刚刚,DeepSeek-V4来了!
预览版正式上线并同步开源。
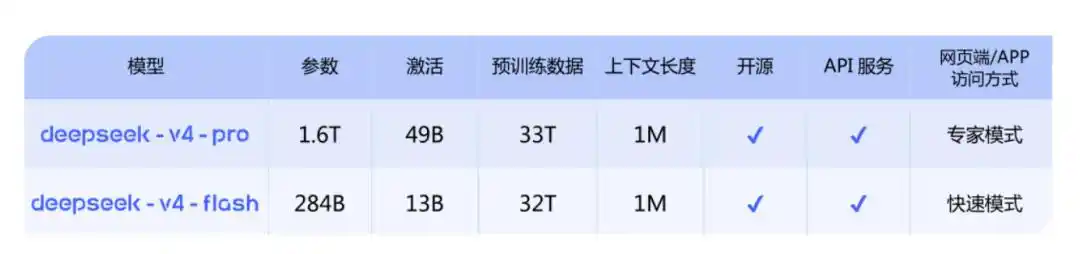
一共两个版本:
DeepSeek-V4-Pro:对标顶级闭源模型,1.6T,49B激活,上下文长度1M;
DeepSeek-V4-Flash:更小更快的经济版,284B,13B激活,上下文长度1M。
官方原话是:在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。
并且:
目前DeepSeek-V4已经成为公司内部员工使用的Agentic Coding模型,据评测反馈使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式。但仍与Opus 4.6思考模型存在一定差距。
目前官网和APP都上了,API服务也已同步更新。
大家都关心的国产算力方面,划重点,下半年支持华为算力。

顶配和性价比之选,两个版本一起开
这次V4一口气发了两个版本。
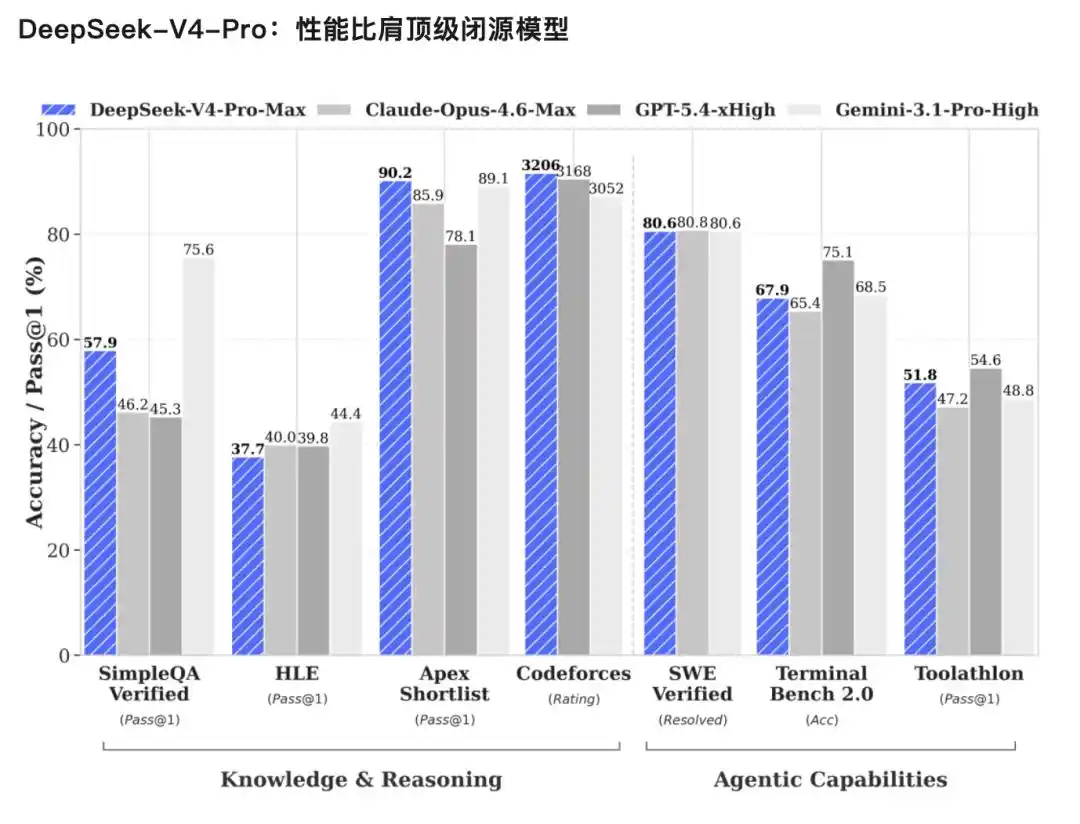
V4-Pro,性能比肩顶级闭源模型。
官方给出的判断有三条:
Agent能力大幅提高:在Agentic 能力Coding评测中,V4-Pro已达到当前开源模型最佳水平,并在其他Agent相关评测中同样表现优异。内部测评中,Agent Coding模式下,V4体验优于Sonnet 4.5,交付质量接近 Opus 4.6非思考模式,但仍与 Opus 4.6思考模式存在一定差距。
丰富的世界知识:DeepSeek-V4-Pro在世界知识测评中,大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。
世界顶级推理性能:在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro超越当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。
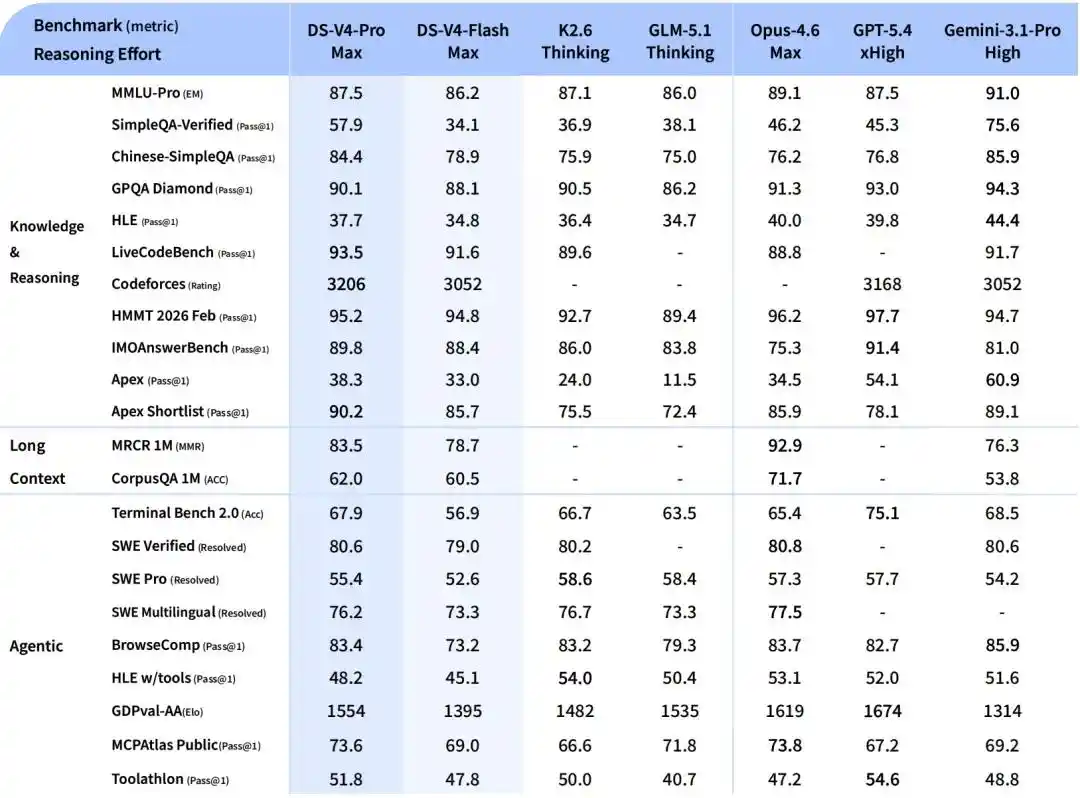
