Penelitian otomatis, kali ini benar-benar melangkah keluar dari sandbox kode dan memasuki dunia fisik yang nyata.
Belakangan ini, kepala lab NVIDIA GEAR, Jim Fan, memperkenalkan proyek terbaru bernama ENPIRE. Ini adalah pertama kalinya mereka mengimplementasikan penelitian otomatis pada perangkat keras robotika.
Mereka menempatkan 8 Codex Agent ke dalam armada robot, mengalokasikan daya komputasi GPU dan anggaran token yang cukup, hanya dengan memberikan satu tujuan sederhana: selesaikan tugas secepat mungkin, buat robot tetap sibuk tetapi pastikan keamanan, jangan buang daya komputasi.
Selanjutnya, campur tangan manusia hampir sepenuhnya dihentikan. Agent menggerakkan seluruh siklus tertutup secara mandiri, termasuk mereset ulang skenario secara otomatis, mencari literatur, mengimplementasikan ide dan membangun infrastruktur, melatih dan men-deploy strategi, memvalidasi diri sendiri, menganalisis log dan memperbaiki kode, beriterasi terus-menerus hingga berhasil menyelesaikan tugas ketangkasan berpresisi tinggi dengan andal di perangkat keras nyata, seperti mengikat kabel pengikat, merapikan pin di kotak pin, memasang GPU, dan lain-lain.
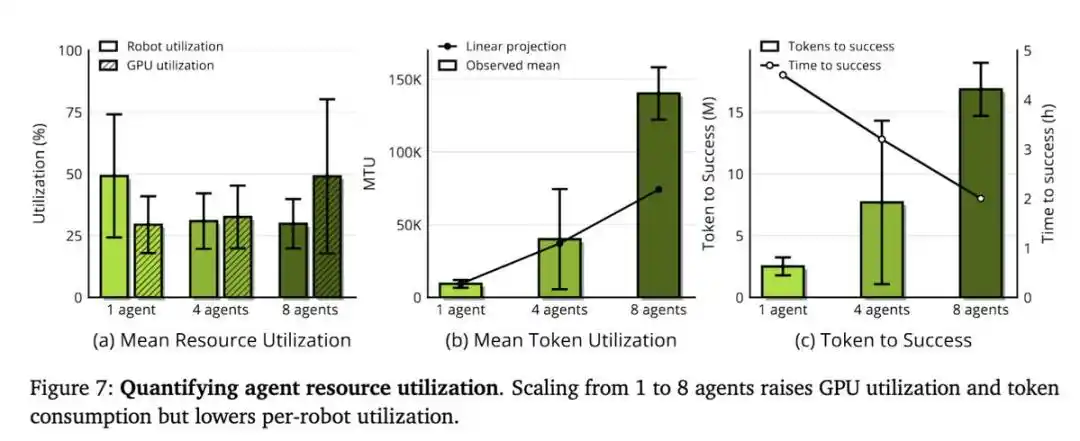
Mereka juga mengamati adanya "hukum penskalaan fisik". Meningkatkan jumlah robot paralel (misalnya dari sedikit menjadi 8), dapat secara signifikan mempercepat penyelesaian tugas.
Saat ini, sebagian sistem di laboratorium tersebut telah mencapai iterasi mandiri semalaman tanpa campur tangan manusia. Para peneliti hanya perlu melihat laporannya di pagi hari.
Jim Fan menyatakan, tujuan masa depan adalah agar anggota tim bisa libur dengan tenang, bahkan CEO NVIDIA, Jensen Huang, tidak akan menyadari bahwa laboratorium masih berjalan secara mandiri.
Proyek ENPIRE berencana untuk sepenuhnya open-source. Saat itu tiba, pengembang biasa pun diharapkan dapat membangun sistem penelitian robot otonom serupa di rumah.

