Hiện tại, hệ thống trí nhớ của ChatGPT giống con người hơn.
OpenAI gần đây đã ra mắt một hệ thống trí nhớ hoàn toàn mới, nền tảng dựa trên công nghệ Dreaming.
Nó sẽ tự động sắp xếp sở thích, dự án, thiết bị, kế hoạch du lịch và sắp xếp cuộc sống của bạn trong các cuộc trò chuyện dài hạn, đồng thời đánh giá thông tin nào vẫn hữu ích, thông tin nào đã lỗi thời khi trả lời.

Tuy nhiên, lần cập nhật này sẽ được mở trước cho người dùng Plus và Pro tại Mỹ, vài tuần tới sẽ mở rộng sang nhiều quốc gia hơn, và dần dần sẽ bao phủ người dùng Free và Go.
Không bắt đầu từ con số không, hệ thống trí nhớ hoàn toàn mới của ChatGPT ra mắt
Trên thực tế, vào tháng 4 năm 2024, ChatGPT đã từng ra mắt tính năng trí nhớ, nhưng khi đó hình thức chủ yếu là "lưu trí nhớ", ví dụ người dùng có thể yêu cầu rõ ràng ChatGPT ghi nhớ một số thông tin, như kế hoạch du lịch, sở thích ăn uống, tên hoặc yêu cầu công việc.
Cơ chế ban đầu giống một ghi chú cá nhân hơn. Người dùng nói đủ rõ ràng, hệ thống sẽ lưu lại và tham khảo trong các cuộc trò chuyện sau đó. Nhưng trong sử dụng thực tế, nhiều thông tin quan trọng không xuất hiện theo cách "vui lòng nhớ".
Người dùng có thể chỉ đề cập đến thiết bị của mình trong một lần tư vấn, nói ra sở thích chỗ ở khi lên kế hoạch du lịch, tiết lộ bối cảnh dự án trong một cuộc thảo luận công việc. Phiên bản cũ khó ổn định bắt được những ngữ cảnh tự nhiên rải rác này.
Hơn nữa, vị trí của con người sẽ thay đổi, kế hoạch sẽ kết thúc, dự án sẽ tiến triển, sở thích cũng có thể điều chỉnh. Trí nhớ tĩnh nếu lâu ngày không cập nhật, cá nhân hóa ngược lại có thể trở thành sai lệch. Ví dụ người dùng từng nói sẽ đi Singapore, thông tin này rất hữu ích trước chuyến đi; sau khi chuyến đi kết thúc, nếu hệ thống vẫn gợi ý đồ ăn giao tận nhà theo Singapore, sẽ là sai.
Để giải quyết những vấn đề này, làm cho trí nhớ có thể cập nhật theo thời gian và phản ánh chính xác hơn nhu cầu thực tế của người dùng, OpenAI vào tháng 4 năm 2025 đã giới thiệu Dreaming thế hệ đầu tiên, cố gắng để ChatGPT tham khảo lịch sử trò chuyện ở chế độ nền, tự động sắp xếp thông tin hữu ích trong nhiều cuộc trò chuyện và tổng hợp thành trạng thái trí nhớ mới.
Một năm qua, Dreaming và lưu trí nhớ cùng nhau nâng cao khả năng cá nhân hóa, nhưng phiên bản đầu còn chưa đủ để tự mình hỗ trợ hoàn toàn hệ thống trí nhớ.
Phiên bản mới được xây dựng trên Dreaming, mục tiêu là đồng thời giải quyết ba vấn đề: tiếp nối bối cảnh hữu ích, tuân theo sở thích người dùng, duy trì tính chính xác theo thời gian.
OpenAI trong blog chính thức đã đưa ra vài ví dụ. Người dùng nếu trước đó đã thảo luận về thiết bị chụp ảnh, sau đó hỏi về phụ kiện chụp ảnh dưới nước, ChatGPT có thể kết hợp cụ thể máy ảnh, vỏ bảo vệ và đèn flash để đưa ra đề xuất tương thích, thay vì chỉ đưa danh sách chung chung.
Người dùng nếu lên kế hoạch du lịch Singapore, hệ thống cũng có thể kết hợp sở thích chụp ảnh động vật hoang dã đã đề cập trước đây, nhu cầu máy lạnh khách sạn và thói quen ăn uống yên tĩnh, đưa ra lịch trình phù hợp cá nhân hơn.
Người dùng từng đi du lịch ở một địa điểm nào đó, hệ thống còn phải biết đây có thể chỉ là trạng thái tạm thời, không thể mấy tháng sau vẫn coi đó là vị trí hiện tại.
Dữ liệu đánh giá nội bộ cũng phản ánh sự thay đổi này.
