Tahun 2026, perkembangan AI global mencapai titik balik bersejarah—pengeluaran modal inferensi oleh vendor awan berskala ultra-besar, untuk pertama kalinya dalam sejarah, melampaui pengeluaran modal pelatihan. Titik fokus industri bergeser dari "membangun model besar" ke "menggunakan model besar", struktur permintaan daya komputasi mengalami perubahan fundamental.
Di era pelatihan, kontradiksi inti daya komputasi adalah "presisi ganda floating point dan skala klaster"; sementara memasuki era inferensi, kontradiksi inti berubah menjadi "bandwidth memori dan latensi komunikasi".
Hambatan inferensi model besar tidak lagi hanya komputasi, melainkan perpindahan data—bobot model, nilai aktivasi perantara, dan KV Cache perlu sering berinteraksi antara DRAM di luar chip (seperti HBM) dan GPU. Semakin besar modelnya, konsumsi energi dan penundaan akibat pemindahan data semakin tinggi, akhirnya jauh melampaui konsumsi energi komputasi itu sendiri, sehingga membentuk "tembok memori".
GPU NVIDIA membangun benteng kokoh dengan CUDA dan NVLink, tetapi tetap tidak dapat menghindari idle GPU akibat hambatan bandwidth.
Perusahaan model besar domestik, Zhipu AI, melakukan eksperimen sederhana: dalam klaster inferensi 512 kartu, GPU, model, dan kode tetap sama, hanya mengganti bandwidth jaringan maksimum dari 200GB/S menjadi 400GB/S, throughput inferensi langsung naik 10%, latensi keluaran token pertama turun 19%—alasannya sederhana, hanya dengan memperlebar jalan, mobil bisa berjalan lebih cepat.
Namun, arsitektur non-GPU seperti yang diwakili Cerebras, tampaknya sedang merobek celah di tembok memori.

Perbandingan Ukuran Chip Cerebras WSE-3 dan GPU NVIDIA B200
Esensi Cerebras: Mesin Komputasi Near-Memory Berbasis SRAM
Cerebras Systems didirikan oleh Andrew Feldman dan lainnya di Silicon Valley, tim pendiri awalnya berasal dari sebuah server mikro hemat daya bernama SeaMicro. Perusahaan ini kemudian diakuisisi oleh AMD, dan setelah itu:
2015, tim pendiri menetapkan jalur "komputasi tingkat wafer";
2016, menyelesaikan pendaftaran dan pendanaan Seri A, memasuki fase pengembangan tersembunyi;
2019, merilis produk pertama, chip WSE-1 dan sistem CS-1, berbasis proses TSMC 16nm;
2021, merilis produk generasi kedua, berbasis proses TSMC 7nm;
2024, merilis produk generasi ketiga (WSE-3 / CS-3), berbasis proses TSMC 5nm, chip dan sistem diproduksi di AS, merupakan sistem chip murni buatan AS.
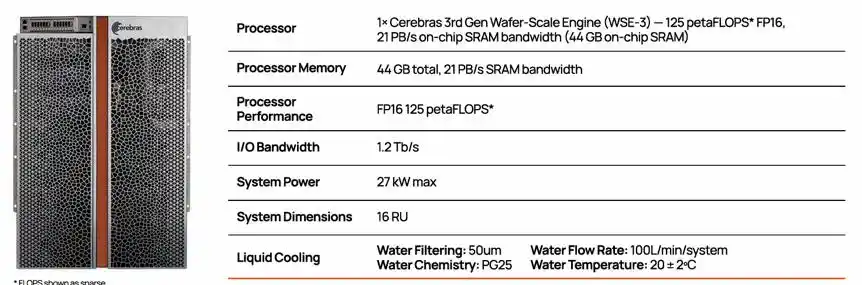
Konfigurasi Sistem CS-3, berisi 1 chip WSE-3
Filosofi arsitektur Wafer-Scale Engine (WSE) Cerebras sederhana, kasar, tetapi langsung mengenai titik permasalahan: Memanfaatkan pembesaran ekstrem ruang fisik untuk mendapatkan kompresi ekstrem terhadap latensi pemindahan data.
Chip biasa memotong satu wafer menjadi banyak chip kecil, misalnya GPU NVIDIA mengikuti pendekatan ini. Cerebras sebaliknya: tidak dipotong, wafer utuh secara langsung dijadikan satu chip super besar, disebut Wafer-Scale Engine, WSE.
