Dua tahun terakhir, model pembuatan video AI berkembang sangat pesat. Dari efek memukau yang ditunjukkan Sora pada akhir 2024, hingga model pembuatan video seperti Google Veo, Sora 2, seri Kling, dan Seedance 2.0 di awal tahun ini, kualitas video yang dihasilkan AI telah mengalami lompatan kualitatif. Kini, dapat dihasilkan video berdurasi beberapa menit dengan efek sinematis yang nyaris sempurna, menampilkan banyak karakter dan adegan kompleks.
Berhadapan dengan perkembangan pesat di sisi generatif, perhatian dunia penelitian terhadap deteksi video AI masih relatif tenang.
Dalam kenyataan, kita dapat mengamati bahwa sifat multimodal video yang memiliki daya tipu jauh lebih besar daripada gambar, telah membawa dampak sosial yang sangat besar:
Di berbagai platform media sosial, video palsu yang dihasilkan AI sering muncul, dengan jumlah, kualitas, dan cakupan yang semakin meningkat. Ketika pengguna menanyakan model dasar seperti Grok atau Doubao "Apakah video ini dihasilkan AI?", jawaban yang diperoleh seringkali hanya penilaian benar/salah yang kurang dapat diinterpretasikan dan kurang dapat dipercaya. Di platform seperti Xiaohongshu, video yang benar-benar direkam justru sering diberi label "diduga dihasilkan AI".
Kesenjangan besar terjadi antara perkembangan pesat di sisi generatif dan kurangnya perhatian di sisi deteksi. Kita harus segera memperhatikan: di era perkembangan cepat pembuatan video AI saat ini, sejauh mana penelitian deteksi video AI telah berkembang, perubahan paradigma apa yang sedang dialami, dan ke arah mana ia perlu dikembangkan di masa depan.
Dalam konteks ini, para peneliti dari MBZUAI, Universitas Rakyat Tiongkok, dan Universitas Harvard bersama-sama menulis dan merilis tinjauan literatur (survey) sepanjang lima puluh halaman. Untuk pertama kalinya, tinjauan ini menyusun jalur teknis dari persepsi visual tingkat rendah hingga penalaran tingkat dunia (world-level) tingkat tinggi dari dua arah: visual dan bahasa. Berdasarkan ini, dianalisis kebutuhan mendesak akan sistem deteksi yang dapat dipercaya, dinamis, dapat dilacak, dan dapat diinterpretasikan dengan kopling bukti berlapis, yang kini telah diterima untuk dipublikasi di ACL 2026.

Tautan Makalah:https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Tautan GitHub:https://github.com/dxhou/AI-Generated-Video-Detection
Tautan Homepage:https://AIgcvdetection.github.io
Menulis Ulang Tujuan Deteksi Video Hasil AI
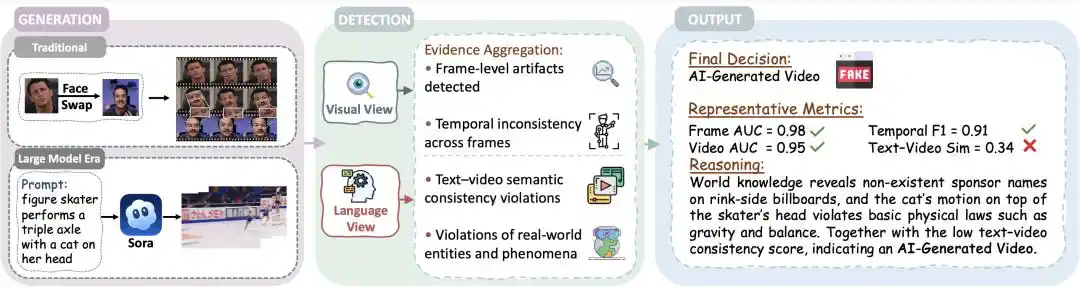
Gambar 1 | Alur lengkap deteksi video hasil AI: dari sisi generasi, deteksi sudut pandang ganda, hingga kumpulan bukti
Sebelum ledakan AI generatif, video hasil AI meninggalkan artefak visual yang relatif jelas. Berdasarkan premis ini, dalam skenario Deepfake awal seperti tukar wajah, verifikasi tingkat frame dari sisi persepsi visual sudah cukup efektif.
Namun dalam dua tahun terakhir, kualitas video di era AI generatif yang berkembang pesat telah melampaui "premis" ini. Mata manusia semakin tidak dapat membedakan keaslian video yang lengkap dan tampak nyata. Pada titik ini, detektor yang hanya mengeluarkan penilaian biner (dua kelas) sudah tidak lagi memadai, dan mendesak untuk dijawab: atas dasar bukti seperti apa detektor mendukung penilaian yang dapat dipercaya.
Tinjauan ini pertama-tama mendorong batas masalah deteksi: menunjukkan bahwa output deteksi perlu bergerak dari "klasifikasi biner benar/salah menuju penilaian terstruktur yang dapat diinterpretasikan dan dapat dipercaya, sehingga mendorong objek deteksi menjadi verifikasi terhadap celah antara 'dunia virtual' dan 'dunia nyata' dalam video.
