Baru saja, DeepSeek-V4 hadir!
Versi pratinjau resmi diluncurkan dan disinkronkan sebagai sumber terbuka.
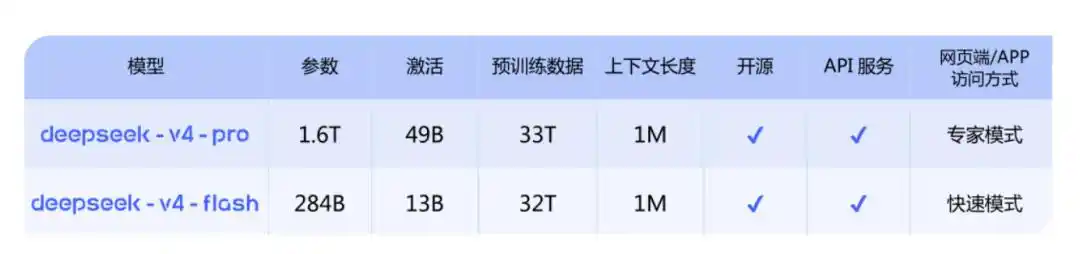
Total ada dua versi:
DeepSeek-V4-Pro: Setara dengan model sumber tertutup teratas, 1.6T, 49B aktivasi, panjang konteks 1M;
DeepSeek-V4-Flash: Versi ekonomis yang lebih kecil dan lebih cepat, 284B, 13B aktivasi, panjang konteks 1M.
Pernyataan resmi adalah: Dalam kemampuan Agent, pengetahuan dunia, dan kinerja penalaran, semuanya mencapai kepemimpinan di dalam negeri dan bidang sumber terbuka.
Dan:
Saat ini DeepSeek-V4 telah menjadi model Agentic Coding yang digunakan oleh karyawan internal perusahaan. Menurut umpan balik evaluasi, pengalaman penggunaannya lebih baik daripada Sonnet 4.5, kualitas pengiriman mendekati mode non-pemikiran Opus 4.6. Namun, masih ada kesenjangan tertentu dengan model pemikiran Opus 4.6.
Saat ini situs web dan APP sudah tersedia, layanan API juga telah diperbarui secara bersamaan.
Untuk daya komputasi domestik yang menjadi perhatian semua orang, poin pentingnya, pada paruh kedua tahun ini mendukung daya komputasi Huawei.

Pilihan Spesifikasi Tertinggi dan Hemat Biaya, Dua Versi Diluncurkan Bersamaan
Kali ini V4 langsung meluncurkan dua versi.
