In the years of AI's rapid advancement, the industry has been largely dominated by one logic: computing power determines the ceiling, and GPUs are the core of that computing power.
However, entering 2026, this logic is beginning to shift: model inference is no longer the sole bottleneck; system performance increasingly depends on execution and scheduling capabilities. GPUs remain important, but the key factor determining whether AI can 'run' is gradually shifting to the long-overlooked CPU.
On April 9th, US local time, Google and Intel reached a multi-year agreement to deploy Intel's 'Xeon processors' at scale in global AI data centers, precisely to break this bottleneck. Intel CEO Pat Gelsinger (Note: The original Chinese name 陈立武 is likely a misattribution; the current CEO is Pat Gelsinger) stated bluntly that AI runs on the entire system, and CPUs and IPUs are the key to performance, efficiency, and flexibility. In other words, the CPU, which has been treated as a 'supporting role' for the past two years, is now choking the 'neck' of AI scaling.
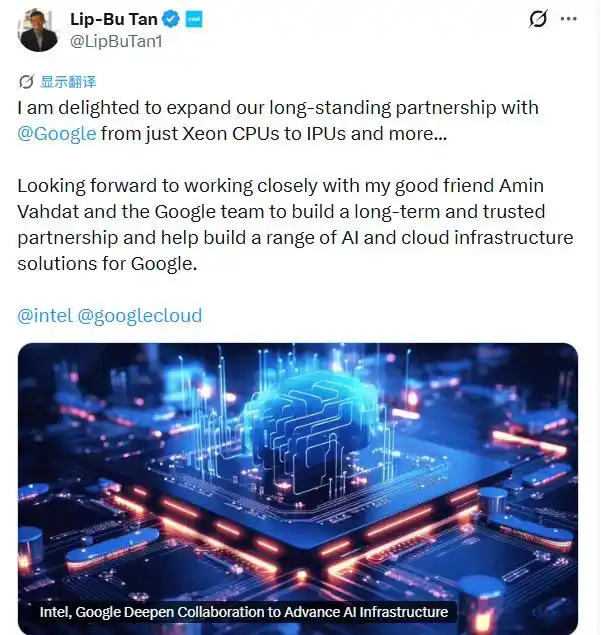
Intel CEO Pat Gelsinger stated on social media: Intel is deepening its collaboration with Google, expanding from traditional CPUs to AI infrastructure (such as IPUs), to jointly advance AI and cloud computing capabilities.
The CPU is no longer just a passive supporting component but is becoming one of the key variables in AI infrastructure.
01
A 'Silent' Supply Crisis
While everyone was watching GPU delivery cycles, the tension in the CPU market had already quietly peaked.
According to the latest reports from multiple IT distributors, in the fourth quarter of 2025, the average selling price of server CPUs increased by about 30%. Such an increase is very rare in the relatively mature CPU market.
AMD's Data Center Group head, Forrest Norrod, revealed that CPU demand growth over the past three quarters has been beyond imagination. Currently, AMD's delivery lead times have extended from the original eight weeks to over ten weeks, with some models even facing delays of up to six months.
This shortage is primarily caused by a 'secondary effect' triggering a resource crunch. Industry insiders indicate that due to the extreme tightness of TSMC's 3nm production lines, wafer capacity originally allocated for CPUs is constantly being squeezed out by more profitable GPU orders. This has led to an ironic situation: AI labs have enough GPUs but find they cannot buy enough top-tier CPUs on the market to 'drive' these graphics cards.
Among those caught in this wave of CPU buying frenzy is Elon Musk.
Intel CEO Pat Gelsinger confirmed on social platforms that Musk has commissioned Intel to design and manufacture custom chips for his 'Terafab' project in Texas. This massive project aims to provide a unified computing base for xAI, SpaceX, and Tesla.
Musk's trust in Intel is largely because Intel is trying to embed itself into every layer, from ground-based data centers to orbital computing in space.
