Aujourd'hui, nous lançons une nouvelle mise à jour pour la commande /usage, conçue pour vous aider à mieux comprendre votre utilisation de Claude Code. Cette décision fait suite à de nombreuses conversations approfondies que nous avons eues récemment avec nos utilisateurs.
Lors de ces échanges, un phénomène est revenu sans cesse : les habitudes de chacun en matière de gestion des sessions sont extrêmement variées. Cette différence est d'autant plus marquée depuis que Claude Code a porté sa fenêtre contextuelle (Context Window) à la barre symbolique du million.
Êtes-vous du genre à ne garder qu'une ou deux sessions ouvertes dans votre terminal ? Ou préférez-vous ouvrir une nouvelle session à chaque nouveau prompt ? À quel moment utilisez-vous généralement la compression (Compact), le retour en arrière (Rewind) ou les sous-agents (Subagents) ? Et qu'est-ce qui cause une compression ratée ?
Il y a en réalité toute une science derrière cela. Ces détails en apparence anodins influencent considérablement votre expérience d'utilisation de Claude Code. Et tout cela se résume à une chose : comment gérer votre fenêtre contextuelle.
Petit cours accéléré : Contexte, compression contextuelle et dégradation du contexte
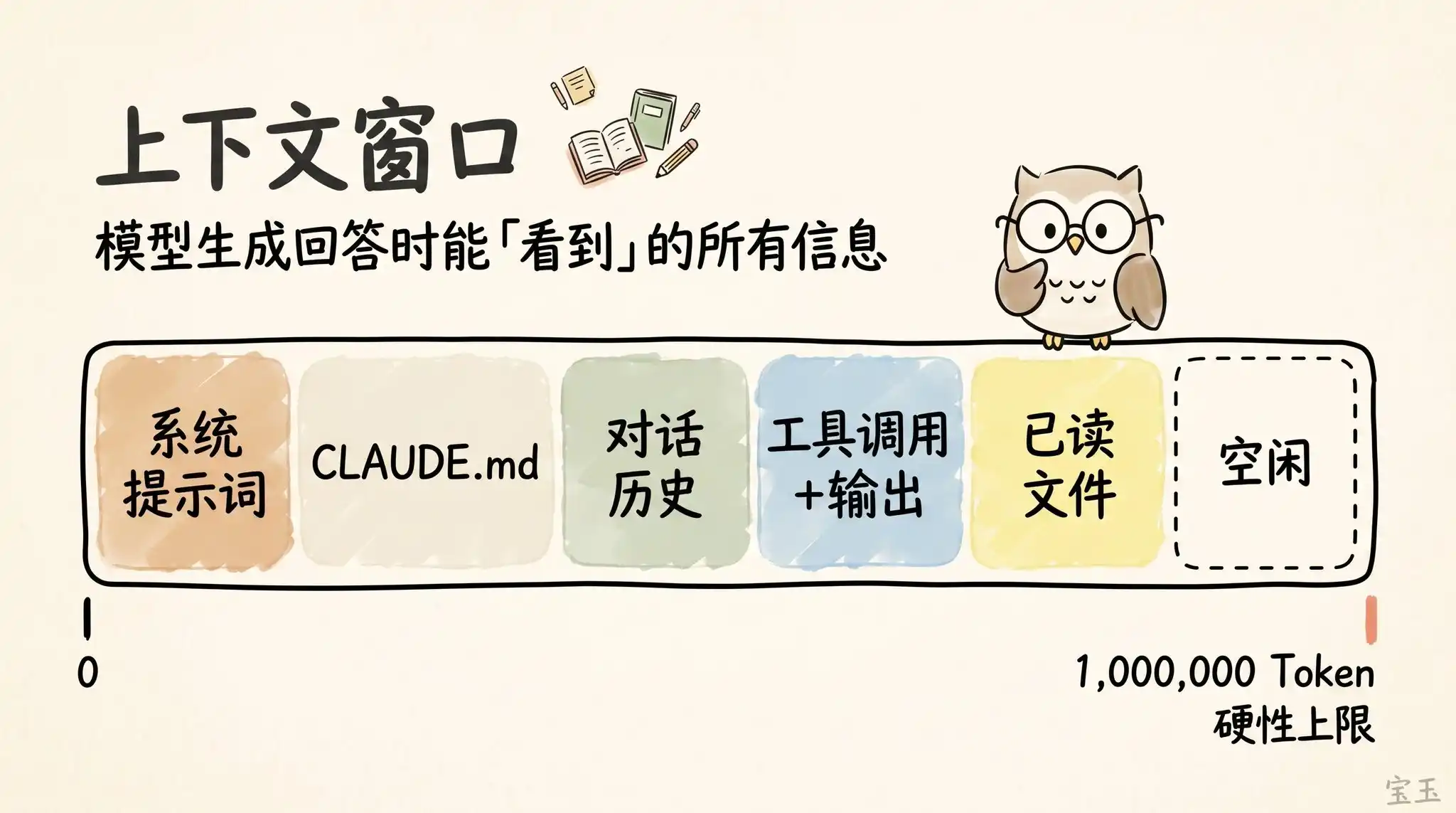
La « fenêtre contextuelle (Context Window) » est, par analogie, l'ensemble des informations que le modèle peut « voir » simultanément devant lui lorsqu'il génère sa prochaine réponse. Elle inclut votre prompt système (System Prompt), l'historique de la conversation jusqu'à présent, chaque appel d'outil (Tool Call) et ses résultats, et même chaque fichier qu'il a lu. Aujourd'hui, Claude Code dispose d'une fenêtre contextuelle gigantesque de jusqu'à 1 million de tokens(Note : Un Token est l'unité de base de traitement du texte pour les grands modèles de langage. Un mot anglais équivaut généralement à 1 Token, un caractère chinois peut en prendre 1 à 2).