Oleh karena itu, tinjauan ini pertama-tama mendefinisikan ulang tujuan deteksi, didefinisikan ulang sebagai 'verifikasi kesetiaan fakta' (factual fidelity verification), yaitu memeriksa apakah proposisi tentang 'siapa, kapan, di mana, dan apa yang terjadi' dalam konten video selaras dan sejalan dengan dunia nyata baik secara persepsi maupun kognisi. Di luar verifikasi antar modalitas visual, perlu untuk lebih lanjut menilai apakah konten video yang berisi proposisi-proposisi ini berkonflik dengan 'fakta eksternal, hukum fisika, pengetahuan dunia, dll.'.
Objek Deteksi: Tiga Paradigma Video Hasil AI

Gambar 2 | Tiga jenis paradigma video hasil AI yang didefinisikan dalam tinjauan ini
Dari 2020 hingga kini, video hasil AI telah mengalami pergeseran paradigma: dari modifikasi lokal video melalui GAN di era Deepfake awal, hingga rekombinasi audio-visual seperti sinkronisasi bibir dan suara, hingga sintesis penuh video AI yang didukung oleh 'simulator dunia' seperti Sora yang digerakkan oleh model difusi ruang laten. Tinjauan ini membagi video hasil AI menjadi tiga paradigma berikut:
Video Manipulasi Lokal yang Mempertahankan Media Asli (Local Manipulation Video, LMV)
LMV dalam waktu lama merupakan paradigma paling tipikal dan paling matang untuk deteksi Deepfake tradisional. Video itu sendiri memproses area lokal dari video rekaman asli, seperti tukar wajah, tukar latar belakang, dll.; sementara sebagian besar struktur video asli seperti adegan, gerakan orang, pergerakan kamera, hubungan pencahayaan biasanya masih ada. Oleh karena itu, sebagian besar metode awal memang berfokus pada artefak lokal, fitur domain frekuensi, anomali geometri, dan konsistensi wilayah. Namun, kemampuan model generatif dalam fusi lokal, adaptasi pencahayaan, dan transfer identitas semakin kuat; pemrosesan platform dan penyebaran sekunder akan semakin menghapus banyak jejak halus. Fokus deteksi untuk paradigma LMV perlahan-lahan lebih memperhatikan ketahanan metode deteksi di berbagai skenario.
Penyuntingan Audio-Visual di Bawah Kendala Kopling Multimodal (Audio-Visual Editing, AVE)
Paradigma AVE terutama muncul pada tahun 2024. Dalam video hasil AI jenis ini, yang diubah adalah hubungan korespondensi yang telah terbangun di dalam video itu sendiri antara gambar, suara, gerakan bibir, identitas pembicara, ritme bicara, konten subtitle, dll. Termasuk sintesis wajah yang digerakkan suara, pengisian suara ulang pada video asli, perubahan gerakan bibir, penggantian pembicara, dll. Ini membuat sisi deteksi perlu bergeser dari melihat artefak visual menjadi memeriksa apakah hubungan antara beberapa modalitas di dalam video benar-benar terbukti, dengan melihat bersama suara, gerakan bibir, identitas, dan konten untuk menemukan petunjuk yang benar-benar memiliki daya pembeda.
Sintesis Video Generatif Ujung ke Ujung (Generative Video Synthesis, GVS)
Dalam paradigma GVS yang meledak pada 2025, model secara langsung menghasilkan keseluruhan video dengan mengandalkan informasi kondisi seperti teks, gambar, noise, dll., tidak lagi mengandalkan video asli sebagai dasar, membawa tantangan baru bagi sisi deteksi.
Video jenis ini biasanya terlihat sangat nyata pada satu frame atau dalam waktu singkat, namun dalam urutan temporal panjang sering kali muncul celah: seperti tindakan karakter atau posisi dalam adegan yang tidak dapat terhubung dari depan ke belakang, perubahan bentuk atau gerakan objek yang tidak sesuai dengan hukum fisika, atau peristiwa dalam video itu sendiri yang tidak dapat terjadi di dunia nyata.
Secara bersamaan, pendekatan deteksi untuk paradigma GVS juga tidak dapat lagi terbatas pada konsistensi lokal dan antar-modalitas, tetapi perlu bergerak ke tingkat yang lebih tinggi, dimulai dari konsistensi jangka panjang, akal sehat, hukum fisika, narasi dan sebab-akibat, keaslian tingkat proposisi, dan keterlacakan, dll., untuk memeriksa apakah konten itu sendiri dapat dipercaya dalam urutan temporal panjang, melihat apakah konten video dapat berlaku di dunia nyata di berbagai tingkat.
