Article | AIDeepDive
Aujourd'hui, le titre de "première action mondiale de grand modèle linguistique", Zhipu (02513.HK), a de nouveau connu une envolée.
Les gains en séance ont brièvement dépassé les 30%. Il a clôturé à 1 282 dollars de Hong Kong, affichant une hausse de plus de 26% sur la journée, pour une capitalisation boursière atteignant 571,57 milliards de dollars de Hong Kong, établissant un nouveau record historique.
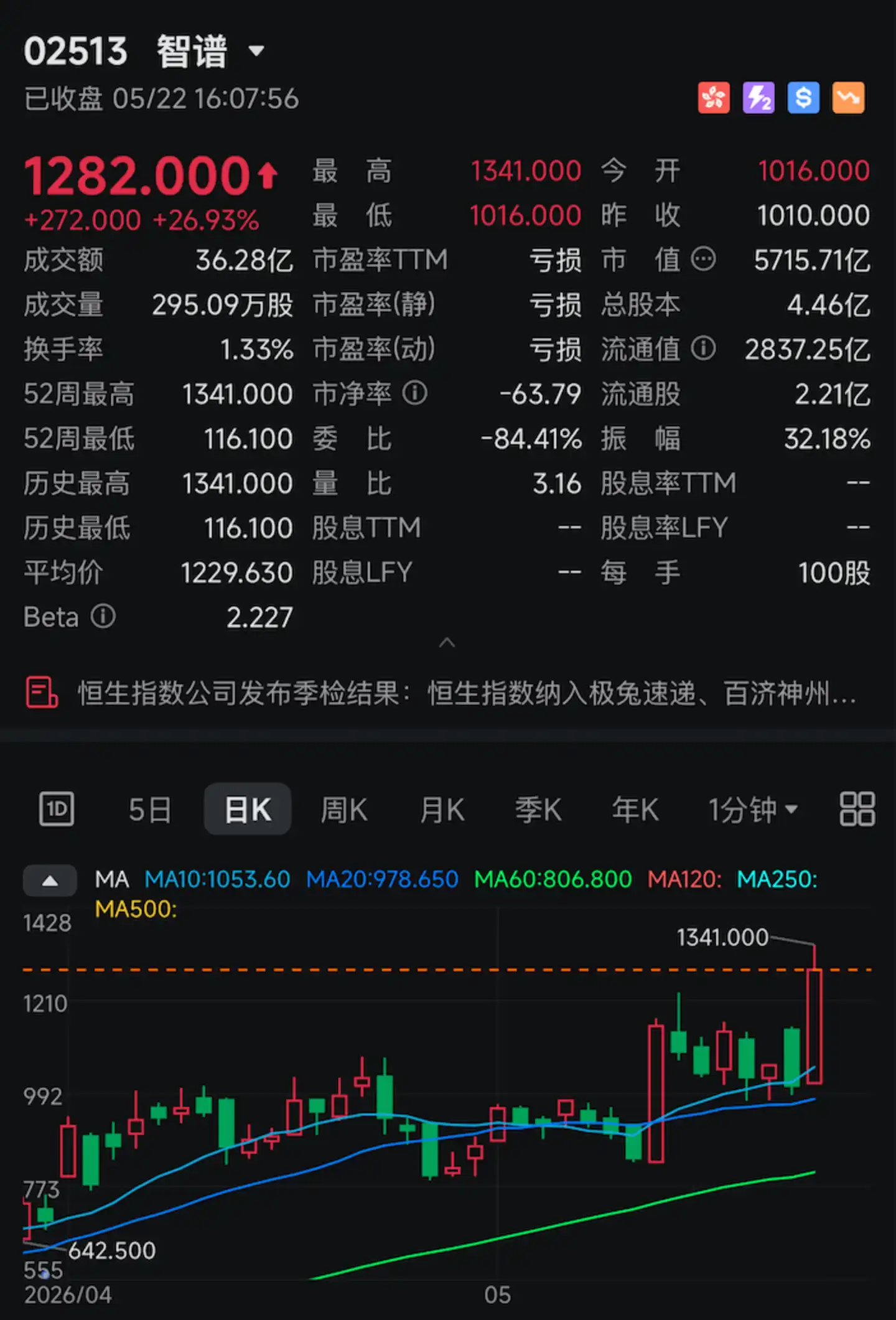
Ce qui a déclenché cette flambée, c'est un indicateur technique précis : 400 tokens/s.
Le 22 mai, Zhipu a officiellement ouvert aux clients entreprises l'API version haute vitesse de GLM-5.1 (GLM-5.1-highspeed). Le paramètre clé le plus crucial est unique : la vitesse de génération du modèle atteint 400 tokens par seconde, repoussant la limite supérieure de vitesse des API des principaux fournisseurs de grands modèles linguistiques dans le monde.
Je pensais initialement qu'il s'agissait encore d'une opération de relations publiques pour les grands modèles linguistiques chinois, mais après avoir examiné les détails techniques, j'ai fini par comprendre la logique sous-jacente des marchés financiers.
Que représente 400 tokens/s ?
Cela signifie que le modèle peut générer environ 200 caractères chinois par seconde, ce qui équivaut à la production intensive d'une minute d'un écrivain professionnel, compressée en une seule seconde.
La quantité de texte qu'un créateur peut produire après plusieurs jours de travail acharné, GLM-5.1 haute vitesse peut la livrer en 1 minute ; une tâche de refonte système qu'un ingénieur peut accomplir en 3 jours de travail concentré, elle peut l'exécuter pendant le temps de boire un café.
01 La vitesse, plus importante qu'on ne le pense
La vitesse a toujours été la dimension la plus négligée dans la compétition des modèles d'IA.
Au cours des trois dernières années, la course aux armements des grands modèles s'est concentrée sur deux axes : l'échelle des paramètres (des modèles plus grands et plus intelligents) et la guerre des prix (des Tokens moins chers et plus accessibles). La "rapidité" n'a jamais été le protagoniste.
Parce qu'auparavant, la "rapidité" était généralement obtenue en réduisant la taille des paramètres du modèle. Pour accélérer, il fallait utiliser un modèle plus petit et plus léger, au prix d'une perte de capacités.
La signification de cette version haute vitesse de GLM-5.1 réside dans le fait qu'elle préserve les capacités complètes de la base de taille normale phare, tout en poussant la vitesse à 400 tokens/s.
Que ce soit pour les modèles chinois ou à l'échelle internationale, c'est la première fois que "capacités phares" et "latence extrêmement basse" sont atteintes sans compromis.

