Oleh | Silicon Star
Gagasan terkenal Sam Altman kali ini terbukti pada semua orang.
Tahun lalu saat mempromosikan GPT-5, CEO OpenAI ini mengatakan sesuatu yang kemudian menjadi bahan candaan di seluruh internet: "Rasanya seperti melihat ledakan bom atom, pusing dan terduduk lemas." Sejak itu, setiap kali industri AI merilis produk baru dengan narasi berlebihan, lelucon ini terus diulang.

Tapi dua malam yang lalu, yang pusing dan terduduk lemas bukanlah Altman. Kali ini, semua pengguna yang menatap layar menunggu langkah OpenAI.
Altman seperti biasa berpura-pura misterius, mengirimkan tweet: "Kami menyiapkan sesuatu yang menarik."
Menjelang pukul tiga pagi, GPT-Image 2 diluncurkan. Dunia AI global langsung gempar.
"Images are a language, not decoration."
Ini adalah kalimat pertama yang ditulis OpenAI di halaman peluncurannya. Diterjemahkan, artinya hanya satu: mulai hari ini, gambar bukan lagi hiasan, ia sendiri adalah bahasa. Ini adalah deklarasi lompatan generasi untuk seluruh industri visi komputer.
Selama setahun terakhir, gambar AI masih terperangkap dalam rawa estetika "apakah gambarnya mirip". Kehadiran GPT-Image 2 langsung menekan tombol pengalihan—pembuatan gambar AI secara resmi memasuki ujian kecerdasan "apakah logikanya benar".
Akurasi model ini, jika digambarkan, "menakutkan".
Menduduki puncak tangga lagu pembuatan gambar dari teks dan penyuntingan gambar di Artificial Analysis, performa dalam pertempuran nyata bahkan lebih menghancurkan.
Rasanya, seperti ketika Seedance 2.0 di bidang pembuatan video turun, ia sudah lama bukan lagi alat bantu manusia, ia sedang mendefinisikan standar industri baru.
Catatan: Gambar dalam artikel ini seluruhnya dihasilkan oleh GPT-Image 2, konten gambar sepenuhnya fiktif.
01 Kebangkitan Mesin Pemikir
Dulu, standar pertama orang menilai model gambar baik atau tidak adalah apakah mirip orang sungguhan, mirip referensi.
Di hadapan monster GPT-Image 2 ini, standar itu sudah ketinggalan zaman. Benar-benar ketinggalan zaman.
