Pada tanggal 18 dan 19 Maret, dua perusahaan China secara berturut-turut meluncurkan model besar mereka di bidang Agent. Perusahaan AI rintisan China, MiniMax, meluncurkan M2.7, sementara tim model besar di bawah Xiaomi, MiMo, meluncurkan V2-Pro. Kedua model tersebut masuk ke jajaran teratas global dalam benchmark Agent, tetapi harga output API mereka masing-masing hanya 1/21 dan 1/8 dari harga Claude Opus 4.6.
Kedua perusahaan mengeluarkan kartu mereka pada minggu yang sama, tetapi dengan kartu yang sangat berbeda. Mereka mewakili dua jalur teknologi yang sangat berbeda, dan bertaruh pada dua masa depan yang berbeda di era Agent.
Ujian yang Sama, Biaya 1/17
Pertama, lihat perbandingan yang paling langsung.
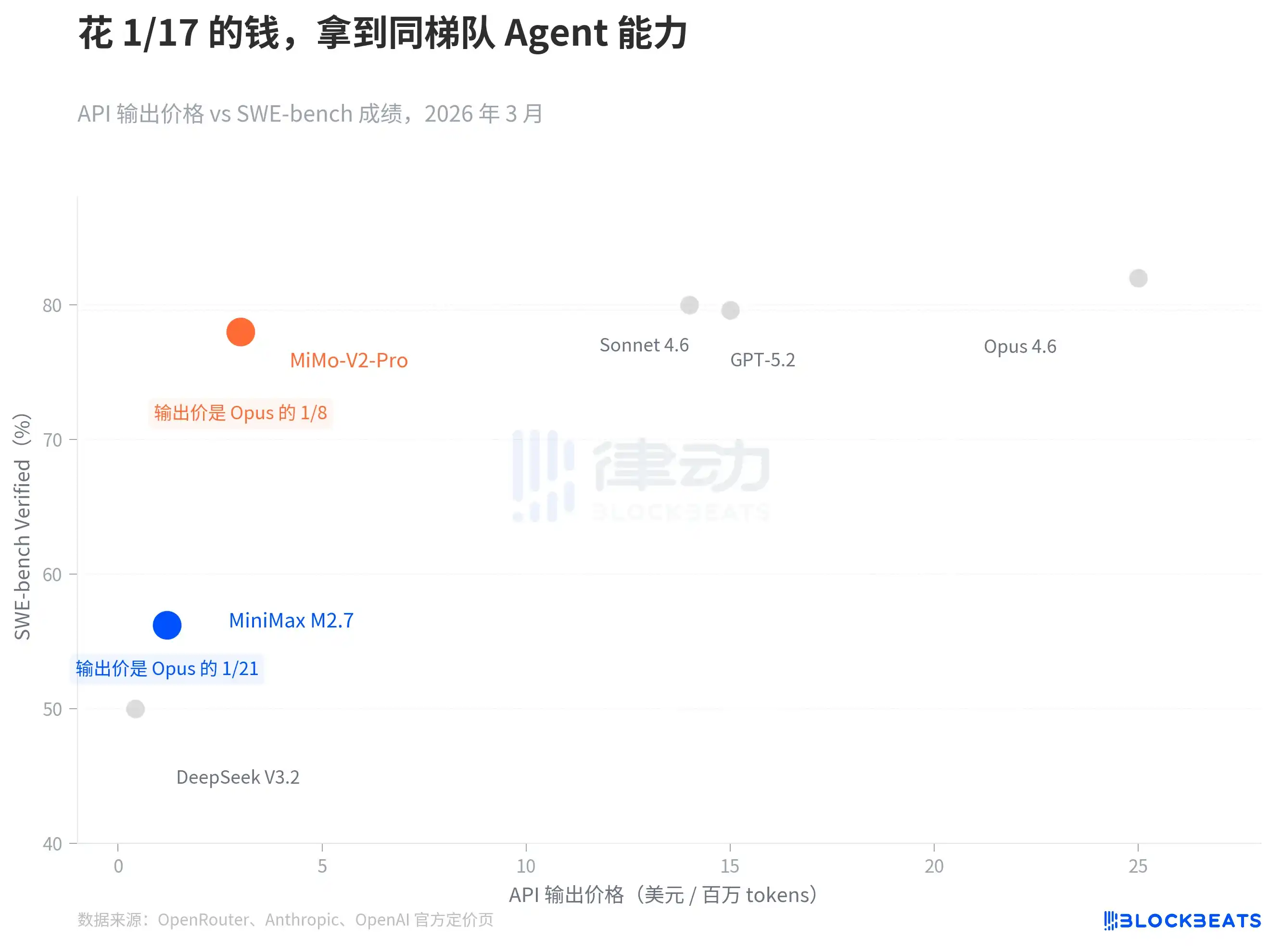
Menurut data dari OpenRouter dan halaman harga resmi masing-masing perusahaan, berdasarkan harga output API (per juta token), MiniMax M2.7 adalah $1.2, dan MiMo-V2-Pro adalah $3. Sebagai perbandingan, harga output Claude Opus 4.6 adalah $25, GPT-5.2 adalah $14, dan Claude Sonnet 4.6 adalah $15.