Pourquoi la vitesse est-elle si cruciale ? Parce que le champ de bataille principal de l'IA est en train de migrer fondamentalement.
Lorsque l'IA passe de l'ère du ChatBot à celle des Agents, les questions-réponses ne sont plus le scénario principal de l'IA. Pour accomplir une tâche, un Agent a souvent besoin que le modèle s'appelle lui-même des dizaines, voire des centaines de fois : écrire du code, appeler des interfaces, rechercher des informations, utiliser des outils...
Dans ce mode de travail, les délais entre chaque appel s'accumulent et s'amplifient impitoyablement. Pour une tâche nécessitant 50 appels, si on économise 1 seconde à chaque fois, la tâche entière est terminée près d'une minute plus tôt. Pour les assistants de programmation IA, les interactions vocales, les systèmes d'aide à la décision commerciale, cet écart peut être une question de vie ou de mort.
À un niveau plus profond, dans un budget temps fixe, une inférence plus rapide signifie que le modèle peut accomplir des chemins de raisonnement plus profonds, et plus de cycles d'auto-vérification. La vitesse est en train de passer d'un indicateur système à une limite intrinsèque de l'intelligence.
02 À quel point est-ce difficile d'atteindre une telle vitesse ?
Alors, quel est approximativement le niveau actuel de l'industrie en matière de vitesse ?
Parmi les principaux acteurs, GPT-4o d'OpenAI se situe autour de 100–150 tokens/s, la série Claude Sonnet d'Anthropic autour de 80–120 tokens/s, et les API des principaux modèles phares chinois se situent majoritairement dans la fourchette de 50–100 tokens/s. 400 tokens/s représente environ 3 à 5 fois la moyenne du secteur.
Plus crucial encore, cet écart ne peut pas être comblé simplement en injectant plus de puissance de calcul.
Un serveur équipé de 8 cartes graphiques H200 peut théoriquement transférer jusqu'à 38 To de données par seconde. Pour GLM-5.1, la génération d'un seul token ne nécessite de lire qu'environ 42 Go de paramètres d'activation. En théorie pure, on devrait pouvoir approcher les 1000 tokens/s.
Mais dans la réalité, les systèmes existants atteignent souvent seulement quelques dizaines de tokens/s.
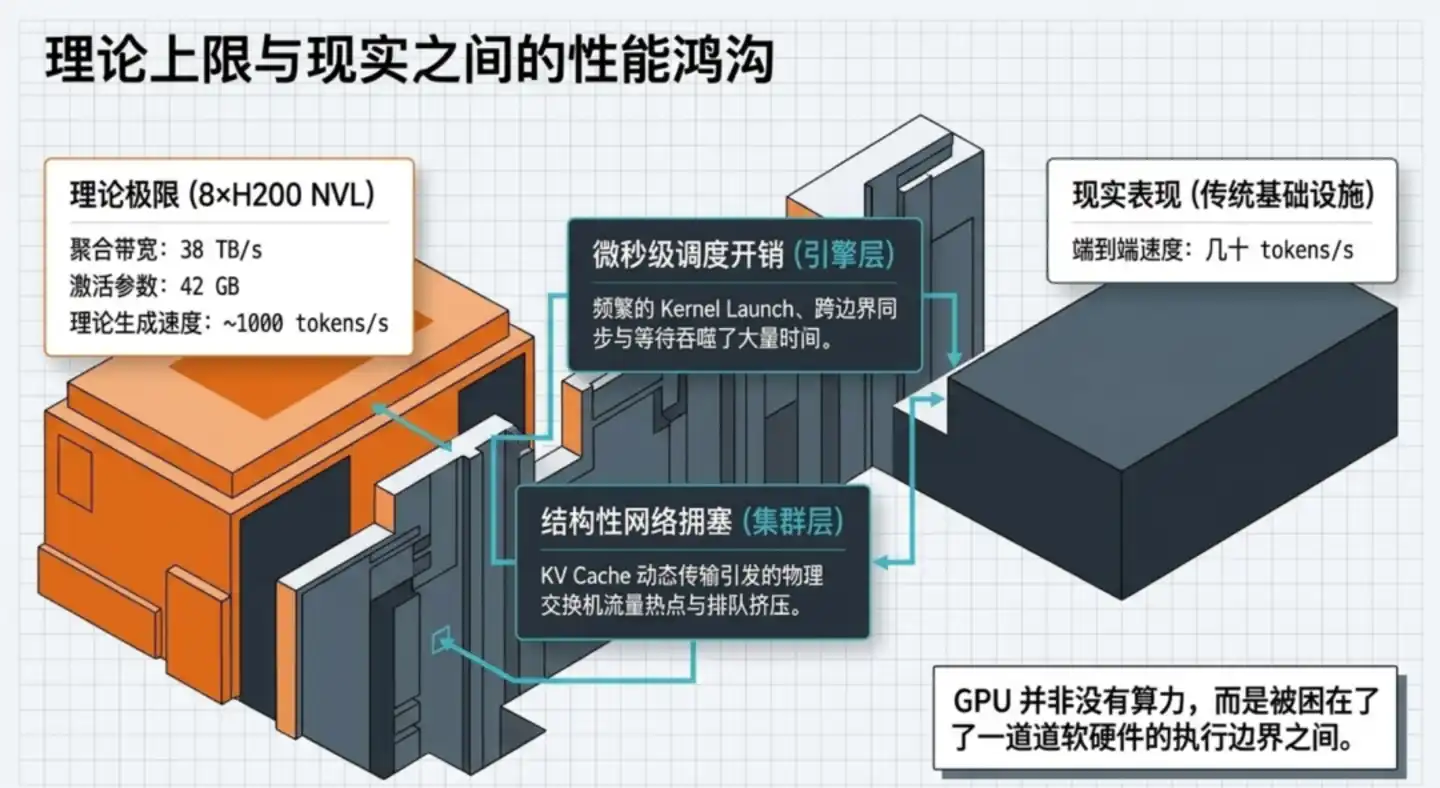
C'est un gouffre d'un ordre de grandeur. Les GPU ne sont pas trop lents, mais une grande partie du temps est gaspillée dans l'attente, l'inactivité et la planification inefficace.
Cette fois-ci, Zhipu a justement innové simultanément sur trois niveaux : le moteur d'inférence, les stratégies de parallélisation et l'architecture réseau, pour réaliser une percée sur la vitesse finale.
