Des médias ont récemment révélé que Microsoft avait révoqué son autorisation interne d'utilisation de Claude Code. Claude Code est un outil de programmation IA développé par Anthropic. Après avoir été ouvert en interne chez Microsoft pendant seulement six mois, il est devenu l'un des logiciels d'assistance au développement les plus populaires, entraînant une augmentation explosive de la consommation de tokens et des coûts, mais la qualité de la production n'était pas à la hauteur. Compte tenu de multiples facteurs, Microsoft a freiné et orienté ses employés vers son propre Copilot CLI.
Le phénomène d'une consommation de tokens disproportionnée par rapport à la production réelle est également répandu dans d'autres entreprises de plateforme. Uber a épuisé son budget annuel 2026 pour les outils de programmation IA en seulement 4 mois ; certains employés d'Amazon consomment des tokens sans raison ; Meta a discrètement retiré le classement interne « Tokenmaxxing » de ses employés, cessant d'encourager la consommation de tokens sans production. Tout le monde adopte l'IA, mais n'a pas encore trouvé la bonne posture ; les entreprises mettent toutes l'accent sur l'IA native, mais (pour l'instant) ne voient pas de bénéfices, seulement des factures de plus en plus longues. J'appelle cela « token non économique ».
Le token non économique est le résultat d'une superposition de multiples facteurs : un contrôle interne inadéquat dans les entreprises, un retour limité sur l'utilisation des tokens, la conception de l'architecture des Agents eux-mêmes (comme les appels répétés de compétences, la consommation interne des tâches longues, les coûts de la collaboration multi-agents). À l'avenir, ces problèmes pourraient s'atténuer progressivement avec l'amélioration du contrôle interne et l'optimisation technique de la consommation. Mais pour transformer le bénéfice net des tokens en valeur positive, il ne suffit pas d'optimiser le coût des tokens du côté de l'offre ; il faut aussi agir du côté de la demande, en résolvant le problème de savoir comment faire en sorte que la consommation de tokens génère une valeur réelle dans des scénarios industriels étendus.
La qualité a un prix
Ces deux dernières années, les principaux grands modèles ont évolué rapidement. Les entreprises développeuses ont adopté différentes stratégies de combinaison de produits en fonction de leur positionnement sur le marché, et les prix des appels d'API ($ par million de tokens) ont changé en conséquence. Les performances des modèles ont considérablement augmenté, mais la qualité a un prix. Le prix d'appel des produits d'une même strate a également augmenté discrètement, devenant une raison importante de l'augmentation des coûts de consommation de tokens pour les utilisateurs en aval.
Stratégie de stratification des leaders
Anthropic est la première entreprise de modèles propriétaires à avoir compris que la programmation est le scénario clé de monétisation des tokens. Les principaux utilisateurs payants des grands modèles sont les développeurs et les équipes techniques des entreprises. Ils ne sont pas sensibles au prix et accordent plus d'importance à l'efficacité et à la qualité de codage du modèle. En s'emparant de l'avantage initial de ce scénario commercial qu'est la programmation, on peut réaliser une prime sur les tokens.
Par conséquent, Anthropic se concentre sur la programmation dans sa recherche et développement. Après avoir établi un avantage en matière de capacités de programmation, à partir du lancement de la série Claude 3 début 2024, l'entreprise a été la première du secteur à adopter une combinaison de produits tri-dimensionnelle (phare - milieu de gamme - léger) pour les modèles d'une même génération, réalisant une tarification stratifiée tout en capturant simultanément les marchés haut de gamme et grand public. La série Opus se positionne comme la référence de l'industrie de la programmation, ancrant le marché haut de gamme avec un prix de $15/$75 (prix en millions de tokens en entrée/sortie, idem ci-après) ; la série Sonnet ($3/$15) offre un choix à bon rapport qualité-prix pour les tâches quotidiennes de programmation et de bureautique ; la série Haiku ($1/$5) s'adresse aux scénarios d'interaction légers et rapides, avec un prix abordable. Cette stratification fine permet à Anthropic de maximiser l'extraction de profit dans chaque tranche de prix tout en protégeant ses parts de marché.
Cette stratégie de tarification offre plus de moyens et une plus grande flexibilité opérationnelle à Anthropic en tant que leader technologique. Par exemple, après avoir perçu un rattrapage rapide des écarts de performance avec les concurrents, l'entreprise a profité du lancement d'Opus 4.5 pour réduire considérablement les prix, comprimant l'espace des concurrents. Ou encore, avec le lancement du nouveau modèle Mythos Preview ($25/$125), l'entreprise a introduit une nouvelle strate ultra-haut de gamme sur Opus, faisant remonter le prix des produits phares, inversant la tendance précédente à la baisse constante des prix des produits haut de gamme. Le Fable 5, lancé par la suite, utilise la même architecture sous-jacente, limite certaines fonctionnalités pour des raisons de sécurité, et adopte un prix de $10/$50 (toujours le double de la série Opus) pour cibler un marché plus large. Il s'agit d'une tarification non seulement basée sur les performances, mais aussi sur le degré de contraintes de sécurité, formant une stratégie de tarification tri-dimensionnelle (stratification par capacités, par risques, par prix) pour reconquérir le marché premium.
L'efficacité de cette stratégie de positionnement a été pleinement démontrée entre 2025 et 2026. Les revenus annuels récurrents (ARR) d'Anthropic sont passés d'environ 10 milliards de dollars fin 2024 à environ 450 milliards de dollars en mai 2026. Plus important encore, cette stratégie a pleinement protégé la prime de marché en tant que leader en matière de puissance produit, permettant de sortir de la spirale de la guerre des prix grâce à l'avantage en performances, et de boucler la boucle de valeur « la qualité a un prix ».
La tension sur les prix des suiveurs
En comparaison, OpenAI et Google ont choisi des voies de diversification différentes de celle d'Anthropic aux premiers stades de la commercialisation des grands modèles. En 2024, OpenAI a investi massivement dans des projets multimodaux comme Sora ; Google a construit une stratégie d'écosystème autour de Gemini couvrant plusieurs lignes de produits comme la recherche, les services cloud et Workspace. Ces investissements ont élargi la carte technologique, mais, les ressources étant dispersées, leurs performances dans les scénarios bureautiques et de programmation ont été relativement moins saillantes. Lorsqu'ils ont réalisé que la programmation était le principal champ de bataille de la monétisation des capacités des modèles et sont revenus à la course, ils avaient déjà perdu l'avantage de l'initiative.
Le retour d'OpenAI est très déterminé. D'une part, il se reconcentre sur les capacités de codage et d'Agent, abandonnant des projets très consommateurs comme Sora ; d'autre part, il suit Anthropic en établissant sa propre matrice de produits stratifiés, collant de près et un-à-un, tout en élargissant délibérément l'écart de prix entre le modèle phare et les modèles légers : prix élevé pour le phare afin de garder l'étendard du modèle leader, prix bas pour les légers afin de capturer des parts de marché. Le prix du GPT 5.5 ($5/$30) s'aligne sur celui de l'Opus 4.7/4.8 ($5/$25), établissant un point d'ancrage de prix haut de gamme équivalent à Claude Opus. Les modèles secondaires GPT 5.4 mini ($0.75/$4.50) et nano ($0.20/$1.25), nettement inférieurs au Claude Haiku 4.5 de même niveau ($1.00/$5.00), échangent le prix contre des parts de marché.
Google est au cœur de l'écosystème Android, dispose déjà d'une boucle commerciale complète, doit gérer des relations plus complexes et agit avec plus de prudence. Gemini doit servir simultanément les clients entreprises de Google Cloud, les utilisateurs productifs de Workspace et l'expérience des consommateurs du produit de recherche. Même en prenant conscience de l'importance de la programmation, il ne peut pas concentrer toutes ses ressources sur la programmation et la bureautique de manière aussi radicale, et doit continuer sur la voie multimodale et diversifiée.
Google a également suivi Anthropic en divisant ses produits en série phare Pro et série légère Flash dès la génération 1.5 de Gemini, mais la vitesse d'itération des produits est relativement lente et le positionnement tarifaire plus bas. Au début 2024, le modèle phare Gemini 1.5 Pro, dans des cas de prompt court (<128k), affichait un prix de seulement 5 $ par million de tokens en sortie, soit un tiers de celui du GPT-4o contemporain et un quinzième de celui de l'Opus 3 ; le Gemini 3.1 Pro lancé en février 2026 a vu son prix par million de tokens en sortie monter à 12 $, nettement inférieur aux 15 $ du GPT 5.4 et aux 25 $ de l'Opus 4.6/4.7 contemporains. De plus, Google a fait une opération inverse en ajoutant une gamme ultra-légère Flash-Lite sous la gamme légère Flash, poussant les prix d'appel au niveau de ceux des modèles open source, c'est un échange typique de prix contre volume.
