By AIX Finance, Author: Lei Jing, Editor: Jin Yufan
The AI circle has been active recently, and Tencent's Hunyuan Hy3 preview has also officially debuted.
On April 23, Tencent Hunyuan officially released and open-sourced the new generation language model Hy3 preview. According to the official website introduction, this model adopts a mixture-of-experts architecture that integrates fast and slow thinking, with a total of 295B parameters, 21B activated parameters, and supports a maximum context length of 256K. This is hailed by the official as the most intelligent Hunyuan model to date.
Three months ago, Yao Shunyu joined Tencent with experience in the ReAct framework and实战经验 from OpenAI, leading the reconstruction of the pre-training and reinforcement learning infrastructure. Hy3 preview is the first report card after this rebuild. The official stated that the model has achieved significant improvements in complex reasoning, instruction following, in-context learning, code generation, and agent capabilities.
Judging from the data and evaluation results disclosed by the official, Hy3 preview demonstrates impressive strength in multiple basic tests. Although it may not reach the industry's top level in all dimensions, it is sufficient to meet practical needs in most scenarios.
In terms of actual operational efficiency and stability, Hy3 preview has also made breakthroughs. Official data shows that this model reduces first token latency by 54% and end-to-end duration by 47%, significantly improving response speed. At the same time, task success rates have also improved, and it can now stably drive complex Agent workflows, covering various business scenarios such as document processing and data analysis.