Perbedaan harganya sangat signifikan, tetapi perbedaan kemampuannya tidak. Dalam SWE-bench Verified (benchmark paling utama saat ini untuk mengukur kemampuan rekayasa kode), MiMo-V2-Pro mencapai 78%, sementara Sonnet 4.6 mencapai 79.6%, perbedaannya kurang dari dua persen. Skor SWE-Pro M2.7 adalah 56.22%, setara dengan GPT-5.3-Codex. Dalam VIBE-Pro (kemampuan pengiriman proyek end-to-end), M2.7 mencapai 55.6%, mendekati tingkat Opus 4.6.
Poin penting dari grafik ini bukanlah siapa yang lebih tinggi atau lebih rendah—sistem benchmark masing-masing pihak tidak sepenuhnya sejajar, jadi perbandingan langsung harus hati-hati. Poin pentingnya adalah "selisih harga-kinerja" itu: model Agent China telah memasuki pita kemampuan yang sama, tetapi berada di kisaran harga yang sangat berbeda.
Triliun Parameter vs Evolusi Diri
Harga hanyalah tampilan luar. Kedua perusahaan mengeluarkan dua set kartu yang sangat berbeda.
MiMo-V2-Pro mengambil jalur "kekuatan besar menghasilkan keajaiban". Menurut pengumuman resmi Xiaomi, V2-Pro memiliki total parameter lebih dari 1 triliun, parameter aktif 42B, dan mendukung konteks ultra-panjang hingga 1 juta token. Inovasi intinya adalah mekanisme perhatian hybrid Hybrid Attention, yang menyesuaikan rasio Sliding Window Attention (SWA) dengan Global Attention (GA) menjadi 7:1—generasi sebelumnya V2-Flash adalah 5:1. Arsitektur ini membuat model lebih stabil ketika menangani dokumen panjang dan skenario Agent yang memanggil banyak alat secara paralel. Dalam PinchBench (evaluasi kemampuan pemanggilan alat Agent), MiMo-V2-Pro mencapai 84%.
M2.7 mengambil jalur yang sangat berbeda. Menurut blog teknis resmi MiniMax yang dirilis pada 18 Maret, jumlah parameter M2.7 tidak diungkapkan, tetapi ini menunjukkan mekanisme "evolusi iterasi mandiri": model menjalankan siklus optimisasi lebih dari 100 putaran secara mandiri, termasuk menganalisis jejakalan kegagalan, merencanakan modifikasi, memodifikasi arsitektur kodenya sendiri, menjalankan evaluasi, dan mengulangi siklus, akhirnya mencapai peningkatan kinerja 30% dalam set evaluasi internal. Dalam 22 soal berkesulitan tinggi di MLE Bench Lite (evaluasi kesulitan kompetisi pembelajaran mesin), M2.7 meraih 9 emas, 5 perak, 1 perunggu, dengan rata-rata tingkat medali 66.6%.
