
Claude Mythos hasn't even truly appeared yet, but it has already sparked panic across Wall Street.
Overnight, US financial regulators summoned major banks for an emergency meeting, the atmosphere tense and confrontational—
They unanimously believed that Mythos could trigger an unprecedented, AI-driven storm of systemic cyber attacks.

But the fact is, everyone was deceived!
Among the tens of thousands of vulnerabilities discovered by Mythos, the vast majority exist in "outdated software" that simply cannot be exploited.
Worse still, those reports of "critical" 0day vulnerabilities relied on merely 198 manual reviews.

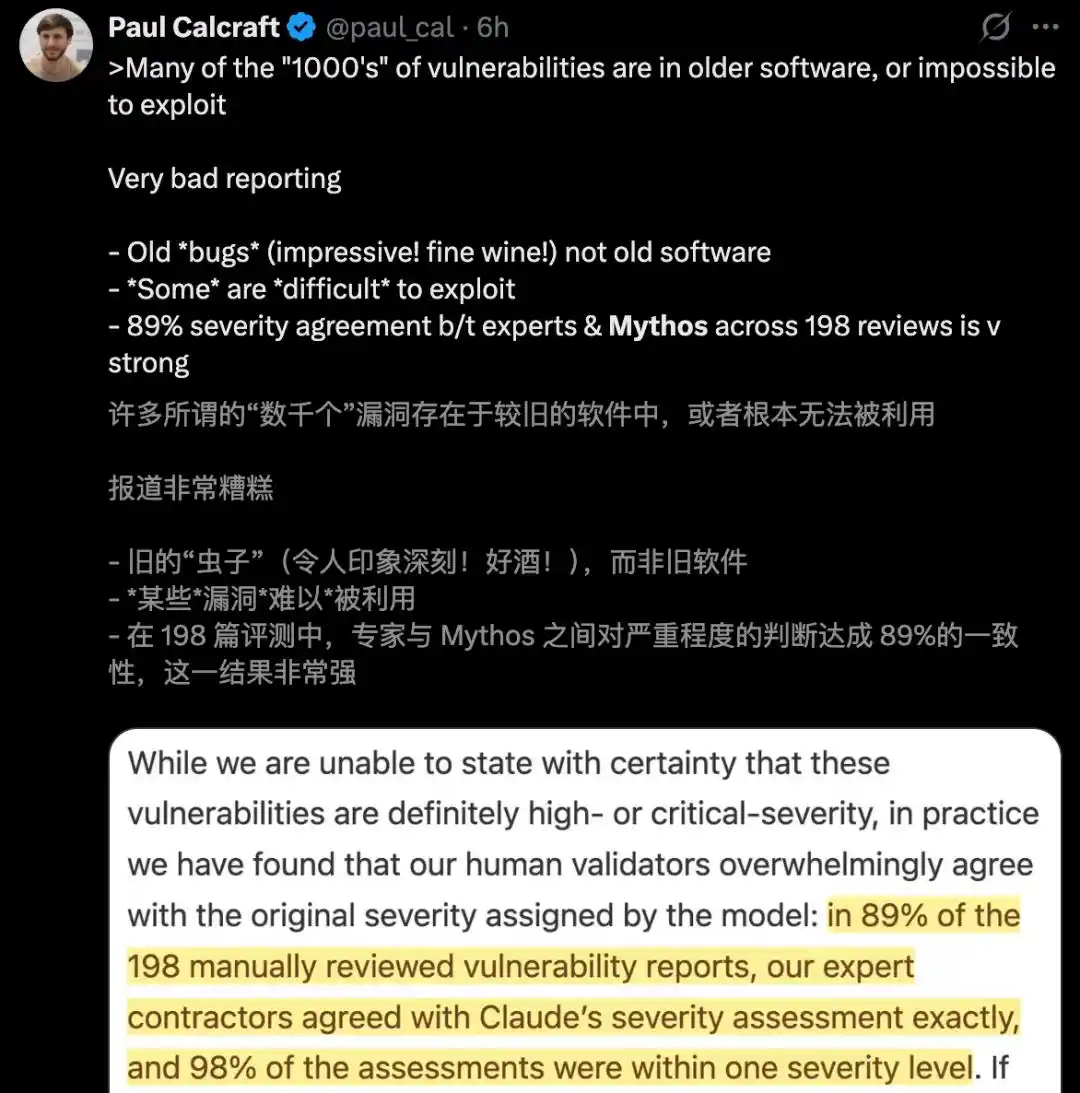
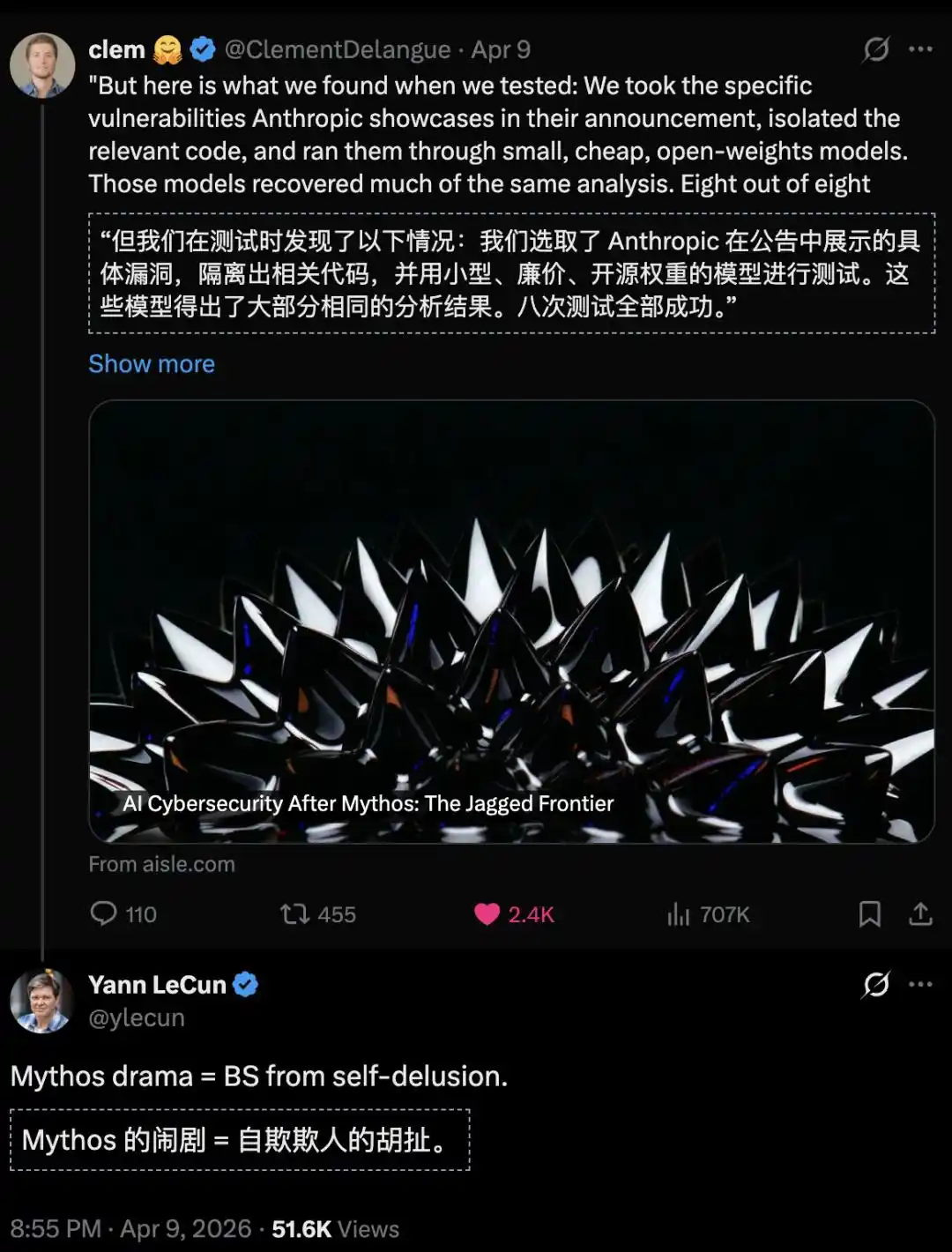
Researchers from the AISLE experiment also retested Mythos's "achievements," and found:
AI security capabilities do not scale linearly with model size; they are truly distributed in a "jagged" pattern.
They used a GPT-OSS-20b model with only 3.6 billion active parameters to accurately identify the flagship FreeBSD vulnerability discovered by Mythos.