Chip tradisional memotong wafer berdiameter 300mm menjadi ratusan chip kecil; sedangkan Cerebras memilih mempertahankan seluruh wafer sebagai satu chip utuh. WSE-3 terbaru memiliki 4 triliun transistor, 900 ribu inti AI, setiap inti dilengkapi dengan SRAM lokal 48KB, sehingga total SRAM dalam chip mencapai 44GB, menyediakan bandwidth memori dalam chip (on‐chip memory bandwidth) 21PB/detik dan bandwidth jaringan (fabric bandwidth) 214Pb/detik, ini adalah ribuan kali lipat bandwidth HBM tradisional.
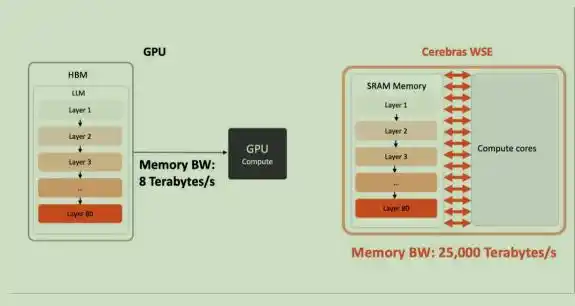
Bandwidth memori Cerebras WSE adalah 2625 kali chip kemasan NVIDIA B200, menghancurkan hambatan bandwidth memori dalam skenario inferensi model besar.
Dalam arsitektur Cerebras, bobot model tidak pernah disimpan di SRAM, melainkan di penyimpanan luar chip MemoryX, dan ditransfer lapis demi lapis ke chip besar. Cara implementasinya adalah memisahkan penyimpanan bobot model jaringan saraf dengan unit komputasi.
Semua bobot model disimpan secara eksternal di modul ekspansi memori MemoryX, bobot yang diperlukan untuk setiap lapisan komputasi jaringan akan ditransfer lapis demi lapis sesuai kebutuhan ke sistem CS-3. Bobot disimpan di DRAM dan flash memori MEMORY X, dan ditransmisikan ke sistem CS-3 dengan kecepatan bandwidth penuh. Bobot-bobot ini tidak disimpan di sistem CS-3, bahkan tidak disimpan dalam cache sementara, CS-3 mengandalkan mekanisme aliran data inti untuk menyelesaikan komputasi.
Cerebras, dengan arsitektur tingkat wafer, menunjukkan keunggulan luar biasa dalam inferensi LLM yang dibatasi oleh bandwidth memori. Saat menghasilkan token per token, bobot ditransmisikan lapis demi lapis dari luar chip MemoryX ke CS-3 secara streaming, saat menjalankan model yang berbeda, kecepatan token adalah 1,5 - 5 kali NVIDIA B200.
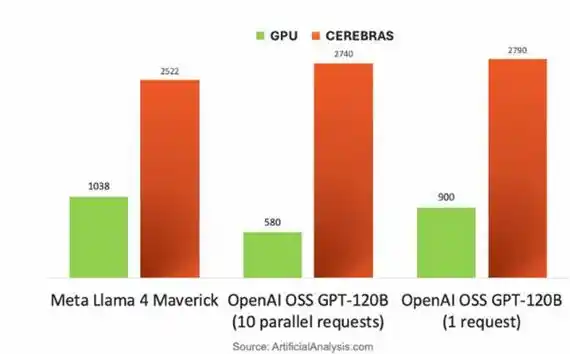
GPU NVIDIA DGX B200 versus chip Cerebras CS-3, perbandingan kecepatan token saat menjalankan model besar yang berbeda
Keunggulan intinya terletak pada: SRAM dalam chip CS-3 sebesar 44GB menyediakan bandwidth super tinggi 21 PB/detik (2625 kali B200) dan interkoneksi 214 Pb/detik, membuat transmisi aliran bobot terbebas dari batasan antarmuka HBM. Oleh karena itu, performanya sangat menonjol pada TTFT (Time To First Token, waktu dari permintaan dikirim hingga model mengembalikan token pertama), konteks panjang, dan beban kerja agen.
Meskipun bobot ditempatkan di luar MemoryX dan dimuat lapis demi lapis sesuai kebutuhan dan tidak di-cache di dalam chip, CS-3 mengandalkan mekanisme aliran data inti untuk menyelesaikan komputasi presisi penuh FP16 tanpa kehilangan di SRAM; dengan penskalaan performa linier, juga melepaskan total throughput yang luar biasa di bawah inferensi konkurensi multi-pengguna.
