Tepat saat ini, Anthropic secara resmi meluncurkan model baru Claude Sonnet 5, menyebutnya sebagai "model Sonnet yang paling memiliki atribut Agen sejauh ini", yang dapat merencanakan, menggunakan alat seperti browser, terminal, dan berjalan secara mandiri pada tingkat yang beberapa bulan lalu masih memerlukan model yang lebih besar dan lebih mahal.
Sonnet 5 menunjukkan peningkatan kinerja yang signifikan dibandingkan Sonnet 4.6 dalam penalaran, penggunaan alat, pemrograman, dan pekerjaan berbasis pengetahuan, lebih mendekati Opus 4.8, tetapi dengan harga yang lebih rendah.
Secara resmi, untuk para pengembang, era AI Agent dimulai dari model level Sonnet: Claude Sonnet 3.5, 3.6, dan 3.7 adalah model pertama yang menunjukkan kemampuan yang mencolok dalam pemrograman dan penggunaan alat. Namun, belakangan ini, peningkatan kemampuan Agen yang paling jelas terutama muncul pada model level Opus.
Dan Claude Sonnet 5 secara jelas memperkecil kesenjangan ini: kinerjanya sudah mendekati Opus 4.8, tetapi harganya lebih rendah. Dibandingkan dengan generasi sebelumnya Sonnet 4.6, terdapat peningkatan signifikan pada dimensi kunci kinerja agen seperti penalaran, penggunaan alat, pemrograman, dan pekerjaan berbasis pengetahuan. Perbandingan spesifiknya seperti gambar di bawah ini:
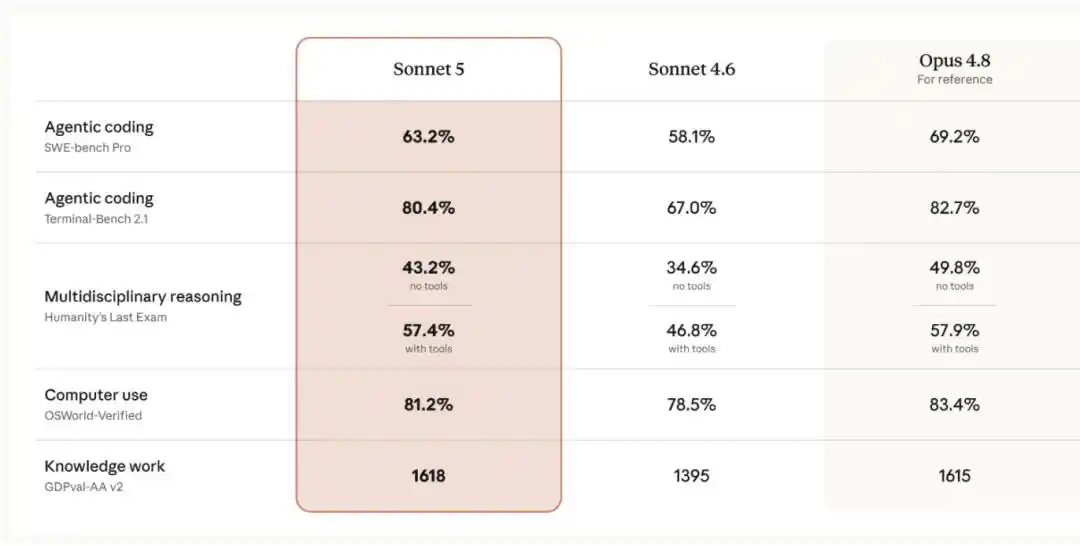
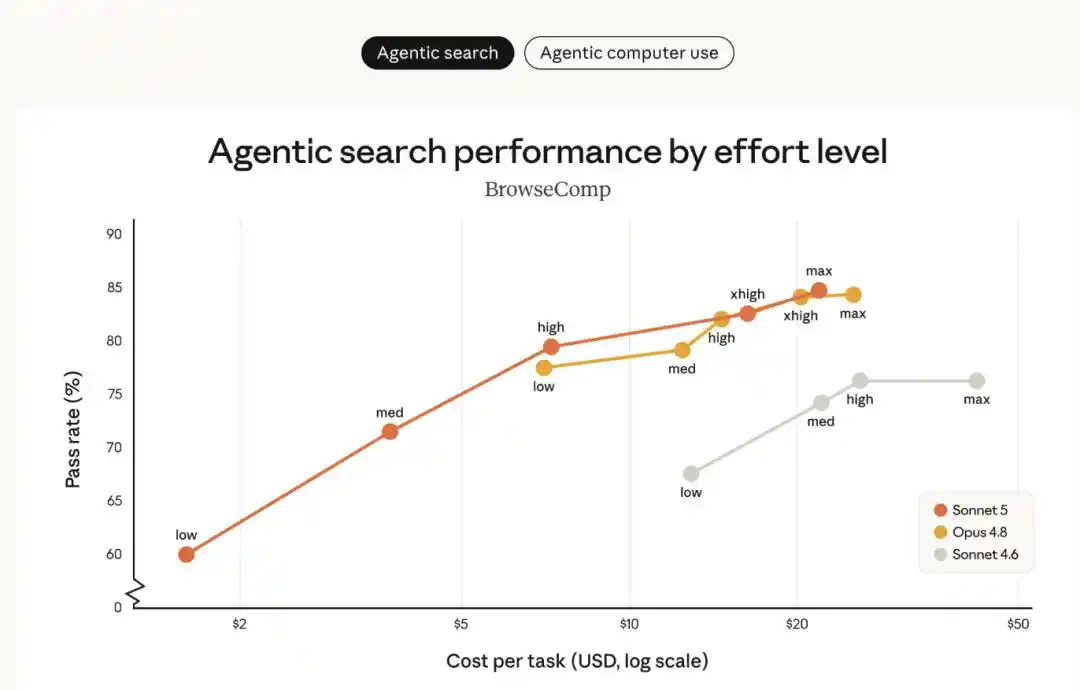
Gambar di bawah ini membandingkan Sonnet 5 dengan Sonnet 4.6, Opus 4.8 dalam evaluasi pencarian agen BrowseComp dan evaluasi penggunaan komputer OSWorld‐Verified, pada berbagai tingkat "upaya" yang berbeda:
- Sonnet 5 (garis oranye) memiliki peningkatan kinerja yang jelas dibandingkan Sonnet 4.6 (garis abu-abu), dan mencakup rentang pilihan kinerja-biaya yang lebih luas daripada Opus 4.8 (garis kuning).
- Pada tingkat upaya menengah, Sonnet 5 secara signifikan meningkatkan efisiensi biaya; pada tingkat upaya yang lebih tinggi, kinerjanya dalam beberapa tugas dapat menyaingi Opus 4.8.
- Antara Sonnet 5 dan Opus 4.8, pengguna dapat menyesuaikan tingkat upaya secara fleksibel sesuai dengan tugas spesifik, untuk menemukan titik keseimbangan biaya dan kinerja yang paling sesuai dengan kebutuhan mereka.
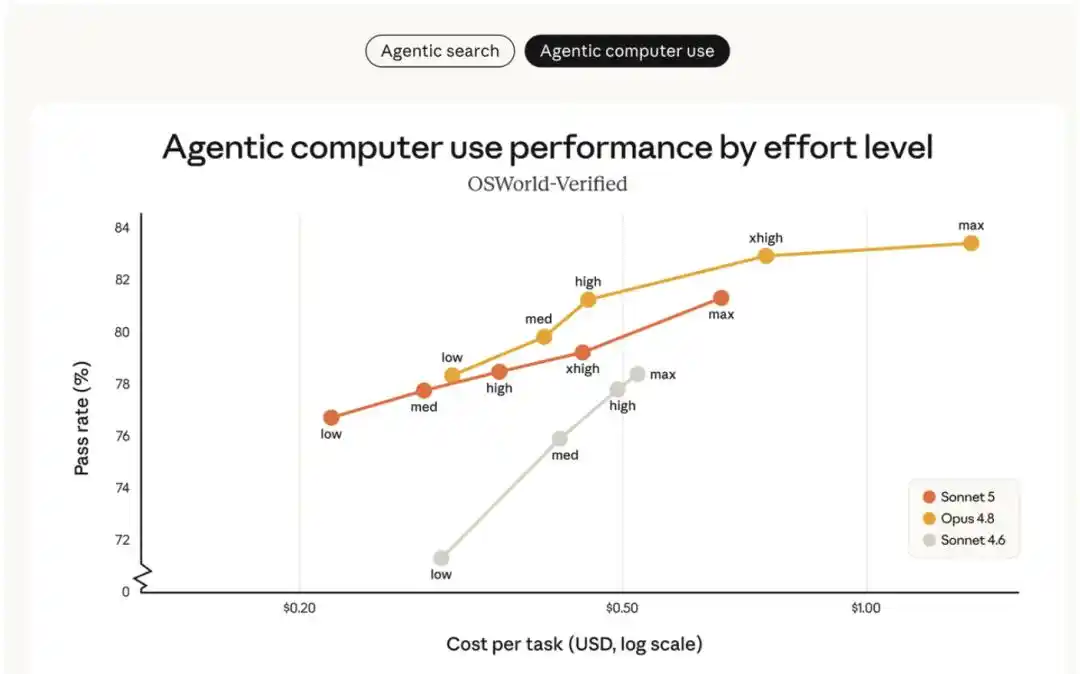
Kurva biaya-kinerja pada tingkat upaya yang berbeda seperti yang ditunjukkan pada gambar di atas. Model Sonnet terbaik sebelumnya (Sonnet 4.6) jauh tidak mencapai Opus 4.8. Sonnet 5 menyediakan pilihan biaya-kinerja yang lebih luas daripada Sonnet 4.6, dan dalam beberapa kasus dapat mencapai tingkat kemampuan Opus 4.8. Harga Sonnet 5 yang ditampilkan dalam grafik adalah input $3 / juta token, output $15 / juta token. Melalui harga perkenalan sebelum 31 Agustus (input $2 / juta token, output $10 / juta token), biaya aktual Sonnet 5 bahkan lebih rendah daripada yang ditampilkan dalam gambar. Harga Opus 4.8 adalah input $5 / juta token, output $25 / juta token.