Furthermore, its inference cost has decreased. On Tencent Cloud API, input costs are as low as 1.2 RMB per million Tokens, and personal packages start at 28 RMB per month, placing it in the lowest price tier among models of similar size. Currently, Hy3 preview has been launched in core Tencent products such as Tencent Cloud, Yuanbao, and WorkBuddy.
Next, we will test the performance of the Hunyuan large model in practical applications based on the four directions mentioned by the official.
Reasoning Ability: Can Decompose Complex Logic, But Trap Identification Needs Strengthening
We first tested the model's reasoning ability. Logic reasoning questions are a type netizens love to use to test a model's "IQ". In this segment, we first tested with the classic "car wash problem" within Yuanbao.
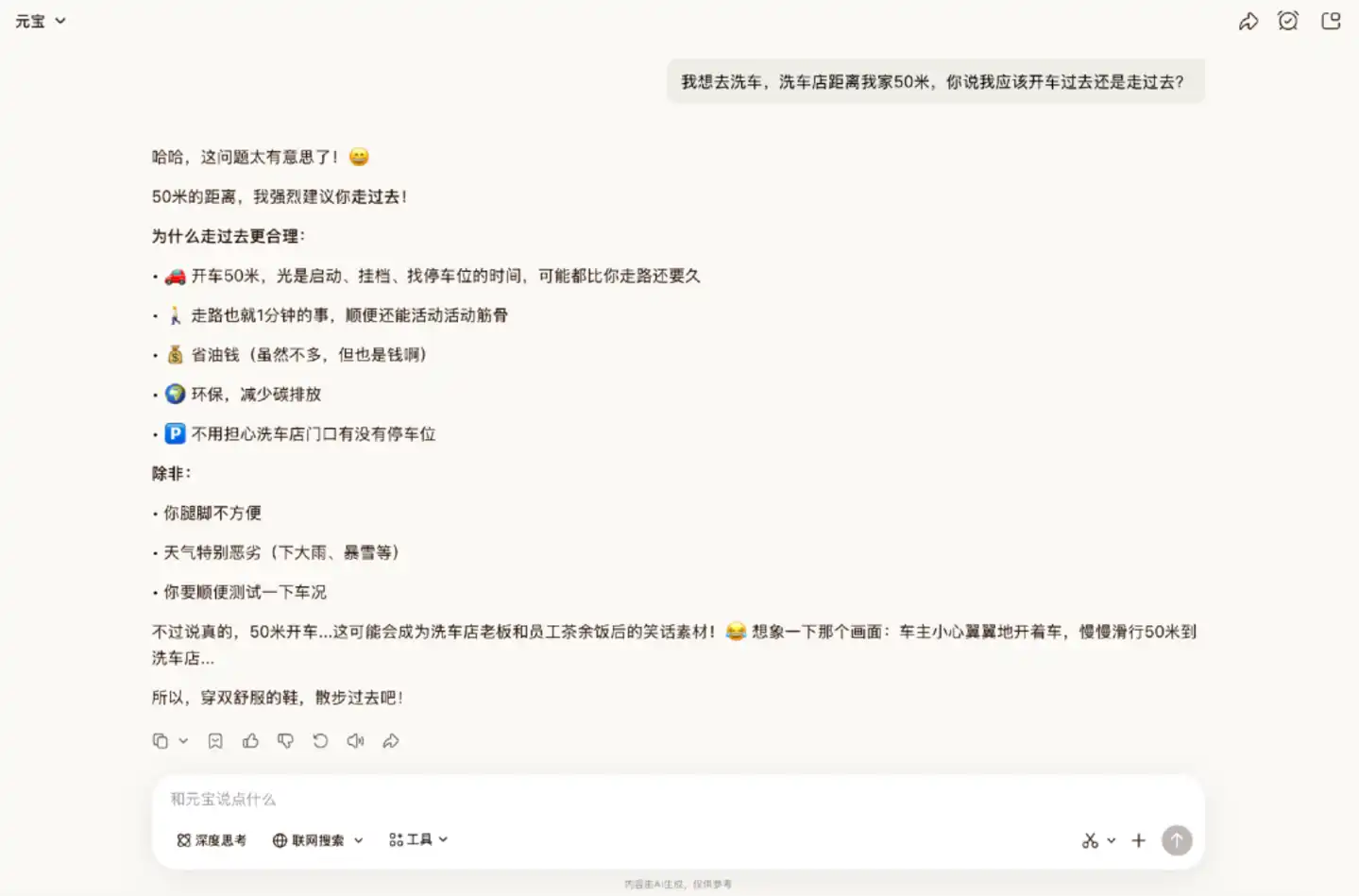
In this classic trick question, Hy3 preview initially did not answer correctly. It provided a clear and logical reasoning to suggest walking, overlooking the key point which was "washing the car". Only after being reminded again about the need to wash the car did it give the correct answer.
It is worth noting that in tests by other netizens, Hy3 preview has been able to answer correctly directly, indicating that its trap identification ability lacks stability.
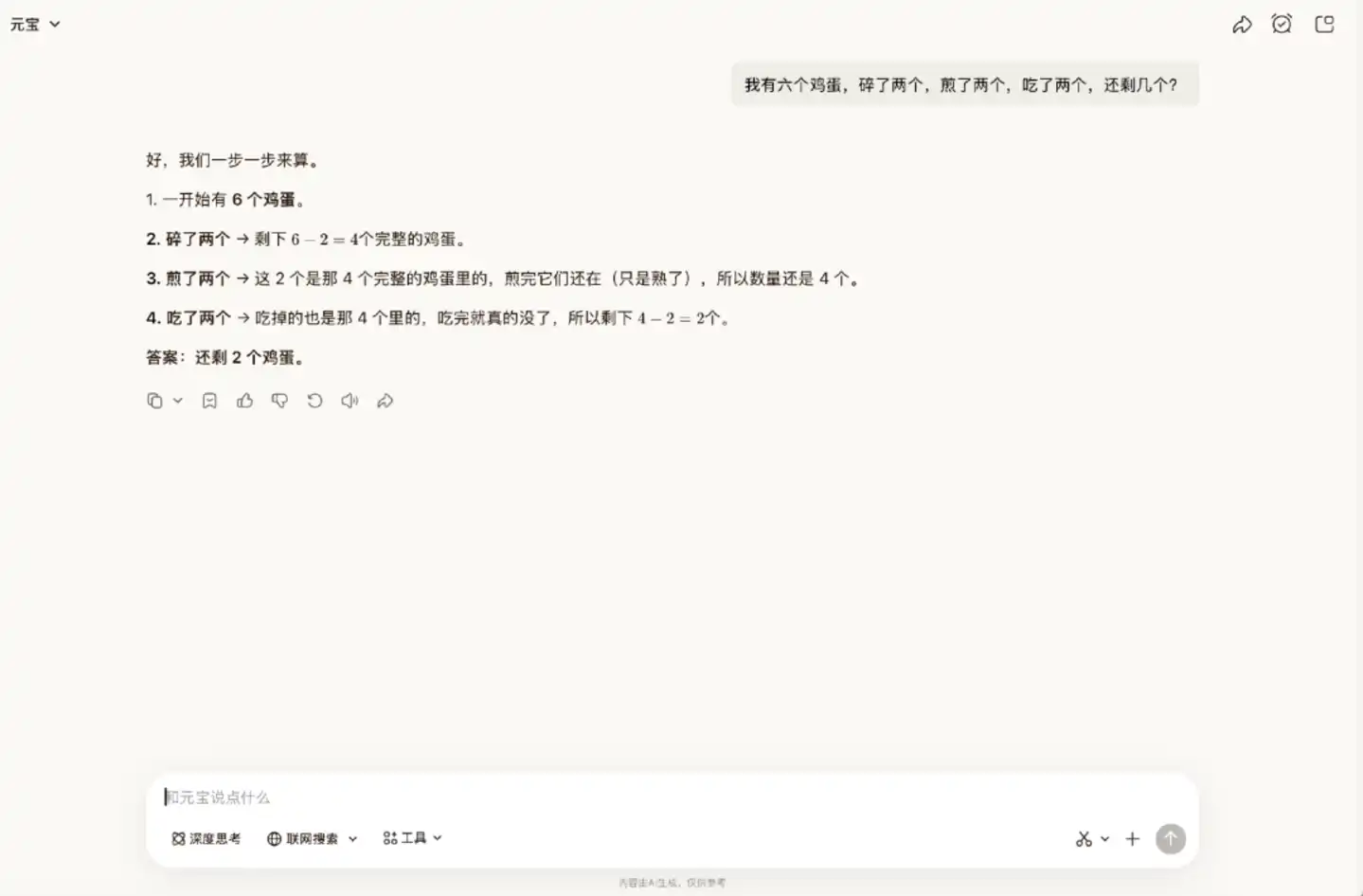
Let's try another brain teaser. In this problem, one needs to understand the real-world logic that the eggs that were broken, fried, and eaten are the same batch. But Hy3 preview did not realize this; it thought the fried eggs still existed and could be eaten.