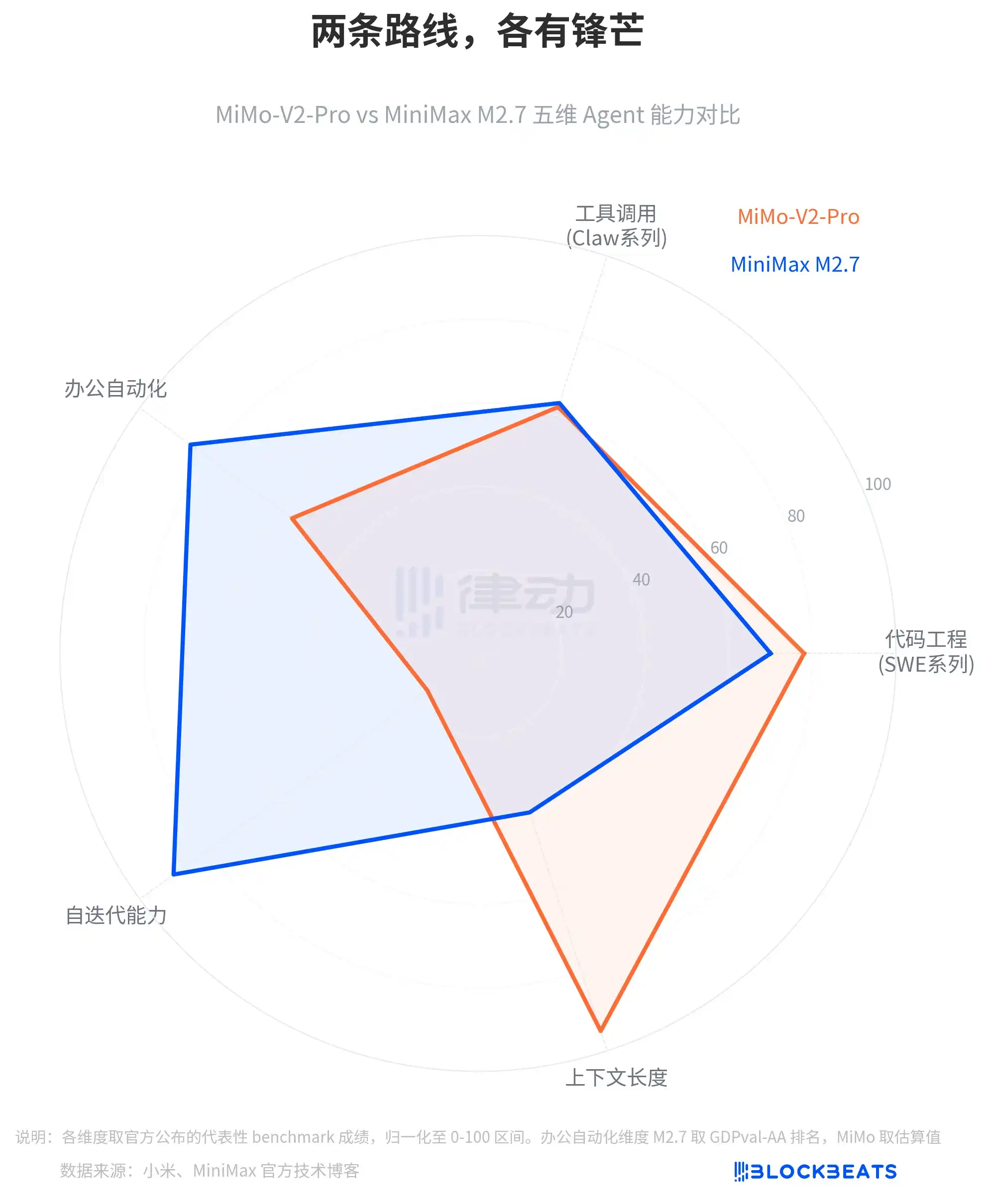
Dari lima dimensi, kedua jalur memiliki keunggulan yang sangat berbeda: MiMo-V2-Pro unggul jelas dalam panjang konteks dan dimensi rekayasa kode, sementara M2.7 unggul dalam otomatisasi perkantoran dan kemampuan iterasi mandiri. Menurut blog teknis MiniMax yang sama, M2.7 mencapai ELO 1495 dalam GDPval-AA (evaluasi pemrosesan dokumen kantor), menempati peringkat pertama model sumber terbuka, dan mempertahankan tingkat kepatuhan keterampilan 97% dalam tes MM-Claw yang mencakup lebih dari 40 keterampilan kompleks.
Empat Versi dalam Lima Bulan
Kedua perusahaan tidak hanya memiliki jalur teknologi yang berbeda, tetapi juga ritme iterasi yang sangat berbeda.