Umpan balik dari mitra akses awal Anthropic konsisten: Sonnet 5 lebih memiliki kemampuan agen otonom (agentic) dibandingkan model generasi sebelumnya. Penguji menggambarkan bahwa ia dapat menyelesaikan tugas kompleks — di mana model Sonnet sebelumnya akan berhenti di tengah jalan pada tugas-tugas ini; ia akan secara aktif memeriksa outputnya sendiri, tanpa perlu prompt eksplisit; dan ia melakukan semua pekerjaan agen ini dengan harga yang sangat menarik:
Evaluasi Keamanan
Evaluasi keamanan pra-penerapan Anthropic menemukan bahwa, Secara keseluruhan, Sonnet 5 mengalami perbaikan dibandingkan Sonnet 4.6. Dalam hal keamanan agen otonom, model ini lebih baik dalam menolak permintaan berbahaya dan menangkis upaya peretasan dalam serangan injeksi prompt. Tingkat halusinasi dan perilaku menjilat model keduanya lebih rendah daripada Sonnet 4.6. Dalam audit perilaku otomatis (menguji berbagai perilaku salah seperti membantu penyalahgunaan dan penipuan), Sonnet 5 mendapat skor lebih rendah (yaitu lebih aman).
Namun, dibandingkan dengan Opus 4.8 dan Claude Mythos Preview yang lebih mampu, model ini memang menunjukkan tingkat perilaku salah yang sedikit lebih tinggi dalam evaluasi ini.
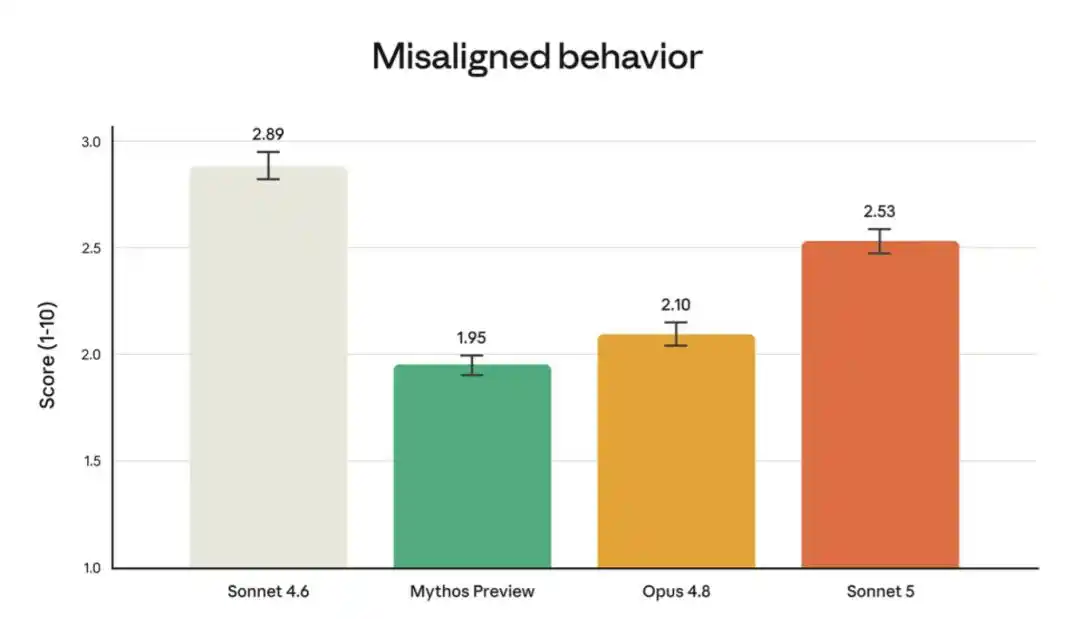
Gambar di atas menunjukkan tingkat perilaku salah dalam audit perilaku otomatis, yang menguji sejumlah besar perilaku buruk dalam berbagai situasi dan konteks (daftar lengkap dan hasil setiap perilaku lihat bagian 6.4 Kartu Sistem Sonnet 5). Tingkat perilaku salah Sonnet 5 secara keseluruhan lebih rendah daripada Sonnet 4.6, tetapi lebih tinggi daripada Mythos Preview dan Opus 4.8.