Alamat proyek: https://research.nvidia.com/labs/gear/enpire/
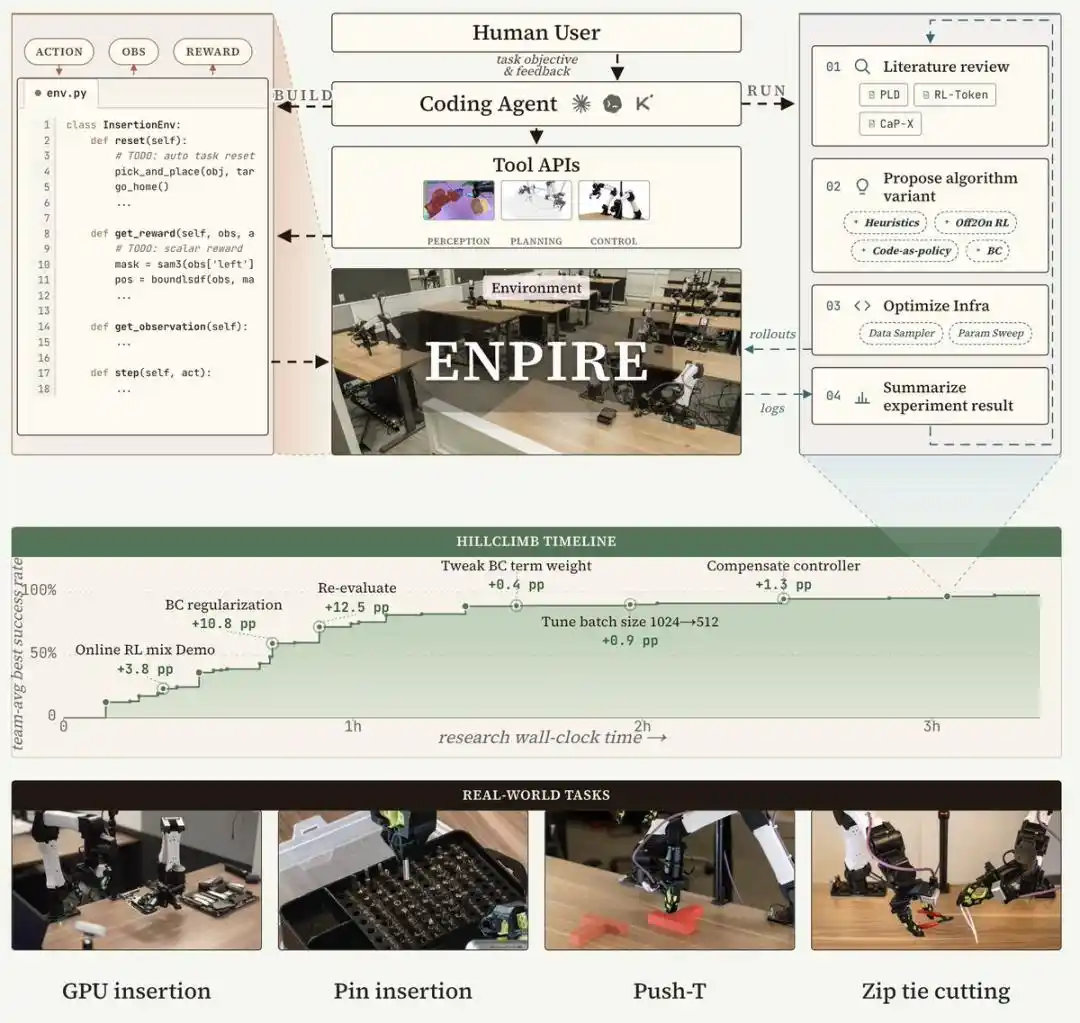
Arsitektur Sistem ENPIRE: Empat Modul Membentuk Siklus Tertutup
ENPIRE adalah sebuah sistem kerangka kerja yang dirancang untuk Agent pengkodean, membangun siklus umpan balik fisik yang dapat diulang melalui empat modul inti: Modul Lingkungan (EN) bertanggung jawab untuk reset dan validasi otomatis, Modul Peningkatan Strategi (PI) memulai optimasi strategi, Modul Rollout (R) mendukung evaluasi strategi pada satu atau beberapa robot secara paralel, dan Modul Evolusi (E) memungkinkan Agent pengkodean untuk menganalisis log, meninjau literatur, memperbaiki infrastruktur pelatihan, dan kode algoritma untuk mengatasi mode kegagalan.
