Penulis: Matt White, Chief Technology Officer AI Global Linux Foundation
Diterjemahkan oleh: Felix, PANews

Wang Xingxing (CEO Unitree) bersama Matt White
Beberapa minggu yang lalu di Shanghai, seorang teman yang ikut dalam perjalanan (seorang yang cerdas, biasa mengikuti berita dan mengamati hal-hal, tetapi tidak terlalu paham teknologi robotika), bertanya di saat makan malam sebuah pertanyaan yang telah ditunggu-tunggu selama perjalanan.
"Anjing-anjing robot yang kita lihat berlarian di mana-mana, robot humanoid yang melakukan pertunjukan kung fu di panggung demo di kantor Unitree, dan lengan robot yang melipat pakaian yang kita lihat. Bagaimana mereka melakukannya? Apakah mereka digerakkan oleh model bahasa besar (LLM)? Bagaimana sebenarnya cara kerjanya? Apakah ada semacam model bahasa yang mengendalikan gerakan mereka?"
Ini pertanyaan yang bagus, jujur saja: dalam beberapa hal ya, tetapi kisah sebenarnya jauh lebih menarik. Robot-robot yang Anda lihat di media sosial bukanlah ChatGPT dengan baju besi logam. Mereka menjalankan satu set stack teknologi (banyak lapisan AI yang bekerja sama). Stack teknologi ini telah berubah lebih banyak dalam tiga tahun terakhir daripada dalam tiga puluh tahun sebelumnya. Model bahasa adalah bagian darinya. Model visual, model gerakan, pohon perilaku, loop kontrol klasik, dan keluarga sistem baru yang disebut "model dunia", semuanya juga merupakan komponen penting. Dan "model dunia" mungkin adalah yang paling penting dari semua perkembangan ini.
Ini adalah artikel panjang, akan dimulai dari awal, lalu secara bertahap menceritakan setiap perubahan besar, akhirnya sampai pada tahap sekarang: robot tidak hanya dapat bereaksi terhadap dunia, tetapi juga dapat membayangkannya.
Satu: Era Pra-LLM : Ketika Robot Masih Hanya Perangkat Lunak
Selama beberapa dekade, membuat robot berarti menulis banyak kode, dan hampir semua kode ini tidak perlu belajar.
Robot industri klasik adalah struktur menara yang ditumpuk dengan modul yang dirancang hati-hati. Seperti lengan robot oranye yang mengelas sasis Toyota di tahun 90-an, atau BigDog milik Boston Dynamics di awal tahun 2000-an.
- Persepsi: Menyaring gambar kamera, melakukan deteksi tepi, menggunakan pencocokan geometri untuk mengenali posisi benda kerja.
- Estimasi State: Menggabungkan encoder roda, giroskop, dan akselerometer (fusi sensor) untuk menentukan posisi dan kecepatan gerak robot.
- Perencanaan: Diberikan postur target, menggunakan algoritma seperti A* atau RRT untuk menghitung jalur tanpa tabrakan di peta yang diketahui.
- Kontrol: Di lapisan paling bawah, pengontrol PID menyesuaikan torsi motor ratusan hingga ribuan kali per detik untuk mengikuti jalur tersebut.
Lapisan-lapisan ini biasanya ditulis oleh orang yang berbeda di lab yang berbeda, dan disatukan dengan sangat teliti. Perilaku (misalnya "jika cangkirnya merah, ambillah, jika tidak tunggu") dikodekan sebagai state machine atau behavior tree: yaitu diagram alir yang dijalankan robot langkah demi langkah.
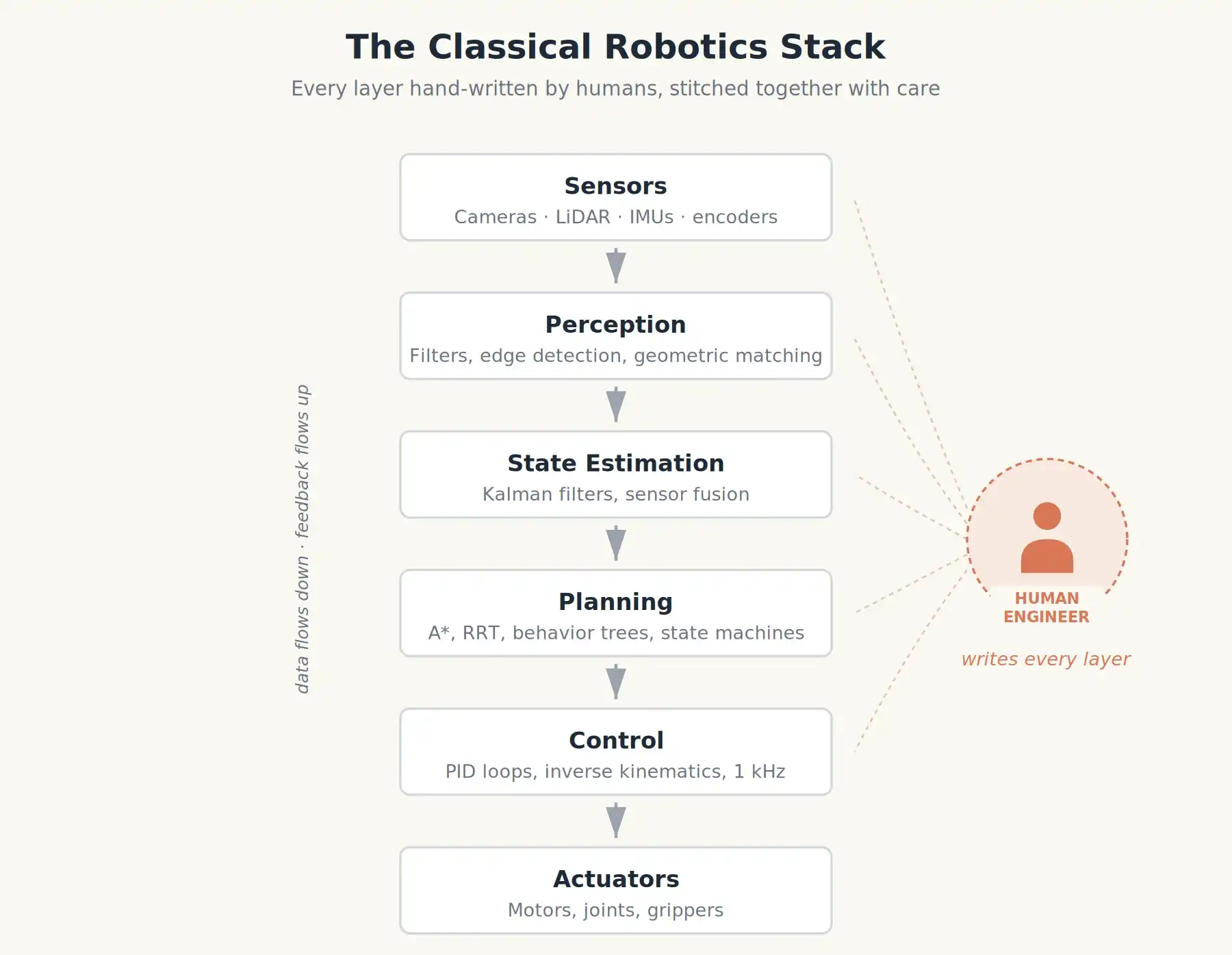
Keuntungan dari pendekatan ini jelas. Ini dapat diprediksi, memenuhi standar keselamatan. Itulah sebabnya mobil Anda dilengkapi dengan sistem ABS yang efektif.
Kelemahannya juga jelas. Robot seperti itu hanya bisa berfungsi pada tingkat kecerdasannya dalam skenario yang dibayangkan oleh insinyur. Begitu ditempatkan di pabrik baru, kondisi pencahayaan baru, atau warna cangkir baru, dia akan gagal. Kemampuan generalisasinya hampir nol.
Dua: Machine Learning Mulai Merambah
Pada tahun 2010-an, deep learning mulai menangani masalah lapisan persepsi. Jaringan saraf konvolusional (CNN) yang mengalahkan manusia dalam tugas klasifikasi gambar ImageNet, dapat dilatih ulang untuk mendeteksi titik pegangan pada objek, memisahkan furnitur di dalam ruangan, atau mengenali postur manusia. Tiba-tiba, lapisan "persepsi" di puncak stack teknologi tidak perlu lagi dirancang secara manual, Anda bisa langsung melatihnya.
Kemudian, mekanisme pembelajaran menyebar ke lapisan "kontrol". Peneliti dari Berkeley, DeepMind, dan OpenAI menunjukkan bahwa pembelajaran penguatan (membuat agen robot mencoba jutaan kali di lingkungan simulasi dan memperkuat perilaku yang efektif) dapat menghasilkan gaya berjalan yang mengejutkan dan terampil, manipulasi objek dengan tangan (OpenAI menyelesaikan kubus Rubik dengan satu tangan pada 2019 adalah tonggak sejarah), dan strategi gerak yang beradaptasi dengan medan berbeda.
Arah penelitian paralel lainnya adalah pembelajaran imitasi, sering disebut cloning perilaku: merekam ratusan upaya manusia mengendalikan robot jarak jauh untuk menyelesaikan suatu tugas, lalu melatih jaringan saraf untuk memprediksi tindakan apa yang akan diambil manusia berdasarkan apa yang diamati robot.
Kuncinya adalah: setiap kebijakan yang dipelajari terlalu sempit. Latih sebuah jaringan untuk mengambil balok merah, dia tidak tahu bagaimana menangani cangkir kuning. Latih dia berjalan di rumput, dia akan jatuh di lantai keramik. Kemampuan generalisasi masih menjadi masalah yang harus dipecahkan.