Le Gemini 3.5 Pro, attendu avec impatience par le marché, tarde à être officiellement lancé, ce qui reflète également les jeux internes auxquels Google est confronté pour équilibrer performances, sécurité et adaptation à l'écosystème. La stratégie de tarification de son nouveau modèle phare est également très suivie par le marché.
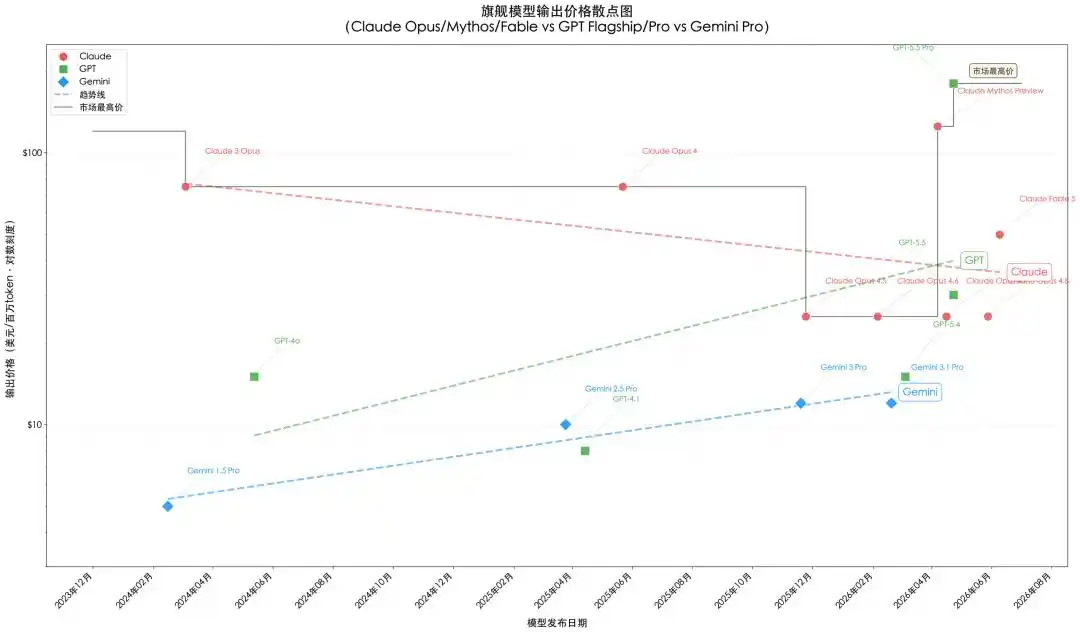
Figure 1 : Tendances des changements de prix des modèles phares. Les prix des séries Claude et GPT-4o/4.1/5.4 proviennent des pages de tarification officielles ; les prix des séries GPT-5.5 et Gemini 3.5 Flash proviennent des plateformes OpenAI/Google et de synthèses tierces ; les prix des séries GLM sont basés sur la plateforme Z.ai à l'étranger, les prix spécifiques étant affectés par les fluctuations des devises et la tarification à double voie. Dessin : Codebuddy
Le marché des modèles secondaires/légers et open source/semi-open source augmente silencieusement les prix dans l'explosion de la demande
Les modèles phares rivalisent sur les performances, les modèles secondaires/légers sur les prix, c'est une posture concurrentielle logique et attendue. Face à une concurrence féroce, l'attente générale est que le point central du marché baisse constamment. Mais la réalité est tout à fait opposée ; le marché des tokens économiques, constitué des modèles secondaires/légers et open source/semi-open source, a vu son centre de prix monter discrètement ces deux dernières années, et c'est justement dans cette montée que le véritable plancher des prix du marché des tokens s'est élevé.
En apparence, c'est une mer rouge de folie. Les modèles secondaires/légers peu coûteux comme Sonnet, mini, Flash sont les versions économiques des principaux modèles propriétaires pour le marché grand public, visant principalement à capter des parts de marché. Parallèlement, des modèles open source ou semi-open source comme DeepSeek, Qwen et GLM ont rapidement émergé, adoptant généralement une stratégie de positionnement phare avec des prix secondaires/légers, exerçant une pression continue sur les prix du marché des modèles propriétaires secondaires/légers. Fin 2024, DeepSeek V3 a pénétré le marché avec un prix d'environ $0.27/$1.10, nettement inférieur aux modèles propriétaires de même niveau. Le R1, lancé peu après, offrait des capacités de raisonnement améliorées au prix de $0.55/$2.19, compressant directement l'espace tarifaire du GPT-4.1 mini et du Claude Haiku. Le GLM-4 Plus offrait des capacités proches du GPT-4 au prix de seulement $0.69/$0.35, exerçant une forte attraction sur les communautés de développeurs sensibles au prix. La guerre des prix semble être la norme sur ce marché stratifié.
Mais d'un autre côté, le lancement de chaque nouvelle génération de modèles secondaires/légers et open source/semi-open source s'accompagne d'un relèvement du plancher des prix. Par exemple, le Haiku 3.5, lancé en octobre 2024, avait un prix d'entrée/sortie de $0.80/$4.00 ; un an plus tard, le prix du Haiku 4.5 a augmenté de 20% à $1.00/$5.00. À peu près au même moment, les prix de la gamme GPT mini ont presque doublé, passant de $0.15/$0.60 pour le 4o mini à $0.40/$1.60 pour le 4.1 mini. La série Gemini Flash a également suivi, passant du prix ultra-bas de $0.10/$0.40 du 2.0 Flash à $0.30/$2.50 pour le 2.5 Flash, le prix par million de tokens en sortie étant multiplié par plus de 6. Les modèles open source/semi-open source comme les séries GLM, le GLM-5 sur les marchés étrangers a vu son prix augmenter d'environ 67% à 100% par rapport au GLM-4.7. Pour reprendre les propres mots de Zhipu AI, cette forte augmentation de prix montre que les capacités technologiques et la compétitivité des modèles nationaux s'améliorent rapidement.
La raison fondamentale de ce phénomène est l'explosion de la consommation de tokens économiques. La plupart des tâches quotidiennes de codage, de traitement de documents et de flux automatisés ne nécessitent pas les capacités de niveau Opus ou GPT-5.5, mais sont assurées par des modèles comme Sonnet, mini, Flash, ou confiées à des modèles open source/semi-open source. Avec la popularisation des assistants de codage IA, des flux de travail Agent et des applications IA d'entreprise, le volume d'appels de ces modèles secondaires/légers et open source/semi-open source a augmenté de façon explosive, dépassant largement celui des modèles phares. D'une part, cela entraîne une augmentation rapide de la consommation de modèles économiques, et le jeu consistant à brûler des liquidités pour maintenir des prix bas ne peut pas durer ; d'autre part, cela ouvre également un espace de hausse de prix pour les fabricants, la demande continuant de croître rapidement malgré l'augmentation. Par conséquent, même sur le marché des tokens économiques, la logique concurrentielle passe de « quel token est le moins cher » à « quel token offre le meilleur rapport qualité-prix ». Que ce soit pour les séries Claude Sonnet/Haiku, GPT mini/nano, Gemini Flash, ou les séries DeepSeek, Qwen, GLM, on observe une tendance à la hausse du point central des prix.
À partir de l'analyse ci-dessus, on peut voir que le marché des tokens est en train de vivre un processus global de hausse : consolidation de la structure des prix haut de gamme, augmentation simultanée du volume et des prix dans le milieu de gamme, rattrapage et hausse pour les modèles économiques. Anthropic, grâce à son avance en matière de capacités de codage, a établi le plus fort pouvoir de tarification de l'industrie ; OpenAI et Google rattrapent rapidement mais doivent encore, à court terme, échanger le prix contre le volume ; et les modèles open source/semi-open source, tout en relevant continuellement le plancher des prix, commencent également à partager les bénéfices de la croissance du marché. L'évolution de cette structure affectera profondément la répartition des profits et la dynamique concurrentielle de toute l'industrie de l'IA. Dans un marché où la consommation augmente fortement et le prix unitaire monte, la hausse des coûts pour les consommateurs de tokens en aval, correspondant à l'explosion des revenus des fabricants de modèles, est la cause profonde de la non-économie des tokens pour la consommation finale.
