Redaksi Jiwa Mesin
Model baru Gemma 4 yang baru saja dibuat open source oleh Google beberapa hari lalu, memberikan kejutan besar bagi industri.
Ia mengadopsi arsitektur teknologi yang sama dengan Gemini 3, mendukung multimodalitas asli, meraih peringkat ketiga global di Arena AI Leaderboard, dan memiliki beberapa model yang dapat dipilih. Beberapa model yang lebih kecil —— E2B (parameter efektif 2.3B) dan E4B (parameter efektif 4.5B)—— dapat langsung di-deploy dan dijalankan secara lokal di perangkat seluler, dengan jendela konteks mencapai 128K, bisa dibilang "pengganti Gemini yang bisa dimasukkan ke dalam saku".
Seperti yang diduga, model ini dengan cepat menjadi mainan baru bagi pengguna ponsel.
Di antaranya, sebuah postingan oleh pengguna X dikunjungi ratusan ribu kali. Dalam postingannya, dia memasang sebuah video yang menceritakan bagaimana dia menjalankan Gemma 4 secara lokal di iPhone, termasuk memproses gambar, audio, dan mengontrol sakelar senter. Dia menyatakan bahwa Gemma 4 sangat cepat, terasa seperti sihir.

Seorang pengguna mengukur kecepatan ini di iPhone 17 Pro, mencatat bahwa jika ponsel menggunakan chip Apple, maka dengan bantuan MLX (framework machine learning Apple) yang dioptimalkan untuk chip ini, kecepatan inferensi model dapat melebihi 40 token / detik.

Ada juga yang mendapatkan kecepatan serupa di Samsung Galaxy, dan itu pun dalam mode pemikiran yang diaktifkan. Hal ini membuat orang berkomentar "terlalu cepat, tidak nyata".
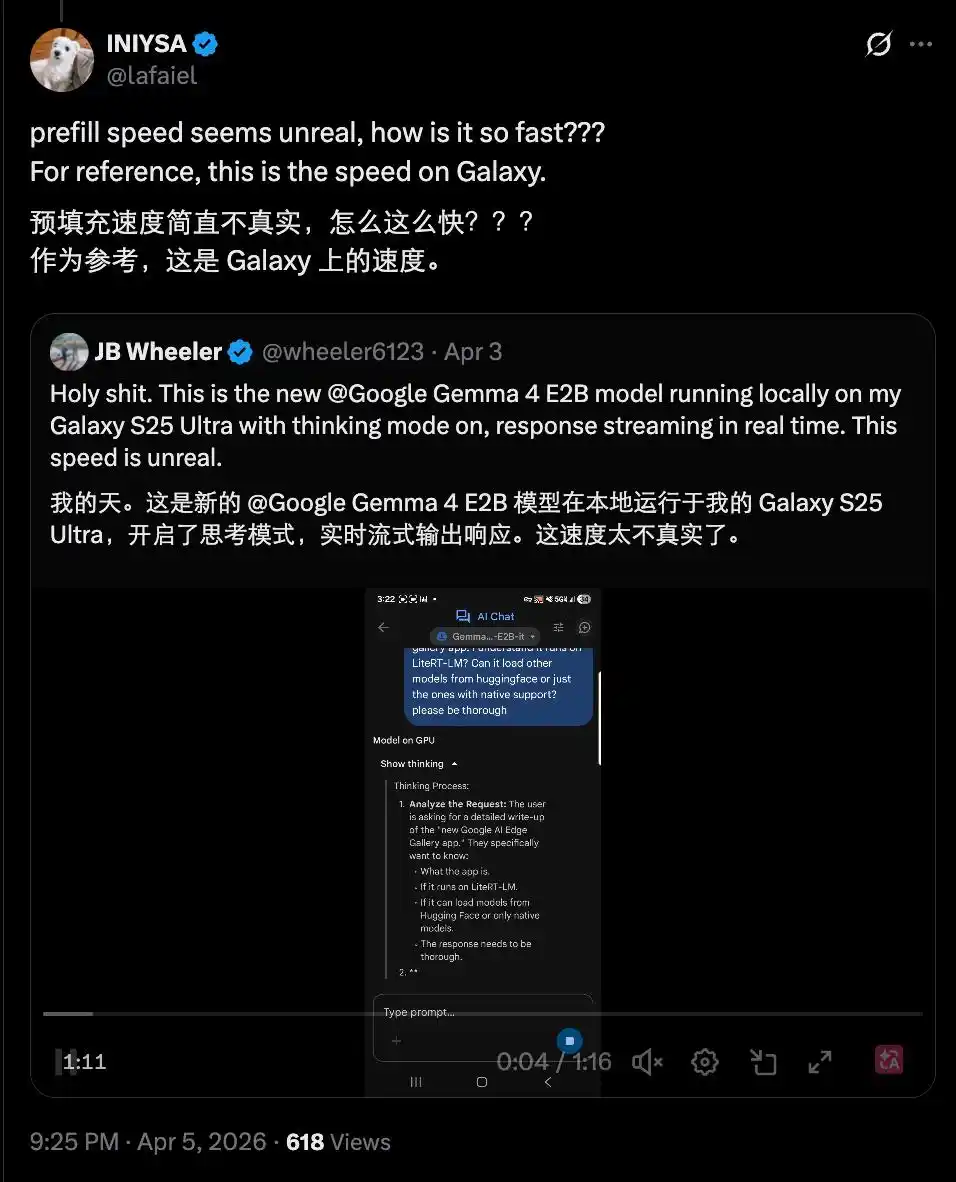
Kecepatan seperti ini membuat menjalankan model AI di perangkat seluler menjadi opsi yang dapat diterima di masa depan, dan sangat berguna dalam skenario sensitif seperti medis.
Jendela konteks 128k juga membuat model-model kecil ini menjadi lebih menarik.
Lalu, bagaimana cara menjalankannya? Sebenarnya sangat sederhana, bukan hanya untuk geek, karena Google merilis App resmi——Google AI Edge Gallery. Yang ingin mencoba di ponsel dapat langsung mengunduh App ini, lalu mengunduh versi model yang ingin dijalankan, setelah itu buka dan langsung bisa dijalankan.

