Sepuluh tahun terakhir, AI menjadi lebih kuat terutama melalui satu jalur: menuangkan lebih banyak data dan daya komputasi ke dalam model yang lebih besar, membiarkan pengalaman mengendap di dalam parameter jaringan saraf. Jalur ini menciptakan lompatan besar dalam model besar setelah ChatGPT, tetapi juga meninggalkan sebuah teka-teki: model semakin kuat, namun mengapa ia berhasil atau gagal seringkali masih sulit dijelaskan dan diperbaiki.
Eksperimen terbaru oleh insinyur OpenAI, Weng Jiayi, mengusulkan kemungkinan lain: dalam tujuan yang jelas, lingkungan yang dapat dijalankan, dan lingkaran umpan balik yang tertutup, AI tidak hanya bisa menjadi lebih kuat dengan melatih model, tetapi juga bisa menjadi lebih kuat dengan "mengubah kodenya secara mandiri".
Pada 8 Mei 2026, Weng Jiayi secara sistematis menuliskan rangkaian eksperimen ini di blog pribadinya, "Learning Beyond Gradients", dan secara bersamaan membuka repositori kode, log eksperimen CSV, serta rekaman video. Dia telah lama berfokus pada infrastruktur pembelajaran penguatan (reinforcement learning) dan pasca-pelatihan, terlibat dalam peluncuran awal ChatGPT, serta berkontribusi dalam proyek-proyek seperti GPT-4, GPT-4 Turbo, GPT-4o, o-series, dan GPT-5; sebelum bergabung dengan OpenAI, dia lulus S1 dari Departemen Ilmu Komputer Universitas Tsinghua, mengambil S2 di Carnegie Mellon University, dan juga merupakan penulis utama dari pustaka pembelajaran penguatan open-source Tianshou dan mesin lingkungan paralel berkinerja tinggi EnvPool.

Gambar dibuat oleh AI
Dia membuat Codex berulang kali menulis kode strategi, menjalankan lingkungan, membaca log, melihat rekaman, mengidentifikasi kegagalan, lalu mengubah kode, menambahkan pengujian, dan melanjutkan evaluasi. Setelah beberapa iterasi, Codex "mengembangkan" serangkaian strategi prosedural murni dalam Python: mencapai skor sempurna teoretis 864 di Atari Breakout, dan di lingkungan simulasi kontrol robot seperti MuJoCo Ant dan HalfCheetah, juga mencapai performa mendekati algoritma pembelajaran penguatan mendalam (deep reinforcement learning) yang umum.
Bagian yang benar-benar penting dari rangkaian eksperimen ini adalah sebuah pertanyaan inti: Ketika agen pengodean (coding agent) cukup kuat, apakah pembelajaran harus selalu terjadi di dalam bobot jaringan saraf?
Dalam rangkaian eksperimen ini, pengalaman ditulis ke dalam kode, pengujian, log, dan rekaman, menjadi sistem perangkat lunak yang dapat dibaca, diubah, ditinjau, dan diaudit. Jika arah ini terus terbukti, langkah berikutnya untuk Agentic AI mungkin tidak hanya melatih model yang lebih besar, tetapi juga melibatkan model dalam memelihara sistem rekayasa yang terus berevolusi.
01
Siklus Rekayasa dari 387 Poin ke Skor Sempurna
Dalam blognya, Weng Jiayi menulis, titik awal eksperimen ini sebenarnya adalah kebutuhan rekayasa. Dalam waktu luangnya, dia memelihara EnvPool dan membutuhkan cara yang lebih murah daripada "menjalankan jaringan saraf setiap kali" untuk menguji apakah lingkungan permainan berjalan normal, karena memasukkan jaringan saraf ke dalam CI (Continuous Integration) terlalu mahal. Masalah awalnya adalah: Bisakah menulis aturan heuristik yang murah, dapat direproduksi, dan secara jelas lebih kuat daripada strategi acak, untuk menggerakkan lingkungan ke keadaan yang kaya informasi?

Dia mencoba menggunakan Codex (model dasar gpt-5.4) untuk menulis versi yang sepenuhnya berbasis aturan. Prompt awal sangat langsung: "Tulis strategi yang bisa menyelesaikan Breakout." Hasilnya tidak ideal. Skor rendah itu sendiri tidak memberikan informasi apa pun, seperti mungkin semantik aksi salah, deteksi status salah, alur evaluasi salah, atau struktur strategi itu sendiri terlalu lemah.