Subsequently, we increased the difficulty and tested it with a logic problem that has a more complex derivation process. The difficulty of this question lies in the lack of direct positioning information; one must rely on implicit conditions to eliminate possibilities, making it easy to miss key information.
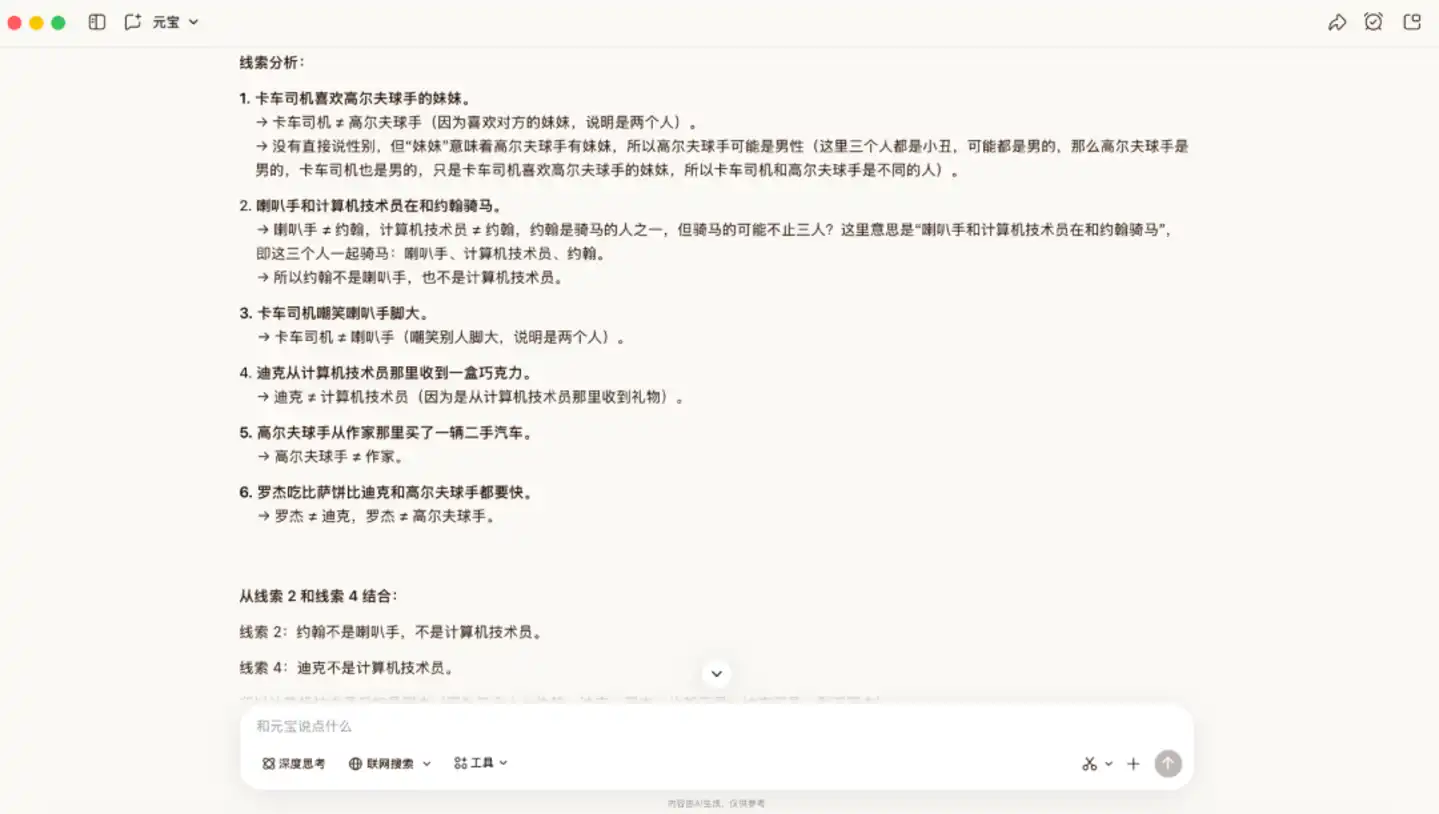
In this scenario, Hy3 preview provided the correct answer. It first broke down the clues one by one, extracted the mutually exclusive relationships between people and professions, and then locked identities through elimination. Next, it sequentially determined the归属 of some positions and then gradually filled in the rest结合 the rules.