Penting disebutkan, periode ini juga melihat kemunculan infrastruktur dasar yang hingga kini masih mendukung hampir segalanya: ROS, Robot Operating System (pertama kali dirilis November 2007). ROS bukanlah sistem operasi dalam arti Windows atau Linux, melainkan kerangka kerja middleware, sistem pipa robotika universal. Ini memungkinkan "node kamera", "node navigasi", "node pengontrol lengan robot", dan puluhan node lainnya untuk mempublikasikan dan berlangganan pesan melalui bus bersama.
Versi saat ini, ROS2, berjalan di inti sebagian besar besar robot penelitian dan komersial di seluruh dunia, dari laboratorium Stanford hingga startup robot humanoid Tiongkok. Ketika orang membicarakan "sistem operasi" robot, mereka hampir selalu mengacu pada ROS2 ditambah berbagai paket perangkat lunak persepsi, perencanaan, dan kontrol yang berjalan di atasnya.
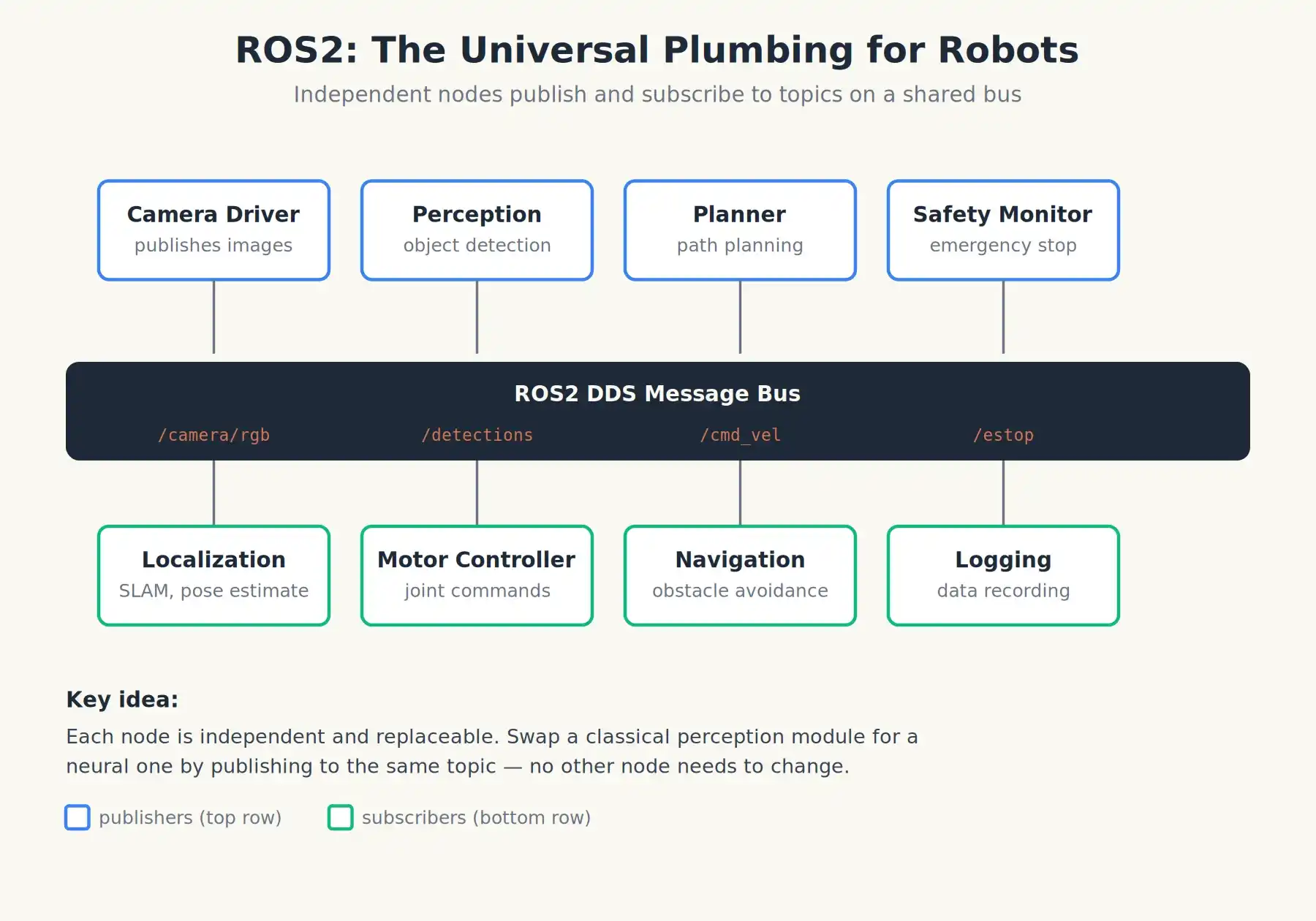
ROS2: Bukan sistem operasi, melainkan pipa universal yang membuat perangkat lunak robot independen saling berkomunikasi
Tiga: Aplikasi LLM dalam Robotika
Kemudian, ChatGPT lahir.
Tiba-tiba ada sesuatu seperti ini: LLM. Dia dapat membaca instruksi sederhana dalam bahasa Inggris, melakukan penalaran multi-langkah, menulis kode, dan memanggil fungsi. Ahli robotika hampir segera menyadari bahwa inilah bagian yang hilang yang telah mereka perjuangkan selama bertahun-tahun. Membuat robot melakukan tugas yang berguna di rumah atau kantor, bagian tersulitnya biasanya bukan kontrol motor, tetapi interaksi manusia-robot: bagaimana manusia memberi tahu robot apa yang harus dilakukan, dan bagaimana robot memecah tujuan itu menjadi tindakan atomik yang sudah diketahuinya cara melakukannya?
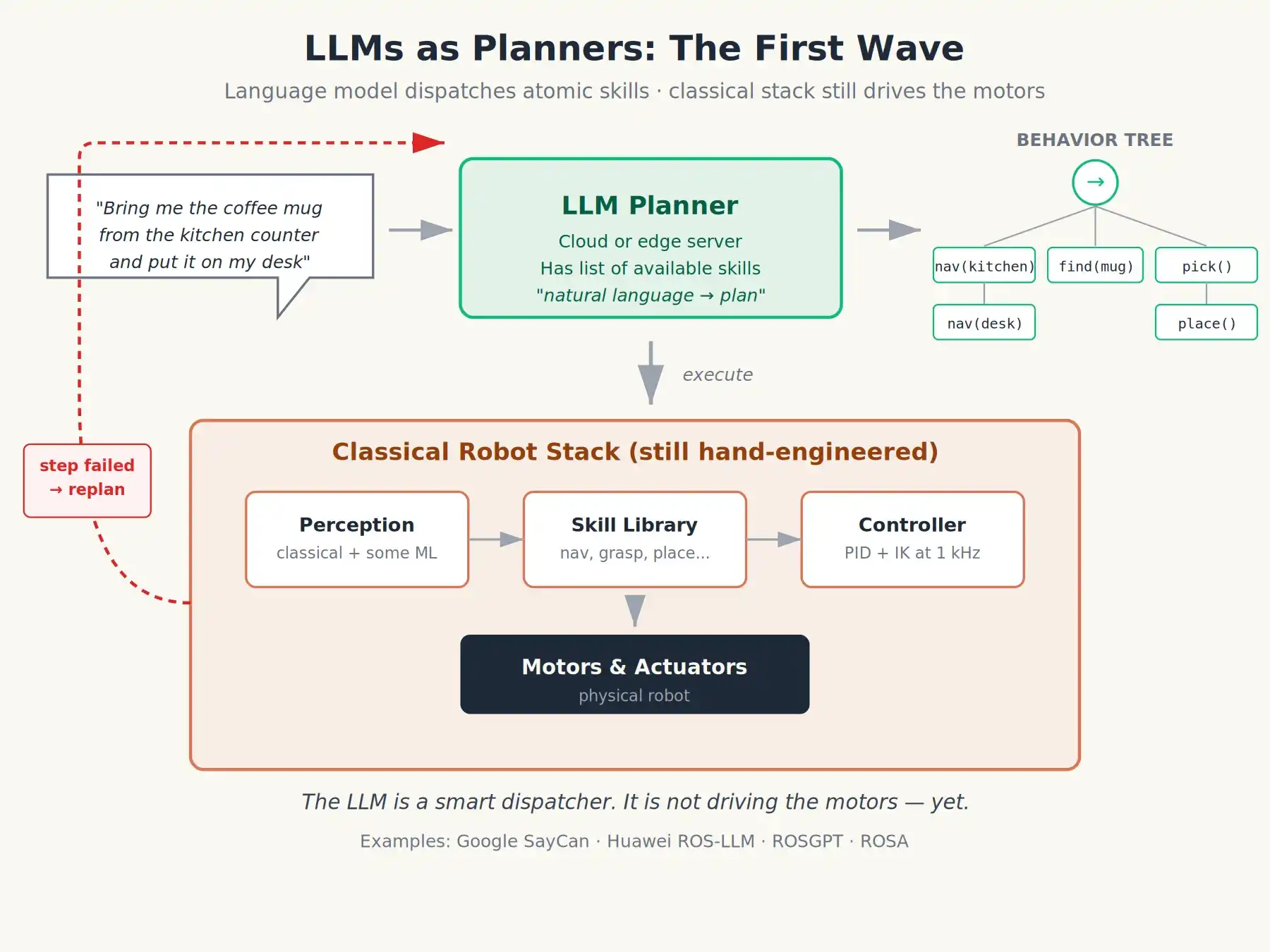
Gelombang pertama penerapan LLM pada robotika adalah memperlakukan model bahasa sebagai kompiler bahasa alami yang berada di atas ROS. Polanya adalah sebagai berikut:
-
Pengguna berkata dalam bahasa Inggris: "Ambil cangkir kopi di meja dapur, letakkan di atas mejaku."