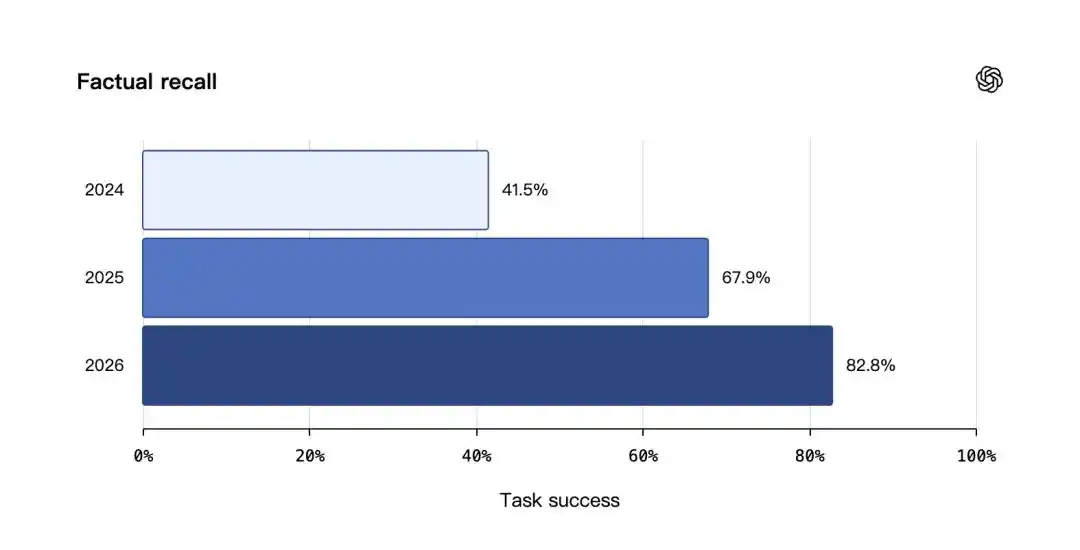
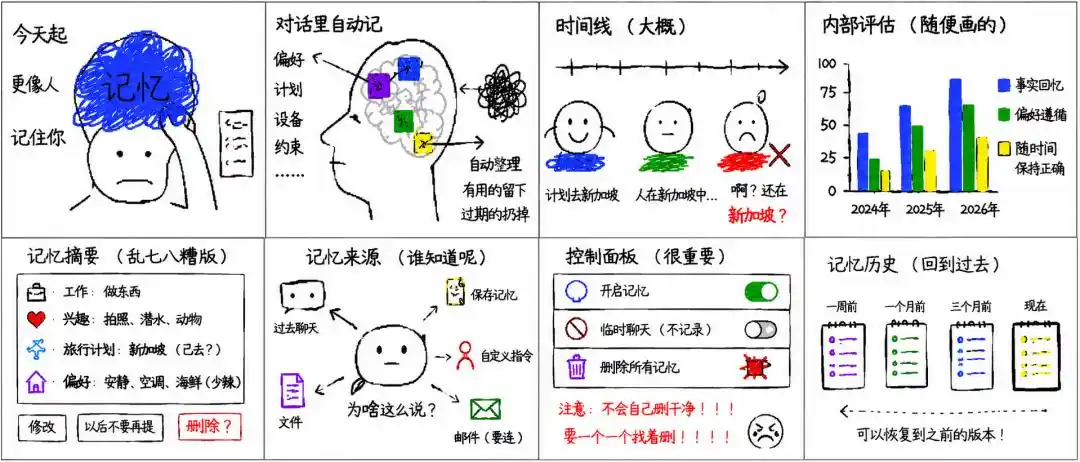
Trong bài kiểm tra hồi tưởng sự thật, tỷ lệ thành công nhiệm vụ của hệ thống lưu trí nhớ (Saved memories) năm 2024 là 41.5%, năm 2025 lưu trí nhớ cộng Dreaming V0 là 67.9%, năm 2026 Dreaming V3 đạt 82.8%.
Trong bài kiểm tra tuân theo sở thích, ba mức lần lượt là 31.4%, 55.3% và 71.3%.