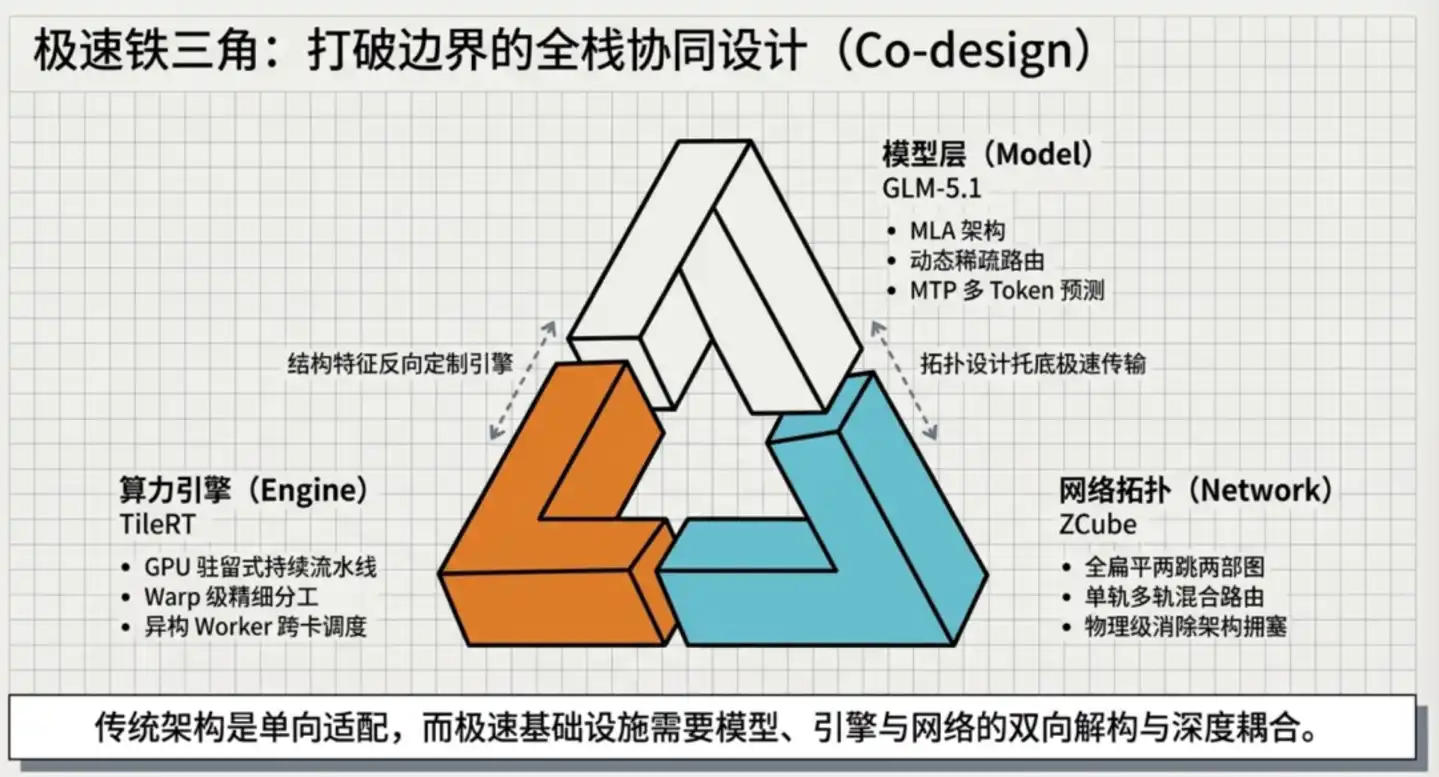
03 Superposition de trois couches technologiques, approchant les limites physiques du matériel
Auparavant, les grands modèles fonctionnaient ainsi : le grand modèle était décomposé en opérateurs indépendants, chaque opérateur lançait un noyau de calcul (kernel) séparément, s'arrêtait après calcul, attendait la synchronisation, puis lançait le suivant.
Pendant la phase d'entraînement, chaque calcul prenait plusieurs secondes, voire plusieurs minutes, ces coûts de lancement et d'attente étaient parfaitement négligeables. Mais lors de l'inférence, la génération d'un seul token, une étape clé peut ne nécessiter que quelques dizaines de microsecondes, les coûts de lancement et d'attente deviennent alors relativement non négligeables.
L'idée centrale de TileRT : compiler l'ensemble du modèle en un moteur fonctionnant en continu, lancé une fois, sans jamais s'arrêter.
TileRT déploie statiquement à l'avance, lors de la phase de compilation du code, toute la logique de calcul du modèle en un pipeline continu. Pendant l'exécution, le GPU maintient constamment un fonctionnement à grande vitesse, les calculs, le transfert de données et la communication avancent en parallèle, les résultats intermédiaires restent autant que possible dans le cache haute vitesse interne du GPU, sans être réécrits de manière répétée dans la mémoire vidéo lente puis relus.
