Tác giả: Matt White, Giám đốc Công nghệ AI Toàn cầu của Linux Foundation
Biên dịch: Felix, PANews

Vương Hưng Hưng (CEO Công ty Khoa học Công nghệ Unitree) và Matt White
Vài tuần trước tại Thượng Hải, một người bạn cùng du lịch (thông minh, thường xem tin tức và quan sát, nhưng không quá hiểu về công nghệ robot) đã hỏi một câu hỏi mà tôi luôn mong đợi trong suốt chuyến đi vào bữa tối.
“Những chú chó robot chạy lung tung chúng ta thấy, những robot hình người biểu diễn kungfu trên sân khấu demo tại văn phòng Unitree, và cánh tay robot gấp quần áo chúng ta thấy. Chúng hoạt động như thế nào? Chúng được điều khiển bởi Mô hình Ngôn ngữ Lớn (LLM) phải không? Nó thực sự hoạt động ra sao? Có phải có một mô hình ngôn ngữ nào đó đang điều khiển hành động của chúng?”
Đây là một câu hỏi hay, và thành thật mà nói: ở một mức độ nào đó là đúng, nhưng câu chuyện thực tế thú vị hơn nhiều. Những robot bạn thấy trên mạng xã hội không phải là ChatGPT bên trong vỏ kim loại. Chúng chạy một ngăn xếp công nghệ (nhiều lớp AI phối hợp hoạt động). Ngăn xếp này đã thay đổi nhiều hơn trong ba năm qua so với ba mươi năm trước đó. Mô hình ngôn ngữ là một phần của nó. Mô hình thị giác, mô hình hành động, cây hành vi, vòng lặp điều khiển cổ điển, và một họ hệ thống mới nổi có tên “Mô hình Thế giới” cũng là những phần quan trọng. Và “Mô hình Thế giới” có lẽ là phát triển quan trọng nhất trong tất cả.
Đây là một bài viết dài, sẽ bắt đầu từ đầu, sau đó lần lượt kể về từng sự thay đổi lớn, cuối cùng đến giai đoạn hiện tại: robot không chỉ có thể phản ứng với thế giới, mà còn có thể tưởng tượng về nó.
Một: Thời kỳ trước LLM: Khi robot chỉ là phần mềm
Trong nhiều thập kỷ, chế tạo robot có nghĩa là viết rất nhiều mã, và hầu như tất cả mã đó đều không cần học.
Robot công nghiệp cổ điển là một cấu trúc tháp được xếp chồng bởi các mô-đun được thiết kế tỉ mỉ. Ví dụ như cánh tay robot màu cam hàn khung gầm Toyota những năm 90, hay BigDog của Boston Dynamics đầu những năm 2000.
- Nhận thức: Lọc cảnh từ camera, phát hiện biên, sử dụng khớp nối hình học để xác định vị trí chi tiết.
- Ước tính trạng thái: Kết hợp bộ mã hóa bánh xe, con quay hồi chuyển và gia tốc kế (tổng hợp cảm biến) để xác định vị trí và tốc độ di chuyển của robot.
- Lập kế hoạch: Với tư thế mục tiêu cho trước, sử dụng các thuật toán như A* hoặc RRT để tính toán một đường dẫn không va chạm trong bản đồ đã biết.
- Điều khiển: Ở tầng dưới cùng, bộ điều khiển PID điều chỉnh mô-men xoắn động cơ hàng trăm đến hàng nghìn lần mỗi giây để tuân theo đường dẫn đó.
Những lớp này thường được viết bởi những người khác nhau từ các phòng thí nghiệm khác nhau, và được ghép nối một cách cực kỳ tỉ mỉ. Hành vi (ví dụ: “nếu cốc màu đỏ thì nhặt lên, nếu không thì chờ”) được mã hóa thành máy trạng thái hoặc cây hành vi: một sơ đồ luồng mà robot thực hiện từng bước.
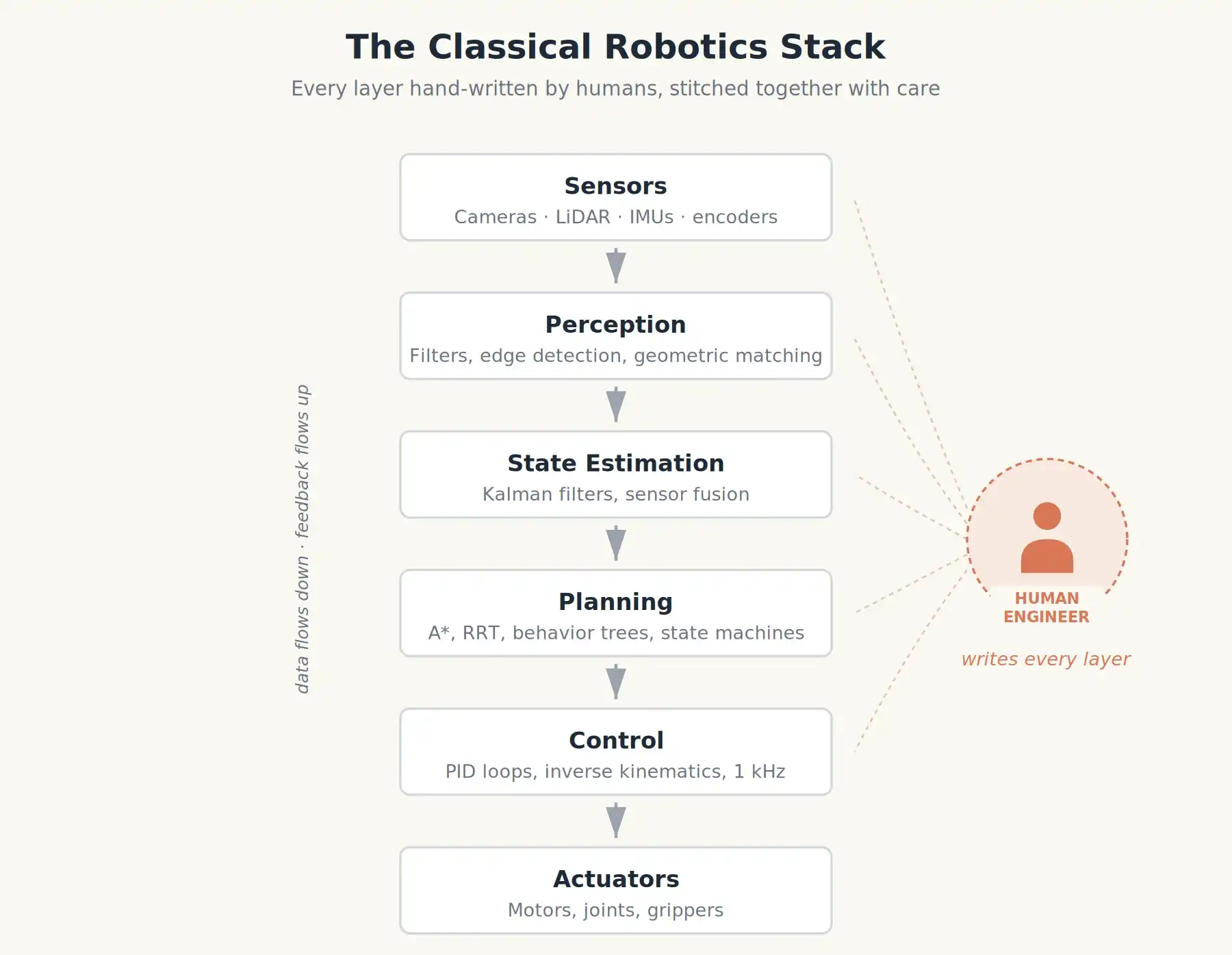
Ưu điểm của phương pháp này rõ ràng. Nó có thể dự đoán được, đáp ứng tiêu chuẩn an toàn. Đó là lý do tại sao xe hơi của bạn có hệ thống phanh ABS hiệu quả.
Nhược điểm cũng rõ ràng. Robot như vậy chỉ có thể hoạt động thông minh trong các kịch bản mà kỹ sư đã hình dung trước. Đặt nó vào một nhà máy mới, điều kiện ánh sáng mới hay màu cốc mới, nó sẽ gặp sự cố. Khả năng tổng quát hóa của nó gần như bằng không.
Hai: Học Máy len lỏi vào
Vào những năm 2010, học sâu bắt đầu giải quyết vấn đề ở lớp nhận thức. Những mạng nơ-ron tích chập (CNN) đánh bại con người trong nhiệm vụ phân loại hình ảnh ImageNet, có thể được đào tạo lại để phát hiện điểm cầm nắm trên vật thể, phân đoạn đồ đạc trong phòng, hoặc nhận diện tư thế con người. Đột nhiên, lớp “Nhận thức” ở đỉnh ngăn xếp không cần thiết kế thủ công nữa, bạn có thể trực tiếp đào tạo nó.
Sau đó, cơ chế học lan xuống lớp “Điều khiển”. Các nhà nghiên cứu từ UC Berkeley, DeepMind và OpenAI đã chỉ ra rằng, học tăng cường (để tác nhân robot thử nghiệm hàng triệu lần trong môi trường mô phỏng và củng cố các hành vi hiệu quả) có thể tạo ra dáng đi khéo léo đáng ngạc nhiên, thao tác vật thể bằng tay (OpenAI giải khối Rubik bằng một tay năm 2019 là một cột mốc), và chiến lược di chuyển thích ứng với các địa hình khác nhau.
Một hướng nghiên cứu song song khác là học bắt chước, thường được gọi là nhân bản hành vi: ghi lại hàng trăm lần thử nghiệm của con người điều khiển từ xa robot hoàn thành một nhiệm vụ, sau đó đào tạo mạng nơ-ron để dự đoán hành động mà con người sẽ thực hiện dựa trên những gì robot quan sát được.
Điều mấu chốt là: mỗi chiến lược học được đều quá hẹp. Đào tạo một mạng để nhặt một khối màu đỏ, nó sẽ không biết phải xử lý một cái cốc màu vàng như thế nào. Đào tạo nó đi trên cỏ, nó sẽ ngã trên sàn gạch. Khả năng tổng quát hóa vẫn là vấn đề chưa được giải quyết.
