the ones that can't handle the task end up in his inbox, waiting for his judgment.
He revealed that since Opus 4.5, all his code has been written by Claude Code, and nowadays most of his code is completed directly on his phone.
Next is the loop, where Agents prompt each other without requiring human review in between.
See, the ultimate form of the loop is already quite clear:
Humans don't write code or prompts; they only write rules and judgments. The rest is all handed over to loops.
How to get looped
So, how do we get looped?
A blogger named Codez on X has already summarized everything for everyone. He posted a 14-step practical roadmap; I'll pick some of the key points here.

Step 1: Don't rush to build; do the '4-condition test' first.
Not every task is suitable for a loop; building blindly will just lose money.
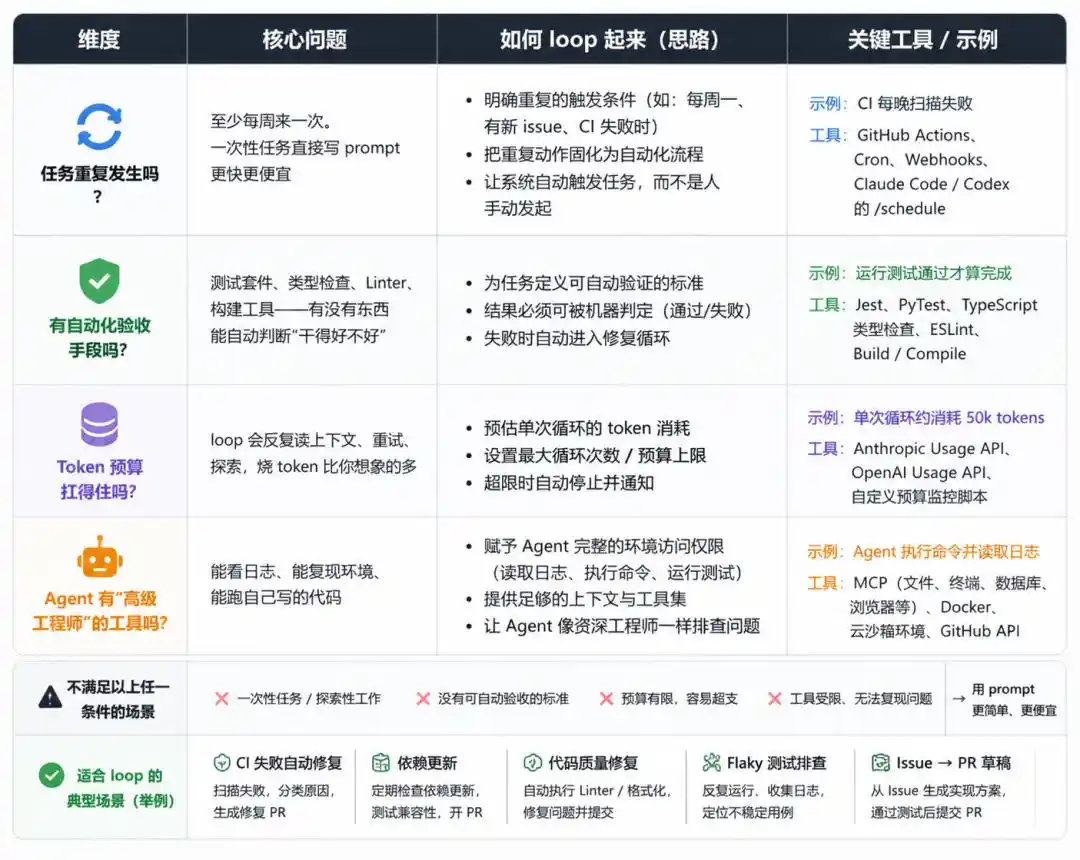
Before you start, answer four questions:
Does the task occur repeatedly?
Is there an automated validation method?
Can the token budget handle it?
Does the Agent have the tools of a 'senior engineer'?
△
Only pass all four conditions is it worth building a loop.
Step 2: Start with the minimum viable loop.
Don't get fancy the first time; just build a four-piece set:
A trigger (Automation): Can be scheduled runs or event-triggered runs. Use /loop in Claude Code and the Automations panel in Codex.
A skill (Skill): Write the project context into STATE.md so that each run doesn't need to re-explain everything.
A state file (State File): Use Markdown to record 'where we are, what succeeded, what failed' so the next run can continue.
A gate (Gate): Tests, type checks, builds—anything that can automatically block bad results.
And the order is crucial: first, run it manually once successfully → write it as a Skill → wrap it into a loop → only then set up scheduling.