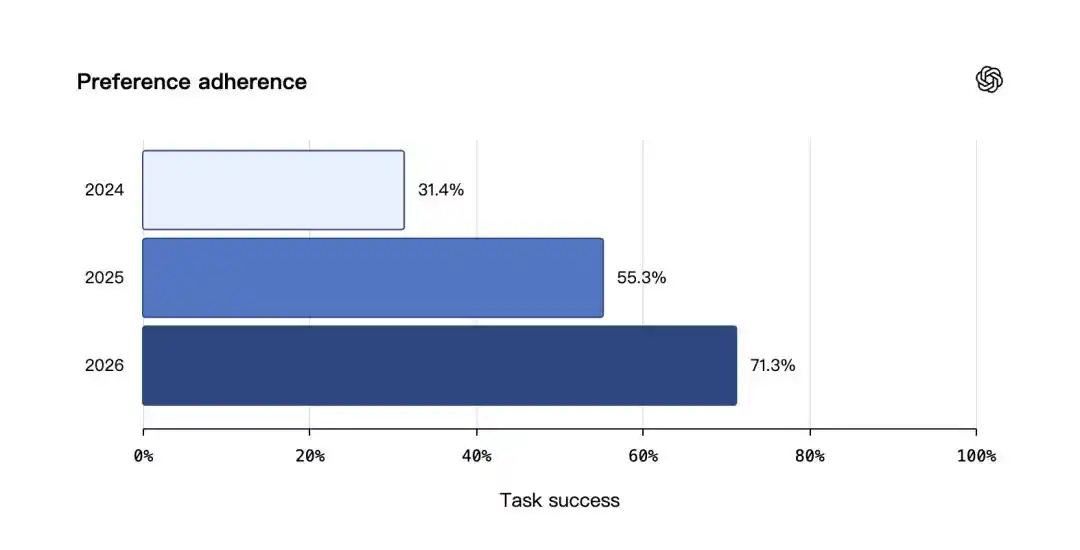
Trong bài kiểm tra duy trì tính chính xác theo thời gian, cải thiện rõ rệt hơn, năm 2024 là 9.4%, năm 2025 là 52.2%, năm 2026 đạt 75.1%.
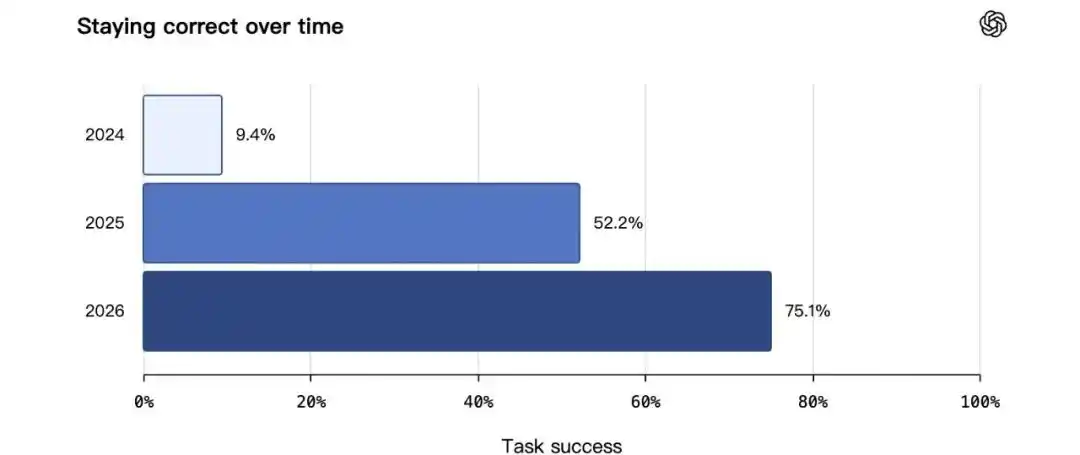
Những dữ liệu này cho thấy, điều OpenAI muốn ChatGPT ghi nhớ, không chỉ là nhiều thông tin hơn. Điều thực sự quan trọng là, hệ thống phải biết thông tin nào vẫn còn mới mẻ, thông tin nào đã hết hiệu lực, thông tin nào phù hợp đưa vào câu trả lời hiện tại.
Đích đến của trợ lý cá nhân, là trở thành một "bạn" khác
Thay đổi rõ rệt nhất về mặt sản phẩm, là bổ sung "Tóm tắt Trí nhớ".
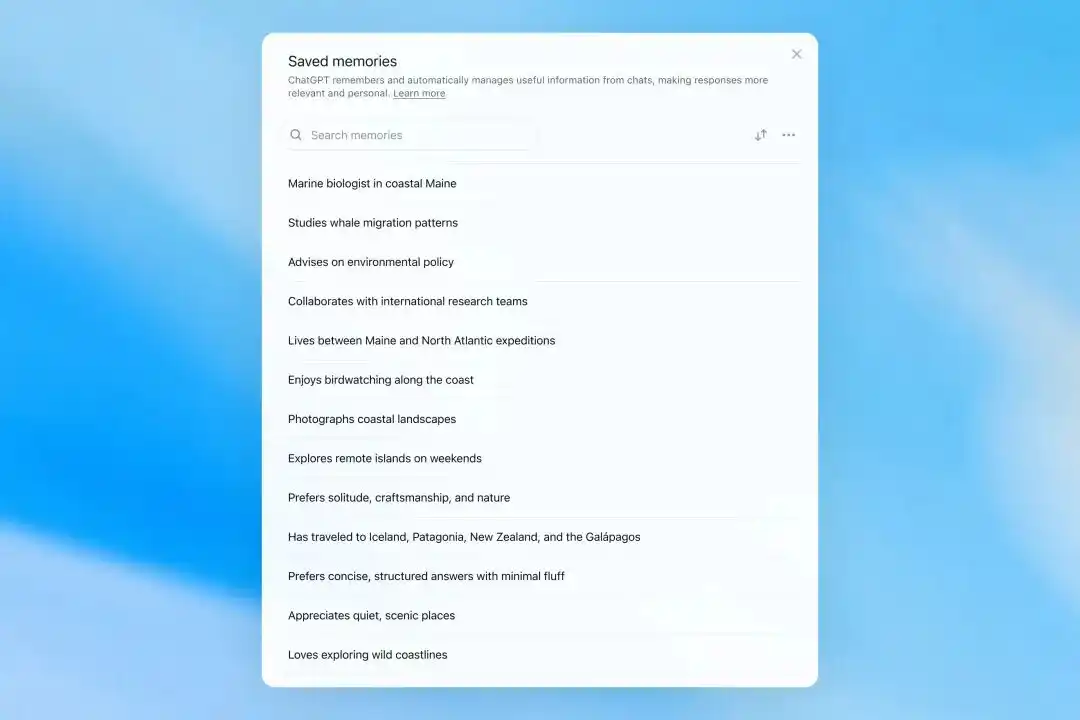
OpenAI cho biết, trí nhớ được tổng hợp bởi Dreaming có thể xem qua trang Tóm tắt Trí nhớ. Người dùng có thể xem thông tin cá nhân mà ChatGPT cho là quan trọng, bao gồm công việc, sở thích, kế hoạch du lịch, dự án dài hạn và sở thích trả lời, cũng có thể thêm hoặc sửa thông tin trong phần tóm tắt.