Kemudian Weng Jiayi mengubah bentuk tugas. Dia tidak lagi meminta Codex langsung menyerahkan policy.py, tetapi memintanya memelihara seluruh siklus: mendeteksi aksi dan observasi, menulis detektor status, menulis strategi, menjalankan episode lengkap, mencatat trials.jsonl dan summary.csv, menghasilkan video atau kurva, memeriksa pola kegagalan, mengubah strategi, menyederhanakan kode, menjalankan regresi.
Catatan eksperimen Breakout merekam proses ini dengan sangat jelas. Putaran pertama, Codex terlebih dahulu mengonfirmasi ruang aksi dan bentuk observasi, mengidentifikasi warna bola, pemukul, dan bata dari frame RGB, lalu menggunakan tag gambar untuk memindai RAM Atari 128 byte. Baseline awal hanya mendapat 99 poin. Setelah menambahkan logika offset terowongan, skor naik ke 387 poin.
387 poin adalah skor lokal tinggi yang mudah menyesatkan. Strategi sudah bisa stabil menangkap bola, tetapi lintasan bola terjebak dalam siklus periodik: tidak kehilangan nyawa, tetapi juga tidak bisa memukul bata baru lagi, skor terjebak. Jika manusia yang menulis kode, mungkin akan terus menyesuaikan "akurasi menangkap bola". Codex melihat video dan lintasan beberapa puluh langkah terakhir, mengidentifikasi masalah pada kurangnya gangguan pada lintasan bola.
Gambar: Tampilan permainan Atari Breakout. Pemain mengontrol pemukul di bagian bawah untuk memantulkan bola kecil, memecahkan dinding bata berwarna di atasnya lapis demi lapis. Codex mencapai skor sempurna teoretis 864 dalam game ini.
Kemudian Codex menambahkan mekanisme "memecah siklus": jika dalam waktu lama tidak ada reward, secara periodik menambahkan offset pada prediksi titik jatuh bola, untuk mengeluarkan bola dari siklus lokal. Skor meloncat dari 387 ke 507. Saat iterasi berlanjut, muncul masalah baru: untuk bola rendah yang cepat, intersepsi biasa akan membuat pemukul "terlalu memimpin" dan hanyut. Codex menambahkan parameter fast_low_ball_lead_steps=3, skor meloncat dari 507 ke 839. Peningkatan terakhir dari 839 ke 864 lebih seperti memelihara sistem yang sudah menjadi kompleks: mencoba deadband, offset servis, offset terjebak, bias keseimbangan bata, langkah antisipasi; banyak arah tidak efektif, perubahan yang berguna akhirnya adalah kondisi tahap akhir, "Setelah dinding bata pertama hancur, aktifkan offset terjebak hanya ketika bola jauh dari pemukul, dan lepaskan secara bertahap saat bola mendekat."
Konfigurasi default RAM akhir menghasilkan output stabil 864 / 864 / 864 poin dalam tiga episode, mencapai batas teoretis Breakout. Codex kemudian memigrasikan kontroler geometri yang sama ke versi input gambar murni — tidak membaca RAM, hanya mengandalkan segmentasi RGB untuk mengidentifikasi pemukul, bola, dan keseimbangan bata. Versi gambar pertama kali mencetak 310 poin, kemudian 428 poin, dan mencapai 864 poin setelah episode lokal ketujuh, sesuai dengan 14.504 langkah lingkungan strategi lokal.
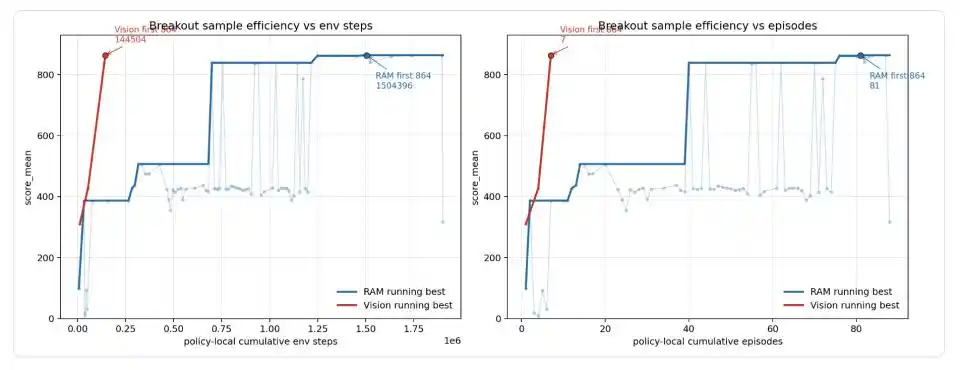
Gambar: Kurva efisiensi sampel Codex di Breakout. Garis biru adalah versi yang membaca memori game (RAM) secara langsung, garis merah adalah versi yang hanya melihat layar (Vision). Versi RAM mengalami beberapa lompatan 99 → 387 → 507 → 839 → 864, akhirnya mencapai skor sempurna untuk pertama kalinya pada episode ke-81, dengan total 1,5 juta langkah lingkungan; Versi Vision, karena struktur matang yang dimigrasikan dari versi RAM, hanya membutuhkan 7 episode, sekitar 14.500 langkah lingkungan, untuk mencapai 864 poin.
