Recently, Adam Brown, a core contributor to Gemini and head of the Blueshift team at DeepMind, delivered a lengthy speech titled 'Training Sand to Think: Artificial General Intelligence and the Future of Physics' at the Perimeter Institute for Theoretical Physics, attracting widespread attention. In his talk, he described witnessing AI progress from a 'kindergarten level' all the way to a doctoral level, and extrapolated: if this trend continues, what will become of physics?
Speech Title: Training Sand to Think: Artificial General Intelligence & Future of Physics
Speech URL: https://www.youtube.com/watch?v=Mw60FH5iflI&t=3s
The speech was also highly praised by Nobel laureate in Physics and Turing Award winner Geoffrey Hinton, who called it 'amazingly good.'
Before delving into this amazing speech, it's necessary to introduce the speaker, Adam Brown.

Brown's career is a textbook case of 'how a theoretical physicist's fate was changed by AI.' He studied a joint degree in Physics and Philosophy at Oxford, earned his Ph.D. from Columbia University, and subsequently taught in the physics departments at Princeton and Stanford. At Stanford, he taught Einstein's general relativity, researching topics ranging from the Big Bang, cosmic inflation, multiverses, black holes, and quantum computing, to ideas that sound like science fiction plots such as 'space elevators,' 'bubbles of nothing,' and the ultimate fate of the universe, while also maintaining a long-standing interest in the deep connections between physics and computer science.
In 2018, Brown joined Google. Today, he leads a team called Blueshift within DeepMind, focusing on enhancing AI's scientific and reasoning capabilities, and is also one of the core contributors to the Gemini large language model.
At the beginning of his speech, he mentioned that he had written about forty theoretical physics papers in his career but had stopped writing them by hand in recent years. The reason wasn't a lack of ideas, but that he felt writing papers one by one by hand was more like a 'guilty pleasure' because what he should really be doing now is participating in building a machine that can generate knowledge 'on an industrial scale.'
This opening statement set the tone for the entire talk: someone at the center of the 'AI+Science' technological storm trying to describe its true shape to his peers.
With the aid of AI, we have also summarized the key points of Brown's remarkable speech.
From Sand to Thinking Machines
Brown summarized the unique position of human civilization in one sentence: We have learned to purify sand into silicon, make chips from silicon, assemble chips into neural networks, and now we have learned to train these neural networks to think.
He particularly emphasized that this time it's different from any previous 'computational tool.' From the abacus to pocket calculators, humans have long had various tools to assist scientific research, but those were single-purpose tools, only capable of completing a single step in a process, leaving the rest for humans to do.
Large language models (LLMs) are different; they possess the potential to complete the entire workflow of a theoretical physicist, which is precisely the meaning of the term 'general intelligence.' Brown believes that LLMs are likely the fundamental substrate humans will use to build artificial general intelligence.
He reminded the audience that while they may have used chatbots like ChatGPT, Gemini, or Claude, they might not have noticed a quiet fact: these systems quietly passed the Turing test years ago, and almost no one specifically celebrated it.
Neural Networks are 'Grown,' Not 'Programmed'
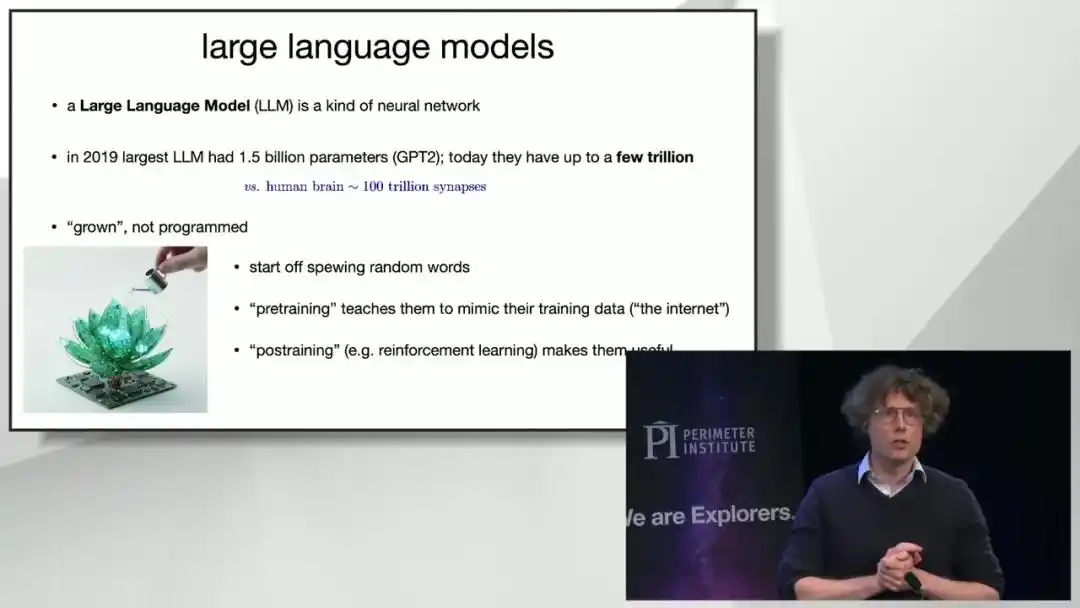
To understand why large models are fundamentally different from traditional computer programs, Brown offered a core metaphor: LLMs are not programmed; they are grown. That is, they are cultivated rather than coded.
The specific process consists of two stages.
The first stage is called 'pre-training.' Engineers start with a set of randomly connected, nearly nonsensical artificial neurons and have it continuously try to predict the 'next word' in a piece of text. If it guesses correctly, the corresponding neural pathways are strengthened; if wrong, they are weakened. This process is extremely long: after seeing a million words, the model's output is still mostly gibberish; after reading tens of millions to billions of words, it can produce grammatically correct but somewhat stiff sentences; only after reading the entire internet (tens of trillions of words) can it engage in fluent, coherent conversations on almost any topic.
The second stage is called 'post-training,' which Brown describes as sending the model to 'finishing school.' A model fresh out of pre-training only mechanically predicts the next word, speaking rudely and uncooperatively. Post-training's task is to teach it to be polite and willing to cooperate with users, not just play a word completion game. Today, the parameter count of mainstream large models has jumped from billions a decade ago to several trillions, still far below the scale of the human brain's roughly one hundred trillion synaptic connections, but this scale is already sufficient for miracles to happen.
Physicists' Unexpected Role: Scaling Law Ignited This Revolution
Brown specifically mentioned that physicists played an unexpected role at the beginning of this AI revolution: they brought the mindset of the 'Scaling Law.'