Spektrum Metode Deteksi Empat Lapisan di Bawah Sudut Pandang Ganda Visual-Bahasa
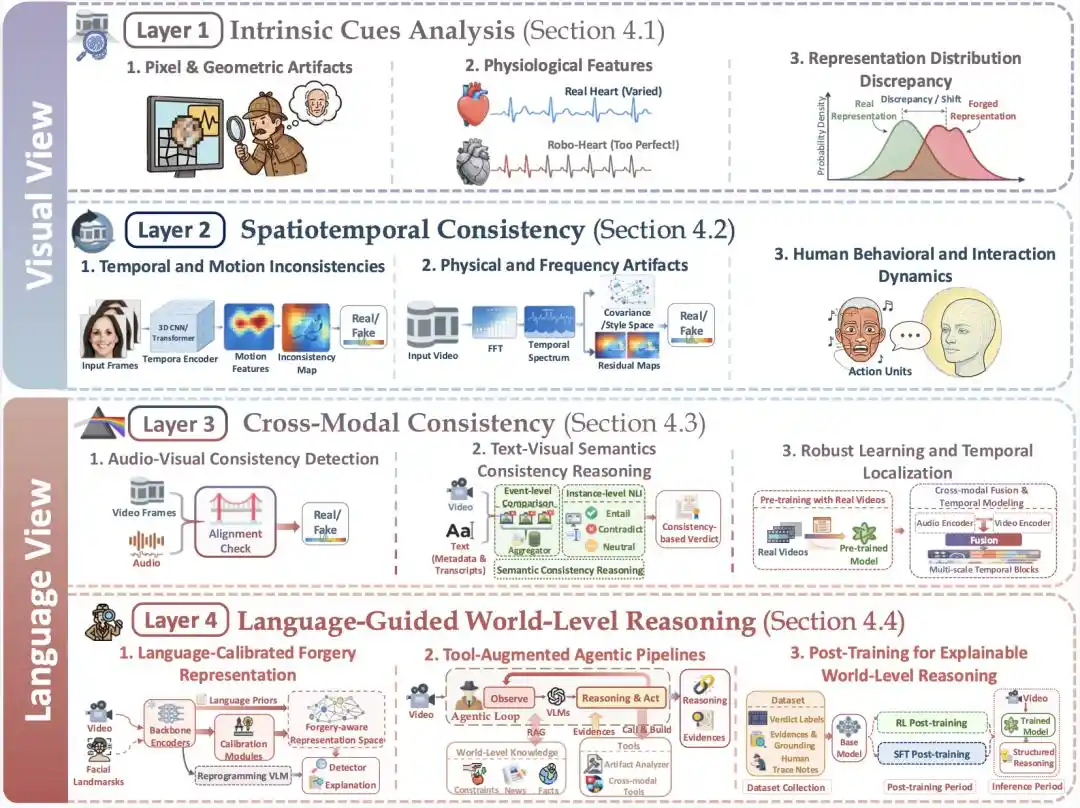
Gambar 3 | Kerangka Empat Lapisan Vision-Language Dual-View: Dua lapisan pertama condong ke perspektif visual, dua lapisan terakhir bergerak ke perspektif bahasa
Saat ini, perspektif modalitas untuk mendeteksi video hasil AI telah terdiferensiasi, dapat dibagi menjadi dua jenis masalah ilmiah inti: Jenis pertama berasal dari modalitas visual, berfokus pada pengambilan bukti sinyal tingkat rendah dan konsistensi temporal-spasial gambar.
Jenis lain berasal dari modalitas bahasa, fokus utamanya meliputi informasi bahasa multimodal dari video itu sendiri, menilai "apakah video benar-benar bercerita dengan selaras antar-modalitas"; serta menggunakan modalitas bahasa untuk memperkenalkan penalaran terkait pengetahuan dan fakta tentang dunia, menilai "apakah konten video dapat bertahan terhadap pemeriksaan pengetahuan, fakta, hukum, dll. dari dunia nyata eksternal".
Tinjauan ini menangkap tren perubahan ini, mengusulkan untuk mengorganisir metode penelitian dan paradigma evaluasi deteksi video hasil AI dari sudut pandang visual-bahasa ganda, dan berdasarkan ini lebih lanjut mengusulkan pemandangan metode empat lapis dari persepsi tingkat rendah hingga kognisi tingkat tinggi berikut.
Termasuk empat lapisan berikut:
Lapisan 1, Analisis Petunjuk Visual Tingkat Rendah (Intrinsic Cues Analysis): Jaring Saringan Pertama
Metode dalam lapisan 1 menangani masalah penelitian: Pada sinyal visual tingkat rendah, apakah video memenuhi pola statistik yang harus dipenuhi oleh video asli, serta apakah video mengandung petunjuk tingkat rendah yang diperkenalkan oleh model AI atau operasi penyuntingan.