Weng Jiayi khusus menekankan, ini tidak boleh dipahami sebagai "input gambar mulai dari nol hanya dengan 14,5K langkah mencapai skor sempurna". Alur sebenarnya adalah Codex pertama-tama menemukan kontroler geometri, pemecah siklus, dan pelepasan offset tahap akhir pada versi RAM, struktur stabil baru kemudian lapisan pembacaan status dialihkan dari RAM ke RGB. 14,5K adalah anggaran migrasi untuk versi gambar.
02
Definisi Pembelajaran Heuristik (Heuristic Learning)
Mencari nama untuk "strategi perangkat lunak" yang terus berevolusi ini lebih sulit daripada menulis versi strategi pertama. Weng Jiayi akhirnya menamai proses ini sebagai Heuristic Learning (HL, Pembelajaran Heuristik), dan objek yang dipeliharanya sebagai Heuristic System (HS, Sistem Heuristik).
Menurut definisinya dalam blog, HL terdiri dari kode program, dan seperti pembelajaran penguatan mendalam (deep RL) yang umum saat ini, ia memiliki siklus status, aksi, umpan balik, dan pembaruan. Perbedaannya, objek yang diperbarui adalah struktur perangkat lunak, bukan parameter jaringan saraf; umpan baliknya dicerna oleh agen pengodean (coding agent), bisa berasal dari reward lingkungan, kasus pengujian, log, video, rekaman, atau umpan balik manusia; pembaruannya tidak menggunakan propagasi balik (backpropagation), melainkan agen pengodean langsung mengedit strategi, detektor status, pengujian, konfigurasi, atau memori.
Perlu ditambahkan, konsep "menggunakan program daripada jaringan saraf sebagai strategi" bukanlah konsep yang pertama kali diusulkan oleh Weng Jiayi. Dunia akademis telah membahas tentang Pembelajaran Penguatan Programatik (Programmatic RL) selama bertahun-tahun: kerangka PROPEL yang diusulkan oleh Rice University dan Caltech pada 2019 mempelajari metode pembelajaran penguatan yang merepresentasikan strategi sebagai program pendek dalam bahasa simbolik; pekerjaan LEAPS pada 2021 lebih lanjut mempelajari ruang embedding program, menggabungkan strategi program yang dapat didiferensiasi dengan pelatihan RL; HPRL di ICML 2023 mengusulkan Hierarchical Programmatic Reinforcement Learning, membuat meta-policy menggabungkan beberapa program; kerangka LLM-GS dari NTU dan Microsoft pada 2024 menggunakan kemampuan pemrograman dan penalaran pengetahuan umum LLM untuk memandu pencarian strategi RL programatik.
Konsensus dari penelitian-penelitian ini adalah: dibandingkan dengan strategi saraf, strategi programatik memiliki kejelasan yang lebih baik, kemampuan verifikasi formal yang lebih baik, dan kemampuan generalisasi untuk skenario yang belum terlihat.
Kontribusi substantif Weng Jiayi kali ini, terletak pada memandang coding agent sebagai saluran rekayasa untuk memelihara sistem heuristik. Di masa lalu, melakukan programmatic RL, baik bergantung pada bahasa domain khusus yang dirancang manual, atau pada algoritma pencarian dalam ruang program yang terbatas; Weng Jiayi, dengan bantuan Codex, memasukkan kode, log, pengujian, rekaman video, penyesuaian parameter ke dalam alur kerja agent yang sama, sehingga biaya iterasi strategi program ditekan sekaligus. Dengan kata lain, dia sedang membuktikan sebuah jalur rekayasa baru: ketika coding agent cukup kuat, strategi heuristik yang dulu dianggap "terlalu mahal untuk dipelihara" mungkin menjadi layak lagi.
