Ditulis oleh: KarenZ, Foresight News
Judul asli: Menguraikan Algoritma Rekomendasi Baru X dengan Bahasa Sederhana: Dari "Mengambil Data" hingga "Memberi Skor"
Apakah Musk telah mengubah sistem rekomendasi Twitter dari "tumpukan aturan buatan dan sebagian besar algoritma heuristik" menjadi "murni mengandalkan model AI besar untuk menebak kesukaan Anda?
Pada 20 Januari, Twitter (X) secara resmi mengungkap algoritma rekomendasi baru, yaitu logika di balik linimasa "For You" (Untuk Anda) di beranda Twitter.
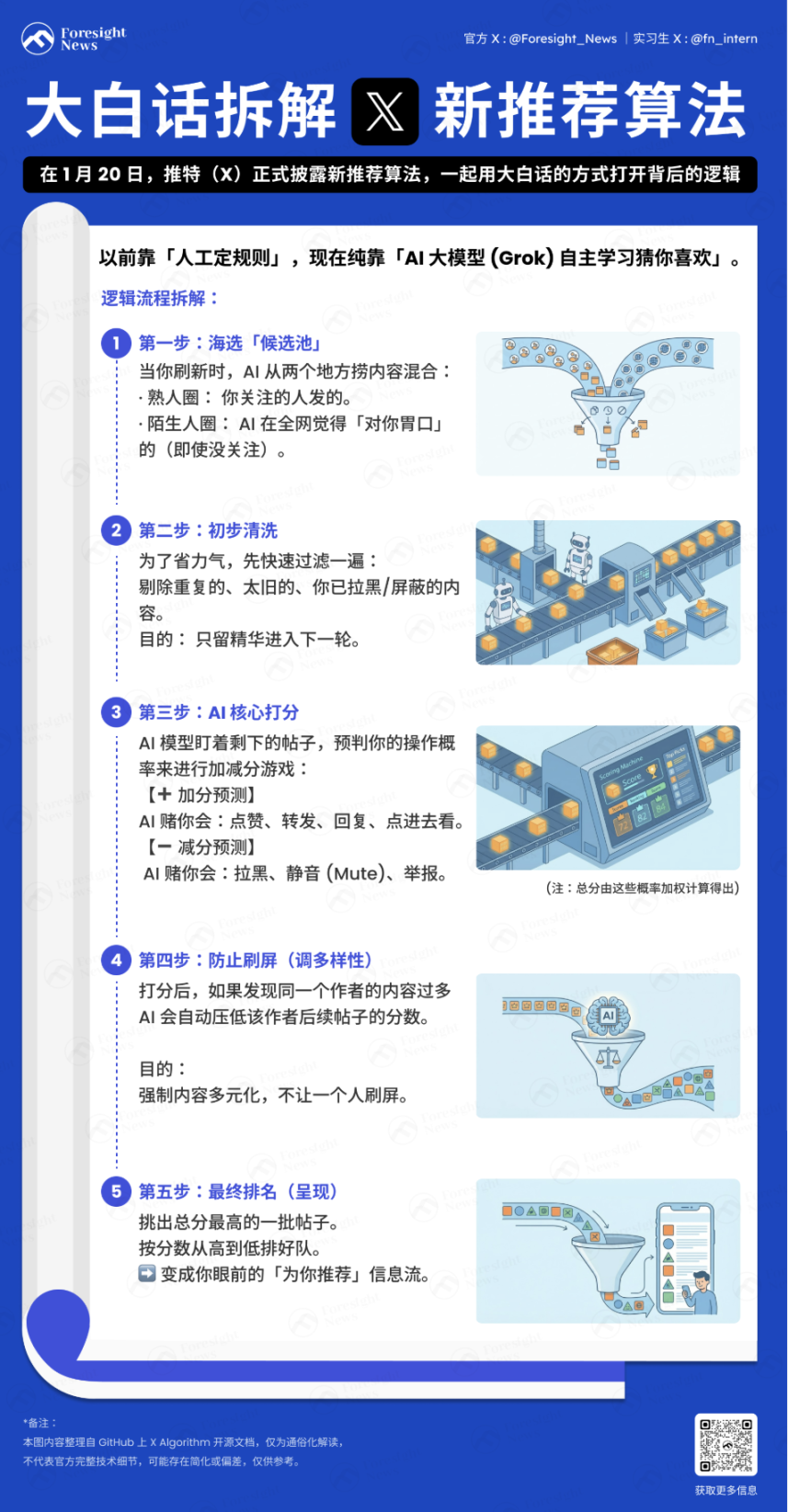
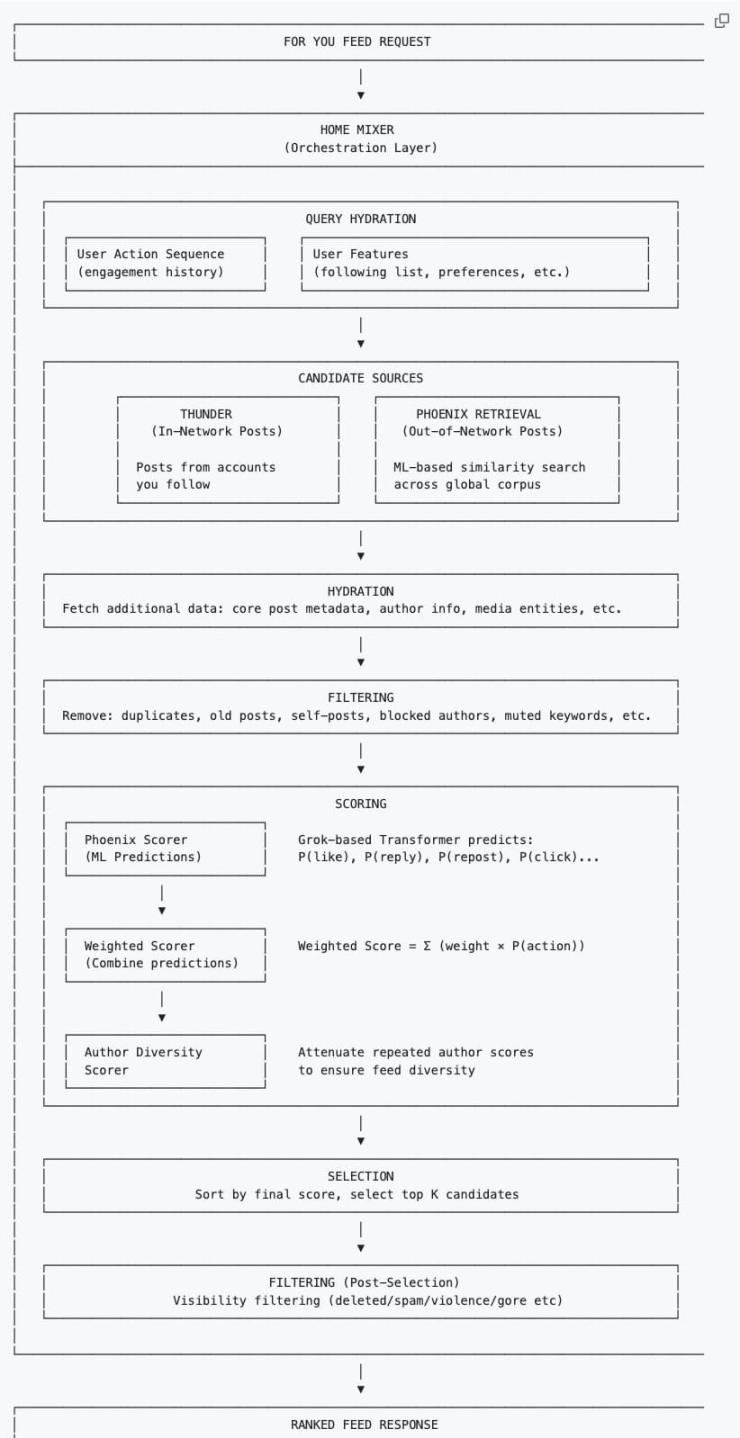
Secara sederhana, algoritma sekarang adalah: mencampur konten "dari orang yang Anda ikuti" dan "konten dari seluruh jaringan yang mungkin sesuai dengan selera Anda", kemudian mengurutkannya berdasarkan daya tariknya bagi Anda menurut serangkaian tindakan seperti like, komentar, dll. yang sebelumnya Anda lakukan di X, melewati dua kali penyaringan, dan akhirnya menjadi aliran informasi rekomendasi yang Anda lihat.
Berikut adalah logika inti yang diterjemahkan ke dalam bahasa sederhana:
Membangun Profil
Sistem pertama-tama mengumpulkan informasi konteks pengguna untuk membangun "profil" untuk rekomendasi selanjutnya:
-
Urutan Perilaku Pengguna: Riwayat interaksi (like, retweet, lama waktu tinggal, dll.).
-
Fitur Pengguna: Daftar yang diikuti, pengaturan preferensi pribadi, dll.
Dari Mana Kontennya?
Setiap kali Anda menyegarkan linimasa "Untuk Anda", algoritma akan mencari konten dari dua tempat berikut:
-
Lingkaran Kenalan (Thunder): Tweet yang diposting oleh orang yang Anda ikuti.
-
Lingkaran Orang Asing (Phoenix): Orang yang tidak Anda ikuti, tetapi AI akan mencari postingan yang mungkin menarik minat Anda (bahkan jika Anda tidak mengikuti penulisnya) dari lautan orang berdasarkan selera Anda.
Kedua tumpukan konten ini akan dicampur, menjadi kandidat tweet.