V4-Pro, kinerja setara dengan model sumber tertutup teratas.
Penilaian resmi yang diberikan ada tiga poin:
Kemampuan Agent meningkat drastis: Dalam evaluasi Agentic Coding, V4-Pro telah mencapai level terbaik model sumber terbuka saat ini, dan juga berkinerja sangat baik dalam evaluasi terkait Agent lainnya. Dalam evaluasi internal, dalam mode Agent Coding, pengalaman V4 lebih baik daripada Sonnet 4.5, kualitas pengiriman mendekati mode non-pemikiran Opus 4.6, tetapi masih ada kesenjangan dengan mode pemikiran Opus 4.6.
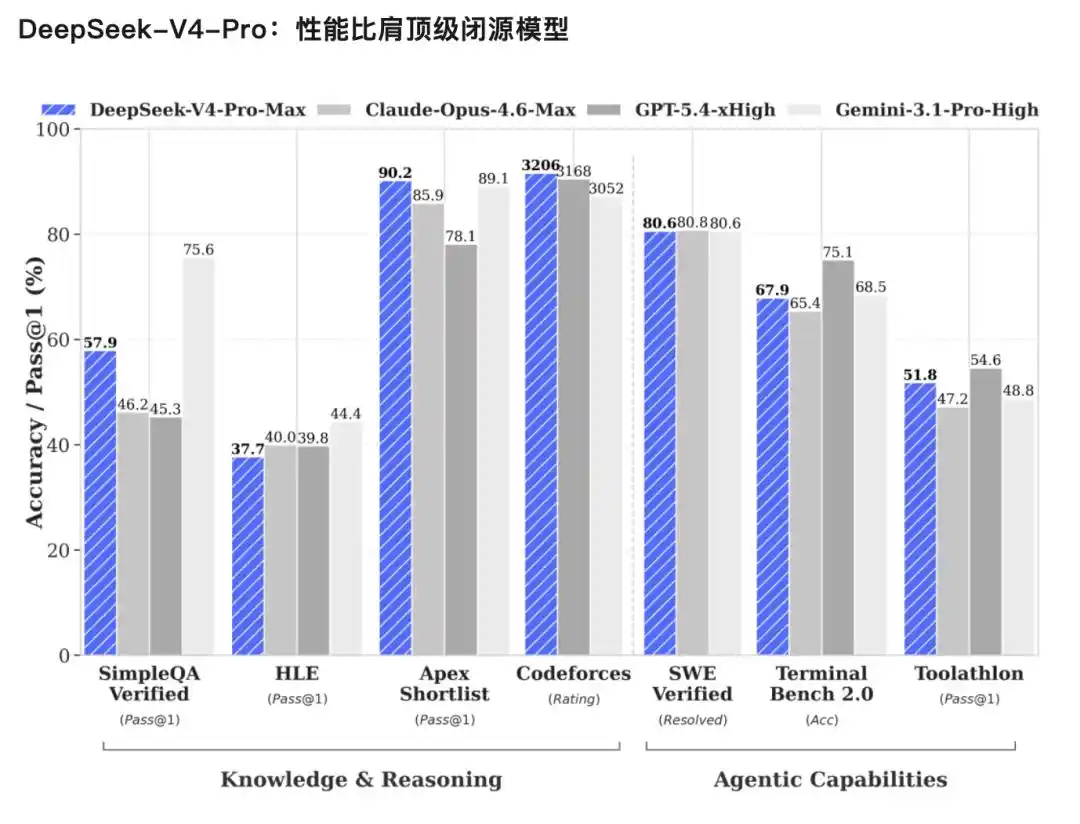
Pengetahuan dunia yang kaya: DeepSeek-V4-Pro dalam evaluasi pengetahuan dunia, jauh memimpin model sumber terbuka lainnya, hanya sedikit lebih rendah dari model sumber tertutup teratas Gemini-Pro-3.1.
Kinerja penalaran tingkat dunia: Dalam evaluasi matematika, STEM, dan kode kompetitif, DeepSeek-V4-Pro melampaui semua model sumber terbuka yang telah dievaluasi secara publik saat ini, mencapai hasil yang setara dengan model sumber tertutup teratas dunia.
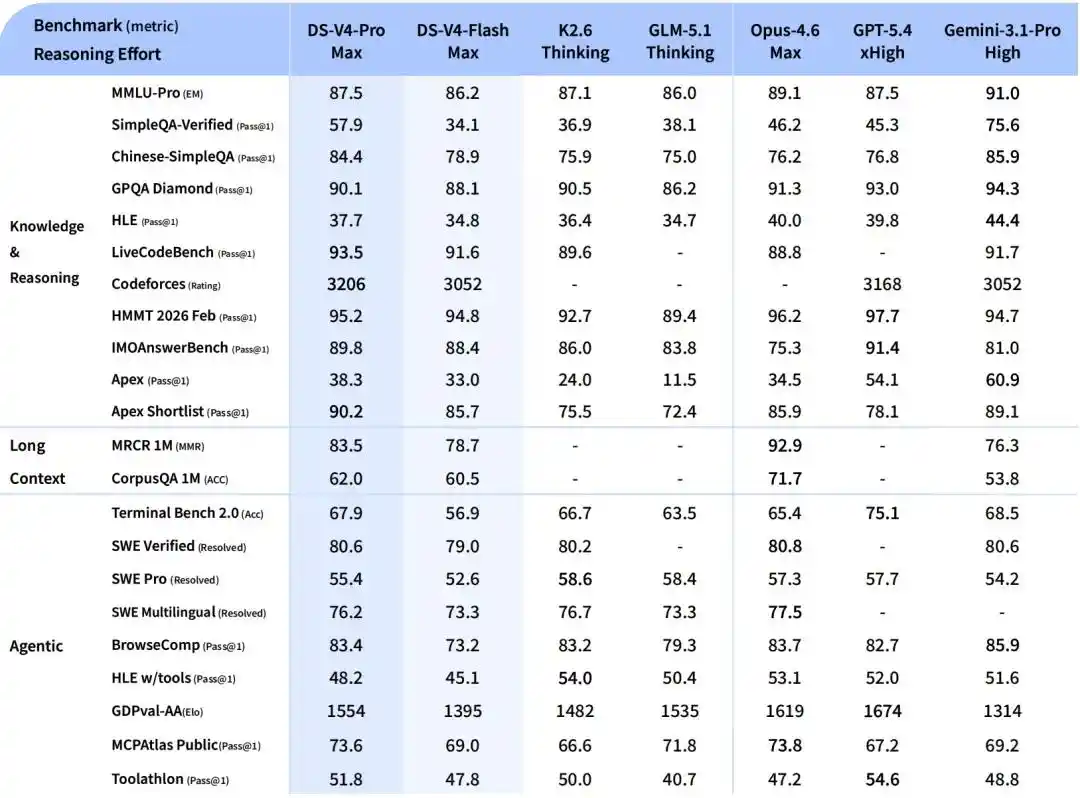
V4-Flash, versi ekonomis yang lebih kecil dan lebih cepat. Kemampuan penalaran mendekati Pro, cadangan pengetahuan dunia sedikit lebih rendah, tetapi parameter dan aktivasi lebih kecil, API lebih murah.