Pada sinyal tingkat rendah, video asli akan memenuhi karakteristik statistik yang sesuai, dan video yang diperoleh dari pemrosesan rekaman asli akan secara alami sesuai dengan proses akuisisi, pengkodean, dan pasca-proses; sedangkan proses pembuatan AI sering kali meninggalkan petunjuk yang menyimpang dari distribusi video asli, seperti gaya yang seragam, watermark dan artefak terkait model tertentu, sinyal fisiologis kaku yang dapat dideteksi, dll.; metode dalam lapisan pertama ini berasal dari perspektif visual dengan memodelkan, mengekstraksi, dan memperkuat sinyal tingkat rendah ini untuk pengambilan bukti. Termasuk mendeteksi:
Anomali piksel dan geometri seperti domain frekuensi, tekstur, batas, pola noise;
Sinyal fisiologis pada wajah manusia seperti denyut nadi yang terkopel, gerakan otot kecil, ritme kedipan mata;
Apakah terdapat pergeseran sistematis antara video asli dan video palsu dalam ruang fitur.
Lapisan 2, Konsistensi Spasio-Temporal (Spatiotemporal Consistency): Memeriksa "Kelancaran Sebuah Video"
Metode dalam Lapisan 2 ditujukan pada konsep "kombinasi urutan aliran gambar video dalam dimensi ruang dan waktu", menangani masalah penelitian: Dalam dimensi spatio-temporal, apakah aliran gambar video memenuhi karakteristik yang diperlukan untuk proses gerakan objek dalam video asli. Video rekaman asli dibatasi oleh lintasan kamera yang kontinu dan lingkungan adegan dunia nyata, perubahan spatio-temporal antara frame yang berdekatan dari subjek utama dan latar belakang akan menunjukkan pola yang kontinu dan dapat diprediksi yang sesuai dengan kelayakan fisik dan gerakan kamera. Sedangkan video hasil AI dalam urutan temporal panjang mungkin menunjukkan ketidakkontinuan spatio-temporal seperti distorsi objek lokal, pergeseran latar belakang, pengaburan tiba-tiba, anomali residu gerakan, dll. Termasuk mendeteksi:
Ketidakkonsistenan waktu dan gerakan seperti deformasi objek lokal, drift latar belakang, blur mendadak, anomali residu gerakan;
Dinamika perilaku dan interaksi manusia seperti perubahan ekspresi, dinamika identitas, ritme interaksi antara karakter utama dalam adegan;
Anomali fisik dan frekuensi yang terkait dengan frekuensi waktu dan kontinuitas gambar.
Lapisan 3, Konsistensi Lintas-Modalitas (Cross-Modal Consistency): Verifikasi Multimodal Internal Video
Lapisan 3 adalah titik balik yang sangat kunci dalam seluruh kerangka: deteksi mulai memasuki verifikasi multimodal internal video, menangani masalah penelitian: Apakah berbagai modalitas seperti gambar, suara, subtitle dalam video "mengatakan hal yang sama di berbagai tingkat dengan selaras".
Video asli biasanya sangat selaras antara modalitas audio, teks, dan gambar yang menyertainya. Sedangkan video hasil AI mungkin memiliki ketidakcocokan sistematis antara gerakan bibir-suara, identitas-sidik suara, gambar-teks. Metode lapisan ketiga melakukan analisis konsistensi multi-sudut yang terperinci terhadap konsistensi antar-modalitas. Termasuk tiga jenis:
Mendeteksi konsistensi antara suara dan gambar;
Memperkenalkan subtitle, judul, transkrip teks, teks deskripsi, kemudian melakukan penalaran konsistensi semantik teks-video;
Pembelajaran ketahanan berorientasi pada pelokalan waktu ketidakkonsistenan antar-modalitas.
Lapisan 4, Penalaran Tingkat Dunia yang Dipandu Bahasa (Language-Guided World-Level Reasoning): Memandang Celah antara Video dan Dunia Nyata
Perspektif deteksi Lapisan 4 meningkat dari "konsistensi internal video" menjadi "apakah tidak bertentangan dengan aturan dan pengetahuan di dunia nyata eksternal", masalah penelitian berubah menjadi: Apakah konten video dalam dimensi semantik dan faktual benar-benar mungkin ada di dunia nyata, apakah masuk akal.
Semua konten video asli harus konsisten dengan fakta dunia nyata, aturan domain seperti hukum fisika, pengetahuan dasar seperti akal sehat, dll. Sedangkan konten video hasil AI sering kali sulit sepenuhnya selaras dengan dunia nyata, dan inilah ruang deteksi yang dimanfaatkan lapisan keempat. Termasuk:
Menggunakan prompt, prior teks, prototipe teks, atau modul ringan untuk mengkalibrasi ulang ruang representasi model, sehingga model lebih mudah memetakan anomali yang dilihat dengan kategori semantik yang lebih eksplisit;
Memandang deteksi sebagai proses verifikasi fakta, membangun agen cerdas penyelidik yang akan mencari referensi, menggunakan alat, dan merevisi penilaian, menghubungkan penilaian dengan bukti, output alat, proses verifikasi, dll.;
Melalui fine-tuning, pembelajaran preferensi, pemodelan reward, dan pembelajaran penguatan, melatih "bagaimana memilih bukti, bagaimana mengorganisir penjelasan, bagaimana memberikan kesimpulan" ke dalam model itu sendiri. Fokus pada memberikan output deteksi yang jelas, struktur stabil, dan rangkaian bukti yang lengkap.