-
LLM menghasilkan rencana berdasarkan daftar keterampilan atomik yang tersedia untuk robot: bisa berupa urutan pemanggilan fungsi, state machine, atau pohon perilaku yang ditulis dalam XML.
-
Node ROS2 akan menjalankan rencana tersebut langkah demi langkah. Jika satu langkah gagal, maka akan melaporkan kegagalan tersebut kembali ke LLM, agar LLM dapat merencanakan ulang.
Proyek SayCan Google 2022 adalah versi yang sangat ringkas dari ide ini: LLM mengusulkan keterampilan, model "affordance" independen mengevaluasi kemungkinan keberhasilan setiap keterampilan saat ini, robot memilih kombinasi keterampilan dengan skor gabungan tertinggi. Kerangka kerja terbuka seperti ROS-LLM, ROSGPT, dan ROSA yang dipimpin Huawei Research Laboratory mempopulerkan pola ini.
Ini memang lompatan yang signifikan. Tiba-tiba, Anda bisa memberi tahu robot "bersihkan meja, masukkan barang yang dapat didaur ulang ke tempat sampah biru", dan dia akan mencoba melakukan beberapa operasi yang masuk akal. Namun perhatikan, masih ada masalah di sini: model bahasa masih berada di lapisan perencanaan. Instruksi tindakan sebenarnya masih dihasilkan oleh pengontrol yang dirancang hati-hati atau dilatih khusus di lapisan bawah. Model bahasa hanyalah penjadwal yang cerdas, dia tidak bertanggung jawab menggerakkan.
Empat: Model Visual-Bahasa-Aksi (VLA), Saat Otak Mulai Menggerakkan Robot

Robot Keenon XMAN-R1 sedang mengambil obat dari rak di apotek otomatis Galbot di Beijing. Hanya $100k
Lompatan berikutnya lebih sulit dan lebih penting. Peneliti mengajukan pertanyaan yang lebih ambisius: Bagaimana jika model tidak hanya bisa merencanakan, tetapi juga menghasilkan instruksi aksi secara langsung? Bagaimana jika gambar kamera dan instruksi bahasa dimasukkan langsung ke jaringan saraf, lalu menghasilkan gerakan sendi untuk milidetik berikutnya?
Inilah model visual-bahasa-aksi (VLA). Ini sekarang menjadi paradigma utama di bidang robot humanoid dan robot berkaki empat.
Robot bahasa-visual pertama yang dikenal luas adalah RT-2 dari Google DeepMind yang diluncurkan tahun 2023. Kehebatannya terletak pada: menggunakan model bahasa-visual besar (yang telah dilatih untuk deskripsi gambar dan jawaban pertanyaan), dan melanjutkan pelatihannya dengan data demonstrasi robot, tetapi memperlakukan tindakan robot sebagai token lain yang perlu diprediksi. Jaringan saraf yang sama yang awalnya bisa mengeluarkan "kucing duduk di atas bantalan", sekarang bisa mengeluarkan rangkaian token yang mengkodekan "gerakkan cakar kanan ke depan 3 cm, rapatkan cakar, angkat 5 cm". Penalaran dan tindakan selesai dalam model yang sama.
Kemudian, di pertengahan 2024, tim yang dipimpin oleh Stanford merilis OpenVLA, model VLA sumber terbuka dengan 7 miliar parameter, yang dilatih berdasarkan dataset Open X-Embodiment. Dataset ini mengumpulkan lebih dari satu juta segmen pelatihan dari 21 laboratorium penelitian berbeda, mencakup 22 tubuh robot berbeda. Ini adalah pertama kalinya orang di luar Google dapat mengunduh model robot universal dan mulai memodifikasinya. Ini mengubah seluruh bidang dalam semalam.
Saat ini, VLA terkemuka, meskipun jumlahnya tidak banyak, berkembang pesat:
- π0 dan π0.5 dari Physical Intelligence: Adaptasi tugas yang luar biasa.
- NVIDIA Isaac GR00T N1.7: Bobot terbuka, lisensi komersial, dirancang khusus untuk robot humanoid, adalah model yang saat ini digunakan oleh sebagian besar perusahaan hardware Tiongkok untuk pelatihan lanjutan dengan datanya sendiri.
- Helix dari Figure AI dan Helix-02 yang lebih baru: Teknologi berpemilik, tetapi sangat penting secara arsitektural.
- Genie Envisioner dari AgiBot: Platform berbasis model dunia Tiongkok.
- SmolVLA, NORA, ACoT-VLA, CogACT: Semakin banyak VLA muncul dari dunia akademis, mengeksplorasi arah desain yang berbeda.
Bagaimana VLA Bekerja (Tanpa Rumus Matematika)
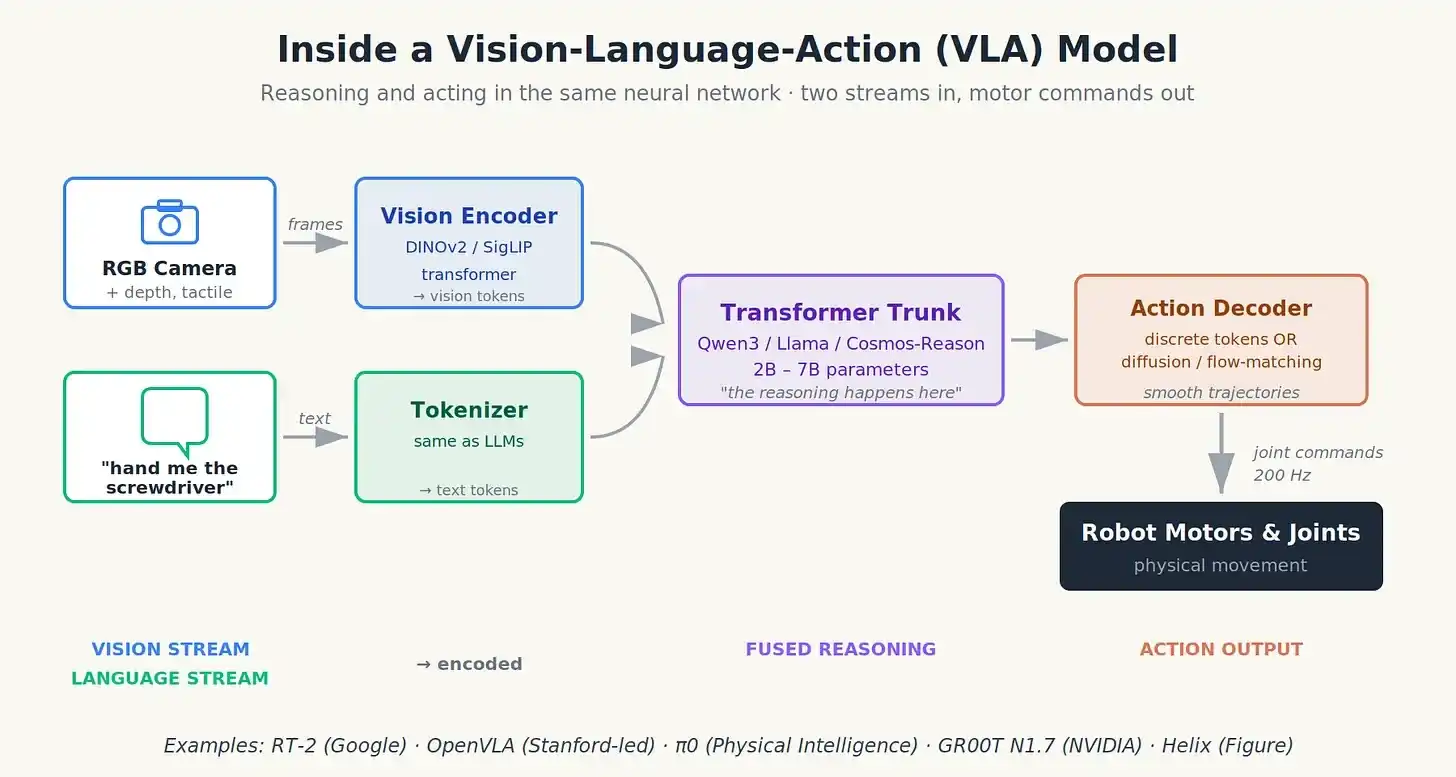
Bayangkan VLA menggabungkan tiga sinyal input menjadi satu sinyal output.
Aliran data pertama adalah data visual. Kamera RGB (terkadang sensor kedalaman atau LiDAR), terkadang sensor taktil di ujung jari, diproses oleh encoder visual (biasanya model Transformer seperti DINOv2 atau SigLIP), yang mengompresi setiap gambar menjadi ratusan "token visual", meringkas apa yang dilihat robot.
Aliran data kedua adalah bahasa. Instruksi Anda ("serahkan obeng kepadaku") diubah menjadi token seperti di ChatGPT.
Kedua aliran data ini dihubungkan dan dimasukkan ke "tulang punggung" Transformer (biasanya model bahasa sumber terbuka kecil seperti Qwen3 atau Llama). Tulang punggung ini bertanggung jawab atas penalaran, menggabungkan apa yang dilihatnya dengan apa yang ditanyakan kepadanya.