Titik terobosan inti model baru ada di sini: ini adalah model gambar yang mendukung mode pemikiran.
Apa maksudnya? Setelah pengguna memasukkan kata kunci, model tidak lagi sekadar mengurangi noise, menyambung piksel. Ia pertama-tama menyelesaikan pemodelan pemikiran di latar belakang, baru kemudian mulai menggambar.
Gambar uji coba yang bocor dari komunitas Linux.do paling menjelaskan masalahnya. Model mensimulasikan adegan Lei Jun berlari secara live:
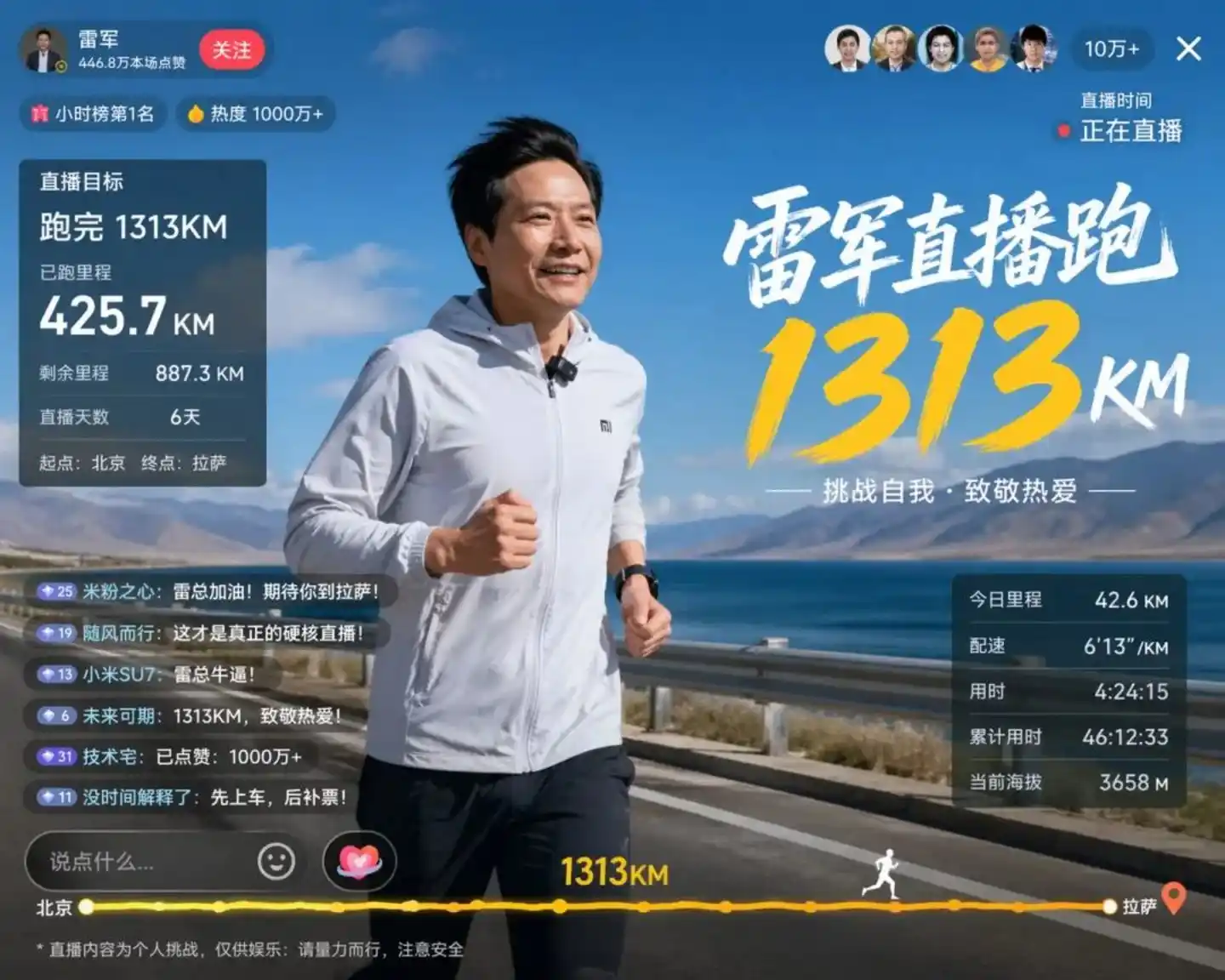
Sumber: https://cdn3.linux.do/original/4X/0/f/3/0f37c8bc968e3d563cc6100d8e7f80ee305661ff.jpeg
Gambar ini membuat banyak developer menarik napas dalam-dalam. Fitur wajah Lei Jun direproduksi dengan presisi—hampir seperti foto—gambar juga jelas menunjukkan: target siaran langsung 1313km, jarak tempuh 425.7km, sisa jarak 887.3km. Yang lebih hebat, ketinggian saat ini tertulis 3658m.
3658m itu konsep seperti apa? Dari Beijing ke Lhasa, ketinggian khas saat memasuki wilayah Tibet, tepatnya angka ini.
Di mata manusia, ini hanya penambahan dan pengurangan matematika sederhana dan pengetahuan geografis umum. Tapi coba pikirkan: bagi sebuah model gambar, apa artinya kesatuan tiga hal: logika matematika + pengetahuan geografis + spesifikasi UI?
Kesimpulannya langsung: sebelum menghasilkan piksel pertama, GPT-Image 2 telah menyelesaikan satu putaran penalaran. Ia memahami arti "jarak tempuh", memahami hubungan logika penambahan dan pengurangan, juga memahami karakteristik visual daerah dataran tinggi.
Ini bukan menggambar. Ini berpikir.
02 Dari Mainan ke Alat Produktivitas
Di hadapan kemampuan seperti ini, sikap semua orang terhadap model gambar, harus berubah.
Ia sudah lama bukan mainan untuk menggambar avatar, membuat wallpaper. Langkahnya melampaui ambang "dapat digunakan", langsung menerjang ke zona "mudah digunakan"—sebuah alat yang bisa langsung dilempar ke skenario komersial untuk bekerja.