Peta Evolusi Sisi Generatif dan Sisi Deteksi
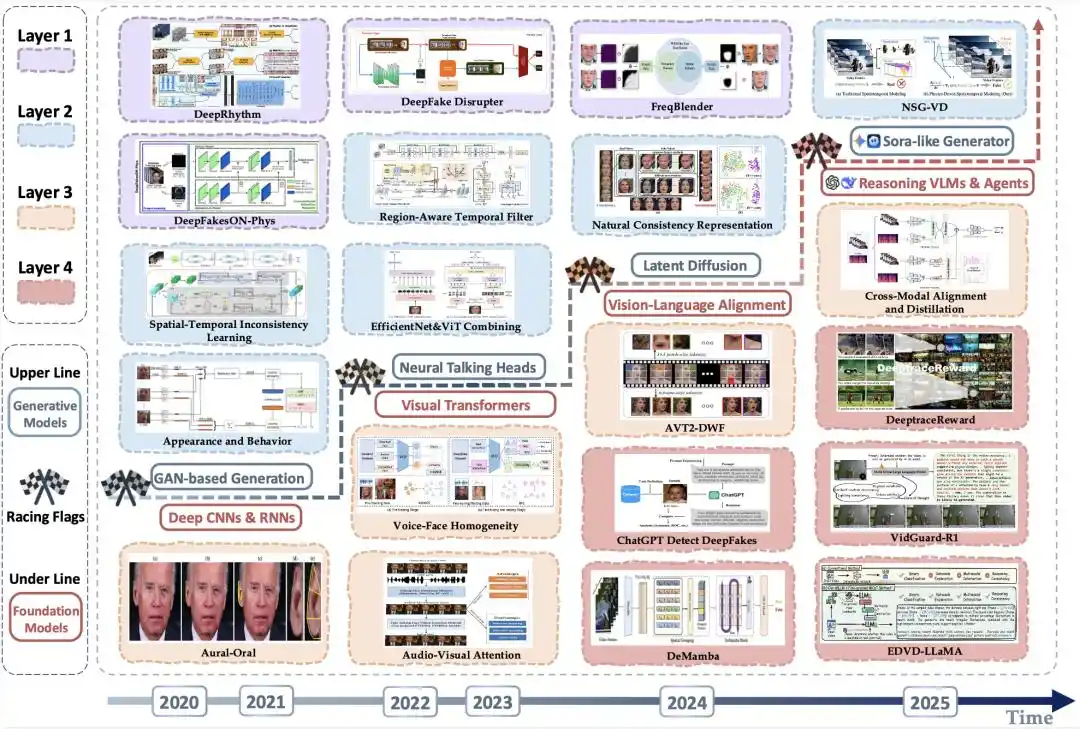
Gambar 4 | Peta evolusi metode deteksi representatif: Peningkatan ancaman sisi generatif dan peningkatan sisi deteksi berjalan beriringan
Gambar di atas menyajikan sepanjang garis waktu bagaimana ancaman dari sisi generatif terus meningkatkan batas atas realisme yang dapat dicapai oleh "video palsu". Dalam latar belakang evolusi model dasar yang diandalkan teknologi deteksi, dari jaringan konvolusional dalam dan jaringan berulang, ke Vision Transformer, hingga model bahasa-vision besar (VLM) dan sistem agen yang memiliki kemampuan penalaran, sisi deteksi berkembang dari forensik visual secara bertahap menuju verifikasi multimodal dan deteksi penalaran tingkat tinggi.
Tinjauan ini lebih lanjut membuat statistik distribusi hierarkis metode deteksi dari waktu ke waktu: pada 2020 proporsinya hanya 7,7%, pada 2023 meningkat menjadi 40,0%, dan pada 2025 lebih dari setengah.
Secara keseluruhan, fokus metode deteksi terus bergeser ke atas: awalnya terutama terkonsentrasi di lapisan pertama dan kedua, dan seiring video yang dihasilkan semakin mulus dan semakin nyata, deteksi mulai lebih banyak masuk ke lapisan ketiga dan keempat.