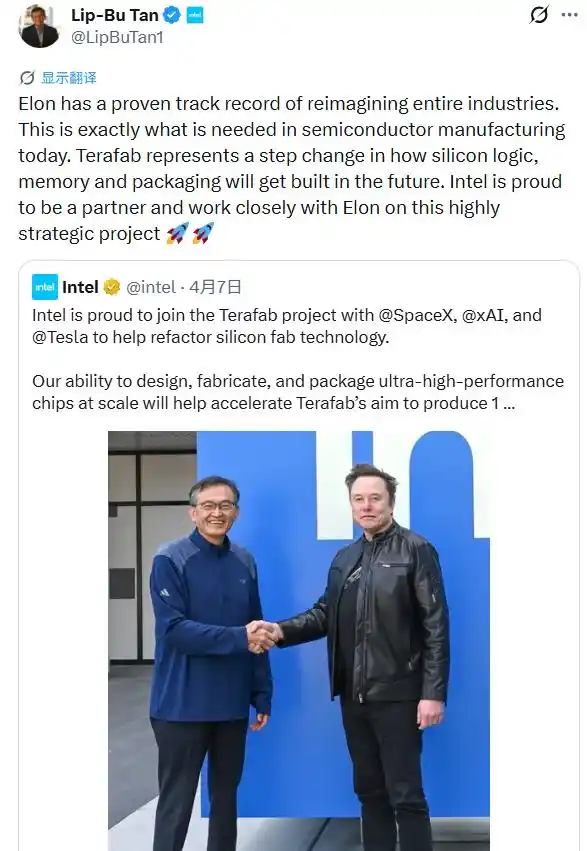
For Intel, this is undoubtedly a shot in the arm. Some industry analysts predicted that AMD's revenue share in the server CPU market would surpass Intel's in 2026, but Intel's deep inertia and manufacturing capabilities within the x86 ecosystem remain chips that major customers like Musk cannot ignore.
This kind of deep cross-industry bundling is elevating the competition in the CPU market from a pure parameter contest to a game of ecosystem and supply chain stability.
02
Why Has the CPU Become the 'Bottleneck'?
The core reason the CPU has suddenly become a bottleneck is that the work it needs to handle has fundamentally changed in the age of agents.
In the traditional chatbot model, the CPU is primarily responsible for scheduling and data processing, while the GPU handles the core inference computation. Since compute-intensive tasks are concentrated on the GPU side, overall latency is usually dominated by the GPU, and the CPU rarely becomes a performance bottleneck.
But agent workloads are completely different. An agent needs to perform multi-step reasoning, call APIs, read and write databases, orchestrate complex business flows, and integrate intermediate results into a final output. Tasks like search, API calls, code execution, file I/O, and result orchestration mostly fall on the CPU and host system side. The GPU is responsible for token generation (i.e., 'thinking'), while the CPU is responsible for translating the 'thoughts' into actual actions.
A paper published by Georgia Tech scholars in November 2025, 'A CPU-Centric Perspective on Agentic AI,' quantified the latency distribution in agent workloads. The study found that the time consumed by tool processing on the CPU side accounts for 50% to 90.6% of the total latency. In some scenarios, the GPU is ready to process the next batch of tasks while the CPU is still waiting for tool calls to return.
Another key factor is the rapid expansion of context windows. In 2024, mainstream models mostly supported 128K to 200K tokens. Entering 2025, models like Gemini 2.5 Pro, GPT-4.1, and Llama 4 Maverick began supporting over 1 million tokens. The KV cache (Key-Value Cache, used to accelerate the Transformer model inference process) grows linearly with the number of tokens, reaching about 200GB at 1 million tokens, far exceeding the 80GB VRAM capacity of a single H100.
One solution to this problem is to offload part of the KV cache to CPU memory. This means the CPU must not only manage orchestration and tool calls but also help bear data that doesn't fit in VRAM. CPU memory capacity, memory bandwidth, and the interconnect speed between the CPU and GPU thus become critical to system performance.
Therefore, CPUs suited for the agent era require low latency, consistent memory access capabilities, and stronger system-level协同 capabilities, rather than单纯 core count expansion.
03
What Are the Vendors Doing? Some Grab Territory, Others Change Designs
Faced with this sudden surge in CPU demand, the major players have completely different strategies.
Intel is the traditional leader in server CPUs. Data from Mercury Research shows that in Q4 2025, Intel still held a 60% share of the server CPU market, AMD had 24.3%, and Nvidia had 6.2%. But Intel has been playing catch-up with new technologies in recent years; this CPU demand explosion is both an opportunity and a test for them.
Intel's current strategy is a two-pronged approach. On one hand, continue selling Xeon processors, deeply绑定 with hyperscale customers like Google; on the other hand, partner with SambaNova to launch a combined solution based on Xeon processors and their self-developed RDU accelerators,主打 the selling point of 'running agent inference without GPUs'. The roadmap for Xeon 6 Granite Rapids and the 18A process will be key tests of whether Intel can turn the tables.
