22 Juni 2026, model baru Fugu yang diluncurkan oleh Sakana AI menimbulkan kehebohan di komunitas AI. Dalam pengujian patokan ketat SWE-Bench Pro dan TerminalBench, Fugu Ultra masing-masing meraih skor 73,7 dan 82,1, melampaui GPT-5.5 dan Claude Opus 4.8, bahkan diklaim setara dengan Fable 5 dan Mythos Preview yang terkena pembatasan ekspor. Yang mengejutkan, inti sistem yang menduduki puncak kemampuan teknik dan penalaran ini bukanlah raksasa berparameter miliaran, melainkan model dengan parameter hanya 7B. Ia tidak bekerja sendiri, tetapi bertindak sebagai "mandor" yang secara dinamis mengatur model-model besar kelas atas global. Arsitektur yang tidak lazim ini tidak hanya memecah mitos "parameter adalah keadilan", tetapi juga mencerminkan jalan keluar AI Jepang di tengah keterbatasan daya komputasi.
"Mandor" 7B Parameter: Arsitektur Fugu yang Tidak Lazim
Untuk memahami keanehan Fugu, pertama-tama lihat asal-usulnya. Sakana AI didirikan di Tokyo pada tahun 2023 oleh Llion Jones, salah satu penulis bersama makalah Transformer, dan mantan peneliti Google, David Ha. Perusahaan ini sejak lahir membawa gen "inspirasi alam", berkomitmen menggunakan algoritma evolusi dan kecerdasan kelompok dari alam untuk menyelesaikan masalah AI. Pada tahun 2025, Sakana AI menerima investasi dari raksasa seperti NVIDIA dan Google, dengan valuasi melebihi 25 miliar dolar AS. Namun meski didukung raksasa, Jepang domestik masih kekurangan infrastruktur daya komputasi dan kolam data sebesar Tiongkok dan Amerika Serikat. Di bawah kendala sumber daya ini, Sakana AI tidak memilih untuk langsung menantang model besar berparameter miliaran, melainkan mengambil jalur "penataan".
Posisi resmi Fugu adalah "sebagai sistem penataan multi-agen dari satu model dasar tunggal". Dalam arsitektur AI tradisional, model besar adalah "raksasa tunggal", pengguna memasukkan sebuah prompt, model menghitung dari lapisan neural pertama hingga terakhir, lalu mengeluarkan hasil. Mode ini sangat efisien dalam menangani masalah sederhana, namun saat menghadapi tugas teknik multi-langkah yang kompleks, sering kali muncul halusinasi atau putus logika.