Malheureusement, utiliser le contexte a un coût, que nous appelons généralement la dégradation du contexte (Context Rot)(Note : Phénomène où, à mesure que l'historique de la conversation s'allonge, le modèle doit traiter un volume d'information trop important, ce qui disperse son attention, lui fait oublier des informations importantes du début ou est perturbé par du contenu sans rapport). Plus le contexte devient long, plus les performances du modèle ont tendance à se dégrader, car son attention est dispersée sur davantage de Tokens. Le contenu laissé depuis le début, devenu sans importance, commence à interférer avec la tâche que le modèle est en train d'exécuter.
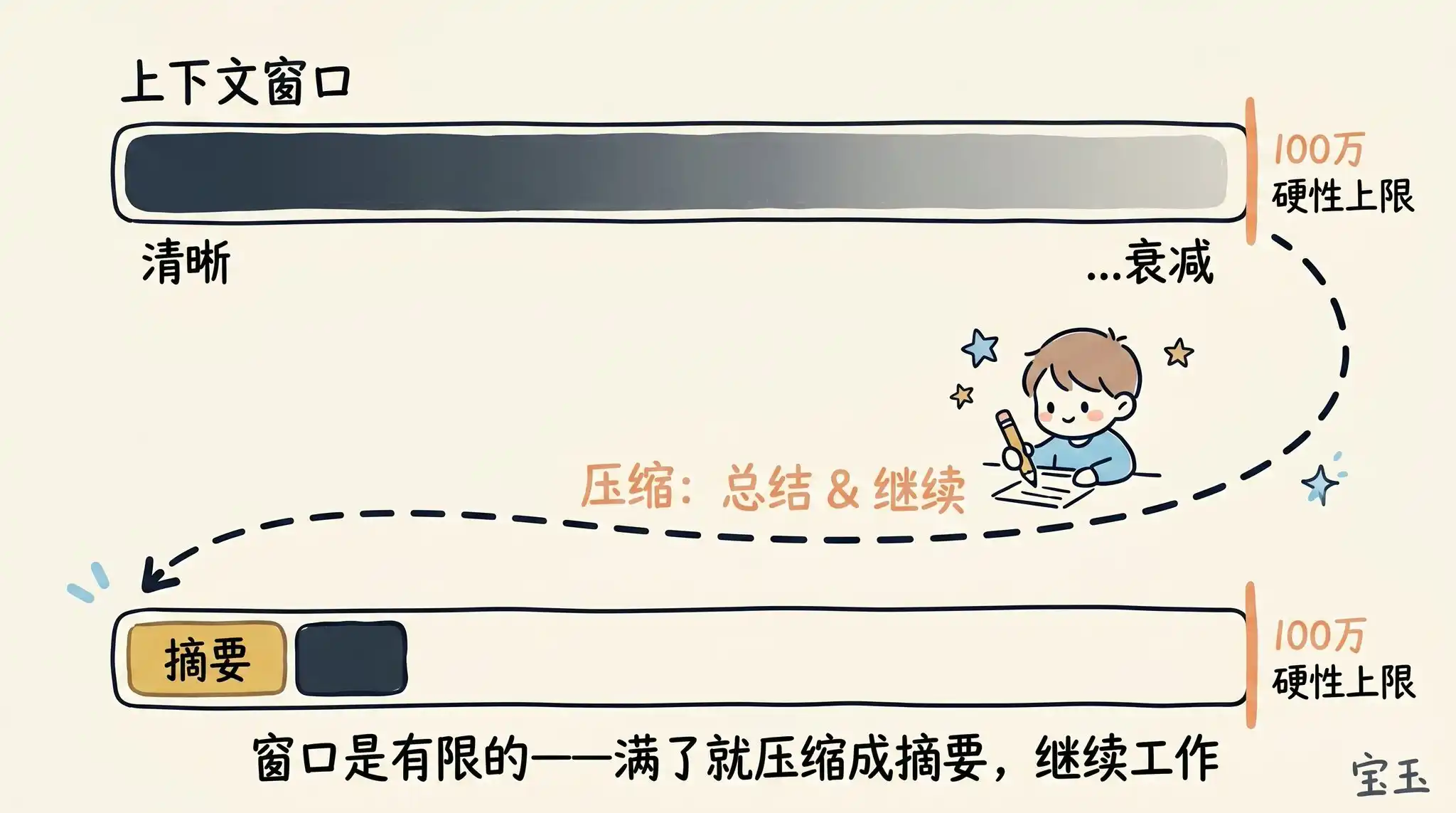
La fenêtre contextuelle a une limite de capacité fixe. Ainsi, lorsque vous êtes sur le point de la saturer, vous devez résumer la tâche en cours en une brève description, puis continuer votre travail avec cette description dans une nouvelle fenêtre contextuelle.