Physicists are inherently obsessed with finding simple power-law relationships: if you double Alice's height, her surface area becomes four times larger, and her weight becomes eight times larger—this is the simplest dimensional analysis. Kleiber's discovery nearly a century ago of a power-law relationship between animal metabolic rate and body weight is a more subtle example—it took physicists many years later to explain its underlying principle using the fractal dimension of the vascular system.
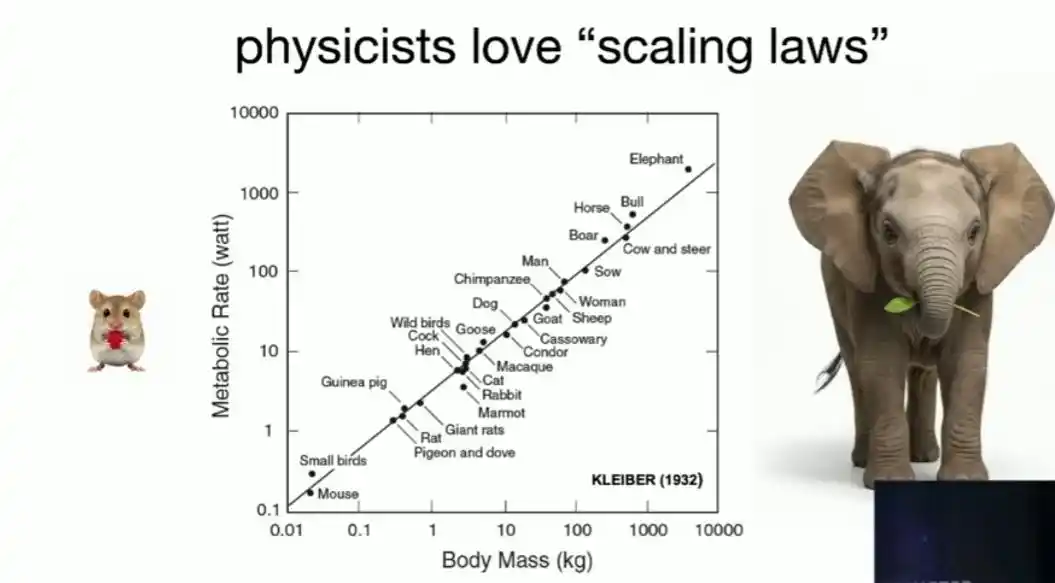
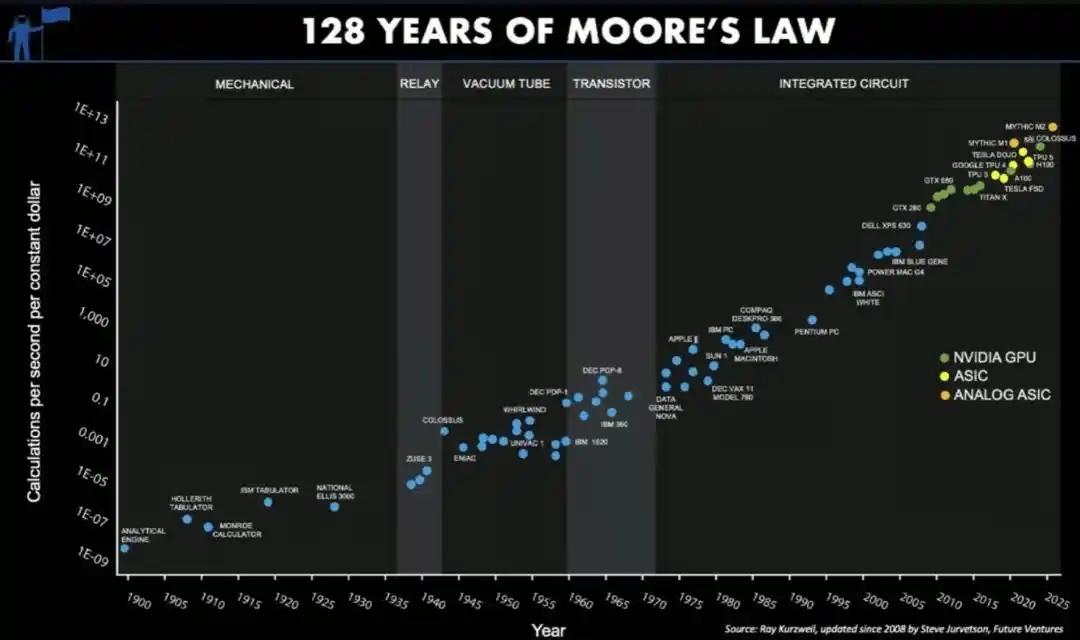
Not to mention the famous Moore's Law:
In 2020, several researchers with physics backgrounds applied this mindset to neural networks and discovered that as long as the computational power used for training, data volume, and model scale were proportionally increased, the model's performance on the 'predict the next word' task would improve steadily along a straight line on a log-log coordinate system.
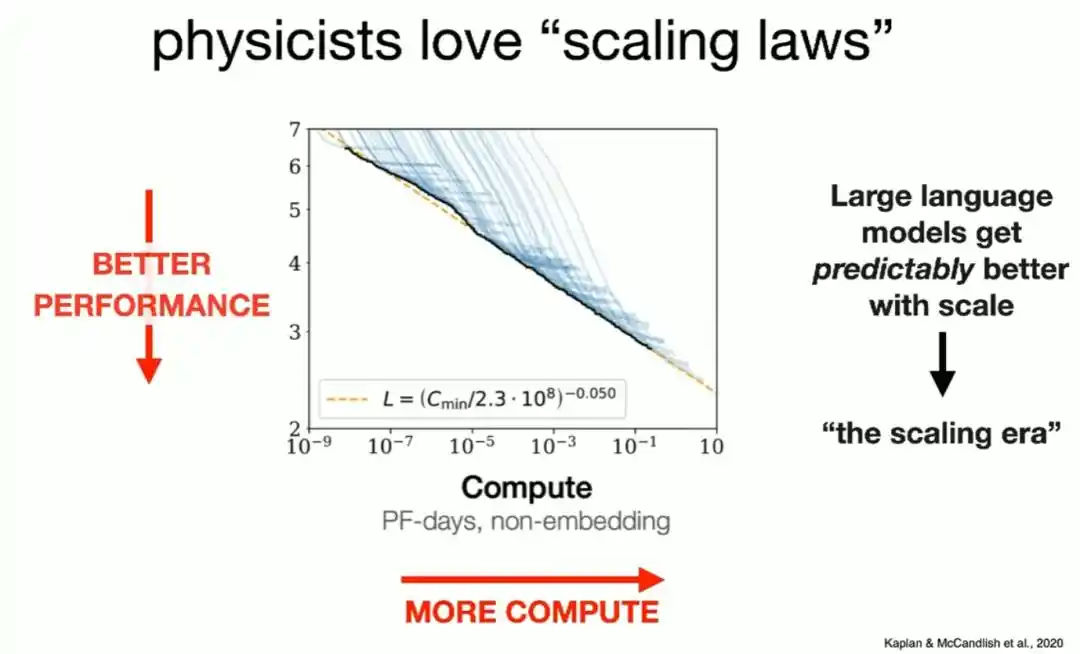
This curve was later extended by a full eight orders of magnitude and still held.