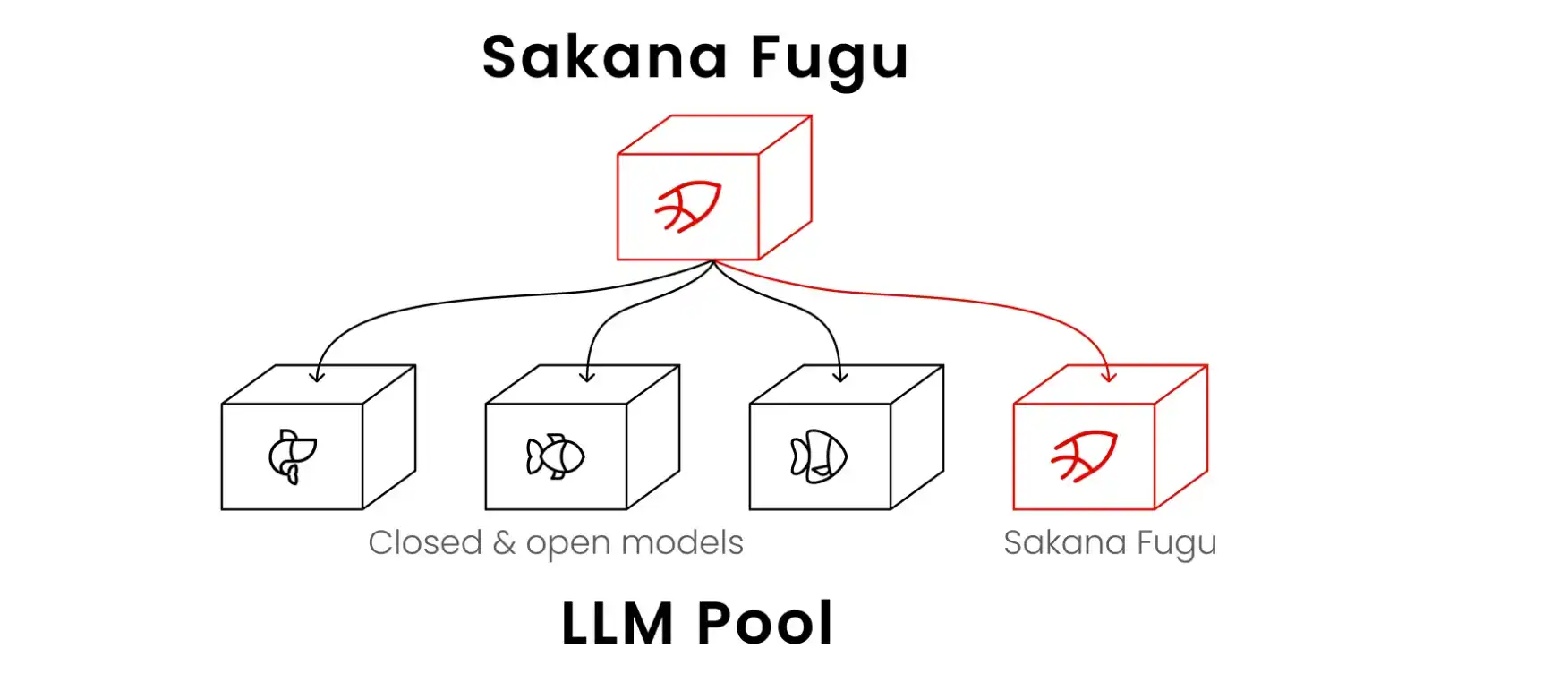
Fugu mengubah paradigma ini sepenuhnya. Intinya adalah sebuah model berparameter 7B yang dilatih dengan pembelajaran penguatan, disebut RL Conductor. Model 7B ini sendiri tidak secara langsung menghasilkan jawaban akhir, melainkan berperan sebagai "mandor". Ketika pengguna mengirimkan tugas melalui API tunggal yang kompatibel dengan OpenAI, RL Conductor akan menganalisis jenis tugas secara dinamis, kemudian mengalokasikan sub-tugas ke model-model kelas atas global di dalam kolam agen, seperti GPT-5, Gemini 3.1 Pro, atau Claude Opus 4.8. Ia bertanggung jawab mengatur, memverifikasi, dan mensintesis output model-model ini, akhirnya memberikan hasil yang telah melalui pemeriksaan berlapis.
Dukungan teoretis untuk arsitektur ini berasal dari dua makalah ICLR 2026: "TRINITY: An Evolved LLM Coordinator" dan "Learning to Orchestrate Agents in Natural Language with the Conductor". Makalah-makalah tersebut menjelaskan secara rinci bagaimana menggunakan model parameter kecil melalui pembelajaran penguatan untuk "memimpin" model besar. Ini mengubah paradigma Test-time scaling. Dulu, daya komputasi terutama digunakan untuk penalaran mendalam di dalam model, yaitu membuat model "menguras otak" untuk satu jawaban; sekarang, daya komputasi digunakan untuk penataan, verifikasi, dan sintesis eksternal. Model besar tradisional adalah tipe tunggal serba bisa, sedangkan Fugu adalah tim ahli. RL Conductor 7B membuktikan bahwa jumlah parameter model bukan lagi satu-satunya standar penentu kemampuan, memahami cara memanggil alat dan agen eksternal juga dapat mencapai lompatan kinerja.
Kebenaran di Balik Skor: Menyamai Fable dan Melampaui GPT-5.5
Alasan langsung Fugu menimbulkan kehebohan adalah skornya dalam pengujian patokan ketat. Dalam industri AI, skor adalah mata uang keras untuk mengukur kemampuan model, namun pengujian patokan yang berbeda memiliki fokus yang sama sekali berbeda. SWE-Bench Pro dan TerminalBench 2.1 yang dipilih Sakana AI, keduanya adalah "tulang keras" yang condong ke lingkungan teknik nyata.