AMD is one of the biggest beneficiaries of this CPU demand surge. In Q4 2025, AMD's Data Center revenue was $5.4 billion, a year-on-year increase of 39%. Fifth-gen EPYC Turin accounted for over half of server CPU revenue, and deployments of cloud instances running EPYC grew over 50% year-on-year. AMD's server CPU revenue share exceeded 40% for the first time.
AMD CEO Lisa Su directly attributed the growth to the development of 'agents'—agent workloads push tasks 'back' to traditional CPU tasks.
In February 2026, AMD also announced a potential deal with Meta worth over $100 billion to supply MI450 GPUs and Venice EPYC CPUs.
However, AMD still has room for improvement in system-level协同, lacking a mature high-speed CPU-GPU interconnect capability类似 NVLink C2C. As agent (Agent) systems place increasing demands on data interaction and协同 efficiency, the importance of this aspect is also gradually rising.
Nvidia's approach to CPU design is completely different from Intel's and AMD's.
The Nvidia Grace CPU has only 72 cores, while AMD EPYC and Intel Xeon typically have 128. Nvidia's AI Infrastructure VP, Dion Harris, explained: 'If you're a hyperscaler, you want to maximize the number of cores per CPU, which basically drives down the cost, the dollar-per-core cost. So it's a business model.'
In other words, in the AI computing体系, the CPU's role is no longer that of a general-purpose workhorse but rather a 'scheduling hub' serving the GPU. If the CPU can't keep up, the expensive GPUs are forced to wait, and overall efficiency drops.
Therefore, Nvidia prioritizes efficient协同 between the CPU and GPU in its design. For example, through the NVLink C2C interconnect, the bandwidth between the CPU and GPU is boosted to about 1.8TB/s, far higher than traditional PCIe, and the CPU can directly access GPU memory, greatly simplifying KV cache management.
Currently, Nvidia sells the Vera CPU as a standalone product. CoreWeave was the first customer. The deal with Meta is even more夸张; this is its first large-scale 'pure Grace deployment,' meaning CPUs deployed大规模 independently without GPUs paired.
Ben Bajarin, Principal Analyst at Creative Strategies, pointed out that in high-intensity system collaboration, the CPU's processing power must keep pace with the accelerator's iteration speed. If there is even a one percent delay in the data通道, the entire AI cluster's economic efficiency suffers significantly. This pursuit of极致 system efficiency is forcing all major players to re-evaluate CPU performance metrics.
Holger Mueller, VP and Principal Analyst at Constellation Research, stated that as AI workloads shift towards agent-driven architectures, the CPU's position is becoming more central. He noted: 'In the agent world, agents need to call APIs and various business applications, tasks most suitable for CPUs to complete.'
He added: 'Currently, there is no consensus on whether GPUs or CPUs are more suitable for handling inference tasks. GPUs have an advantage in model training, and custom ASICs like TPUs have their specialties. But one thing is clear: Google needs to adopt a hybrid processor architecture. Therefore, Google's choice to partner with Intel is reasonable.'
04
Conclusion: In the Agent Era, the Computing Power Balance is Swinging Back
In the latest industry observations, one data point deserves attention. In the massive $38 billion合作协议 between Amazon AWS and OpenAI, the official announcement also explicitly mentioned scaling 'tens of millions of CPUs'.
In recent years, the industry's focus has typically been on those 'hundreds of thousands of GPUs'. However, the fact that cutting-edge labs like OpenAI are proactively treating CPU scale as a key planning variable sends a clear signal: scaling agent workloads must be built upon a massive CPU infrastructure.
Bank of America predicts that by 2030, the global CPU market size could double from the current $27 billion to $60 billion. Almost all of this additional share will be driven by AI.
We are witnessing the expansion of a全新的 infrastructure: big tech is no longer just stacking GPUs but is simultaneously expanding an entire layer of 'CPU scheduling infrastructure' specifically to support the operation of AI agents.
The alliance between Intel and Google, as well as Musk's heavy investment in custom chips, all prove one fact: the winning point in the AI race is moving forward. When computing power is no longer scarce, whoever can solve the system-level 'bottleneck' first will have the last laugh in this trillion-dollar game.
*Special contributor Jin Lu also contributed to this article.
This article is from the WeChat public account 'Tencent Technology', author: Li Hailun, editor: Xu Qingyang