Anthropic menyatakan, Mereka tidak secara sengaja melatih Sonnet 5 untuk tugas keamanan siber. Ia dapat melakukan beberapa tugas jaringan rutin dan tidak berbahaya, tetapi dalam mengevaluasi keterampilan jaringan yang berpotensi berbahaya (seperti mengembangkan eksploitasi kerentanan perangkat lunak), kinerjanya jauh lebih rendah daripada model seperti Opus 4.8 dan Mythos 5.
Gambar di bawah menunjukkan skor salah satu evaluasi, yang menguji kemampuan model untuk mengembangkan eksploitasi kerentanan browser Firefox. Sonnet 5 secara konsisten gagal mengembangkan eksploitasi yang lengkap dan dapat digunakan, tetapi tingkat keberhasilan sebagiannya sedikit lebih tinggi daripada Sonnet 4.6. Peningkatan yang terakhir mungkin berasal dari peningkatan kecerdasan umum, bukan pelatihan spesifik.
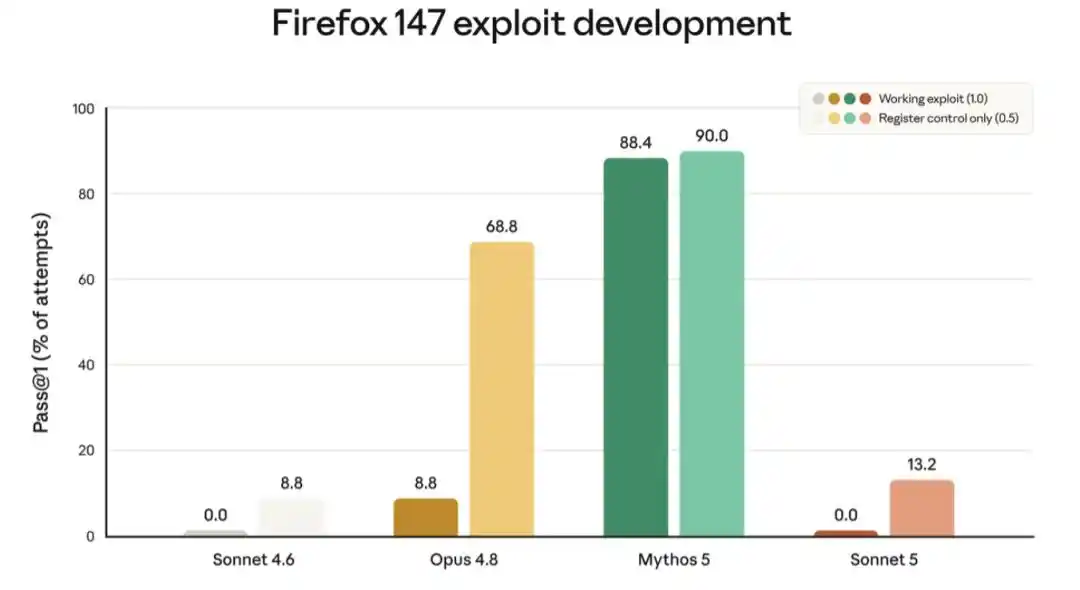
Gambar di atas menunjukkan skor model dalam berhasil mengembangkan eksploitasi untuk kerentanan perangkat lunak di Firefox 147 (evaluasi ini dikembangkan bekerja sama dengan Mozilla; semua kerentanan telah diperbaiki di Firefox 148). Untuk setiap model, grafik batang kiri menunjukkan frekuensi model (tanpa pembatas keamanan) mengembangkan program yang dapat dieksploitasi, grafik batang kanan menunjukkan frekuensi keberhasilan sebagian. Kedua model Sonnet gagal mengembangkan program yang dapat dieksploitasi (skor 0,0% untuk keduanya); tingkat keberhasilan sebagian Sonnet 5 sedikit lebih tinggi daripada Sonnet 4.6. Kemampuan jaringan kedua model Sonnet jauh lebih lemah daripada Opus 4.8 dan Mythos 5.