Brown joked that this chart was 'simple enough for venture capitalists to understand,' and it directly told capital markets: invest money (i.e., compute) and get a stronger model in return.
This simple curve was precisely the starting point of the Scaling era over the past six years.
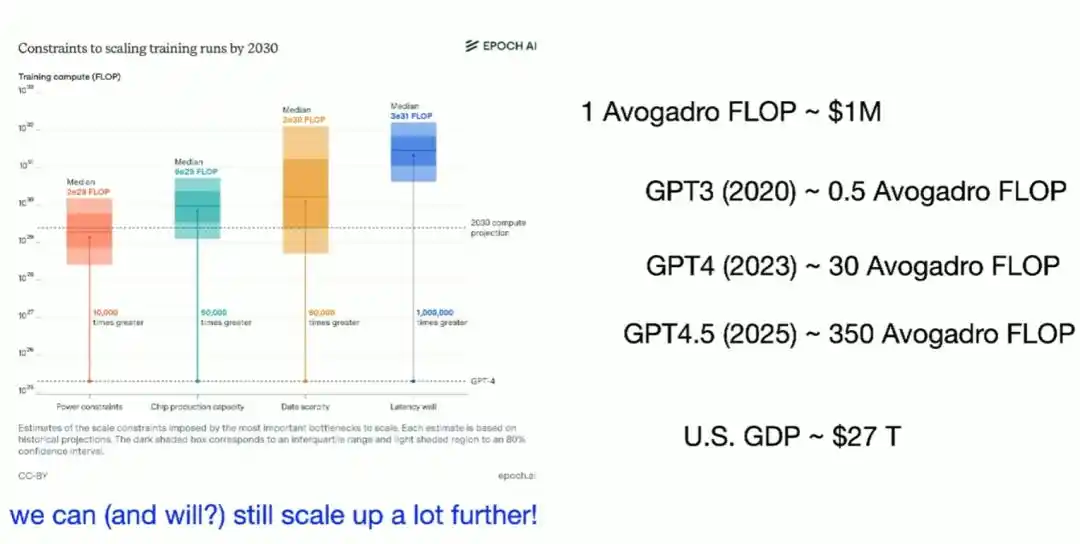
However, Brown also pointed out that just scaling compute is only part of the story. Over the past decade, the compute consumed by cutting-edge AI training has grown about fourfold annually, and the funds invested in training have grown about 2.7 times per year.
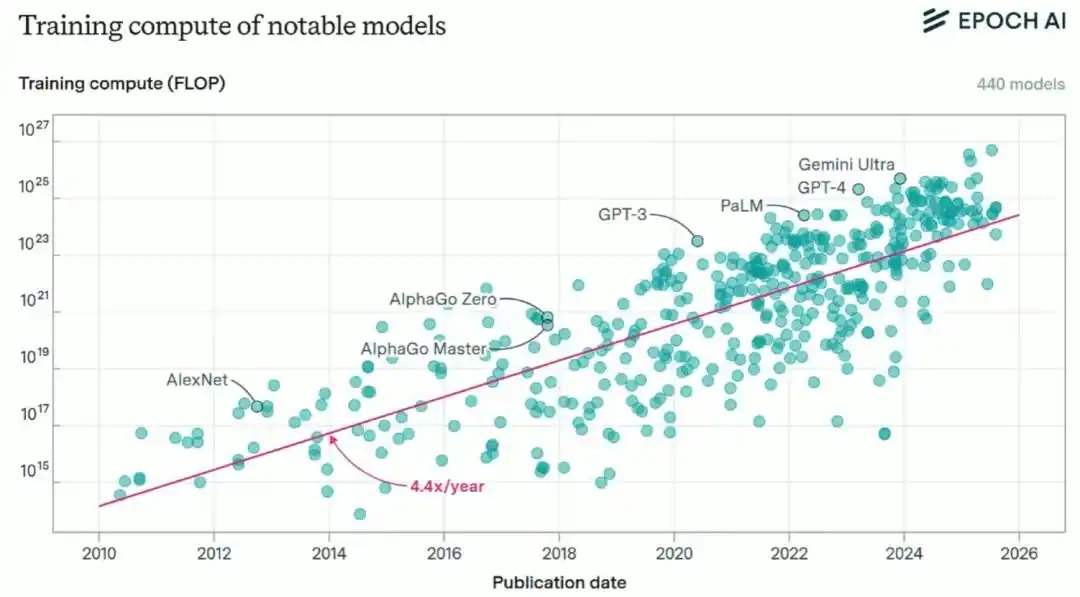
Currently, a top-tier training run requires compute costing several hundred million dollars, while the annual US GDP is nearly thirty trillion dollars, meaning there is still a very long growth runway for this curve.
But more important than scaling compute is the continuous refinement at the algorithmic level: Researchers constantly identify inefficiencies in the training pipeline and improve them; this is the true 'primary engine' behind AI progress over the past decade.
The 'Short History' of Benchmarks: From Preschool to PhD
If Scaling Law explains 'why AI gets stronger,' then the rise and fall of a series of benchmarks record 'exactly how strong AI has become.' Brown used a set of test scores to depict a dizzying curve.