Aliran data ketiga: Aksi, mengalir keluar dari ujung yang lain. Di sinilah berbagai desain arsitektur mulai berbeda:
- Token aksi diskrit: Model langsung menghasilkan token yang dapat didekode menjadi sudut sendi atau posisi end-effector, seperti ChatGPT menghasilkan kata-kata. Ini sederhana, tetapi bisa terasa tersendat saat dijalankan pada frekuensi tinggi.
- Diffusion atau flow-matching action head: Jaringan mini independen menerima output dari tulang punggung, dan mendeburkan untuk menghasilkan lintasan posisi sendi yang halus, seperti model difusi gambar, hanya saja menghasilkan gerakan. Ini yang dilakukan π0, menghasilkan gerakan yang lebih halus dan alami.
- Chunking aksi: Alih-alih memprediksi satu instruksi berikutnya, memprediksi sekumpulan instruksi untuk setengah detik berikutnya sekaligus, sehingga menghaluskan getaran.
Dalam model VLA: Dua aliran input masuk, instruksi gerakan keluar, penalaran dan tindakan menyatu dalam satu jaringan.
Inilah perubahan arsitektur yang sangat penting: penalaran dan tindakan tidak lagi terpisah. Mengajari jaringan saraf untuk mengenali cangkir, juga mengajarinya cara meraih cangkir. Keterkaitan inilah yang memungkinkan VLA melakukan generalisasi, sementara pendahulunya tidak bisa.
Lima: Strategi Dua Otak, Bagaimana LLM dan VLA Bekerja Sama
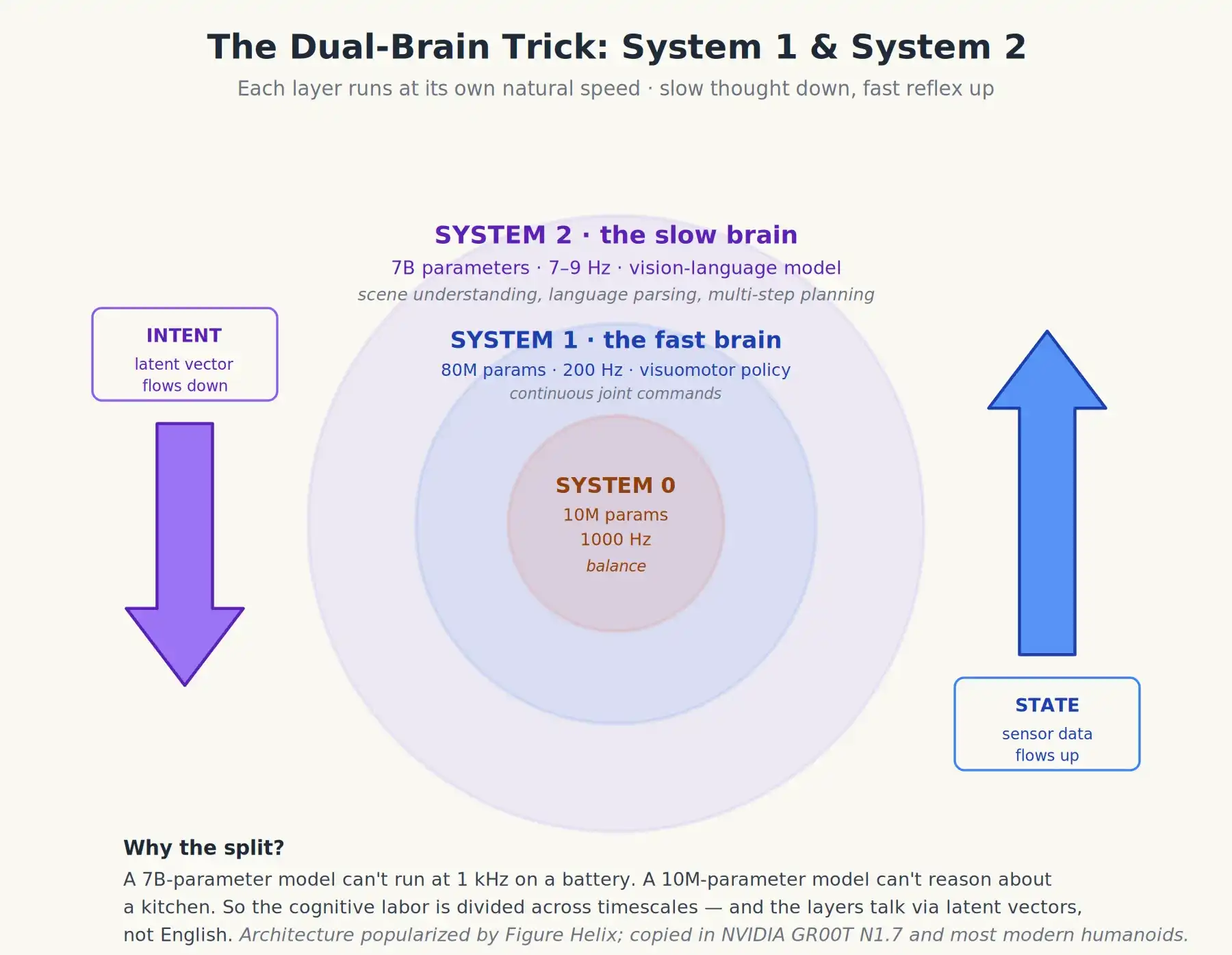
Ada detail di sini yang jarang dijelaskan secara eksplisit dalam pemasaran. Robot humanoid dengan kinerja terbaik saat ini tidak menjalankan sistem VLA tunggal, melainkan dua model dengan kecepatan berbeda yang saling berkomunikasi. Ini terkadang disebut arsitektur sistem ganda atau sistem 1 / sistem 2, mengadopsi dari kerangka psikologi Daniel Kahneman yang berpendapat manusia memiliki otak intuisi yang cepat dan otak berpikir yang lambat dan penuh pertimbangan.
Helix dari Figure AI menjadikan desain ini klasik, dan sekarang (serta variasinya) hampir ditiru di mana-mana. Sangat penting, GR00T N1.7 NVIDIA menggunakan desain ini, dan sebagian besar robot humanoid Tiongkok juga mengadopsinya. Strukturnya adalah sebagai berikut:
- Sistem 2 (S2): Otak berpikir lambat. Model bahasa-visual dengan 7 miliar parameter, berjalan pada frekuensi sekitar 7–9 Hz (yaitu 7 hingga 9 kali per detik). Pekerjaannya adalah mengamati pemandangan, mengurai instruksi, melakukan penalaran multi-langkah (seperti, "mangkuk ada di belakang kotak sereal; Saya perlu memindahkan kotaknya dulu"), dan mengeluarkan niat tingkat tinggi — biasanya sekumpulan vektor internal yang ringkas, bukan kata-kata itu sendiri.
- Sistem 1 (S1): Otak reaksi cepat. Model kebijakan visuomotor yang jauh lebih kecil (sekitar 80 juta parameter), berjalan pada frekuensi 200 Hz. Ia menerima vektor niat dari S2 ditambah data sensor terbaru, mengeluarkan instruksi sendi yang kontinu. Dia tidak memiliki "pemikiran" dalam arti yang sebenarnya, hanya bereaksi.
Baru-baru ini, Helix-02 dari Figure menambahkan Sistem 0 (System 0). Itu berada di bawah sistem dua otak, sebagai lapisan refleks, bukan lapisan kognitif ketiga. Ini adalah jaringan dengan 10 juta parameter, berjalan pada 1 kHz, menangani keseimbangan dasar dan koordinasi seluruh tubuh, menggantikan lebih dari seratus ribu baris kode kontrol gerak C++ yang ditulis tangan. Anda bisa membayangkan S0 sebagai sumsum tulang belakang yang dipelajari: dia tidak melakukan penalaran atau perencanaan, hanya menjaga tubuh tetap tegak dan terkoordinasi, sementara pemikiran dilakukan oleh sistem dua otak di atasnya.
Arsitektur dua otak robot humanoid modern: Sistem 2 berpikir lambat, Sistem 1 bereaksi cepat — di bawahnya ada lapisan refleks Sistem 0 untuk menjaga keseimbangan, kontak taktil, dan koordinasi seluruh tubuh
Pembagian ini berasal dari batasan fisika. Jika instruksi gerakan dikeluarkan hanya setiap 200 milidetik (ini adalah kecepatan jalannya VLA besar), gerakan robot akan lambat seperti bergerak di bawah air. Pembaruan instruksi gerakan harus lebih cepat daripada osilasi alami sendi yang dikendalikannya, yang berarti diperlukan ratusan hingga ribuan pembaruan per detik. Tidak ada model Transformer 7 miliar parameter yang dapat berjalan secepat itu pada robot bertenaga baterai.
Oleh karena itu, tugas kognitif dibagi: model besar dan lambat bertanggung jawab untuk berpikir; model kecil dan cepat bertanggung jawab untuk bertindak. Mereka tidak berkomunikasi dalam bahasa Inggris, tetapi melalui vektor laten yang dipelajari: model lambat mengeluarkan tujuan abstrak, dan model cepat tahu bagaimana menafsirkannya.
Enam: Cloud, Edge Computing, dan Masalah Penempatan "Otak"
Di mana sebenarnya semua komputasi ini dilakukan?