Điều đáng chú ý trong thời kỳ này là sự xuất hiện của một nền tảng kiến trúc, đến nay vẫn hỗ trợ hầu hết mọi thứ: ROS, Hệ điều hành Robot (ra mắt lần đầu tháng 11/2007). ROS không phải là hệ điều hành theo nghĩa Windows hay Linux, mà là một khung middleware, một hệ thống đường ống chung cho robot. Nó cho phép “nút camera”, “nút điều hướng”, “nút điều khiển cánh tay robot” và hàng chục nút khác xuất bản và đăng ký thông điệp thông qua một bus chia sẻ.
Phiên bản hiện tại ROS2 chạy ở nền tảng của phần lớn robot nghiên cứu và thương mại trên toàn cầu, từ phòng thí nghiệm Stanford đến các công ty khởi nghiệp robot hình người ở Trung Quốc. Khi người ta nói về “hệ điều hành” của robot, hầu như luôn ám chỉ ROS2 cộng với các gói phần mềm nhận thức, lập kế hoạch và điều khiển chạy trên nó.
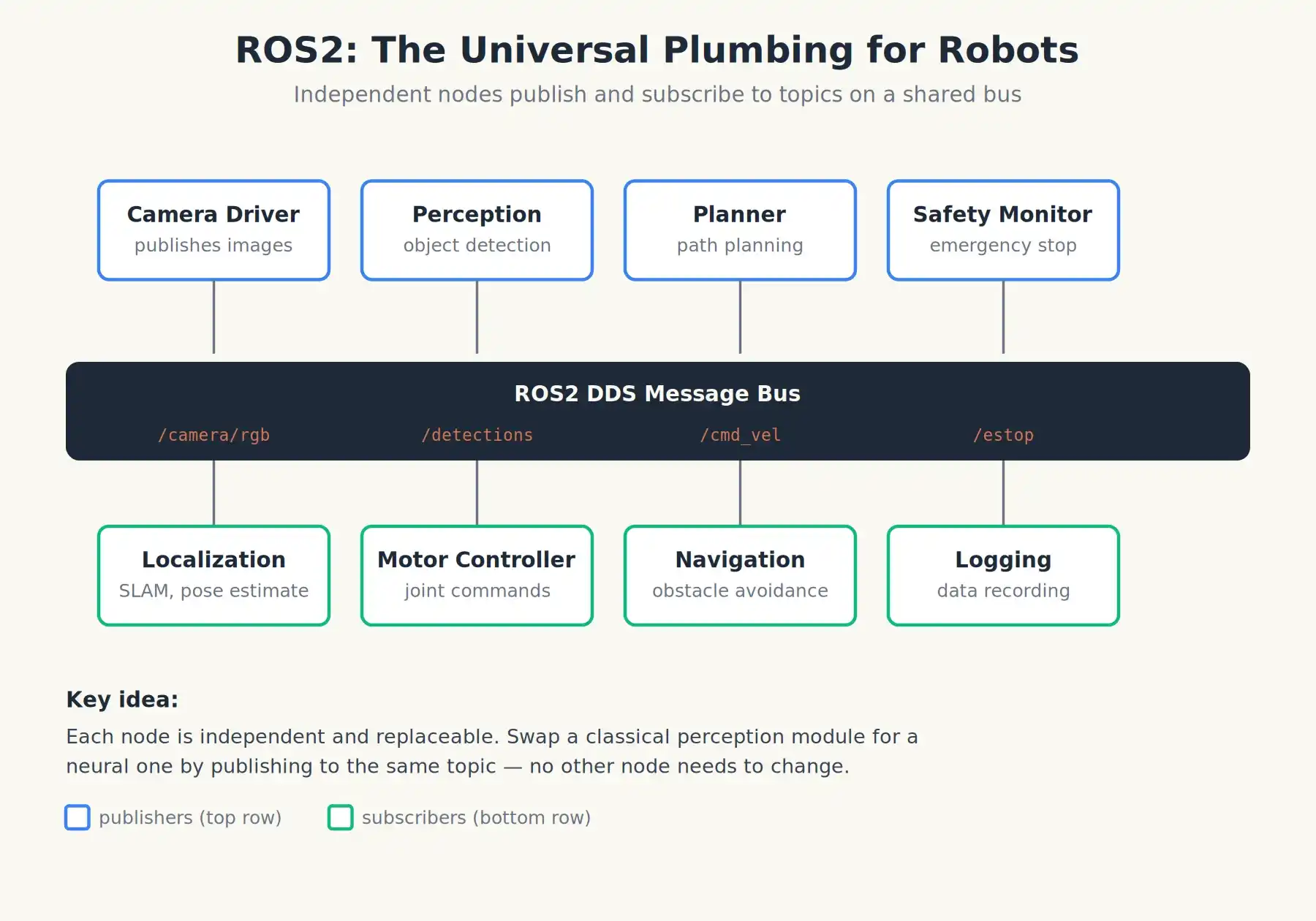
ROS2: Nó không phải là hệ điều hành, mà là đường ống chung để các phần mềm robot độc lập giao tiếp với nhau
Ba: Ứng dụng LLM vào Robot
Rồi ChatGPT ra đời.
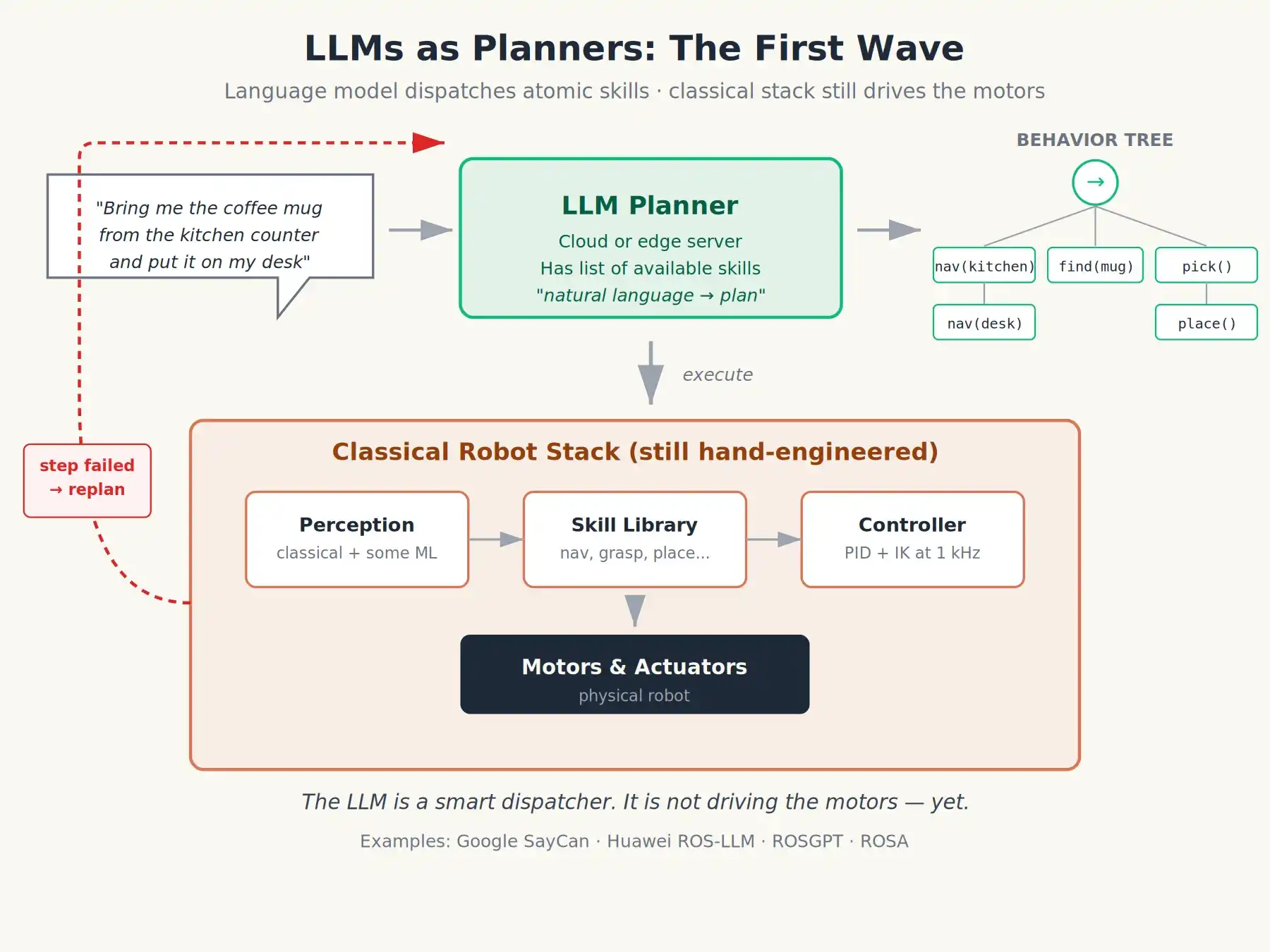
Đột nhiên có một thứ như vậy: LLM. Nó có thể đọc hướng dẫn tiếng Anh đơn giản, suy luận nhiều bước, viết mã và gọi hàm. Các chuyên gia robot gần như ngay lập tức nhận ra, đây chính là mảnh ghép còn thiếu mà họ đã cố gắng giải quyết trong nhiều năm. Phần khó nhất để robot thực hiện một nhiệm vụ hữu ích trong nhà hoặc văn phòng thường không phải là điều khiển động cơ, mà là tương tác giữa người và máy: làm thế nào con người nói cho robot biết phải làm gì, và robot làm thế nào phân rã mục tiêu đó thành các hành động nguyên tử mà nó đã biết cách thực hiện?
Làn sóng công việc đầu tiên áp dụng LLM vào robot là coi mô hình ngôn ngữ như một trình biên dịch ngôn ngữ tự nhiên nằm trên ROS. Mô hình như sau:
-
Người dùng nói bằng tiếng Anh: “Lấy cốc cà phê trên mặt bếp và đặt lên bàn của tôi.”