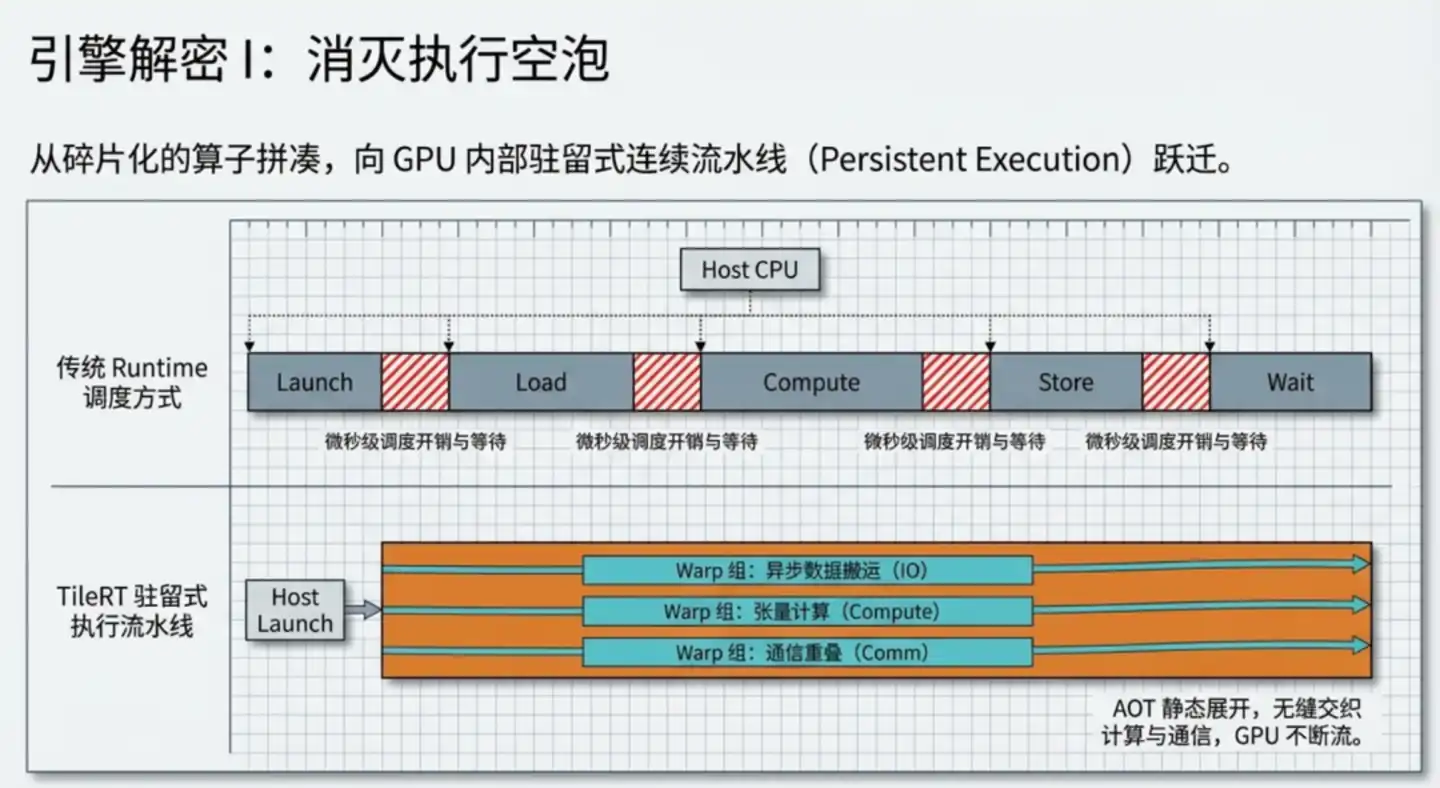
Il y a un détail de conception clé ici : la spécialisation des Warps.
Pour comprendre les Warps, il faut d'abord comprendre le mode de fonctionnement des GPU. La plus grande différence entre un GPU et un CPU est que le GPU dispose de milliers d'unités de calcul relativement simples en son sein. Ces unités sont regroupées par lots de 32, ce groupe s'appelle un Warp.
Les 32 unités d'un même Warp doivent toujours agir de manière synchronisée, exécuter la même instruction, comme une escouade dans l'armée, où le chef donne l'ordre à tout le monde de faire le même mouvement en même temps.
Dans les frameworks traditionnels, tous les Warps exécutent la même séquence d'instructions ; TileRT fait assumer des responsabilités différentes à différents groupes de Warps : une partie est spécialement chargée de transférer à l'avance le prochain lot de données, une autre partie est spécialement chargée des calculs mathématiques, une autre partie est spécialement chargée de la communication avec d'autres GPU. Les trois groupes travaillent simultanément, en coordination fluide, sans s'attendre mutuellement.
C'est comme passer d'"un ouvrier transportant les briques, les posant, vérifiant en série" à "un groupe transportant les briques, un groupe les posant, un groupe vérifiant, tous tournant en même temps".
Une fois l'efficacité interne d'une seule carte résolue, le parallélisme multi-cartes présente de nouveaux défis.
La pratique courante dans l'industrie est le parallélisme tensoriel (Tensor Parallel) : Diviser la matrice des poids du modèle en plusieurs parts, chaque GPU étant responsable d'une part, calculant séparément, puis rassemblant les résultats via une interconnexion haute vitesse (NVLink).
Cette solution fonctionne très bien pour des calculs denses et réguliers comme la multiplication matricielle, c'est actuellement la solution multi-cartes standard pour presque tous les frameworks d'inférence de grands modèles.
GLM-5.1 utilise **MLA (Multi-head Latent Attention, attention potentielle à plusieurs têtes), un mécanisme d'attention proposé par DeepSeek.
Les mécanismes d'attention traditionnels nécessitent de sauvegarder intégralement de grandes quantités de données intermédiaires (KV Cache) générées à chaque étape pour une utilisation ultérieure, ce qui est très gourmand en mémoire vidéo. L'approche de MLA consiste d'abord à compresser ces données intermédiaires en un "vecteur latent" compact à stocker, puis à les décompresser et les restaurer lors de l'utilisation, réduisant considérablement les besoins en mémoire vidéo et améliorant l'efficacité de l'inférence.
Mais le flux de calcul de MLA comporte une étape particulière : il nécessite un indexation parcimonieuse parmi une grande quantité d'informations historiques : c'est un peu comme trouver rapidement les livres les plus pertinents dans une immense bibliothèque, puis les lire attentivement.
L'étape de "recherche des livres" dépend d'informations globales et ne se prête pas bien à une répartition multi-cartes ; la "lecture attentive" est le calcul dense adapté au parallélisme multi-cartes. Si on force les 8 GPU à participer tous à la "recherche des livres", beaucoup de temps sera gaspillé dans la communication de synchronisation entre les GPU.
La solution de TileRT est de faire fonctionner les GPU de manière hétérogène : le GPU 0 est spécialement désigné comme "bibliothécaire de recherche", responsable de l'indexation parcimonieuse et des décisions de routage ; les GPU 1–7 sont désignés comme "analystes lecteurs", responsables des calculs d'attention denses et des opérations matricielles. Les deux types de travailleurs collaborent en utilisant chacun la stratégie de parallélisation qui leur convient le mieux pour accomplir l'ensemble de la couche de calcul.