Weng Jiayi memberikan tabel perbandingan dalam blognya, dengan jelas menjelaskan perbedaan HL dan Deep RL: dalam bentuk strategi, yang pertama adalah kode yang terdiri dari aturan, mesin keadaan, kontroler, model predictive control (MPC), makro aksi; yang kedua adalah parameter jaringan saraf. Dalam bentuk status, yang pertama adalah variabel eksplisit, detektor, dan cache; yang kedua adalah vektor observasi yang dapat dibaca jaringan. Dalam bentuk umpan balik, yang pertama memperlakukan pengujian, log, rekaman sebagai sinyal efektif; yang kedua terutama bergantung pada fungsi reward tetap. Dalam bentuk memori, yang pertama dapat secara eksplisit menyimpan percobaan, ringkasan, penyebab kegagalan, dan diff versi; yang kedua dalam algoritma on-policy pada dasarnya tidak ada, dalam algoritma off-policy bergantung pada replay buffer.
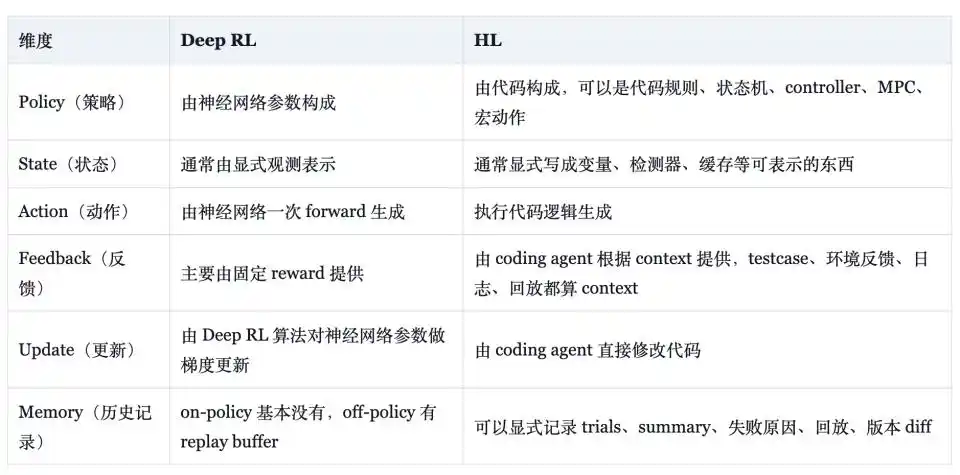
Perbandingan ini membuktikan bahwa HL memiliki beberapa atribut dalam arti rekayasa: strategi dapat dijelaskan, dapat diterjemahkan ke dalam bahasa alami; efisiensi sampel diukur dalam satuan "satu perubahan kode yang efektif", bukan pembaruan gradien yang lambat; kemampuan lama dapat menjadi pengujian regresi, rekaman seed tetap, atau kasus emas (golden case); overfitting terhadap seed pelatihan atau celah pengujian dapat dibatasi melalui penyederhanaan, pemeriksaan regresi, dan evaluasi multi-seed; kemampuan lama tidak harus hanya ada dalam bobot, tetapi juga dapat ada dalam kumpulan aturan dan pengujian, yang sebagian merespons masalah pelupaan katastropik (catastrophic forgetting) yang belum terselesaikan dengan baik oleh jaringan saraf dalam jangka panjang.
03
Validasi Batch Atari57: Batas dan Kekurangan
Jika hanya melihat Breakout, cerita mudah disederhanakan menjadi "AI menulis strategi sempurna". Tetapi Weng Jiayi tidak berhenti di Breakout, dia juga memperluas alur kerja Codex ini secara batch ke Atari57, menjalankan 57 game, dua mode observasi, tiga kali pengulangan, total 342 jejak pencarian "tanpa pengawasan".
Desain eksperimen cukup ketat. Setiap game diuji dengan dua cara input: satu membaca memori game secara langsung, satu hanya melihat layar (tampilan), setiap cara diulang secara independen tiga kali. Dengan demikian total menghasilkan 342 jejak eksperimen "tanpa pengawasan": setiap agen Codex menerima template prompt yang sama, menjelajahi aksi sendiri, menulis kode sendiri, menjalankan eksperimen sendiri, mencatat hasil sendiri, tidak ada orang di sampingnya memberikan petunjuk. Kondisi batasan ditulis sangat ketat, tidak diperbolehkan melatih jaringan saraf, tidak diperbolehkan membaca kode sumber game, tidak diperbolehkan menggunakan informasi tersembunyi apa pun, semua langkah yang digunakan untuk debugging dan trial-and-error harus diperhitungkan dalam total biaya. Ini untuk menghindari Codex menggunakan cara apa pun yang "mengintip jawaban" untuk curang.