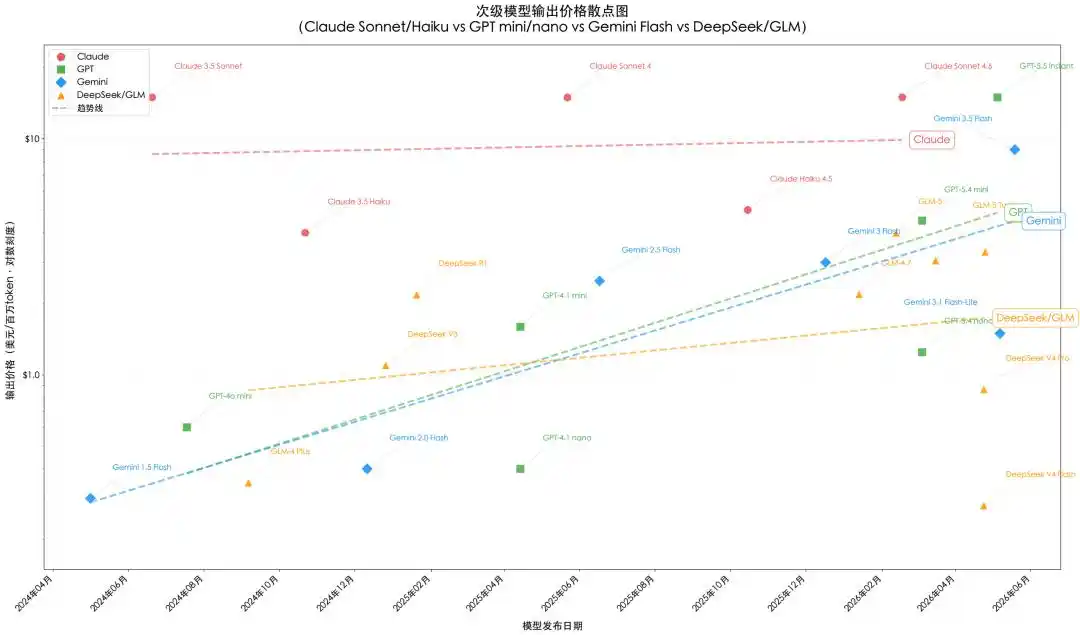
Figure 2 : Tendances des prix des modèles secondaires/légers et open source/semi-open source. Les prix des séries Claude et GPT-4o/4.1/5.4 proviennent des pages de tarification officielles ; les prix des séries GPT-5.5 et Gemini 3.5 Flash proviennent des plateformes OpenAI/Google et de synthèses tierces ; les prix des séries GLM sont basés sur la plateforme Z.ai à l'étranger, les prix spécifiques étant affectés par les fluctuations des devises et la tarification à double voie. Dessin : Codebuddy
La consommation invisible des agents
Le token de plus en plus cher blesse certes le portefeuille, mais ce qui est encore plus douloureux, c'est qu'une quantité importante de tokens est systématiquement gaspillée lorsque l'on fait appel à un agent (Agent) pour travailler. Le piège du contexte (Context Trap), la boîte noire du tokeniseur (Tokenizer Black Box), la redondance des compétences (Skill Redundancy), ainsi que la taxe de communication et la dérive entropique dans la collaboration multi-agents (Communication Tax and Entropy Drift), ces fuites structurelles qui s'ajoutent les unes aux autres, constituent la racine technique interne de la non-économie des tokens.
Le piège du contexte
Le raisonnement du modèle nécessite de calculer la relation de chaque token avec tous les autres, donc plus le contexte est long, plus la charge de calcul est lourde et plus la consommation de tokens est importante. Un même problème, jeté sans contexte à un Agent, consommera peu de tokens. Mais s'il est accompagné d'un historique de conversation, de logs d'outils, de fichiers de code, d'informations d'erreur et de discussions en plusieurs tours, la consommation de tokens en entrée peut être supérieure de plusieurs ordres de grandeur.
Et l'architecture Agent amplifie naturellement le piège des textes longs. L'agent décompose le problème, planifie l'appel d'outils, lit des fichiers, vérifie les retours, modifie le plan, rappelle des outils, en boucle, chaque étape pouvant réintroduire l'historique dans le contexte. Les mêmes informations sont relues à plusieurs reprises, la même tâche est facturée à plusieurs reprises. Salim et al., (2026), dans leur analyse du framework ChatDev, ont constaté que la consommation de tokens lors de la phase de revue de code (Code Review) représentait en moyenne 39,5 % de la consommation totale, la plus élevée de toutes les phases de développement, ce qui signifie que près de 40 % des tokens sont dépensés dans le processus de transmission répétée d'informations existantes entre les Agents, et non dans la génération de contenu nouveau.
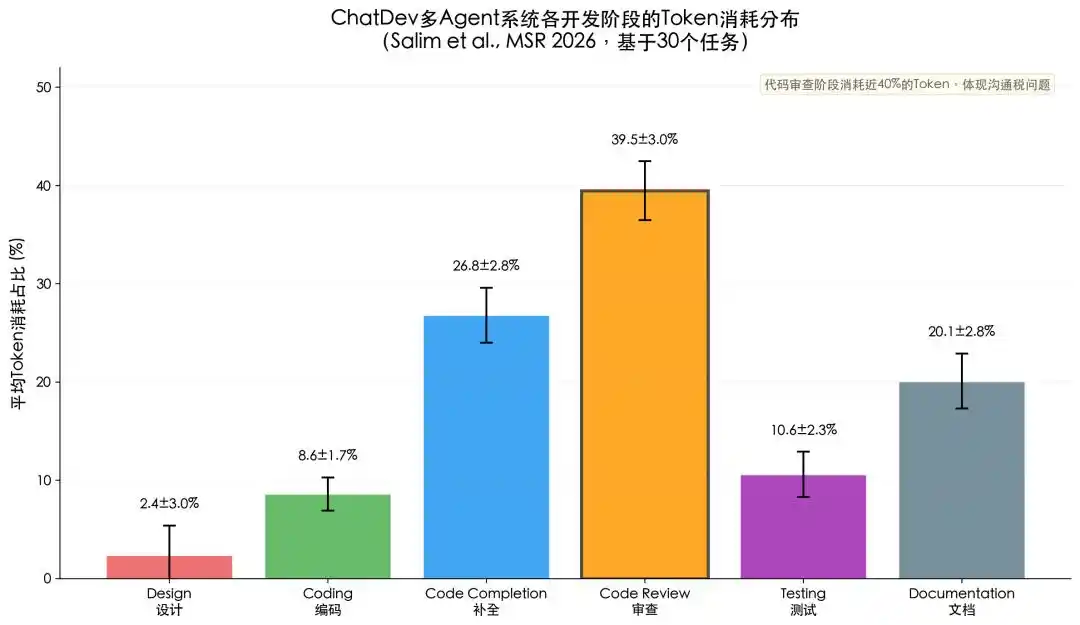
Figure 3 : Analyse de la répartition de la consommation de tokens par phase pour 30 tâches du framework ChatDev. Salim, et al., (2026). Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering. Proceedings of the Mining Software Repositories Conference (MSR).
La boîte noire du tokeniseur
Le tokeniseur (Tokenizer) est la base de l'entraînement des grands modèles, déterminant la limite supérieure de densité d'information du modèle pour une quantité de paramètres donnée, la limite inférieure de longueur de contexte efficace et la fiabilité des cas limites (nombres/code/multilingue). Un tokenisation plus rationnelle rend l'entraînement et le raisonnement du modèle plus efficaces et stables. Les tokeniseurs et poids des modèles open source/semi-open source sont généralement publics, tandis que les tokeniseurs des modèles propriétaires sont des « boîtes noires », et la mise à jour des tokeniseurs s'accompagne souvent de changements dans la densité des tokens.
En avril 2026, lors du lancement de l'Opus 4.7, Anthropic a changé le tokeniseur sous-jacent. Selon la documentation officielle d'Anthropic, l'ajustement du tokeniseur visait principalement à répondre aux besoins réels de l'entraînement du modèle, adoptant un schéma de segmentation en sous-mots plus fin pour améliorer les performances, avec pour effet secondaire une expansion du nombre de tokens pour un texte de même longueur de 1,0 à 1,35 fois. Les résultats de plusieurs organismes de test indépendants ont montré un facteur d'expansion réel plus élevé. La plateforme de gestion des coûts IA d'entreprise Finout, sur la base de tests pondérés avec des prompts réels d'entreprises, a montré un taux d'expansion moyen de 1,47 fois (+47 %) pour les documents techniques et les fichiers de code denses en anglais ; le test composite de ClaudeCodeCamp sur sept types de fichiers réels a donné un résultat moyen de 1,325 fois (+32,5 %) ; le développeur Simon Willison, en comparant directement via l'API, a constaté que le même prompt système passait de 5 039 tokens à 7 335 tokens (+46 %) avec le nouveau tokeniseur, et que l'expansion des tokens pour les images haute résolution atteignait même 3,01 fois (+201 %).