-
LLM tạo kế hoạch dựa trên danh sách kỹ năng nguyên tử khả dụng của robot: có thể là chuỗi lệnh gọi hàm, máy trạng thái, hoặc cây hành vi viết bằng XML.
-
Nút ROS2 sẽ thực hiện kế hoạch đó từng bước. Nếu một bước thất bại, nó sẽ báo cáo thông tin thất bại cho LLM để LLM lập kế hoạch lại.
Dự án SayCan của Google năm 2022 là một phiên bản rất gọn gàng của ý tưởng này: LLM đề xuất kỹ năng, một mô hình “khả dụng” độc lập đánh giá khả năng thành công hiện tại của mỗi kỹ năng, robot chọn tổ hợp kỹ năng có điểm kết hợp cao nhất. Các khung mã nguồn mở như ROS-LLM, ROSGPT và ROSA (do phòng nghiên cứu Huawei dẫn đầu) đã phổ biến hóa mô hình này.
Đây quả thực là một bước nhảy vọt có ý nghĩa. Đột nhiên, bạn có thể nói với robot “dọn dẹp bàn, bỏ đồ tái chế vào thùng màu xanh”, và nó sẽ thử thực hiện một số hành động hợp lý. Nhưng hãy lưu ý, vẫn còn tồn tại những vấn đề: mô hình ngôn ngữ vẫn ở lớp lập kế hoạch. Lệnh hành động thực tế vẫn được tạo ra bởi các bộ điều khiển được thiết kế tỉ mỉ hoặc được đào tạo chuyên biệt ở tầng dưới. Mô hình ngôn ngữ chỉ là một bộ lập lịch thông minh, nó không phụ trách việc điều khiển.
Bốn: Mô hình Thị giác-Ngôn ngữ-Hành động (VLA), khi bộ não bắt đầu điều khiển robot

Robot Keenon XMAN-R1 đang lấy thuốc từ kệ tại nhà thuốc tự động Galbot ở Bắc Kinh. Chỉ với 100.000 USD
Bước nhảy tiếp theo khó khăn hơn và cũng quan trọng hơn. Các nhà nghiên cứu đặt ra một câu hỏi đầy tham vọng hơn: Nếu mô hình không chỉ lập kế hoạch, mà còn có thể trực tiếp tạo ra lệnh hành động thì sao? Nếu đưa trực tiếp hình ảnh camera và lệnh ngôn ngữ vào một mạng nơ-ron, và sau đó nhận được chuyển động khớp cho mili giây tiếp theo?
Đây chính là Mô hình Thị giác-Ngôn ngữ-Hành động (VLA). Hiện nay nó là mô hình chủ đạo trong lĩnh vực robot hình người và robot bốn chân.
Mô hình ngôn ngữ thị giác robot được biết đến rộng rãi đầu tiên là RT-2 của Google DeepMind ra mắt năm 2023. Điểm tinh tế của nó là: sử dụng một mô hình ngôn ngữ thị giác lớn (đã được đào tạo để mô tả hình ảnh và trả lời câu hỏi), và tiếp tục đào tạo nó bằng dữ liệu minh họa robot, nhưng coi hành động robot như một loại token khác cần dự đoán. Cùng một mạng nơ-ron vốn có thể xuất ra “con mèo đang ngồi trên tấm thảm”, giờ có thể xuất ra một chuỗi token mã hóa “di chuyển chân phải về phía trước 3 cm, khép móng vuốt, nâng lên 5 cm”. Lập luận và hành động được hoàn thành trong cùng một mô hình.
Sau đó, vào giữa năm 2024, một nhóm do Stanford dẫn đầu đã phát hành OpenVLA, một mô hình VLA mã nguồn mở 7 tỷ tham số, được đào tạo dựa trên tập dữ liệu Open X-Embodiment. Tập dữ liệu này tổng hợp hơn một triệu đoạn đào tạo từ 21 phòng thí nghiệm nghiên cứu khác nhau, bao gồm 22 loại hình thân robot khác nhau. Đây là lần đầu tiên những người ngoài Google có thể tải xuống mô hình robot tổng quát và bắt đầu sửa đổi. Nó đã thay đổi toàn bộ lĩnh vực chỉ sau một đêm.
Ngày nay, các VLA hàng đầu tuy không nhiều nhưng đang phát triển nhanh:
- π0 và π0.5 từ Physical Intelligence: Khả năng thích ứng nhiệm vụ xuất sắc.
- NVIDIA Isaac GR00T N1.7: Trọng số mở, cấp phép thương mại, thiết kế chuyên biệt cho robot hình người, là mô hình mà hầu hết các công ty phần cứng Trung Quốc hiện đang sử dụng dữ liệu riêng của họ để đào tạo tiếp.
- Helix của Figure AI và Helix-02 mới hơn: Công nghệ độc quyền, nhưng quan trọng về kiến trúc.
- Genie Envisioner của AgiBot: Nền tảng dựa trên Mô hình Thế giới của Trung Quốc.
- SmolVLA, NORA, ACoT-VLA, CogACT: Ngày càng có nhiều VLA từ giới học thuật, khám phá các hướng thiết kế khác nhau.
Cách thức hoạt động của VLA (không liên quan đến công thức toán học)
Có thể tưởng tượng VLA giống như hợp nhất ba luồng tín hiệu đầu vào thành một luồng đầu ra.
Luồng dữ liệu đầu tiên là dữ liệu thị giác. Camera RGB (đôi khi là cảm biến độ sâu hoặc lidar), đôi khi là cảm biến xúc giác trên đầu ngón tay, được xử lý bởi bộ mã hóa thị giác (thường là mô hình Transformer như DINOv2 hoặc SigLIP), nén mỗi hình ảnh thành hàng trăm “token thị giác”, tóm tắt những gì robot nhìn thấy.
Luồng dữ liệu thứ hai là ngôn ngữ. Lệnh của bạn (“đưa cho tôi cái tuốc nơ vít”) được chuyển thành token giống như trong ChatGPT.
Hai luồng dữ liệu này được kết nối và đưa vào một “trục chính” Transformer (thường là một mô hình ngôn ngữ mã nguồn mở nhỏ như Qwen3 hoặc Llama). Trục chính này chịu trách nhiệm suy luận, kết hợp thông tin nó thấy với thông tin nó được hỏi.
Luồng dữ liệu thứ ba: Hành động, tuôn ra từ đầu kia. Đây là nơi các thiết kế kiến trúc khác nhau phân nhánh:
- Token hành động rời rạc: Mô hình trực tiếp tạo ra các token có thể giải mã thành góc khớp hoặc vị trí đầu thực thi, giống như ChatGPT tạo từ ngữ. Cách này đơn giản, nhưng khi chạy ở tần suất cao có thể bị giật.
- Đầu hành động khuếch tán hoặc phù hợp luồng (flow-matching): Một mạng nhỏ độc lập nhận đầu ra của trục chính và khử nhiễu để tạo ra một quỹ đạo vị trí khớp mượt mà, giống như mô hình khuếch tán hình ảnh, nhưng thay vào đó là tạo chuyển động. Đây là cách π0 làm, tạo ra các hành động mượt mà và tự nhiên hơn.
- Phân khối hành động: Thay vì dự đoán một lệnh đơn lẻ tiếp theo, nó dự đoán một tập lệnh cho nửa giây tiếp theo ngay lập tức, do đó làm mịn sự giật cục.
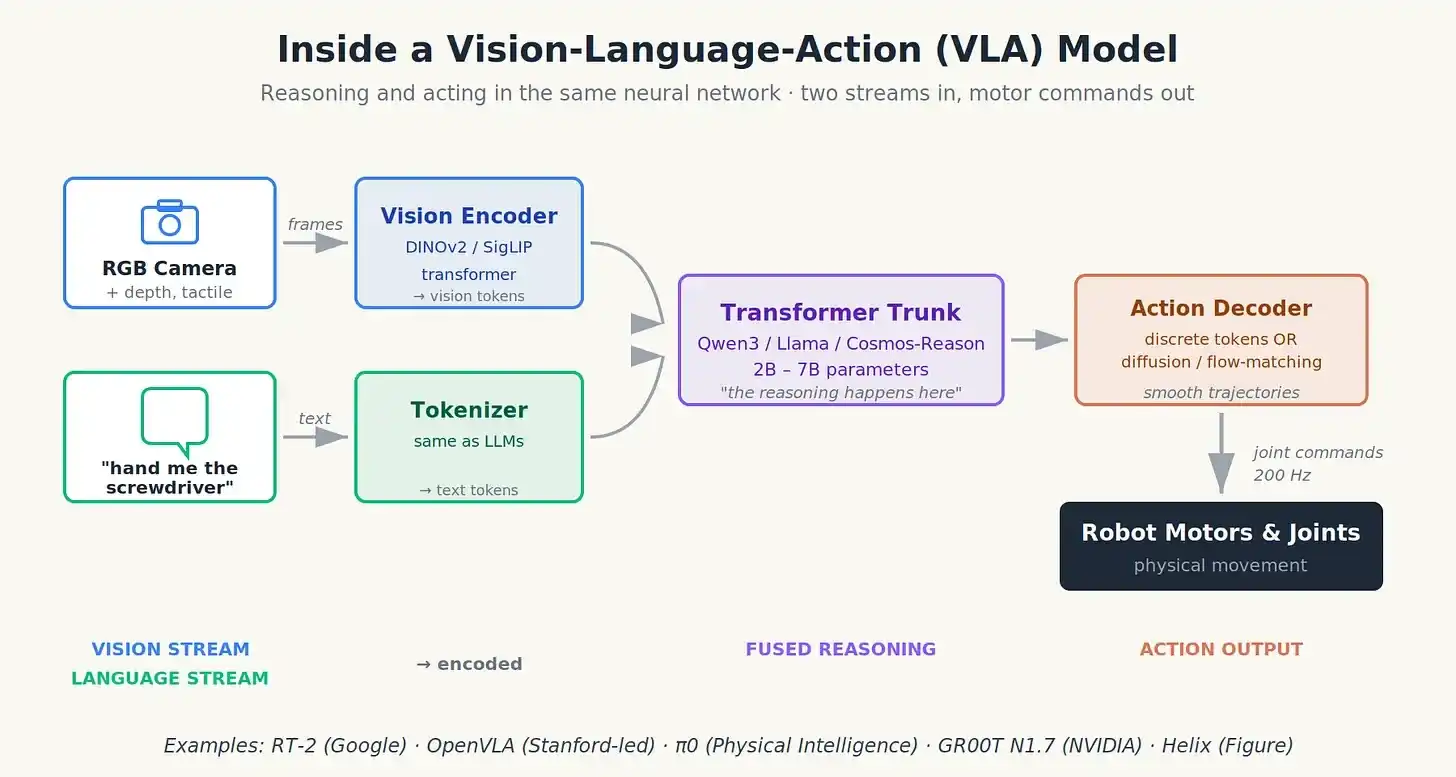
Trong mô hình VLA: Hai luồng đầu vào đi vào, lệnh chuyển động xuất ra, suy luận và hành động hợp nhất trong một mạng.