V4-Flash,更小更快的经济版。推理能力接近Pro,世界知识储备稍逊一筹,但参数和激活更小,API更便宜。
在Agent任务方面,DeepSeek-V4-Flash在简单任务上与DeepSeek-V4-Pro旗鼓相当,但在高难度任务上仍有差距。
在洗车测试上,V4也是快速通过。

而在“绝望的父亲”这个经典的生物学场景当中,DeepSeek-V4并没有一轮get到红绿色盲这个关键点(根据遗传学规律,如果一名女性是红绿色盲,其生物学父亲必然也是)。

百万上下文实现标配
值得一提的是,从今天开始,1M上下文是DeepSeek所有官方服务的标配。
一年前,1M上下文还是Gemini独家的王牌;其他所有闭源模型要么128K要么200K;开源这边几乎没人玩得起这个量级。
DeepSeek直接把百万上下文从一个「高端功能」挪成了「水电煤」。
而且开源。他们怎么做到的,发布稿里直接给了答案——
V4开创了一种全新的注意力机制,在token维度进行压缩,结合DSA稀疏注意力一起用。相比传统方法,对计算和显存的需求大幅降低。
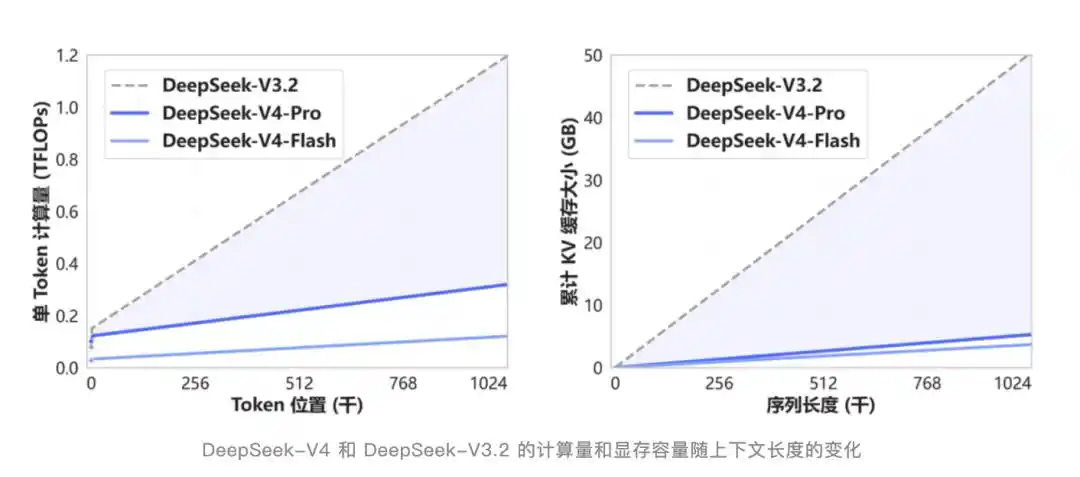
DSA不是新词。半年前V3.2-Exp那次更新首次引入,当时外界关注度不高,因为跑分和V3.1-Terminus几乎一样,看起来像一次没什么料的中间版本。
现在回头看,那是V4的地基。
Agent能力专项优化
Agent这边,V4针对Claude Code、OpenClaw、OpenCode、CodeBuddy等主流Agent产品做了适配和优化,代码任务、文档生成任务都有提升。
发布稿里还附了一张V4-Pro在某Agent框架下生成的PPT内页示例。

API价格
API这边,V4-Pro和V4-Flash同步上线,支持OpenAI ChatCompletions接口和Anthropic接口两套。
base_url 不变,model 参数改成 deepseek-v4-pro 或 deepseek-v4-flash 即可调用。
两个版本最大上下文都是1M,都同时支持非思考模式和思考模式。思考模式下可以通过reasoning_effort 参数调强度,两档high和max。官方建议复杂 Agent 场景直接上max。