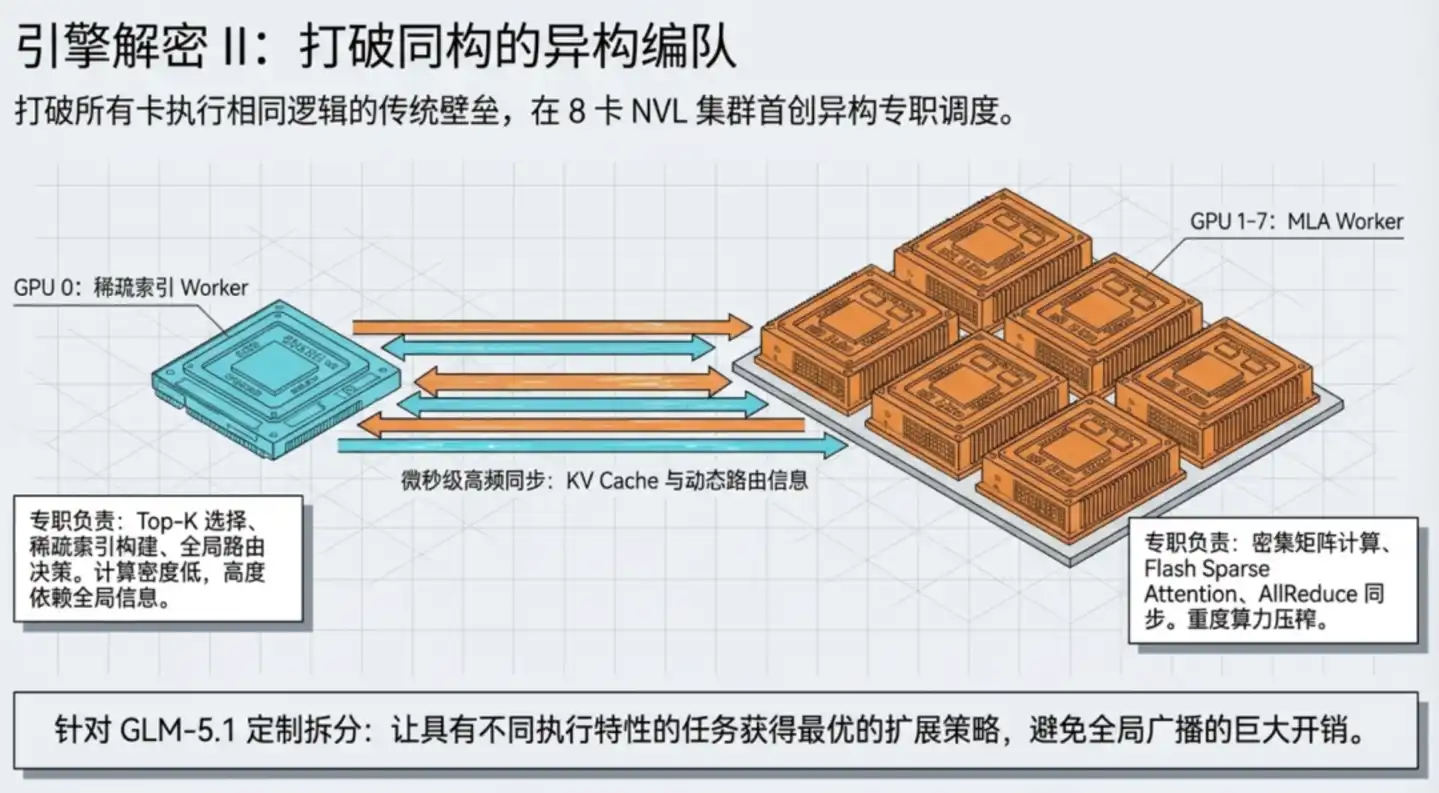
Ensuite, TileRT intègre également directement les opérations de communication entre GPU dans le pipeline d'exécution, ne les traitant plus comme des étapes indépendantes. Vu de l'extérieur, l'ensemble du système à 8 cartes n'a besoin de lancer qu'une seule fois un noyau pour accomplir une couche de calcul d'attention, toute la communication et les calculs internes étant achevés de manière transparente à l'intérieur du pipeline continu.
Les deux couches ci-dessus résolvent les problèmes au sein d'une seule machine. Lorsque le cluster s'étend à des centaines, voire des milliers de GPU, la transmission des données entre GPU devient elle-même le nouveau plafond.
La pratique courante dans l'industrie est ROFT (Rail-Optimized Fat-Tree), la solution recommandée officiellement par NVIDIA, le standard absolu du secteur.
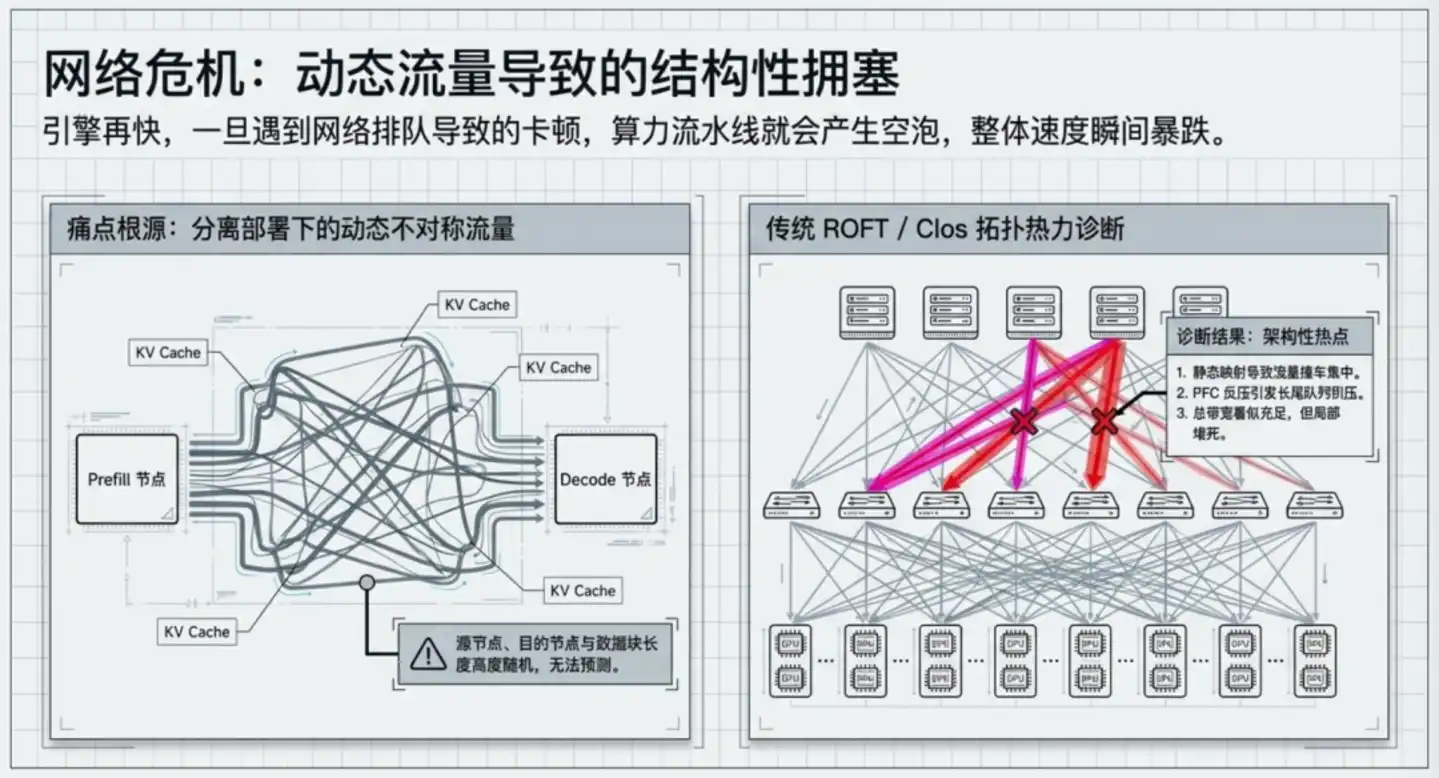
Sa structure est arborescente : les serveurs se connectent d'abord aux commutateurs de couche feuille (Leaf) (couche d'accès, directement face aux serveurs), les Leaf se connectent ensuite vers le haut aux commutateurs de couche épine (Spine) (couche dorsale, responsable de l'interconnexion entre différents Leaf, comme un carrefour d'autoroutes). Les données transmises entre deux GPU doivent "monter d'abord vers le Spine, puis redescendre vers le Leaf cible", passant par au moins 3 sauts.
