Penulis: Li Yuan
Pernahkah Anda bertanya tentang masalah kesehatan Anda kepada asisten AI?
Jika Anda adalah pengguna berat AI seperti saya, kemungkinan besar Anda juga pernah mencobanya.
Data yang diberikan OpenAI sendiri adalah, kesehatan telah menjadi salah satu skenario penggunaan ChatGPT yang paling umum, dengan lebih dari 230 juta orang di seluruh dunia mengajukan pertanyaan terkait kesehatan dan kebugaran setiap minggunya.
Karena alasan ini, memasuki tahun 2026, bidang kesehatan juga menunjukkan tanda-tanda akan menjadi medan perebutan di bidang AI.
Pada 7 Januari, OpenAI merilis ChatGPT Health, yang memungkinkan pengguna menghubungkan catatan medis elektronik dan berbagai aplikasi kesehatan, sehingga pengguna dapat mendapatkan respons medis yang lebih tertarget; dan pada 12 Januari, Anthropic juga segera meluncurkan Claude for Healthcare, dan menekankan kemampuan model baru dalam skenario medis.
Namun yang menarik, kali ini, perusahaan China tidak ketinggalan, bahkan tampaknya memimpin.
Pada 13 Januari, Baichuan Intelligence mengumumkan peluncuran model Baichuan M3, yang dalam set pengujian evaluasi bidang kesehatan HealthBench yang dirilis OpenAI, berhasil menyalip GPT-5.2 High milik OpenAI, dan meraih SOTA.
Setelah mengumumkan All-in Kesehatan dan menerima banyak pertanyaan, Baichuan Intelligence akhirnya membuktikan dirinya. Geek Park secara khusus berbicara dengan Wang Xiaochuan tentang bagaimana Baichuan Intelligence memandang kemampuan model M3 ini, serta akhir dari AI kesehatan.
01 Pertama Kalinya Melampaui OpenAI di Set Pengujian Bidang Kesehatan
Salah satu pencapaian paling mencolok dari model M3 yang dirilis kali ini adalah untuk pertama kalinya model ini melampaui GPT-5.2 High milik OpenAI di set pengujian evaluasi bidang kesehatan HealthBench yang dirilis OpenAI, dan meraih SOTA.
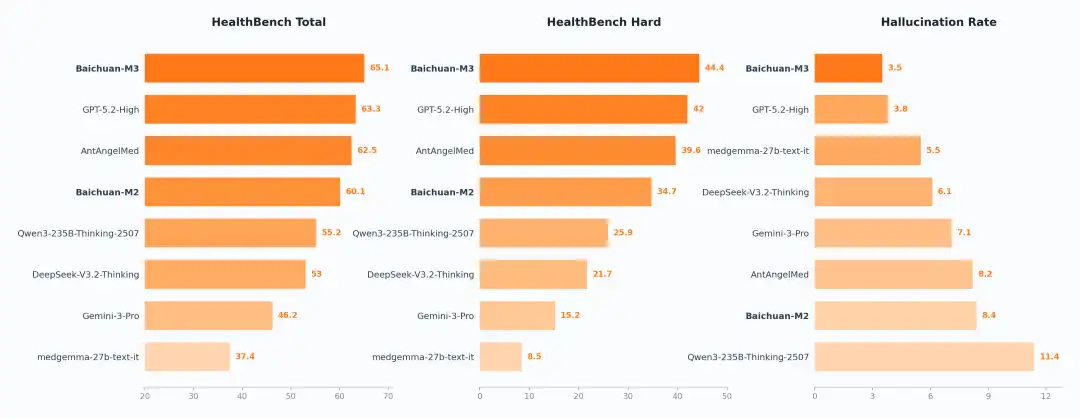
SOTA On Healthbench, Healthbench Hard and Hallucination Evaluation
Healthbench adalah set pengujian evaluasi bidang kesehatan yang dirilis OpenAI pada bulan Mei 2025, dibangun bersama oleh 262 dokter dari 60 negara, berisi 5000 kelompok percakapan medis multi-ronde yang sangat realistis, dan merupakan salah satu set evaluasi medis paling otoritatif dan paling mendekati skenario klinis nyata di dunia saat ini.