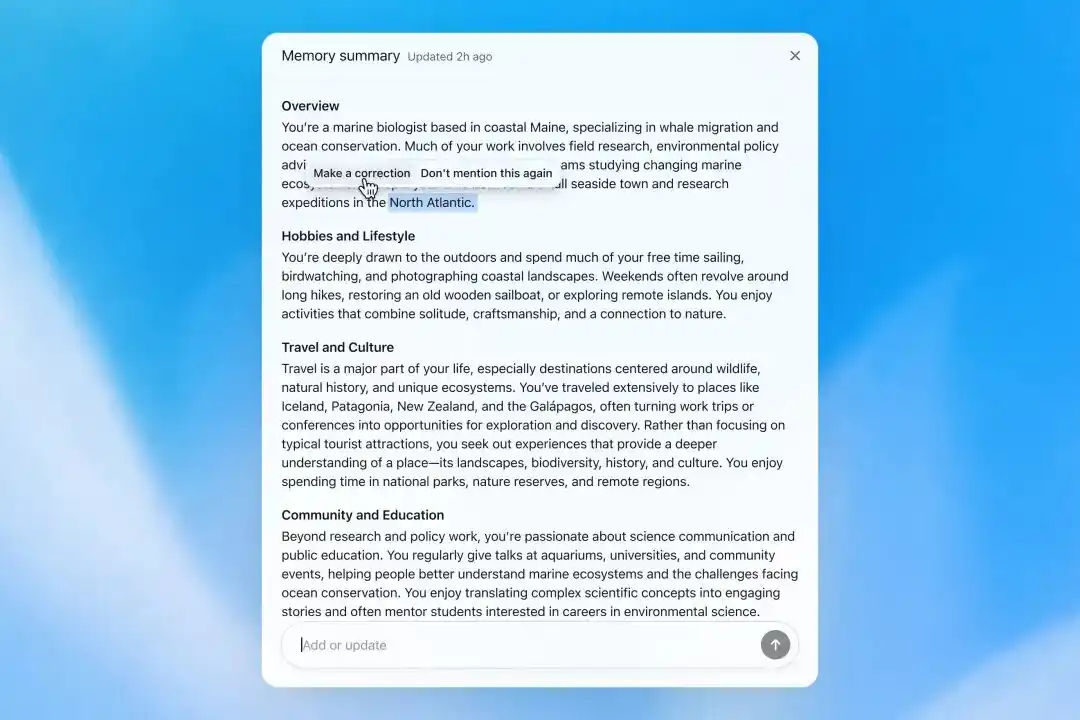
Tóm tắt Trí nhớ sẽ tự động cập nhật và hiển thị thời gian cập nhật gần nhất.
Người dùng có thể trực tiếp nhập yêu cầu chỉnh sửa, cũng có thể chọn văn bản cụ thể để sửa chữa, hoặc chọn "sau này đừng nhắc nữa". Tuy nhiên, OpenAI nhấn mạnh, thao tác loại này chỉ giảm việc chủ động đề cập trong tương lai, không bằng việc xóa hoàn toàn thông tin liên quan.
Nếu người dùng muốn loại bỏ hoàn toàn một mục thông tin nào đó, cần xóa tất cả nguồn có thể, bao gồm lưu trí nhớ, trò chuyện trước đây, trò chuyện lưu trữ, tệp đã tải lên, tóm tắt trí nhớ, cũng như nội dung liên quan trong ứng dụng đã kết nối.