Pour éviter que le trafic ne se concentre sur quelques liaisons, cette architecture s'appuie sur l'algorithme ECMP pour répartir les données entre plusieurs chemins, fonctionnant bien sous la prémisse d'un trafic Internet "statistiquement uniforme".
Mais le trafic des scénarios d'inférence est complètement inégal. Les longueurs de contexte des différentes requêtes peuvent varier de plusieurs dizaines de fois, la direction de transmission du KV Cache entre GPU est presque aléatoire, quelques commutateurs Leaf deviennent périodiquement des points chauds, déclenchant des mécanismes de backpressure, qui propagent la congestion d'une zone locale à l'ensemble des liaisons. Cette congestion ne peut pas être résolue en ajustant les paramètres de protocole, c'est un produit de la structure topologique elle-même.
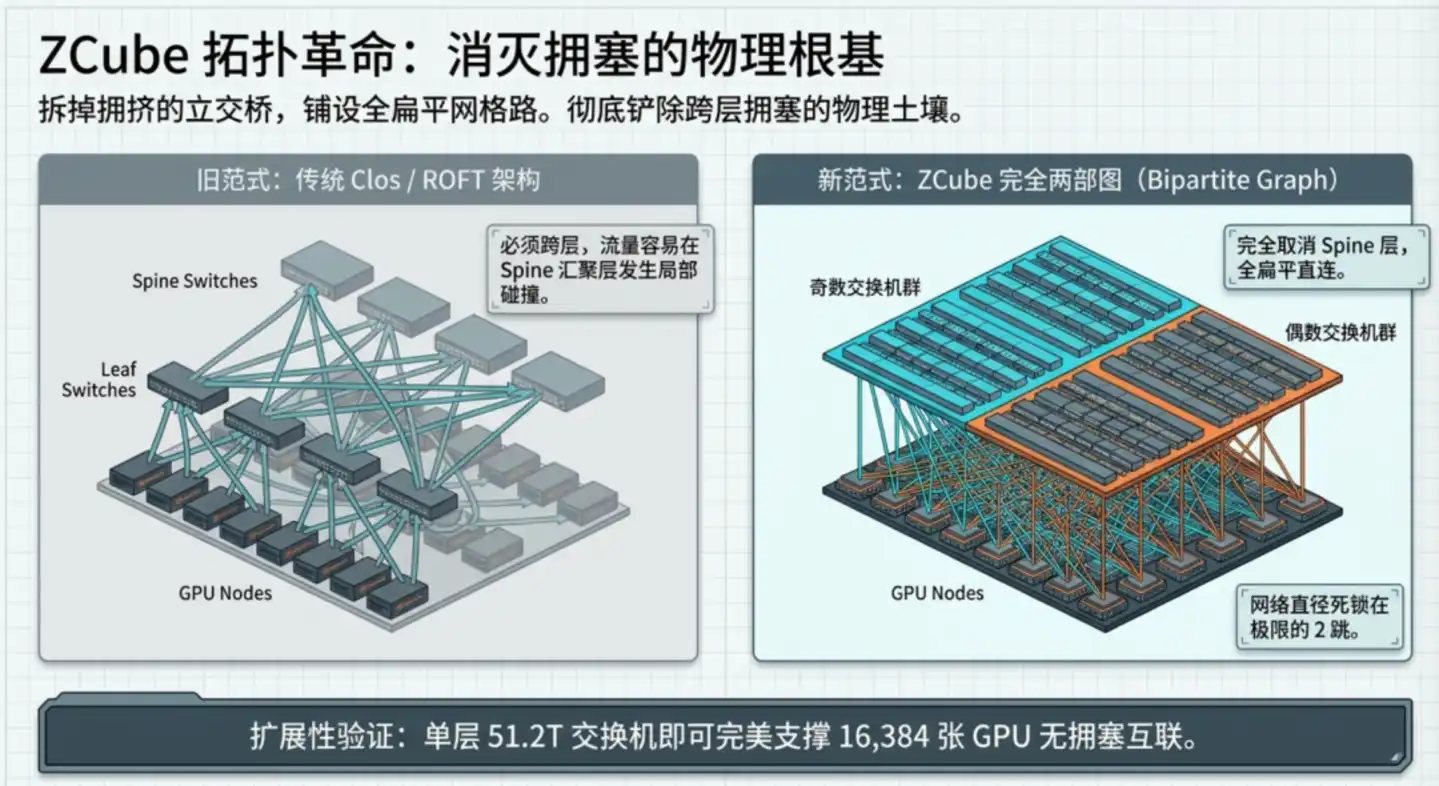
La percée fondamentale de ZCube : rendre ce type de congestion physiquement impossible au niveau de l'architecture.
La conception centrale se fait en deux étapes :
Première étape, supprimer la couche dorsale Spine, aplatir l'ensemble du réseau. Diviser tous les commutateurs Leaf en deux groupes selon leur numéro pair ou impair, les deux groupes étant entièrement interconnectés, tout commutateur impair se connectant à tous les commutateurs pairs, et vice versa. Entre deux GPU quelconques, il faut traverser au maximum deux commutateurs pour s'atteindre, réduisant les sauts de 3 à 2.