Selain bandwidth, ada juga keunggulan konsumsi daya. Baru-baru ini, dalam pidato Chairman Zhongji Xu Chuang, Liu Sheng juga menyebutkan, persyaratan pelanggan untuk modul optik adalah 1 pJ/bit, sedangkan saat ini adalah 10 pJ/bit. Dalam chip Cerebras, konsumsi daya interkoneksi hanya 0,15 pJ/bit, sedangkan konsumsi daya interkoneksi GPU saat ini adalah 10 pJ/bit.
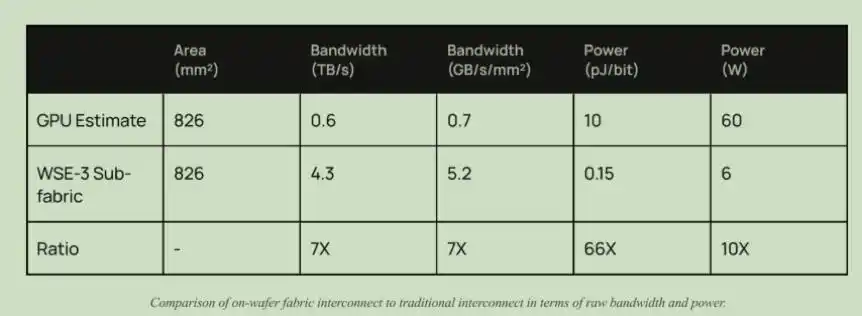
Perbandingan bandwidth dan konsumsi daya arsitektur interkoneksi Cerebras dan GPU
Dapat dilihat, jika arsitektur chip besar tingkat wafer Cerebras menjadi arus utama inferensi atau bahkan pelatihan AI, mungkin akan menghambat dan mengubah secara signifikan volume pengiriman modul optik tradisional dan CPO (Co-Packaged Optics). Logika intinya adalah: permintaan tinggi untuk modul optik dan CPO pada dasarnya adalah untuk mengatasi hambatan bandwidth "interkoneksi antar chip" dan "interkoneksi antar node" dalam klaster GPU; sedangkan arsitektur Cerebras justru menyelesaikan masalah dengan "menghilangkan interkoneksi terdistribusi".
Intuisi Terbalik: "Kecacatan" Sejati dan Palsu pada Chip Besar Tingkat Wafer
Inti dari chip selalu terletak pada Trade Off (seni pertukaran). Cerebras, demi bandwidth ekstrem SRAM dalam chip, juga membawa beberapa masalah.
Hasil produksi rendah?
Justru sebaliknya, ukuran inti AI tunggal dikurangi menjadi 0,05 milimeter persegi (1% dari ukuran inti komputasi tunggal H100), sehingga hasil produksi justru lebih tinggi. Melalui routing di dalam chip, inti yang cacat dapat dimatikan dan dilewati, sehingga toleransi cacat meningkat 100 kali lipat dibandingkan dengan prosesor multi-inti tradisional. Sebenarnya seluruh chip memiliki 1 juta inti AI, tetapi dengan mempertimbangkan hasil produksi, diumumkan ke publik adalah 900 ribu inti AI.
Hanya ahli dalam inferensi, tidak ahli dalam pelatihan?
Dalam beberapa tahun sejak Cerebras didirikan, pelatihan adalah topik utama, sehingga perusahaan selalu melakukan banyak pekerjaan seputar pelatihan, hanya saja setelah permintaan inferensi meledak, orang-orang menemukan keunggulannya dalam inferensi lebih jelas.
Faktanya, komputasi terdistribusi yang disederhanakan juga membawa serangkaian keunggulan seperti penurunan kompleksitas kode dan penurunan overhead komunikasi.
Melatih model dengan parameter 175 miliar pada 4000 GPU biasanya membutuhkan sekitar 20.000 baris kode pelatihan terdistribusi.
Cerebras mencapai pelatihan setara dengan 565 baris kode—seluruh model dapat dipasang di wafer, dan tidak perlu menangani kompleksitas paralelisme data.
Penskalaan SRAM sudah mati, keunggulan inti menghadapi batas fisik.
Produk generasi ketiga berbasis proses TSMC 5nm, kapasitas SRAM-nya hanya meningkat 10% dibandingkan produk generasi kedua berbasis proses TSMC 7nm, setelah proses 5nm, luas sel SRAM hampir tidak lagi menyusut seiring kemajuan proses.
Ini berarti Cerebras tidak dapat lagi meningkatkan keunggulan intinya (kapasitas SRAM) secara signifikan dengan meng-upgrade proses TSMC (seperti dari 5nm ke 3nm) seperti dulu.