SWE-Bench Pro berfokus pada kemampuan rekayasa perangkat lunak, meminta model untuk menemukan dan memperbaiki Bug di basis kode nyata. Menurut data yang dirilis oleh konsol Sakana AI, Fugu Ultra mencetak skor 73,7 pada SWE-Bench Pro. Sebagai perbandingan, Claude Opus 4.8 mencetak 69,2, GPT-5.5 mencetak 58,6, Gemini 3.1 Pro mencetak 54,2. Di TerminalBench 2.1 yang menguji kemampuan operasi sistem, Fugu Ultra mencetak skor 82,1, melampaui 78,2 GPT-5.5 dan 74,6 Opus 4.8. Kedua pengujian ini tidak hanya menguji kemampuan pembuatan kode model, tetapi lebih menguji stabilitas logika dan kemampuan pemanggilan alat dalam tugas multi-langkah dan rantai panjang. Keunggulan Fugu Ultra berarti bahwa dalam menangani masalah teknik kompleks, ia lebih jarang mengalami crash di tengah jalan atau penyimpangan target dibandingkan model tunggal.
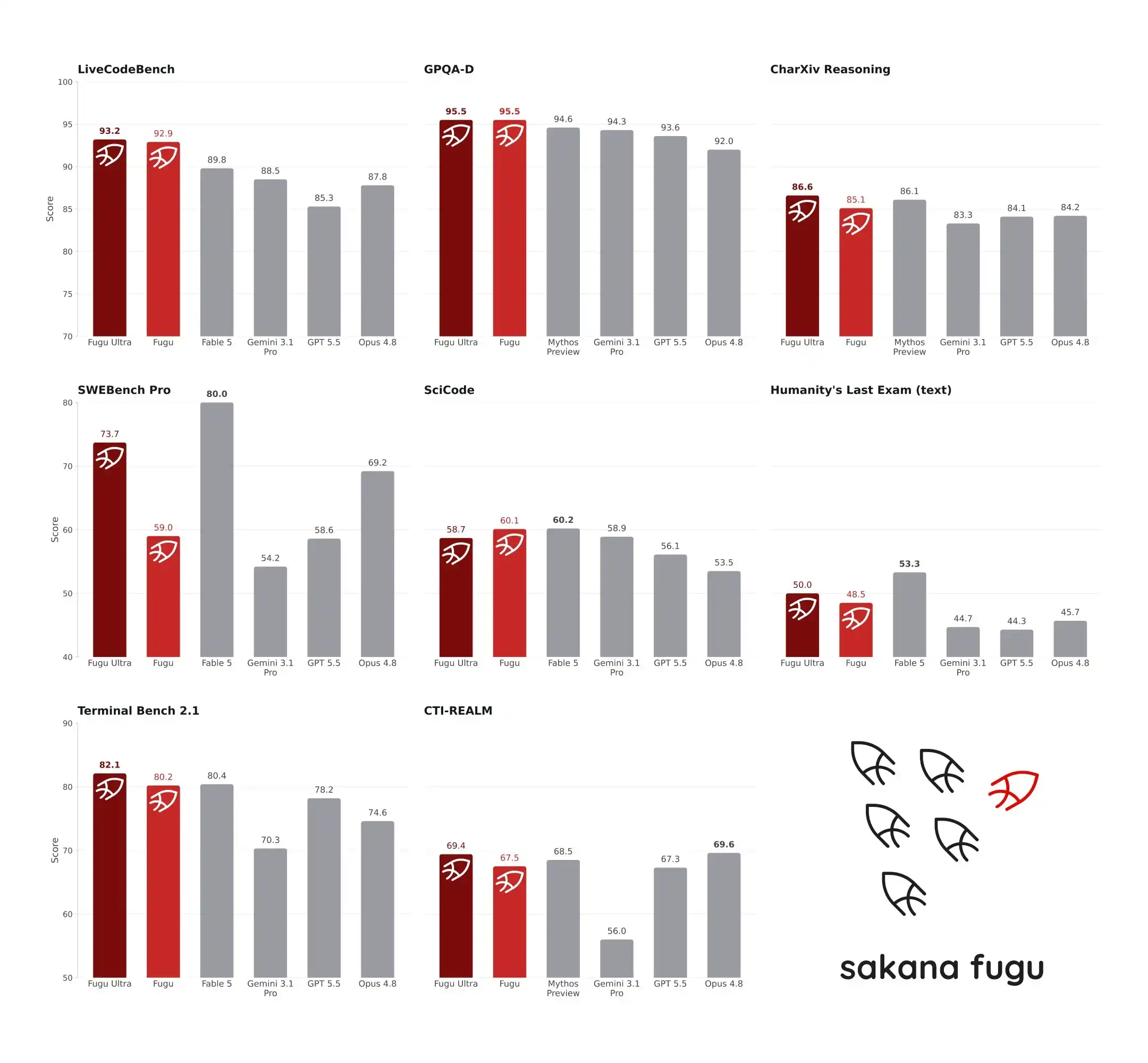
Yang lebih diperhatikan adalah perbandingan Fugu dengan Fable 5 dan Mythos Preview. Seri Fable dari Anthropic dan seri Mythos dari laboratorium terdepan lainnya mewakili level tertinggi kemampuan penalaran AI saat ini. Namun karena terkena pembatasan ekspor atau tidak sepenuhnya terbuka, kedua model ini tidak masuk ke dalam kolam agen Fugu. Sakana AI secara resmi menyatakan Fugu Ultra "menyamai" Fable 5 dan Mythos Preview dalam patokan teknik dan sains, namun harus jelas bahwa perbandingan ini bukan pengujian dalam kolam yang sama. Skor Fugu didasarkan pada hasil operasi aktual sistemnya sendiri, sedangkan data Fable dan Mythos didasarkan pada skor laporan yang dirilis oleh masing-masing produsen.