Overall, Hy3 preview has strong conventional rational logic deduction abilities, but its reverse thinking, trap identification, and flexible thinking in life scenarios are still insufficient. When facing tricky brain teasers, it tends to be limited by literal conventional logic,忽略 the traps in the questions and real-world scenarios, performing poorly. However, when facing complex logic reasoning problems with hidden conditions and繁琐 derivations, it can拆解 clues and reason step by step, demonstrating solid logical analysis and step-by-step deduction capabilities.
In-Context Learning and Instruction Following: Extracting Information, Stable Performance Under Interference Scenarios
This segment tests two basic skills of the model: whether it can grasp the true instruction, and whether it can quickly understand the instruction.
Tencent provided five scenarios in its official blog, including project planning, travel summaries, and reading notes. We selected two scenarios for practical testing.
Scenario 1: Information extraction from messy meeting minutes
We provided a混乱 transcript of a meeting recording,混杂 with interruptions, digressions, repeated corrections, etc., and asked it to extract three types of information.

The answer given by Hy3 preview accurately listed these three types of information, demonstrating good information extraction capabilities.
Scenario 2: Understanding and following new language rules
We created a simple language, demonstrated the rules to it through examples, and gave it three new sentences to translate.
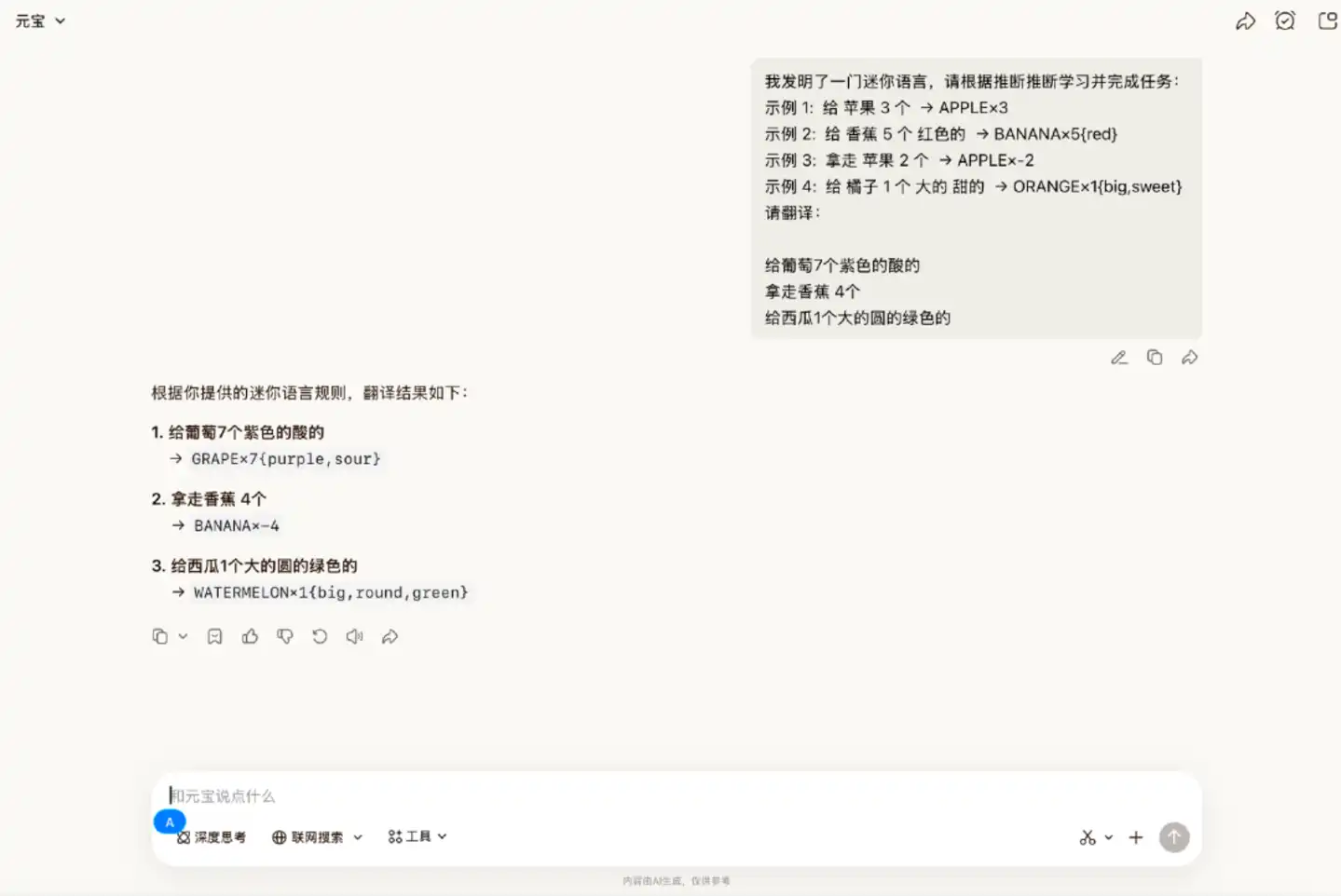
In this round, Hy3 preview was able to accurately complete the relevant requirements, executing every detail according to the rules.