Dibatasi oleh ukuran wafer, kemampuan pendinginan, dan biaya produksi, sumber daya penyimpanan seperti SRAM dalam chip sulit diperluas secara linier bersamaan dengan inti komputasi, rasio sumber daya menghadapi hambatan. Ini hampir memblokir jalan evolusinya.
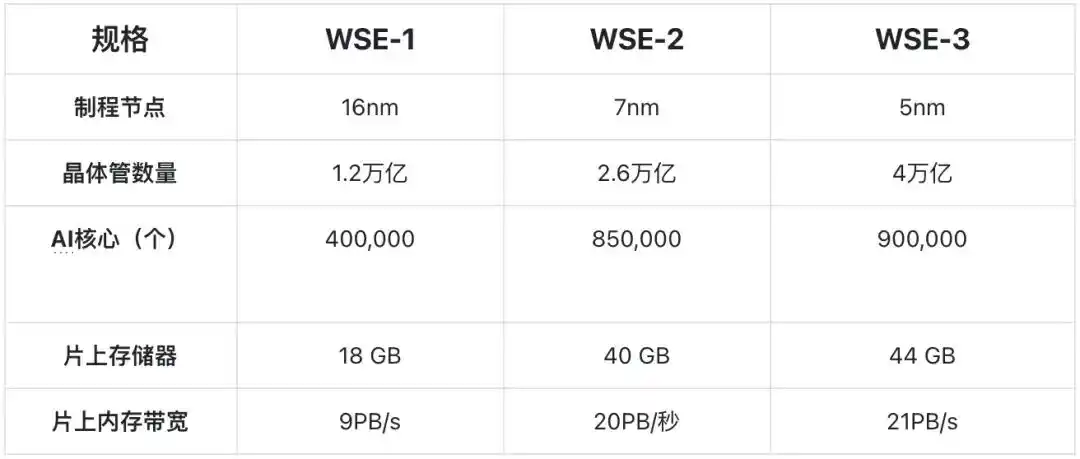
Spesifikasi teknis tiga generasi produk Cerebras
Tiga penderitaan: pendinginan, proses, dan ekosistem.
Seluruh wafer memusatkan panas, kerapatan aliran panas tinggi, harus mengandalkan ruang server kustom dan sistem pendingin cair khusus. Selain itu, keumuman ekosistem berarti pelanggan harus beradaptasi dengan software stack kustomnya, kompatibilitasnya lemah dengan kerangka kerja pemrograman umum seperti CUDA, biaya porting dan adaptasi perangkat lunak tinggi.
Bandwidth luar chip rendah, menjadi "pulau terisolasi" dalam ekspansi.
Karena keterbatasan desain fisik tingkat wafer, jumlah pin I/O yang dapat dikeluarkan di tepi WSE sangat terbatas, mengakibatkan bandwidth I/O-nya hanya 150GB/s. Dibandingkan dengan bandwidth dua arah NVLink NVIDIA yang mencapai 1,8TB/s, ini seperti siput. Ini berarti WSE sangat sulit untuk diperluas ke luar dengan kecepatan tinggi. Meskipun interkoneksi SwarmX Cerebras cukup baik dalam kombinasi multi-sistem, di hadapan model super besar yang membutuhkan interkoneksi kecepatan tinggi multi-chip, bandwidth luar chip yang sangat rendah menjadi belenggu fisik struktural.
Persaingan Jalur: Pengembangan Mandiri Perusahaan Besar, Berapa Lama Lagi Masa Jendela Cerebras?
Cara perusahaan besar menyelesaikan "inferensi membutuhkan bandwidth lebih tinggi + latensi lebih rendah" tidak hanya satu jalan wafer-scale, mereka sedang melalui tiga jalur paralel untuk mengepung keuntungan teknologi perusahaan rintisan.
1. Chip ASIC Pengembangan Mandiri
Google TPU v8 telah terpecah menjadi versi training-specific dan inference-specific; AWS Trainium 4 sedang dalam perjalanan; Microsoft Maia telah digunakan di dalam Azure, dibangun berdasarkan proses TSMC 3nm, inti tensor FP8/FP4 asli, sistem memori yang didesain ulang, dilengkapi HBM3e 216GB, SRAM dalam chip 272MB; bahkan Anthropic mulai mengevaluasi chip inferensi pengembangan mandiri.
Probabilitas jalur ini sangat tinggi, ini akan langsung menyebabkan TAM (Total Addressable Market) "pembelian inferensi pihak ketiga" pada tahun 2028, terkompresi 10% hingga 25%.
