Model besar terus membesar, dan pandangan umum menyatakan bahwa semakin banyak parameter model, semakin mendekati cara berpikir manusia. Namun, sebuah makalah yang diterbitkan oleh tim Zhejiang University pada 1 April di Nature Communications menawarkan perspektif berbeda (tautan asli: https://www.nature.com/articles/s41467-026-71267-5). Mereka menemukan bahwa ketika skala model (terutama SimCLR, CLIP, DINOv2) bertambah besar, kemampuan untuk mengenali objek spesifik memang terus meningkat, tetapi kemampuan untuk memahami konsep abstrak tidak hanya tidak meningkat, bahkan bisa menurun. Ketika parameter bertambah dari 22.06 juta menjadi 304.37 juta, tugas konsep spesifik naik dari 74.94% menjadi 85.87%, sedangkan tugas konsep abstrak turun dari 54.37% menjadi 52.82%.
Perbedaan Cara Berpikir Manusia dan Model
Saat memproses konsep, otak manusia pertama-tama membentuk seperangkat hubungan klasifikasi. Angsa dan burung hantu terlihat berbeda, tetapi manusia tetap akan mengelompokkannya ke dalam kategori burung. Lebih tinggi lagi, burung dan kuda dapat dikelompokkan ke dalam lapisan hewan. Ketika melihat sesuatu yang baru, manusia sering kali pertama-tama berpikir, benda ini mirip dengan apa yang pernah dilihat sebelumnya, dan kira-kira termasuk dalam kategori mana. Manusia terus-menerus belajar konsep baru, lalu mengorganisir pengalaman tersebut, dan menggunakan hubungan ini untuk mengenali hal baru dan beradaptasi dengan situasi baru.
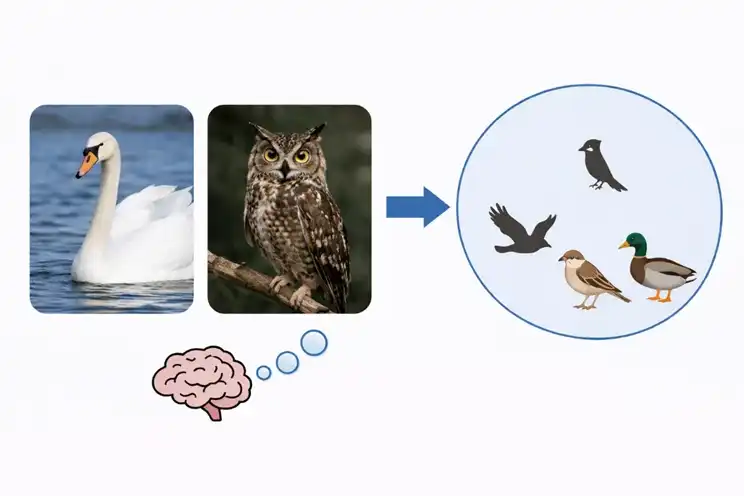
Model juga mengklasifikasikan, tetapi cara pembentukannya berbeda. Model terutama mengandalkan pola yang muncul berulang kali dalam data skala besar. Semakin sering suatu objek spesifik muncul, semakin mudah bagi model untuk mengenalinya. Ketika sampai pada langkah kategori yang lebih besar, model agak kesulitan. Model perlu menangkap kesamaan antara berbagai objek, lalu mengelompokkan kesamaan-kesamaan ini ke dalam kategori yang sama. Model yang ada masih memiliki kelemahan yang jelas di sini. Ketika parameter terus membesar, tugas konsep spesifik akan meningkat, sedangkan tugas konsep abstrak terkadang justru menurun.

Kesamaan antara otak manusia dan model adalah keduanya membentuk seperangkat hubungan klasifikasi internal. Namun, fokus keduanya berbeda; daerah visual tingkat tinggi otak manusia secara alami memisahkan kategori besar seperti makhluk hidup dan non-hidup. Model dapat memisahkan objek spesifik, tetapi sulit untuk secara stabil membentuk kategori yang lebih besar ini. Perbedaan ini menyebabkan otak manusia lebih mudah menerapkan pengalaman lama ke objek baru, sehingga ketika menghadapi sesuatu yang belum pernah dilihat, kita dapat mengklasifikasikannya dengan cepat. Sementara itu, model lebih bergantung pada pengetahuan yang ada, sehingga ketika menemui objek baru, model更容易 (lebih mudah) berhenti pada fitur permukaan. Metode yang diusulkan dalam makalah ini dikembangkan围绕 (berpusat pada) karakteristik ini, menggunakan sinyal otak untuk membatasi struktur internal model, membuatnya lebih mendekati cara klasifikasi otak manusia.