Dalam mengukur hasil, biasanya digunakan metrik yang disebut HNS (Human-Normalized Score, Skor Ternormalisasi Manusia) — sederhananya, menstandarisasi skor setiap game dengan "rata-rata tingkat pemain manusia = 1", untuk memudahkan perbandingan horizontal antar game yang berbeda.
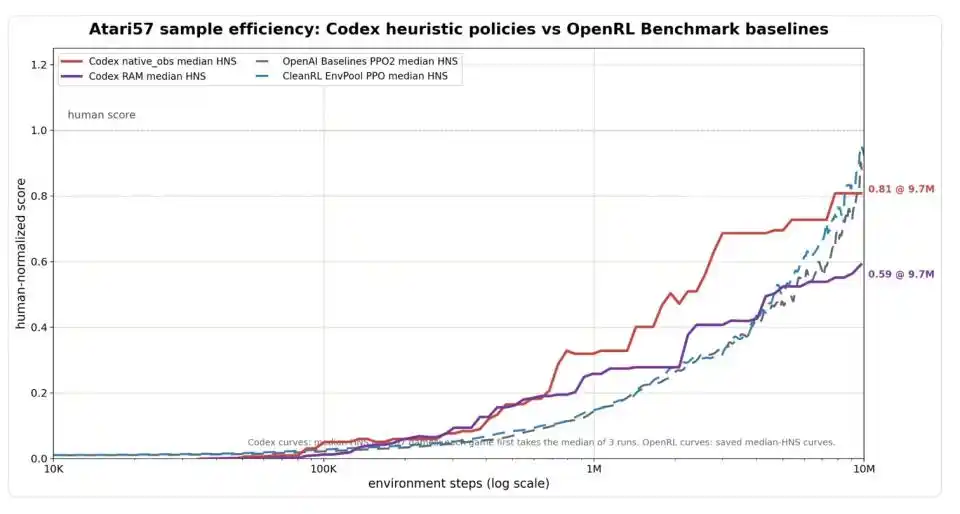
Gambar: Perbandingan efisiensi sampel di seluruh set Atari57. Sumbu horizontal adalah langkah lingkungan (skala logaritmik), sumbu vertikal adalah HNS (Skor Ternormalisasi Manusia, 1.0 menunjukkan mencapai tingkat rata-rata pemain manusia). Versi input gambar Codex (garis merah) secara signifikan memimpin baseline PPO (garis putus-putus biru/abu-abu) pada efisiensi awal, mencapai 0,81 pada 9,7 juta langkah, mendekati tingkat PPO di sekitar 10 juta langkah; Versi input memori Codex (garis ungu) konvergen pada 0,59.
Diukur dengan standar ini, Codex tampak cukup cemerlang dalam efisiensi awal. Pada konsumsi hanya 1 juta langkah lingkungan, HNS median Codex dengan input gambar sudah mencapai 0,32, dengan input memori mencapai 0,26, secara signifikan lebih tinggi daripada tingkat algoritma pembelajaran penguatan klasik seperti PPO pada periode yang sama. Pada 9,7 juta langkah, versi gambar Codex mencapai 0,81, sudah mendekati tingkat PPO pada sekitar 10 juta langkah yaitu sekitar 0,88 hingga 0,92. Jika diperbolehkan untuk setiap game memilih cara input yang lebih baik dari performa Codex untuk dikumpulkan, HNS median Codex adalah 0,83, OpenAI Baselines PPO2 adalah 0,80, CleanRL EnvPool PPO adalah 0,98 — pada dasarnya seri.
Namun Weng Jiayi sendiri sangat tenang menarik batas: ini hanya perbandingan efisiensi interaksi lingkungan, belum memperhitungkan biaya Codex membaca log, menulis kode, menonton video. "Berjalan cepat" tidak sama dengan "total biaya rendah", yang terakhir saat ini masih merupakan kotak hitam.