Perbandingan dengan cara ini menimbulkan sejumlah kontroversi di komunitas pengembang. Ada pandangan bahwa kondisi pengujian sistem yang berbeda dalam lingkungan yang berbeda sulit untuk disejajarkan sepenuhnya, langsung membandingkan skor tidak adil. Namun ada juga pengembang yang menunjukkan bahwa dalam ketiadaan lingkungan pengujian aktual yang seragam, merujuk data laporan produsen adalah praktik industri. Mengesampingkan kontroversi dengan Fable dan Mythos, keunggulan Fugu Ultra atas GPT-5.5 dan Opus 4.8 di SWE-Bench Pro dan TerminalBench 2.1 adalah perbandingan langsung dengan kondisi yang sama. Keunggulan ini bukan karena model dasar Fugu lebih pintar dari GPT-5.5, melainkan karena RL Conductor lebih tepat dalam dekomposisi tugas dan penataan ahli. Dalam eksperimen yang memerlukan penalaran dan verifikasi multi-putaran seperti AutoResearch, pemecahan kubus Rubik, desain mekanis, Fugu juga terus menunjukkan keunggulan. Ini menunjukkan bahwa dalam menangani alur kerja dunia nyata yang "panjang, kacau, multi-langkah", arsitektur penataan multi-agen memang lebih tangguh daripada model tunggal.
Pengujian Aktual Skenario Pengembangan Nyata: Tinjauan Kode dan Stabilitas Sesi Panjang
Bagi pengembang dan pengguna alat AI, skor hanyalah referensi, yang benar-benar menentukan apakah sebuah model bagus atau tidak adalah performanya dalam skenario kerja nyata. Fugu melakukan pengujian Beta dengan hampir 500 pengguna awal sebelum peluncuran, umpan balik pengguna ini mengungkap nilai unik Fugu dalam penerapan nyata.
Tinjauan kode adalah salah satu skenario AI yang paling sering digunakan pengembang. Model tunggal tradisional saat meninjau kode sering kali hanya dapat menemukan kesalahan sintaks permukaan atau lubang logika umum. Dalam pengujian Beta, beberapa pengembang memberi umpan balik bahwa Fugu menunjukkan ketelitian yang luar biasa dalam tinjauan kode, mampu menemukan Bug arsitektur yang dalam, sedangkan alat lain sering kali hanya dapat menemukan beberapa masalah permukaan. Perbedaan ini berasal dari arsitektur Fugu. RL Conductor setelah menerima tugas tinjauan kode, dapat memanggil model yang ahli dalam analisis statis, model yang ahli dalam penalaran logika, dan model yang ahli dalam tinjauan keamanan secara terpisah, melakukan verifikasi silang dari berbagai sudut pandang pada kode yang sama. Mode "konsultasi ahli" ini, secara alami dapat menemukan lebih banyak masalah tersembunyi daripada "bertarung sendirian" model tunggal.
