Seberapa kecilkah sebuah gambar dapat dikompresi?
Pada Februari 2025, Kelompok Ahli Gambar Internasional (JPEG) mengumumkan sebuah pencapaian yang dirayakan secara sederhana oleh industri: JPEG AI, standar internasional pertama untuk pengkodean gambar berbasis pembelajaran end-to-end yang telah lama dinantikan, secara resmi diluncurkan.

Berita ini tersebar, dan banyak peneliti membagikannya di media sosial dengan komentar seperti 'AI akhirnya masuk ke dalam standar.'
Standar JPEG lahir pada 1992 dan selama lebih dari tiga dekade telah menjadi bahasa dasar bagi gambar digital manusia. Dan sekarang, kecerdasan buatan mulai mengambil alih dan menulis ulang tata bahasa bahasa tersebut.
Namun, di balik perayaan tersebut, terdapat sebuah realitas yang halus: bahkan JPEG AI pun masih memiliki jarak yang cukup jauh dari kompresi perseptual yang sesungguhnya.
Para insinyur tahu bahwa metrik tradisional untuk mengukur kualitas kompresi, Peak Signal-to-Noise Ratio (PSNR), sebenarnya tidak terlalu berkaitan dengan 'apakah terlihat bagus' menurut mata manusia. Sebuah gambar mungkin mendapat skor PSNR tinggi, tetapi orang yang melihatnya mungkin merasa biasa-biasa saja; sebaliknya, gambar dengan PSNR rendah mungkin dianggap kaya detail dan teksturnya nyata. Mengoptimalkan metrik matematis dan mengoptimalkan persepsi mata manusia adalah dua hal yang sangat berbeda.
Selama beberapa dekade, dari JPEG ke VVC, hingga JPEG AI, hampir semua logika desain codec masih berputar dalam kerangka metrik matematis. Kompresi perseptual (yang mengoptimalkan langsung untuk pengalaman visual manusia) selalu tampak seperti tujuan jangka panjang dalam makalah akademis, bukan realitas teknis yang dapat dimasukkan ke dalam ponsel.
Di momen inilah, sebuah tim insinyur Apple diam-diam menerbitkan sebuah makalah penelitian yang memberikan jawaban mereka, dengan kode nama: PICO.

Judul Makalah: What Matters in Practical Learned Image Compression
Alamat Makalah: https://arxiv.org/pdf/2605.05148
Mengapa "Terlihat Lebih Baik" Jauh Lebih Sulit daripada "Angka Lebih Tinggi"?
Sebelum memahami PICO, kita perlu memahami apa yang sebenarnya dilakukan oleh kompresi gambar.
Menyimpan sebuah foto menjadi file pada dasarnya adalah soal memilih 'apa yang dilupakan dan apa yang diingat'. Ruang penyimpanan terbatas, sehingga sebagian informasi harus dibuang, sambil berusaha agar orang yang melihatnya tidak terlalu menyadarinya. Codec yang berbeda mengikuti 'cara membuang' yang berbeda.
Codec tradisional seperti JPEG, AV1, VVC adalah sistem aturan yang dirancang secara manual oleh insinyur. Mereka membagi gambar menjadi blok-blok, melakukan transformasi, kuantisasi, dan pengkodean entropi — setiap langkah adalah pengalaman buatan manusia yang terakumulasi selama puluhan tahun. Sistem seperti ini dapat berkinerja sangat baik dalam metrik matematis seperti PSNR, tetapi desainnya pada dasarnya berorientasi pada 'mengurangi kesalahan piksel', bukan 'mengurangi ketidaknyamanan visual bagi mata manusia'.
Masalahnya, mata manusia bukanlah pengukur kesalahan piksel. Sensitivitas mata manusia terhadap tekstur, teks, dan detail jauh lebih kompleks daripada rumus matematika. Saat Anda mengompresi foto pemandangan jalan menjadi sangat kecil, PSNR mungkin masih terlihat baik, tetapi Anda akan melihat tepi bangunan yang buram, huruf pada papan nama yang terdistorsi — dan hal-hal inilah yang pertama kali disadari oleh mata manusia.