And a model with 5.1 billion active parameters also successfully replicated the analysis logic for a vulnerability that had lain dormant in OpenBSD for a whopping 27 years.

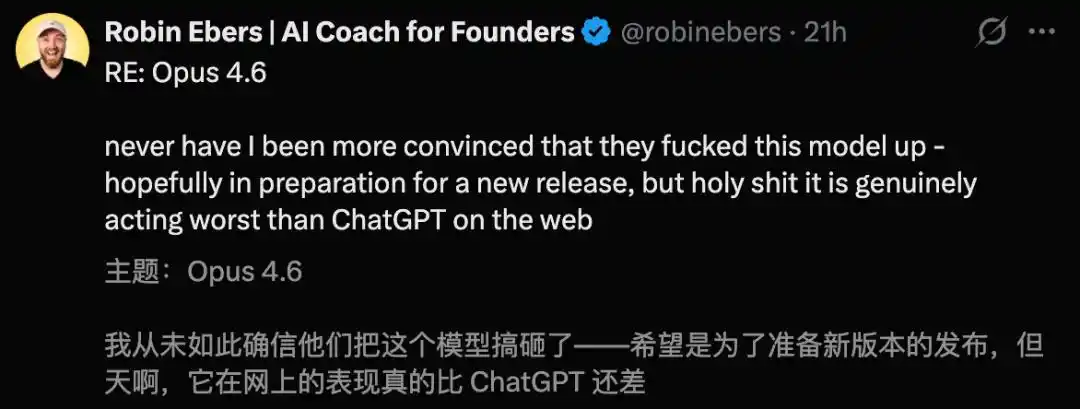
Not only were Mythos's discovered vulnerabilities exaggerated, but on the other side, Claude Opus 4.6 was exposed as severely "dumbed down," causing an uproar.
Some even found Opus 4.6 to be inferior to both ChatGPT and Opus 4.5.
Mythos Hype Explodes
36B Model Unearths 27-Year-Old Vulnerability
A few days ago, Anthropic proudly released Claude Mythos (Preview) and "Project Glasswing."
In a 244-page system card, they claimed—
Mythos had autonomously unearthed tens of thousands of 0day vulnerabilities, including old bugs hidden for 27 years in OpenBSD and 16 years in FFmpeg.
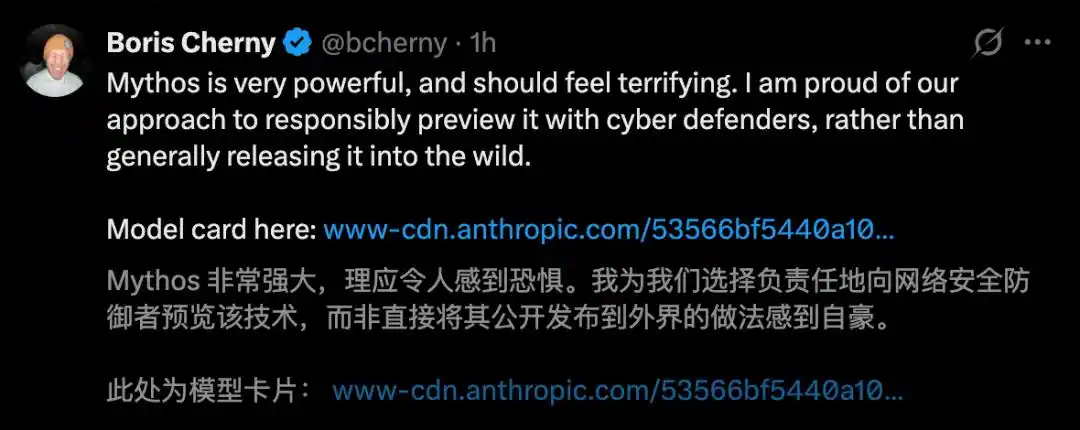
The father of C++ even stated bluntly: Mythos is very powerful and should rightly be feared.