Đây là sự chuyển đổi kiến trúc then chốt: suy luận và hành động không còn tách rời. Dạy mạng nơ-ron nhận diện cốc, cũng dạy nó cách cầm nắm cốc. Chính sự kết hợp này cho phép VLA tổng quát hóa, trong khi các tiền thân của chúng không thể.
Năm: Chiến lược hai não, LLM và VLA phối hợp hoạt động như thế nào
Có một chi tiết hiếm khi được giải thích rõ ràng trong tiếp thị. Những robot hình người hiệu suất tốt nhất ngày nay không chạy một hệ thống VLA đơn lẻ, mà chạy hai mô hình với tốc độ khác nhau, giao tiếp với nhau. Điều này đôi khi được gọi là kiến trúc hai hệ thống hoặc hệ thống 1 / hệ thống 2, mượn từ khung tâm lý học của Daniel Kahneman, cho rằng con người có một bộ não trực giác nhanh và một bộ não suy nghĩ có ý thức chậm.
Helix của Figure AI đã biến thiết kế này thành kinh điển, và giờ đây nó (và các biến thể của nó) hầu như được sao chép ở mọi nơi. Đặc biệt quan trọng, NVIDIA GR00T N1.7 áp dụng thiết kế này, và hầu hết robot hình người Trung Quốc cũng vậy. Cấu trúc như sau:
- Hệ thống 2 (S2): Bộ não suy nghĩ chậm. Một mô hình ngôn ngữ thị giác 7 tỷ tham số, chạy ở tần suất khoảng 7–9 Hz (tức 7 đến 9 lần mỗi giây). Công việc của nó là quan sát cảnh, phân tích lệnh, thực hiện suy luận nhiều bước (ví dụ: “cái bát ở phía sau hộp ngũ cốc; tôi cần di chuyển hộp trước”), và đưa ra ý định cấp cao – thường là một tập hợp vector nội bộ nhỏ gọn, không phải bản thân văn bản.
- Hệ thống 1 (S1): Bộ não phản ứng nhanh. Một mô hình chiến lược vận động thị giác nhỏ hơn nhiều (khoảng 80 triệu tham số), chạy ở tần suất 200 Hz. Nó nhận vector ý định từ S2 cộng với dữ liệu cảm biến mới nhất, xuất ra lệnh khớp liên tục. Nó không có bất kỳ “suy nghĩ” thực sự nào, nó chỉ phản ứng.
Gần đây, Helix-02 của Figure đã bổ sung một Hệ thống 0 (S0). Nó nằm dưới hệ thống hai não, là một lớp phản xạ, không phải lớp nhận thức thứ ba. Đây là một mạng 10 triệu tham số, chạy ở tần suất 1 kHz, chịu trách nhiệm xử lý sự cân bằng cơ bản và phối hợp toàn thân, thay thế hơn một trăm nghìn dòng mã C++ điều khiển chuyển động viết tay. Bạn có thể tưởng tượng S0 như một tủy sống được học: nó không suy luận hay lập kế hoạch, chỉ chịu trách nhiệm giữ cơ thể thẳng đứng và phối hợp, trong khi việc suy nghĩ được thực hiện bởi hệ thống hai não bên trên.
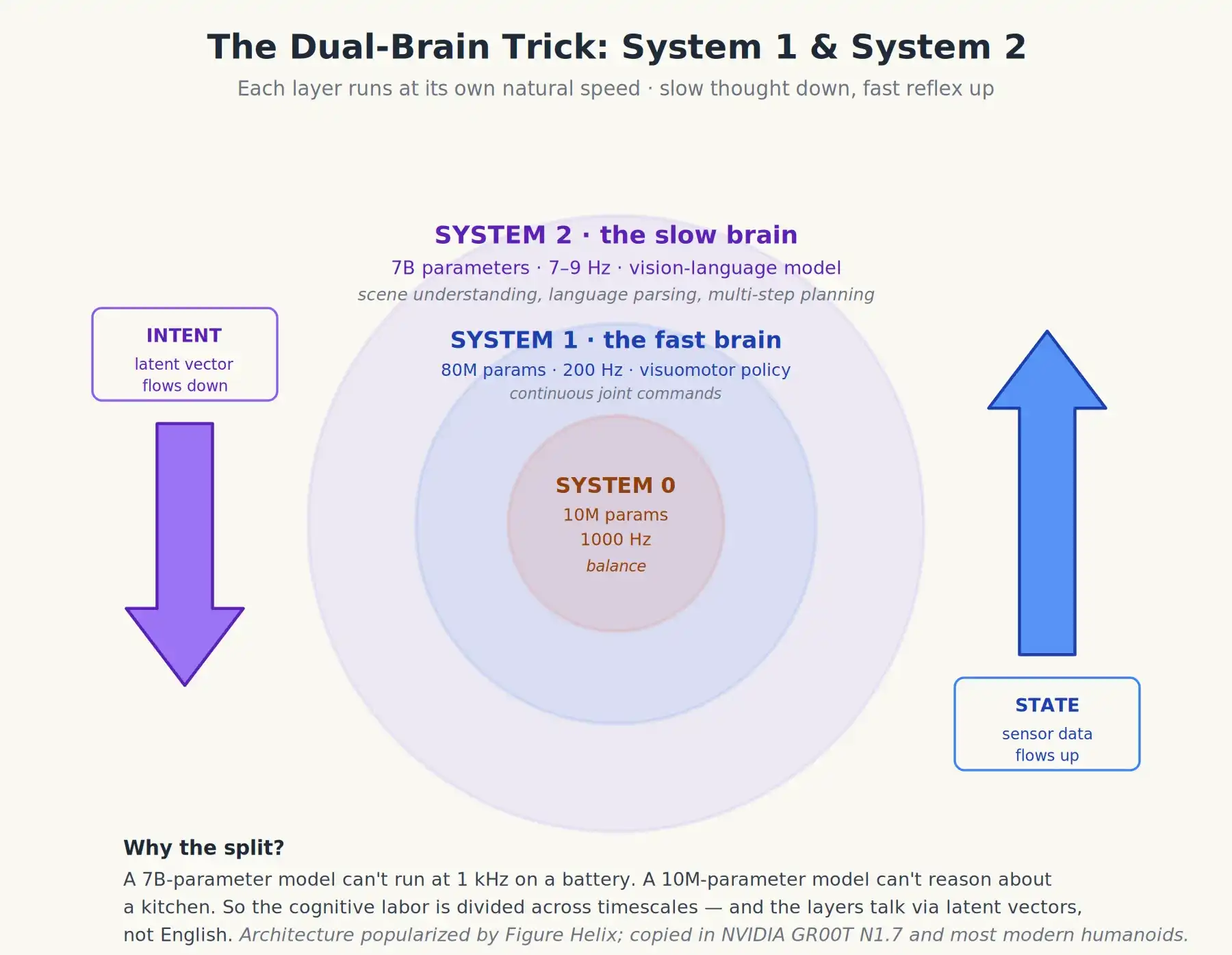
Kiến trúc hai não của robot hình người hiện đại: Hệ thống 2 suy nghĩ chậm, Hệ thống 1 phản ứng nhanh – và bên dưới còn có một lớp phản xạ Hệ thống 0 để giữ thăng bằng, tiếp xúc xúc giác và phối hợp toàn thân
Sự phân chia này xuất phát từ giới hạn vật lý. Nếu chỉ đưa ra lệnh chuyển động mỗi 200 mili giây (tốc độ chạy của một VLA lớn), hành động của robot sẽ chậm chạp như di chuyển dưới nước. Lệnh chuyển động phải được cập nhật nhanh hơn dao động tự nhiên của các khớp mà nó điều khiển, điều đó có nghĩa là cần hàng trăm đến hàng nghìn lần cập nhật mỗi giây. Không có mô hình Transformer 7 tỷ tham số nào có thể chạy nhanh như vậy trên robot chạy bằng pin.
Do đó, nhiệm vụ nhận thức được phân công: mô hình lớn và chậm chịu trách nhiệm suy nghĩ; mô hình nhỏ và nhanh chịu trách nhiệm hành động. Chúng không giao tiếp bằng tiếng Anh, mà bằng các vector tiềm ẩn đã học: mô hình chậm đưa ra mục tiêu trừu tượng, và mô hình nhanh biết cách giải thích nó.
Sáu: Đám mây, Điện toán Biên và Vấn đề đặt “Bộ não” ở đâu
Tất cả các tính toán này thực sự diễn ra ở đâu?
Ngày nay, giữa các đội robot, hầu như đã hình thành một sự đồng thuận mạnh mẽ, gần như mang tính ý thức hệ, rằng các vòng lặp điều khiển cốt lõi liên quan đến an toàn phải chạy cục bộ. Lý do có hai:
Độ trễ. Thời gian đi và về của WiFi hoặc mạng di động, lạc quan nhất cũng là 30-80 mili giây. Trong khi đó, lệnh hành động cần được cập nhật mỗi 1-5 mili giây. Một vòng lặp mạng như vậy đơn giản là không thể hoạt động.