Kemunculan codec berbasis pembelajaran, secara teori, membuka pintu baru: jaringan saraf dapat dilatih secara end-to-end langsung untuk persepsi manusia, bukan untuk rumus matematika. Namun, sebelum PICO, codec pembelajaran perseptual yang ada, baik itu terlalu lambat untuk digunakan praktis, kurang kompatibilitas lintas perangkat, atau tidak dapat mengontrol bitrate dengan fleksibel, sama sekali tidak dapat dimasukkan ke dalam produk konsumen.
Tiga Masalah Inti, Tiga Solusi
PICO adalah singkatan dari Perceptual Image Codec (Codec Gambar Perseptual). Nama ini langsung menyebutkan tujuannya: memuaskan mata manusia.
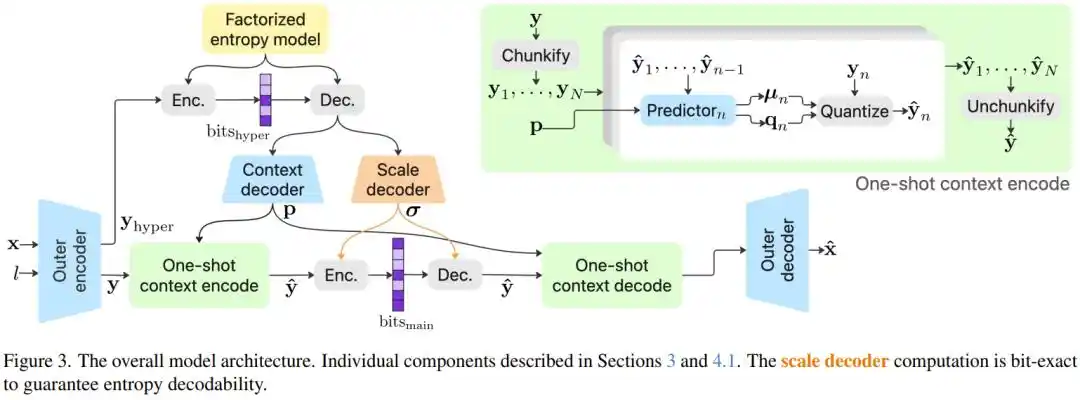
Tim peneliti secara sistematis mengeksplorasi jutaan konfigurasi model dan memperkenalkan beberapa inovasi teknologi kunci.
Masalah Pertama: Pengkodean Entropi Lambat, Bagaimana Solusinya?
Ada tantangan dalam kompresi gambar: untuk mengompresi lebih kecil, codec perlu menggunakan 'model entropi' untuk memperkirakan dengan tepat jumlah informasi setiap piksel. Metode yang paling tepat disebut pengkodean autoregresif: setiap piksel yang dikompresi harus melihat terlebih dahulu piksel di sekitarnya yang telah dikompresi, untuk memprediksi selanjutnya. Ini seperti seorang koki yang setiap kali menambahkan bahan, harus melihat kembali ke dalam wajan untuk memutuskan langkah berikutnya. Tepat, tetapi sangat lambat.
Solusi PICO adalah "Model Konteks Sekali Jalan" (One-shot Context Model): memisahkan parameter 'skala' yang paling kritis dalam pengkodean entropi, menghitungnya semua dalam satu kali propagasi maju, tanpa perlu menunggu bolak-balik; sementara parameter lainnya dapat dihitung secara paralel, mempertahankan akurasi autoregresif, namun menghindari hambatan kecepatannya. Hasilnya: tanpa modul ini, kinerja model turun 10,28%; dengannya, kecepatan hampir tidak terpengaruh.