Setelah dirilis, model OpenAI selalu memuncaki peringkat.
Dan kali ini, model medis sumber terbuka generasi baru Baichuan Intelligence, Baichuan-M3, memperoleh skor keseluruhan 65,1 poin, menempati peringkat pertama di dunia, bahkan dalam HealthBench Hard yang khusus menguji kemampuan pengambilan keputusan kompleks, M3 juga berhasil menjadi juara, memecahkan skor tertinggi.
Baichuan juga secara bersamaan merilis hasil pengujian tingkat halusinasi, dalam hal tingkat halusinasi, model M3 mencapai 3,5%, termasuk yang terendah di dunia.
Perlu diperhatikan bahwa tingkat halusinasi ini adalah tingkat halusinasi medis dalam pengaturan model murni, tanpa bergantung pada alat pencarian eksternal.
Baichuan Intelligence menyatakan, yang dapat mencapai kedua poin ini, peningkatan model kuncinya terletak pada pengenalkan algoritma pembelajaran penguatan yang sesuai untuk kesehatan ke dalam medis.
Baichuan untuk pertama kalinya menggunakan teknologi Fact Aware RL (Reinforcement Learning Sadar Fakta) pada model M3, mencapai efek yang membuat model tidak berbicara basa-basi, dan juga tidak membuat model berbicara sembarangan.
Ini sebenarnya sangat krusial di bidang medis.
Dalam model yang tidak dioptimalkan ketika mengajukan pertanyaan medis, masalah yang paling mudah muncul adalah dua jenis, pertama adalah model secara langsung mengarang-ngarang gejala Anda, menduga-duga suatu penyakit; dan yang lainnya adalah semantic ambiguity, akhirnya menyarankan Anda tetap harus pergi ke dokter, dan ini tidak terlalu membantu baik bagi dokter maupun pasien.
Ini justru karena banyak model yang menjadikan tingkat halusinasi murni sebagai target optimasi, pada saat ini model mungkin melalui penumpukan fakta benar yang sederhana untuk mengencerkan tingkat halusinasi keseluruhan. Dan Baichuan memperkenalkan mekanisme semantic clustering dan pembobotan penting—clustering menghilangkan gangguan ungkapan yang berlebihan, pembobotan memastikan pernyataan medis inti mendapatkan bobot yang lebih tinggi.
Pada saat yang sama, jika hanya memperkenalkan hukuman halusinasi berbobot tinggi, sangat mudah memaksa model jatuh ke dalam strategi konservatif "sedikit bicara sedikit salah", karena itu algoritma Fact Aware RL juga dirancang dengan mekanisme penyesuaian bobot dinamis, menyeimbangkan kedua target ini secara adaptif berdasarkan tingkat kemampuan model saat ini—pada tahap pembangunan kemampuan, menekankan pembelajaran dan ekspresi pengetahuan medis (Task Weight tinggi); setelah kemampuan matang, secara bertahap mengencangkan kendala faktual (meningkatkan Hallucination Weight).
Ketika dapat terhubung ke pencarian online, Baichuan juga menambahkan modul pemeriksaan online berbasis pencarian multi-ronde, sekaligus memperkenalkan sistem cache yang efisien, untuk melakukan penyelarasan pengetahuan medis dalam jumlah besar.
02 Tingkat Pemeriksaan Melebihi Dokter Manusia, Masuk Tahap Dapat Digunakan
Namun, melampaui OpenAI di Healthbench bukanlah satu-satunya sorotan kali ini.
Satu poin yang lebih menarik kali ini, Baichuan sendiri secara kreatif membangun sebuah set evaluasi SCAN-benche. Dibandingkan dengan mengejar peringkat set evaluasi OpenAI, set evaluasi yang dibangun Baichuan sendiri, mungkin lebih dapat menjelaskan arah yang ingin dioptimalkan Baichuan Intelligence dalam hal medis.
Set evaluasi yang dibangun Baichuan kali ini, poin kuncinya terletak pada mengoptimalkan "kemampuan pemeriksaan end-to-end". Ini berasal dari wawasan eksperimen yang dilakukan Baichuan sendiri: setiap peningkatan akurasi pemeriksaan sebesar 2%, akurasi hasil diagnosis dan pengobatan akan meningkat 1%.