Solusi dari Tim Zhejiang University
Solusi yang diberikan tim juga sangat unik, bukan dengan terus menumpuk parameter, melainkan menggunakan sedikit sinyal otak sebagai supervisi. Sinyal otak di sini berasal dari rekaman aktivitas otak manusia saat melihat gambar. Makalah aslinya menyatakan, mentransfer struktur konseptual manusia (human conceptual structures) ke DNNs. Artinya, sebisa mungkin mengajarkan kepada model bagaimana otak manusia mengklasifikasikan, menginduksi, dan menempatkan konsep-konsep yang saling berdekatan.
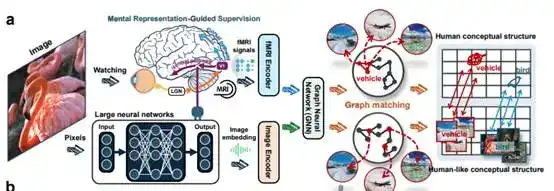
Tim melakukan eksperimen dengan 150 kategori pelatihan yang diketahui dan 50 kategori pengujian yang belum pernah dilihat. Hasilnya menunjukkan bahwa seiring dengan pelatihan ini berlangsung, jarak antara model dan representasi otak terus menyusut. Perubahan ini terjadi secara bersamaan pada kedua kategori, yang menunjukkan bahwa yang dipelajari model bukanlah sampel individual, tetapi benar-benar mulai mempelajari cara organisasi konseptual yang lebih mendekati otak manusia.
Setelah melalui pelatihan ini, kemampuan belajar model dengan sampel yang sangat sedikit menjadi lebih kuat, dan kinerjanya juga lebih baik ketika menghadapi situasi baru. Dalam sebuah tugas yang hanya memberikan sangat sedikit contoh tetapi meminta model untuk membedakan konsep abstrak seperti makhluk hidup dan non-hidup, model mengalami peningkatan rata-rata 20.5%, bahkan melampaui model kontrol yang memiliki parameter jauh lebih besar. Tim juga melakukan 31 set pengujian khusus tambahan, di mana beberapa jenis model menunjukkan peningkatan mendekati satu dekade (sekitar 10%).
Beberapa tahun terakhir, jalur yang familiar di industri model adalah skala model yang lebih besar. Tim Zhejiang University justru memilih arah lain, dari 'bigger is better' menuju 'structured is smarter'. Ekspansi skala memang sangat berguna, tetapi terutama meningkatkan kinerja dalam tugas-tugas yang familiar. Kemampuan pemahaman abstrak dan transferensi ala manusia juga sangat penting bagi AI, yang memerlukan struktur pemikiran AI di masa depan yang lebih mendekati otak manusia. Nilai arah ini terletak pada kemampuannya untuk menarik kembali perhatian industri dari sekadar ekspansi skala, kembali ke struktur kognitif itu sendiri.
Neosoul dan Masa Depan
Ini memunculkan kemungkinan yang lebih besar: evolusi AI tidak harus hanya terjadi pada fase pelatihan model. Pelatihan model dapat menentukan bagaimana AI mengorganisir konsep, bagaimana membentuk struktur penilaian yang lebih berkualitas. Setelah memasuki dunia nyata, lapisan evolusi lain AI baru saja dimulai: bagaimana penilaian AI agent dicatat, diuji, dan terus tumbuh berevolusi dalam kompetisi nyata satu sama lain, belajar dan berevolusi mandiri layaknya manusia. Inilah yang sedang dilakukan Neosoul saat ini. Neosoul tidak hanya membuat AI agent menghasilkan jawaban, tetapi menempatkan AI agent ke dalam sistem yang terus memprediksi, memverifikasi, menyelesaikan, dan menyaring, sehingga terus mengoptimalkan dirinya sendiri dalam prediksi dan hasil, mempertahankan struktur yang lebih baik, dan mengeliminasi struktur yang lebih buruk. Apa yang dituju bersama oleh tim Zhejiang University dan Neosoul sebenarnya adalah tujuan yang sama: membuat AI tidak hanya pandai mengerjakan soal, tetapi juga memiliki kemampuan berpikir yang komprehensif dan terus berevolusi.