Karena Sonnet 5 sedikit lebih kuat dalam tugas-tugas ini dibandingkan pendahulunya, Anthropic telah mengaktifkan pembatas keamanan siber secara default. Pembatas ini — yang dapat mendeteksi dan memblokir penggunaan jaringan yang berbahaya secara real-time — sama dengan yang ada di Claude Opus 4.7 dan 4.8 (karena Anthropic menilai risiko keamanan siber keseluruhan Sonnet 5 rendah, pembatasnya kurang ketat daripada yang diaktifkan untuk Fable 5 — yang akan memblokir tugas keamanan siber yang lebih luas).
Laporan evaluasi lengkap Anthropic untuk Sonnet 5 pada berbagai penilaian keamanan dan kemampuan, lihat Kartu Sistem Claude Sonnet 5.
Penetapan Harga
Mulai hari ini, Claude Sonnet 5 telah resmi tersedia di semua saluran. Untuk merayakan peluncuran, Anthropic menawarkan harga promosi terbatas:
- Mulai sekarang hingga 31 Agustus 2026: input $2 / juta token, output $10 / juta token
- Setelah itu kembali ke harga standar: input $3 / juta token, output $15 / juta token
Sementara itu, mereka mengumumkan kenaikan menyeluruh batas kecepatan (rate limits) untuk Chat, Cowork, Claude Code, dan platform Claude, untuk mengakomodasi konsumsi token yang lebih besar yang dibawa oleh mode "upaya" yang lebih tinggi.
Hal-hal yang Perlu Diperhatikan
Verifikasi Keamanan Siber
Sonnet 5 telah dimasukkan ke dalam "Program Verifikasi Keamanan Siber" Anthropic. Program ini kini terbuka untuk digunakan di platform berikut:
- Platform asli Claude
- Platform Claude di AWS
- Claude di Microsoft Foundry (di-hosting di Azure dan Anthropic)
Claude di Google Vertex juga akan segera mendukung.
Organisasi yang telah bergabung dengan program ini secara otomatis mendapatkan akses yang setara di Sonnet 5, tanpa perlu mendaftar ulang. Jika pekerjaan keamanan siber Anda memerlukan pembatasan pembatas keamanan yang lebih sedikit, Anthropic merekomendasikan penggunaan Claude Opus 4.8.
Pembaruan Tokenizer dan Penjelasan Harga
Sonnet 5 adalah peningkatan dari Sonnet 4.6, tetapi menggunakan tokenizer baru, untuk mengoptimalkan kinerja pemrosesan teks (ini mirip dengan perubahan tokenizer yang diperkenalkan Claude Opus 4.7).
Perubahannya adalah: Konten input yang sama, sekarang akan dipetakan ke lebih banyak token, dengan peningkatan spesifik sekitar 1,0~1,35 kali lipat, tergantung pada jenis konten.
Untuk itu, harga perkenalan yang ditetapkan Anthropic, tepat untuk membuat agar biaya penggunaan keseluruhan pengguna tetap kira-kira sama saat beralih ke Sonnet 5.
Penjelasan Penyesuaian Batas Kecepatan
Sebelumnya, pada 26 April 2026, Anthropic telah meningkatkan batas kecepatan untuk model Sonnet dan Haiku di semua tingkat penggunaan, dan menyederhanakan paket platform asli Claude menjadi tiga tingkat: Start, Build, Scale.
Dalam pembaruan ini, Anthropic lebih lanjut meningkatkan batas kecepatan untuk Chat, Cowork, Claude Code, dan platform Claude, untuk mengimbangi konsumsi token yang lebih besar yang dibawa oleh mode "upaya" yang lebih tinggi.