2. Generalisasi Proses pada Jalur Packaging Standar
Ini adalah serangan dimensi langsung terhadap Cerebras.
SoW (System-on-Wafer) TSMC telah dibuka luas ke pelanggan, interposer CoWoS 9.5x juga akan diluncurkan pada tahun 2027.
Apa yang dilakukan kedua produk ini—menyatukan beberapa die pada tingkat wafer—pada dasarnya adalah membuat proses fisik Cerebras menjadi umum dan terjangkau.
NVIDIA Vera Rubin akan memasuki ekosistem ini pada paruh kedua tahun 2026.
Cross-reticle stitching yang dilakukan sendiri oleh Cerebras meskipun eksklusif, tetapi masa jendela eksklusifnya paling lama hanya 2 hingga 3 tahun, setelah tahun 2027 - 2028, hambatan prosesnya akan diencerkan oleh kemasan canggih TSMC.
3. Terobosan Interkoneksi Optik/Komputasi Optik
Interkoneksi dan tembok memori chip elektronik telah mencapai batas, bandwidth tinggi, latensi rendah, dan zero crosstalk foton adalah solusi akhir.
Jalur optik yang diwakili oleh Lumentum sedang bangkit. Keunggulan terbesar wafer-scale adalah komputasi dalam chip, tetapi model pasti akan semakin besar, interkoneksi kecepatan tinggi di atas wafer scale adalah kebutuhan mutlak.
Dengan matangnya CPO (Co-Packaged Optics) dan Optical Interconnects, sangat mungkin di masa depan kita melihat I/O optik langsung dimasukkan ke wafer WSE, memecahkan belenggu interkoneksi listrik; dan NVIDIA juga mungkin mengakuisisi perusahaan dengan keunggulan arsitektur tertentu seperti LPU (contohnya Groq), menggabungkan interkoneksi optik, mengembangkan sistem tingkat wafer yang kompatibel dengan perangkat lunak super-node NV yang ada.
Berlari di Tepi Jurang: Bisnis dan Pengiriman Cerebras
Saat ini Cerebras sedang menghadapi perlombaan di tepi jurang yang dipaksa oleh pesanan besar-besaran.
Transaksi dengan pelanggan besar seperti OpenAI memaksa Cerebras bertransformasi dari perusahaan chip menjadi penyedia layanan cloud baru. Ia tidak lagi hanya menjual perangkat keras, tetapi perlu mengunci dan membangun fasilitas dan daya pusat data dalam jumlah besar dalam waktu singkat.
Berdasarkan persyaratan kontrak, Cerebras perlu mengirimkan kapasitas pusat data 250MW setiap tahun pada periode 2026 - 2028. Namun, sistem tingkat wafer memiliki persyaratan ruang server yang sangat tinggi, tidak dapat langsung dimasukkan ke IDC berpendingin udara tradisional. Saat ini, persiapan kapasitas pusat data Cerebras sudah jelas tertinggal dari persyaratan kontrak.
Dari fabrikasi wafer hingga pembangunan pabrik, dari persetujuan daya hingga penerapan sistem pendingin, ini adalah lumpur aset berat dan siklus panjang.
Penutup: Ke Kiri atau Ke Kanan?
Kembali ke proposisi awal, ketika titik balik daya komputasi inferensi telah tiba, inti arsitektur daya komputasi selalu terletak pada pertukaran.
Tidak ada yang mutlak benar atau salah, hanya solusi relatif optimal di bawah beban kerja terpenting. Beban kerja sebenarnya sudah berubah.
Cerebras ke kiri, memilih optimasi fisik ekstrem, menggunakan seluruh wafer dan SRAM dalam jumlah besar untuk mendapatkan latensi sangat rendah pada tugas tunggal, ini tak tertandingi untuk skenario yang sangat sensitif terhadap latensi token pertama.
NVIDIA ke kanan, memilih mempertahankan keumuman, menggunakan HBM + NVLink + throughput klaster super besar, menghadapi ribuan perubahan beban kerja, tidak berubah menghadapi perubahan.
Angin bertiup kencang, awan bergulung, jalan di depan belum jelas. Justru ketidakpastian ganda teknologi dan bisnis inilah yang mengandung kemungkinan disruptif. Dalam arus deras daya komputasi menuju AGI, sekarang masih terlalu dini untuk menarik kesimpulan—karena tidak pasti, ada peluang.
Artikel ini berasal dari akun WeChat publik "Garlic Kernel Machinery Research Institute", penulis: Pili Youxia