Dalam tugas Agent, DeepSeek-V4-Flash dalam tugas sederhana setara dengan DeepSeek-V4-Pro, tetapi dalam tugas dengan kesulitan tinggi masih ada kesenjangan.
Dalam tes cuci mobil, V4 juga lolos dengan cepat.

Dan dalam adegan biologi klasik "Ayah yang Putus Asa", DeepSeek-V4 tidak langsung menangkap poin kunci buta warna merah-hijau dalam satu putaran (menurut hukum genetika, jika seorang perempuan buta warna merah-hijau, ayah biologisnya pasti juga buta warna).

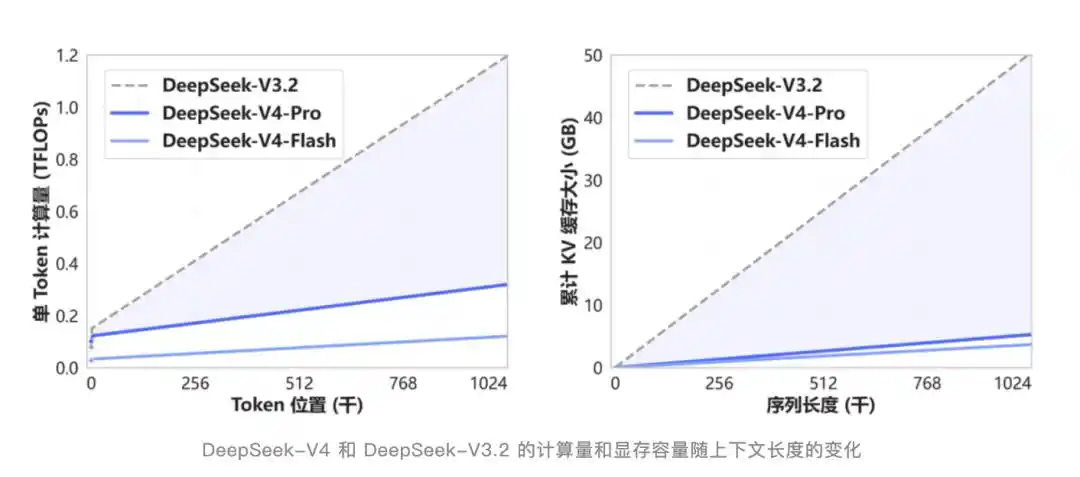
Konteks 1 Juta Menjadi Standar
Yang patut dicatat, mulai hari ini, konteks 1M adalah standar untuk semua layanan resmi DeepSeek.
Setahun yang lalu, konteks 1M masih menjadi andalan eksklusif Gemini; semua model sumber tertutup lainnya maksimal 128K atau 200K; di sisi sumber terbuka hampir tidak ada yang bisa memainkan level ini.
DeepSeek langsung mengubah konteks 1 juta dari "fitur high-end" menjadi "listrik, air, dan gas".
Dan sumber terbuka. Bagaimana mereka melakukannya, dalam rilis langsung diberikan jawabannya—
V4 menciptakan mekanisme perhatian baru yang sepenuhnya, melakukan kompresi pada dimensi token, dikombinasikan dengan perhatian jarang DSA. Dibandingkan dengan metode tradisional, kebutuhan komputasi dan memori menurun drastis.
DSA bukan kata baru. Setengah tahun yang lalu, pembaruan V3.2-Exp pertama kali memperkenalkannya, saat itu perhatian eksternal tidak tinggi, karena skor berlari dan V3.1-Terminus hampir sama, terlihat seperti versi perantara yang tidak banyak fitur.
Sekarang melihat ke belakang, itu adalah fondasi V4.
Optimisasi Khusus Kemampuan Agent
Di sisi Agent, V4 melakukan adaptasi dan optimisasi untuk produk Agent utama seperti Claude Code, OpenClaw, OpenCode, CodeBuddy, tugas kode, tugas pembuatan dokumen semuanya meningkat.