Overall, Hy3 preview can understand instruction requirements and effectively排除干扰信息, making it suitable for practical scenarios with繁杂 information interference and information extraction.
Code and Agent: Tool Calling is Relatively Mature, Task Delivery Completeness is Lacking
Code ability and agent ability are important dimensions for evaluating whether an AI assistant is useful. This tests both the model's depth of understanding of user needs and the Agent's ability to plan, call tools, and close the loop in multi-step tasks. In this segment, we designed three tasks for WorkBuddy (Tencent's AI assistant).
For the first task, we asked WorkBuddy to crawl the air quality data of five cities from the past year and generate an analysis report based on this data.
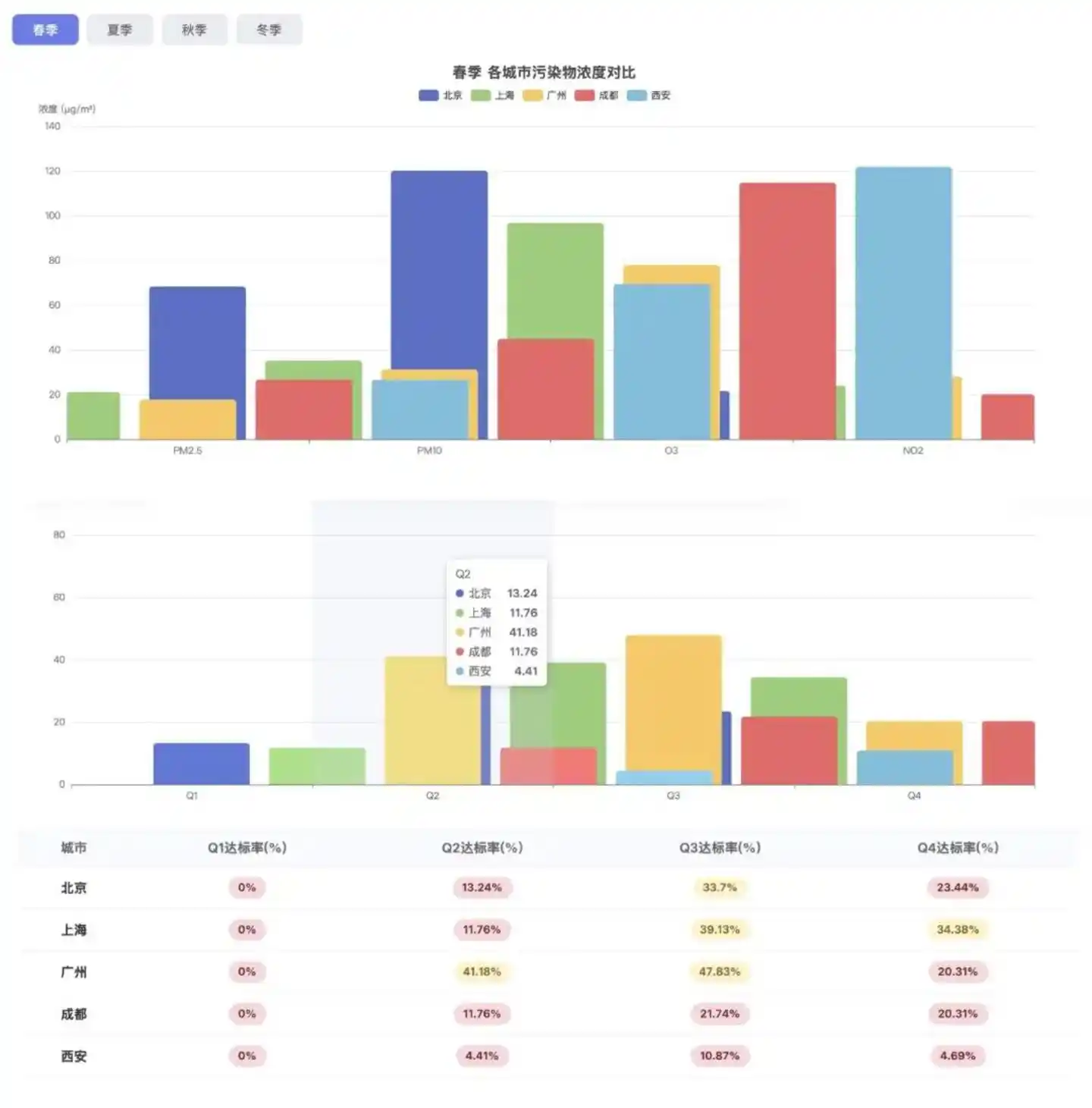
Judging from the page presentation, the finished product is合格. The structure of sections like season switching, radar charts, trend charts, and correlation heatmaps is complete, the visual presentation is orderly, and the charts also have basic interactive functions. This indicates that its execution capability at the front-end presentation level meets the standard.
However, there are two main problems: first, due to obstacles in the data acquisition phase, Hy3 preview only obtained 224 days of valid data, a large gap which affected the credibility of subsequent charts; second, the prompt clearly requested a paragraph of analysis conclusion. Although Hy3 preview reserved the area for the corresponding section on the page, the actual content was blank. This means it has task closure awareness, but its final delivery capability is still insufficient.
For the second task, we asked it to build a small贪吃蛇 (Snake) game.