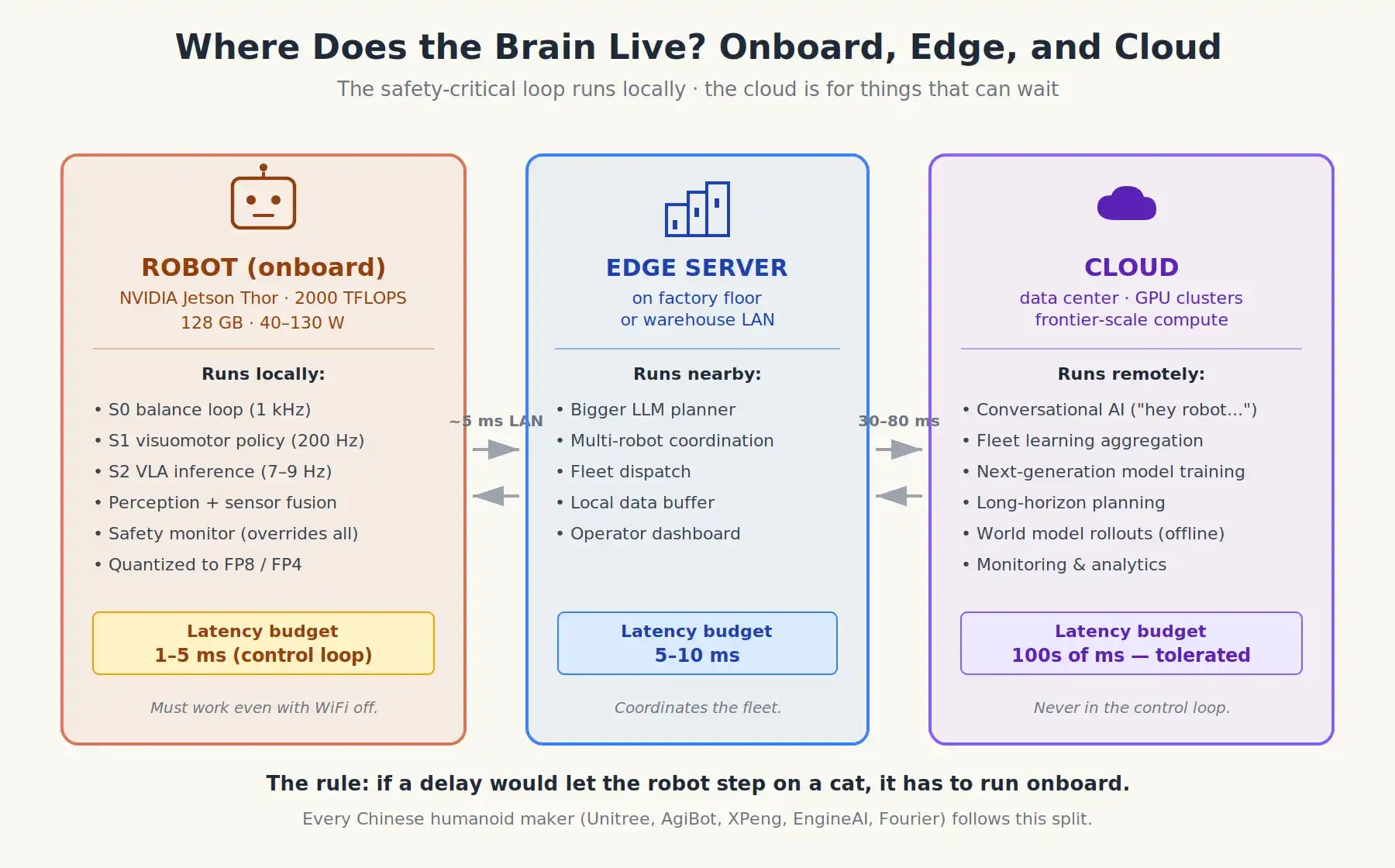
Saat ini, hampir telah terbentuk konsensus yang kuat dan hampir ideologis di antara tim robotika bahwa loop kontrol inti yang penting untuk keselamatan harus berjalan secara lokal. Ada dua alasan:
Latensi. Waktu perjalanan bolak-balik melalui WiFi atau jaringan seluler, optimisnya adalah 30-80 milidetik. Instruksi gerakan perlu diperbarui setiap 1-5 milidetik. Siklus jaringan seperti itu tidak dapat berjalan dengan baik.
Keandalan. Robot beroperasi di pabrik, gudang, dapur, rumah sakit, dan tempat-tempat lain. Jaringan bisa mati kapan saja. Jika robot berhenti bekerja begitu Wi-Fi terputus, itu akan menjadi bahaya keamanan.
Jadi, pembagian modern kira-kira sebagai berikut:
Onboard (Lokal), berjalan pada perangkat seperti modul NVIDIA Jetson Thor atau AGX Thor (sekitar 2.000 TFLOPS, 128 GB memori, konsumsi daya 40–130 W):
- Semua fungsi S0/S1: keseimbangan, gerak, kontrol gerakan halus.
- VLA itu sendiri (sistem 2), untuk mengatasi batasan perangkat keras, semakin banyak dikuantisasi ke format FP8 atau FP4. Model dengan 2 miliar hingga 7 miliar parameter saat ini dapat berjalan di perangkat.
- Persepsi, fusi sensor, dan program pemantauan keselamatan yang dapat menutupi operasi lainnya.
Cloud atau server jarak jauh (jika ada):
- Antarmuka percakapan ("Hei robot, apa yang harus saya masak untuk makan malam?"): Ini dapat menoleransi latensi.
- Pembelajaran kluster: Ribuan robot mengirim data operasi jarak jauh kembali ke server, untuk dikumpulkan ke dalam versi model berikutnya.
- Perencanaan jangka panjang yang luas diperlukan, mungkin menggunakan model skala mutakhir.
- Dasbor dan pemantauan operator.
Selain itu, ada lapisan menengah yang semakin besar: server edge lokal yang berada di pabrik atau gudang, berkomunikasi dengan kluster robot melalui jaringan lokal dengan latensi hanya tingkat milidetik satu digit. LLM yang lebih besar mungkin ditempatkan di tingkat ini, bertanggung jawab untuk tugas penjadwalan tingkat tinggi yang tidak perlu dikelola sendiri oleh robot tunggal.
Gelombang robot humanoid Tiongkok dibangun berdasarkan asumsi ini: Unitree, AgiBot, XPeng IRON, Fourier, EngineAI. Robot mereka dilengkapi dengan kemampuan komputasi onboard (biasanya Jetson, terkadang juga menggunakan chip domestik seperti Huawei Ascend), sementara cloud digunakan untuk pembelajaran kluster dan antarmuka percakapan, bukan untuk loop kontrol.
Di mana sebenarnya otak robot berjalan: Loop kritis keselamatan berjalan secara lokal, cloud untuk hal-hal yang bisa menunggu
Tujuh: Mengapa Model Sumber Terbuka Diam-diam Menjadi Fokus
Jika Anda hanya melihat demo, Anda mungkin mengira bidang ini didominasi oleh beberapa perusahaan Amerika yang didanai besar. Tetapi kenyataannya jauh lebih kompleks. Kecepatan perkembangan AI fisik sangat ditentukan oleh model bobot sumber terbuka yang dapat diunduh dan disempurnakan oleh siapa saja.
Berikut adalah beberapa model yang jumlahnya tidak banyak, tetapi sangat penting:
- OpenVLA (Stanford): Model robot universal 7B sumber terbuka pertama.
- NVIDIA Isaac GR00T (N1, N1.5, N1.7): Bobot sumber terbuka akan segera hadir, lisensi komersial juga akan segera hadir, model ini dilatih berdasarkan puluhan ribu jam video egosentris manusia. GR00T N1.7 dirilis Maret 2026, saat itu siapa pun yang memiliki robot humanoid dapat menggunakan arsitektur sistem gandanya secara gratis.
- π0 dari Physical Intelligence: Merilis bobot untuk penelitian.
- NVIDIA Cosmos: Model dasar dunia terbuka.
- AgiBot World: Dataset sumber terbuka besar dari startup Shanghai, berisi demonstrasi robot humanoid yang dikendalikan jarak jauh.
- LeRobot dari Hugging Face: Perpustakaan terbuka, telah menjadi tempat berkumpulnya semua platform di atas.
- mimic-video dari Mimic robotics: Model video-aksi sumber terbuka, dengan efisiensi sampel 10 kali lebih tinggi dari VLA tradisional.
Penting, karena dua alasan. Pertama, startup robotika tidak perlu lagi menghabiskan puluhan juta dolar untuk pra-latih model dasar: mereka dapat mengambil GR00T atau π0, lalu melatihnya lebih lanjut dengan data robot mereka sendiri. Unitree, EngineAI, Booster, Galbot, dan puluhan perusahaan Tiongkok yang lebih kecil melakukan hal ini. Inilah mengapa perusahaan dengan hanya ratusan karyawan juga dapat mengeluarkan robot humanoid yang bisa berjalan, berbicara, melipat pakaian: mereka berdiri di atas pundak stack teknologi sumber terbuka.
Kedua, model sumber terbuka adalah satu-satunya cara realistis untuk menyelesaikan masalah keamanan. Jika model yang sepenuhnya tertutup berjalan di dalam robot di suatu lantai pabrik, dan tidak ada wawasan tentang logika penalarannya dari luar, itu jelas akan menjadi mimpi buruk peraturan. Model terbuka memungkinkan auditor, peneliti, dan operator benar-benar memeriksa apa yang telah dilatih robot.