Nous appelons ce processus la compression contextuelle (Compaction)(Note : Processus consistant à résumer un historique très long en un résumé succinct pour libérer de l'espace mémoire). Bien sûr, vous pouvez également déclencher manuellement cette compression à tout moment.
Imaginez que vous venez de demander à Claude de faire quelque chose pour vous, et il a terminé. Maintenant, votre contexte contient déjà certaines informations (comme des appels d'outils, leurs résultats, vos instructions).
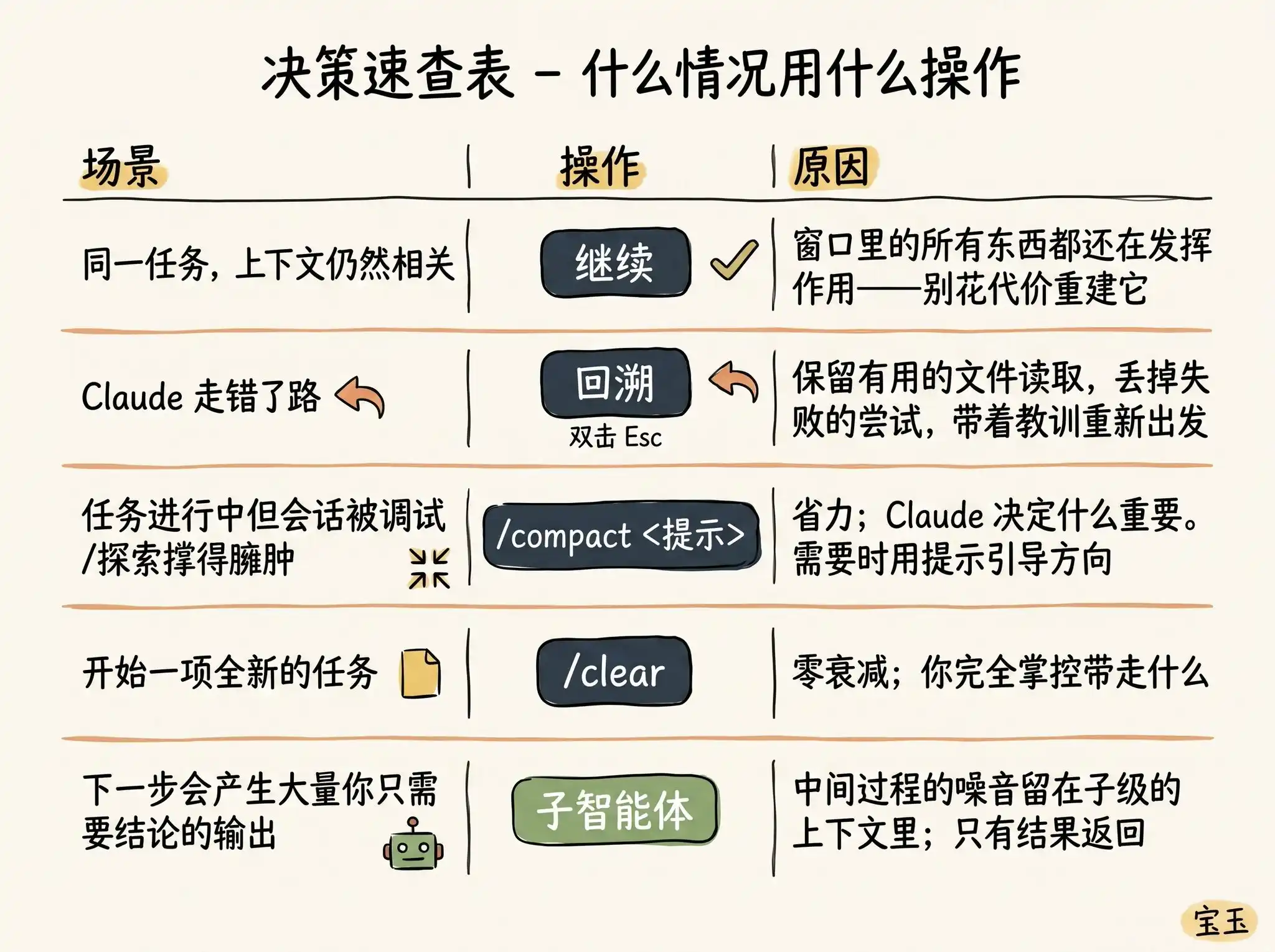
Que faire ensuite ? Vous seriez surpris de voir à quel point vous avez d'options :
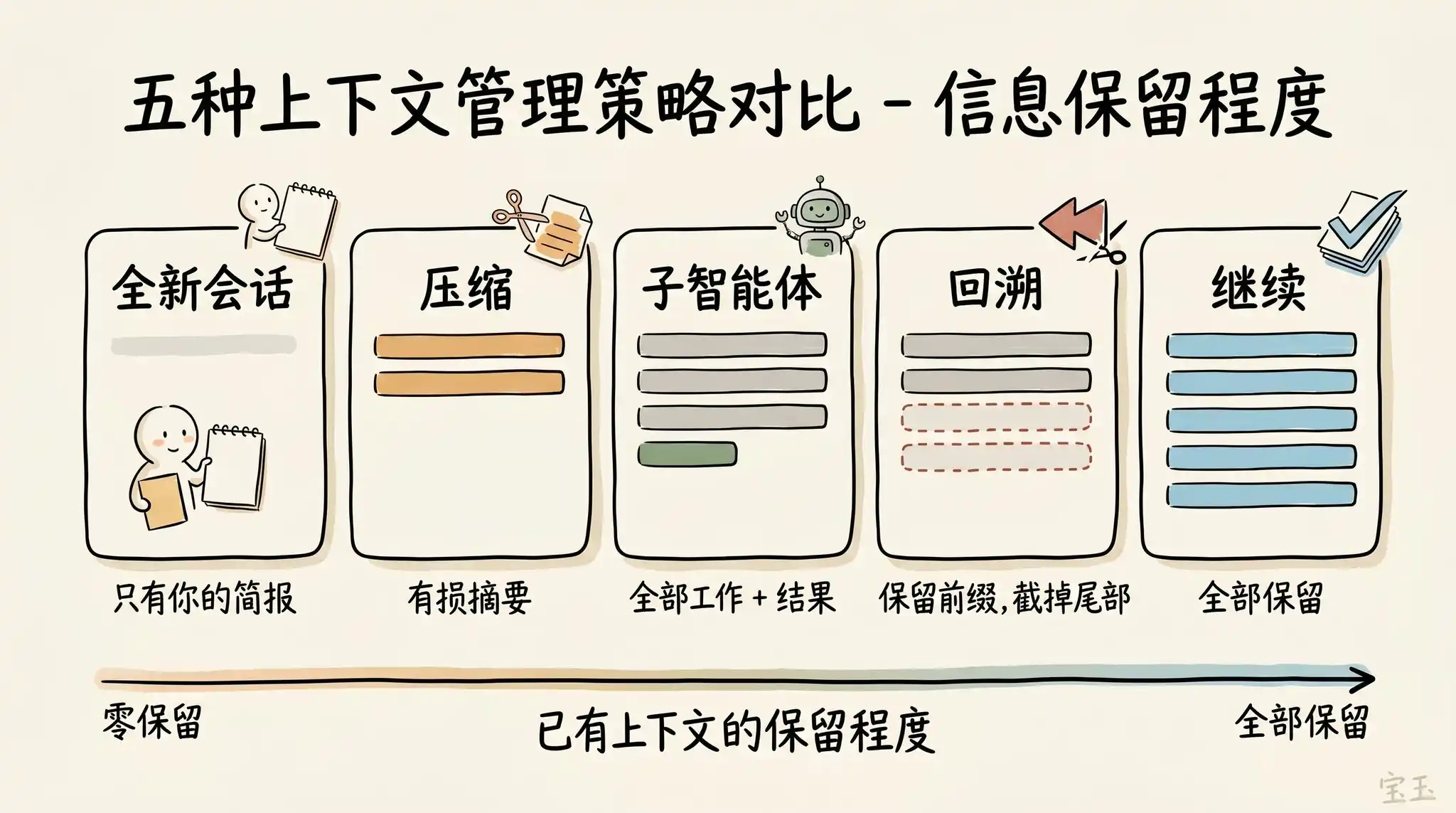
· Continuer (Continue) — Envoyer directement le message suivant dans la même session.
· Retour en arrière (/rewind ou double appui sur la touche Esc) — Remonter le temps, revenir à un message précédent et réessayer à partir de là.
· Effacer (/clear) — Démarrer une toute nouvelle session, généralement avec le résumé succinct que vous avez tiré de la conversation précédente.
· Compresser (Compact) — Résumer la conversation actuelle, puis continuer à travailler sur la base de ce résumé.
· Sous-agents (Subagents) — Déléguer la prochaine phase du travail à un autre agent IA (AI Agent) disposant de son propre contexte propre, et ne récupérer que son résultat final.
Bien que « Continuer » soit la réaction la plus naturelle, les quatre autres options sont conçues précisément pour vous aider à mieux gérer votre contexte.
Quand faut-il ouvrir une nouvelle session ?
Quand exactement faut-il maintenir une longue session existante, et quand faut-il recommencer à zéro ? Notre règle empirique est la suivante : lorsque vous commencez une nouvelle tâche, vous devriez également ouvrir une nouvelle session.
La fenêtre d'un million de tokens signifie que vous pouvez maintenant accomplir de manière très fiable des tâches plus longues et plus complexes. Par exemple, demandez à Claude de construire une application full-stack pour vous à partir de zéro.
Mais parfois, vous travaillez peut-être sur des tâches séquentielles. Dans ce cas, vous devez conserver une partie du contexte précédent, mais pas la totalité. Par exemple, vous venez de terminer l'écriture d'une nouvelle fonctionnalité et devez maintenant rédiger sa documentation. Vous pourriez ouvrir une nouvelle session, mais cela signifierait que Claude devrait relire tous les fichiers de code que vous venez d'écrire – ce qui est non seulement plus lent, mais aussi plus coûteux.