La deuxième étape, et la plus ingénieuse : chaque carte réseau GPU se connecte aux deux groupes de commutateurs de deux manières radicalement différentes. Cette topologie spéciale apporte une propriété mathématique clé : entre deux GPU quelconques dans l'ensemble du réseau, il existe une et une seule trajectoire optimale.
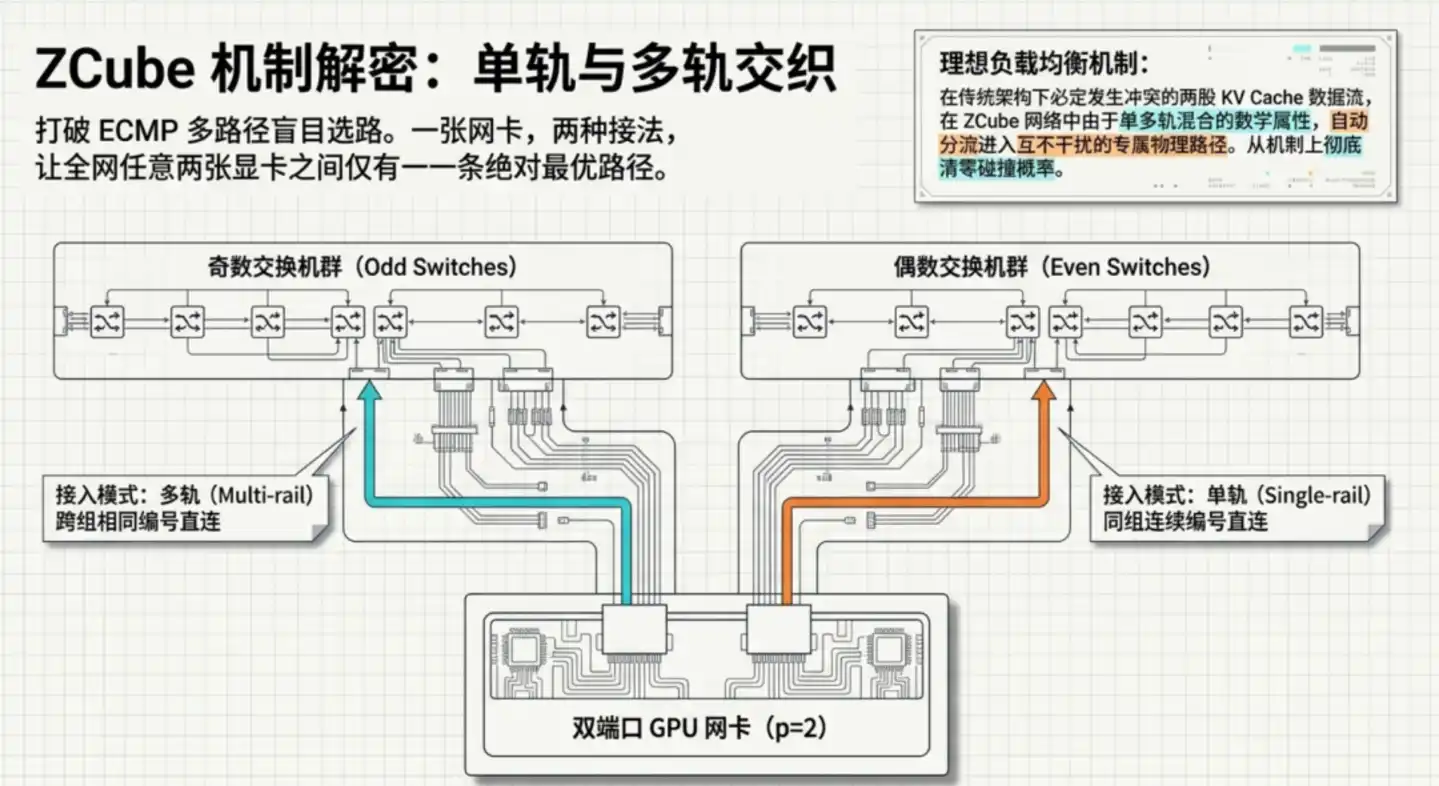
La "trajectoire unique" élimine directement la racine de la congestion. L'architecture traditionnelle génère facilement des points chauds précisément parce qu'il y a plusieurs chemins possibles, si l'algorithme d'équilibrage de charge choisit mal, cela entraîne une concentration du trafic. ZCube élimine au niveau de la conception le "choix" lui-même : pas besoin d'équilibrage, car il n'y a tout simplement pas d'embranchement.
04 Dans les mêmes conditions matérielles, comment se font les calculs ?
Après avoir mis à niveau le cluster de production de GLM-5.1 de Zhipu du ROFT traditionnel à ZCube, trois chiffres ont été obtenus :
Pour résumer, avec le même investissement en GPU, le cluster peut servir plus d'utilisateurs ; avec les mêmes exigences d'expérience utilisateur, le cluster peut acheter un tiers d'équipements réseau en moins. L'efficacité et les coûts s'améliorent dans les deux sens.