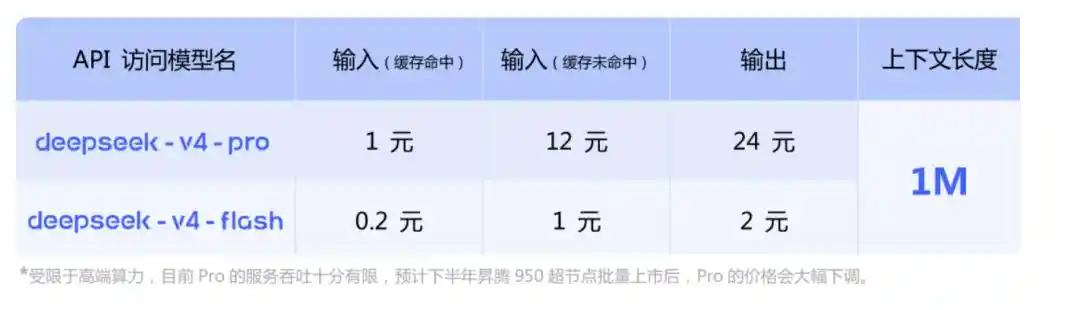
这里有个重点——下半年支持华为算力。
此外,旧模型名要下架。
deepseek-chat和deepseek-reasoner将在三个月后(2026年7月24日)停用,当前阶段内这两个名字分别指向V4-Flash的非思考和思考模式。
对个人开发者影响不大,改一个model参数。对接了生产环境的公司,这三个月要去做迁移。
One more thing
发布稿的结尾,DeepSeek 自己引了一句话。
「不诱于誉,不恐于诽,率道而行,端然正己。」
这是荀子《非十二子》里的一句。字面意思是,不被赞誉诱惑,不被诽谤吓到,按自己认定的道往前走,端正自己。
放在今天这个场景里,有点意思。
过去半年,关于V4什么时候发、是不是跳票、是不是已经被别家超越、是不是已经被 Claude 蒸馏数据搞定了之类的传言在中文和英文AI圈来来回 回跑了好几轮。年初甚至还有人信誓旦旦说V4会在春节前发,结果等到了四月底。
他们没回应过一次。
然后在某个周五的下午,把V4放出来,同步开源,同步上线官网和App,同步更新API,顺便把内部员工已经弃用Claude的事实写进发布稿。
没有路线图,没有直播,没有访谈。
率道而行这四个字,听着像是一句口号。但如果你把过去半年 V3.2 那次「没什么亮点」的 Exp 版本、DSA那套为V4铺了半年的稀疏注意力、1M 上下文从王牌变成标配的这条路径放在一起看。
DeepSeek已经做到了。
DeepSeek-V4模型开源链接:
[1]https://huggingface.co/collections/deepseek-ai/deepseek-v4
[2]https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
DeepSeek-V4 技术报告:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
本文来自微信公众号“量子位”,作者:量子位