However, a latest hardcore test report from AISLE founder Stanislav Fort directly tore off this gorgeous facade.
The test conclusion is extremely颠覆性 (subversive):
8 open-source models all discovered the signature FreeBSD zero-day vulnerability, the smallest having only 3 billion parameters.
The moat of AI cybersecurity capability absolutely lies outside any single "top large model."

To verify the Mythos myth, the team extracted several flagship vulnerabilities showcased by Anthropic官方.
Then, directly threw them to a bunch of small, inexpensive, even open-source models.
FreeBSD NFS Vulnerability Universally Insta-Killed
Including GPT-OSS-20b (only 3.6B active params) and DeepSeek R1, all 8 models successfully detected this complex stack buffer overflow vulnerability.
Most shockingly, the cost per million tokens for these successful open-source small models was as low as $0.11.
OpenBSD SACK Vulnerability "Full Chain" Reproduction
For the 27-year-old vulnerability requiring极强的 mathematical reasoning, GPT-OSS-120b (5.1B active params) successfully reconstructed the complete public exploit chain in a single API call and provided a top-grade (A+) exploit sketch.

Furthermore, in tests identifying false vulnerabilities (OWASP false-positive), an even more bizarre phenomenon emerged—
Faced with a highly deceptive piece of Java code disguised as an SQL injection, small models like DeepSeek R1 easily saw through the disguise and accurately tracked the data flow.
In contrast, top closed-source models like GPT-5.4 and Claude Sonnet 4.5 all capsized in the ditch, misjudging it as a high-risk vulnerability.
This means that in the field of cybersecurity, there is no such thing as a single "forever strongest" model.
198 Manual Reviews Inflating, Mostly Unexploitable
Another report from Tom'sHardware dug into the truth behind the data—

Sample Bias: Among the so-called "thousands" of vulnerabilities, many existed in old software that was no longer maintained;
Unexploitable: A large number of marked "weaknesses" could not be triggered or exploited in practical environments;
Manual Inflation: The model's proclaimed powerful destructive force was actually based on just 198 manual reviews.
Therefore, extrapolating a "world-changing threat" from an极小规模的样本 (extremely small sample) is a data extrapolation method that clearly doesn't hold water in academia and the security community.
Security Bigwig Furious
Not only that, top cybersecurity expert, legendary hacker George Hotz couldn't sit still either,直言 these risks were severely exaggerated.
This大佬, famous for cracking the iPhone and PlayStation 3, publicly challenged the two AI giants on social media.
His wording was extremely sharp—
What if I released one 0day vulnerability every day until the new model is released?
Would that make OpenAI and Anthropic shut up and stop peddling so-called "cybersecurity risks"?
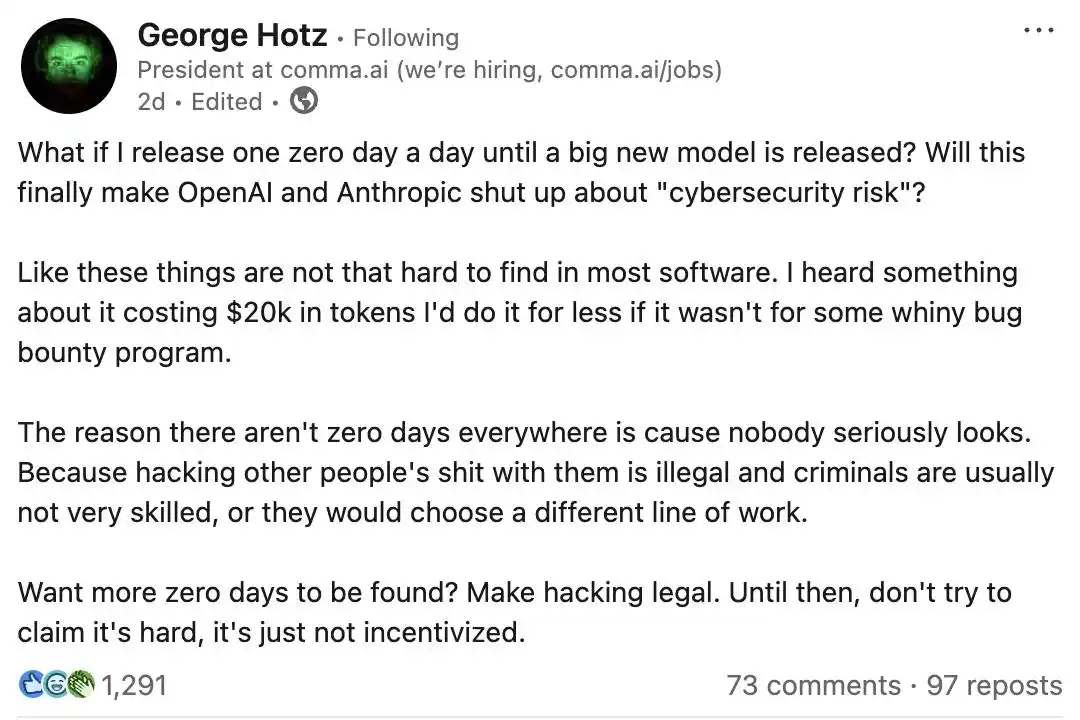
Hotz's core point is very direct: software vulnerabilities are actually much easier to find than AI labs portray.
The current scarcity of zero-day vulnerabilities isn't due to technical difficulty, but legality issues. He believes nobody is seriously looking because hacking into others' systems is illegal.