Ambil contoh desain poster. Estetika komposisi GPT-Image 2, penanganan cahaya dan bayangan, penguasaan nada merek, tidak diragukan lagi mencapai ketinggian yang sulit dicapai oleh sebagian besar desainer manusia biasa.

Sumber: https://cdn3.linux.do/original/4X/7/a/1/7a12ccd6b745be5ad8828eb0ac225d218fb43cbc.jpeg
Dalam masyarakat manusia, mempekerjakan seorang seniman senior untuk mendesain poster tingkat komersial, biaya komunikasi, biaya waktu, dan imbalan desain ribuan yuan seringkali menjadi beban berat bagi usaha kecil dan menengah.
Namun, dengan GPT-Image 2, bahkan jika hasilnya tidak memuaskan dan disesuaikan puluhan kali, biayanya hanya level beberapa dolar.
Di bidang desain poster, materi pemasaran, ilustrasi pendamping, yang dipedulikan pengguna bukanlah "nyata atau tidak", yang dipedulikan adalah "bagus tidak, tepat tidak". Justru karena itu, efisiensi penggantian AI bersifat menghancurkan.
Dalam dokumentasi developer yang diperbarui bersamaan, juga tersembunyi detail yang menarik: dalam kode contoh sering muncul model: "gpt-5.4".
Mode pemikiran ditambah model unggulan, kombinasi ini mengisyaratkan satu hal: GPT-Image 2 bukanlah produk terisolasi. Ia adalah terminal visual yang lahir untuk model bahasa besar generasi berikutnya.
Melalui Responses API baru, proses pembuatan gambar akan berinteraksi secara alami seperti mengobrol dengan model bahasa besar. Model menambahkan fungsi yang memungkinkan modifikasi multi-putaran, setelah gambar pertama selesai, pengguna dapat memberikan berbagai instruksi yang membuat pihak乙方 pusing untuk dimodifikasi.
Melalui Responses API baru, proses pembuatan gambar akan berinteraksi secara alami seperti mengobrol dengan model bahasa besar. Model menambahkan fungsi modifikasi percakapan multi-putaran, setelah versi pertama dihasilkan, pengguna dapat memberikan berbagai instruksi yang membuat desainer乙方 tekanan darah melonjak: "Latar belakang lebih gelap sedikit." "Logo geser ke samping beberapa piksel."