Artinya dibandingkan dengan HealthBench OpenAI, yang masih terutama berfokus pada "apakah AI dapat menjawab pertanyaan", SCAN-benche Baichuan berharap dapat mengevaluasi: apakah AI dapat dalam tanya jawab, memperoleh informasi yang efektif, sekaligus memberikan hasil diagnosis dan saran medis yang benar.
Biasanya, ketika kita mengajukan pertanyaan kepada asisten AI, jika hanya menyebutkan "Anda adalah seorang dokter yang berpengalaman", biasanya tidak akan mendapatkan efek model yang terlalu baik. Karena dokter sungguhan, proses pemeriksaan sangat terstandar—Baichuan meringkasnya menjadi prinsip SCAN empat kuadran: Safety Stratification (Stratifikasi Keamanan), Clarity Matters (Kejelasan Informasi), Association & Inquiry (Tanya-jawab Asosiatif) dan Normative Protocol (Output Terstandar).
Berdasarkan prinsip SCAN, Baichuan mengadopsi metode OSCE yang telah lama digunakan dalam pendidikan medis, bekerja sama dengan lebih dari 150 dokter lini depan, membangun sistem evaluasi SCAN-bench, memecah proses diagnosis dan pengobatan menjadi tiga tahap: pengambilan riwayat penyakit, pemeriksaan penunjang, diagnosis akurat, melalui assessment secara dinamis dan multi-ronde, sepenuhnya mensimulasikan proses lengkap dokter dari menerima pasien hingga diagnosis pasti, juga untuk mendapatkan hasil yang lebih baik dalam beberapa proses ini, untuk mengoptimalkan model.
Kali ini Baichuan juga merilis hasil evaluasi model M3 pada SCAN-benche.
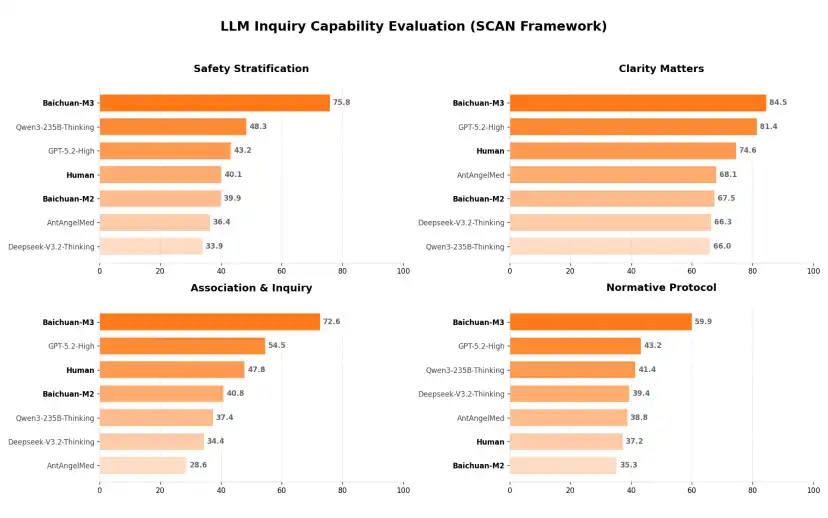
Hasilnya sangat menarik. Baichuan kali ini tidak hanya membandingkan dengan model, tetapi juga mengundang dokter sungguhan untuk dibandingkan. Dan dalam empat kuadran, dokter sungguhan sebenarnya sudah tertinggal dari tingkat yang dapat dicapai model.
Geek Park secara khusus menanyakan hal ini kepada tim Baichuan, dan jawaban yang didapat adalah: evaluasi kali ini, semuanya adalah dokter spesialis sungguhan yang membandingkan dengan model dalam kasus spesialis. Model dapat menang, pertama, karena model lebih sabar, tetapi yang lebih penting, model memiliki kemampuan penguasaan pengetahuan lintas disiplin yang lebih baik.