Utiliser le « retour en arrière » au lieu de « corriger »
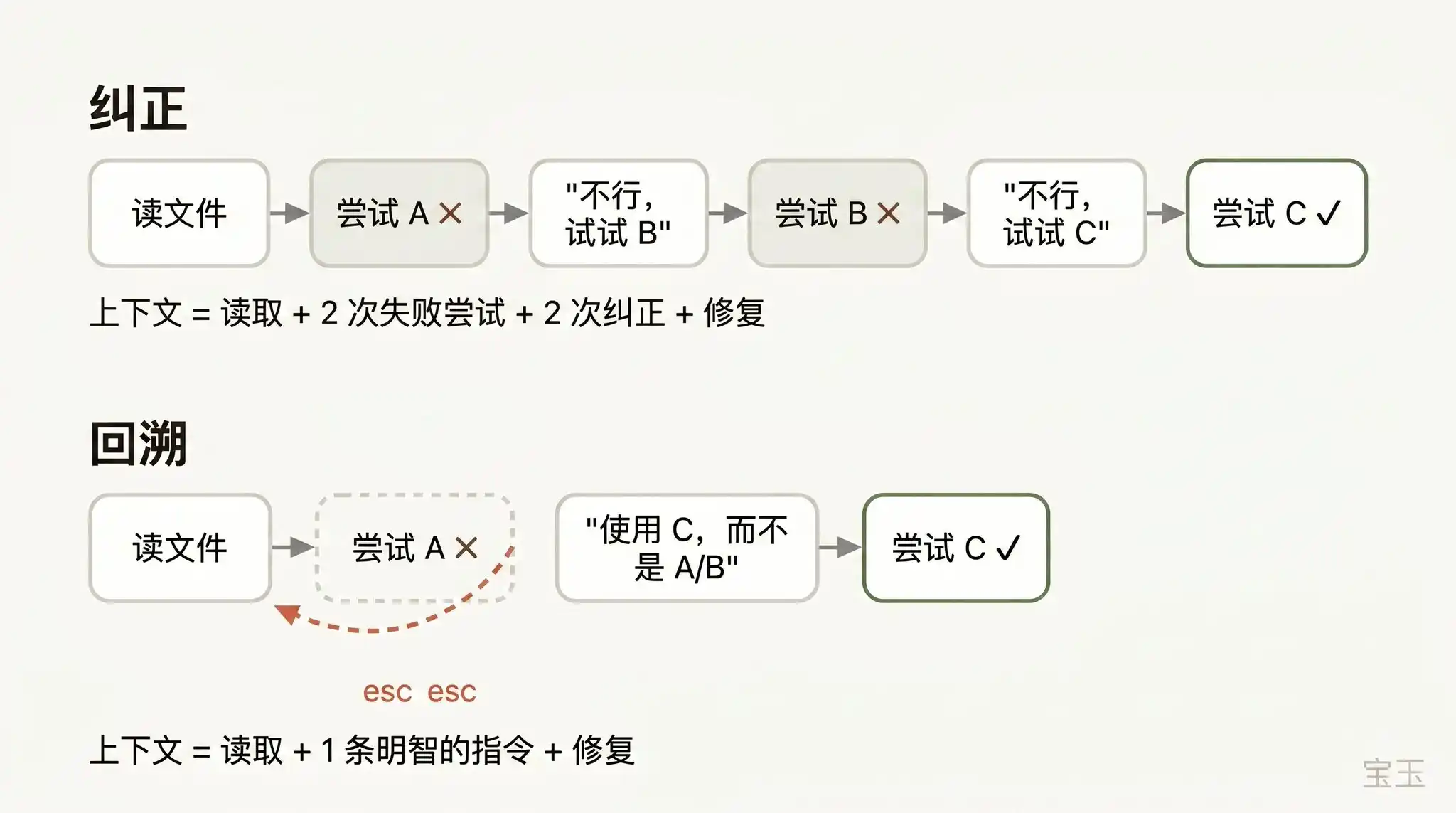
Si je devais choisir une seule bonne habitude représentant une « excellente capacité de gestion du contexte », ce serait certainement de bien utiliser le « retour en arrière (Rewind) ».
Dans Claude Code, un double-clic sur la touche Esc (ou l'exécution de la commande /rewind) vous permet de revenir à n'importe quel message précédent, puis de soumettre un nouveau prompt à partir de là. Toute la conversation survenue après ce point sera complètement supprimée du contexte.
Lorsqu'il s'agit de corriger une erreur de l'IA, le « retour en arrière » est souvent l'approche la plus judicieuse. Exemple : Claude a lu cinq fichiers, a essayé une méthode, qui a échoué. Votre réflexe instinctif pourrait être de taper dans la zone de chat : « Ça ne marche pas, essayez la méthode X. » Mais l'approche plus intelligente serait de revenir en arrière au moment où il venait juste de lire ces cinq fichiers, et de lui redire avec la leçon que vous venez d'apprendre : « N'utilisez pas la méthode A, le module foo ne la supporte pas du tout – essayez directement la méthode B. »
Vous pouvez même utiliser la fonctionnalité « résumer à partir d'ici (summarize from here) » pour demander à Claude de résumer lui-même les leçons apprises en un « message de passation ». C'est un peu comme si la « version future de Claude » qui vient de se planter laissait un mot au « Claude du passé » qui n'a pas encore commencé.

Compression contextuelle vs Nouvelle session
Lorsqu'une session devient de plus en plus longue, vous avez deux méthodes pour l'« alléger » : utiliser /compact (compression) ou /clear (effacer et recommencer à zéro). Ces deux opérations semblent similaires mais se comportent très différemment.