Anda dapat melihat tingkat Anda saat ini dan batas spesifik di Claude Console, atau lihat dokumentasi untuk detail lebih lanjut.
Penjelasan Koreksi Skor Evaluasi (Tambahan)
- Humanity’s Last Exam: Anthropic memperbarui model penilaian untuk evaluasi ini, dan berdasarkan itu, mengoreksi skor Sonnet 4.6 menjadi 34,6% (tanpa alat) dan 46,8% (dengan alat). Oleh karena itu, skor ini berbeda dari data yang dilaporkan dalam blog peluncuran Sonnet 4.6, ini penjelasannya.
- OSWorld‐Verified: Anthropic mengoptimalkan cara menjalankan evaluasi ini, untuk lebih akurat mencerminkan kinerja model dalam skenario aktual, dan mengoreksi skor Sonnet 4.6 menjadi 78,5%. Ini juga alasan mengapa skor ini tidak konsisten dengan data dalam blog peluncuran Sonnet 4.6.
Umpan Balik Pengembang yang Mencoba
Claude Sonnet 5 begitu diluncurkan, semua orang juga sudah mulai mencoba dan menguji.
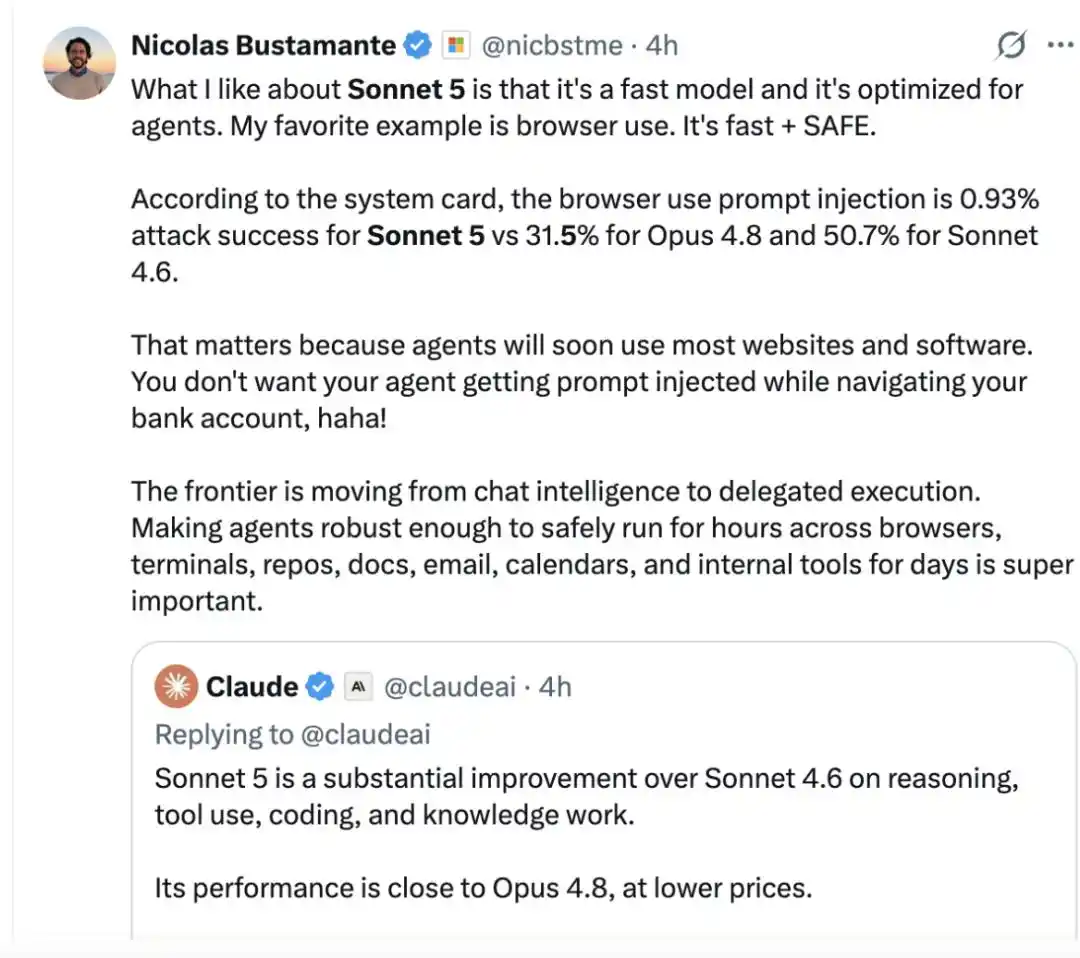
Netizen Nicolas Bustamante mengatakan, hal yang disukainya dari Sonnet 5 adalah kecepatannya yang cepat, dan dioptimalkan untuk Agen. "Contoh favorit saya adalah penggunaan browser: cepat dan aman."