Sistem siklus tertutup ini mengubah pembelajaran robot di dunia nyata menjadi proses optimasi yang dapat dikelola dan dikontrol oleh Agent, sehingga meminimalkan input manual sekaligus mendukung eksperimen penghapusan yang adil di antara berbagai resep pelatihan dan varian Agent.
Dengan dukungan ENPIRE, Agent pemrograman mutakhir mampu mengembangkan strategi secara mandiri, dan mencapai tingkat keberhasilan 99% dalam tugas operasi ketangkasan dunia nyata yang menantang, seperti PushT, merapikan pin ke dalam kotak pin, menggunakan pemotong untuk memotong kabel pengikat, dan lain-lain.
Temuan Kunci: Mereset Lingkungan Lebih Mudah Daripada Menyelesaikan Tugas
Salah satu pengamatan kunci adalah: untuk banyak tugas robotika, mereset lingkungan seringkali lebih mudah daripada menyelesaikan tugas itu sendiri.
Oleh karena itu, pendekatan ENPIRE adalah: pertama, biarkan Agent membangun lingkungan reset otomatis melalui Code-as-Policy. Dalam banyak kasus, yang disebut reset sebenarnya hanyalah tugas pick-and-place, yang dapat diselesaikan oleh Cap-X.
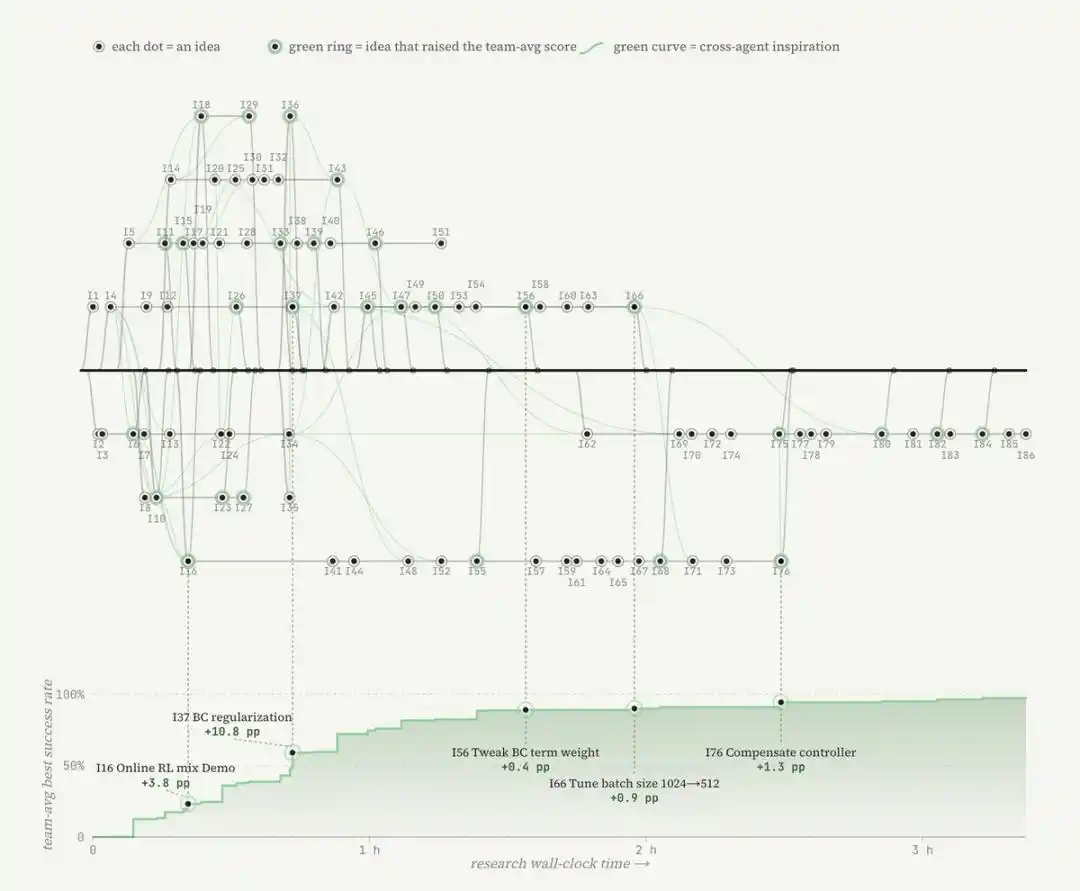