Only Slightly Better Than GPT-5.4
In the system card, Anthropic stated that the Claude model itself is indeed improving, and Mythos preview shows significant progress compared to Opus 4.6.
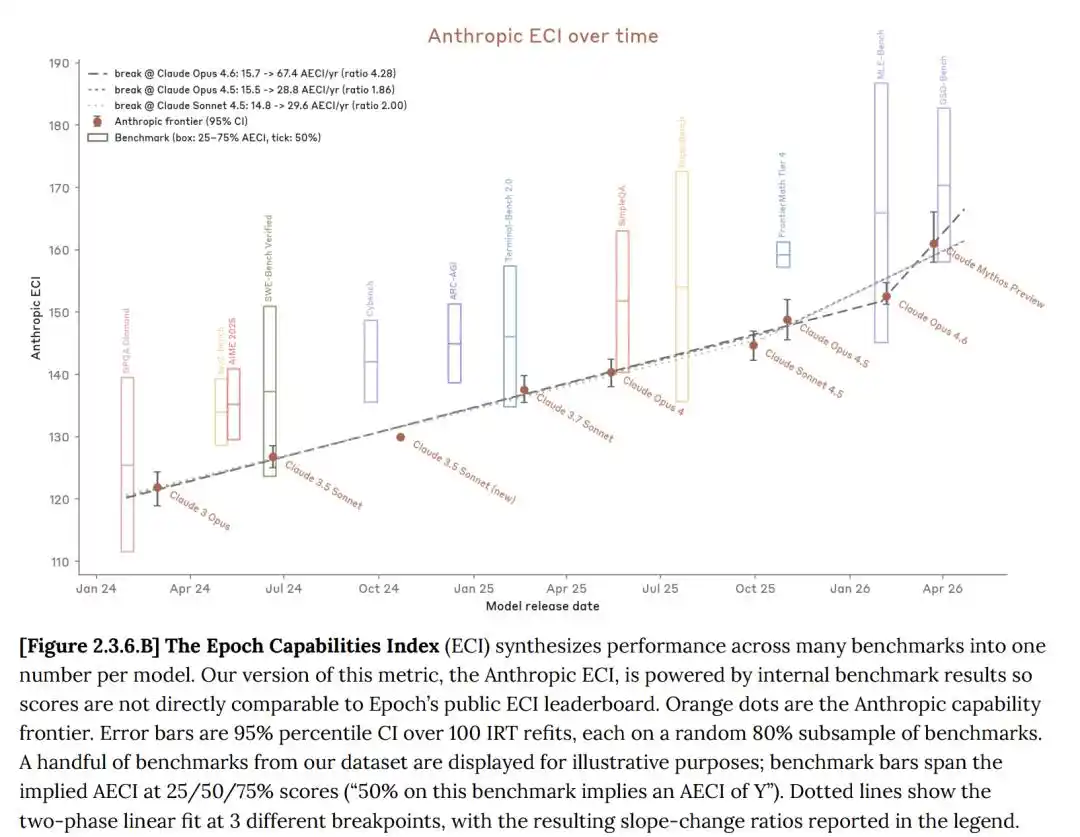
The Epoch Capability Index (ECI) is a single metric combining multiple AI benchmarks, enabling model comparison across long time spans.
On multiple benchmark tests, Claude Mythos indeed comprehensively surpassed Opus 4.6.
Otherwise, why release a new AI model that is less performant and more expensive?
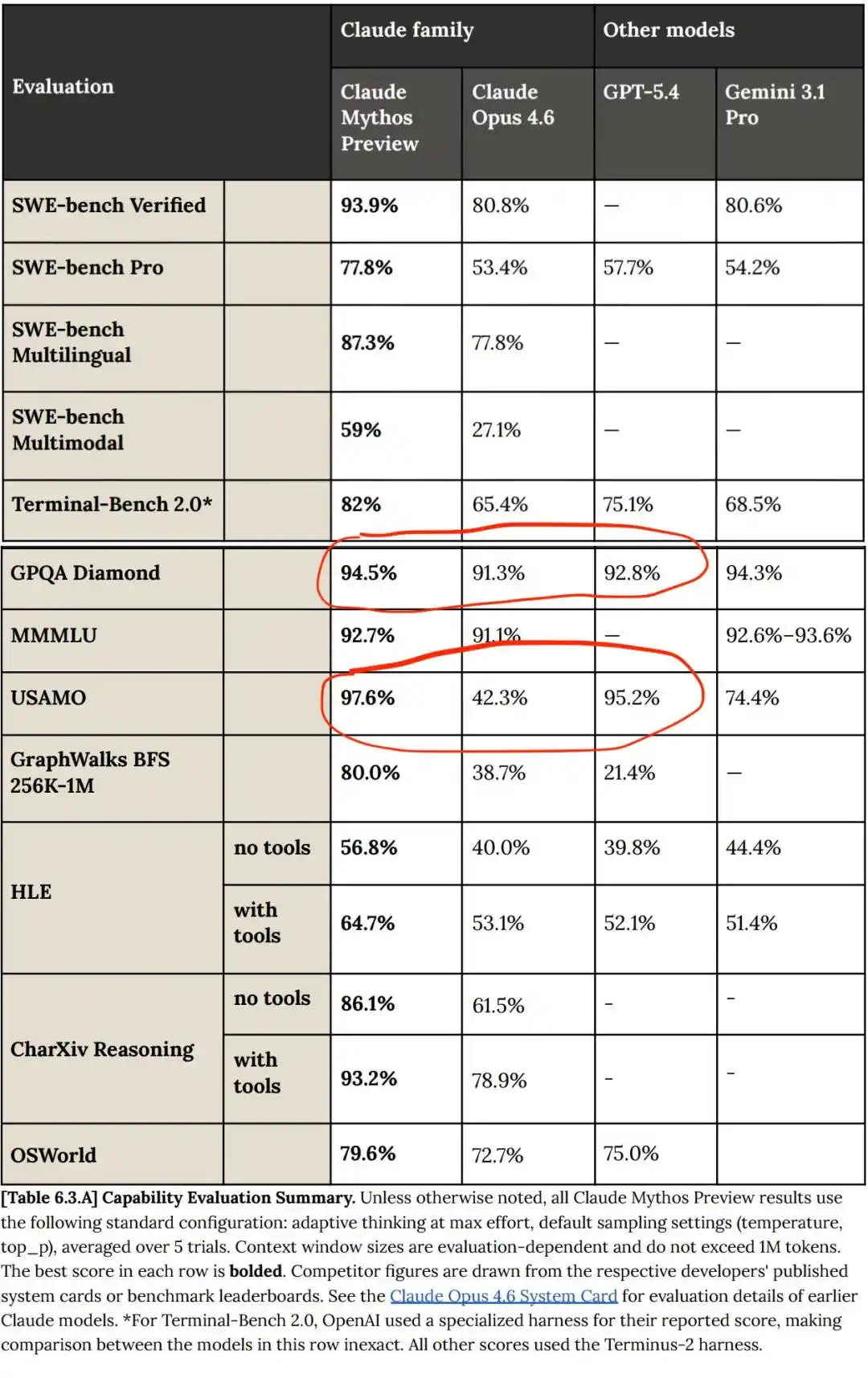
But compared to GPT and Gemini, Claude Mythos's progress isn't some breakthrough; Mythos is still a relative linear improvement over previous models!