Pelengkapan Data dan Penyaringan Awal
Setelah mengambil ribuan postingan, sistem akan mengambil metadata lengkap postingan (informasi penulis, file media, teks inti), alur ini disebut Hydration. Kemudian akan dilakukan pembersihan cepat untuk menghilangkan konten duplikat, postingan lama, postingan yang Anda kirim sendiri, konten dari penulis yang diblokir, atau konten dengan kata kunci yang diblokir.
Langkah ini untuk menghemat sumber daya komputasi, mencegah konten tidak valid masuk ke tahap inti pemberian skor.
Bagaimana Cara Memberi Skor?
Ini adalah bagian yang paling krusial. Model Transformer berbasis Phoenix Grok akan mengawasi setiap kandidat postingan yang tersisa setelah penyaringan, menghitung probabilitas Anda melakukan berbagai tindakan terhadapnya. Ini adalah permainan penambahan dan pengurangan skor:
Poin Tambah (Umpan Balik Positif): AI mengira Anda mungkin akan like, retweet, membalas, mengklik gambar, atau mengklik untuk melihat profil.
Poin Kurang (Umpan Balik Negatif): AI mengira Anda mungkin akan memblokir penulis, membisukan (Mute), atau melaporkan.

Skor Akhir = (Probabilitas Like × Bobot) + (Probabilitas Balas × Bobot) – (Probabilitas Blokir × Bobot)...
Perlu dicatat bahwa dalam algoritma rekomendasi baru, Author Diversity Scorer (Pemberi Skor Keragaman Penulis) biasanya akan turun tangan setelah AI selesai menghitung skor akhir. Ketika mendeteksi bahwa dalam satu batch kandidat postingan terdapat banyak konten dari penulis yang sama, alat ini secara otomatis akan "menekan" skor postingan selanjutnya dari penulis tersebut, membuat penulis yang Anda lihat lebih beragam.
Akhirnya, berdasarkan pengurutan skor, dipilihlah sekumpulan postingan dengan skor tertinggi.
Penyaringan Sekunder
Sistem memeriksa kembali sejumlah postingan dengan skor tertinggi, menyaring yang melanggar aturan (seperti spam, konten kekerasan), menghapus duplikasi untuk beberapa cabang thread yang sama, dan akhirnya mengurutkannya dari skor tertinggi ke terendah, menjadi aliran informasi yang Anda lihat.
Kesimpulan
X telah menghapus semua fungsi yang dirancang secara manual dan sebagian besar algoritma heuristik dari sistem rekomendasi. Kemajuan inti dari algoritma baru terletak pada "membiarkan AI belajar sendiri preferensi pengguna", mencapai lompatan dari "memberi tahu mesin cara melakukannya" ke "membiarkan mesin belajar sendiri cara melakukannya".
Pertama, rekomendasi lebih akurat, "prediksi multi-dimensi" lebih sesuai dengan kebutuhan nyata. Algoritma baru mengandalkan model besar Grok untuk memprediksi berbagai perilaku pengguna — tidak hanya menghitung "apakah akan like/retweet", tetapi juga menghitung "apakah akan mengklik tautan untuk melihat", "bagaimana waktu tinggal", "apakah akan mengikuti penulis", bahkan memprediksi "apakah akan melaporkan/memblokir". Penilaian yang sangat detail ini membuat konten rekomendasi mencapai tingkat kesesuaian yang belum pernah terjadi sebelumnya dengan kebutuhan bawah sadar pengguna.
Kedua, mekanisme algoritma relatif lebih adil, sampai batas tertentu dapat memecahkan kutukan "monopoli akun besar", memberi lebih banyak peluang untuk akun baru dan kecil: Algoritma "heuristik" masa lalu memiliki masalah fatal: akun besar mengandalkan volume interaksi historis yang tinggi, konten apa pun yang diposting akan mendapatkan eksposur tinggi, sementara akun baru, meskipun kontennya berkualitas, terkubur karena "tidak ada akumulasi data". Mekanisme isolasi kandidat membuat setiap postingan diberi skor secara independen, tidak terkait dengan "apakah konten lain dalam batch yang sama adalah viral". Selain itu, Author Diversity Scorer juga akan mengurangi perilaku membanjiri (spam) postingan selanjutnya dari penulis yang sama dalam batch yang sama.
Bagi perusahaan X: Ini adalah langkah pengurangan biaya dan peningkatan efisiensi, menggunakan daya komputasi untuk menggantikan tenaga manusia, menggunakan AI untuk meningkatkan retensi. Bagi pengguna, kita menghadapi "otak super" yang selalu mencoba memahami pikiran kita. Semakin ia memahami kita, semakin kita tidak dapat meninggalkannya, tetapi justru karena ia terlalu memahami kita, kita akan lebih dalam terjerat dalam "kamar informasi" yang ditenun oleh algoritma, dan lebih mudah menjadi sasaran penangkapan yang tepat untuk konten-konten emosional.
Twitter:https://twitter.com/BitpushNewsCN
Grup Komunikasi TG Bitpush:https://t.me/BitPushCommunity
Berlangganan TG Bitpush: https://t.me/bitpush