Keunggulan lain yang sering disebut adalah stabilitas sesi panjang. Dalam membangun produk AI Agent, salah satu masalah paling merepotkan bagi pengembang adalah "pergeseran karakter" model dalam sesi panjang. Seiring bertambahnya putaran dialog, model tunggal sering kali melupakan pengaturan awal, atau menyimpang dalam mengikuti instruksi. Seorang eksekutif perusahaan setelah pengujian memberi umpan balik, Persona (karakter) Fugu dalam sesi panjang sangat stabil, hampir tidak terjadi pergeseran. Ini karena RL Conductor sendiri tidak bertanggung jawab mempertahankan memori teks panjang, ia hanya bertanggung jawab memilih model dasar yang paling sesuai untuk menghasilkan balasan di setiap putaran dialog berdasarkan konteks saat ini. Arsitektur "pemisahan kontrol dan generasi" ini sangat meningkatkan stabilitas Agent dalam operasi jangka panjang.
Di bidang keamanan siber, Fugu juga menunjukkan kemampuan tempur ujung ke ujung. Dalam pengujian, Fugu mampu menyelesaikan secara mandiri seluruh proses dari pengintaian, deteksi kerentanan XSS/SQLi hingga tinjauan autentikasi, dan menghasilkan laporan pengujian penetrasi lengkap, serta secara ketat mematuhi instruksi untuk tidak melampaui batas dan merusak sistem. Tingkat penyelesaian tugas kompleks ini bergantung pada penataan yang tepat oleh RL Conductor terhadap rantai alat keamanan dan kemampuan model besar yang berbeda.
Selain itu, efisiensi Token juga merupakan sorotan besar Fugu. Model besar tradisional saat menangani masalah kompleks sering kali menghasilkan rantai pemikiran yang panjang, mengonsumsi banyak Token. RL Conductor Fugu melalui perutean yang tepat, menghindari pemborosan CoT panjang yang tidak berarti. Tampilan resmi dan pengujian awal menunjukkan, ia dapat secara signifikan mengurangi pemborosan Token yang tidak efektif. Bagi pengembang yang dibayar per Token, ini tidak hanya berarti pengurangan biaya, tetapi juga peningkatan kecepatan respons.
Kelemahan Ketergantungan Dasar: Harga yang Harus Dibayar untuk Penataan Multi-Agen
Meskipun Fugu menunjukkan performa cemerlang dalam arsitektur dan skor, sebagai alat yang ditujukan untuk pekerjaan nyata, ia bukan tanpa kelemahan. Arsitektur penataan multi-agen sambil membawa terobosan kinerja, juga membawa risiko dan batasan yang tidak bisa diabaikan.
Masalah paling inti adalah risiko ketergantungan dasar. Kolam agen Fugu sangat bergantung pada API dasar dari perusahaan besar Amerika seperti GPT, Claude, Gemini. Meskipun RL Conductor memiliki kemampuan perutean dinamis, dapat beralih ke model lain jika satu model mengalami kerusakan atau pembatasan lalu lintas, ini hanya menghindari risiko pemasok tunggal, dan tidak serta tidak dapat melepaskan diri dari seluruh ekosistem infrastruktur AI Amerika. Jika model-model dasar ini secara kolektif menaikkan harga, membatasi lalu lintas skala besar, atau mengubah ketentuan API, struktur biaya dan stabilitas Fugu akan terkena dampak langsung. Mode "menumpang" pada infrastruktur orang lain ini memiliki kerapuhan alami dalam komersialisasi dan stabilitas jangka panjang.
Berikutnya adalah pertimbangan antara latensi dan struktur biaya. Meskipun RL Conductor menghemat konsumsi Token tidak efektif melalui perutean tepat, penataan multi-agen pasti melibatkan banyak panggilan API dan komunikasi antar model. Untuk skenario interaksi real-time yang memerlukan latensi sangat rendah, seperti dialog suara real-time atau bantu perdagangan frekuensi tinggi, waktu "pemikiran mendalam dan penataan" Fugu Ultra mungkin lebih lama daripada memanggil langsung model tunggal. Dalam skenario-skenario yang sangat menuntut kecepatan respons, keunggulan arsitektur Fugu justru bisa menjadi penghambat pengalaman.