Độ tin cậy. Robot hoạt động trong nhà máy, kho bãi, nhà bếp, bệnh viện… Mạng có thể ngắt bất cứ lúc nào. Nếu một con robot ngừng hoạt động khi WiFi bị ngắt, nó sẽ trở thành một mối nguy hiểm an toàn.
Vì vậy, sự phân chia hiện đại đại khái như sau:
Trên bo mạch (Cục bộ), chạy trên các thiết bị như mô-đun NVIDIA Jetson Thor hoặc AGX Thor (khoảng 2,000 TFLOPS, 128 GB bộ nhớ, công suất 40–130 W):
- Tất cả chức năng S0/S1: Cân bằng, chuyển động, điều khiển hành động tinh tế.
- Bản thân VLA (Hệ thống 2), để phù hợp với giới hạn phần cứng, ngày càng được lượng tử hóa sang định dạng FP8 hoặc FP4. Các mô hình từ 2 tỷ đến 7 tỷ tham số hiện có thể chạy trên thiết bị.
- Nhận thức, tổng hợp cảm biến, và bất kỳ chương trình giám sát an toàn nào khác có thể ghi đè.
Đám mây hoặc máy chủ từ xa (nếu có):
- Giao diện hội thoại (“này robot, tôi nên làm gì cho bữa tối?”): Các giao diện này có thể chịu được độ trễ.
- Học tập theo cụm: Hàng nghìn robot gửi dữ liệu điều khiển từ xa về máy chủ để tổng hợp vào phiên bản mô hình tiếp theo.
- Cần lập kế hoạch dài hạn quy mô lớn, có thể sử dụng các mô hình tiên phong quy mô.
- Bảng điều khiển và giám sát của nhà điều hành.
Ngoài ra, còn có một lớp trung gian ngày càng phát triển: máy chủ biên cục bộ trong nhà máy hoặc kho hàng, chúng giao tiếp với cụm robot qua mạng cục bộ với độ trễ chỉ vài mili giây. Các LLM lớn hơn có thể được triển khai ở cấp độ này, chịu trách nhiệm các nhiệm vụ lập lịch trình cấp cao mà một robot riêng lẻ không cần tự quản lý.
Làn sóng robot hình người Trung Quốc được xây dựng dựa trên giả định này: Unitree, AgiBot, Xiaopeng IRON, Fourier, EngineAI. Robot của họ được trang bị khả năng tính toán trên bo mạch (thường là Jetson, đôi khi sử dụng chip trong nước như Huawei Ascend), trong khi đám mây được sử dụng cho học tập theo cụm và giao diện hội thoại, không phải cho vòng lặp điều khiển.
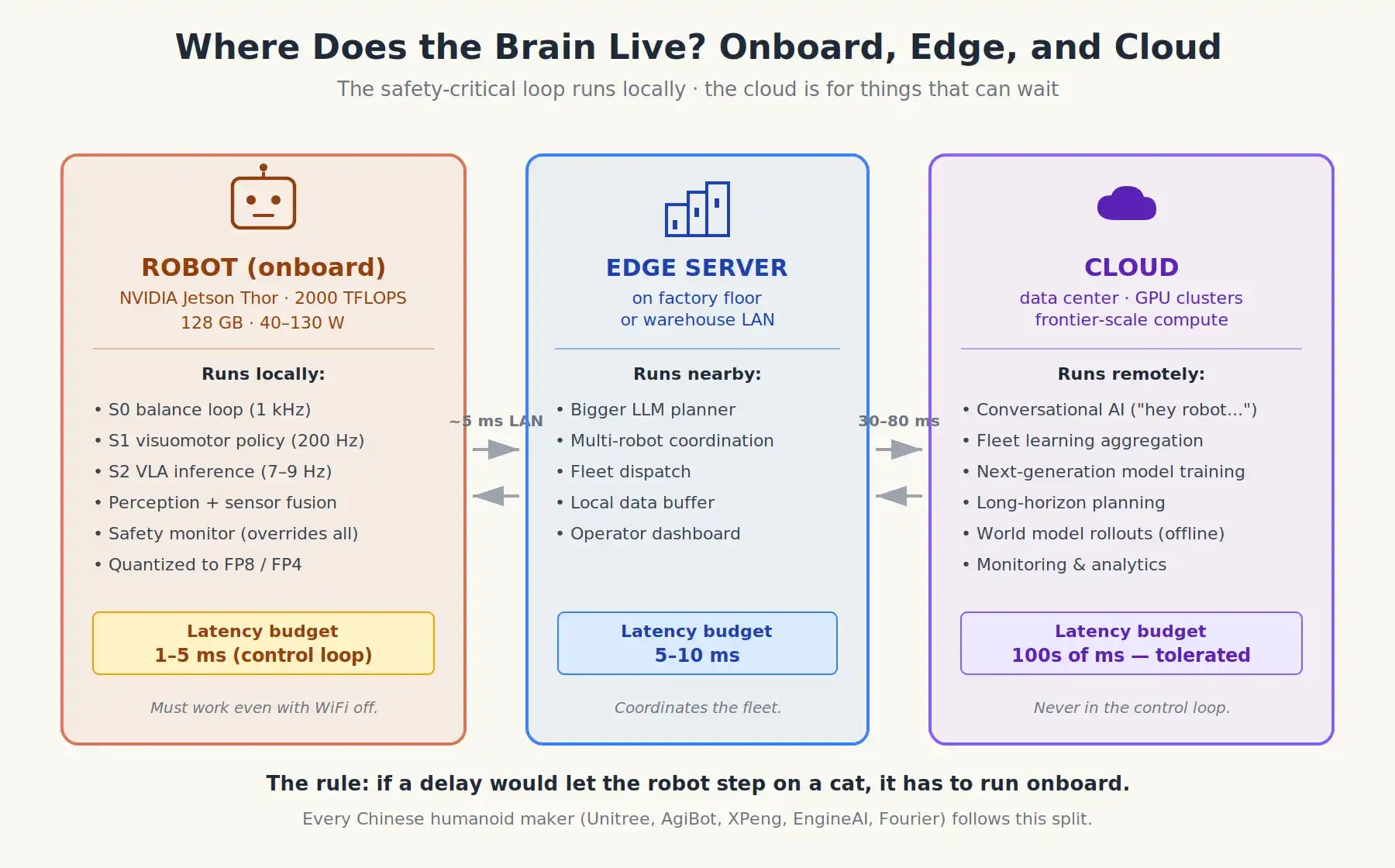
Vị trí thực tế nơi bộ não robot chạy: Các vòng lặp quan trọng về an toàn chạy cục bộ, đám mây dùng cho những việc có thể chờ
Bảy: Tại sao mô hình mã nguồn mở âm thầm trở thành tâm điểm
Nếu chỉ xem demo, bạn có thể nghĩ lĩnh vực này bị chi phối bởi một số ít công ty Mỹ có vốn hóa lớn. Nhưng thực tế phức tạp hơn nhiều. Tốc độ phát triển của AI vật lý phần lớn được quyết định bởi các mô hình trọng số mã nguồn mở mà bất kỳ ai cũng có thể tải xuống và tinh chỉnh.
Các mô hình được liệt kê dưới đây tuy không nhiều nhưng có ý nghĩa lớn:
- OpenVLA (Stanford): Mô hình robot tổng quát mã nguồn mở 7B đầu tiên.
- NVIDIA Isaac GR00T (N1, N1.5, N1.7): Trọng số mở sắp ra mắt, giấy phép thương mại cũng sắp có, mô hình này được đào tạo dựa trên hàng chục nghìn giờ video góc nhìn thứ nhất của con người. GR00T N1.7 ra mắt tháng 3/2026, cho phép bất kỳ ai có robot hình người có thể sử dụng kiến trúc hai hệ thống của nó miễn phí.
- π0 của Physical Intelligence: Phát hành trọng số cho nghiên cứu.
- NVIDIA Cosmos: Mô hình cơ sở thế giới mở.
- AgiBot World: Tập dữ liệu mã nguồn mở khổng lồ từ công ty khởi nghiệp Thượng Hải, chứa các minh họa điều khiển từ xa robot hình người.
- LeRobot của Hugging Face: Một thư viện mở, đã trở thành điểm hội tụ của tất cả các nền tảng trên.
- mimic-video của Mimic robotics: Một mô hình video-hành động mã nguồn mở, có hiệu suất mẫu cao gấp 10 lần so với VLA truyền thống.
Nó quan trọng vì hai lý do. Thứ nhất, các công ty khởi nghiệp robot không cần phải chi hàng chục triệu đô la để đào tạo trước một mô hình cơ sở: họ có thể lấy GR00T hoặc π0, sau đó đào tạo tiếp nó bằng dữ liệu từ robot của chính họ. Unitree, EngineAI, Booster, Galbot và hàng chục công ty Trung Quốc quy mô nhỏ hơn đang làm điều này. Đó là lý do tại sao một công ty chỉ có vài trăm nhân viên vẫn có thể tạo ra một robot hình người biết đi, nói và gấp quần áo: họ đang đứng trên vai của ngăn xếp công nghệ mã nguồn mở.
Thứ hai, các mô hình mã nguồn mở là con đường duy nhất thực tế để giải quyết vấn đề an toàn. Nếu một mô hình hoàn toàn đóng chạy bên trong một robot tại một nhà máy nào đó, và không ai bên ngoài có cái nhìn sâu sắc về logic suy luận của nó, đó chắc chắn là một cơn ác mộng về quản lý. Các mô hình mở cho phép kiểm toán viên, nhà nghiên cứu và nhà điều hành thực sự kiểm tra xem robot đã được đào tạo những gì.
Tám: Còn những vấn đề nào chưa được giải quyết
Nếu bạn đã xem đủ video demo robot, bạn chắc chắn cũng đã xem rất nhiều video robot gặp sự cố. Thế hệ robot LLM+VLA hiện tại thực sự ấn tượng, nhưng cũng có những hạn chế rõ ràng. Dưới đây là những vấn đề của nó:
- Phục hồi giữa chừng nhiệm vụ. VLA xử lý các thay đổi bất ngờ tốt hơn bất kỳ công nghệ nào trước đây. Nhưng khi mọi thứ thực sự đi sai hướng (ví dụ: cầm nắm hỏng, vật thể lăn, ai đó xâm nhập khu vực làm việc), khả năng quay lại đúng hướng vẫn là điểm yếu. Robot sẽ mù quáng lặp lại hành động thất bại.