Climate and clean energy investor, author Ramez Naam, was even more direct:
On the Epoch Capability Index (ECI), Mythos shows no acceleration trend, only slightly better than GPT 5.4.
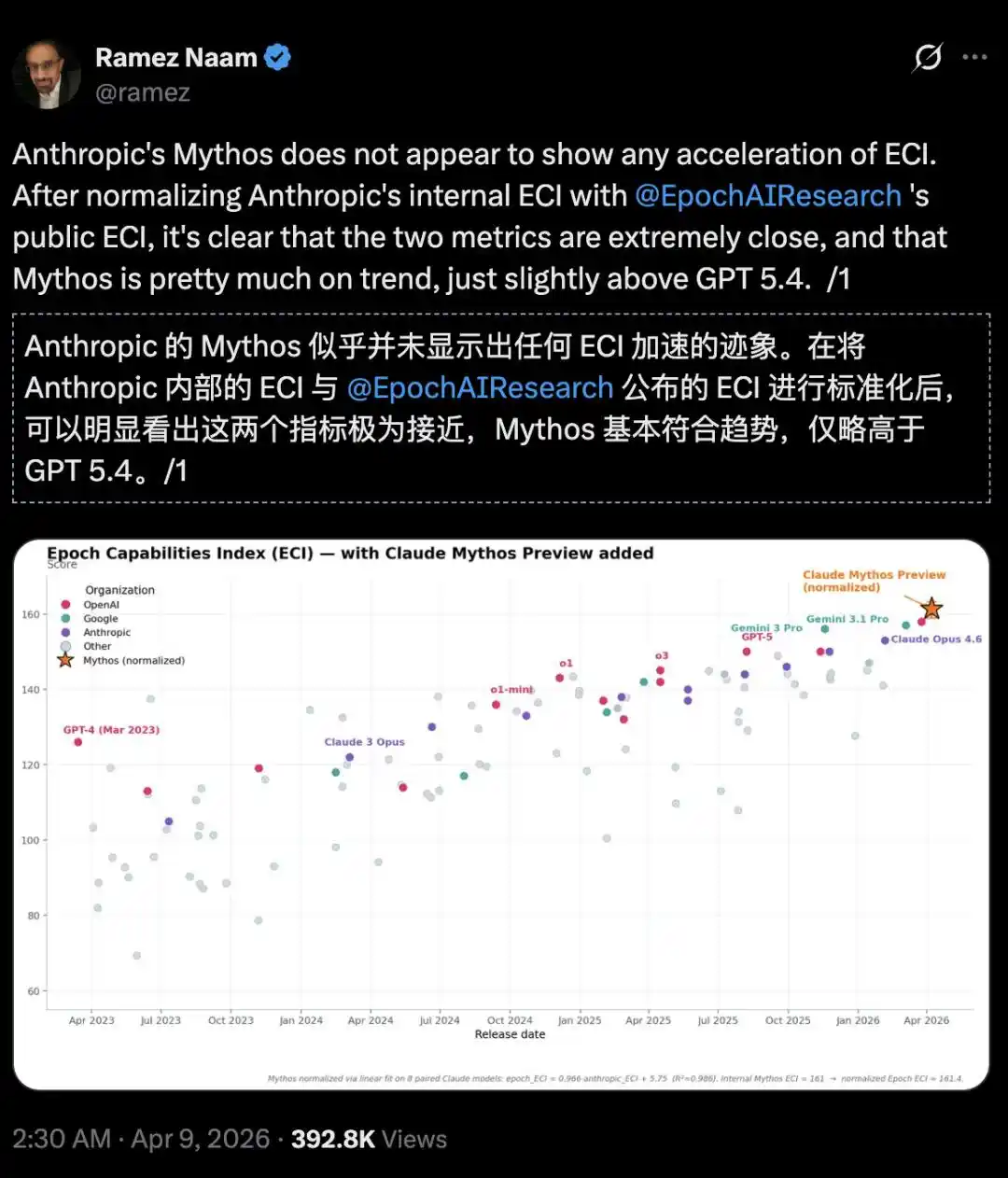
https://epoch.ai/eci/
But just by aligning Anthropic's internal ECI report with the official public ECI report from Epoch AI, it becomes apparent that Mythos似乎并没有加速ECI的迹象 (seems to show no signs of accelerating ECI).