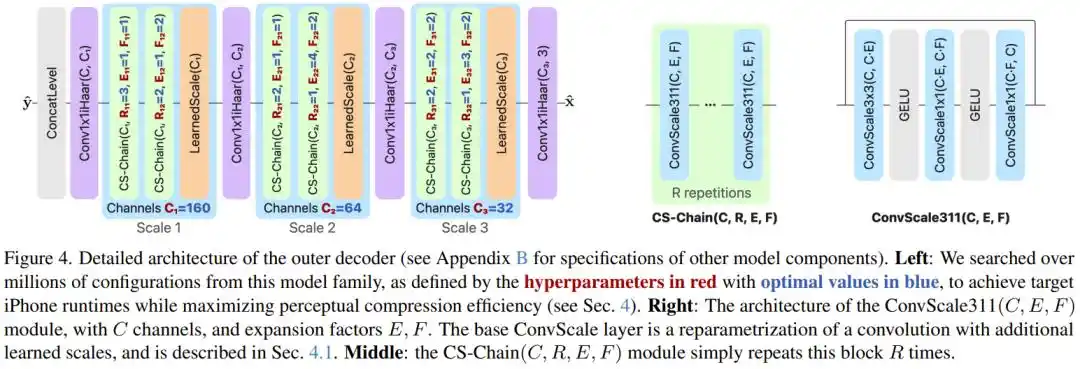
Masalah Kedua: Pelatihan Perseptual Menghasilkan Halusinasi, Bagaimana Solusinya?
Gambar yang dilatih dengan GAN (Generative Adversarial Network) seringkali 'terlihat sangat nyata', tetapi bisa jadi kenyataan yang dibuat-buat — helai rambut berubah menjadi pola yang tidak ada, permukaan halus muncul tekstur palsu. Yang lebih merepotkan, mata manusia sangat sensitif terhadap teks, bahkan sedikit perubahan pada satu huruf pun akan langsung terdeteksi.
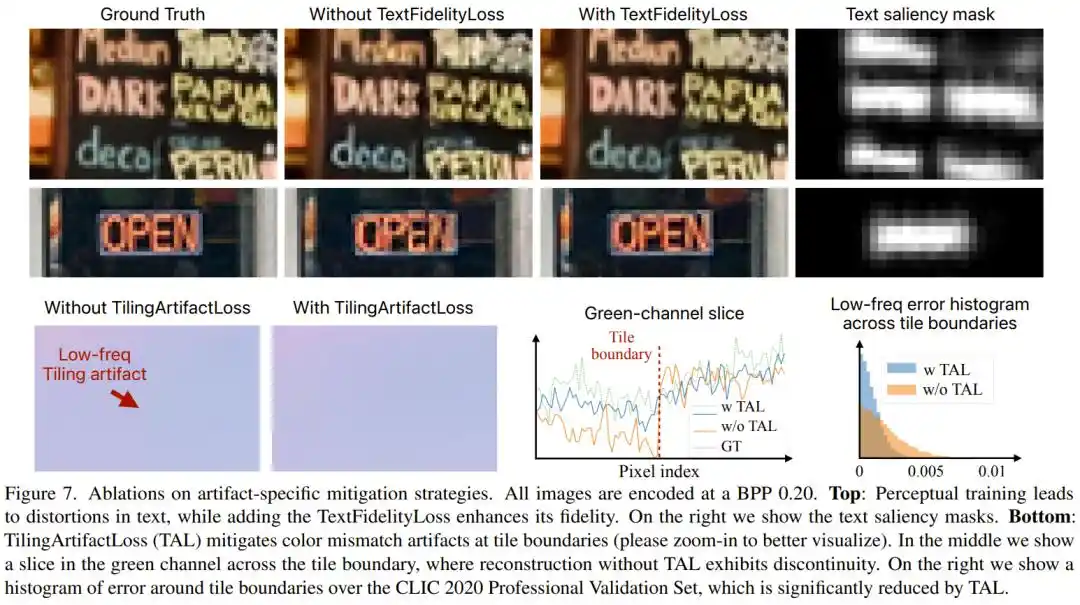
PICO secara khusus merancang TextFidelityLoss untuk teks: menggunakan pendeteksi teks yang sudah ada untuk secara otomatis menemukan area teks dalam gambar, kemudian menerapkan batasan ketat pada kesetiaan piksel di area tersebut, sekaligus menekan 'ruang bermain' GAN di area teks. Eksperimen menunjukkan bahwa dengan menambahkan fungsi kerugian ini, kesalahan absolut di area teks berkurang hingga setengahnya.