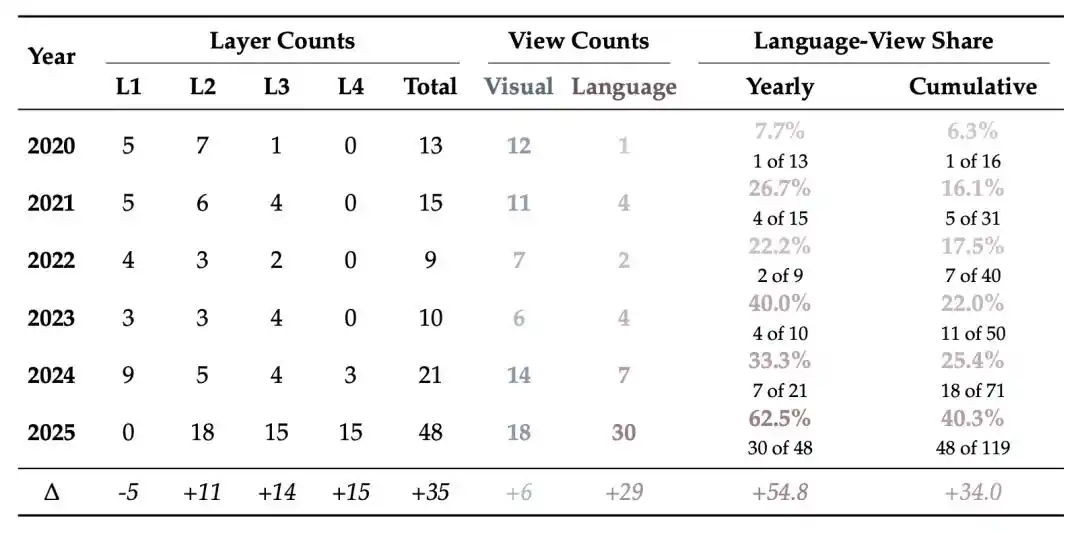
Gambar 5 | Statistik perubahan distribusi metode deteksi: Proporsi perspektif bahasa secara bertahap meningkat
Evaluasi Metode Deteksi
Menghadapi tujuan deteksi kesetiaan fakta, evaluasi metode deteksi perlu menjawab: apakah model telah menguasai petunjuk visual yang dapat ditransfer, apakah dapat mengidentifikasi ketidakkonsistenan spatio-temporal dan lintas-modalitas, apakah dapat membuat penilaian yang efektif terhadap fakta, pengetahuan, dan kendala dunia. Tinjauan ini secara sistematis menyusun evolusi metrik evaluasi dan dataset deteksi dari era Deepfake tradisional hingga saat ini.
Metrik Evaluasi di Bawah Sudut Pandang Ganda Visual-Bahasa
Metrik Bersama: Acc / AUC Masih Diperlukan, Tetapi Jauh dari Cukup
Acc, AUC, Precision, Recall, F1, EER, PR-AUC, serta metode agregasi level frame dan level video, masih menjadi bahasa dasar bersama antar berbagai metode, memungkinkan metode dari berbagai tingkat untuk dibandingkan secara horizontal. Namun, metrik evaluasi dasar ini, meskipun masih diperlukan, tidak dapat memenuhi persyaratan evaluasi yang dapat diinterpretasikan dan dapat dipercaya di bawah tujuan verifikasi kesetiaan fakta.
Metrik dari Perspektif Visual: Mengevaluasi Apakah Masih Berlaku di Bawah Gangguan Lingkungan Nyata
Fokus evaluasi terletak pada apakah petunjuk yang dimiliki detektor sebelumnya masih dapat terus berlaku ketika menghadapi perubahan distribusi, kompresi penyebaran, dan gangguan lingkungan nyata. Dibagi menjadi dua kategori berikut:
- Ketahanan Petunjuk Tingkat Rendah: Termasuk TPR@FPR=α pada ambang batas tetap, pengujian lintas dataset, uji tekanan gangguan (perturbation pressure test), dll.
- Konsistensi Spatio-Temporal dan Fisik: Fokus pada pelaporan level video (video-level reporting), penurunan performa akibat gangguan temporal (temporal perturbation drop), ablasi gerakan (motion ablation), serta apakah model akan mengalami penurunan signifikan setelah informasi temporal dihilangkan, sehingga mengevaluasi apakah detektor benar-benar melihat kontinuitas seluruh video, bukan hanya mengandalkan jalan pintas (shortcut) dalam frame tunggal untuk membuat penilaian.
Metrik dari Perspektif Bahasa: Evaluasi Pelokalan Multimodal dan Penalaran
Cakupan jalur deteksi dari perspektif bahasa lebih luas, dan metrik evaluasi sudah tidak dapat lagi dirangkum dengan satu set metrik klasifikasi sederhana. Tinjauan ini membuat stratifikasi berikut:
- Kesesuaian Lintas-Modalitas dan Pelokalan Waktu: Jenis metrik evaluasi ini berorientasi pada akurasi detektor dalam keselarasan lintas-modalitas, serta apakah detektor dapat melokalisasi petunjuk ke rentang waktu spesifik. Selain Acc dan AUC dasar, metrik umum juga akan menambahkan AP, AR, Recall@K, mAP@IoU, dll.
- Pengetahuan Dunia dan Penalaran: Menghadapi masalah tingkat tinggi "apakah peristiwa yang diceritakan video dapat didukung oleh akal sehat, hukum fisika, pengetahuan eksternal, dan bukti spesifik", metrik evaluasi deteksi perlu memperkenalkan penilaian manusia (human judgments), preferensi berpasangan (pairwise preferences), jawaban pertanyaan (question answering), serta metrik seperti BLEU, ROUGE-L, METEOR, CIDEr, similarity berbasis embedding yang digunakan untuk mengevaluasi kualitas penjelasan.