Skipping steps is the main reason loops die in production.
Step 3: Be the one who 'separates the papers,' not the one who 'grades them.'
The most important principle in the entire loop design has been mentioned before—the code writer and the code validator must be separate.
Concretely, this means:
Use one model (or sub-agent) responsible for writing and another independent model (or sub-agent) responsible for validation. The validator must not see the reasoning process of the writer.
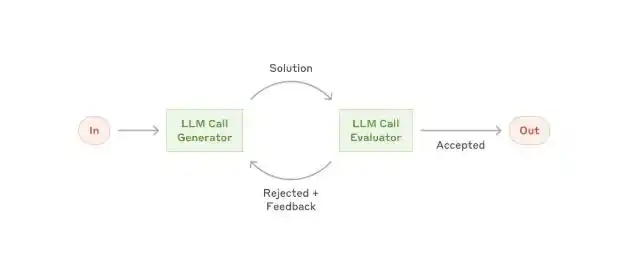
Why is this important? Because when a model grades its own code, it tends to be 'too lenient.'
All code that 'looks good' can probably be picked apart by an independent validator.
Step 4: Don't step into pits others have already stepped into.
Here are a few pitfalls to avoid.
1. No hard stop condition. A loop runs until you notice the bill or get rate-limited, so you need to set token limits, iteration limits, and time limits.
2. State not persisted. An Agent's memory is short-term; what it learns today is forgotten tomorrow, so you need to write it into a state file (STATE.md) and read it for each run.
3. Letting loops handle 'judgment-required' tasks. Don't let loops touch tasks like architectural rewrites, authorization code, payment logic, or product direction decisions. Loops are suitable for tasks with 'clear right/wrong, machine-verifiable, and not dependent on human judgment,' such as Lint auto-fixes, dependency update PRs, CI failure categorization, and Flaky test reproduction.
4. Not reading diffs. Loops merge code faster and faster, while your understanding of the codebase becomes shallower. This is called 'comprehensibility debt'—the real cost isn't the token bill but the day you have to debug a system no one on the team has read. So it's recommended that you read diffs, even if just a glance.
Step 5: There's only one metric that matters.
Ignore how many tokens were burned, how many PRs were opened, or how many tasks were run.
The only useful metric is: What is the average cost per accepted change?
If your 'acceptance rate' is below 50%, it means you're doing the review work that the loop was supposed to save you from, i.e., the loop is losing money.
From prompts to loops: Four paradigm shifts
Now that we understand the principles and methods, the final question remains:
Why are loops so popular now?
Although strictly speaking, the concept of Loop Engineering is less than three weeks old.
It didn't appear out of thin air. Looking back at the timeline reveals a clear evolutionary path.
This path has already been summarized by the big names; we can just copy their homework:
From Prompt → Context → Harness → Loop, a total of four shifts.
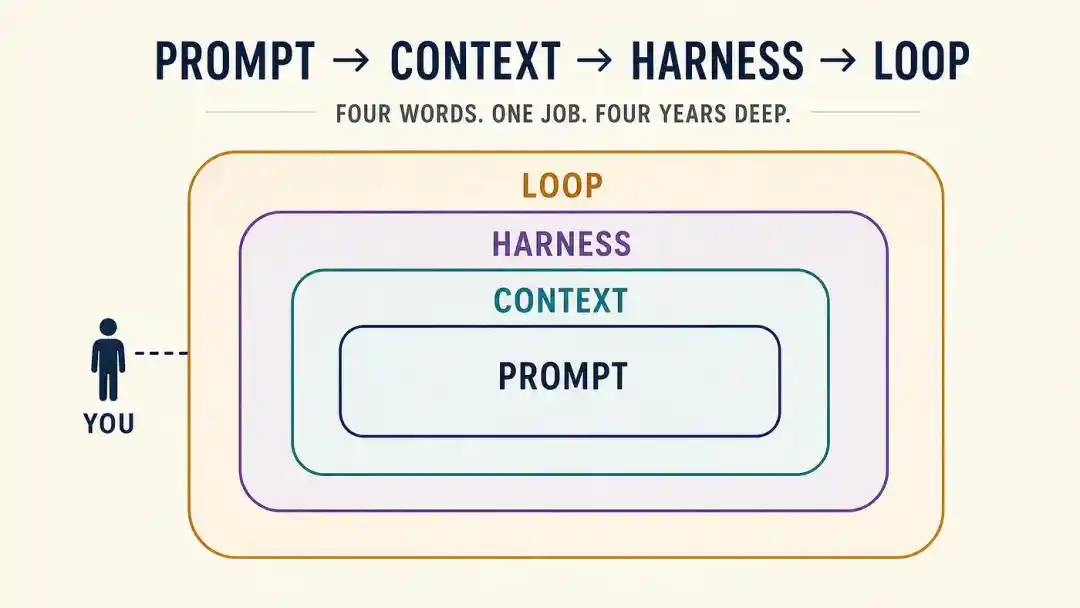
In short, from 2023~2024, it was the era of Prompt Engineering.