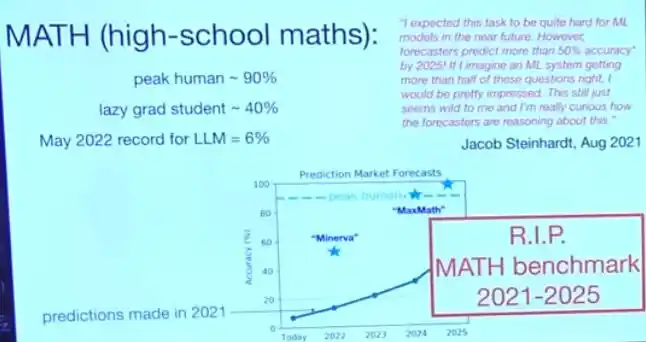
Four years ago, a benchmark called MATH for high school math problems emerged. The researchers had a computer science Ph.D. student who wasn't particularly good at math take the test, scoring about 40%; they also had a three-time International Mathematical Olympiad (IMO) gold medalist take it, scoring 90%. At that time, the most advanced large model could only manage 6%—almost indistinguishable from random guessing, as the model couldn't even understand what the questions were asking.
The prediction market at the time thought that by 2025, a model achieving 50% would be 'reckless optimism.' The benchmark's creator publicly stated that if a model actually achieved this, he would be 'quite shocked.'
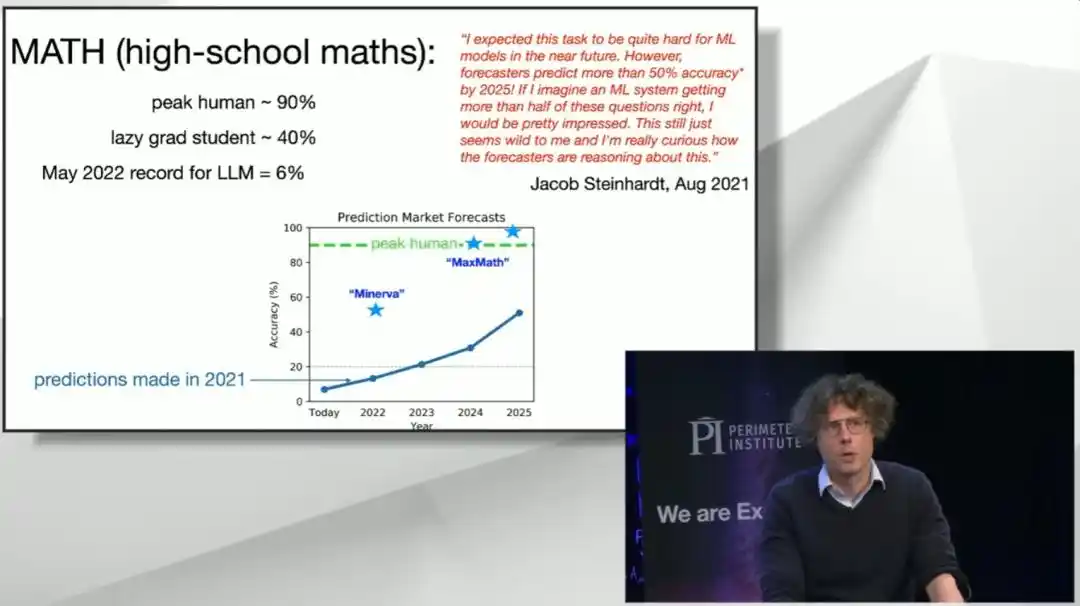
As it turned out, this 50% threshold was crossed 'immediately' by a system called Minerva. By mid-2024, Brown's team's system scored 90% on this benchmark. They even held a 1990s-style roller disco party to celebrate. However, just six months later, off-the-shelf large models were solving these problems nearly perfectly. The MATH benchmark thus 'died,' and it went directly from 'too difficult' to 'too easy,' with almost no pause in between.
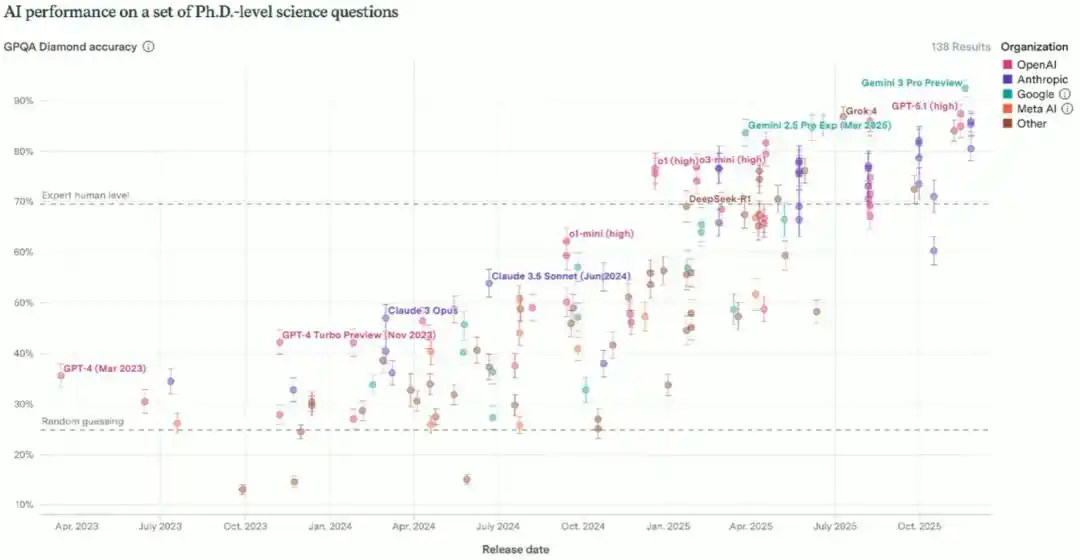
Next to fall was the GPQA test aimed at graduate students, simulating the difficulty of first-year Ph.D. qualifying exams, with human experts averaging around 70%. Starting close to random guessing, models surged past expert level between 2024 and 2025, now achieving near-perfect scores. To rule out the possibility that 'the model just memorized the answers,' Brown's team specifically designed new questions from the same distribution that had never appeared on the internet, and the model's performance barely declined.
Brown even presented his own graduate-level final exams on general relativity and quantum mechanics, which he had personally graded at Stanford (these questions had never been online), and the model also achieved perfect scores within a year and a half. He half-joked that even his own exam questions had 'unfortunately fallen.'