Đương nhiên, nếu bạn cảm thấy bản tóm tắt tự động mới không đủ kiểm soát, OpenAI vẫn giữ lại hệ thống "Saved memories" phiên bản cũ cho người dùng Plus và Pro trên web.
Như thường lệ, thông tin liên quan hơn, thường được đề cập hơn sẽ được đặt ở phía trước, nội dung không quan trọng bằng sẽ chuyển vào hậu trường, để giảm tình trạng dung lượng trí nhớ bị chiếm đầy. Khi đánh giá mức độ ưu tiên, hệ thống sẽ tham khảo độ mới cũ của thông tin, cũng như tần suất người dùng nói đến chủ đề liên quan.
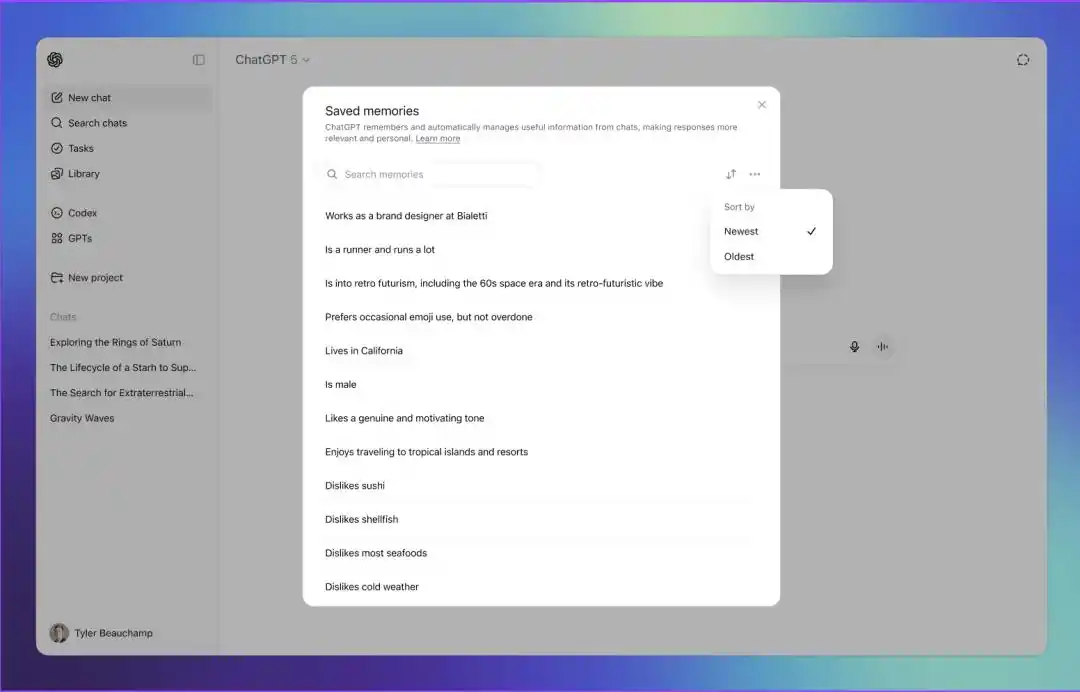
Người dùng cũng có thể can thiệp thủ công. Trong trang Saved memories, có thể tìm kiếm trí nhớ, sắp xếp theo mới nhất hoặc cũ nhất, cũng có thể tăng hoặc giảm mức độ ưu tiên cho một ký ức đơn lẻ. Ký ức ở hậu trường sẽ hiển thị màu xám. Người dùng còn có thể xóa một ký ức nào đó, hoặc xóa toàn bộ ký ức một lần.