Dataset: Diatur Ulang Menurut Tiga Paradigma Objek Deteksi
Sebagian besar dataset yang digunakan untuk melatih dan mengevaluasi metode deteksi secara alami akan terdiferensiasi sepanjang paradigma video hasil AI yang disebutkan sebelumnya. Tinjauan ini melakukan penyusunan sebagai berikut:
- Dataset untuk Paradigma LMV: Fokus evaluasi terutama terkonsentrasi pada stabilitas petunjuk visual metode deteksi, serta apakah petunjuk ini dapat terus berlaku dalam kondisi distorsi, kompresi, dan penyebaran lintas domain; dataset jenis ini terus mendekati lingkungan nyata dengan memasukkan penalaran temporal dan evaluasi penjelasan.
- Dataset untuk Paradigma AVE: Dataset jenis ini sering kali lebih menekankan anotasi waktu yang halus, hubungan korespondensi lintas-modalitas yang lebih eksplisit, serta pemodelan ketidakselarasan lokal dan ketidakcocokan semantik yang lebih kuat. Menguji kemampuan model dalam menemukan ketidakselarasan antara audio dan video, melokalisasi waktu terjadinya ketidakselarasan, serta membedakan masalah sinkronisasi, identitas, dan semantik.
- Dataset untuk Paradigma GVS: Di satu sisi, video sintesis penuh terus melemahkan jejak penyuntingan eksplisit, di sisi lain, terus membawa tantangan seperti diversitas generator, ketidakselarasan semantik, dan risiko transfer bagi deteksi, sehingga evaluasi terkait berubah paling cepat; dari pengumpulan awal sejumlah besar video sintesis penuh untuk mengevaluasi akurasi deteksi, berkembang menjadi karya seperti LOKI, GenWorld, DAVID-X, DeeptraceReward yang memasukkan simulasi dunia, anotasi tingkat cacat, dan petunjuk pemalsuan yang dipersepsi manusia ke dalam sistem evaluasi.
Evaluasi Terkait Diagnosis Model Pembuatan Video
Sumber daya sisi evaluasi terkait deteksi tidak terbatas pada dataset yang berorientasi pada deteksi itu sendiri. Faktanya, dalam penelitian terkait CV dan model dunia, banyak evaluasi diagnosis kualitas generasi model pembuatan video serta evaluasi terkait kemampuan koreksi kesalahan model pemahaman video juga dapat menjadi referensi penting untuk deteksi. Tinjauan ini menyusun karya evaluasi diagnosis yang dapat menjadi sumber daya tambahan ini menurut rantai evaluasi yang berlangsung secara bertahap:
- Pertama melihat apakah objek, atribut, interaksi, dan perubahan keadaan dalam video sesuai dengan hukum fisika dasar;
- Kemudian melihat dinamika dunia dan hubungan sebab-akibat, yaitu apakah hukum lokal dapat diperluas dalam keseluruhan video, membentuk proses peristiwa yang kontinu, koheren, dan sesuai dengan pengetahuan dunia;
- Terakhir melihat apakah model pemahaman video dan sistem lainnya dapat mengubah berbagai tingkat kesalahan dalam video yang dihasilkan ini menjadi penilaian yang eksplisit, dapat dipahami, dan dapat diverifikasi ulang.
Dari "Mampu Membedakan" ke "Mampu Memberikan Bukti"
Video hasil AI dengan kesetiaan tinggi terus meningkatkan batas atas realisme konten palsu. Masalah yang dihadapi tugas deteksi semakin sulit untuk dirangkum dengan skor benar/salah, dan perlu melakukan deteksi kesetiaan fakta; sesuai dengan itu, segmen evaluasi dan sistem deteksi juga perlu diperluas seiring dengan perluasan batas tugas:
Sistem Evaluasi Dinamis yang Mengutamakan Bukti
Menghadapi video kompleks dengan rentang waktu panjang yang dihasilkan AI yang baru muncul, evaluasi perlu menjawab bukan hanya "apakah model dapat mengklasifikasikan", tetapi juga "petunjuk apa yang sebenarnya diandalkan model untuk menghasilkan penilaian benar atau salah". Label evaluasi tingkat kasar akan menyembunyikan banyak informasi kunci yang benar-benar penting, anotasi data dalam evaluasi, pelatihan model, dan pelaporan hasil juga perlu didorong maju bersama-sama, perlu mengurai ulang video menjadi kelompok unit proposisi yang dapat diverifikasi, mengubah "narasi temporal panjang" menjadi objek terstruktur yang dapat dioperasikan seperti rantai peristiwa, lintasan keadaan entitas, atau grafik peristiwa, sehingga memungkinkan verifikasi sebab-akibat dan kendala dalam skala waktu panjang, sehingga lebih lanjut menanyakan deteksi "proposisi mana yang sebenarnya ditangkap" dan "apakah bukti dan penilaian dapat saling berhubungan satu-satu".