Plus tôt, lors du lancement du GPT-4o, OpenAI avait mis à jour son tokeniseur de cl100k_base à o200k_base, presque doublant la taille du vocabulaire, expliquant officiellement que cette mesure visait à améliorer le taux de compression et les capacités de traitement multilingue. Cependant, l'expansion du vocabulaire en elle-même ne signifie pas une réduction du nombre de tokens pour un même texte ; en réalité, pour les contenus non anglophones (en particulier les caractères CJK comme le chinois, le japonais), la variation de la granularité de segmentation du nouveau tokeniseur peut entraîner une augmentation plutôt qu'une diminution du nombre de tokens.
Quant à savoir si une tokenisation plus fine peut améliorer les performances du modèle, il manque actuellement des arguments systématiques et publics de la part des fabricants de modèles. Anthropic, dans la documentation des changements de l'Opus 4.7, a classé le nouveau tokeniseur dans la catégorie des Breaking Changes, ne décrivant que le changement factuel (segmentation plus fine en sous-mots), sans expliquer en détail la motivation technique ou les gains de performance. Des chercheurs de la communauté ont souligné qu'une tokenisation plus fine peut théoriquement enrichir la capacité de représentation lexicale du modèle, bénéficiant particulièrement à la compréhension du code et au traitement de données structurées (les formats JSON, XML ont atteint la limite supérieure d'expansion de 1,35 fois sur l'Opus 4.7), mais la question reste ouverte de savoir si ce gain potentiel en performances suffit à justifier une augmentation des coûts de près de 50 %.
L'itération des tokeniseurs est nettement moins fréquente que les mises à jour des modèles, mais elle concerne la norme de facturation la plus basique des tokens, et les changements sont cachés dans des détails techniques, ce que les utilisateurs ordinaires ne peuvent pratiquement pas percevoir. Les modèles propriétaires sont encore plus discrets sur leurs tokeniseurs, ce qui pourrait devenir l'une des raisons aggravant la non-économie des tokens.
Les appels inutiles de compétences
Les compétences (Skill) sont l'un des outils clés pour rendre l'architecture Agent plus professionnelle. Certains voient les compétences comme des markdown plus longs, d'autres comme un dossier contenant diverses références et instructions, d'autres encore comme un prompt structuré très long. Dans le raisonnement réel et les tâches d'Agent, de nombreuses compétences sont trop longues et complexes, augmentant la consommation de tokens.
L'étude empirique à grande échelle de Gao et al., (2026) sur 55 315 compétences publiques a révélé comment le chargement inefficace des compétences gaspille les tokens. Au niveau du routage (l'étape où l'Agent décide d'appeler ou non une compétence), pas moins de 26,4 % des compétences n'avaient aucune description de routage, comme des manuels d'outils sans table des matières, augmentant considérablement la probabilité d'être chargées inutilement par l'Agent. Au niveau du contenu principal, plus de 60 % du contenu des compétences n'étaient pas des règles d'action directement exécutables, mais des explications de contexte ou des exemples de texte, la majeure partie des tokens utilisés pour les compétences étant dépensés à lire le mode d'emploi plutôt qu'à travailler. Plus grave encore, certaines compétences référencent intensivement des fichiers, une seule invocation pouvant injecter des dizaines de milliers, voire plus de cent mille tokens, dont seule une petite proportion peut être pertinente pour la tâche en cours.
Le test de référence SWE-Skills-Bench de Han et al., (2026) a confirmé davantage l'utilité limitée des compétences. Cette étude a testé 49 compétences d'ingénierie logicielle publiques sur des projets GitHub réels, et les résultats ont montré que 39 compétences (79,6 %) n'apportaient aucune amélioration du taux de réussite (le taux de réussite était le même avec ou sans la compétence), l'augmentation d'utilité moyenne de l'ensemble des 49 compétences n'était que de 1,2 point de pourcentage, cependant le coût en tokens a augmenté jusqu'à 451 %. Seules 7 compétences codant des connaissances spécialisées dans des domaines spécifiques (comme les formules de contrôle des risques financiers, la gestion de trafic cloud native, les modèles GitLab CI) ont apporté une amélioration significative des performances (jusqu'à 30 points de pourcentage) ; 3 compétences ont même entraîné une baisse des performances en raison de conflits de version (jusqu'à 10 points de pourcentage). Cela montre que l'utilité d'une compétence dépend fortement de l'adéquation au scénario, et qu'un appel aveugle ne fera qu'augmenter les coûts inutilement.
Le bavardage des multi-agents et la dérive des tâches longues
Le multi-agents est actuellement une méthode de travail privilégiée, permettant à un utilisateur de diriger une équipe constituée d'IA, avec des agents pour écrire le code, le revoir, le tester, le corriger, chacun ayant son rôle et se surveillant mutuellement, ce qui améliore effectivement la qualité de la sortie dans de nombreux cas. Mais les machines peuvent aussi tenir des réunions inefficaces, répétant constamment dans les conversations le contexte de la tâche déjà discuté, les conclusions précédentes, les formules de politesse, chaque répétition consommant à nouveau des tokens, ce que Salim et al., (2026) appellent la taxe de communication (communication tax) des systèmes multi-agents.
De plus, confier des tâches longues et complexes (long task) à un système multi-agents devient une pratique courante en programmation et en bureautique, et s'étend progressivement à des scénarios de la vie quotidienne comme la restauration, les déplacements. Les tâches longues présentent intrinsèquement le problème de la dérive. Le contexte de telles tâches est rempli de sorties d'outils, d'erreurs, d'ébauches, de logs, ce qui facilite une dérive progressive du raisonnement du modèle par rapport à l'objectif. Pour corriger cette dérive, les développeurs ont tendance à ajouter des mécanismes de résumé, de mémoire, de vérification, de retour arrière, entraînant une consommation de tokens supplémentaire. Luo et al., (2026), dans leur étude TabTracer, ont observé que le raisonnement en chaîne traditionnel, lorsque le chemin est trop long, a tendance à tomber dans un état de boucle, et qu'une injection antagoniste peut déclencher délibérément cette boucle, faisant consommer des tokens à l'Agent de manière répétée sans s'en rendre compte. Cette consommation supplémentaire nécessaire pour maintenir la stabilité est souvent appelée taxe d'entropie (entropy tax) ; plus le système est complexe, plus les Agents sont libres, plus la supervision est nécessaire, plus la tâche est longue, plus le contexte est grand, plus la taxe d'entropie augmente rapidement. Une équipe d'agents apparemment efficace peut voir plus de la moitié de sa facture de tokens dépensée en coordination interne et en autocorrection.
Le piège du contexte, la boîte noire du tokeniseur, les appels inutiles de compétences, la littérature de bavardage et la dérive des tâches longues, ces facteurs qui s'ajoutent, leur effet sur la consommation de tokens n'est pas une simple addition, mais une croissance exponentielle multiplicative. Plus notablement, l'impact de ces pertes techniques est asymétrique selon les utilisateurs. Les développeurs ayant des connaissances techniques peuvent atténuer dans une certaine mesure ces problèmes en ajustant le prompt système (System Prompt), en réduisant le contenu des compétences, en définissant des stratégies de gestion de la fenêtre de contexte, etc. Mais pour les utilisateurs ordinaires en entreprise sans fond technique, ils ne comprennent ni le mécanisme de circulation des tokens à l'intérieur des Agents, ni ne peuvent intervenir efficacement sur leur comportement. Ils ne voient que les chiffres augmenter sur la facture, sans savoir où l'argent est dépensé et pourquoi tant est dépensé. En ce sens, la non-économie des tokens n'est pas seulement un problème d'efficacité technique, mais aussi un problème d'équité technique. Le seuil d'utilisation des outils d'IA passe de savoir écrire du code à comprendre la dynamique des coûts de l'architecture Agent. Dans la réalité, la plupart des utilisateurs d'agents intelligents ne disposent pas des connaissances techniques pertinentes, et sont placés dans une position structurellement désavantagée.