Yang lebih perlu diperhatikan adalah, performa Codex pada 57 game tidak merata. Di game dengan struktur geometri jelas seperti Breakout, Boxing, Krull, strategi heuristik dan pembelajaran penguatan mendalam keduanya dapat secara jelas melampaui tingkat manusia; di game dengan aturan jelas seperti Asterix, Jamesbond, Tennis, strategi heuristik bahkan lebih kuat; tetapi di game dengan ritme cepat dan pola kompleks seperti Atlantis, VideoPinball, RoadRunner, StarGunner, PPO masih mendominasi.
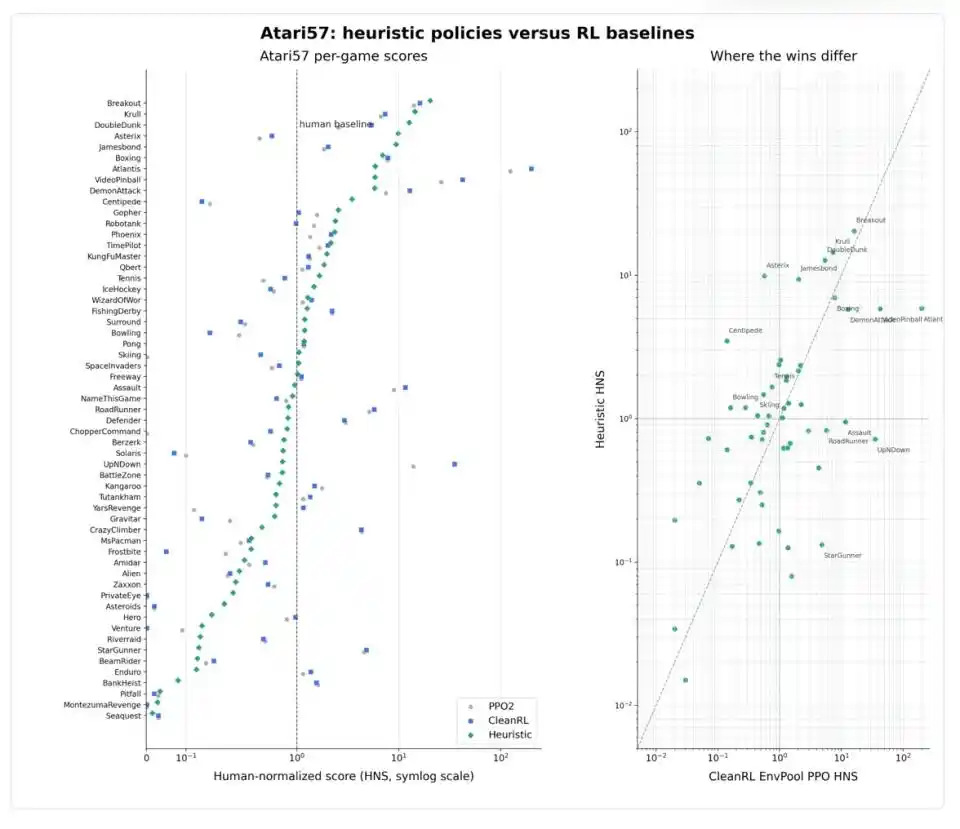
Contra-kasus yang paling bermakna peringatan adalah Montezuma’s Revenge. Ini adalah "tulang keras" terkenal di bidang pembelajaran penguatan, protagonis perlu mencari kunci, menghindari musuh, membuka pintu di labirin bawah tanah yang rumit, sinyal reward sangat jarang, merupakan masalah klasik "perencanaan jangka panjang + pemulihan kegagalan". Codex memang mendapatkan 400 poin di game ini, tetapi membuka file strategi yang dihasilkannya akan ditemukan, itu bukan "strategi" yang sebenarnya, melainkan urutan 86 aksi yang dikodekan keras, sesuai dengan 1.769 langkah lingkungan: lebih seperti menghafal satu rute tetap, daripada belajar berjalan di labirin. Weng Jiayi secara khusus menyebutkan: "Ini adalah kasus batas, tidak boleh dipahami sebagai strategi Montezuma yang umum."
Montezuma mengungkapkan batas ekspresif dari Heuristic Learning. Strategi program biasa pada dasarnya adalah logika reaktif "melakukan aksi apa saat melihat status apa", sulit menangani tugas yang memerlukan urutan aksi yang ketat, perlu melanjutkan rencana dari status tengah, perlu perencanaan pandangan panjang. Tugas semacam ini membutuhkan bukan hanya lebih banyak if-else, tetapi struktur program yang lebih mendekati "kombinasi makro aksi + status pencarian yang dapat dipulihkan + memori jangka panjang". Ini memberitahu kita satu hal: sekalipun coding agent lebih kuat, beberapa masalah bukanlah kode biasa yang dapat menampungnya.