Dan, karena dirilis resmi oleh Google, masalah keamanan tentu juga tidak perlu terlalu dikhawatirkan.
Selain model-model kecil yang dijalankan di perangkat seluler ini, ada juga yang mencoba versi Gemma 4 yang lebih besar di perangkat keras yang lebih kuat, seperti menjalankan Gemma 4 Mixture-of-Experts 26B di MacBook Pro versi M5 Pro.

Jika untuk percakapan langsung, kecepatan model ini masih cukup cepat, pembuatan teks, penjelasan kode, semuanya lancar.

Tetapi ketika dia benar-benar menggunakan Gemma 4 sebagai coding agent, masalah pun muncul. Karena menjalankan agent membutuhkan konteks yang besar (Gemma 4 26B memiliki jendela konteks 256k), prompt yang kompleks, dan pemanggilan alat yang stabil, Gemma 4 jelas tidak tahan di tempat-tempat ini, sering macet, error, atau output strukturnya tidak benar.

Titik balik terjadi ketika dia mengganti model dengan qwen3-coder, dalam lingkungan yang sama, pembuatan file, eksekusi perintah, tugas multi-langkah semua dapat berjalan normal. Dia berpendapat, masalahnya bukan pada framework agent, tetapi pada apakah model itu sendiri telah dioptimalkan untuk "pemanggilan alat + output terstruktur". Dalam hal ini, Gemma 4 mungkin belum cukup, atau mungkin pengembang ini belum menemukan cara yang benar.