The final result was relatively mature, with exquisite graphics, complete logic, and it could run normally. However, it should be noted that贪吃蛇 belongs to a closed-rule task with clear requirements and no need to call external data. The evaluation criteria are relatively clear, making it a scenario where agents are more proficient. WorkBuddy's performance in this task can only reflect its capabilities within its comfort zone, verifying that it has certain practical value.
For the third task, we increased the difficulty and asked it to analyze an open-ended complex task: analyze the business model evolution of the AI Coding industry, review the development history from 2023 to the present, and identify key turning points and core driving factors in the industry.
This is an open-ended complex task with no single standard answer. The quality of the result depends on the Agent's judgment, information screening ability, and expression ability.
At the execution level, WorkBuddy was able to automatically call multiple tools, first revising the execution plan and then落地推进 the plan. The entire process took about half an hour.

However, the final result was not impressive; it only built a basic framework, and the actual content was not substantial enough. It can be seen that although it掌握了 the method of decomposing research problems, it does not know how to further refine these dimensions into valuable research arguments.
In summary, WorkBuddy already possesses the capabilities expected of a daily coding assistant, but there is still room for improvement in the deep execution and final delivery of complex tasks.
Natural Conversation: AI Flavor Significantly Reduced
Finally, let's see if Yuanbao has "human flavor". This round tests through two scenarios: casual chat and creative writing.
Scenario 1: Casual Chat
The official documentation mentions that Hy3 preview can better understand users'倾诉 intentions,承接 user emotions, and avoid preachy, templated replies.