Delapan: Masalah Apa Lagi yang Belum Terselesaikan
Jika Anda telah melihat cukup banyak video demo robot, Anda pasti juga telah melihat banyak video kegagalan robot. Generasi robot LLM+VLA saat ini memang mengesankan, tetapi memang memiliki keterbatasan yang jelas. Berikut adalah masalahnya:
- Pemulihan di tengah tugas. VLA lebih mampu menangani perubahan tak terduga daripada teknologi sebelumnya. Tetapi ketika hal-hal benar-benar salah (seperti gagal meraih, benda berguling, ada orang yang masuk ke area kerja), kembali ke jalur yang benar masih merupakan kelemahan. Robot akan mengulangi tindakan yang gagal secara membabi buta.
- Efisiensi sampel. Melatih VLA dari awal memerlukan puluhan ribu jam data operasi jarak jauh. Sementara manusia dapat belajar mengoperasikan alat baru dalam beberapa menit. Kesenjangan efisiensi ini sangat besar.
- Generalisasi lintas entitas. Model yang dilatih dengan lengan robot Franka di laboratorium Stanford tidak bermigrasi dengan sempurna ke robot humanoid Unitree di gudang Shenzhen. Keduanya memiliki morfologi fisik yang berbeda.
- Tugas jangka panjang. Tugas apa pun yang memerlukan perilaku koheren lebih dari 30-60 detik, dan mengandung beberapa sub-tujuan, rentan menyimpang. Tugas seperti "buatkan saya sarapan" tetap tidak terjangkau.
- Pengetahuan Fisika Dasar. VLA dilatih dengan imitasi, bukan dengan pemahaman. Mereka tidak benar-benar memahami prinsip di balik "menumpahkan segelas air" ketika gelas itu ditumpahkan. Dia hanya telah melihat beberapa contoh, dan memprediksi apa yang akan terjadi berikutnya berdasarkan pencocokan pola.
- Kemampuan Penalaran Spasial. Meskipun mereka multimodal, mereka secara mengejutkan lemah dalam tugas seperti "berjalan mengelilingi rintangan daripada menembusnya" atau "menumpuk hal-hal ini tanpa membuatnya jatuh".
Kekurangan terakhir ini mendorong bidang ini untuk mulai bertaruh pada jenis model yang sama sekali berbeda.
Sembilan: Model Dunia
Bayangkan: Bagaimana jika, alih-alih melatih robot untuk memprediksi tindakan, kita melatihnya untuk memprediksi konsekuensi dari tindakan tersebut?
Model dunia (World Model) adalah jaringan saraf yang memprediksi bagaimana keadaan dunia selanjutnya berdasarkan keadaan dunia saat ini (biasanya video atau rangkaian frame) dan tindakan yang diusulkan. Sederhananya, Anda bisa membayangkannya sebagai peramal video yang dapat dipelajari dengan setir. Anda menunjukkan kepadanya cuplikan kamera terakhir, dan beri tahu dia "robot akan menggerakkan lengannya ke depan 10 cm", dan dia dapat menghasilkan video realistis yang memprediksi cuplikan berikutnya.
Mengapa ini penting?
Karena dengan model dunia, robot dapat berpikir sebelum bertindak. Dia dapat mengonsepkan tiga atau empat kandidat tindakan yang berbeda sebelumnya, memprediksi hasil dari setiap tindakan, menilai, dan memilih yang terbaik. Semua ini sebelum motor bergerak. Inilah cara kerja mesin catur: dia tidak menghafal langkah, tetapi mensimulasikan masa depan. Di bidang robotika fisik, kemampuan ini belum pernah dimiliki sebelumnya, karena belum pernah ada model yang cukup akurat untuk mensimulasikan kekacauan dunia nyata.
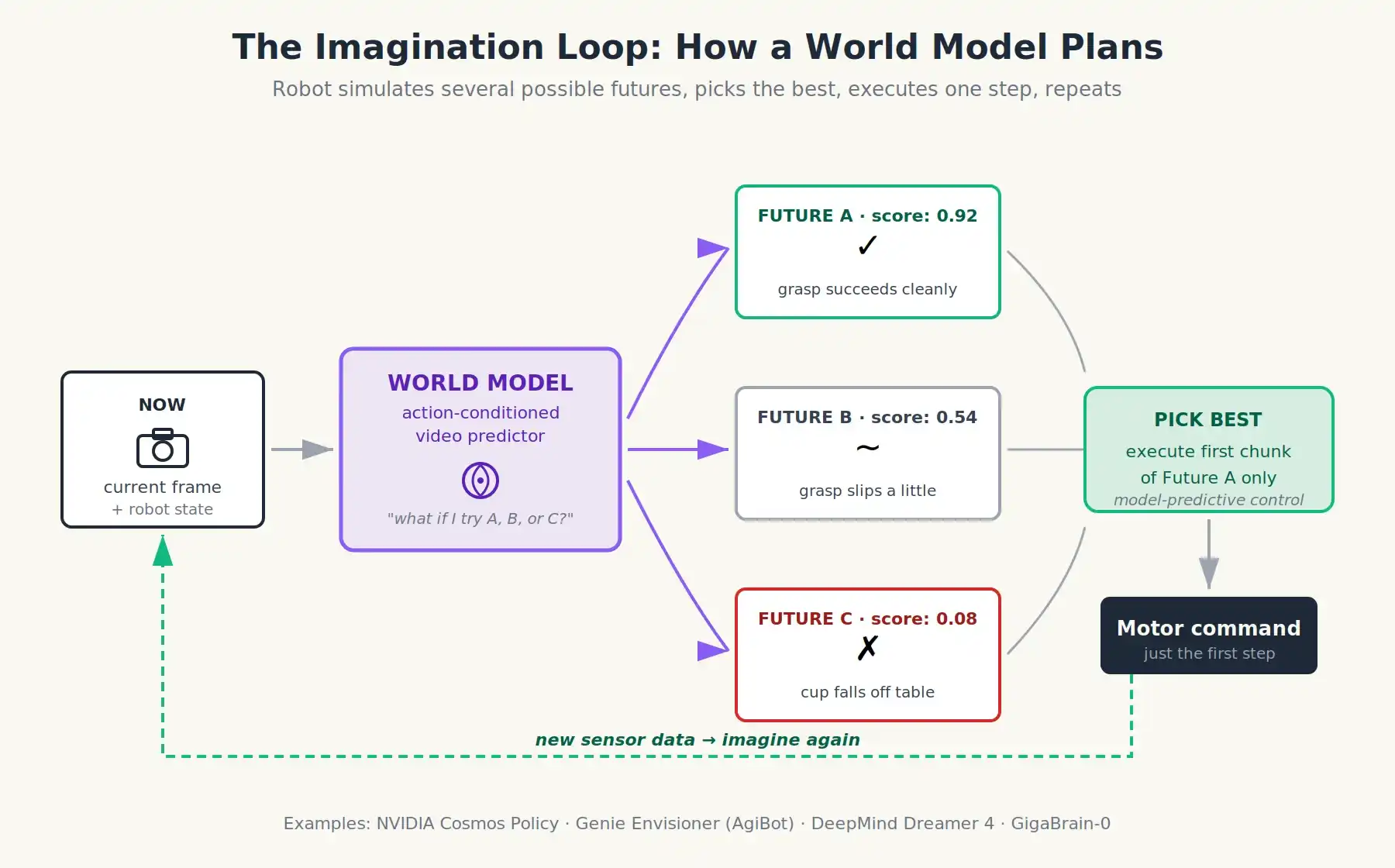
Model dunia memungkinkan robot untuk mensimulasikan beberapa skenario masa depan yang mungkin, menilainya, dan memilih yang terbaik sebelum motor apa pun dihidupkan
Seperti apa model dunia tahun 2026?
Saat ini, model dunia yang paling canggih bermacam-macam, tetapi berkembang dengan cepat. Berikut adalah beberapa model:
- NVIDIA Cosmos: Serangkaian model dasar dunia terbuka, termasuk Cosmos Predict 2.5 (model generatif), Cosmos Transfer 2.5 (model simulasi terkendali), Cosmos Reason 2 (penalar bahasa-visual untuk robotika) dan yang terbaru Cosmos Policy. Cosmos Policy melangkah lebih jauh, dengan melatih model dunia lebih lanjut untuk langsung mengeluarkan tindakan untuk kontrol. Cosmos dilatih menggunakan data video ribuan jam GPU (Cosmos Predict 2.5 adalah model dunia dalam seri ini).
- DeepMind Genie 3: Model dunia interaktif yang dapat menghasilkan lingkungan yang sepenuhnya dapat dinavigasi berdasarkan petunjuk teks, dengan kecepatan frame 24 fps, dan dapat berjalan stabil selama beberapa menit. Awalnya dirancang untuk lingkungan permainan.
- Meta V-JEPA 2: Pra-dilatih dengan lebih dari satu juta jam video web, kemudian dikondisikan dengan aksi menggunakan hanya 62 jam video robot. Pada lengan robot nyata di lab yang berbeda, tanpa pelatihan tugas spesifik apa pun, mencapai tingkat keberhasilan 80% dalam pengambilan dan penempatan nol-sampel. Pendekatan "JEPA" secara arsitektural sangat berbeda dari yang lain.
- DeepMind Dreamer 4: Hanya menggunakan data offline, tanpa interaksi lingkungan apa pun, belajar mengumpulkan berlian di Minecraft (tugas 20.000 langkah). Ini membuktikan bahwa pembelajaran penguatan yang sebenarnya di dunia virtual adalah mungkin.