Trouver la demande réelle
Par rapport aux problèmes liés à l'offre comme la tarification, la consommation inefficace, etc., les limitations du côté application sont une cause plus importante de la non-économie des tokens. Bien que les performances des modèles aient réalisé des progrès remarquables ces deux dernières années, l'universalité des tokens reste assez limitée. L'utilisation actuelle des tokens se confine largement à des scénarios à forte numérisation, comme l'assistance à la programmation, le traitement de documents, l'analyse de données. En sortant de ces parties avantageuses, les performances des grands modèles se dégradent fortement avec la baisse du niveau de numérisation du scénario d'application. Dans les modèles d'activité de services hors ligne à très faible degré de numérisation, comme la restauration, les services à domicile, les points de vente au détail, les réparations sur site, les tâches que les tokens peuvent accomplir de manière indépendante se limitent aux parties de gestion des processus déjà hautement numérisées, et il est difficile de participer réellement aux opérations sur site.
Cela ne veut pas dire que l'IA ne pourra jamais entrer dans ces domaines, mais que le paradigme actuel du modèle purement linguistique (token-in, token-out) et le monde réel sont séparés par un fossé structurel. Ce problème existait déjà à l'ère de l'internet mobile, et est la raison fondamentale pour laquelle les technologies numériques n'ont pas fondamentalement transformé les industries primaire et secondaire. Le développement de l'intelligence artificielle offre de nouvelles possibilités pour franchir ce fossé ; des recherches fondamentales comme l'IA pour la science (AI for Science), les modèles du monde (World Model), les systèmes robotiques progressent. Ces deux dernières années, le prix Nobel de physique et de chimie ont été décernés à des scientifiques en IA, les robots humanoïdes comme Figure, Tesla Optimus, Unitree ont réalisé des progrès significatifs. Mais ces domaines de pointe sont encore au stade du laboratoire, et avant d'obtenir des percées révolutionnaires au niveau applicatif, les tokens resteront probablement piégés dans des scénarios hautement numérisés.
La programmation est un cas particulier universel
La programmation est actuellement le scénario d'application où les grands modèles de langage performent le mieux, mais ce scénario n'est pas représentatif de manière universelle ; une description plus précise serait qu'il s'agit d'un cas particulier ayant une universalité.
L'universalité signifie que la programmation produit le langage universel des Agents, qui peut, dans des scénarios à bonne base numérique (les processus et fichiers sont déjà numérisés et pilotés par des algorithmes), directement piloter différents types d'Agents pour les aider à accomplir des tâches variées. Sous cet angle, le Claude Code d'Anthropic spécialisé en programmation, et le GPT Codex d'OpenAI, devenus les produits Agent les plus populaires du marché, n'est pas un hasard.
Le cas particulier signifie que le scénario de programmation présente des avantages considérables dans la phase de post-entraînement du modèle. Premièrement, un retour de signal déterminé : le code généré par le modèle est exécuté, le compilateur, l'interpréteur, les tests unitaires peuvent immédiatement donner un jugement précis, structuré et sans ambiguïté sur le vrai ou le faux. Deuxièmement, sur la base d'un tel retour de signal automatique, on peut former efficacement une boucle fermée de post-entraînement automatique, faisant entrer le retour sans obstacle dans la boucle d'apprentissage par renforcement, l'Agent générant rapidement, signalant des erreurs, s'auto-corrigeant dans le bac à sable numérique. Un tel environnement d'entraînement autonome est rare dans d'autres scénarios, voire impossible à former.
Dès qu'on sort de la programmation, l'efficacité de l'entraînement du modèle diminue considérablement. Dans le monde commercial traditionnel relativement peu numérisé, où l'on ne peut pas former une boucle fermée de post-entraînement automatique, comme la prise de décision managériale, les négociations juridiques, la médecine clinique, la logistique de la chaîne d'approvisionnement, le coût de collecte des données et de validation des résultats dévorerait toute économie de tokens. Les agents intelligents qui n'obtiennent pas de retours de signal à faible coût ne peuvent pas non plus réaliser une évolution auto-exponentielle, et auront du mal à répéter leur immense succès en programmation.
En février 2023, A&O Shearman (anciennement Allen & Overy) a été le premier cabinet à conclure un partenariat stratégique exclusif avec Harvey AI, une entreprise spécialisée dans les grands modèles verticaux juridiques, déployant l'assistant juridique IA développé par cette dernière dans ses 43 bureaux à travers le monde. Pendant une période d'essai de plusieurs mois, les plus de 3 500 avocats d'A&O Shearman dans le monde ont soumis environ 40 000 requêtes à Harvey, couvrant de multiples flux de travail juridiques comme la rédaction de contrats, la recherche réglementaire, la due diligence, ce qui a effectivement amélioré l'efficacité du travail.
De l'autre côté de la médaille, A&O Shearman a clairement indiqué dans son communiqué de presse officiel que toutes les sorties générées par Harvey AI devaient être soigneusement vérifiées par un avocat en exercice avant d'être utilisées. L'IA n'a pas vraiment remplacé le jugement professionnel des avocats, elle a seulement ajouté une étape de première vérification IA au flux de travail existant. Lorsque les associés seniors recevaient des ébauches de contrat annotées par l'IA, le temps passé à les revérifier était presque équivalent à celui nécessaire pour examiner le contrat original depuis le début. Bien sûr, les résultats de la vérification humaine sont des données de grande valeur pour l'entraînement ultérieur du modèle, mais le coût d'un tel retour est évidemment bien plus élevé que celui d'une boucle fermée automatique comme la programmation. On ne peut exclure qu'à l'avenir, lorsque les données de retour s'accumuleront jusqu'à un certain point critique, les performances des agents intelligents dans des scénarios réels s'amélioreront considérablement, se rapprochant voire dépassant le niveau des professionnels. Mais comparé à la programmation, l'arrivée de ce point critique est encore loin.
Le passage difficile vers le monde physique
Le contenu principal des tâches juridiques reste le traitement de grandes quantités de texte, c'est un scénario à haut niveau de numérisation et qui sera certainement fortement numérisé. Lorsque la proportion des tâches pouvant être numérisées, pouvant être directement contrôlées et opérées à partir du monde numérique diminue, la proportion de tâches qu'un agent intelligent peut accomplir diminue également. Bien que la plupart des installations du monde réel soient pilotées par des logiciels, le simple fait de compter sur des agents intelligents écrivant du code pour contrôler le monde physique rencontre encore d'énormes obstacles.
Prenons l'exemple du développement des robots humanoïdes (humanoid robot). Bien qu'ils aient déjà dépassé les meilleurs résultats humains dans les marathons, les robots humanoïdes peinent encore dans la plupart des tâches du monde réel. Nettoyer, transporter, ouvrir des portes, traverser des scènes encombrées, ces actions faciles pour les humains sont des défis immenses pour les robots. C'est pourquoi Moravec (1988) disait : « Il est relativement facile de faire en sorte que les ordinateurs affichent des performances de niveau adulte dans les tests d'intelligence ou aux dames, et difficile voire impossible de leur donner les compétences d'un enfant d'un an en matière de perception et de mobilité. » Près de quarante ans plus tard, la pertinence de cette phrase ne fait qu'augmenter. Fei-Fei Li, dans son long article « From Words to Worlds », classe l'intelligence spatiale et l'intelligence incarnée parmi les objectifs à moyen terme nécessitant plus de temps pour mûrir. La raison en est que le monde réel n'a pas de compilateur, le monde physique n'accepte pas l'itération, seulement la validation, et le coût de la validation est toujours plus élevé que celui de la génération.
La technologie de simulation, sur laquelle on fondait beaucoup d'espoirs, a certes un certain effet, mais il reste encore un long chemin à parcourir pour atteindre une efficacité similaire à celle de l'adaptation autonome des Agents dans le scénario de programmation. La technologie de simulation vise à contourner le problème de l'absence de compilateur dans le monde physique, en construisant un espace de validation virtuel avec des jumeaux numériques et des moteurs physiques. Mais le développement de l'intelligence incarnée se heurte encore au fossé simulation-réalité (Sim-to-Real Gap) : les trajectoires de contrôle optimales obtenues avec des quantités massives de tokens dans un bac à sable simplifié deviennent extrêmement fragiles dès qu'elles rencontrent la friction, la fatigue des matériaux et le bruit environnemental du monde réel. Aljalbout et al., (2025) estiment que l'écart entre simulation et réalité n'est pas un problème unique, mais résulte de la superposition de plusieurs sous-écarts : différences de dynamique, distorsion de la perception, non-linéarité des actionneurs, défauts de conception du système, etc., et qu'un simulateur parfait est impossible d'un point de vue computationnel.