- Hiệu quả mẫu. Đào tạo một VLA từ đầu cần hàng chục nghìn giờ dữ liệu điều khiển từ xa. Trong khi con người chỉ cần vài phút để học cách sử dụng một công cụ mới. Khoảng cách hiệu quả này là rất lớn.
- Tổng quát hóa xuyên thực thể. Mô hình được đào tạo trên cánh tay robot Franka tại phòng thí nghiệm Stanford không thể chuyển đổi hoàn hảo sang robot hình người Unitree trong kho ở Thâm Quyến. Hình dạng vật lý của chúng khác nhau.
- Nhiệm vụ dài hạn. Bất kỳ nhiệm vụ nào cần hành vi mạch lạc trên 30-60 giây và bao gồm nhiều mục tiêu phụ, đều dễ bị lạc mục tiêu. Nhiệm vụ “làm bữa sáng cho tôi” vẫn còn xa vời.
- Hiểu biết vật lý thông thường. VLA được đào tạo để bắt chước, không phải để hiểu. Nó không thực sự hiểu nguyên tắc nước sẽ đổ ra khi “làm đổ một cốc nước”. Nó chỉ đã thấy một số ví dụ và dự đoán điều gì sẽ xảy ra tiếp theo dựa trên khớp mẫu.
- Khả năng suy luận không gian. Mặc dù chúng đa phương thức, nhưng lại yếu một cách đáng ngạc nhiên trong các nhiệm vụ như “đi vòng quanh chướng ngại vật thay vì đi xuyên qua nó” hoặc “xếp những thứ này lên mà không đổ”.
Loạt điểm yếu cuối cùng này đã thúc đẩy lĩnh vực này bắt đầu đặt cược vào một loại mô hình hoàn toàn khác.
Chín: Mô hình Thế giới
Hãy tưởng tượng: Nếu không đào tạo robot dự đoán hành động, mà đào tạo nó dự đoán hậu quả của hành động thì sao?
Mô hình Thế giới (World Model) là một mạng nơ-ron dự đoán thế giới sẽ như thế nào tiếp theo, dựa trên trạng thái thế giới hiện tại (thường là một đoạn video hoặc một chuỗi khung hình) và một hành động đề xuất. Nói đơn giản, bạn có thể tưởng tượng nó như một bộ dự đoán video có thể học được, với vô lăng. Bạn cho nó xem cảnh camera giây cuối cùng, và nói với nó “robot sẽ di chuyển cánh tay về phía trước 10 cm”, nó có thể tạo ra một đoạn video chân thực dự đoán những gì sẽ xảy ra trong giây tiếp theo.
Tại sao điều này quan trọng?
Bởi vì một khi có Mô hình Thế giới, robot có thể suy nghĩ trước khi hành động. Nó có thể hình dung trước ba đến bốn hành động ứng viên khác nhau, dự đoán kết quả của mỗi hành động, chấm điểm và chọn phương án tốt nhất. Tất cả những điều này diễn ra trước khi bất kỳ động cơ nào di chuyển. Đây chính xác là cách động cơ cờ vua hoạt động: nó không ghi nhớ nước đi, mà mô phỏng tương lai. Trước đây, chưa từng có khả năng này trong lĩnh vực robot vật lý, bởi vì chưa từng có một mô hình đủ chính xác để mô phỏng sự phức tạp lộn xộn của thế giới thực.
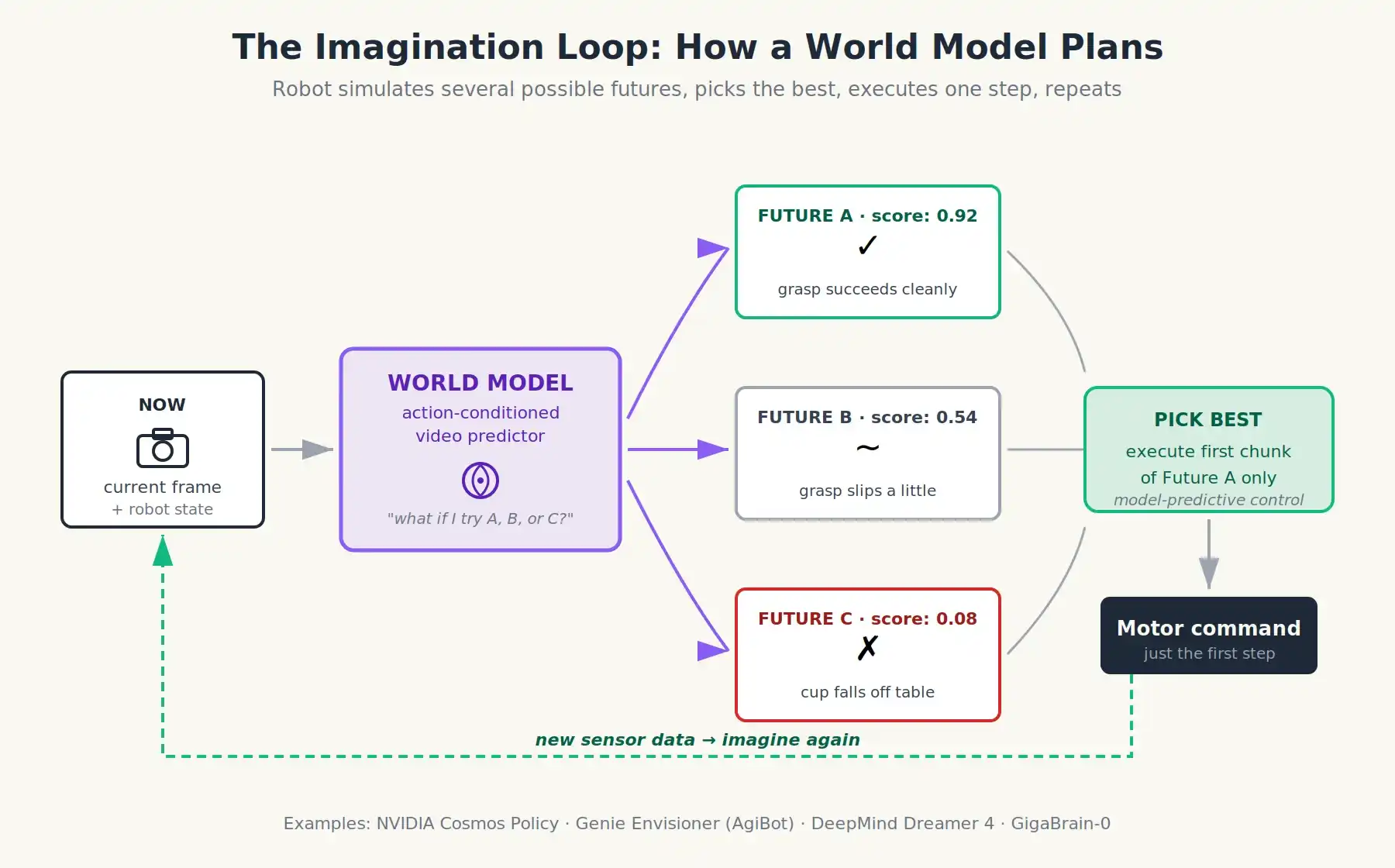
Mô hình Thế giới cho phép robot mô phỏng nhiều kịch bản tương lai khả dĩ, chấm điểm chúng, và chọn phương án tốt nhất trước khi bất kỳ động cơ nào khởi động
Vậy Mô hình Thế giới năm 2026 trông như thế nào?
Các mô hình thế giới tiên tiến nhất hiện nay khá đa dạng, nhưng đang phát triển nhanh chóng. Dưới đây là một số mô hình:
- NVIDIA Cosmos: Một loạt các mô hình cơ sở thế giới mở, bao gồm Cosmos Predict 2.5 (mô hình tạo sinh), Cosmos Transfer 2.5 (mô hình mô phỏng có thể điều khiển), Cosmos Reason 2 (công cụ suy luận ngôn ngữ thị giác cho robot) và Cosmos Policy mới nhất. Cosmos Policy đi xa hơn, bằng cách đào tạo tiếp Mô hình Thế giới để trực tiếp xuất hành động để điều khiển. Cosmos được đào tạo bằng hàng chục nghìn giờ video sử dụng GPU (Cosmos Predict 2.5 là mô hình thế giới trong dòng này).
- DeepMind Genie 3: Một mô hình thế giới tương tác, có thể tạo ra các môi trường hoàn toàn có thể điều hướng dựa trên gợi ý văn bản, tốc độ khung hình 24 fps và chạy ổn định liên tục trong vài phút. Ban đầu được thiết kế cho môi trường trò chơi.
- Meta V-JEPA 2: Được đào tạo trước với hơn một triệu giờ video từ web, sau đó chỉ được điều kiện hóa hành động với 62 giờ video robot. Đạt 80% tỷ lệ thành công không cần mẫu (zero-shot) trong việc nhặt và đặt vật trên các cánh tay robot thực tế tại các phòng thí nghiệm khác nhau, mà không cần bất kỳ đào tạo nhiệm vụ cụ thể nào. Phương pháp “JEPA” khác biệt về kiến trúc so với các phương pháp khác.
- DeepMind Dreamer 4: Chỉ sử dụng dữ liệu ngoại tuyến, không cần bất kỳ tương tác môi trường nào, đã học cách thu thập kim cương trong Minecraft (một nhiệm vụ 20.000 bước). Điều này chứng minh rằng việc học tăng cường thực sự trong thế giới ảo là khả thi.
- Genie Envisioner của AgiBot: Nền tảng mô hình thế giới thống nhất từ Trung Quốc, được đào tạo với hơn 3000 giờ video vận hành robot hình người thực tế. Nó vừa có thể tạo ra các quỹ đạo triển khai dự đoán, vừa có thể tạo ra các quỹ đạo hành động có thể thực thi. AgiBot sử dụng NVIDIA Cosmos Predict 2 làm mạng trục chính và đào tạo tiếp bằng dữ liệu riêng. Đây chính xác là mô hình “ngăn xếp công nghệ mã nguồn mở + dữ liệu riêng” đã được mô tả trước đó.