Masalah Ketiga: Pemrosesan Gambar Per Blok Menyebabkan Batasan Blok Warna, Bagaimana Solusinya?
Agar dapat berjalan cepat pada chip ponsel, PICO memotong gambar menjadi ubin-ubin berukuran 504×504 piksel, memprosesnya secara terpisah, lalu menyatukannya kembali. Namun, GAN saat pelatihan cenderung mengabaikan warna frekuensi rendah, menyebabkan perbedaan warna yang terlihat antara ubin yang berdekatan, mirip dengan perasaan 'tidak tersambung dengan baik' saat mengedit foto. Tim peneliti secara khusus memperkenalkan TilingArtifactLoss, sebuah kerugian L1 multi-resolusi, yang memaksa model untuk menjaga konsistensi warna pada beberapa frekuensi spasial. Langkah ini juga mengurangi kesalahan pada batas ubin hingga lebih dari setengahnya.
Hasil Eksperimen
Tim Apple tidak hanya mengandalkan metrik evaluasi patokan. Mereka mempercayakan platform pihak ketiga, Mabyduck, untuk mengorganisir evaluasi subjektif manusia dalam skala besar.
Evaluasi dilakukan dengan metode perbandingan berpasangan buta (blind pairwise comparison): 610 evaluator yang telah disaring (harus lulus tes buta warna dan tes identifikasi artefak kompresi) membandingkan hasil rekonstruksi gambar yang sama dari codec yang berbeda secara berpasangan, yang akhirnya disimpulkan menjadi skor Bayesian ELO. Total dikumpulkan 74.925 hasil perbandingan berpasangan.

Angka akhir menjelaskan semuanya: Pada kualitas visual yang sama, ukuran file PICO hanya sepertiga hingga setengah dari AV1, AV2, VVC, ECM, dan JPEG AI — dengan kata lain, untuk menyimpan gambar yang sama, PICO hanya membutuhkan 30%-43% bit dari standar-standar tersebut. Dibandingkan dengan codec pembelajaran perseptual terkuat saat ini (seperti HiFiC, MRIC), PICO juga menghemat 20%-40% ukuran file.
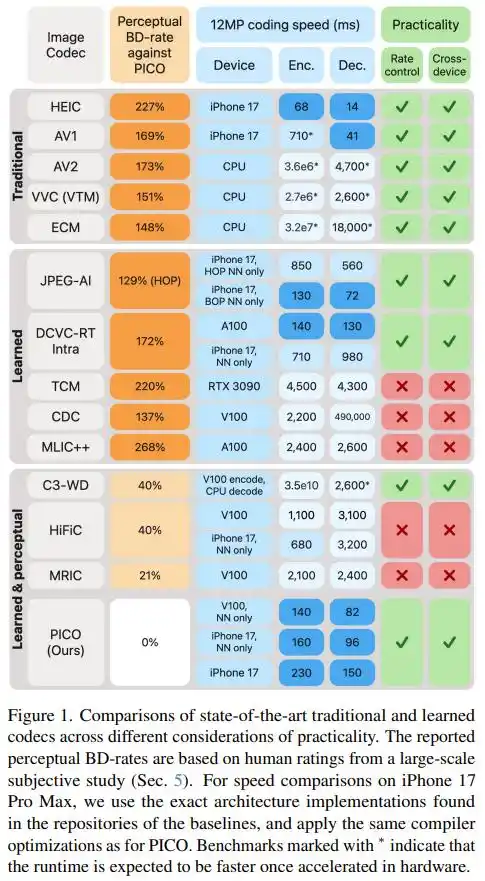
Dari sisi kecepatan, pada iPhone 17 Pro Max, PICO hanya membutuhkan 230 milidetik untuk mengkodekan foto 12MP, dan hanya 150 milidetik untuk mendekodenya. Sedangkan sebagian besar codec ML tingkat tinggi berjalan lebih lambat dari ini bahkan di server dengan kartu grafis NVIDIA V100.