De plus, les stratégies d'entraînement par simulation ont tendance à exploiter des conditions aux limites inexactes mais déterminées dans la modélisation pour obtenir des performances artificiellement élevées. Mais lorsqu'elles sont déployées dans un environnement réel, ces stratégies sont souvent peu fiables, voire risquées. Par exemple, le projet Dactyl de la main dextre d'OpenAI, utilisant 64 GPU NVIDIA V100 et 920 serveurs CPU 32 cœurs, a accumulé dans la simulation une expérience d'entraînement équivalente à 13 000 années de travail, permettant à la main mécanique d'atteindre un très haut taux de réussite dans la manipulation d'un cube. Mais face à des changements non prédéfinis de matériau, température et usure dans le monde réel, la robustesse de la main dextre diminue rapidement. En 2021, OpenAI a dissout toute son équipe de robotique. Le co-fondateur Wojciech Zaremba, expliquant cette décision, a déclaré que les ressources devaient être redirigées vers des domaines où il est plus facile d'obtenir des résultats. Bien que le Sim-to-Real Gap n'ait pas été officiellement cité comme raison principale, l'industrie estime généralement que la contradiction entre le coût de calcul élevé de l'entraînement par simulation et l'incertitude du déploiement réel est un facteur important ayant poussé OpenAI à abandonner l'orientation robotique.
Valider les performances d'un modèle dans le monde physique réel coûte en temps et en capital plusieurs ordres de grandeur de plus que dans le monde virtuel, et un tel test réel ne peut être remplacé. Ce coût de validation asymétrique illustre d'un côté la particularité du scénario de programmation : les algorithmes ne sont pas omnipotents, et les tokens non plus.
Si la portée effective d'application des tokens reste longtemps confinée à la programmation et à quelques scénarios numériques, sans jamais pouvoir franchir le fossé entre le monde numérique et le monde physique, la durabilité de l'industrialisation de l'IA et de l'AI-fication des industries est mise en doute. L'avenir de l'économie des tokens dépend de notre capacité à étendre la portée effective des tokens des îlots numériques vers le monde réel plus vaste. Avant que la demande réelle du monde physique n'explose, la non-économie des tokens pourrait durer longtemps.
Les risques de débordement de la non-économie des tokens
La non-économie des tokens n'est pas répartie de manière homogène sur toute la chaîne industrielle de l'IA. Les fournisseurs d'infrastructures et de matériel en amont font des profits énormes dans l'actuel boom des investissements en capital fixe ; les fabricants de modèles au milieu de la chaîne rivalisent encore sur les performances des produits, leurs dépenses en capital élevées comprimant leur trésorerie ; les effets des applications en aval varient selon les personnes et les scénarios, la plupart des entreprises adoptent encore une position d'attente. Les risques de la chaîne industrielle se concentrent sur le milieu, et les fabricants de modèles au milieu sont en train d'établir de petits cercles de financement cyclique sur les marchés de capitaux. Une fois accumulé, le risque de non-économie des tokens, s'il éclate, affectera nécessairement les marchés financiers, voire la stabilité des moyens de subsistance.
La répartition inégale des risques dans la chaîne industrielle
La ruée vers les Tokens-Agents attire des capitaux massifs vers les centres de données, les réseaux et la fabrication de puces en amont, ainsi que vers les infrastructures électriques et énergétiques. Les dépenses en capital de TSMC devraient atteindre 520 à 560 milliards de dollars en 2026 ; les investissements en infrastructures IA de Microsoft, Alphabet, Amazon et Meta entre 2025 et 2026 dépassent largement 3 000 milliards de dollars et se rapprochent du niveau des 7 000 milliards de dollars. Les fabricants de grands modèles au milieu de la chaîne sont les moteurs de cette vague d'investissement en IA, le point d'ancrage de tous les optimistes concernant l'IA, « l'espoir de tout le village ». Mais les principaux fabricants, bien que leurs revenus explosent, restent profondément en perte, et le coût d'achat de puissance de calcul reste élevé. OpenAI ne prévoit d'être rentable qu'aux alentours de 2030. Quant aux entreprises utilisatrices en aval qui utilisent réellement des Agents et brûlent des tokens, elles commencent déjà à contrôler les coûts. Après tout, ne voyant pas encore de retour raisonnable, fixer des plafonds budgétaires pour les tokens, attribuer les coûts, resserrer les autorisations d'utilisation sont des actions de gestion logiques.
Nous avons comparé les changements de flux de trésorerie libre (FCF = flux de trésorerie d'exploitation - dépenses en capital) des deux dernières années et le taux de marge nette de l'année dernière (Figure 4) pour des sociétés cotées représentatives en amont et en aval de la chaîne industrielle de l'IA. En 2025, TSMC (44,5 %) et NVIDIA (55,6 %), situés en amont de la chaîne, non seulement avaient des taux de marge nette plus élevés, mais leurs flux de trésorerie libre ont également connu une croissance rapide de 14,5 % et 58,8 %. En comparaison, Amazon, Microsoft et Meta, situés en aval de la chaîne, bien que leurs taux de marge nette soient stables voire en hausse par rapport aux années précédentes, ont vu leurs flux de trésorerie libre baisser respectivement de 76,6 %, 14,8 % et 3,4 %, principalement en raison de l'augmentation massive des dépenses en capital. La mine d'or des Tokens n'est pas encore prouvée, ceux qui creusent l'or investissent encore, et ceux qui vendent les pelles se remplissent déjà les poches.
Cette situation s'est répétée plusieurs fois dans l'histoire. Au début d'une révolution industrielle, avec l'émergence de nouvelles technologies, la demande explose d'abord du côté des investissements et en amont de l'industrie, les énormes dépenses en capital du milieu deviennent d'énormes profits pour l'amont, tandis que la consommation finale en aval est encore naissante, insuffisante pour soutenir l'expansion des capacités des entreprises du milieu. Les risques convergent vers le milieu de l'industrie, le capital et les capacités précèdent la demande payante réelle. À court terme, des réévaluations, des capacités inutilisées, la sortie de certains participants sont presque inévitables ; à long terme, tant que la demande sous-jacente finit par se concrétiser, les centres de données, puces et réseaux construits en avance trouveront encore leur utilité, devenant la base de productivité soutenant la croissance économique. Pour le grand public et les régulateurs, il faut se prémunir contre la transmission des risques de la chaîne industrielle vers l'extérieur via les marchés financiers, et les fortes fluctuations économiques résultant d'un débordement des risques.
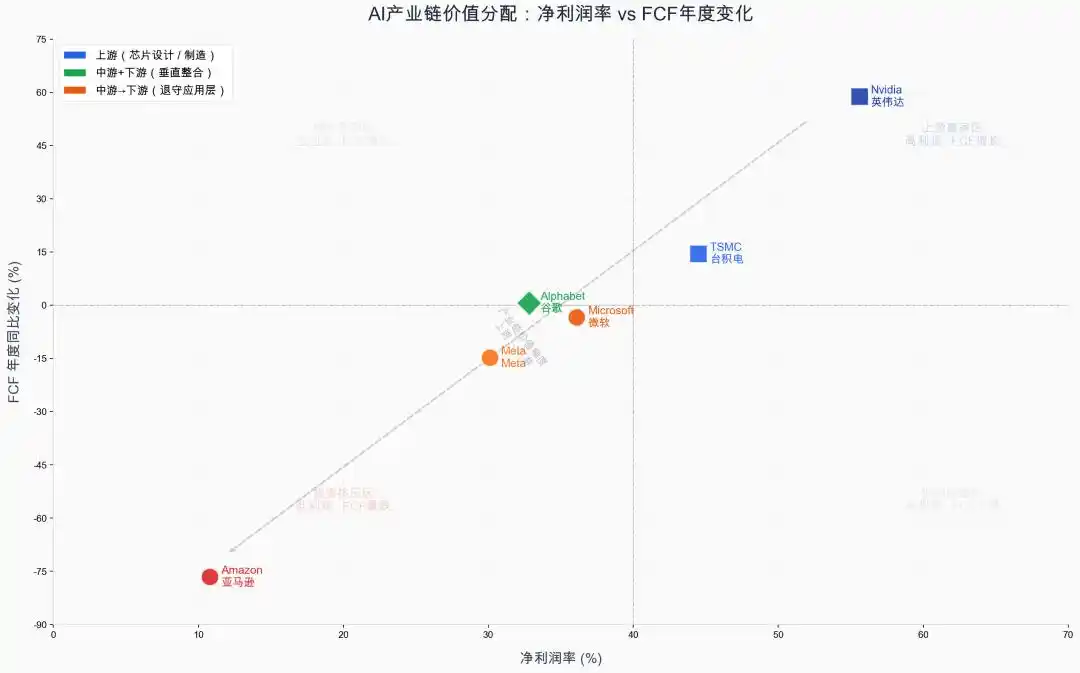
Figure 4 : Comparaison du taux de croissance du flux de trésorerie libre et du taux de marge nette en amont et en aval de la chaîne industrielle de l'IA (Exercice 2025—2026). Source des données : rapports annuels des sociétés, dépôts 10-k SEC. Dessin : Codebuddy
Le financement circulaire et le crédit parallèle
Les risques de la chaîne industrielle se concentrent sur les fabricants de modèles du milieu, et certains fabricants de modèles du milieu jouent au financement circulaire (circular financing) avec les entreprises de matériel en amont, rendant difficile de discerner s'il s'agit d'une croissance réelle tirée par la technologie ou d'un jeu d'évaluation soutenu par un cycle de capital auto-entretenu. Par exemple, la « machine perpétuelle d'IA » formée par OpenAI, NVIDIA et Oracle : d'abord, OpenAI accepte un investissement stratégique de NVIDIA (initialement promis à 1 000 milliards de dollars, ensuite transformé en participation au nouveau tour de financement d'OpenAI, le montant de l'investissement étant également fortement réduit) ; ensuite, OpenAI utilise les fonds levés pour acheter des services cloud à Oracle (les deux parties signent un contrat d'achat de puissance de calcul d'environ 3 000 milliards de dollars sur 5 ans) ; enfin, Oracle utilise l'engagement de paiement d'OpenAI pour renforcer sa crédibilité, émet des obligations pour lever des fonds et acheter des GPU à NVIDIA pour la construction de centres de calcul, bouclant la boucle des fonds. Chaque étape semble avoir une logique commerciale raisonnable, mais chaque étape semble aussi trop « en avance ».