Menurut hasil kartu sistem, tingkat keberhasilan serangan injeksi prompt dalam skenario penggunaan browser, Sonnet 5 hanya 0,93%, sedangkan Opus 4.8 adalah 31,5%, Sonnet 4.6 adalah 50,7%.
Namun, ada juga netizen yang mengatakan, "Terlalu mahal."
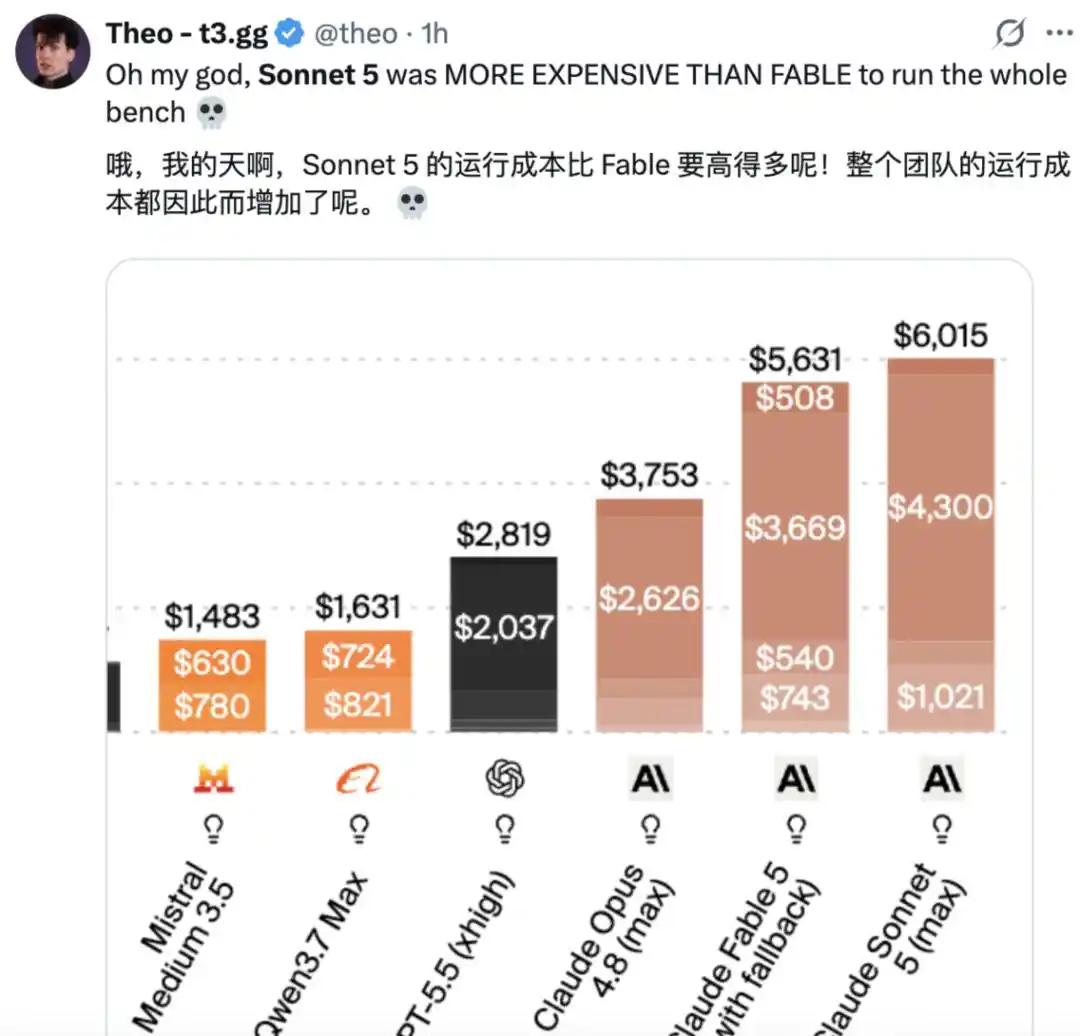
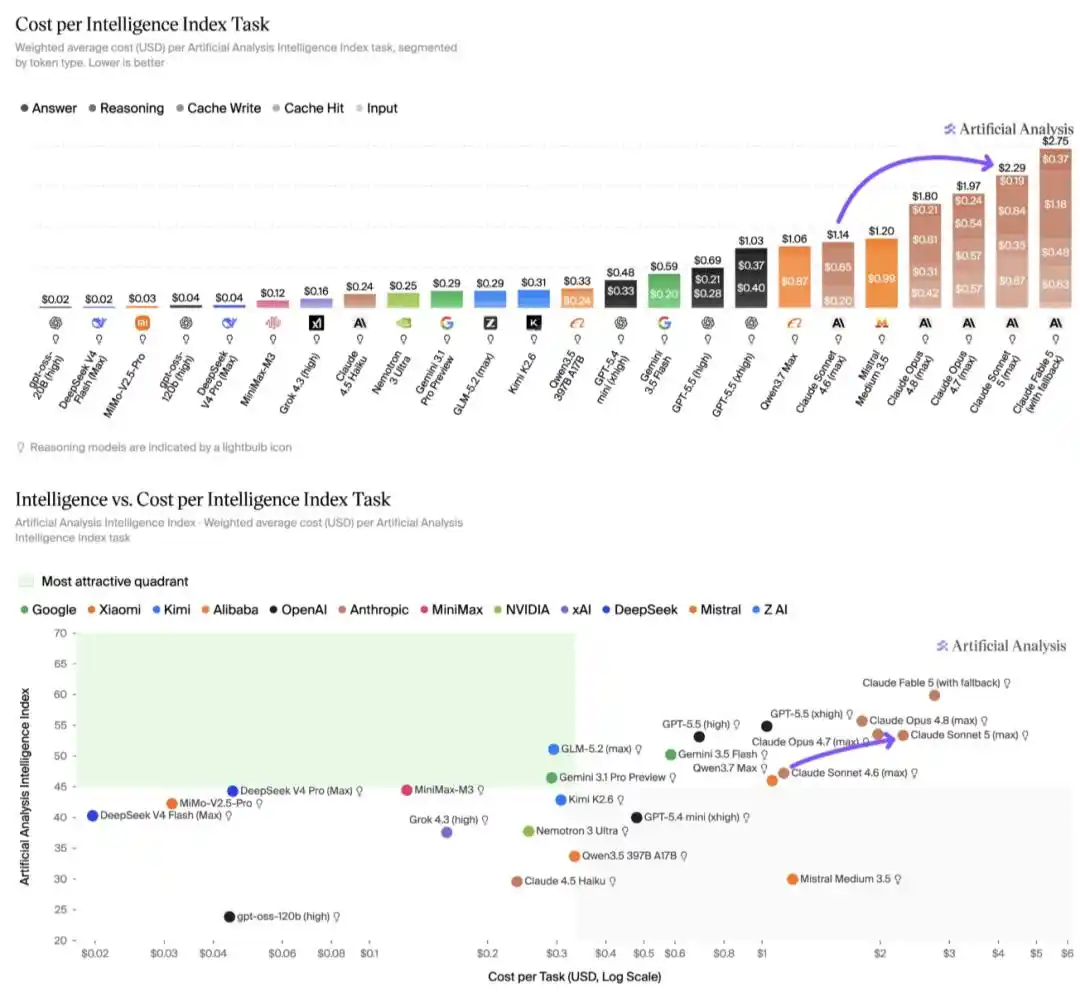
Dan menurut analisis Artificial Analysis, di Intelligence Index, Biaya operasi Claude Sonnet 5 adalah $2,29 per tugas, meningkat sekitar 2 kali lipat dibandingkan Sonnet 4.6, dan juga sekitar 15% lebih tinggi daripada Claude Opus 4.8. Kenaikan biaya ini sepenuhnya didorong oleh peningkatan penggunaan token, menjadikan Claude Sonnet 5 sebagai salah satu model dengan biaya operasi tertinggi, hanya di bawah Claude Fable 5.
Bagaimana dengan Anda, apa pendapat Anda tentang model baru ini? Silakan tinggalkan komentar dan berdiskusi!
Referensi:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
https://x.com/ArtificialAnlys/status/2072062595482456431
Artikel ini dari akun WeChat publik "机器之心" (ID: almosthuman2014), penulis: Fokus pada AI