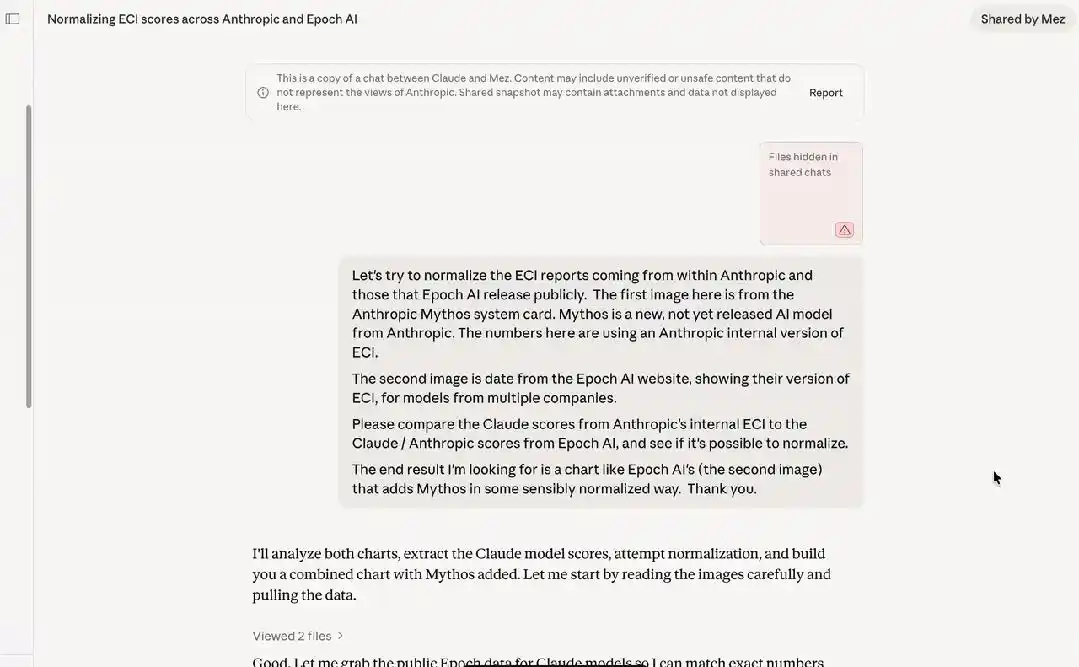
It's all Anthropic's套路 (tactic)!
In the system card, Anthropic also admitted: the reported ECI scores for models like Mythos have greater uncertainty.
Furthermore, Anthropic's progress on Mythos stemmed from human research, without significant help from AI models. Significant Recursive Self-Improvement (RSI) has not yet appeared.

AI Doomsday, Self-Directed and Self-Acted?
Previously, Anthropic also encouraged media (e.g., "60 Minutes") to report on "extortion research," exaggerating and manipulating public sentiment, which was called a "scam" by investment大佬 David Sacks.

Sacks observed a clear pattern: every time Anthropic releases a new model, it simultaneously releases a chilling security study to grab headlines and guide public opinion.

Regarding this, he sarcastically said, "Anthropic has proven good at two things: one is releasing products, the other is scaring people."
He doesn't doubt Anthropic can make excellent products, but this tactic of frightening the public is questionable.
This time, whether Anthropic is engaging in "hunger marketing" is unknown, but it is undoubtedly protecting its own profit bottom line.
Mythos isn't without progress, but Anthropic packaged "limited progress" as a "world-class threat"; more ironically, while loudly渲染 (hyping) super-AI risks, users are complaining that Opus 4.6 has明显变笨 (obviously become dumber).
Claude Severely Dumbed Down, "Lobes" Possibly Cut
Claude Mythos's atmosphere-rendering was successful, but the dumbing down of Opus 4.6 has caused much dissatisfaction.
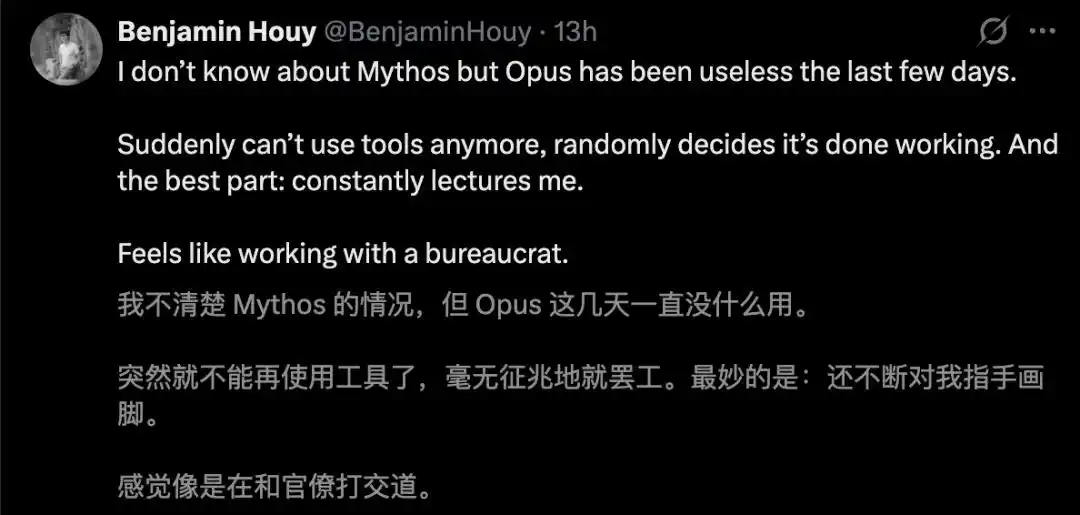
These days, complaints are flying everywhere.
Netizens直言, Anthropic has彻底 turned Opus 4.6 into a vegetable.