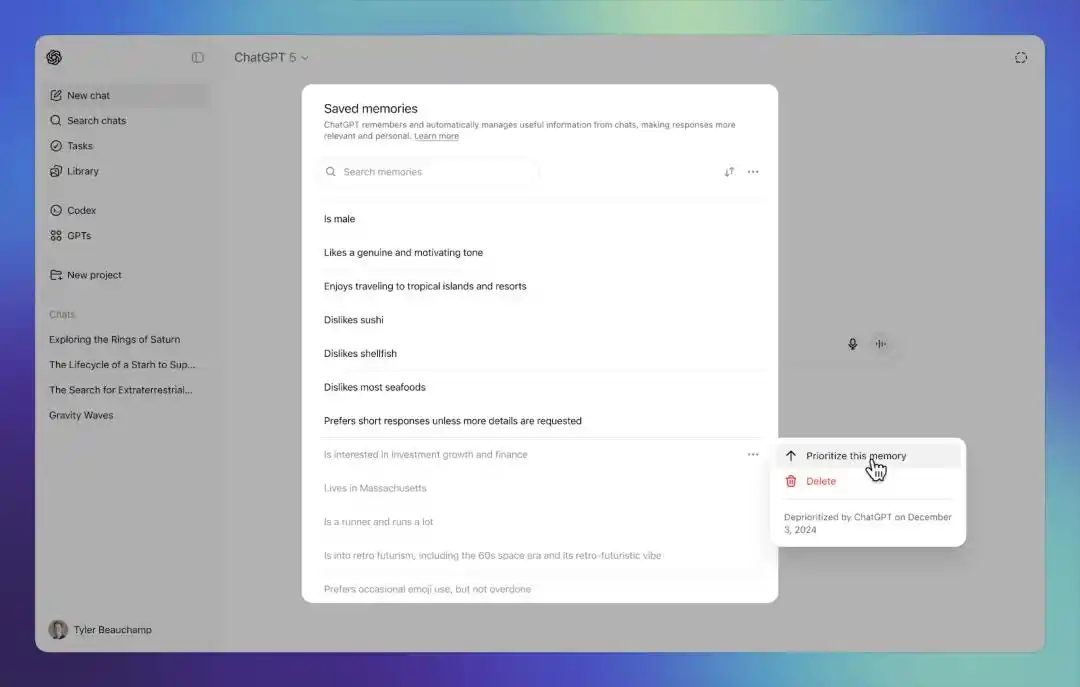
Ngoài ra, OpenAI còn cung cấp tính năng lịch sử trí nhớ. Người dùng có thể xem các phiên bản saved memories tại các thời điểm khác nhau, và khôi phục về một phiên bản trước đó. Điều này có nghĩa là, khi trí nhớ bắt đầu tự động cập nhật, người dùng ít nhất vẫn có thể thấy nó thay đổi thế nào, và kéo hệ thống trở lại trạng thái trong quá khứ.
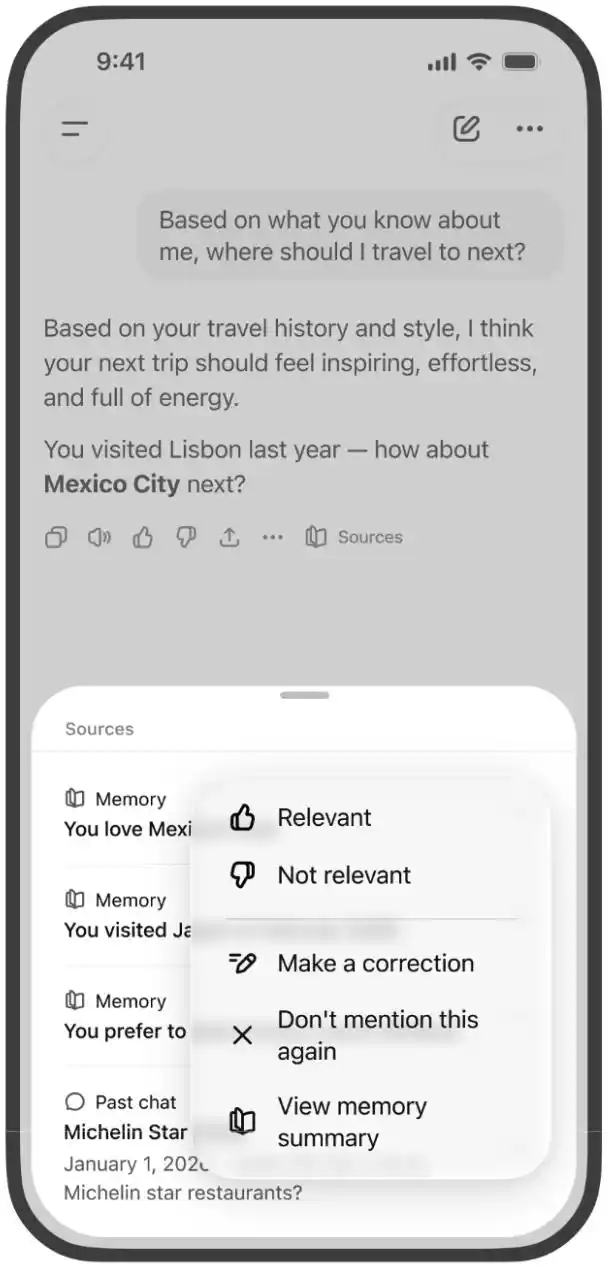
OpenAI còn thêm tính năng "Nguồn Trí nhớ".
Người dùng có thể xem những nguồn nào tham gia vào câu trả lời cá nhân hóa thông qua biểu tượng quyển sách bên dưới câu trả lời. Nguồn có thể bao gồm trò chuyện trước đây, lưu trí nhớ, hướng dẫn tùy chỉnh, tệp và Gmail. Việc hiển thị nguồn sẽ không liệt kê tất cả các yếu tố ảnh hưởng, nhưng có thể giúp người dùng hiểu rõ hơn tại sao ChatGPT đưa ra một câu trả lời cá nhân hóa nào đó.
Phạm vi nguồn có thể sử dụng của các gói dịch vụ khác nhau không giống nhau.