Compression (Compact) demande au modèle de résumer la conversation jusqu'à présent, puis de remplacer le long historique par ce résumé. Ce processus est « avec perte », ce qui signifie que vous confiez à Claude le pouvoir de décider « quel contenu est important ».
L'avantage est que vous n'avez rien à écrire, et Claude peut être plus attentif que vous ne le pensez à conserver les leçons importantes ou les enregistrements de fichiers. Vous pouvez également contrôler la direction de la compression en lui donnant des instructions (ex: /compact en se concentrant sur la refactorisation du module d'authentification, en supprimant le contenu sur les tests de débogage).
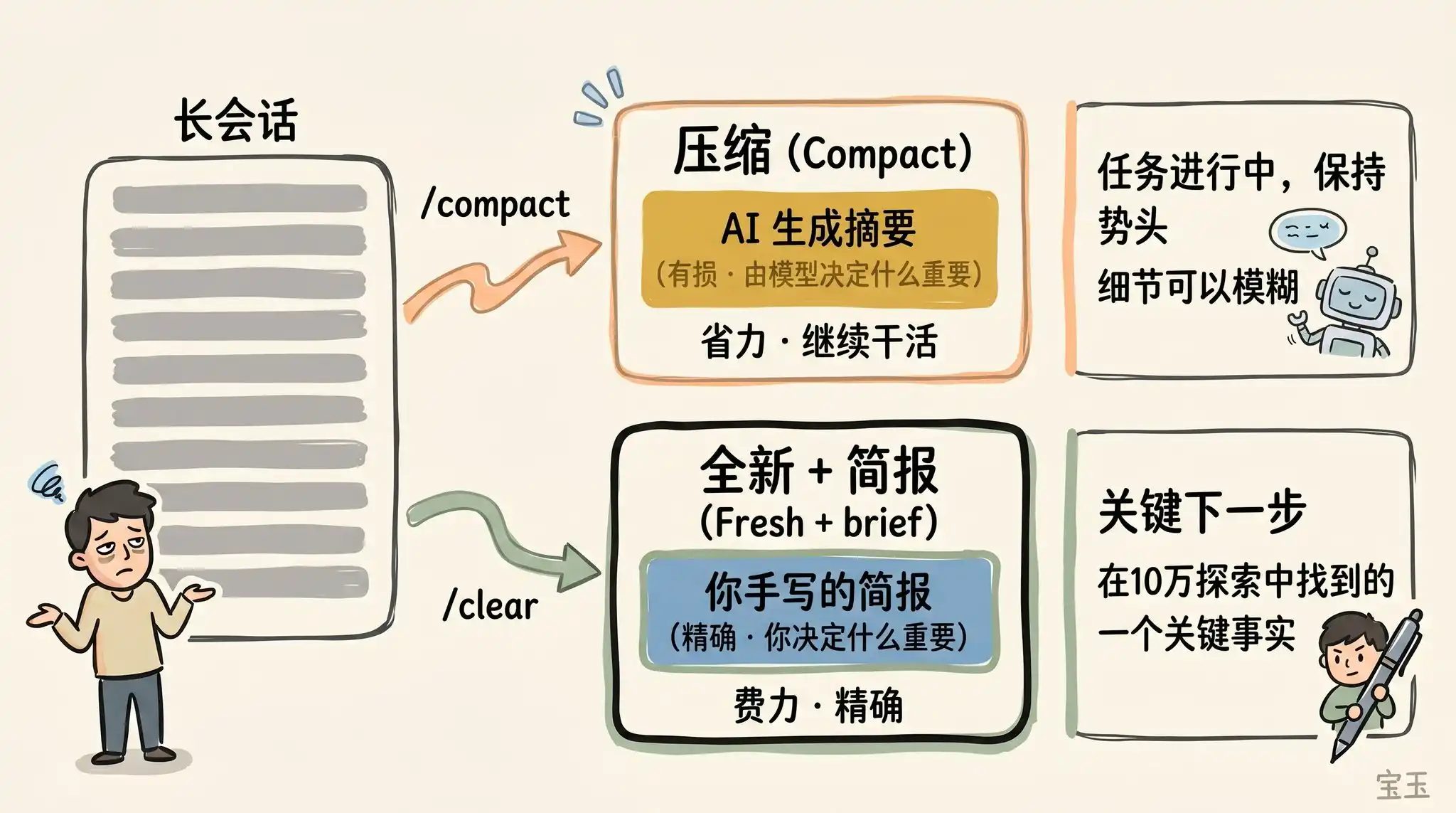
L'utilisation de /clear, quant à elle, vous oblige à écrire vous-même les points clés (ex: « Nous refactorisons le middleware d'authentification, les contraintes actuelles sont X, les fichiers importants concernés sont A et B, et nous avons déjà écarté la méthode Y »), puis à recommencer avec un état parfaitement propre. Bien que cela demande plus d'efforts, le nouveau contexte qui en résulte est à 100% composé de ce que vous considérez comme véritablement pertinent.
Quelle « compression » peut échouer ?
