- 受 Pectra 升级的乐观情绪推动,以太坊在第二季度反弹,涨幅达 39.4%。
- 鲸鱼买入价值 7539 万美元的 ETH,导致 ETH 突破 2550 美元阻力位,引发看涨势头。
- 以太坊[ETH]再次引起轰动。
突破关键的 2,550 美元阻力位后,这一山寨币之王正凭借强劲的季度收益和引人注目的巨鲸购买力而一路高歌猛进。
一位关键投资者的最新举动增强了看涨情绪,并暗示 ETH 可能出现突破,此前该投资者的买入策略早于两周的价格上涨。
以太坊反弹
2025 年伊始,以太坊经历了充满挑战的开局,第一季度暴跌 45.41%,但在第二季度却实现了惊人的反弹,上涨了 39.4%。
这一积极转变与 Pectra 升级的推出密切相关——Pectra 升级是一项旨在提高可扩展性、安全性和用户体验的关键网络增强功能。
围绕此次升级的市场乐观情绪显然增强了投资者信心,帮助 ETH 重新站稳脚跟。
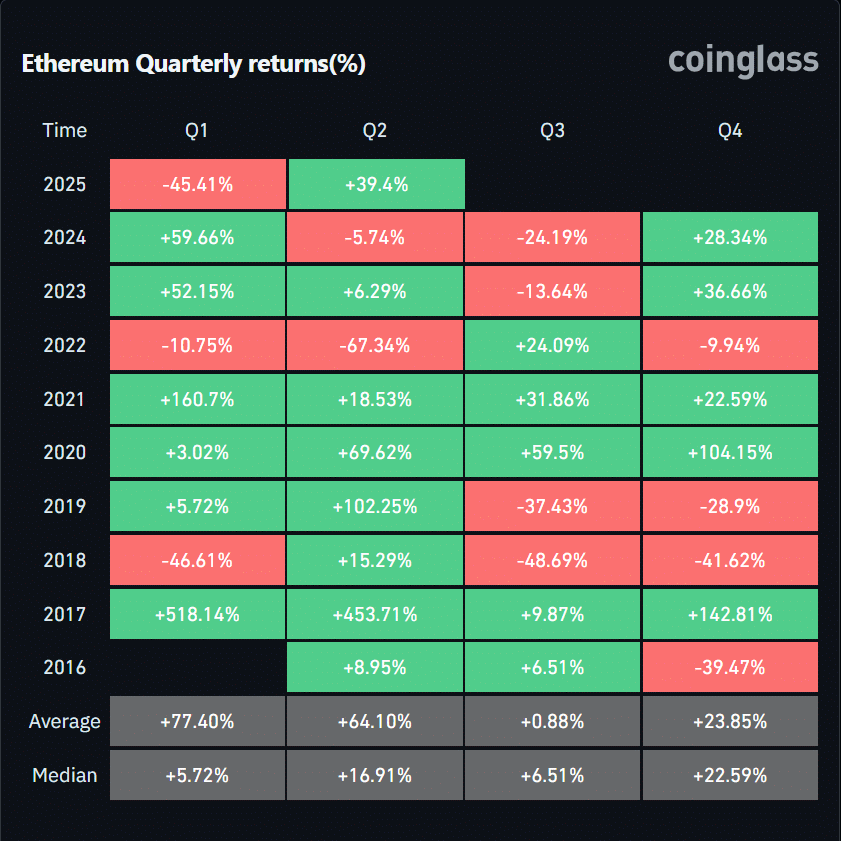
从历史上看,以太坊在第二季度表现强劲。但今年的反弹意义非凡,因为它重新确立了看涨势头,并为下半年可能出现的强劲表现奠定了基础。