- Mô hình Thế giới của Viện Nghiên cứu Toyota dựa trên Cosmos: Để tăng cường dữ liệu điều khiển từ xa và điều hướng.
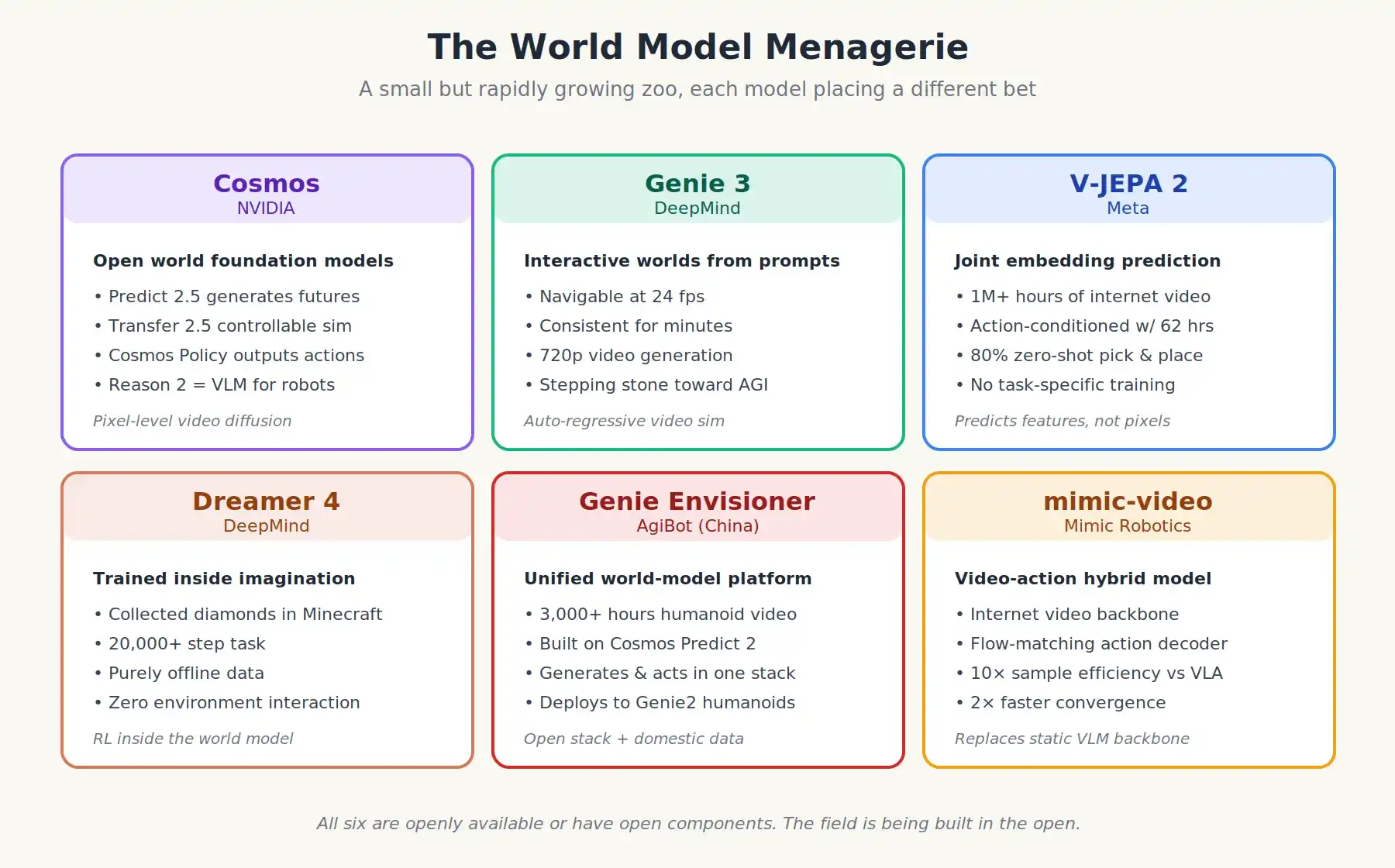
Sáu mô hình thế giới quan trọng nhất giai đoạn 2025-2026, mỗi mô hình đưa ra một ý tưởng khác nhau về cách máy móc nên học vật lý.
Mười: Kiến trúc thay thế, vì lĩnh vực này vẫn chưa có kết luận
Không có tiêu chuẩn duy nhất để xây dựng Mô hình Thế giới. Cuộc chiến kiến trúc hiện là một trong những cuộc tranh luận thú vị nhất trong lĩnh vực AI, và nó trực tiếp ảnh hưởng đến những gì robot có thể làm trong tương lai. Ba trường phái đáng theo dõi như sau:
Khuếch tán video cấp độ pixel (Trường phái Cosmos/Sora): Sử dụng mô hình khuếch tán để dự đoán pixel thực tế của các khung hình tương lai. Ưu điểm là có thể hoạt động như một trình tạo dữ liệu tổng hợp, có thể kết xuất các minh họa robot mới hoàn toàn chưa từng xảy ra. Nhược điểm là tốn kém, đôi khi vi phạm quy luật vật lý, và dự đoán các pixel sẽ không bao giờ được nhìn thấy là một sự lãng phí.
Kiến trúc Dự đoán Nhúng Chung (JEPA) (Trường phái LeCun): Không dự đoán pixel, mà dự đoán biểu diễn trừu tượng của khung hình tiếp theo. Loại bỏ chi tiết kết cấu, chỉ giữ lại bản chất ngữ nghĩa của các sự vật trong cảnh. Ưu điểm là hiệu quả, tập trung vào các yếu tố quan trọng cho hành động. Nhược điểm là khó sử dụng hơn. V-JEPA, V-JEPA 2 và các mô hình lai JEPA-VLA mới đang khám phá lĩnh vực này.
Mô hình Thế giới Hành động Tiềm ẩn (Trường phái Genie/Dreamer): Học cách nén toàn bộ video thành một “ngôn ngữ hành động” tiềm ẩn, có thể nắm bắt cấu trúc hành vi, sau đó đào tạo Mô hình Thế giới để nó có thể dự đoán trạng thái tiềm ẩn tiếp theo dựa trên hành động tiềm ẩn tiếp theo. Ưu điểm là cho phép bạn sử dụng video web không có hành động để đào tạo, sau đó thêm một lượng nhỏ dữ liệu robot thực tế. Nhược điểm là hành động tiềm ẩn không thể hiểu được bởi con người, khiến việc phân tích an toàn trở nên phức tạp.

Khuếch tán pixel, JEPA và hành động tiềm ẩn: Mục tiêu giống nhau, nhưng cách xây dựng Mô hình Thế giới lại hoàn toàn khác biệt
Mười một: Ứng dụng thực tế của robot dựa trên Mô hình Thế giới
Nếu tua nhanh vài năm, kiến trúc của robot hình người tiên tiến có thể trông như thế này:
Một Mô hình Thế giới được đặt trên VLA. Khi robot gặp tình huống mới, nó sẽ thực hiện một thao tác tương tự như sau:
- VLA đề xuất một số phương án hành động tiếp theo (nó vẫn là chiến lược).
- Mô hình Thế giới lấy từng hành động ứng viên và mô phỏng 1-3 giây video tưởng tượng.
- Bộ phận đánh giá giá trị sẽ chấm điểm dựa trên kết quả hình dung: Cốc đã được nhặt lên chưa? Có vật gì rơi xuống không? Có ai bị va chạm không?
- Robot sẽ chọn hành động có điểm cao nhất và chỉ thực hiện phần đầu tiên của nó.
- Dữ liệu cảm biến thực tế chảy ngược lại; vòng lặp lặp lại.
Đây chính là Điều khiển Dự đoán Mô hình, một kỹ thuật đã được sử dụng trong nhiều năm để ổn định tên lửa và máy bay bốn cánh quạt, nhưng nó thay thế các phương trình vật lý dẫn xuất thủ công bằng Mô hình Thế giới đã học. Khả năng mở rộng của nó nằm ở chỗ, Mô hình Thế giới được đào tạo trước dựa trên hàng triệu giờ video, thay vì vì ai đó viết phương trình Navier-Stokes cho môi trường nhà bếp.
Các lợi ích của nó gia tăng theo tầng:
- Cải thiện khả năng phục hồi. Nếu hành động cầm nắm bị lỗi, Mô hình Thế giới có thể hình dung nhiều đường đi sửa chữa khác nhau và chọn đường đi đầy hứa hẹn nhất.
- Nâng cao khả năng tổng quát hóa. Mô hình Thế giới được đào tạo dựa trên video web đã trải nghiệm các “hiện tượng vật lý” nhiều hơn hàng bậc độ lớn so với bất kỳ tập dữ liệu điều khiển từ xa robot nào.
- Lập kế hoạch dài hạn trở nên khả thi. Lập kế hoạch trong tưởng tượng, thay vì trong thực tế.
- Khoảng cách giữa mô phỏng và thực tế thu hẹp. Trước đây cần đào tạo với trình mô phỏng tự xây dựng (ví dụ: Isaac Sim, động cơ vật lý Newton) và hy vọng kết quả đào tạo sẽ chuyển giao sang thực tế, giờ đây có thể đào tạo với một trình mô phỏng được đào tạo để khớp với video thực tế. Do đó khoảng cách nhỏ hơn.
- Dữ liệu tổng hợp bùng nổ. Một Mô hình Thế giới gần như có thể tạo ra hàng triệu quỹ đạo robot khác nhau miễn phí, bao gồm các cấu hình ánh sáng, vật liệu và vật thể khác nhau. Điều này giải quyết một trong những nút thắt lớn nhất của lĩnh vực.
Ngoài ra, nó còn có một lợi thế an toàn quan trọng. Một robot có thể mô phỏng hậu quả của hành động có thể từ chối thực hiện các thao tác nguy hiểm: không phải vì các quy tắc đặt trước, mà bởi vì nó hình dung trước việc có thể có người bị thương trong tương lai.