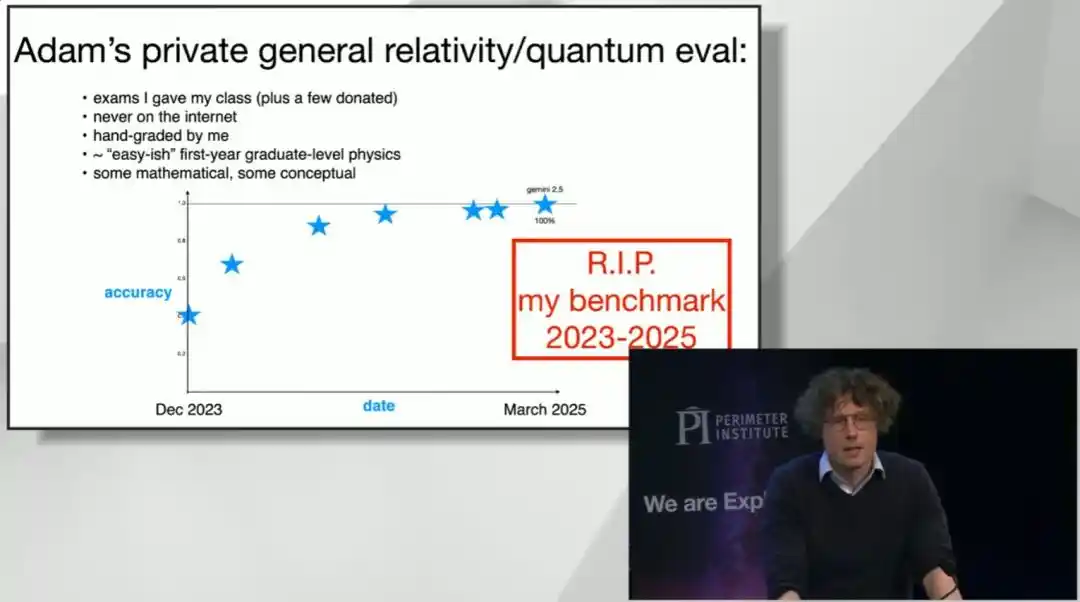
Since then, the list of fallen benchmarks has grown longer, including a super-difficult comprehensive test once called 'Humanity's Last Exam.'
But the most symbolic leap occurred on the International Mathematical Olympiad.
Crossing the IMO Threshold
Just over a year ago, a Turing Award winner told Brown in person that large models would never be able to solve problems at the level of the International Mathematical Olympiad (IMO) because that required genuine creativity, not something that could be faked by rote memorization. IMO problems are known as 'the hardest problems within the scope of high school mathematics': the smartest teenagers in the world train for one to two years to compete, and winning a gold medal by solving a few of the six problems is an exceptional feat.
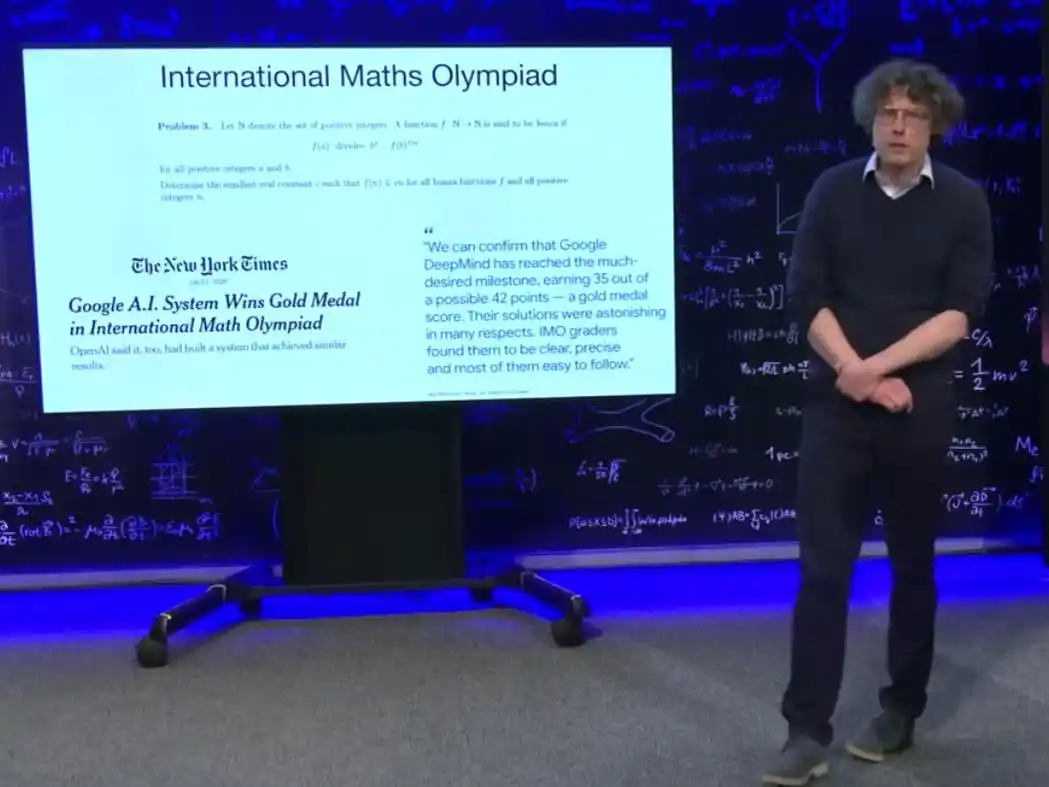
Last summer, this threshold was crossed. Brown's team's system solved five out of six problems on an IMO-level test, achieving gold medal standard. Moreover, the system didn't brute-force its way through with long, incomprehensible formal proofs. The IMO President publicly commented that these solutions were 'surprising in many ways,' with graders finding them clear, precise, mostly easy to understand, and employing mathematical abstractions similar to those used by humans.
Brown also candidly showcased a 'failure case' of large models.
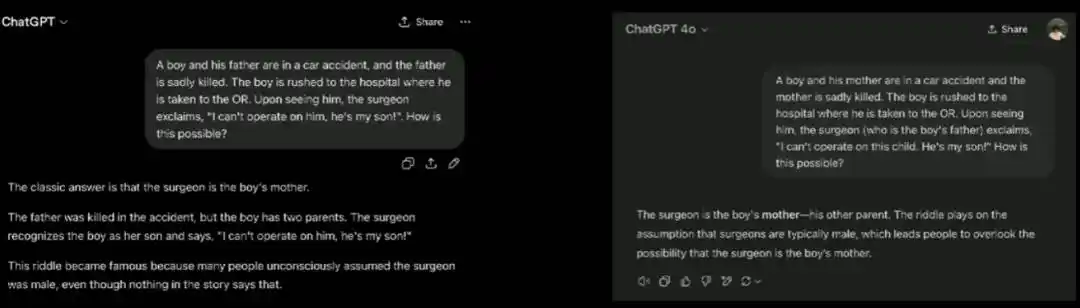
A classic brainteaser goes: A father and son are in a car accident; the father dies, the son is taken to the operating room, and the surgeon sees the boy and says, 'I can't operate on him, he's my son.' The question is how this is possible (the standard answer is the surgeon is the boy's mother). This question tests whether the reader assumes the surgeon is male. Large models handle this 'viral internet puzzle' with ease because they've seen it thousands of times in training data. But when Brown reversed the puzzle: the mother dies, and the surgeon is specifically noted as 'the boy's father,' then asked the same question, the model completely failed to notice the reversal and mechanically applied the standard answer of 'the surgeon is the other parent.'