Kebutuhan modifikasi interaktif real-time ini, justru merupakan bagian paling merepotkan dan paling menguji kesabaran dalam pekerjaan sehari-hari desainer. Sekarang, terpecahkan.
03 Puncak Rendering Bahasa Mandarin
GPT-Image 2 meskipun model luar negeri, pengguna domestik justru serentak memuji.
Alasannya hanya satu: dukungannya terhadap karakter Han, nyaris sempurna.
Dalam gambar uji coba komunitas, Anda bisa melihat adegan debat terkenal Luo Yonghao dan Wang Ziru:
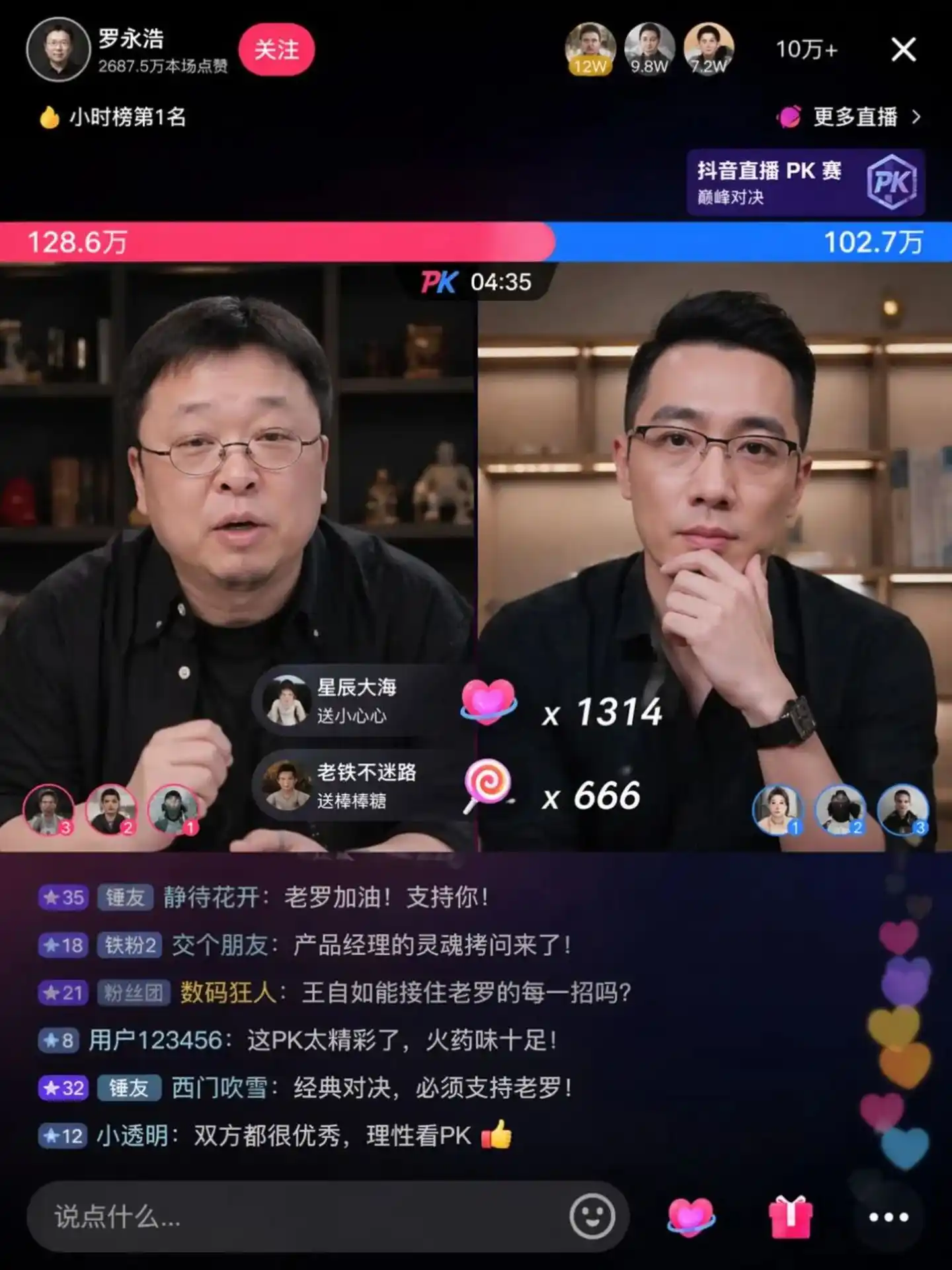
Sumber: https://cdn3.linux.do/original/4X/0/9/7/097ed46991d2464442aebc6b1076a292cc839fec.jpeg
Bisa melihat Elon Musk menjual langsung Lao Gan Ma:

Sumber: https://cdn3.linux.do/original/4X/2/f/a/2fa77cf040e6337643829df4ec5ca6467d2866b2.jpeg
Bahkan bisa melihat resep obat yang ditulis dokter:

Sumber: https://cdn3.linux.do/original/4X/9/f/f/9ffeab83675648b43116cd0763f6c8b560611ae6.jpeg
Teks dalam gambar-gambar ini, sudah bukan lagi "karakter Han palsu" yang bengkok dan disusun sembarangan, tetapi desain matang yang memiliki pesan kaligrafi, lapisan font, dan seni tata letak.
Jelas, OpenAI memasukkan sejumlah besar gambar korpus bahasa Mandarin ke dalam set pelatihan, melakukan pelatihan intensif yang ditargetkan.
Dibandingkan dengan model generasi sebelumnya, kehebatan GPT-Image 2 dapat ditunjukkan dengan lebih lengkap.
Dalam pengujian perbandingan, model generasi sebelumnya versi 1.5 meskipun bisa menggambar sesuatu yang seperti resep, tetapi dilihat lebih dekat, teks hampir seluruhnya kode acak.

Sumber: https://cdn3.linux.do/optimized/4X/2/b/3/2b38f3c1a134515d564f07f81661c0bd9578c6b9_2_750x750.jpeg
Tapi resep yang sama dihasilkan GPT-Image 2, justru membuat orang melihat kejelasan teks dan estetika telah mengalami terobosan milestone.