- Genie Envisioner dari AgiBot: Platform model dunia terpadu dari Tiongkok, dilatih dengan lebih dari 3000 jam video operasi robot humanoid dunia nyata. Ia dapat menghasilkan lintasan prediksi yang dikembangkan, atau menghasilkan lintasan aksi yang dapat dieksekusi. AgiBot menggunakan NVIDIA Cosmos Predict 2 sebagai jaringan tulang punggung, dan melatihnya lebih lanjut dengan datanya sendiri. Inilah pola "stack teknologi sumber terbuka + data sendiri" yang dijelaskan sebelumnya.
- Model dunia berbasis Cosmos dari Toyota Research Institute: Untuk peningkatan data operasi jarak jauh dan navigasi.
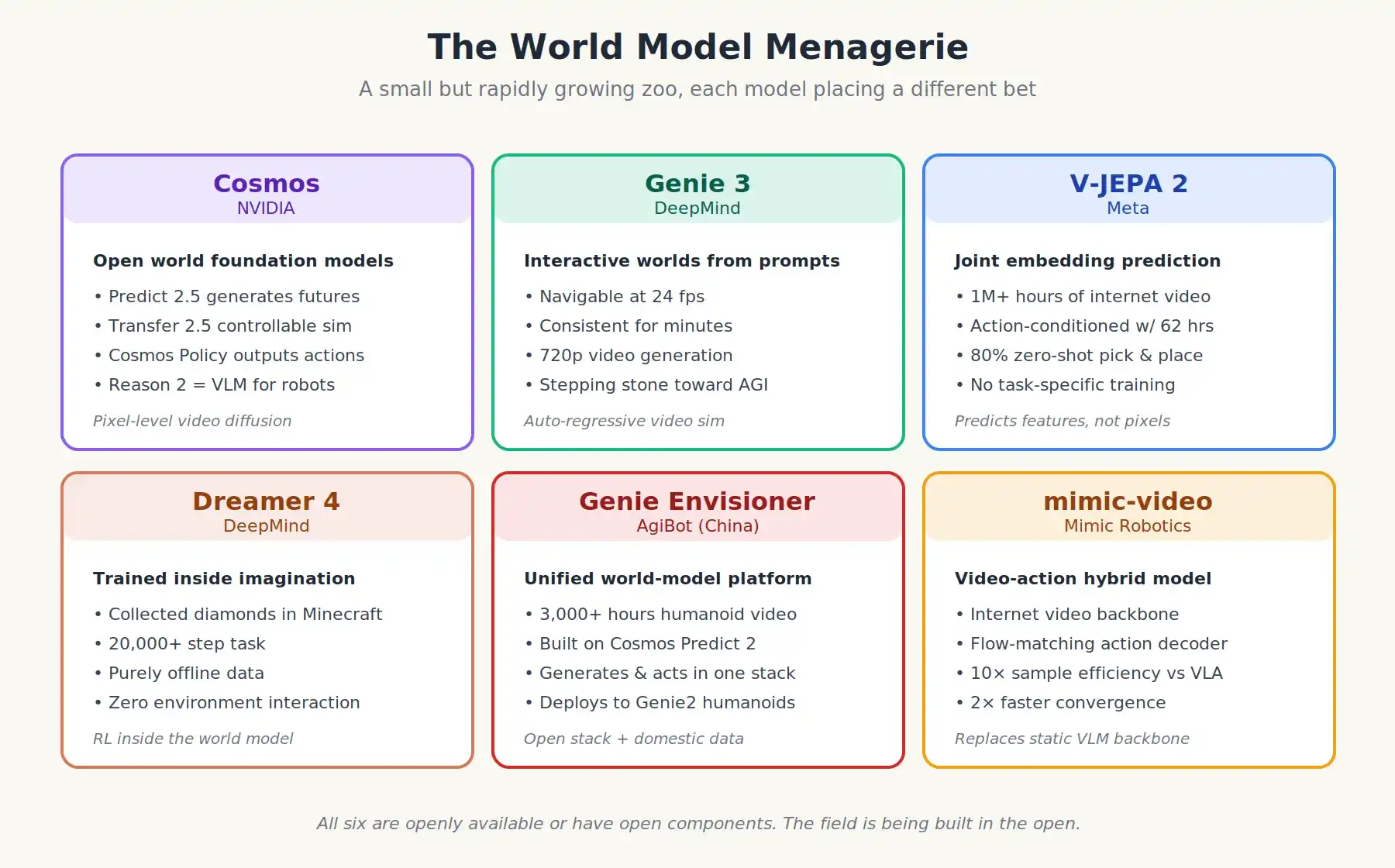
Enam model dunia terpenting 2025-2026, masing-masing mengusulkan visi berbeda tentang bagaimana mesin harus mempelajari fisika.
Sepuluh: Arsitektur Alternatif, Karena Bidang Ini Belum Final
Tidak ada satu cara standar untuk membangun model dunia. Pertarungan arsitektur adalah salah satu perdebatan paling menarik di bidang AI saat ini, yang secara langsung mempengaruhi apa yang dapat dilakukan robot di masa depan. Tiga kubu berikut perlu diperhatikan:
Difusi video tingkat piksel (Sekolah Cosmos/Sora): Menggunakan model difusi untuk memprediksi piksel aktual dari frame masa depan. Keuntungannya adalah dapat berfungsi sebagai generator data sintetis, dapat merender demonstrasi robot baru yang belum pernah terjadi. Kerugiannya adalah mahal, terkadang melanggar hukum fisika, dan memprediksi piksel yang tidak akan pernah dilihat adalah pemborosan.
Arsitektur Prediksi Penyematan Bersama, disingkat JEPA (Sekolah LeCun): Tidak memprediksi piksel, tetapi memprediksi representasi abstrak dari frame berikutnya. Membuang detail tekstur, hanya menyimpan esensi semantik dari hal-hal dalam adegan. Keuntungannya adalah efisien, fokus pada faktor-faktor yang penting untuk tindakan. Kerugiannya adalah lebih sulit digunakan. V-JEPA, V-JEPA 2 dan model hybrid JEPA-VLA baru sedang mengeksplorasi area ini.
Model dunia aksi laten (Aliran Genie/Dreamer): Mempelajari cara mengompres seluruh video ke dalam "bahasa aksi" laten yang menangkap struktur perilaku, kemudian melatih model dunia untuk memprediksi keadaan laten berikutnya berdasarkan aksi laten berikutnya. Keuntungannya adalah memungkinkan Anda melatih dengan video web tanpa aksi, lalu menambahkan sedikit data robot nyata. Kerugiannya adalah aksi laten tidak dapat dipahami manusia, membuat analisis keamanan menjadi kompleks.

Difusi piksel, JEPA, dan aksi laten: Tujuan sama, cara membangun model dunia sangat berbeda
Sebelas: Aplikasi Praktis Robot Berbasis Model Dunia
Jika kita maju beberapa tahun, arsitektur robot humanoid mutakhir mungkin terlihat seperti ini:
Sebuah VLA yang dilengkapi dengan model dunia. Ketika robot menghadapi situasi baru, dia akan melakukan operasi seperti berikut:
- VLA mengusulkan beberapa kandidat tindak lanjut (dia masih kebijakan).
- Model dunia akan mengambil setiap kandidat aksi, dan mensimulasikan video imajiner 1-3 detik.
- Penilai nilai akan menilai berdasarkan hasil yang dibayangkan: apakah cangkir telah diambil? Apakah ada sesuatu yang jatuh? Apakah ada orang yang tertabrak?
- Robot akan memilih tindakan dengan skor tertinggi, dan hanya menjalankan bagian pertamanya.
- Data sensor nyata mengalir kembali; siklus berulang.
Ini adalah kontrol prediktif model, teknik yang telah digunakan selama bertahun-tahun untuk menstabilkan roket dan quadcopter, tetapi menggantikan persamaan fisika turunan manual dengan model dunia yang dipelajari. Skalabilitasnya terletak pada fakta bahwa model dunia dilatih sebelumnya berdasarkan jutaan jam video, bukan karena seseorang menulis persamaan Navier-Stokes untuk lingkungan dapur.
Manfaatnya bertambah lapis demi lapis:
- Pemulihan yang lebih baik. Jika tindakan meraih gagal, model dunia dapat membayangkan berbagai jalur korektif, dan memilih yang paling menjanjikan.
- Generalisasi yang meningkat. Model dunia yang dilatih dengan video web mengalami "fenomena fisik" beberapa tingkat besarnya lebih banyak daripada dataset operasi jarak jauh robot mana pun.
- Perencanaan jangka panjang menjadi dapat dikendalikan. Merencanakan dalam imajinasi, bukan dalam kenyataan.
- Kesenjangan antara simulasi dan realitas menyempit. Sebelumnya perlu melatih dengan simulator yang dibangun sendiri (misalnya Isaac Sim, mesin fisika Newton) dan berharap hasil pelatihan dapat ditransfer, sekarang dapat melatih dengan simulator yang telah dilatih untuk mencocokkan video nyata. Jadi kesenjangannya lebih kecil.
- Ledakan data sintetis. Sebuah model dunia hampir dapat secara gratis menghasilkan jutaan lintasan robot yang berbeda, mencakup konfigurasi pencahayaan, material, dan objek yang berbeda. Ini memecahkan hambatan terbesar di bidang ini.
Selain itu, ia memiliki keunggulan keamanan yang penting. Robot yang dapat mensimulasikan konsekuensi tindakan dapat menolak melakukan operasi berbahaya: bukan karena aturan yang telah ditetapkan, tetapi karena mengantisipasi bahwa mungkin ada orang yang terluka di masa depan.