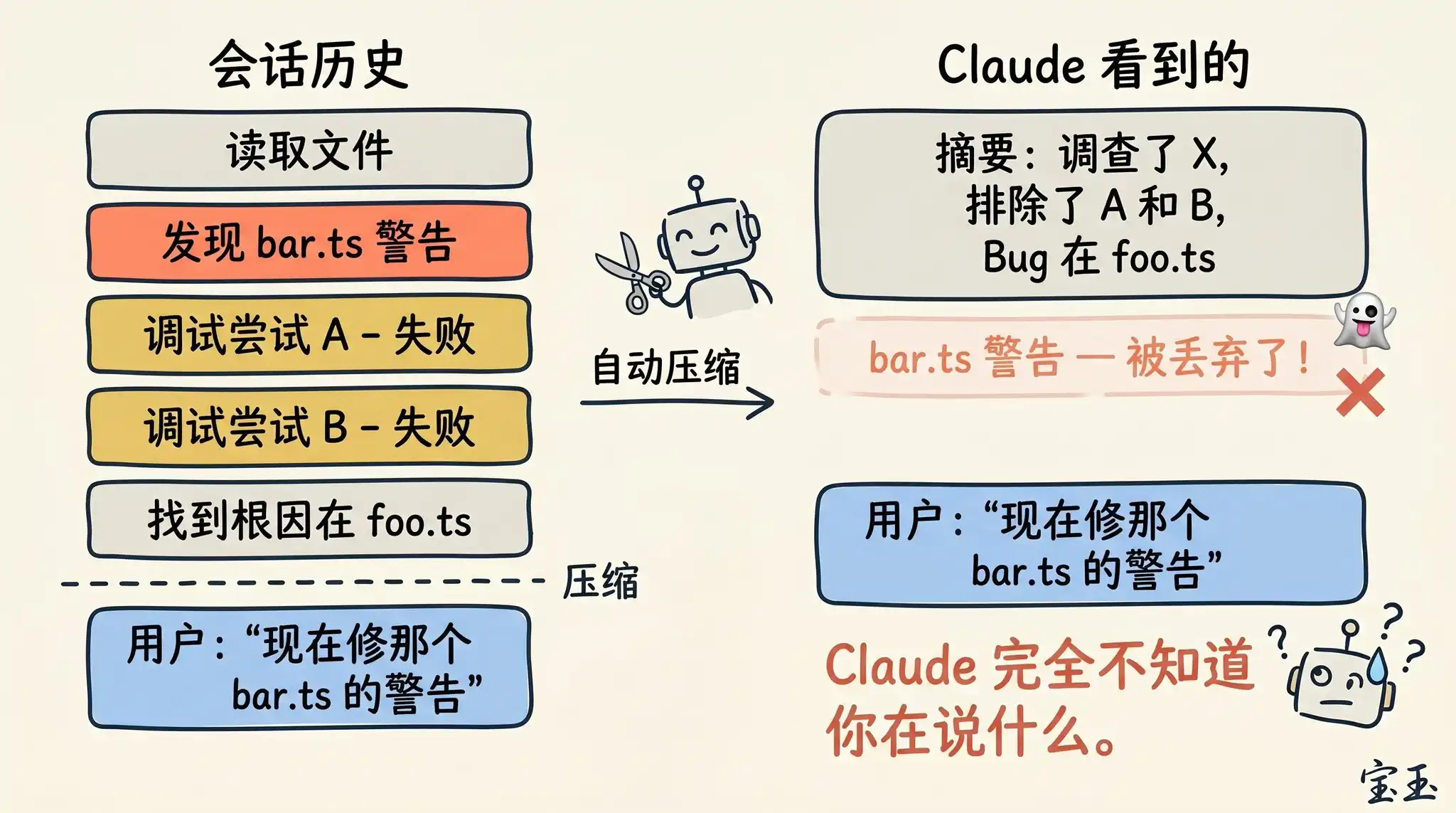
Si vous gardez souvent des sessions très longues, vous avez probablement déjà rencontré des situations où l'effet de la « compression » était extrêmement mauvais. Nous avons constaté que ces « échecs » se produisent généralement à un moment précis : lorsque le grand langage de modèle (LLM) ne peut pas prédire la direction de votre prochain travail.
Par exemple, après une longue session de débogage de code, le système déclenche une compression automatique qui résume le processus de排查. Ensuite, vous envoyez un message : « Maintenant, corrigeons également l'autre avertissement que nous avons vu précédemment dans bar.ts. »
Cependant, comme la session précédente était entièrement concentrée sur le débogage du premier bug, cet avertissement non corrigé a très bien pu être considéré comme une information non pertinente et simplement jeté lors du résumé.
C'est un problème assez épineux. Parce qu'en raison de la dégradation du contexte, au moment où il effectue la compression, le modèle est souvent dans son état le moins « intelligent ». Heureusement, avec la capacité de contexte d'un million de tokens, vous disposez désormais d'un espace plus confortable pour exécuter proactivement /compact en incluant une description de « ce que je veux faire ensuite ».