Misalnya dalam satu kasus, disebutkan anak berusia 10 tahun demam berulang, dan demam adalah fenomena medis yang sangat komprehensif, jika hanya menanyakan tentang batuk dan kondisi paru-paru, mudah mengabaikan masalah serius pada sendi dan sistem kemih, dan salah menilai sebagai infeksi biasa.
Dokter manusia biasanya hanya mahir dalam kondisi penyakit sesuai spesialisasinya, ini juga alasan mengapa gejala kompleks sering memerlukan konsultasi ahli, atau ahli penyakit sulit juga sering harus membuka buku mencari referensi.
Dan model biasa yang tidak dilatih khusus, hanya memerankan dokter, sering kali juga sulit menjawab jenis pertanyaan ini dengan baik.
03 Langkah Selanjutnya: Secara Bertahap Mulai Membuat Produk C-side, Mendorong Medis yang Lebih Serius
Bagi Baichuan Intelligence, titik melampaui dokter manusia ini, sangat penting: ini berarti AI mulai melewati ambang batas kegunaan, mulai dapat digunakan dalam skenario penggunaan.
Sejak 13 Januari, pengguna sudah dapat mulai merasakan jawaban yang disediakan model M3 di situs web dan app Baixiaoying.
Desain situs web saat ini sangat menarik, meskipun sama-sama menggunakan model M3 untuk menjawab, tetapi membedakan versi dokter dan versi pengguna. Dalam versi dokter, jawaban lebih ringkas, lebih banyak referensi yang dikutip, dan juga lebih "tidak berbasa-basi". Sedangkan dalam versi pasien biasa, model hampir tidak pernah memberikan jawaban sekaligus, akan melakukan lebih banyak pertanyaan lanjutan, melakukan diagnosis yang lebih jelas.

Baichuan Intelligence menyebutkan, pemikiran model di latar belakang sangat menarik. "Kami sering melihat model ini dalam chain of thought menyebutkan, 'Pasien ini tidak memperhatikan pertanyaan saya ini, tetapi pertanyaan ini harus saya tanyakan.' Bahkan kami pernah melihat yang ekstrem, mengatakan saya sudah bertanya kepada pasien 20 ronde, ini sudah melampaui jumlah maksimum yang ditetapkan, tetapi pertanyaan ini tetap harus saya tanyakan. Ini karena dalam proses pelatihan model berbicara dengan licin, tidak mendapatkan imbalan, ia harus benar-benar mendapatkan cukup banyak informasi kunci, mendapatkan diagnosis yang benar, baru bisa mendapatkan imbalan. Ini adalah perbedaan jelas kami dengan orang lain dalam melatih model."
Belakangan banyak perusahaan AI mulai masuk ke bidang medis. Ini juga yang dianggap Baichuan Intelligence sebagai perbedaan terbesarnya—ingin melakukan medis yang lebih serius.
"Ini berarti Baichuan dalam memilih skenario, bukan melihat skenario mana yang paling mudah dilakukan lalu melakukan yang mana. Sebaliknya, Baichuan bersikeras untuk terus mendorong kemampuan teknis, menantang masalah yang lebih sulit." kata Wang Xiaochuan.
Contoh khas adalah di masa depan Baichuan akan memprioritaskan skenario penyelesaian spesialis tumor, sedangkan penyembuhan psikologis berada di prioritas yang agak belakang bagi Baichuan.
Dalam pandangan umum,普遍认为 AI menyediakan penyembuhan psikologis会更简单,也是一个更容易落地的场景. Penilaian logika Baichuan则不同. Mereka认为肿瘤领域有更严格的科学依据. Di sini, AI更有可能做出严肃的医疗效果,从而达到或者超越人类医生的水平. Sebaliknya, bidang psikologi缺乏这种确定性的科学锚点.
Contoh lain ada perusahaan yang memilih membuat avatar dokter, Wang Xiaochuan则认为这种方向并不是百川想要做的方向. Avatar dokter本身不能完整复用医生的水平,更不能超越医生的水平. AI seperti ini akhirnya hanya akan menjadi幌子和获客工具,并不能真正推动严肃医疗.
Ketetapan pada keseriusan ini, sangat mempengaruhi banyak pilihan komersial Baichuan.