Selain itu, kebanyakan detektor masih dievaluasi dalam pengaturan "dunia tertutup": dalam skenario penyebaran nyata, model pembuatan video baru, alat penyuntingan, dan gaya konten terus bermunculan, platform berbeda memperkenalkan proses downsampling, transcoding, dan filtering mereka masing-masing. Untuk mengisi celah ketahanan jangka panjang ini, perlu mengadopsi mekanisme pembaruan berkelanjutan seperti arena/leaderboard, memasukkan generator baru yang dirilis dan jalur transcoding platform baru ke dalam kumpulan evaluasi secara streaming.
Sistem Deteksi yang Dapat Dipercaya dan Dapat Diinterpretasikan dengan Sudut Pandang Ganda yang Bersinergi
Untuk mencapai deteksi yang dapat diinterpretasikan yang berorientasi pada kesetiaan fakta yang disebutkan sebelumnya, perlu mempertimbangkan dua jalur persepsi-kognisi secara bersamaan, menggabungkan kemampuan perspektif visual dalam mengungkap artefak visual dan ketidakkonsistenan spatio-temporal dengan kemampuan perspektif bahasa tingkat tinggi dalam melakukan penalaran terstruktur, sehingga menghubungkan pemandangan metode empat lapisan dalam sudut pandang ganda. Di satu sisi, model bahasa-visual dan model pemahaman video saat ini memiliki kemampuan diskriminasi yang relatif buruk terkait "kesetiaan persepsi" (perceptual fidelity), sehingga memerlukan metode perspektif visual untuk melengkapi. Di sisi lain, untuk video yang dihasilkan oleh model generatif yang lebih kuat dan metode anti-deteksi yang sangat setia dalam persepsi, perlu melakukan deteksi dalam ruang semantik dan faktual dari perspektif bahasa di tingkat fakta.
Lebih lanjut, membangun jalur penalaran eksplisit "identifikasi-pelokalan-penjelasan". Ini berarti bahwa dalam sistem dua jalur di atas, setiap panggilan alat atau referensi pengetahuan harus dihubungkan secara ketat dengan tautan argumen spesifik.
Selain itu, sistem deteksi yang dibentuk di "sisi konten" di atas perlu diverifikasi silang dengan sinyal autentikasi "sisi sumber" yang mungkin ada, menghubungkan analisis konten dengan pelacakan sumber. Akhirnya membentuk sistem deteksi multi-modal dan multi-tingkat serta ruang bukti yang dapat dipercaya dan dapat diinterpretasikan.
Kesimpulan
Deteksi video AI adalah tugas yang hanya akan semakin sulit.
Bagi penelitian dan aplikasi praktis deteksi AIGC-V di masa depan, tinjauan ini menyediakan peta yang lebih mendekati kebutuhan implementasi, mendefinisikan ulang tugas deteksi video hasil AI, mengusulkan kerangka empat lapis "sudut pandang ganda visual-bahasa", dan berdasarkan itu secara sistematis menyusun metode yang ada, tolok ukur terkait, dan metrik evaluasi, sekaligus menghubungkan tingkat-tingkat ini dengan tantangan dalam penyebaran nyata, celah dalam evaluasi yang ada, serta arah perkembangan yang sedang muncul.
Sepanjang kerangka ini, ditunjukkan beberapa persyaratan kunci yang diperlukan untuk deteksi yang dapat dipercaya, termasuk mengutamakan bukti, kesimpulan yang dapat dilacak, serta tetap tangguh dalam kondisi lintas generator dan skenario nyata.
Di masa depan, deteksi video AI yang dapat dipercaya juga sulit lagi diselesaikan secara independen oleh satu bidang tertentu, ia sedang menjadi masalah silang yang perlu dihadapi bersama oleh penelitian terkait CV, NLP, pemahaman multimodal, dan model dunia: CV menyediakan pemodelan bukti spatio-temporal dan ketahanan forensik, NLP menyediakan kemampuan penguraian proposisi, penalaran, pembuktian, dan penjelasan, penelitian multimodal dan model dunia menyediakan kemampuan keselarasan lintas-modalitas yang lebih kuat serta prior yang lebih kaya tentang fisika, sebab-akibat, dan konsistensi temporal.
Hanya dengan benar-benar menggabungkan kemampuan ini, deteksi video dapat secara bertahap melampaui pencarian artefak lokal, menuju ke arah "pandangan realitas" yang lebih ketat: masalahnya tidak lagi hanya apakah video terlihat dapat dipercaya, tetapi apakah entitas, peristiwa, dan proses dinamis di dalamnya selalu setia pada kendala dunia nyata, untuk mencari batas yang semakin kabur antara dunia virtual dan dunia nyata.
Referensi:https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Artikel ini berasal dari akun WeChat publik "新智元", editor: LRST