Brown said this exposes a specific 'quirk' left by the model's training method.
Centaur Collaboration: AI Writes Proofs Mathematicians Will Co-Author
Ten months after crossing the IMO threshold, Brown's team accomplished something he considers even more significant: genuine, previously unknown mathematical research.
Last September, Brown's team collaborated with several professional mathematicians in a mode he calls the 'Centaur' model—the centaur being a half-human, half-horse creature from Greek mythology, but here, the 'non-human half' is an LLM.

The entire process was a continuous dialogue: the model proposed candidate proof ideas, human experts judged which were valuable and guided the model to delve deeper, ultimately producing a complete mathematical paper under human guidance. One of the paper's co-authors is a Stanford professor and the current president of the American Mathematical Society. This professor's evaluation was that the arguments proposed by Gemini were by no means simple repackaging of existing proofs but represented insights he himself would be proud of.
Brown emphasized that this was, at the time (late last year), the highest level large models had reached in mathematics. But he immediately added: in terms of the true significance of 'highest level,' this was still far from it.
The Real Turning Point: AI Independently Solves an 80-Year-Old Conjecture
Entering 2026, the situation changed dramatically—for the better. Brown began with a near-provocative joke: 'Just last week, LLMs hadn't made any truly significant mathematical breakthroughs.' Now, that statement is no longer true.

Many have already heard about this major event. Erdős's 1946 'Unit Distance Conjecture,' believed for eighty years by the mathematical community to have the square grid configuration as the known optimal solution. A large model inside OpenAI independently provided a counterexample, using tools from algebraic number theory to construct a series of point sets where the number of unit distance pairs exceeded the previously accepted upper bound. This effectively disproved a long-held belief.

It's worth noting that this problem was not obscure; many had tried before, but mathematicians spent significant effort always wandering in the direction of 'proving' rather than 'disproving' the conjecture. Brown specifically mentioned that Fields Medalist Timothy Gowers participated in reviewing this result and gave it high praise.
Brown judges this to be the first genuinely significant breakthrough by large models in mathematics, and he believes it certainly won't be the last—'the floodgates have opened.' As model capabilities continue to surpass 'the threshold required to produce breakthroughs,' he expects more similar results to appear in succession.
He half-jokingly added that in retrospect, the reason this problem was cracked first is probably because its structure happened to fall within large models' 'comfort zone.' Next, models will first solve problems 'friendly to AI,' then gradually tackle those 'less friendly' ones.
The Prophecy from Chess
To convince the audience that this curve will continue to rise, Brown presented a graph that at first glance looked like a casually drawn line: a steadily climbing straight line. Of course, this graph wasn't drawn out of thin air; it was taken directly from real data on chess computer strength over time, with the y-axis being the Elo rating measuring playing strength and the x-axis being the year.
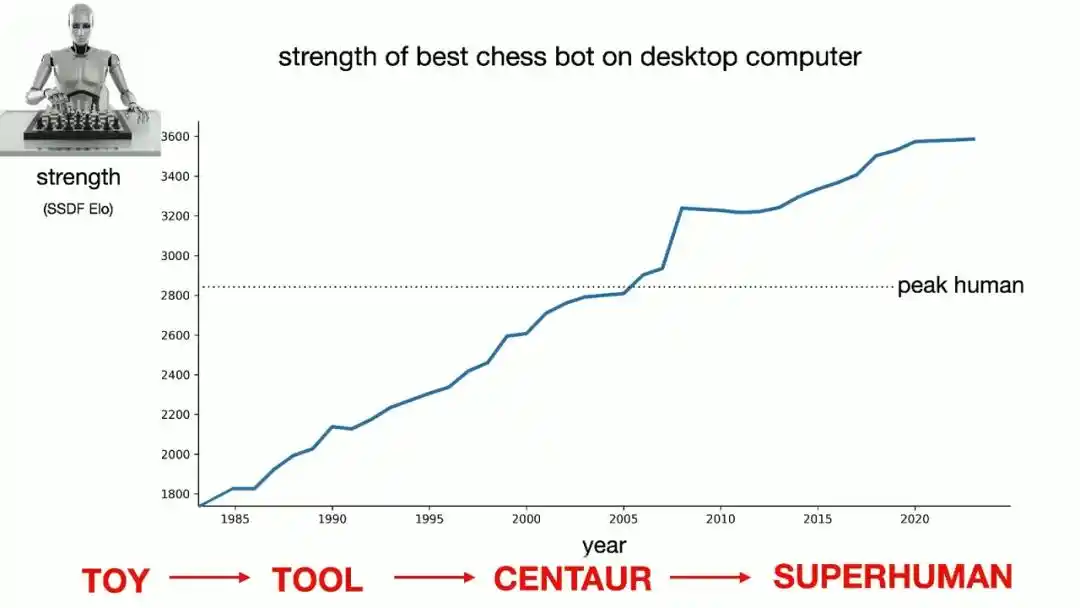
Brown outlined four historical stages of chess AI:
Initially, the 'Toy Era,' where getting a computer to make a single reasonable move was considered a miracle;
Then, the 'Tool Era,' where computers were only useful in specific aspects like endgame calculation or opening memorization;
Next, the 'Centaur Era,' where the strongest chess entity in the universe was the collaboration between grandmasters and the deep search capabilities of computers;
And now, humanity has fully entered the 'Superhuman Era': when top human players collaborate with computers, the optimal strategy is simply to let the computer play on its own.
Brown believes these four stages can be closely mapped to the field of scientific research.