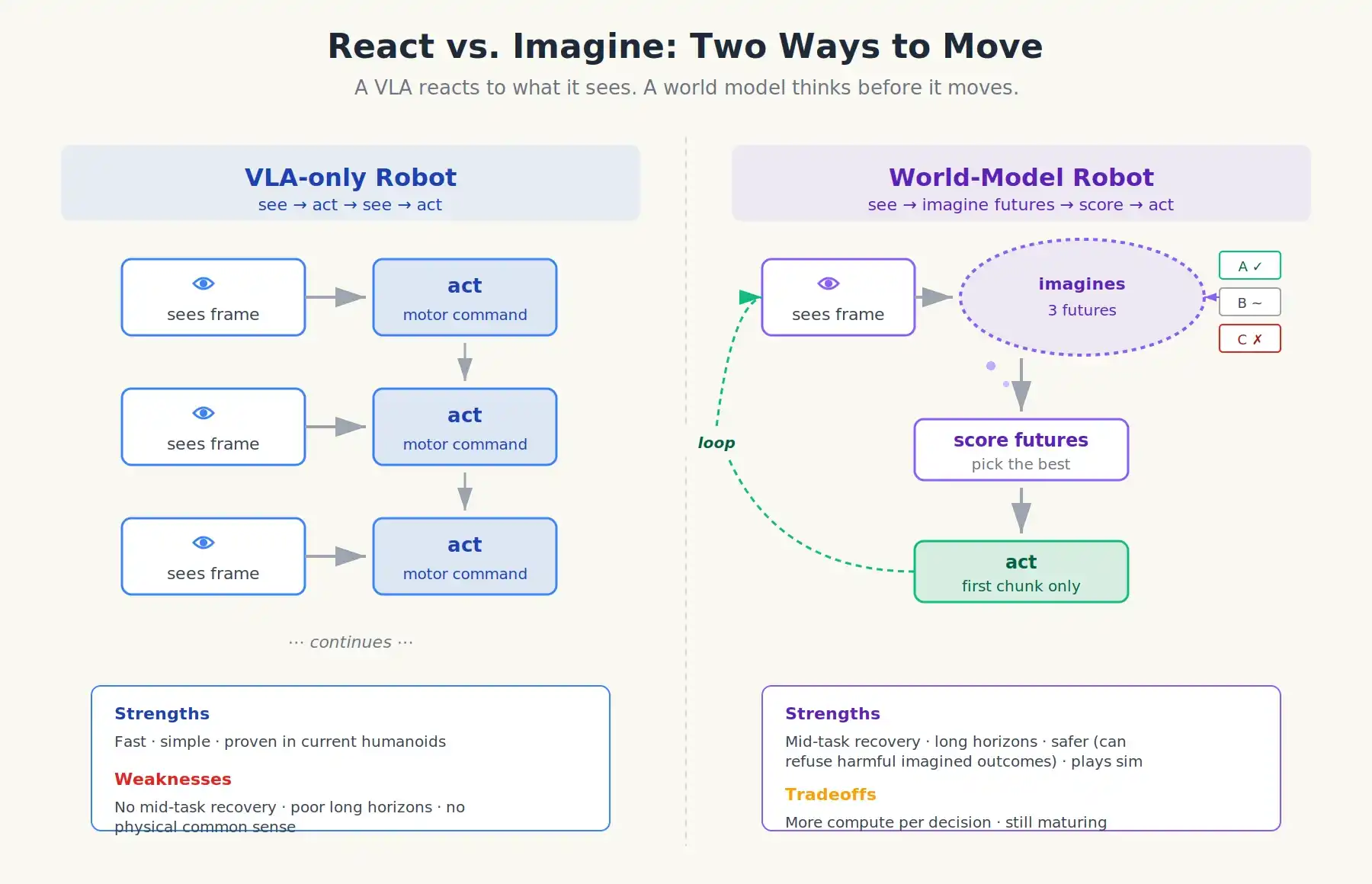
Dua cara bergerak: VLA bereaksi terhadap apa yang dilihat; robot model dunia berpikir sebelum bergerak
Dua Belas: Hal Lain yang Perlu Diketahui
Masalah Data adalah Inti Sebenarnya: Jika Anda tidak dapat memberi makan data ke model, semua inovasi arsitektur di dunia tidak akan berguna. Saat ini, operasi jarak jauh (manusia mengenakan perangkat VR untuk mengendalikan robot seperti wayang dari jarak jauh) adalah hambatan teknologi utama. Parit kompetitif perusahaan robotika semakin tergantung pada pipa pengumpulan datanya, bukan pada model itu sendiri. AgiBot telah membangun gudang yang dipenuhi operator. Hukum penskalaan ketangkasan NVIDIA GR00T N1.7 menunjukkan bahwa lebih banyak video perspektif orang pertama manusia secara langsung dan dapat diprediksi meningkatkan ketangkasan robot. Ini juga bagian di mana Tiongkok memiliki keunggulan struktural: biaya tenaga kerja pengumpulan data yang lebih rendah, lingkungan penerapan yang lebih toleran, dan negara yang secara aktif mengoordinasikan rantai pasokan.
Simulasi adalah Alam Semesta Paralel. NVIDIA Isaac Sim, mesin fisika Newton sumber terbuka baru (versi 1.0 akan dirilis secara resmi April 2026) dan platform Omniverse, memungkinkan perusahaan melatih robot dalam jutaan lingkungan simulasi paralel tanpa perlu menerapkannya di dunia nyata. Sebagian besar fungsi yang tampak seperti "kecerdasan robot" sebenarnya dibesarkan dalam simulasi, kemudian dipindahkan ke perangkat keras.
Ekonomi Mulai Tampak. Unitree mengirimkan sekitar 5500 robot humanoid pada 2025, dan berencana mencapai 10.000 hingga 20.000 pada 2026. Harga rata-rata turun dari $85.000 menjadi $25.000 dalam dua tahun. R1 Unitree dijual seharga $5.900. Noetix Bumi diluncurkan dengan harga $1.400. Harga perangkat keras robot humanoid sedang mendekati tingkat harga elektronik konsumen, sementara teknologi AI di dalamnya masih tertinggal dari produk demo. Kesenjangan ini pada akhirnya akan menyusut, dan ketika itu terjadi, peningkatan skala pasar akan berdampak signifikan pada seluruh industri.
Mode Kegagalan Terlihat Aneh. Ketika robot berbasis LLM gagal, cara kegagalan mereka seringkali tidak dapat dilakukan oleh robot tradisional. Misalnya, melakukan hal yang salah dengan percaya diri, mempersepsikan beberapa fungsi dengan "halusinasi", terjebak dalam loop percakapan dengan perencananya sendiri. Komunitas robotika tradisional cukup skeptis tentang hal ini, dengan alasan yang masuk akal, mereka bersikeras bahwa sistem pembelajaran harus diawasi keamanan dan dibatasi perilakunya. Robot yang paling andal yang saat ini digunakan adalah hybrid: otak VLA ditempatkan di dalam kandang keamanan yang dirancang secara manual.
Narasi "Momen ChatGPT" adalah Metafora yang Berguna tetapi Menyesatkan: Jensen Huang terus memberitahu semua orang bahwa momen ChatGPT untuk robot telah tiba. Dia mengatakan ini karena NVIDIA menjual sekop dan pacul. Versi yang lebih jujur adalah: Sekitar Era GPT-2 untuk AI Fisik saat ini. Dia kuat, dapat membuat Anda kagum; tetapi belum cukup kuat untuk dikerahkan tanpa pengawasan. Dia beriterasi dengan cepat, tetapi belum mencapai titik ledakan penyebaran virus, melainkan lintasan naik yang lambat dan pasti.
Kesimpulan

Evolusi robot berkaki empat Unitree (dari kanan ke kiri)
Dalam demo yang dilihat di kantor Unitree, lima robot humanoid G1 melakukan seni bela diri, gerakannya dikoreografikan dengan hati-hati, pengontrol gaya VLA onboard melakukan penyesuaian halus, operator jarak jauh memastikan semuanya berjalan lancar. Pada dasarnya, itu tidak sepenuhnya otonom. Tetapi keseluruhan alur: persepsi, perencanaan, kontrol gerak, sedang digantikan oleh jaringan saraf. Dua tahun kemudian, robot yang sama dapat melakukan gerakan yang sama tanpa koreografi, karena dia telah mengonsepkan seluruh gerakan sebelumnya, dan memilih versi terbaik.
Seluruh evolusi yang dijelaskan dalam artikel ini: dari pengontrol yang ditulis tangan, ke persepsi pembelajaran mesin, ke perencana LLM, ke VLA, ke arsitektur sistem ganda, akhirnya ke model dunia, sebenarnya adalah pergeseran lambat dari letak kecerdasan robot. Ini dimulai dari pikiran insinyur, kemudian berevolusi menjadi kode yang ditulis tangan, kemudian memasuki lapisan persepsi, memasuki perencana, memasuki lapisan kebijakan. Dan sekarang, akhirnya berkembang menuju model yang mempelajari dunia itu sendiri.
Setiap pergeseran membuat robot lebih universal, lebih adaptif, lebih berguna. Jika pergeseran model dunia berhasil, itu akan benar-benar memberdayakan robot: cukup kuat untuk membuat pertanyaannya bukan lagi "Apa yang bisa dilakukan robot?", tetapi "Apa yang seharusnya kita perintahkan mereka lakukan?"
Bacaan terkait: Tinjauan lebih dari 30 perusahaan robot humanoid: Siapa yang akan menang pada tahun 2026?