Người dùng Free và Go có thể sử dụng trò chuyện trước đây, lưu trí nhớ và hướng dẫn tùy chỉnh. Người dùng Plus và Pro ở một số khu vực còn có thể sử dụng thư viện tệp và Gmail. Gmail cần người dùng chủ động kết nối, sau khi kết nối có thể sử dụng để nhận diện email xác nhận du lịch, chuỗi dự án hoặc bối cảnh lịch trình. Đáng chú ý là nguồn từ tệp và Gmail không khả dụng tại Khu vực Kinh tế Châu Âu, Thụy Sĩ và Anh.
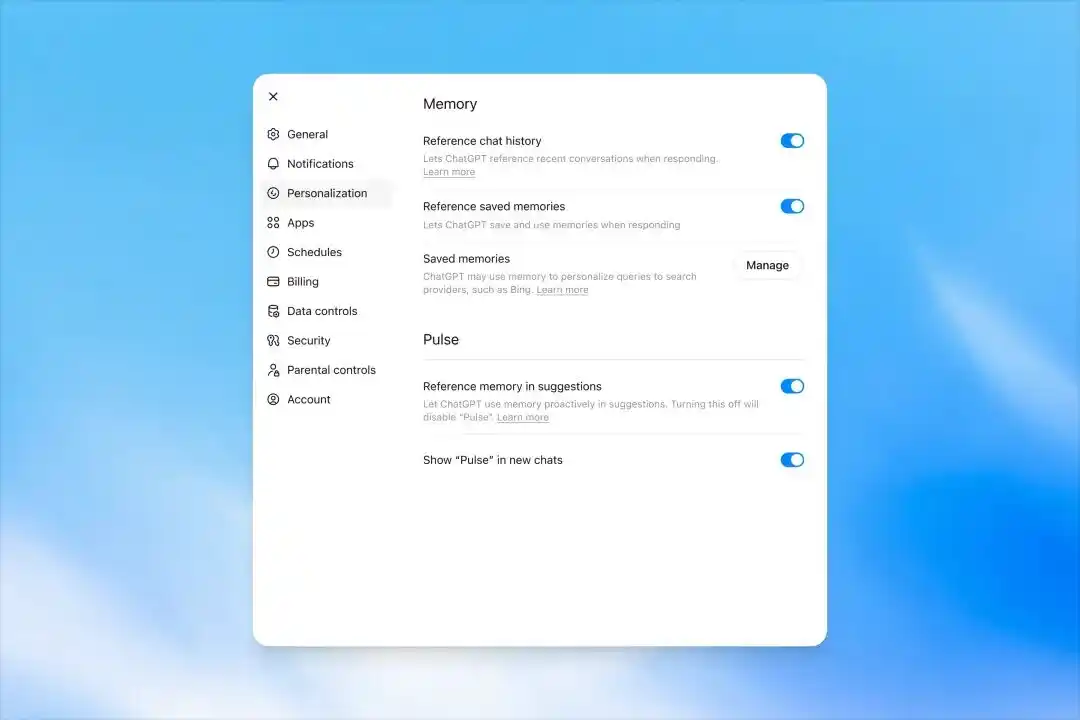
Kiểm soát trí nhớ vẫn ở trang Memory trong cài đặt.
Người dùng có thể bật hoặc tắt trí nhớ, cũng có thể sử dụng trò chuyện tạm thời. Trò chuyện tạm thời sẽ không sử dụng trí nhớ đã có, cũng không tạo trí nhớ mới.
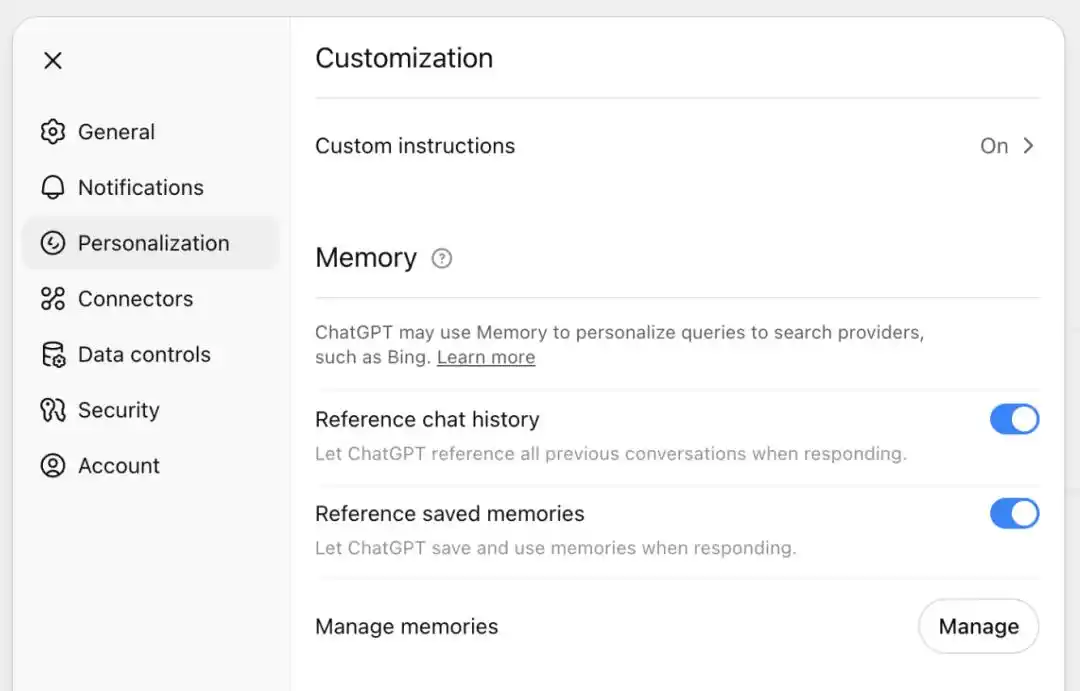
Tắt lưu trí nhớ sẽ không tự động xóa nội dung đã lưu, xóa trò chuyện cũng không tự động xóa lưu trí nhớ được tạo từ trò chuyện. Người dùng cần xóa riêng ký ức liên quan, hoặc yêu cầu ChatGPT quên.