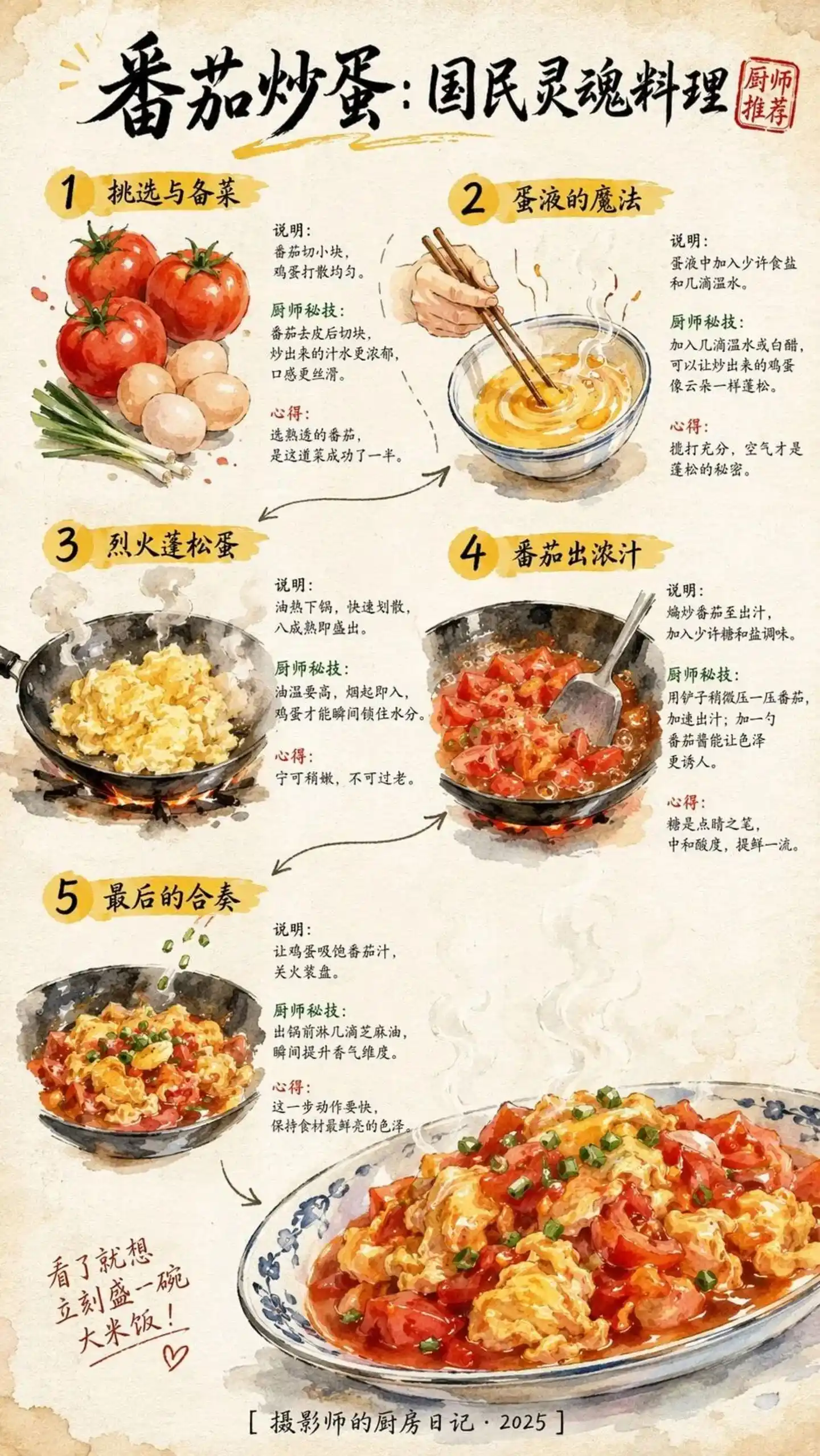
Sumber: https://cdn3.linux.do/original/4X/0/2/5/02513b10135d824ccb1c22bd0c7eb441f1e34455.jpeg
Untuk kata kunci ratusan karakter Mandarin, lima langkah masih terlihat, konsistensi teks dan gambar memuaskan. Ini bukan hanya sebuah gambar, tetapi juga skema operasional yang dapat direproduksi.