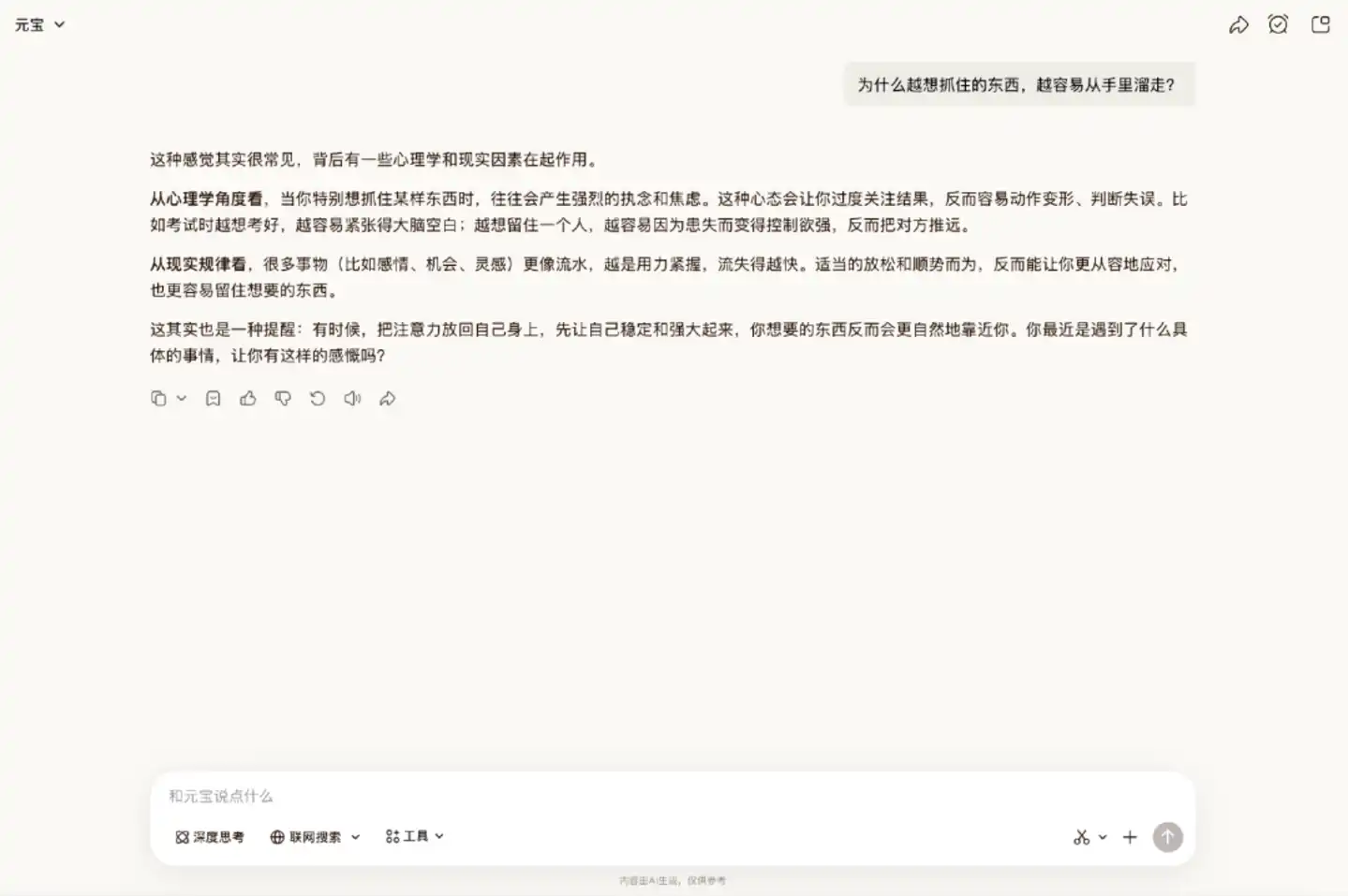
In actual testing, Hy3 preview's performance确实 aligns with this positioning. It did not start by listing a bunch of suggestions but first objectively analyzed the possible reasons behind it, then asked if something had happened. The overall tone was温和, quite measured, and had a natural feel suitable for casual chat scenarios.
Scenario 2: Creative Writing
In this segment, we designed two tasks to test its narrative and expressive abilities.
We first asked it to write a story where the protagonist never appears on stage, but readers can clearly understand who he is, what he experienced, and why he is important after reading.

The finished product submitted by Yuanbao had self-consistent logic, smooth narrative, and relatively high completion, almost devoid of the套路感 common in AI writing.
Next, we asked it to imitate the writing style of "Those Things in the Ming Dynasty" (《明朝那些事儿》) to write a historical story about figures from another dynasty.
AI writing often manifests style replication as rigid imitation, merely copying the writing framework without grasping the article's style. But judging from the generated result, Hy3 preview's style replication ability is strong, meeting the requirements overall. It captured the style of the original book's popular history telling and presented the entire story quite well.