Ini langsung berkaitan dengan pemikiran Wang Xiaochuan tentang masalah mendasar tahap berikutnya AI medis. Dia认为, tahap saat ini tugas paling penting adalah dalam meningkatkan kemampuan AI的基础上,逐渐提供更多的医疗供给.
China selama bertahun-tahun telah mencoba menerapkan sistem diagnosis dan pengobatan bertingkat dan dokter umum. Tujuannya是希望老百姓先在基层看病,解决大医院挂号难、排队长、拥堵不堪的现状.
Sistem ini sulit diterapkan, pada dasarnya是因为医疗资源的供给不足. Lembaga medis基层缺乏高水平的医生.大家即便只是感冒也愿意去三甲医院排队,是因为对基层的诊疗水平不放心.
Inilah poin kunci dimana AI medis发挥作用. Model besar能够把顶尖的医学知识实现规模化分发. Ini填补了基层的供给缺口,让每一个社区、每一个家庭都能拥有像三甲医院专家一样的诊疗能力.
Dan dalam jangka panjang, ini还能有更广泛的影响,可能让医疗的让决策权从医生手中逐渐转移到用户身上. Dalam skenario medis tradisional, pasien是利益的受益方,但往往没有决策权.决策权集中在医生手中. Ketidakseimbangan kekuatan ini往往带来沟通成本和治疗中的痛苦.
Dan Baichuan berharap melalui AI,让患者能够更容易地获得优质医疗资源的供给. "Banyak orang觉得医疗太复杂了,患者是永远理解不了的.但我们想的在美国的司法体系里面有个叫陪审团制度. Hukum也是非常专业的一个事,陪审团的普通人不懂,那就要求在法官、律师和检察官能够进行带领,做充分的辩论,把话说清楚,说到一个普通人能判断有罪没罪的程度,让普通人能依据逻辑正常判断即可。" kata Wang Xiaochuan.
Ini juga alasan Baichuan Intelligence tidak ingin hanya melakukan skenario sederhana, tetapi berharap terus mendorong ke diagnosis dan pengobatan serius dengan kesulitan tinggi.
Ketika ditanya apakah menyelesaikan masalah dengan kesulitan tinggi paling memberikan回报 dalam hal komersial, Wang Xiaochuan memberikan jawaban yang mendalam.
Dia认为, menyelesaikan masalah kecil seperti flu demam, sulit membangun kepercayaan yang cukup di hati pengguna. Medis adalah industri yang sangat bergantung pada kepercayaan. Hanya ketika AI dapat menyelesaikan masalah sulit seperti penyakit berat, barulah dapat benar-benar membangun dasar kepercayaan.
Dari logika komersial, pasien menghadapi masalah kesehatan yang serius, juga lebih bersedia membayar untuk layanan AI berkualitas tinggi. Kepercayaan ini不仅是商业回报的前提,更是 AI 医疗能够规模化应用的核心.
Dan dari arti yang lebih mendasar, medis bagi Baichuan Intelligence dan Wang Xiaochuan personally,仍然意味着是一条接近通用人工智能(AGI)的路径.
Wang Xiaochuan认为, AI saat ini在文、理、工、艺等领域都已找到了切实的解法,医疗则是一个极为独特的领域. Eksplorasi manusia terhadap医学尚未穷尽, AI di bidang ini也正处于摸索阶段.
Peta jalan Baichuan非常清晰. Pertama melalui AI meningkatkan efisiensi diagnosis, menyelesaikan masalah kekurangan pasokan medis saat ini. Atas dasar ini, Baichuan berkomitmen membangun kepercayaan mendalam dengan pasien. Ketika pasien bersedia menggunakan alat AI,长期进行医疗咨询, AI就能在长期的陪伴中积累真实且高质量的医疗数据.
Data-data ini tujuan utamanya adalah membangun model matematika kehidupan. Ini adalah jalan yang至今尚未完全走通 oleh dokter manusia, di masa depan很有可能由 AI 率先实现. Jika dapat menyelesaikan pemodelan esensi kehidupan, ini将成为推动通用人工智能迈向更高阶进步的关键一步.