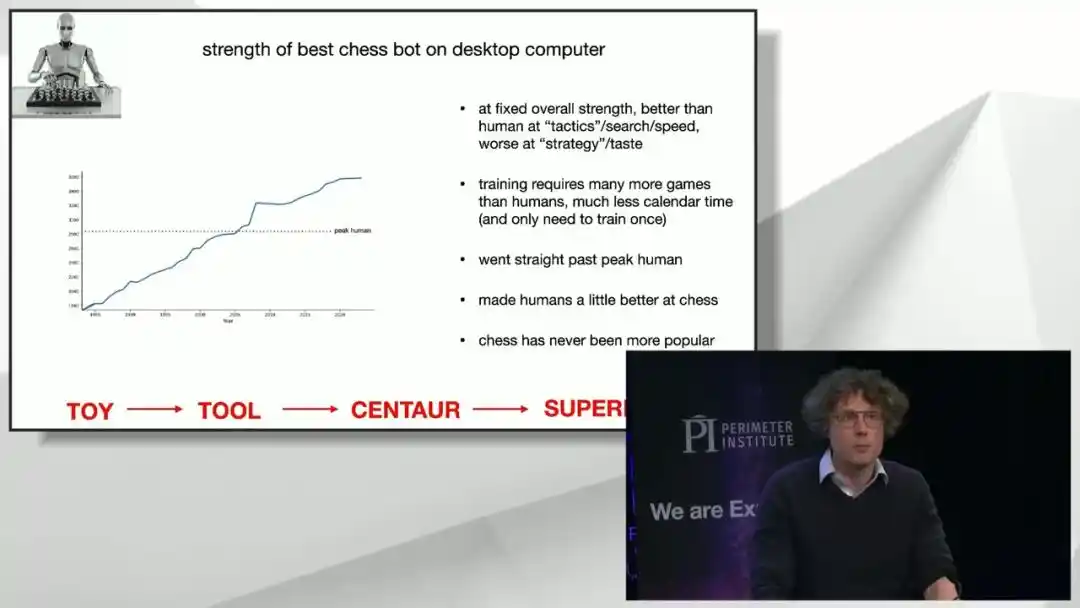
The first pattern is: at comparable overall strength, computers surpass humans in tactics and search speed but are weaker in strategy and 'taste' judgment. This precisely matches the characteristics currently exposed by large models in mathematical and physical research: they excel at applying existing lemmas and techniques but are less adept at judging 'which overall direction to take,' though this shortcoming is rapidly shrinking.
The second pattern is: the number of games needed to 'experience' for training a chess AI far exceeds the total number of games a human can play in a lifetime, but because machines can tirelessly play against themselves at high speed, the actual 'calendar time' required is far shorter than training a human chess player.
The third pattern is that once computer chess strength surpassed peak human level, it never stopped, as there is no physical or logical reason for it to conveniently stop near human level.
The fourth comforting fact is: the rise of chess AI has actually improved the overall level of human chess players; the strongest human players today are stronger than at any time in history, partly thanks to learning from super-strong AIs; and the game of chess itself has never been more popular.
Brown's implication is clear: if scientific research follows this trajectory, humanity will likely first encounter fully autonomous 'AI scientists,' followed by something akin to 'AI Einsteins'... What happens after that, he admits, is beyond his predictive abilities.
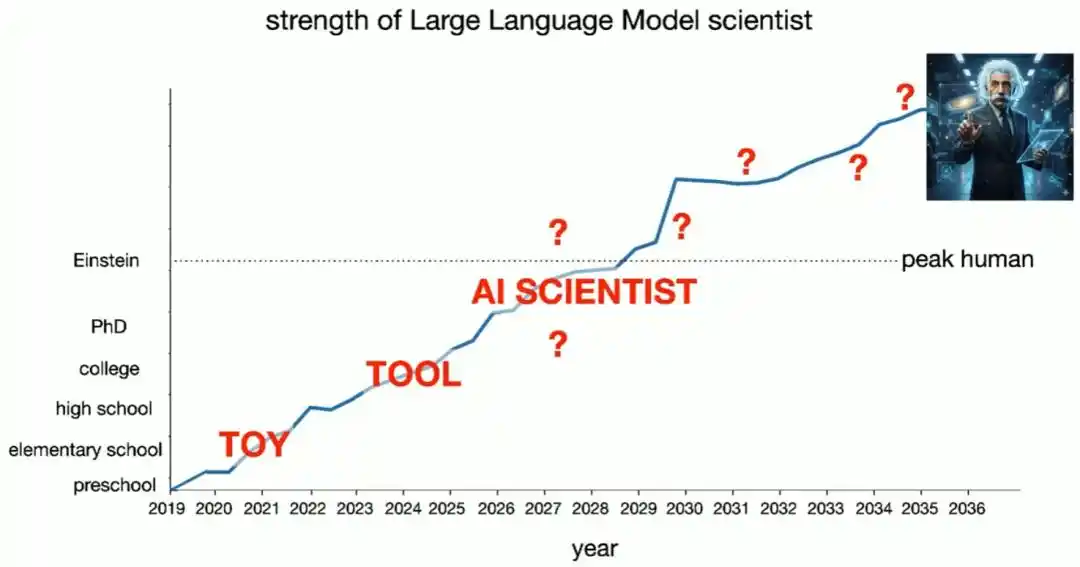
Even if Progress Stops Here, Physics Has Already Been Transformed
Brown also raised a cautionary 'pessimistic hypothesis': what if large model capabilities completely stagnate starting today?

He bluntly stated that what truly 'doesn't work' right now is directly asking the model, 'Please invent a brand new theory of quantum gravity for me.' The answer would likely be worthless, sleep-inducing 'AI nonsense.'
More generally, current large models still have four obvious shortcomings: low autonomy, slow learning speed, poor planning ability, and weak error-correction capability.

Brown admitted that all four shortcomings have significantly improved over the past year, but none have been completely solved. Consequently, a system that can ace graduate-level exams in every discipline has yet to produce results that could be called 'major breakthroughs.'
While preparing for this speech, he even specifically drew this as a flat 'straight line' marked with a question mark, self-deprecatingly admitting it was perhaps the only chart in the entire talk that 'didn't keep rising.' But he added that before the end of 2026, people would probably start arguing about how to define the term 'major breakthrough.' As it turned out, this day arrived even sooner than he himself anticipated.
However, even if progress truly stopped at this moment, Brown believes large models are already sufficient to completely transform the landscape of physics research.
He listed several already mature and still-improving use cases:
As a 'non-judgmental private tutor,' available at 3 AM to answer a physicist's own unclear knowledge gaps without waking a world-class expert;
As a programming assistant, now so strong that 'calling it just a programming assistant feels somewhat insulting.' Many physics problems previously considered 'not programming problems' can now be reframed as coding problems to solve;
As a literature retrieval tool, capable of reading an entire field's paper repository and directly telling you if an idea has already been explored; additionally, serving as a brainstorming partner.