Patut dicatat, makalah ini juga secara khusus mencatat sebuah 'contoh sebaliknya': pada metrik tradisional PSNR, kinerja PICO biasa-biasa saja, bahkan kalah dari DCVC-RT dan VVC. Ini justru mengonfirmasi penilaian dasar tim: mengoptimalkan kualitas perseptual dan mengoptimalkan metrik matematis pada dasarnya adalah dua arah yang berbeda, sulit untuk mendapatkan keduanya sekaligus.
Sebuah Titik Dalam Sejarah, Bukan Akhir
PICO tentu juga memiliki keterbatasan. Makalah ini secara terbuka mengakui bahwa untuk gambar sintetis yang sangat teratur seperti kartun atau diagram skematis, efisiensi kompresi PICO tidak sebaik codec tradisional, karena konten seperti ini secara alami cocok untuk pemodelan autoregresif yang digerakkan aturan, bukan untuk pembangkitan perseptual.
Namun, keterbatasan ini tidak mengaburkan makna dari pekerjaan ini.
Selama tiga puluh tahun terakhir, kemajuan teknologi kompresi gambar hampir seluruhnya terjadi di jalur 'membuat angka terlihat lebih baik'. Dari JPEG ke HEVC, hingga VVC, yang dioptimalkan para insinyur dari generasi ke generasi adalah metrik seperti PSNR dan SSIM. Sedangkan persepsi mata manusia, selalu menjadi 'masalah sulit' yang dihindari.
PICO adalah pertama kalinya seseorang secara sistematis membedah masalah sulit ini secara langsung: mulai dari pencarian arsitektur, desain fungsi kerugian, hingga evaluasi subjektif manusia skala besar, dan akhirnya memasukkannya ke dalam sebuah codec yang dapat berjalan secara real-time di ponsel.
Saat Anda berikutnya berbagi foto menggunakan perangkat Apple, Anda mungkin tidak merasakan perbedaan apa pun. Namun, mungkin dalam proses kompresi yang sunyi itu, seperangkat algoritma yang dirancang khusus untuk persepsi mata manusia sedang memutuskan informasi mana yang layak dipertahankan, dan mana yang bisa dilupakan dengan diam-diam.
Tim: Dari WaveOne ke Apple
Penulis korespondensi makalah ini adalah Oren Rippel, peneliti Apple, dan wajah lama di bidang kompresi.
Namanya pertama kali muncul secara luas pada tahun 2017. Saat itu, ia masih berada di perusahaan startup WaveOne, menerbitkan sebuah makalah berjudul "Real-Time Adaptive Image Compression", di mana ia menggunakan jaringan saraf untuk mengalahkan semua codec utama saat itu, sambil mempertahankan kecepatan real-time. Makalah itu menimbulkan gelombang kecil di dunia akademis dan juga mengukuhkan posisi Rippel di bidang kompresi berbasis pembelajaran.

Kemudian, inti tim yang sama terus mendalami di WaveOne dan meluncurkan ELF-VC untuk kompresi video, yang pada kumpulan uji video UVG menghemat bitrate hingga 44% dibandingkan H.264, sementara kecepatan operasinya lima kali lebih cepat daripada codec ML sejenis.
Tim dari WaveOne ini kemudian bergabung seluruhnya dengan Apple. Dan PICO ini adalah jawaban sistematis pertama mereka dengan sumber daya komputasi dan platform Apple di bidang kompresi gambar perseptual.
Artikel ini berasal dari akun WeChat "机器之心" (ID: almosthuman2014), penulis: 压缩即智能 (Kompresi adalah Kecerdasan)