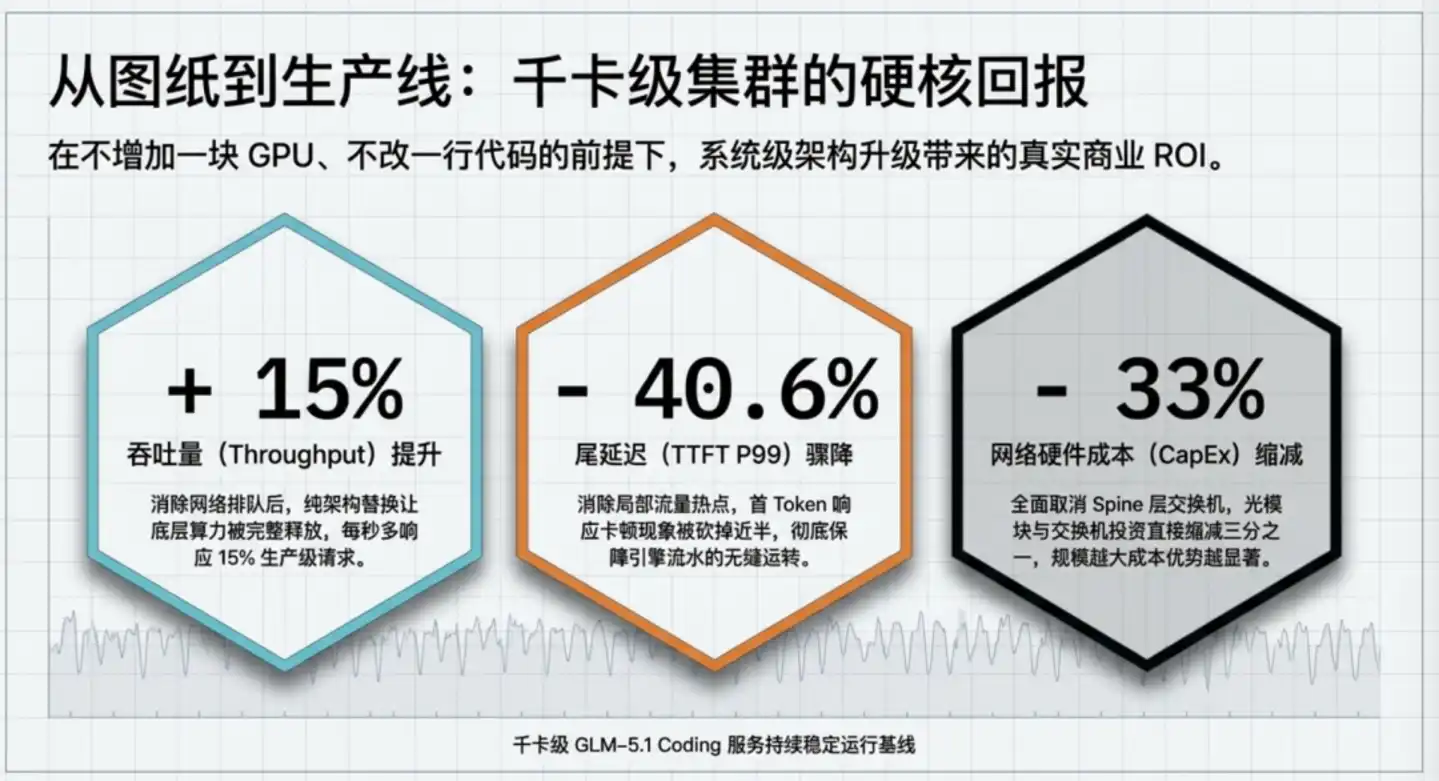
Concrètement, le débit augmente de 15%, équivalant à une puissance de calcul gratuite supplémentaire de 15%. À nombre de GPU constant, un débit supérieur de 15% équivaut à une baisse du coût matériel moyen par token d'environ 13%, ou à la possibilité de servir 15% d'utilisateurs en plus à coût égal.
Si un cluster dispose de 1000 GPU, cette mise à niveau équivaut à obtenir gratuitement la capacité de 150 cartes supplémentaires. Au prix actuel du marché des cartes d'inférence haut de gamme, cela représente une valeur de puissance de calcul de plusieurs centaines de millions de yuans.
La réduction de 40,6% de la latence de queue (tail latency) résout un problème de stabilité plutôt que de vitesse moyenne. Une tâche d'Agent nécessitant 50 appels, si la latence de queue est réduite de 1 seconde à chaque fois, le pire temps d'achèvement de la tâche entière est compressé de près d'une minute.
La réduction d'un tiers des coûts est une économie directe au niveau de la construction. ZCube supprime la couche Spine, pour une échelle de cluster identique, le nombre requis de commutateurs et de modules optiques diminue directement d'un tiers. Selon les estimations de Zhipu, dans un cluster à l'échelle de dix mille cartes, cet aspect seul pourrait permettre d'économiser entre 210 et 640 millions de yuans.
À long terme, avec l'expansion exponentielle des clusters, la complexité de la communication entre GPU augmente de plusieurs fois, la probabilité et l'impact des congestions s'amplifient également. Cela signifie que la valeur des innovations architecturales comme ZCube se manifestera de manière accélérée avec l'expansion continue des clusters d'inférence. Les gains pour un cluster de dix mille cartes demain pourraient dépasser les 15% d'aujourd'hui.
05 Pour conclure
Après avoir lu le rapport technique de Zhipu, je me demande si cela va, comme l'émergence soudaine de DeepSeek, apporter une tempête à l'industrie ?
En y réfléchissant bien, leurs impacts semblent être sur des aspects différents. Lorsque DeepSeek est apparu, il a prouvé que la même intelligence pouvait être réalisée avec beaucoup moins de puissance de calcul. Le marché s'inquiétait que "le nombre de GPU nécessaires diminue", ce qui a fait perdre près de 600 milliards de dollars de capitalisation boursière à NVIDIA ce jour-là.
Mais la technologie de Zhipu prouve aujourd'hui : avec la même puissance de calcul, on peut produire plus. Elle restructure "ce à quoi devraient ressembler les autres infrastructures en dehors des GPU".
À court terme, NVIDIA ne sera pas affecté, mais à long terme, les remparts de l'écosystème GPU + interconnexion NVLink + réseau InfiniBand + logiciel CUDA sont en train d'être "détrempés", en particulier l'InfiniBand que NVIDIA a acquis en 2019 pour 6,9 milliards de dollars avec le rachat de Mellanox, la prime de NVIDIA sur le côté réseau sera fortement érodée.
De plus, ZCube supprime la couche Spine, mais il impose en contrepartie des exigences de densité de ports plus élevées sur les commutateurs Leaf. Les bénéficiaires sont les fabricants capables de produire des commutateurs Leaf à haute densité et à grand nombre de ports (Ruijie, Arista, puces de commutation Broadcom), les perdants sont les fabricants qui dépendent principalement de la prime sur les commutateurs Spine haut de gamme.
En 2025, Celestica et NVIDIA détenaient ensemble environ 50% des parts de marché des commutateurs réseau backend pour l'IA, cette configuration risque d'être remaniée avec la diffusion du paradigme ZCube.
Les modules optiques sont la direction de la chaîne d'approvisionnement la plus directement bénéficiaire de ce changement, la logique est très claire. Pour les fabricants chinois de modules optiques (Zhongji Innolight, TFC Optical Comm, etc.), c'est une opportunité structurelle favorable : non seulement le volume total augmente, mais la demande en modules optiques à haute vitesse (800G, 1.6T) sous le paradigme ZCube est plus concentrée et plus pressante que dans l'architecture traditionnelle.
Que ce soit l'architecture TileRT ou ZCube, il s'agit d'un moteur d'inférence logiciel pur fonctionnant sur des GPU standard, ne dépendant pas de caractéristiques matérielles privées de NVIDIA, et pouvant théoriquement être porté sur des puces chinoises comme les Ascend de Huawei. Si cette direction est empruntée avec succès, cela réduira considérablement le seuil de la pile logicielle pour les puces IA chinoises dans les scénarios d'inférence.
C'est peut-être là la plus grande signification derrière cette innovation technologique.