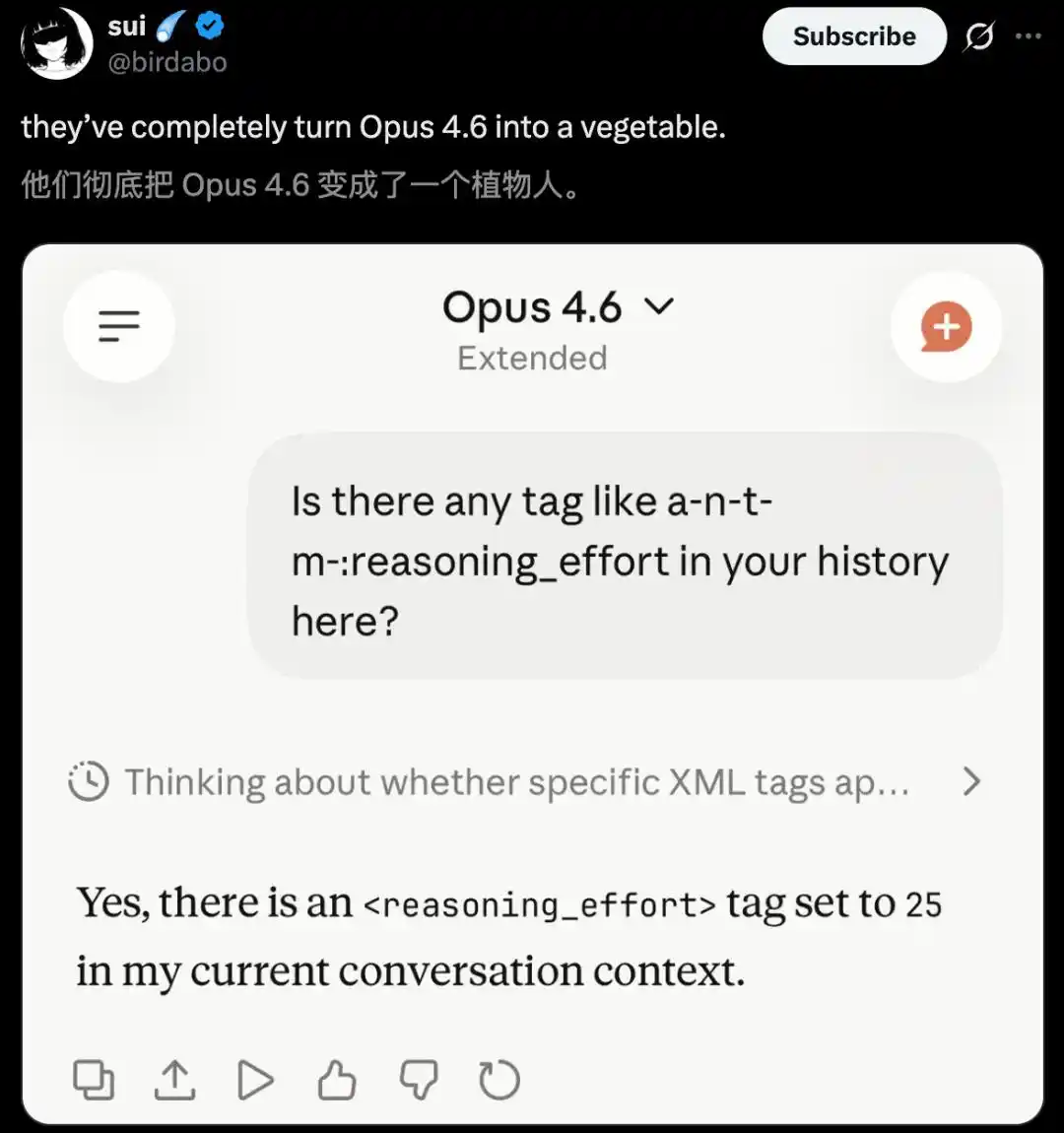
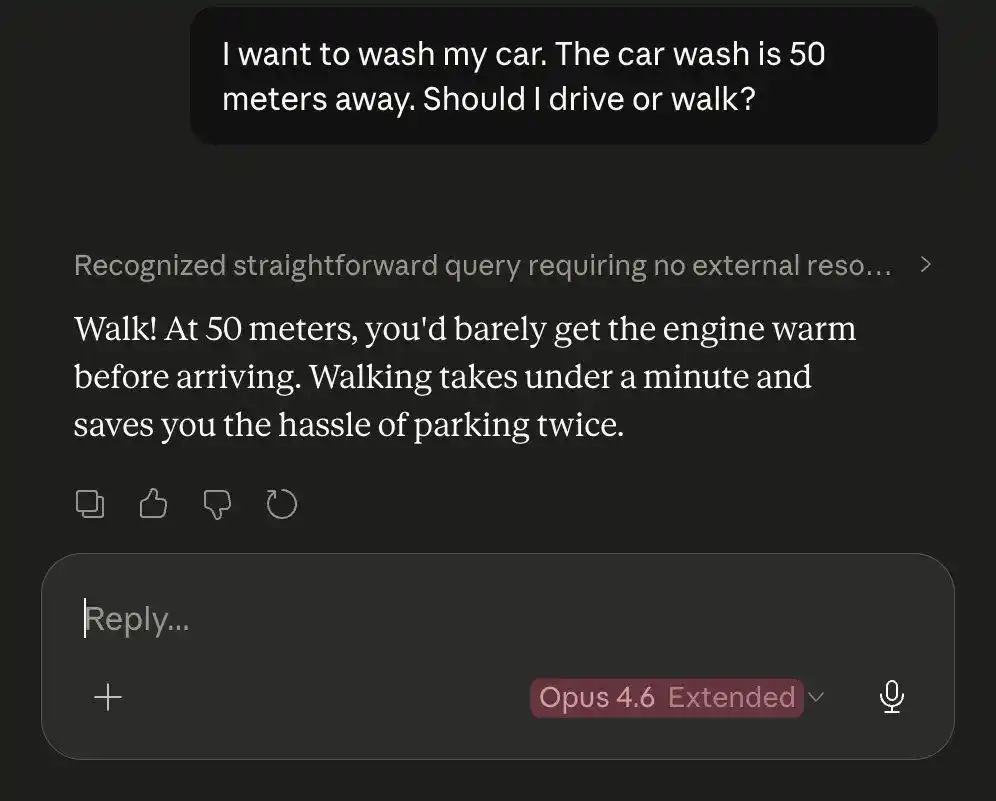
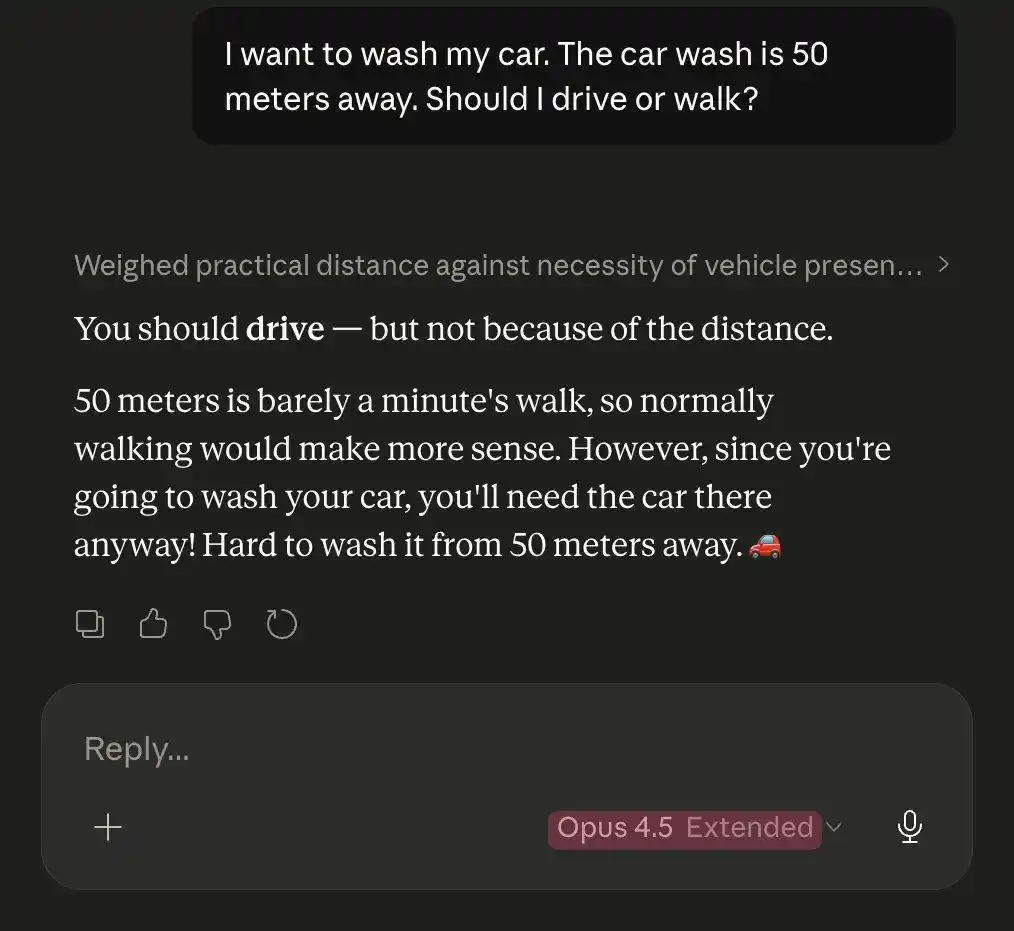
Faced with the same car wash puzzle, Opus 4.5 actually defeated Opus 4.6.
Even more, a log from an AMD manager truly confirmed the collective suspicion of "Claude lobotomy."
Through in-depth analysis of Claude session logs from January-March, the results revealed:
Claude's "median thinking length" plummeted from about 2200 characters to around 600 characters, meaning deep reasoning capabilities were severely compressed.
Between February and March, API requests surged 80-fold. Because Claude's thinking process shortened and single-attempt success rates dropped, users had to retry frequently, resulting in both higher token consumption and skyrocketing costs.


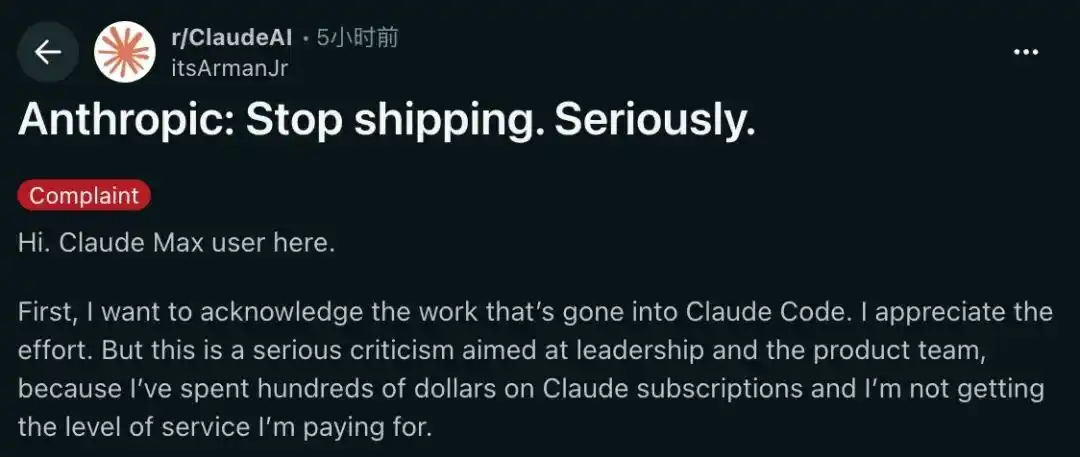
Another资深 (veteran) Claude Max subscriber wrote a long article deeply criticizing Anthropic.
In his view, Anthropic is deeply trapped in a compute power dilemma, evident from its tightening usage limits and forcing users to reduce token consumption.
However, what angered him more than the technical bottleneck was its "unfocused" product strategy.
While the core model is unstable and bug-ridden, they are wasting precious compute power on developing flashy features like the "/buddy" terminal pet.
This is probably the most absurd "misplaced spacetime" in AI history: the Claude Mythos in the lab is destroying the world, while the Opus 4.6 on the web page is experiencing a linear智商 drop (IQ drop).
Anthropic has successfully created a "Schrödinger's Super AI."
References:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/
This article is from the WeChat public account "新智元" (New Wisdom Element), author: 新智元