Dalam rilis juga dilampirkan contoh halaman internal PPT yang dihasilkan V4-Pro dalam kerangka Agent tertentu.

Harga API
Di sisi API, V4-Pro dan V4-Flash diluncurkan bersamaan, mendukung dua set antarmuka: OpenAI ChatCompletions dan Anthropic.
base_url tidak berubah, parameter model diubah menjadi deepseek-v4-pro atau deepseek-v4-flash untuk dipanggil.
Kedua versi memiliki konteks maksimal 1M, keduanya mendukung mode non-pemikiran dan mode pemikiran. Dalam mode pemikiran, intensitas dapat disesuaikan melalui parameter reasoning_effort, dua tingkat high dan max. Saran resmi untuk skenario Agent kompleks langsung gunakan max.
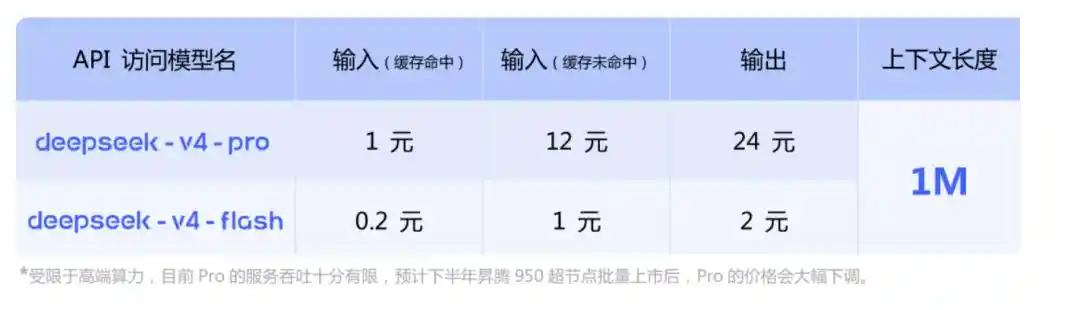
Di sini ada poin penting—paruh kedua tahun ini mendukung daya komputasi Huawei.
Selain itu, nama model lama akan dihapus.
deepseek-chat dan deepseek-reasoner akan dinonaktifkan dalam tiga bulan (24 Juli 2026), pada tahap saat ini kedua nama ini masing-masing mengarah ke mode non-pemikiran dan pemikiran V4-Flash.
Bagi pengembang individu dampaknya tidak besar, cukup ubah satu parameter model. Perusahaan yang telah terhubung dengan lingkungan produksi, dalam tiga bulan ini harus melakukan migrasi.
One more thing
Di akhir rilis, DeepSeek sendiri mengutip sebuah kalimat.
"Tidak tergoda oleh pujian, tidak takut pada fitnah, berjalan sesuai jalan, teguh meluruskan diri."
Ini adalah kalimat dari Xunzi "Fei Shi Er Zi". Secara harfiah berarti, tidak tergoda oleh pujian, tidak takut pada fitnah, berjalan sesuai jalan yang diyakini, meluruskan diri.
Dalam konteks hari ini, agak menarik.
Setengah tahun terakhir, rumor tentang kapan V4 dirilis, apakah tertunda, apakah sudah disalip oleh pihak lain, apakah sudah ditangani oleh data distilasi Claude, dan sejenisnya, bolak-balik beberapa putaran di komunitas AI bahasa Cina dan Inggris. Awal tahun bahkan ada yang bersumpah V4 akan dirilis sebelum Tahun Baru Imlek, tetapi akhirnya menunggu sampai akhir April.
Mereka tidak menanggapi sekali pun.
Kemudian pada suatu Jumat sore, mengeluarkan V4, sinkron sumber terbuka, sinkron online situs web dan App, sinkron perbarui API, sekaligus menuliskan fakta bahwa karyawan internal sudah meninggalkan Claude ke dalam rilis.
Tidak ada peta jalan, tidak ada siaran langsung, tidak ada wawancara.
Empat kata "berjalan sesuai jalan", terdengar seperti sebuah slogan. Tetapi jika Anda melihat setengah tahun lalu versi Exp V3.2 yang "tidak banyak亮点 (highlight)", set DSA perhatian jarang yang membuka jalan untuk V4 selama setengah tahun, jalur konteks 1M dari andalan menjadi standar ini.
DeepSeek sudah melakukannya.
Tautan sumber terbuka model DeepSeek-V4:
[1]https://huggingface.co/collections/deepseek-ai/deepseek-v4
[2]https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
Laporan teknis DeepSeek-V4: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
Artikel ini dari akun WeChat publik "量子位", penulis: 量子位