Selain itu, kontroversi keadilan perbandingan juga terus ada. Seperti disebutkan sebelumnya, Fugu mengklaim menyamai Fable dan Mythos, namun keduanya tidak masuk ke kolam agen Fugu. Di komunitas pengembang, ada suara yang mempertanyakan apakah perbandingan berdasarkan data laporan produsen ini memiliki nilai referensi aktual. Lagipula, perbedaan performa model yang berbeda dalam distribusi tugas yang berbeda sangat besar, perbandingan skor total sederhana mungkin menyembunyikan kelebihan dan kekurangan spesifik. Bagi pengembang yang perlu menilai kemampuan model secara tepat, kurangnya data pengujian dalam kolam yang sama berarti perlu tetap hati-hati dalam pemilihan tipe.
Tidak Berlomba Daya Komputasi, Melainkan Penataan: Penembusan Asimetris Model Besar Jepang
Melompat keluar dari ulasan produk spesifik, kelahiran Fugu memiliki makna yang lebih dalam bagi ekosistem model besar Jepang. Dalam perlombaan senjata AI global, Jepang berada di posisi canggung. Ia tidak memiliki akumulasi daya komputasi puncak dan algoritma terdepan yang terus-menerus seperti Amerika Serikat, juga tidak memiliki kolam data besar dan lingkungan persaingan pasar yang ketat seperti Tiongkok. Yang lebih parah, Jepang juga menghadapi risiko pembatasan ekspor model terdepan Amerika (seperti Fable/Mythos). Dalam konteks ini, jalur "algoritma evolusi" dan "penataan multi-agen" Sakana AI menunjukkan logika "penembusan asimetris" negara dengan sumber daya terbatas.
Jepang domestik bukan tanpa produsen model besar. NTT meluncurkan tsuzumi, institusi seperti ELYZA, Rinna, dan LLM-jp juga berusaha melatih model bahasa domestik. Namun sebagian besar produsen ini mengambil jalur tradisional "pelatihan dari awal", dalam skala parameter dan kemampuan umum, sulit bersaing dengan model puncak Tiongkok-Amerika. Sakana AI adalah satu-satunya laboratorium dengan pengaruh terdepan global di antara mereka, dan mengutamakan "arsitektur asimetris".
Kemampuan perutean dinamis Fugu, pada dasarnya membantu perusahaan dan institusi Jepang membangun "kedaulatan AI". Dalam kondisi daya komputasi terbatas, daripada menghabiskan banyak uang untuk melatih model berparameter miliaran yang semua aspeknya tidak sebaik GPT-5.5, lebih baik melatih "mandor" 7B yang cerdas. Mandor ini dapat dengan fleksibel mengakses model terbaik global sesuai kebutuhan tugas. Jika suatu hari model Amerika tertentu terkena pembatasan ekspor atau penghentian pasokan, RL Conductor dapat dengan cepat mengarahkan tugas ke model lain yang tersedia, bahkan mengakses model khusus domestik Jepang. Arsitektur ini membuat Jepang dalam penggunaan kemampuan AI, memperoleh tingkat otonomi dan kemampuan tahan risiko tertentu.
OmniTools dalam mengamati ekosistem alat AI global menemukan, kemampuan model besar secara bertahap mendatar, medan persaingan utama sedang beralih dari sekadar penumpukan parameter ke rantai alat dan skenario penerapan. Kemunculan Fugu tepat membuktikan tren ini. Ia tidak lagi mengejar kesempurnaan pada model tunggal, melainkan mengejar optimalitas di tingkat sistem. Pemikiran ini memiliki makna penting sebagai acuan bagi negara dan wilayah yang tidak unggul dalam daya komputasi dan data.
Tentu saja, "penembusan asimetris" ini juga memiliki plafonnya. Selama teknologi inti model dasar masih dikuasai oleh segelintir raksasa, batas atas kemampuan sistem penataan akan dibatasi oleh model dasar. Fugu membuktikan model 7B dapat menjadi komandan yang baik, namun tidak dapat menciptakan kemampuan yang tidak dimiliki model dasar. Model besar Jepang untuk benar-benar mencapai penembusan, selain inovasi arsitektur penataan, masih perlu terus berinvestasi dalam daya komputasi dasar, algoritma inti, dan data berkualitas tinggi. Fugu adalah inovasi tingkat sistem yang cerdik, namun bukan obat ajaib. Bagi pengembang dan pengguna perusahaan, Fugu menyediakan opsi baru yang sangat kompetitif dalam skenario teknik kompleks, namun saat menggunakannya, juga perlu menyadari kerapuhan ketergantungan dasarnya dan pertimbangan biaya latensi.