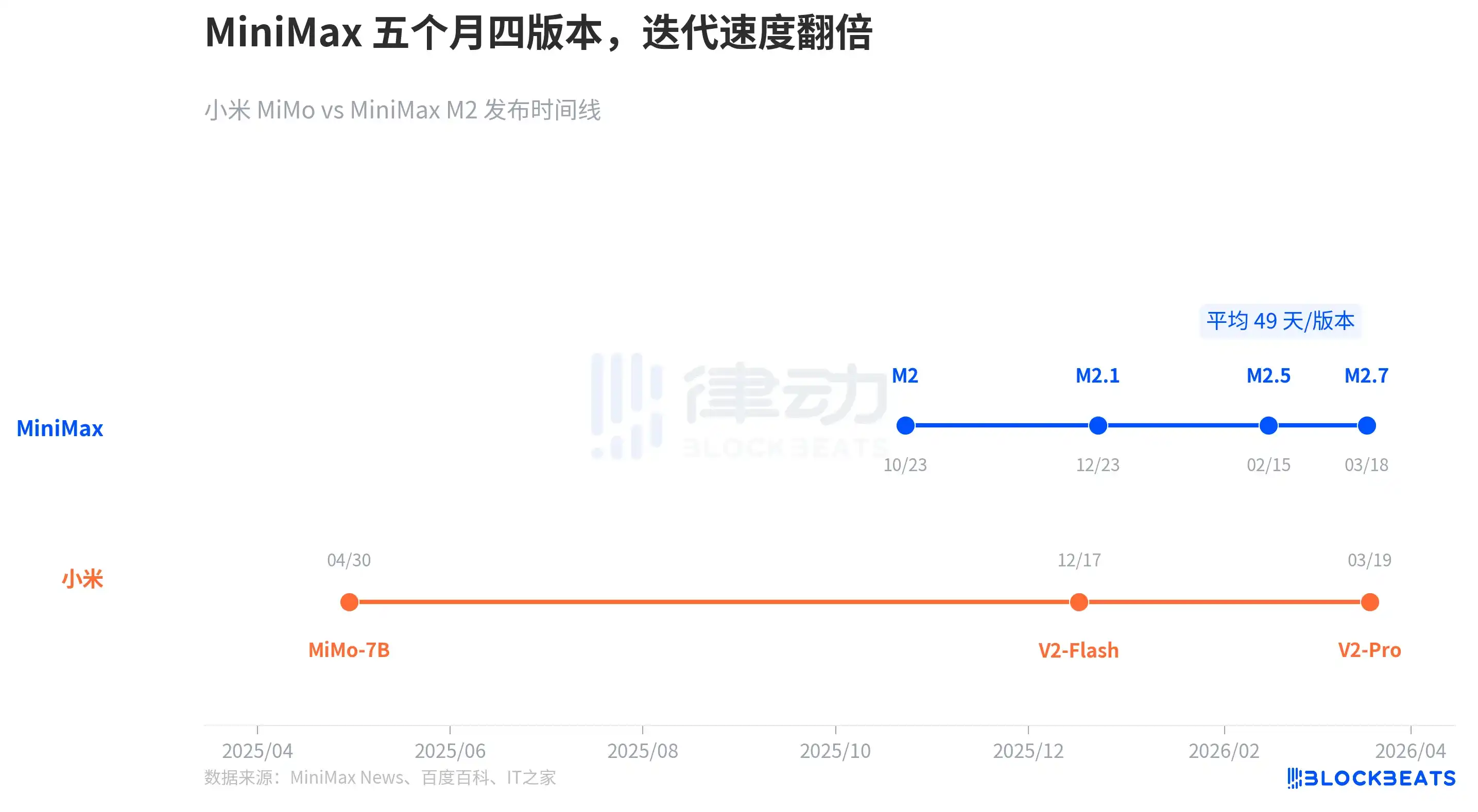
Menurut catatan rilis publik, MiniMax dari rilis M2 pada Oktober 2025 hingga rilis M2.7 pada Maret 2026, mengiterasi empat versi dalam lima bulan, rata-rata satu versi besar setiap 49 hari. Jarak antara M2.5 dan M2.7 hanya sekitar 30 hari.
Ritme Xiaomi MiMo berbeda: merilis MiMo-7B (model inferensi sumber terbuka 7B parameter) pada April 2025, merilis V2-Flash (total 309B parameter) pada Desember 2025, dan merilis V2-Pro (total 1T parameter) pada Maret 2026. Setiap generasi memiliki lompatan skala parameter yang lebih besar, tetapi interval versinya juga lebih panjang.
MiniMax memilih langkah kecil dan cepat, setiap iterasi tidak terlalu besar tetapi frekuensinya sangat tinggi, mekanisme iterasi mandiri M2.7 sendiri dirancang untuk "evolusi berkelanjutan". Xiaomi memilih serangan terkonsentrasi, setiap versi adalah lompatan besar dalam skala parameter dan arsitektur.
Anonim 8 Hari, Menduduki Puncak OpenRouter
Selain jalur teknologi, strategi rilis Xiaomi juga memecah kebiasaan industri.
Menurut laporan Reuters, pada 11 Maret, sebuah model anonim bernama Hunter Alpha muncul di platform agregasi API terbesar dunia, OpenRouter. Tanpa dukungan merek, tanpa konferensi pers, tanpa blog teknis. Harga API-nya sangat rendah, tetapi kinerjanya sangat kuat secara mengejutkan.