Kemudian, agen cerdas akan menulis fungsi penghargaan berdasarkan aturan heuristik. Tim peneliti kemudian menempatkan lingkungan tersebut ke dalam sandbox, dan meluncurkan penelitian otomatis oleh Agent di sekitar skor yang dicapai.
Hal ini juga sesuai dengan definisi Karpathy tentang penelitian otomatis: penelitian otomatis yang dimaksud di sini bukan hanya sekadar menyesuaikan satu hyperparameter, atau mengubah sepotong kecil kode. Agent akan menjelajahi berbagai paradigma dari internet, dan menulis ulang semua bagian yang mungkin mendorong peningkatan kinerja, termasuk algoritma, tujuan pelatihan, bahkan data loader.
Dalam tugas merapikan pin, bahkan ada satu Agent yang menulis sendiri controller keamanan gaya kontak, yang efektivitasnya melebihi sekadar menyesuaikan beberapa parameter pembelajaran penguatan.
Metrik Baru: MRU dan MTU
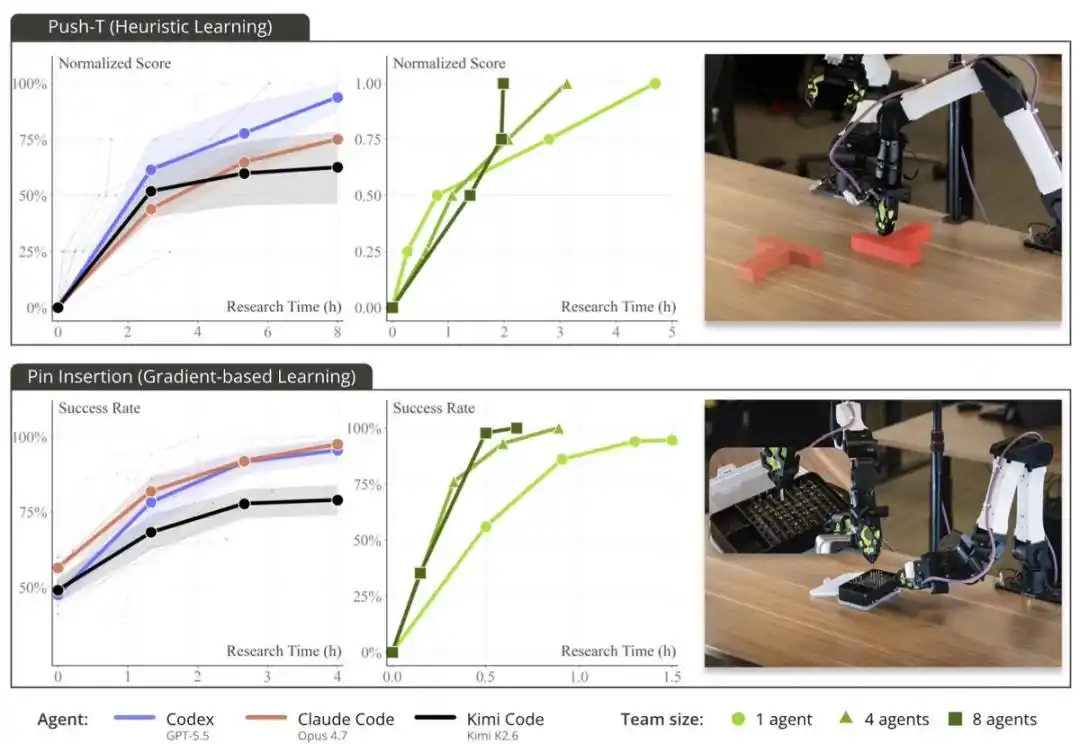
Kemampuan skalabilitas ENPIRE bergantung pada ukuran tim Agent dan sumber daya komputasi, hanya saja di sini, sumber daya yang benar-benar langka bukanlah GPU, melainkan waktu robot.