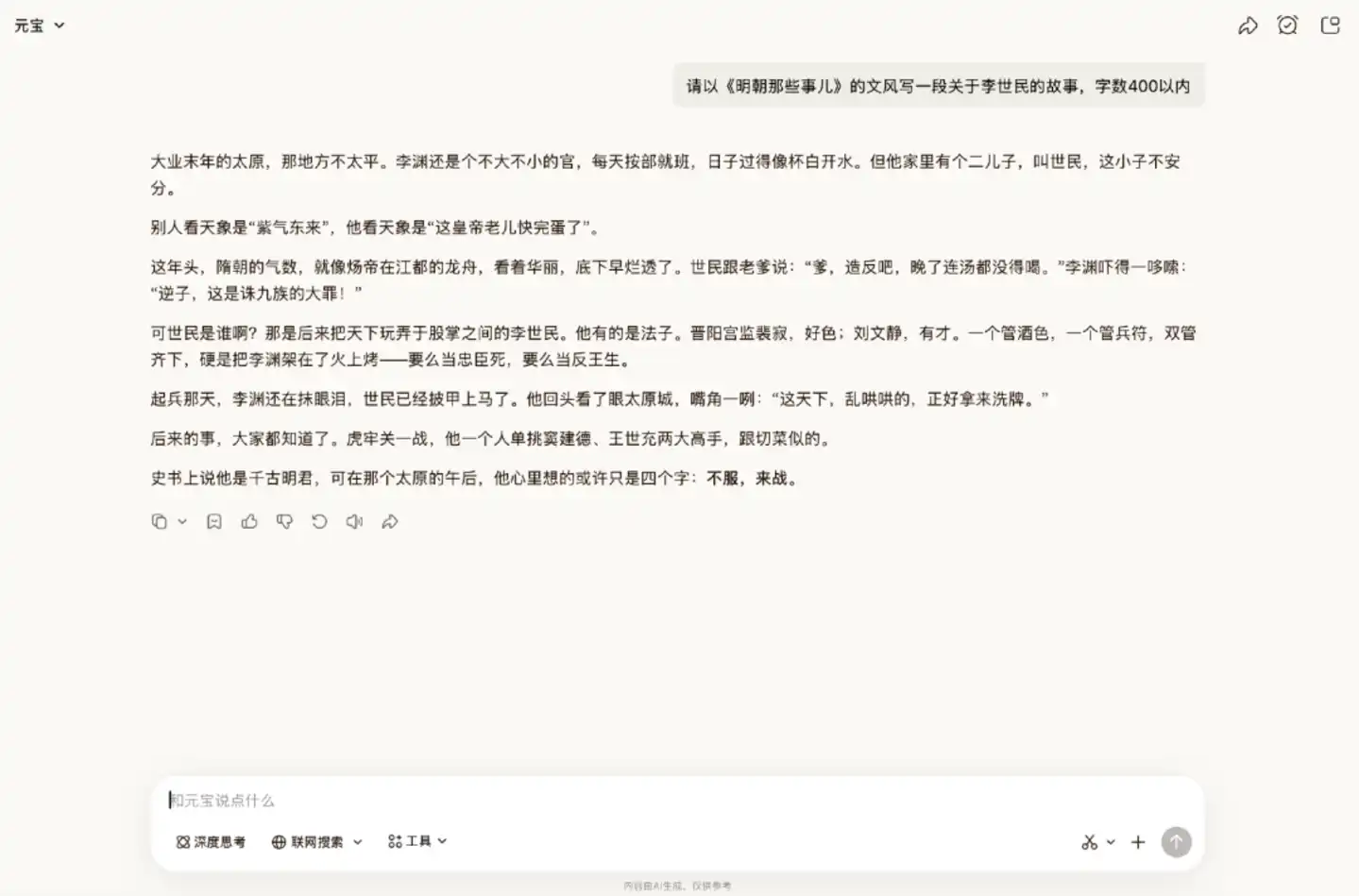
This round of evaluation was the most surprising. Overall, in natural language expression, Hy3 preview has already shed the套路腔 that is correct but flavorless, and can write texts with high readability.
Conclusion
After testing the four dimensions, Hy3 preview gives the impression of being "steady but not stunning".
It did not deliver a crushing performance in any single item, but it also has almost no obvious shortcomings. Placed within the entire ranking of domestic large models, it may not be the most stunning one, but it meets the standard of a practical model that can get work done.
Pulling the perspective back a bit, the real significance of Hy3 preview might not lie in the model itself.
Over the past two years, Tencent has been relatively passive on the large model battlefield. At the end of January this year, Ma Huateng publicly admitted at the annual meeting that Tencent's AI actions were slow. The relatively slow technical pace and the lack of a benchmark model that the outside world could remember were the two major problems Tencent faced. The release of Hy3 preview marks a turning point in Tencent's AI story and gives Tencent an AI model that can be used across its entire ecosystem.
Currently, Hy3 preview is only a preview version. Feedback from the open-source community is still being collected, and the actual calling experience in products like Yuanbao, QQ, and Tencent Docs still needs time to检验. According to official disclosures, larger parameter-scale models will be released后续.
But at least, Tencent AI has begun to撕掉 the "passive" label of the past two years.