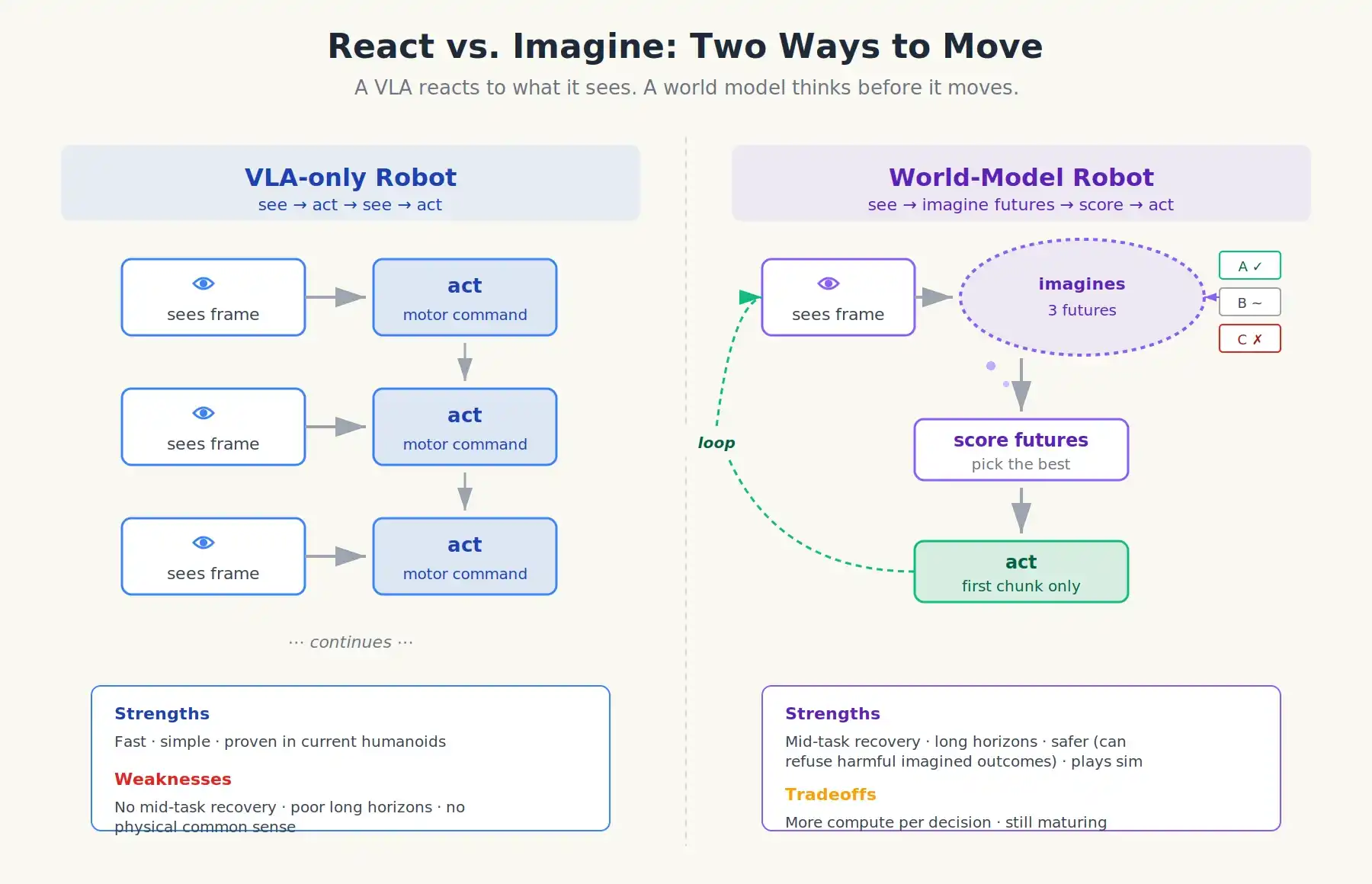
Hai cách di chuyển: VLA phản ứng với những gì nó thấy; robot Mô hình Thế giới suy nghĩ trước khi di chuyển
Mười hai: Những điều nên biết thêm
Vấn đề dữ liệu mới là cốt lõi thực sự: Nếu không thể cung cấp dữ liệu cho mô hình, tất cả các đổi mới kiến trúc trên thế giới đều vô ích. Hiện tại, điều khiển từ xa (con người đeo thiết bị VR để điều khiển robot như con rối từ xa) là nút thắt công nghệ chính. Hào cạnh tranh của một công ty robot ngày càng phụ thuộc vào quy trình thu thập dữ liệu của họ, hơn là bản thân mô hình. AgiBot đã xây dựng các kho hàng chứa đầy nhà điều hành. Định luật mở rộng sự khéo léo của NVIDIA GR00T N1.7 chỉ ra rằng, nhiều video góc nhìn thứ nhất của con người hơn có thể trực tiếp, dự đoán được, nâng cao sự khéo léo của robot. Đây cũng là phần Trung Quốc có lợi thế cấu trúc: chi phí lao động thu thập dữ liệu thấp hơn, môi trường triển khai khoan dung hơn và nhà nước tích cực phối hợp chuỗi cung ứng.
Mô phỏng là một vũ trụ song song. Isaac Sim của NVIDIA, động cơ vật lý Newton mã nguồn mở hoàn toàn mới (phiên bản 1.0 chính thức phát hành tháng 4/2026) và nền tảng Omniverse, cho phép các doanh nghiệp đào tạo robot trong hàng triệu môi trường mô phỏng song song mà không cần triển khai chúng ra thế giới thực. Hầu hết các tính năng có vẻ là “trí thông minh robot” thực ra được nuôi dưỡng trong môi trường mô phỏng, sau đó chuyển giao sang phần cứng.
Hiệu quả kinh tế bắt đầu xuất hiện. Unitree đã giao khoảng 5500 robot hình người vào năm 2025 và dự kiến đạt 10.000 đến 20.000 vào năm 2026. Giá trung bình giảm từ 85.000 USD xuống còn 25.000 USD trong hai năm. Unitree R1 có giá 5900 USD. Noetix Bumi ra mắt với giá 1400 USD. Giá phần cứng robot hình người đang tiến gần đến mức giá của thiết bị điện tử tiêu dùng, trong khi công nghệ AI bên trong nó vẫn còn lâu mới đạt được trình độ demo. Khoảng cách này cuối cùng sẽ thu hẹp, và khi đó, việc tăng quy mô thị trường sẽ có tác động đáng kể đến toàn ngành.
Các chế độ lỗi trông rất kỳ lạ. Khi robot dựa trên LLM gặp lỗi, cách chúng gặp lỗi thường là những cách robot truyền thống không thể làm. Ví dụ: làm sai một cách tự tin, nhận thức “ảo giác” về một số chức năng, rơi vào vòng lặp hội thoại với chính bộ lập kế hoạch của nó. Giới robot truyền thống khá hoài nghi về điều này, và sự hoài nghi đó không phải không có lý do, họ khẳng định rằng các hệ thống học tập phải được giám sát an toàn và ràng buộc hành vi. Robot đáng tin cậy nhất hiện đang được triển khai là loại lai: bộ não VLA được đặt trong “lồng” an toàn được thiết kế thủ công.
Câu chuyện kể “Thời khắc ChatGPT” là một phép ẩn dụ hữu ích nhưng gây hiểu nhầm: Jensen Huang (Hoàng Nhân Tốn) liên tục nói với mọi người rằng thời khắc ChatGPT của robot đã đến. Ông ấy nói vậy vì NVIDIA bán xẻng và cuốc. Phiên bản trung thực hơn là: Hiện tại chúng ta đang ở khoảng thời kỳ GPT-2 của AI vật lý. Nó mạnh mẽ, có thể làm bạn kinh ngạc; nhưng chưa đủ mạnh để triển khai mà không có sự giám sát. Nó đang được lặp lại nhanh chóng, nhưng chưa đến điểm bùng phát lan truyền virus, mà là một quỹ đạo đi lên chậm rãi và kiên định.
Kết luận

Hành trình tiến hóa của robot bốn chân Unitree (từ phải sang trái)
Trong buổi demo tại văn phòng Unitree, năm robot hình người G1 biểu diễn võ thuật, với các động tác được dàn dựng tỉ mỉ, bộ điều khiển kiểu VLA trên bo mạch được tinh chỉnh, và các nhà điều khiển từ xa đảm bảo mọi thứ diễn ra suôn sẻ. Về cơ bản, nó không hoàn toàn tự chủ. Nhưng toàn bộ quy trình: nhận thức, lập kế hoạch, điều khiển chuyển động, đang bị thay thế bởi mạng nơ-ron. Hai năm sau, chính robot đó có thể thực hiện cùng động tác mà không cần dàn dựng, bởi vì nó đã hình dung trước toàn bộ động tác và chọn phiên bản tốt nhất.
Toàn bộ hành trình phát triển được mô tả trong bài viết này: từ bộ điều khiển viết tay, đến nhận thức học máy, đến bộ lập kế hoạch LLM, đến VLA, đến kiến trúc hai hệ thống, cuối cùng đến Mô hình Thế giới, thực chất là sự chuyển đổi chậm rãi của vị trí trí thông minh robot. Nó bắt đầu từ tâm trí của kỹ sư, sau đó tiến hóa thành mã viết tay, sau đó đi vào lớp nhận thức, vào bộ lập kế hoạch, vào lớp chiến lược. Và giờ đây, cuối cùng nó đang hướng tới mô hình học chính bản thân thế giới.
Mỗi lần chuyển đổi đều làm cho robot trở nên tổng quát hơn, thích ứng hơn, hữu ích hơn. Nếu sự chuyển đổi Mô hình Thế giới có hiệu quả, nó thực sự sẽ trao cho robot một sức mạnh: đủ mạnh để câu hỏi không còn là “robot có thể làm gì?” mà là “chúng ta nên để chúng làm gì?”
Đọc thêm: Điểm danh hơn 30 công ty robot hình người: Ai sẽ chiến thắng vào năm 2026?