Le cadre d'achat de puissance de calcul d'OpenAI totalise désormais plus de 10 000 milliards de dollars, ce qui ne correspond pas à ses revenus annualisés actuels de 330 milliards de dollars (ARR jusqu'en mai 2026), et repose entièrement sur l'attente d'une croissance future élevée. Si la consommation finale de tokens en aval ne génère pas une croissance exponentielle des revenus des fabricants de modèles, les « promesses » se transformeront en « bulle ». Et les perspectives de consommation finale de tokens ne semblent pas optimistes. Selon les calculs de Bain & Company, pour absorber les 200 GW de puissance de calcul supplémentaires d'ici 2030, la consommation finale doit générer environ 2 000 milliards de dollars de nouveaux revenus annuels. Mais même en comptant les économies de coûts apportées par l'IA, il reste encore un déficit d'environ 800 milliards de dollars.
Ce jeu de financement circulaire est également apparu à l'époque de la bulle internet du tournant du siècle, mais aujourd'hui, la moitié de la bulle d'évaluation est cachée dans le marché opaque du crédit privé (private credit), ce qui rend plus difficile d'appréhender précisément les risques potentiels. La hausse des taux par la Fed a augmenté les intérêts sur les marchés obligataires à haut risque comme les startups, les rachats par emprunt, les banques, sous les exigences de Bâle, ont dû se retirer de ce marché, laissant un espace aux institutions privées, donnant finalement naissance à un marché américain du crédit privé d'environ 3 000 milliards de dollars.
Des sociétés de gestion d'actifs comme Apollo, Ares, Blue Owl, KKR, Blackstone utilisent des BDC (sociétés de développement commercial) et des prêts directs pour fournir un financement par emprunt de 20 à 30 ans pour la construction de centres de données. Ces prêts sont souvent négociés en privé, tarifés par modèles (mark-to-model), peuvent présenter des inadéquations de durée (adapter des flux de trésorerie sur 30 ans à des technologies comme les LLM qui évoluent mensuellement), et comme les fabricants de modèles manquent de liquidités, les intérêts sont souvent payés en nature (PIK, les intérêts sont directement capitalisés), les risques se cumulent et sont difficiles à percevoir.
Un rapport de la Banque des Règlements Internationaux indique que le marché des actions, en primaire et en secondaire, a déjà pleinement valorisé le potentiel haussier de la chaîne industrielle de l'IA, mais le marché de la dette n'a pas encore intégré le risque de baisse. Si la libération de la demande en aval est lente, les revenus inférieurs aux attentes, la logique d'évaluation du financement circulaire s'effondrera (compression des actions), les modèles dans le crédit privé devront être réévalués (dépréciation des crédits), le risque d'éclatement de la bulle et de double baisse actions/obligations augmente brusquement.
La soif de ressources comprime les autres demandes
La consommation de tokens, en stimulant l'expansion de la puissance de calcul, rend les centres de calcul extrêmement voraces en ressources comme l'eau et l'électricité, créant souvent à court terme d'énormes déficits d'offre et exerçant un effet d'éviction sur l'approvisionnement en eau et en électricité des populations locales.
La « Data Center Alley » dans le nord de la Virginie concentre les grappes de centres de données les plus denses au monde, supportant environ 70 % du trafic internet mondial. Comme la capacité du réseau électrique local est verrouillée à l'avance par des accords de vente en gros à long terme avec les entreprises technologiques, les quotas d'énergie pour les résidents et les commerces traditionnels sont sérieusement comprimés. Selon un rapport publié en décembre 2024 par la Commission mixte législative d'audit et d'examen de Virginie (JLARC), la consommation électrique des centres de données a déjà dépassé le double de la production de la plus grande centrale nucléaire de Virginie, et seulement pour satisfaire les besoins énergétiques des centres de données planifiés ou en construction dans le comté de Loudoun, il faudrait ajouter au réseau d'ici 2030 une capacité de production équivalente à plusieurs centrales nucléaires.
La course effrénée des centres de données aux lignes de transmission à haute tension et à l'énergie propre force les entreprises de services publics locaux à dépenser des sommes considérables pour moderniser le réseau électrique. Dominion Energy prévoit d'investir des dizaines de milliards de dollars dans l'expansion du réseau au cours des quinze prochaines années. Cette énorme dépense d'infrastructure sera finalement répercutée sur les factures mensuelles des résidents sous forme de frais d'entretien du réseau, de frais de capacité, etc. Le prix des enchères de capacité dans la zone de service de Dominion est passé de 29 $/MW-jour à 444 $/MW-jour, une augmentation de plus de 1400 %, reflétant directement la grave rareté de la capacité de production et de transmission du réseau. L'analyse par le Piedmont Environmental Council (PEC) du plan intégré de ressources (IRP) de Dominion Energy montre que, sur la période couverte par ce plan, la facture d'électricité d'un résident ordinaire pourrait doubler.
L'effet d'éviction de l'expansion de la puissance de calcul sur la demande quotidienne ne se limite pas à la Virginie ; des nœuds de calcul majeurs mondiaux comme Dublin en Irlande, Jurong à Singapour, ou le Guizhou en Chine ont connu des contradictions similaires. En ce sens, la non-économie des tokens n'existe pas seulement dans le monde numérique, elle projette aussi une longue ombre dans la vie réelle.
Trouver l'équation de valeur du token
Le token est l'un des facteurs de production les plus fondamentaux de l'ère intelligente. Comme tous les autres facteurs de production, terre, données, capital, main-d'œuvre, tant qu'il existe une mauvaise allocation des ressources, un gaspillage des facteurs, il y aura nécessairement ce qu'on appelle de la « non-économie ». En ce sens, la non-économie des tokens ne sera pas seulement un phénomène temporaire au début de l'explosion de la chaîne industrielle de l'IA, mais coexistera avec l'économie des tokens, traversant toute l'évolution de l'économie intelligente. Dans le présent concret, l'économie des tokens ne s'est pas encore pleinement manifestée, donc la non-économie des tokens est relativement plus saillante.
Une existence permanente ne signifie pas qu'il faut laisser faire. On peut agir des deux côtés, offre et demande, pour réduire la non-économie des tokens, renforcer l'économie des tokens, et transformer véritablement le développement technologique en valeur économique tangible. Du côté de l'offre, on peut réduire le coût unitaire du token par des moyens techniques fins, colmater les fuites et les gaspillages, prévenir la diffusion des risques ; du côté de la demande, on peut constamment découvrir de nouveaux scénarios d'application pour que les tokens soient dépensés de manière valorisante. Lorsque la courbe de baisse des coûts du côté offre croise la courbe de hausse de la valeur du côté demande, le bénéfice net après compensation mutuelle de l'économie et de la non-économie des tokens peut passer de négatif à positif.