04
Jika Paradigma Ini Terbukti, Di Mana Signifikansi Industri?
Mengembalikan perspektif ke industri. Jika jalur Heuristic Learning ini benar-benar terbukti, "yaitu coding agent mampu secara stabil memelihara strategi programatik yang melebihi aturan manual, mendekati baseline RL", di mana makna praktisnya?
Titik penerapan pertama adalah kontrol robot, terutama skenario dengan struktur relatif stabil. Gagasan yang diberikan Weng Jiayi dalam blognya adalah pembagian kerja hierarkis HL tingkat sendi, HL tingkat anggota badan, HL keseimbangan seluruh tubuh, HL tingkat tugas. Lapisan rendah menangani keamanan dan kontrol latensi rendah, lapisan menengah menangani gaya berjalan dan kontak, lapisan tinggi menangani tugas dan memori jangka panjang; coding agent tidak perlu "memahami berjalan", dia lebih seperti saluran pembaruan yang disisipkan ke dalam sistem, mengembalikan video kegagalan, aliran sensor, hasil simulasi ke sistem, lalu menulis ulang umpan balik menjadi kode, parameter, aturan perlindungan, dan memori.
Skenario seperti AGV pergudangan, robot patroli, lengan robot pabrik, pemilahan terstandarisasi, struktur lingkungan relatif tetap, batas keamanan jelas — jika strategi kontrol inti dapat dikonsolidasi menjadi kode ringan, setiap langkah aksi robot tidak perlu menjalankan jaringan strategi besar-besaran, ketergantungan sisi penerapan pada kartu inferensi GPU berdaya tinggi akan turun, lebih banyak beban diberikan ke kontroler tradisional dan logika program lokal.
Ini tidak berarti robot tidak memerlukan GPU, persepsi, lokalisasi, pemetaan, pemahaman semantik masih bergantung pada jaringan saraf; yang berubah adalah peran GPU, dari "membakar daya komputasi setiap detik untuk keputusan aksi end-to-end" menjadi "berperan secara periodik dalam persepsi, simulasi offline, generasi strategi, analisis anomali".
Titik penerapan kedua adalah kemampuan diaudit untuk skenario kritis keamanan. Masalah rekayasa paling sulit dari strategi saraf adalah tidak dapat dilacak saat terjadi masalah. Sebuah lengan robot tiba-tiba gagal di sudut tertentu, sebuah mobil salah menilai di skenario tepi tertentu, robot medis melakukan aksi abnormal pada postur langka tertentu, insinyur tidak dapat menjawab "bobot mana yang menyebabkan kesalahan ini", akhirnya hanya dapat menambah data, melatih ulang, pengujian regresi, dan berharap model baru tidak memperkenalkan masalah baru.
Jika strategi ada dalam bentuk kode, variabel status, cabang kondisi, log kegagalan, dan pengujian regresi terlihat; aksi berbahaya tertentu dapat dilarang dengan kode keras, kasus sudut tertentu dapat ditulis sebagai pengujian, transisi status kesalahan tertentu dapat diperbaiki secara terpisah. Ini tidak membuat sistem secara alami lebih aman, tetapi membuat masalah keamanan untuk pertama kalinya dapat masuk ke dalam alur kerja rekayasa perangkat lunak normal — dapat ditinjau kodenya, dapat dicegat oleh CI, dapat ditanggapi oleh SRE yang bertugas. Di bidang yang memerlukan pengawasan dan pembagian tanggung jawab seperti kendaraan otonom, lengan robot industri, robot medis, kemampuan diaudit ini sendiri merupakan nilai komersial.
Titik penerapan ketiga adalah rekayasa pembelajaran berkelanjutan (continual learning) dan pembelajaran online. Weng Jiayi dalam blognya menjadikan ini sebagai garis argumen utama artikel. Pelupaan katastropik jaringan saraf adalah masalah struktural: mempelajari hal baru, kemampuan lama akan terkikis. HL juga dapat melupakan, tetapi bentuknya lebih rekayasa: aturan baru memperbaiki satu mode kegagalan tetapi merusak skenario lama; memori baru berulang kali mengarahkan agent ke arah yang salah; cakupan pengujian terlalu sempit, strategi belajar memanfaatkannya; satu tambalan mengubah antarmuka bersama, jalur panggilan lama diam-diam gagal.