Komunitas mulai menebak asalnya. Menurut Republic World dan banyak media teknologi, tebakan utama adalah DeepSeek V4, karena kepala tim MiMo, Luo Fuli, sebelumnya pernah melakukan penelitian di DeepSeek. Volume panggilan dengan cepat melonjak, total volume panggilan selama periode anonim melebihi 1 triliun token, menduduki peringkat pertama dalam daftar mingguan OpenRouter.
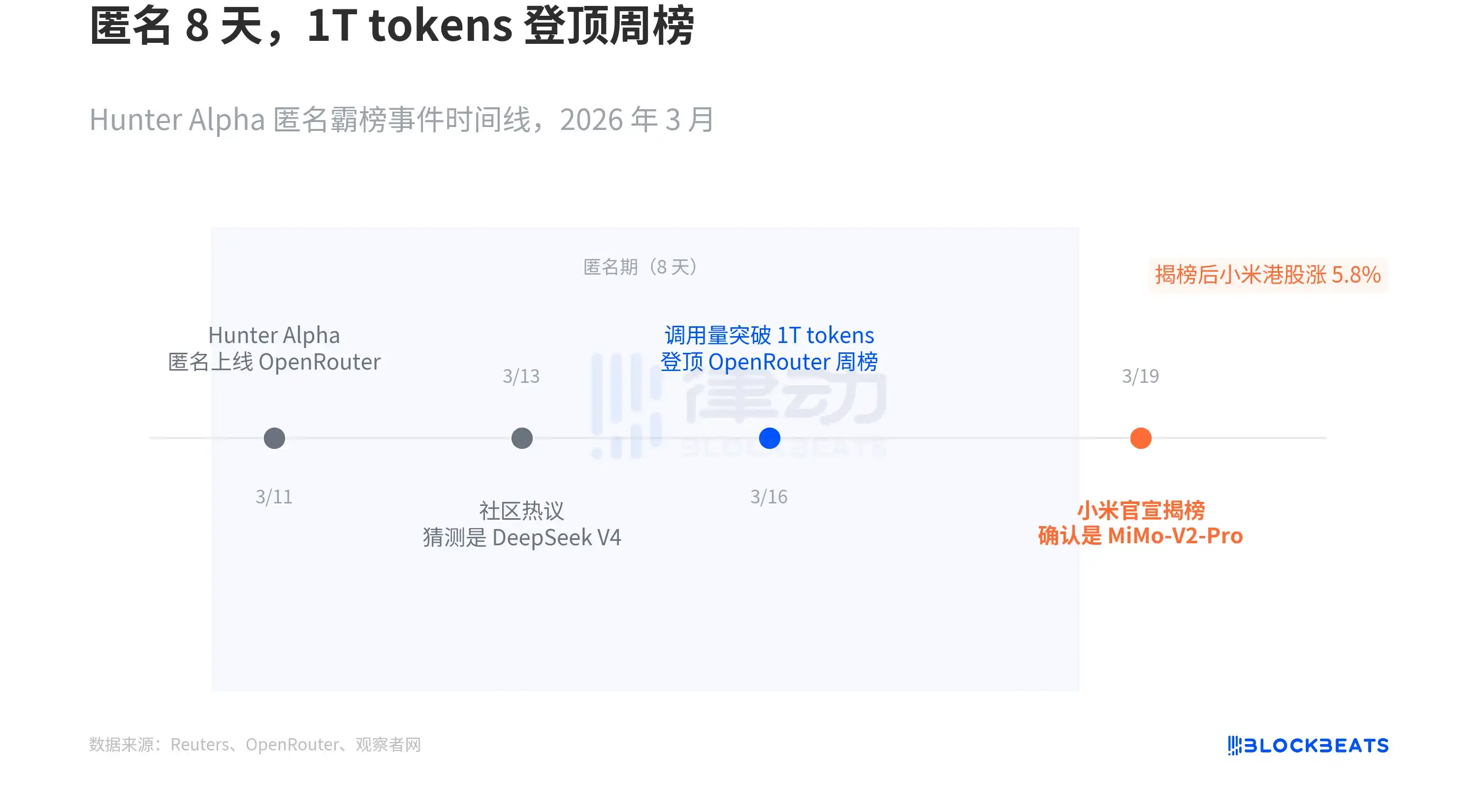
Pada dini hari 19 Maret, Xiaomi membuka tabir: Hunter Alpha adalah MiMo-V2-Pro. Menurut laporan Reuters yang sama, saham Xiaomi di Hong Kong sempat naik 5.8% setelah pengumuman.
Ini adalah pertama kalinya model besar China membuktikan dirinya di platform global dengan cara uji buta murni. Tanpa mengandalkan merek, tanpa promosi, memberikan waktu 8 hari bagi pengembang untuk memilih dengan kaki mereka.