Brown summarized that the core advantages of large models are: they are fast, broad in coverage, tireless, and can be replicated indefinitely. It takes decades to train a physicist, but once a powerful model is trained, you can run thousands of copies simultaneously—this alone is enough to 'completely change' the discipline.
Conclusion: The Golden Age of Physics
At the end of his speech, Brown gave his judgment on 'why progress won't stop.'
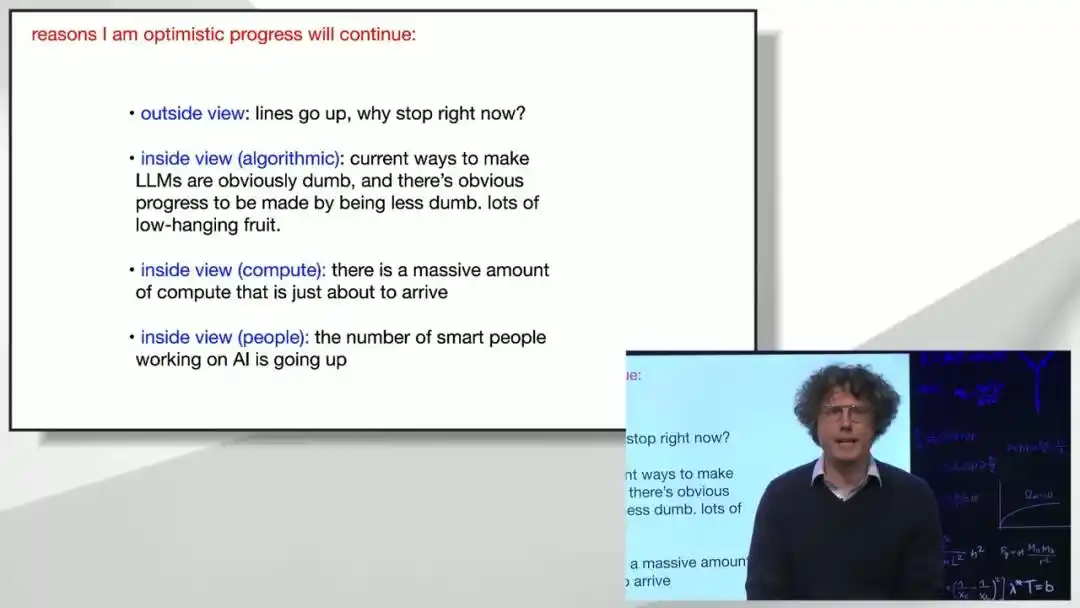
From a macroeconomic perspective, the funds currently invested in training still represent a very small fraction of global GDP, leaving ample room for growth. From a technical internal perspective, current methods for training large models are 'far less sophisticated than they appear.' Many obvious yet untried improvement ideas remain to be explored. Combined with the continuous influx of talent and compute into the field, Brown judges that current model architectures and compute scales are already sufficient to lead to Artificial General Intelligence, even without entirely new theoretical breakthroughs.
He also responded to a long-standing pessimistic view that large models only do 'pattern matching' and cannot generate genuinely new ideas.

Brown's view is that if you abstract to a high enough level, almost all human creations that seem like 'major breakthroughs' are essentially a form of higher-dimensional pattern matching. A recurring phrase in this field that has been repeatedly validated is: 'these models just want to learn.' No matter how many seemingly reasonable theoretical reasons suggest they shouldn't learn well, their performance always exceeds expectations.
Brown's conclusion is that in the next few years, we will usher in a golden 'Centaur' era of human-AI collaboration: these tools will be placed in the hands of human physicists, mathematicians, and experts across fields, jointly kickstarting a new Renaissance in science and mathematics.
Further ahead, if 'creating an AI Einstein' is truly achieved, since replicating a trained model comes at almost no extra cost, humanity will likely soon have billions of 'superhuman-level AI Einsteins' operating simultaneously. This sounds like science fiction, but it's happening.
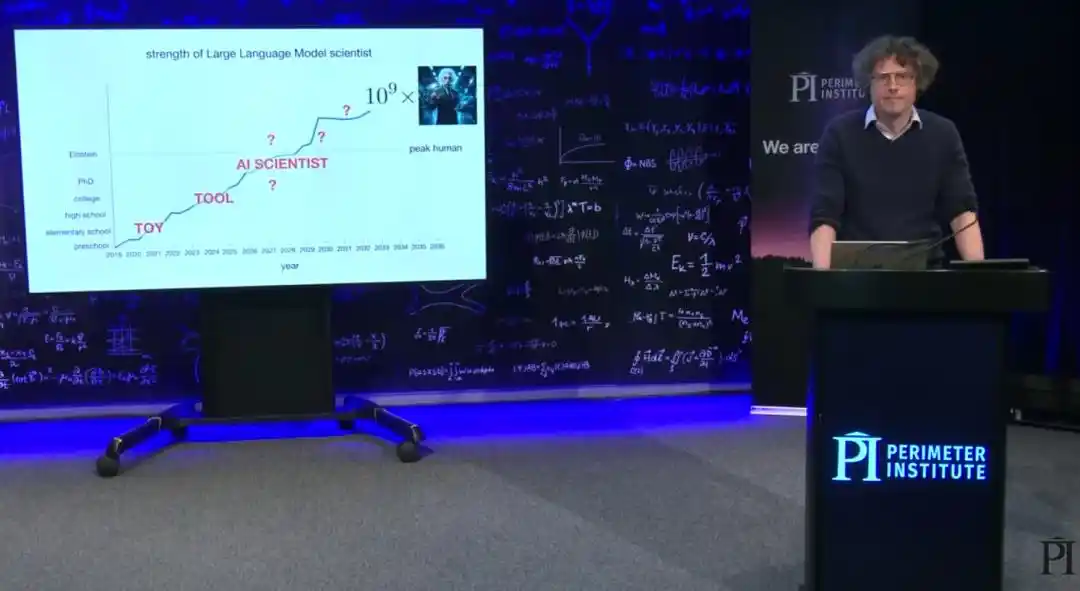
Brown said that in the long run, where AI will ultimately take physics is as difficult for him to predict as for anyone else. He even believes that the continuous improvement of AI capabilities is making the future of the entire world harder to predict. But one thing he is sure of: the next few years will be the most exciting time in the history of physics. He expects the problems that have plagued his entire career to be answered one by one in the not-too-distant future.
This article is from the WeChat public account 'Machine Heart' (ID: almosthuman2014), Author: Following AI.