Du code à la cognition : un guide de dix mille mots sur l'évolution du cerveau robotique
Auteur: Matt White, CTO AI mondial de la Linux Foundation.
Compilé par: Felix, PANews.
Cette longue exploration retrace l'évolution de l'intelligence des robots, des systèmes classiques codés à la main aux approches modernes fondées sur l'IA.
**L'ère pré-LLM** était dominée par une pile logicielle modulaire (perception, estimation d'état, planification, contrôle) et des arbres de comportement, prévisible mais peu adaptable.
**L'apprentissage automatique** a ensuite révolutionné la perception (réseaux neuronaux) et le contrôle (apprentissage par renforcement, imitation), mais chaque compétence restait étroite et spécifique.
**L'avènement des LLM** a introduit un planificateur en langage naturel, capable de décomposer une instruction en séquences d'actions atomiques exécutées par des contrôleurs existants (ex: SayCan de Google).
Le saut suivant fut les **modèles Vision-Langage-Action (VLA)**, comme RT-2 de DeepMind ou OpenVLA. Ces réseaux de neurones unifiés fusionnent flux visuel et instruction linguistique pour générer directement des commandes motrices, couplant raisonnement et action.
Les architectures les plus performantes, comme le GR00T de NVIDIA ou Helix de Figure AI, adoptent une **stratégie à "deux cerveaux"** : un système 2 lent (VLA, ~7-9 Hz) pour la réflexion et un système 1 rapide (~200 Hz) pour l'exécution réactive, avec parfois un système 0 réflexe pour l'équilibre. Les calculs critiques s'exécutent localement (ex: sur module NVIDIA Jetson) pour la latence et la fiabilité.
**L'essor des modèles open-source** (OpenVLA, GR00T N1.7, π0) est crucial, permettant aux startups de raffiner des bases pré-entraînées avec leurs propres données, accélérant le développement et favorisant l'audit de sécurité.
Cependant, des défis persistent : récupération après erreur, efficacité des données, généralisation entre corps robotiques, planification à long terme et raisonnement physique/spatial.
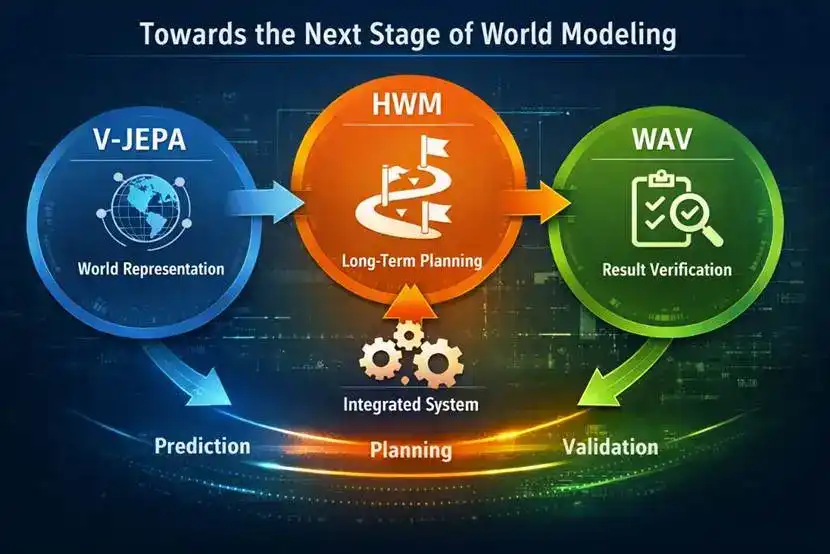
C'est là qu'interviennent les **modèles du monde (World Models)**, comme NVIDIA Cosmos ou Meta V-JEPA 2. Ces réseaux prédisent les conséquences futures d'une action (simulant une vidéo). Ils permettent au robot d'évaluer mentalement plusieurs scénarios avant d'agir, améliorant la reprise, la généralisation et la planification. Différentes approches architecturales coexistent (diffusion de pixels, JEPA, modèles à actions latentes).
L'acquisition de **données** (téléopération) reste un gouffre clé. La simulation (Isaac Sim) permet un entraînement massif. Les coûts matériels chutent rapidement (ex: robots humanoïdes à ~2500$). Les modes de défaillance des robots pilotés par LLM peuvent être étranges, nécessitant des contraintes de sécurité.
En conclusion, l'intelligence robotique migre progressivement du code des ingénieurs vers des modèles apprenant le monde lui-même. Nous en sommes à une phase de progression constante (analogue à GPT-2 pour l'IA physique), promettant à terme des robots bien plus généraux et adaptatifs. La question évolue de "que peuvent-ils faire ?" vers "que devrions-nous leur faire faire ?".
marsbit06/07 13:08