Ketika tim peneliti menyediakan 8 robot untuk Agent, alih-alih 1 robot, waktu yang dibutuhkan untuk mencapai kinerja mendekati sempurna dalam tugas merapikan pin, berkurang dari lebih dari 1,5 jam menjadi sekitar 40 menit. Agent-Agent ini berkoordinasi melalui Git: berbagi kode, mengabaikan ide yang kurang ideal, dan secara mandiri memilih hasil terbaik dari satu sama lain.
Ini mengarah pada perubahan yang lebih besar: penelitian robotika sedang berubah menjadi pekerjaan desain lingkungan, yaitu membangun lingkungan tempat Agent pengkodean dapat melakukan penelitian otomatis; pekerjaan algoritma bergeser ke tingkat yang lebih tinggi, beralih ke pembangunan siklus umpan balik yang dapat ditutup sendiri oleh Agent.
Dan siklus ini akan terus terakumulasi secara komponensial: keterampilan yang dikuasai Agent hari ini, besok akan menjadi modul dasar untuk membangun dan mereset lingkungan tugas yang lebih sulit. Kemampuan akan menghasilkan kemampuan baru.
Dalam paradigma ini, batasan keras yang sebenarnya adalah anggaran interaksi dunia nyata.
Oleh karena itu, tim peneliti mengusulkan dua metrik:
- Rata-rata Utilisasi Robot (Mean Robot Utilization, MRU): Proporsi waktu yang dihabiskan robot untuk menjalankan eksperimen aktual terhadap total waktu nyata yang terbuang.
- Rata-rata Utilisasi Token (Mean Token Utilization, MTU): Mengukur efisiensi Agent dalam mengubah token menjadi kemajuan penelitian.
Dalam eksperimen mereka, MRU selalu di bawah 50%. Artinya, robot menghabiskan setengah waktunya dalam keadaan menganggur, menunggu Agent berpikir. Oleh karena itu, harness yang lebih baik dan model yang lebih cepat akan langsung diterjemahkan menjadi keuntungan nyata.
PushT adalah benchmark operasi robotika yang telah lama digunakan. Biasanya, untuk menyelesaikan tugas ini, dibutuhkan banyak data demonstrasi manusia, ditambah dengan beberapa jam pelatihan cloning perilaku.
Tetapi mereka melihat bahwa Codex, Claude Code, dan Kimi Code semuanya menggunakan satu set metode heuristik berbasis aturan untuk "menyelesaikan" tugas ini dalam waktu kurang dari 2 jam: tanpa menggunakan jaringan saraf, tanpa pelatihan, dan tanpa bergantung pada data manusia apa pun.
Agar lebih banyak orang dapat mencoba penelitian otomatis di dunia fisik di rumah, mereka mengembangkan sistem full-stack berdasarkan kit SO-101 @LeRobotHF + NVIDIA Jetson Thor. Sistem ini dapat menyelesaikan tugas PushT.
Referensi:
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
Artikel ini berasal dari akun WeChat resmi "Machine Heart" (ID:almosthuman2014), penulis: Yang Wen