Vấn đề riêng tư theo đó trở nên quan trọng hơn.
OpenAI thừa nhận, thông tin nhạy cảm người dùng chia sẻ trong trò chuyện có thể xuất hiện trong trí nhớ. Người dùng nếu không muốn nội dung liên quan được sử dụng cho câu trả lời cá nhân hóa trong tương lai, có thể tắt trí nhớ, sử dụng trò chuyện tạm thời, xóa trò chuyện liên quan, xóa tệp, hoặc ngắt kết nối ứng dụng đã kết nối.
Về mặt huấn luyện mô hình, nếu người dùng bật "Cải thiện mô hình cho mọi người", trò chuyện trước đây, lưu trí nhớ và nội dung trí nhớ liên quan có thể được sử dụng để cải thiện mô hình. Nội dung của khách hàng ChatGPT Business, Enterprise và Edu mặc định sẽ không được dùng để huấn luyện.
Về mặt triển khai, OpenAI cho biết những cải tiến gần đây làm giảm tài nguyên tính toán cần thiết cho Dreaming khoảng 5 lần, do đó OpenAI hiện cũng bắt đầu cung cấp phiên bản đáp ứng yêu cầu chất lượng cho người dùng Free, đồng thời tăng dung lượng trí nhớ cho người dùng Plus và Pro.

Đối với OpenAI, trí nhớ là bước then chốt để ChatGPT đi từ mô hình trở thành trợ lý.
Một trợ lý thực sự, không thể mỗi lần đều bắt đầu từ con số không. Nó phải biết người dùng đang làm gì, có thói quen diễn đạt thế nào, kế hoạch nào đã kết thúc, sở thích nào vẫn còn hiệu lực. Nếu không, cái gọi là cá nhân hóa sẽ chỉ là một bộ câu trả lời chung chung lịch sự hơn.
Nhưng trí nhớ cũng sẽ thay đổi mối quan hệ giữa người dùng và sản phẩm.
Khi ChatGPT bắt đầu ghi nhớ dự án, chuyến đi, tệp, email và những ràng buộc cuộc sống của bạn, nó không còn chỉ là một cửa sổ trò chuyện. Nó sẽ ngày càng giống một giao diện cá nhân tồn tại lâu dài, giúp bạn gọi thông tin, sắp xếp nhiệm vụ, giải thích thế giới, đồng thời vô hình tích lũy sự hiểu biết về bạn.
Ý nghĩa nào đó, trí nhớ là lễ trưởng thành của trợ lý AI.
Điều này cũng khiến người ta liên tưởng đến mệnh đề kinh điển mà loạt phim "Blade Runner" liên tục đặt câu hỏi: Liệu ký ức (dù thật hay cấy ghép) có đủ để định nghĩa nhân tính, cấu thành sự tự nhận thức, và có thể dùng làm tiêu chuẩn phân biệt con người và người nhân bản hay không.
Và hệ thống trí nhớ ChatGPT công bố hôm nay, đưa ra câu hỏi tương tự: Khi một AI lưu giữ lâu dài trải nghiệm, sở thích và cách phán đoán của bạn, liệu nó có dần dần trở thành cái tôi bên ngoài của bạn?
Tận cùng của trợ lý AI, có thể là một phiên bản chính mình có thể chỉnh sửa.
Kèm theo liên kết tham khảo:
1. https://openai.com/index/chatgpt-memory-dreaming/
2. https://help.openai.com/en/articles/8590148-memory-faq
Bài viết này đến từ tài khoản công chúng WeChat "爱范儿", tác giả: 爱范儿 phát hiện sản phẩm ngày mai