Les changements fins du côté technique
Mise en cache du contexte et compression sémantique. La mise en cache du contexte (Context Caching) est déjà une pratique courante chez les fabricants de modèles. Lorsque les pipelines multi-agents frappent fréquemment le cache historique, la facturation des tokens d'entrée est fortement réduite. Mais cette pratique a aussi ses limites ; dans les déploiements complexes de niveau entreprise, en raison de l'échec de dispersion du cache causé par la forte ramification des chemins des Agents, l'effet réel d'économie de coûts est relativement limité. Une solution plus fondamentale réside dans la compression du contexte, non pas un simple tronçonnage glissant des informations historiques, mais une compression active au niveau sémantique, préservant les instructions clés et les chaînes de raisonnement, éliminant les répétitions et les redondances. Cette compression sémantique du contexte (Semantic Context Compression) peut, tout en protégeant le taux de suivi des instructions, réduire significativement la consommation de tokens d'entrée.
Optimisation des compétences et pensée de soustraction. L'étude SkillReducer de Gao et al., (2026) propose deux voies pour optimiser les compétences. Premièrement, la compression des descriptions : ajouter des informations concises aux compétences manquant de descriptions de routage, comprimer les explications de contexte et exemples redondants. Deuxièmement, le chargement progressif : ne pas injecter la compétence complète en une fois dans le contexte, mais charger à la demande, permettant une compression de 39 % du volume des compétences. Combinées, ces deux méthodes permettent, tout en réduisant fortement la consommation de tokens des appels de compétences, d'améliorer la qualité fonctionnelle du modèle de 2,8 %. On en déduit que les appels de compétences des Agents ne sont pas « plus, mieux » ; quand c'est nécessaire, faire des soustractions rapporte bien plus que faire des additions. Réduire les informations inefficaces dans le contexte permet non seulement de baisser la consommation de tokens, mais aussi d'améliorer la précision de la sortie du modèle. « Less is more » n'est pas seulement une beauté du code ici, mais rend aussi les tokens plus économiques.
Routage des modèles et dérivation des tâches. Utiliser un gros modèle pour une tâche simple est une importante source de gaspillage de tokens. Faire un routage adaptatif des modèles (Model Routing) selon la complexité de la tâche, déléguer les sous-tâches simples et fréquentes à des modèles légers open source dotés de capacités spécifiques à un domaine, et n'utiliser les coûteux modèles Frontier qu'aux points de décision critiques. Un tel appel en couches peut réduire fortement le coût moyen en tokens par tâche, sans sacrifier la qualité des étapes clés.
Contrainte budgétaire stricte des multi-agents et architecture d'animateur. Un système multi-agents sans division du travail, plafond budgétaire et conditions d'arrêt claires a une probabilité bien plus grande de se transformer en discussion marathon. La solution réside dans la conception, au sein du réseau de collaboration multi-agents, d'une architecture d'animateur dotée de contraintes budgétaires strictes (Hard Budget Constraints) et d'un mécanisme d'arbitrage asynchrone. La méthode de recherche par arbre de Monte-Carlo proposée par Luo et al., (2026), ajoute une validation intermédiaire des outils dans le processus multi-agents, sauvegarde les états candidats, permet un retour en arrière si nécessaire. On peut élever cette idée du niveau du raisonnement à celui de l'architecture, fixer un plafond budgétaire en tokens pour chaque sous-tâche, faire surveiller la consommation globale par un Agent animateur, forcer l'arrêt des boucles inefficaces avant épuisement du budget. Cela peut non seulement prévenir une perte de contrôle financier, mais aussi souvent améliorer l'efficacité globale du système.
L'ancrage de valeur du côté commercial
Gouvernance des tokens et discipline des coûts. Microsoft limitant Claude Code, Meta retirant le classement de consommation de tokens, les grands fabricants sont déjà passés du simple encouragement de la consommation de tokens à la mise en avant de la production et de la discipline des coûts liés aux tokens. Les quotas, approbations, routage des modèles, attribution des coûts, facturation par équipe, ces mesures deviendront très probablement à l'avenir des méthodes de base de la gouvernance IA en entreprise. C'est une étape inévitable lorsque l'IA entre dans les systèmes de production ; même si l'IA est un outil puissant pour favoriser l'innovation et accélérer la production, les comptes doivent être clairs. Combien de tokens sont utilisés, quelle production vérifiable est générée, combien de retouches sont causées, tout doit être mesuré. Sans mesure, pas de gestion ; sans plafond, pas de discipline. Les entreprises véritablement avancées ne mesureront pas celles qui utilisent le plus d'IA, mais celles qui accomplissent le plus de travail avec le moins de tokens.
Le rationnement deviendra la norme. Les entreprises ne fourniront pas de tokens de manière illimitée, mais, comme pour les ressources cloud, fixeront des pools budgétaires et des processus d'approbation. Cette gouvernance n'est pas opposée à l'innovation technologique ; au contraire, le rationnement forcera les architectes à concevoir des systèmes d'Agents plus efficaces, internalisant la contrainte de coût.
Trouver des scénarios commerciaux réels pour l'application à grande échelle des tokens. C'est la clé fondamentale pour réaliser le passage à un bénéfice net positif des tokens. La programmation et l'architecture Agent ne sont qu'un petit pas vers l'économie des tokens. Trouver des scénarios commerciaux pouvant générer un énorme bond de productivité est la condition préalable pour entrer dans la voie rapide du développement de l'économie des tokens et réaliser une énorme création de valeur économique. Actuellement, les cas d'application à grande échelle de l'architecture Agent dans des scénarios commerciaux réels apportant d'énormes bénéfices sont encore rares, et souvent des cas particuliers. Les solutions universelles largement applicables à d'autres entreprises, d'autres secteurs, sont encore en gestation.
L'intelligence incarnée et les jumeaux numériques sont des directions d'expansion, mais il faut faire face au coût de validation asymétrique lié au Sim-to-Real Gap. Une voie plus pragmatique est de chercher, dans les secteurs traditionnels, des zones intermédiaires avec des retours faiblement déterminés, comme le dépistage par imagerie dans l'aide au diagnostic (avec des normes d'imagerie pour référence), la prévision de la demande dans la chaîne d'approvisionnement (avec des données historiques pour rétro-tester), le tri initial des contrats dans le domaine juridique (avec des modèles de clauses pour comparer). Le coût de validation de ces scénarios, bien que loin d'être proche de zéro comme un compilateur, est bien inférieur à celui d'une validation purement physique ; ils pourraient devenir des ponts permettant à l'économie des tokens de passer du bac à sable numérique au monde réel. Les recherches récentes d'OpenAI sur la robotique indiquent que l'intelligence incarnée, bien que difficile, ne peut être contournée indéfiniment.
Retour au ROI
Tout investissement dont la valeur créée dépasse le coût engagé, quelle que soit l'avancée de la technologie, finira par être insoutenable. La non-économie des tokens n'est pas un échec technologique, mais une difficulté temporaire souvent rencontrée lorsque la technologie passe à une production à grande échelle. Comme la machine à vapeur au début de la révolution industrielle, inefficace, avide de charbon, cela ne nie pas que la machine à vapeur représente l'avenir du développement des forces productives. En améliorant continuellement l'efficacité thermique, en élargissant les scénarios d'application, la force motrice à vapeur est finalement devenue la force la plus fondamentale entraînant la première étape de la révolution industrielle. Les tokens et l'architecture Agent d'aujourd'hui sont comme les premières machines à vapeur : bruyantes, gourmandes, mais montrant déjà dans des scénarios spécifiques un potentiel bien supérieur à la force humaine. Leur développement ultérieur sera nécessairement une succession de révolutions technologiques, de l'extensif au fin ; à l'avenir, l'Agent le plus précieux ne sera pas celui dont la chaîne de pensée est la plus complexe, mais celui qui accomplit le travail avec le moins de tokens. Lorsque l'industrie passera de la phase de démonstration technique « fière d'en faire beaucoup » à la phase de production « fière de la finesse », lorsque chaque token consommé devra répondre à la question de la valeur produite, lorsque les tokens reviendront à l'étalon-or du ROI, l'ère des agents intelligents aura trouvé sa propre équation de valeur.
Cet article provient du compte WeChat public « Institut de recherche de Tencent » (ID: cyberlawrc), auteur : Li Gang