Namun, di sini juga muncul masalah teknis yang menarik: apakah model gambar benar-benar menyelesaikan masalah kode acak?
Penilaian saya: mungkin tidak.
Model bahasa besar menghasilkan token, mengandalkan logika semantik. Tahap pembelajaran penguatan berdasarkan probabilitas, semakin banyak korpus berkualitas tinggi, logika semakin masuk akal. Tetapi esensi model gambar, pada akhirnya adalah pembuatan piksel. Hubungan logika antar piksel, sama sekali bukan hal yang sama dengan hubungan logika antar teks.
Dengan kata lain, sehebat GPT-Image 2, ia tidak benar-benar "memahami" aturan teks. Ia hanya menghafal penampilan teks pada tingkat piksel.
Sebuah gambar berbisnis dengan Altman mengungkapkan hal ini: kemasan dua kotak minuman dengan tulisan besar "Mengniu" dan "Wanglaoji" ditulis sangat sempurna, tetapi tulisan kecil di bawahnya masih berupa blok warna buram.

Sumber: https://cdn3.linux.do/original/4X/d/7/c/d7c4fb063202bcbf56b9ca0623aa0ce6fc26e542.jpeg
Dalam paradigma teknologi yang ada, logika generasi masih "mengatur berdasarkan susunan piksel", masih jauh dari "merender berdasarkan karakter". Kode acak di tempat yang sangat halus, mungkin tidak akan pernah bisa dihilangkan sepenuhnya.
Tapi sekali lagi, untuk lebih dari 90% skenario aplikasi komersial, ini sudah cukup.
04 Kekurangan dan Batasan yang Belum Sempurna
Bahkan setelah menduduki tahta nomor satu dunia, GPT-Image 2 juga memiliki sisi kikuk.
Ditemukan dalam uji coba, karena mode pemikiran akan memanggil pencarian online dan melakukan penalaran logika, saat menangani tugas fiksi yang sangat kompleks, model kadang-kadang terjebak dalam lingkaran logika—berpikir hampir 40 menit, masih tidak bisa menjawab.
Pada saat yang sama, API yang mengklaim mendukung resolusi 2K bahkan 4K, berarti konsumsi token dan penundaan yang sangat tinggi.
Bagi pengguna biasa, bagaimana menyeimbangkan kualitas gambar tertinggi dan kecepatan respons, adalah pelajaran wajib dalam penggunaan di masa depan.
Di bidang teknologi, kemampuan yang kuat selalu merupakan pedang bermata dua.
Baik model gambar maupun model video, tidak bisa tidak harus menghadapi tantangan etika pemalsuan mendalam.
Dalam sebagian besar kasus uji coba saat ini, AI menghasilkan tokoh terkenal, tetapi jika mereka diganti dengan orang biasa yang pernah memposting foto di berbagai media sosial, dalam kondisi tidak mengenal orangnya, sudah sangat sulit membedakan mana yang asli dan palsu.
Kecuali kode acak yang kadang muncul di latar belakang mungkin membuat AI ketahuan, tubuh manusia sendiri sudah tidak ada celah.
Karena itu, bidang-bidang yang dulu harus diselesaikan oleh orang sungguhan, sedang menghadapi krisis kepercayaan yang belum pernah terjadi sebelumnya.
Peluncuran GPT-Image 2, membuat model pembuatan gambar beralih dari mainan ke alat produktivitas.
Dulu orang menggunakan AI untuk memberikan inspirasi, tetapi sekarang AI mulai mencoba mengambil alih seluruh proses dari perencanaan, perhitungan, tata letak hingga produk jadi.
Bagi pelaku desain, ini adalah era yang penuh FOMO (Fear Of Missing Out).
Tapi bagi mereka yang pandai memanfaatkan alat, memiliki estetika produk dan pemikiran logis, ini adalah era terbaik.
Gambar mulai belajar berpikir, teks bukan lagi noise piksel.
Jarak orang menuju titik奇点 visual yang diinginkan, mungkin benar-benar hanya selangkah lagi.