Selain itu, ada yang mengatakan bahwa tingkat kecerdasan Gemma 4 masih agak setengah-setengah.
Meskipun demikian, kemunculan Gemma 4 sebagai "performance powerpack" ini tetap tidak boleh diremehkan. Jika nanti banyak tugas kueri sehari-hari, obrolan, penalaran sederhana, pembuatan kode, pemahaman gambar dapat dijalankan secara lokal, tidak perlu lagi membeli token, bukankah produsen yang menjual token akan berada dalam posisi yang canggung?
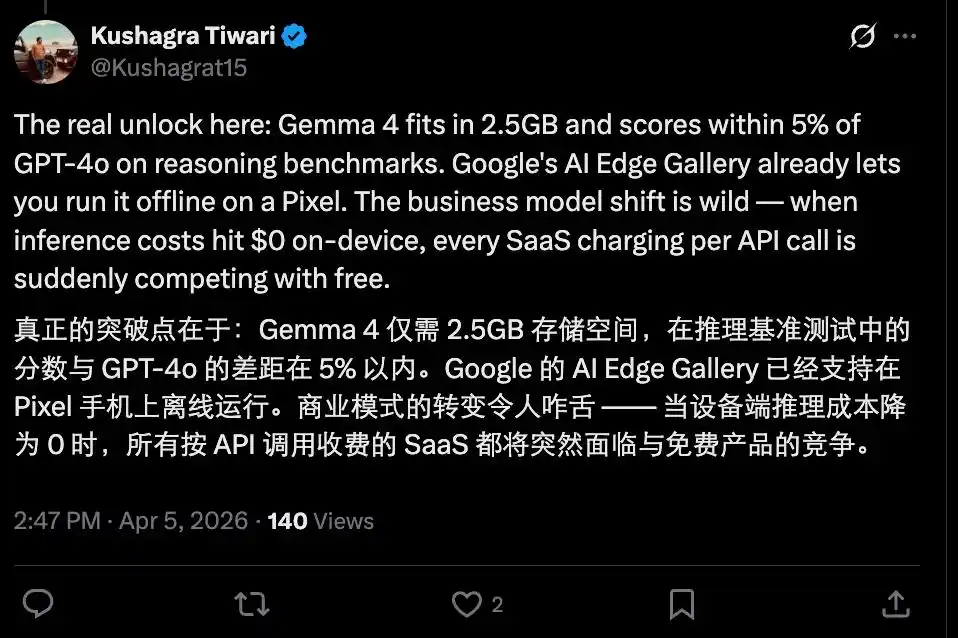
Tentu saja, situasi saat ini belum begitu suram, mengingat masih ada kesenjangan antara model yang dibuat open source saat ini dengan model tertutup flagship terdepan, dan sebagian besar model open source yang tangguh masih dibatasi oleh kemampuan perangkat keras, untuk sementara belum bisa mencapai tingkat yang dapat digunakan di sisi perangkat (edge).
Namun tren masa depan jelas. Dalam jangka pendek, model tertutup cloud masih unggul dalam penalaran kompleks paling mutakhir dan kolaborasi multi-agent skala sangat besar; tetapi dalam jangka panjang, ketika perangkat keras terus berkembang, teknologi kuantisasi terus dioptimalkan, model sisi perangkat akan secara bertahap menggerogoti tugas-tugas sederhana yang frekuen di cloud.
Para vendor yang hanya mengandalkan penjualan token, langganan API, akan terpaksa lebih keras bersaing di bagian yang "benar-benar sulit" —— Agent yang super kuat, konteks yang andal dan sangat panjang, serta kemampuan khusus yang membutuhkan data real-time dalam jumlah besar.
Gemma 4 hanyalah sebuah awal. Kejutan berikutnya, mungkin adalah suatu model sisi perangkat yang dalam penggunaan sehari-hari membuat pengguna sama sekali tidak merasakan perbedaan "lokal" dan "cloud". Pada hari itu tiba, seluruh model bisnis industri AI, akan menyambut sebuah perombakan yang sesungguhnya.
Artikel ini dari akun WeChat resmi "Jiwa Mesin" (ID:almosthuman2014), penulis: Jiwa Mesin