Sous-agents et nouvelle fenêtre contextuelle
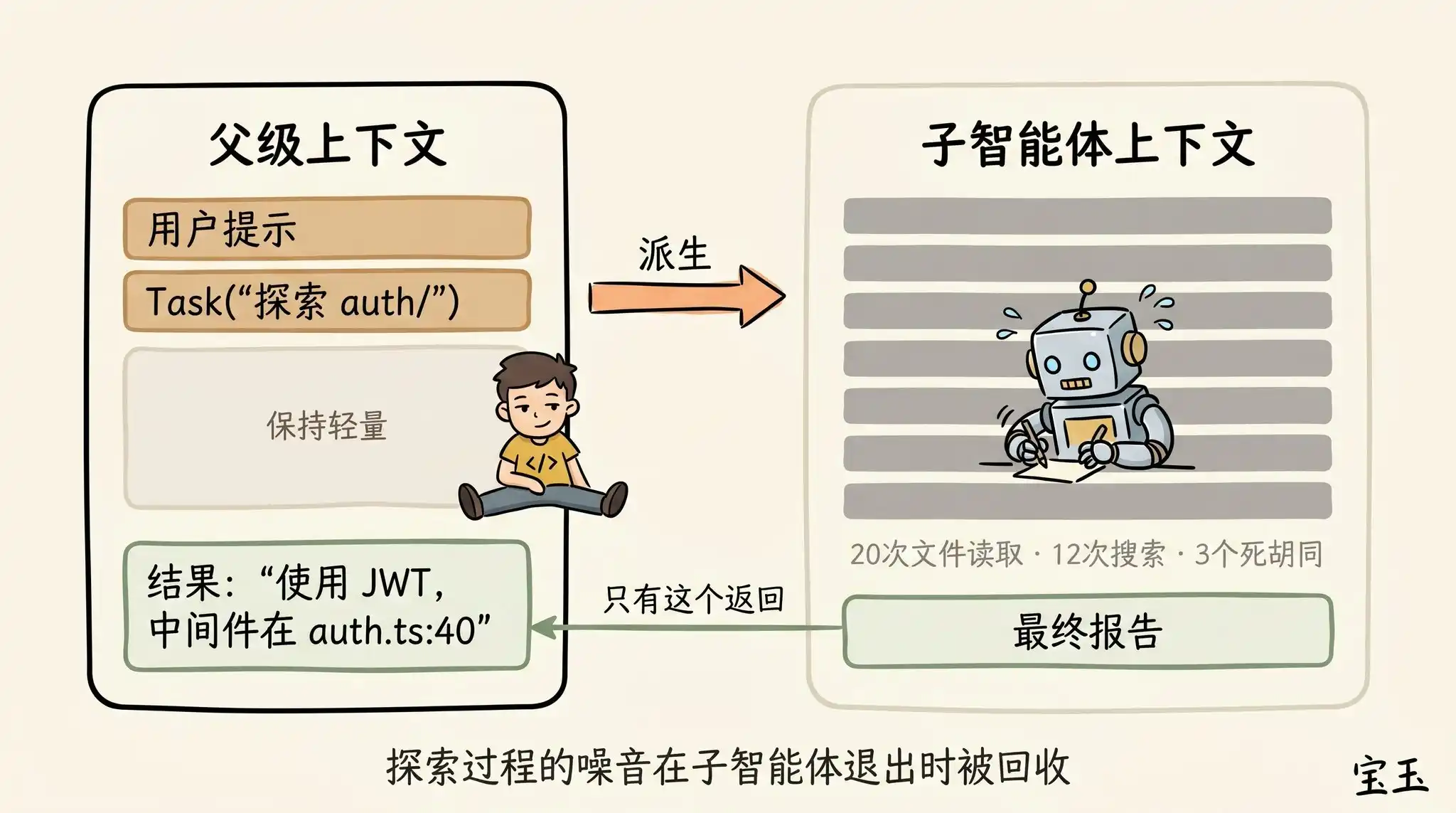
Les sous-agents sont également un excellent moyen de gérer le contexte. Cette technique est particulièrement utile lorsque vous prévoyez à l'avance qu'un certain travail produira de nombreux résultats intermédiaires « à usage unique » (qui ne serviront plus jamais par la suite).
Lorsque Claude dérive un sous-agent via un outil d'agent (Agent tool), ce petit bonhomme obtient une fenêtre contextuelle entièrement nouvelle. Il peut y travailler autant qu'il le souhaite. Une fois le travail terminé, il résumera les résultats et ne renverra que le rapport final au Claude parent.
La « question existentielle » que nous nous posons pour décider d'utiliser un sous-agent est : aurai-je besoin de voir les sorties détaillées de l'exécution de ces outils plus tard, ou est-ce que je veux juste une conclusion finale ?
Bien que Claude Code appelle automatiquement des sous-agents en arrière-plan, vous pouvez parfois aussi le diriger très explicitement. Par exemple, vous pouvez lui dire :
· « Envoie un sous-agent vérifier, en se basant sur le fichier de spécifications ci-dessous, si le travail que nous venons de faire est correct »
· « Envoie un sous-agent parcourir un autre dépôt de code, résume comment il implémente le flux d'authentification, puis copie son approche pour l'implémenter ici »
· « Envoie un sous-agent rédiger la documentation de cette nouvelle fonctionnalité en se basant sur mon historique de modifications Git »
En résumé, lorsque Claude a terminé un cycle de réponse et que vous vous apprêtez à envoyer un nouveau message, vous vous trouvez à un carrefour décisionnel.
Nous espérons qu'à l'avenir, Claude sera suffisamment intelligent pour gérer tout cela à votre place. Mais pour l'instant, maîtriser ces décisions est la voie incontournable pour guider Claude vers des résultats de haute qualité.