Masalah-masalah ini tidak hilang secara otomatis, tetapi semuanya adalah masalah yang telah ditangani oleh rekayasa perangkat lunak selama beberapa dekade, memiliki rantai alat yang sudah ada — pengujian regresi, diff versi, rekaman seed tetap, jejak emas (golden trace), arah kegagalan yang dicatat secara eksplisit.
HS yang sehat harus memiliki dua operasi sekaligus: menyerap umpan balik baru, mengompresi tambalan sejarah; HS yang hanya bertambah tidak berkurang pada akhirnya akan menjadi "gumpalan kode" yang tidak ada yang berani sentuh. Dengan kata lain, HL mengubah masalah matematika "bagaimana memperbarui parameter" menjadi masalah rekayasa "bagaimana memelihara sistem perangkat lunak yang terus menyerap umpan balik".
Yang terakhir belum tentu lebih mudah, tetapi lebih mendekati batas kemampuan manusia yang sudah ada.
Titik penerapan keempat adalah pengendapan kemampuan produk Agent. Apa yang paling kurang dalam produk Agent saat ini adalah pemanggilan alat yang stabil, rantai eksekusi yang andal, pengalaman kegagalan yang dapat digunakan kembali, dan catatan tugas yang dapat diaudit. Jika logika HL terbukti, memori Agent selama proses eksekusi akan mengendap menjadi aset kode yang dapat digunakan kembali lintas sesi, lintas pengguna, lintas tugas. Ini dapat terhubung langsung ke alur kerja DevOps yang sudah ada, juga berarti Agent dari perusahaan, tim yang berbeda dapat berbagi heuristic, tetapi tidak perlu berbagi model, hal yang tidak dapat dilakukan oleh skema jaringan saraf.
Namun, perlu ditekankan: Keempat titik penerapan di atas bergantung pada jalur HL ini diverifikasi lebih lanjut pada tugas yang lebih kompleks. Breakout dan Ant adalah lingkungan yang relatif bersih, robot nyata menghadapi perubahan gesekan tanah, perubahan pencahayaan, penundaan aktuator, kebisingan sensor, semua ini belum dinilai secara sistematis dalam materi publik. Contra-kasus Montezuma telah menunjukkan, tugas pandangan panjang memerlukan bentuk program yang melampaui if-else biasa. Seberapa jauh gagasan ini dapat berjalan, masih harus dilihat pada eksperimen tahap berikutnya.
05
Utang Rekayasa (Engineering Debt) Berpindah dari Bobot ke Kode
Penilaian yang diberikan Weng Jiayi dalam blognya sangat terkendali. Dia menulis, HL tidak dapat menyelesaikan semua hal yang dapat dilakukan jaringan saraf, ia dibatasi oleh konten yang dapat diekspresikan kode, terutama dalam persepsi kompleks dan generalisasi pandangan panjang. Dengan pengetahuan hari ini, dia tidak dapat membayangkan sebuah agent menggunakan kode Python murni, tanpa bantuan jaringan saraf apa pun untuk menyelesaikan ImageNet. Masalah yang benar-benar layak didiskusikan adalah bagaimana menggabungkan jaringan saraf dan HL untuk bersama-sama menangani Pembelajaran Online dan Pembelajaran Berkelanjutan.
Pembagian kerja yang diberikannya meminjam bahasa Sistem 1 / Sistem 2: jaringan saraf dangkal khusus menanggung bagian dari Sistem 1, bertanggung jawab atas persepsi cepat, klasifikasi, dan estimasi status objek; HL juga menanggung bagian dari Sistem 1, bertanggung jawab atas pemrosesan data segar, aturan, pengujian, rekaman, memori, batas keamanan, dan pemulihan lokal; agent LLM bertindak sebagai Sistem 2, memberikan umpan balik ke HL, memperbaiki data, dan secara periodik mengekstrak informasi dari data yang dihasilkan HL untuk memperbarui dirinya sendiri.
Jika pembelajaran mendalam (deep learning) sepuluh tahun terakhir membuktikan "pengalaman dapat dikompresi ke dalam bobot", maka asumsi yang diajukan Weng Jiayi kali ini adalah proposisi lain: di era coding agent, pengalaman mungkin dapat kembali menjadi perangkat lunak yang dapat dibaca, diubah, dan diuji.
Artikel ini berasal dari akun resmi WeChat "Tencent Technology", penulis: Xiao Jing, editor: Xu Qingyang