观鲸
5 月 26 日,一位神秘的以太坊巨鲸以令人震惊的 7539 万美元 ETH 购买量引起轰动。
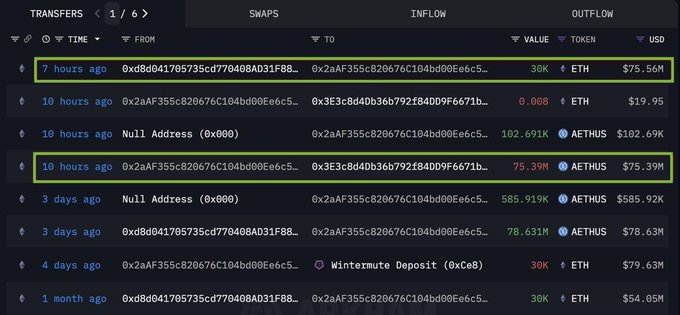
这不是一位普通的投资者——同一个钱包的上一次大额购买导致 ETH 在两周内翻了一番。
现在,ETH 过去已上涨 2373 万美元,而最新价格已上涨 152 万美元,交易员和分析师正在密切关注这一走势,这进一步增强了当前的看涨情绪。
随着多头获得控制权,ETH 突破阻力位
截至发稿时,以太坊突破了 2,550 美元的阻力位,交易价为 2,553.26 美元。小时图显示,在短暂回调后,一根看涨的绿色 K 线推动 ETH 上涨,表明买家兴趣再度升温。
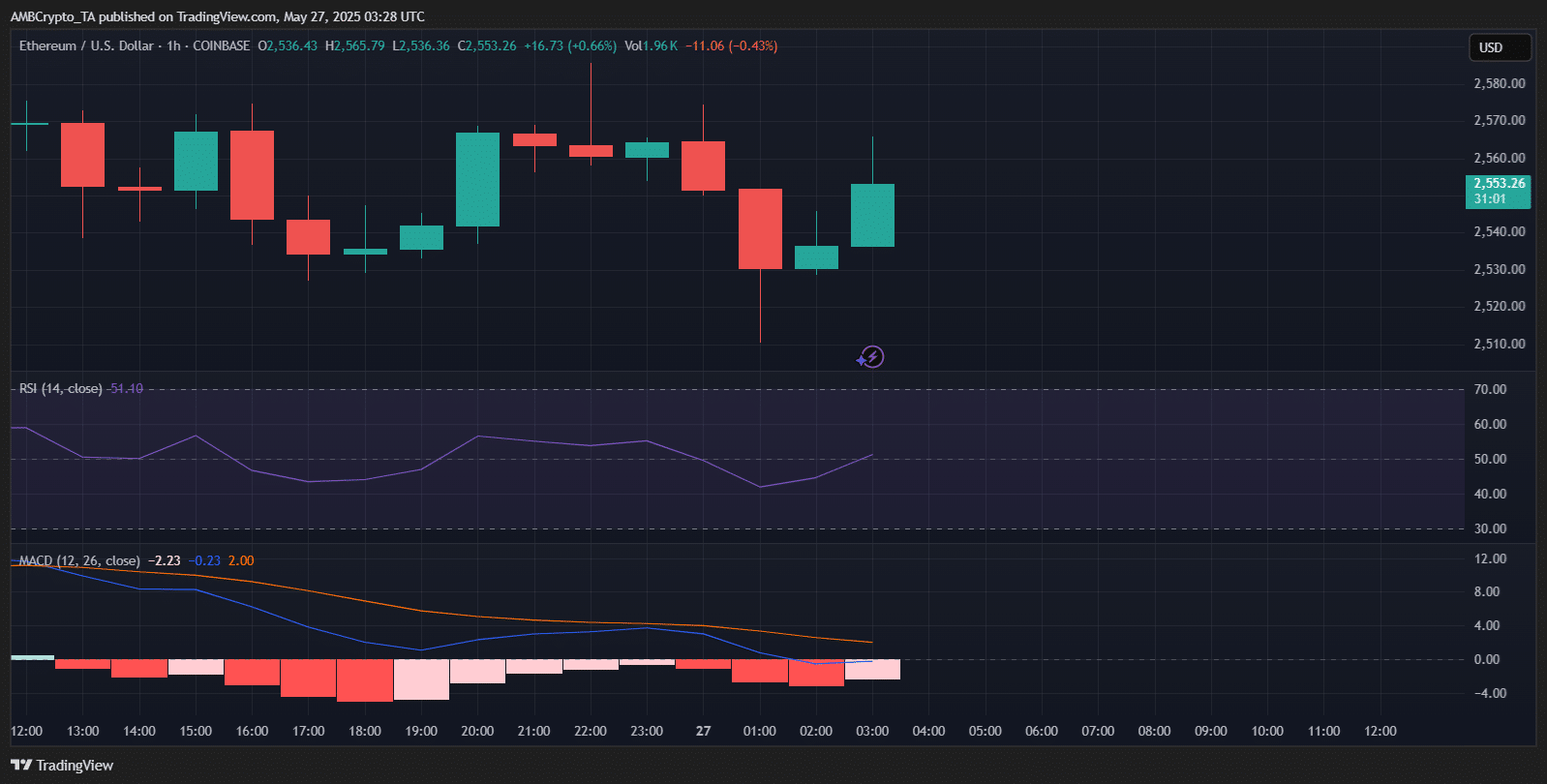
RSI 为 54.40,为中性但正在攀升,而 MACD 则保持在零线以下,表明早期看涨势头。此次突破可能标志着短期趋势逆转,尤其是在鲸鱼增持引发市场乐观情绪之后。
如果交易量维持且 ETH 保持在此水平之上,下一个目标可能是 2,680 美元的大关。








