- Трейдер потерял $1,76 млн из-за мемкоина LIBRA.
- Ранее ему удалось заработать более $7,3 млн благодаря инвестициям в токен TRUMP.
Неизвестный трейдер понес потери в размере $1,76 млн на инвестициях в мемкоин LIBRA, который продвигал президент Аргентины Хавьер Милей. Об этом сообщили в аналитической компании Lookonchain.
TRUMP made this guy a profit of $7.32M, but MELANIA caused him to lose $617K, and LIBRA caused him to lose another $1.76M!
— Lookonchain (@lookonchain) February 18, 2025
This guy has lost twice on $LIBRA.
3 days ago, he spent $1.7M to buy $LIBRA and sold for $136K, losing $1.56M.
After Javier Milei (@JMilei) retweeted a… pic.twitter.com/LvAckm03Hi
Эксперты подчеркнули, что инвестору удалось заработать $7,32 млн на мемкоине Дональда Трампа, однако он потерял $617 000 на инвестициях в MELANIA.
Что касается LIBRA. Сначала трейдер потратил $1,7 млн на покупку LIBRA, а продал активы по цене за $136 000, потеряв $1,56 млн. После того как Хавьер Милей «ретвитнул» пост о покупке LIBRA, он снова инвестировал $300 000 и потерял еще $200 000.
На момент написания мемкоин торгуется ниже отметки в $0,32:
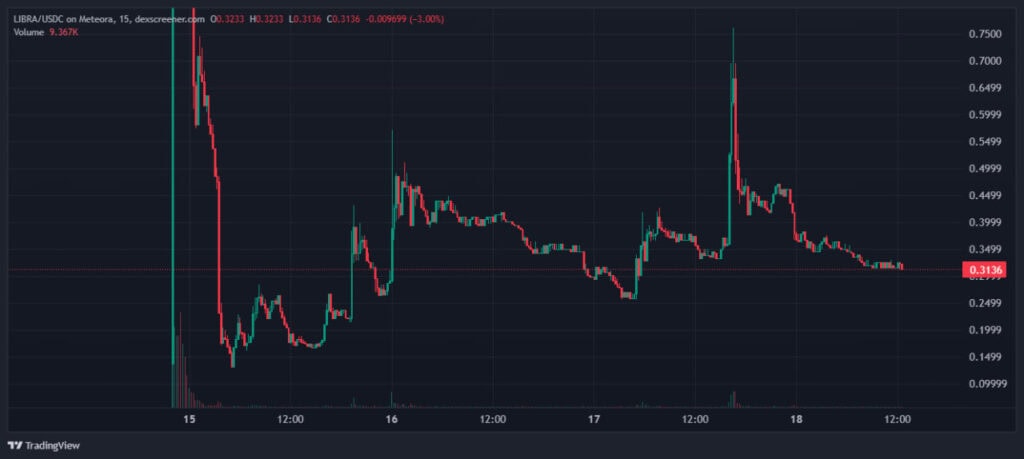
Напомним, мемкоин LIBRA запустили 14 февраля 2025 года, тогда его поддержал президент Аргентины. Впрочем, через несколько часов после запуска курс токена обвалился на 99%. Подробнее об афере читайте в материале:
Отметим, у Incrypted есть Telegram-канал о мемкоинах. Чтобы быть в курсе самых актуальных событий в этой сфере, подписывайтесь на MEMEcrypted.