Back then, everyone was figuring out one thing: How to write prompts to make AI work properly.
Good prompts vs. bad prompts produced vastly different results. So at that time, 'knowing how to write prompts' basically equated to 'knowing how to use AI.'
At this stage, the relationship between humans and AI remained at the most superficial level—you say one thing, it replies, with every instruction requiring manual input.
But as model capabilities increased, context windows lengthened, and RAG and codebase integration became common, the focus shifted for the first time.
Around 2024 to early 2025, the industry began emphasizing the importance of 'Context Engineering,' shifting the focus from 'how to ask' to 'what to show the AI.'
In other words, AI no longer relied solely on a single prompt but on the entire background you provided.
At this stage, information organization skills became more important than prompt writing, and the granularity of control moved from 'a single sentence' to 'a bundle of information.'
By 2025~2026, as Agent systems gradually entered real development workflows, the problem expanded further.
It was realized that just providing information and context wasn't enough. The AI needed to connect to tools, run code, call APIs, and go through permission approvals.
Therefore, you had to build a runtime environment where it could work, be constrained, and access real-world resources.
'Harness Engineering' was born for this purpose.
And building upon Harness, 'Loop Engineering' became the latest evolutionary direction.
If Harness solved the problem of 'whether AI can work in a real environment,' then Loop solves the problem of 'whether AI can work continuously in this environment, advance tasks on its own, without needing step-by-step human supervision.'
Its core is no longer single-execution capability but the operational capability of a closed-loop system.
So, from Prompt to Context, to Harness, to Loop, it may look like a succession of concepts, but essentially it's a continuous migration path:
Human control over AI has been moving up in granularity, from 'writing a sentence' to 'providing information,' to 'building a system,' and finally to 'designing loops.'
A process of gradually liberating human hands.

In fact, although this loop thing just got hot in the industry, academia already had similar concepts much earlier.
And much of the important work is related to someone familiar to us today: Shunyu Yao (from Tencent).
One of his most representative works in the direction of large model Agents is the ReAct framework (Reason+Act) from 2022.
This work received Oral level at ICLR 2023 and later garnered tens of thousands of citations.
ReAct did a very crucial thing: bounding 'reasoning' and 'action' into a cyclical process.
A large model no longer outputs an answer once; instead, it first engages in interpretable thinking, then calls tools to perform actions, observes environmental feedback after execution, and then enters the next round of reasoning. Abstractly, it's:
Think → Act → Observe → Think again → Act again...
This structure is essentially the earliest systematically expressed prototype of an 'agent loop.'
After ReAct, this route continued to expand. For example, Reflexion introduced a feedback mechanism for 'learning from mistakes,' Tree of Thoughts expanded into multi-path search-style reasoning, and a series of subsequent tool-use agent works gradually perfected the complete chain of 'planning + execution + feedback.'
These academic achievements gradually pushed forward, eventually converging in the engineering world into what we call 'loop systems' today.
So, from an academic perspective, loops are not someone's invention; they are a gradually converging technical path.
It's just that on this path, a familiar Chinese researcher happens to stand at a key node.
Finally, one can't help but marvel at how fast AI development has been, from prompts to loops.
The consequence of being so fast is that some are excited, while others find it hard to hide their concerns.
The namesake of Loop Engineering, Google Engineering Director Addy Osmani, is one of the latter.
He made it very clear in his long article 'Loop Engineering':
It's still very early. I'm cautious. You have to be very careful with token costs.

Karpathy's words are even more thought-provoking. At the Sequoia Capital AI Ascent 2026 conference, he quoted a phrase that he himself kept pondering:
You can outsource your thinking, but you cannot outsource your understanding.
To translate: AI can think of solutions for you, but you yourself must truly understand the problem.
This is probably the most sobering voice amid the entire loop frenzy.
References:
[1]https://x.com/i/trending/2068190968809980300
[2]https://x.com/addyosmani/status/2064127981161959567
This article is from the WeChat public account 'QbitAI', author: Yishui





