Agentic Design Patterns : un livre qui m'a fait redéfinir "ce qu'est vraiment un Agent"
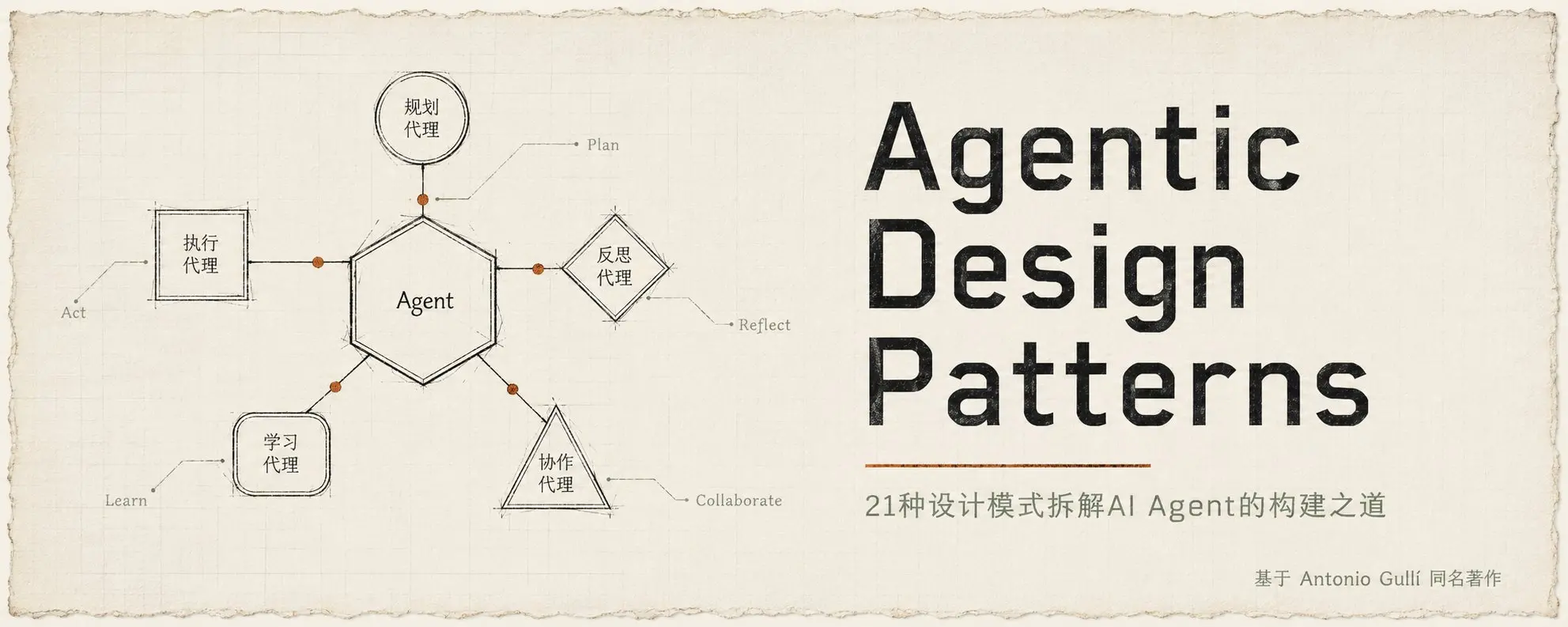
"**Agentic Design Patterns**" d'Antonio Gulli offre une vision structurée des agents IA à travers 21 modèles de conception. L'essentiel : un véritable agent va bien au-delà d’un simple LLM (niveau 0). Il se définit par sa capacité à utiliser des outils de façon autonome (niveau 1), à planifier et à pratiquer l’*Ingénierie du Contexte* pour filtrer et optimiser les informations (niveau 2), et, si nécessaire, à collaborer au sein d’équipes multi-agents spécialisées (niveau 3).
L’article souligne deux concepts clés. D’abord, l’*Ingénierie du Contexte*, qui dépasse le simple prompt pour gérer stratégiquement les couches d’information (système, données externes, données implicites, boucle de feedback) présentées à l’agent. Ensuite, le modèle *Producteur-Critique* (Reflection), où deux agents aux rôles distincts (création et révision critique) travaillent en boucle pour améliorer continuellement la qualité du résultat, comme dans la génération de code.
Il met également en garde contre la complexité inutile : un agent de niveau 2 bien conçu est souvent suffisant. Les systèmes multi-agents (niveau 3) ne sont nécessaires que pour les tâches véritablement complexes et parallélisables, et leur architecture de communication (par exemple, superviseur central ou réseau pair-à-pair) doit correspondre à la nature de la tâche.
Enfin, la mémoire de l’agent doit être pensée en trois couches : la session (contexte immédiat), l’état (données temporaires de la tâche) et la mémoire à long terme (expériences persistantes). Le livre se conclut par des perspectives ambitieuses, comme les systèmes multi-agents "auto-transformants" qui se réorganisent dynamiquement pour atteindre un objectif.
L’auteur en retire trois actions pratiques : ajouter un agent critique à ses workflows existants, se concentrer sur l’ingénierie du contexte plutôt que seulement sur les prompts, et perfectionner un agent unique avant de se lancer dans des architectures multi-agents complexes.
链捕手05/25 04:51