Ces dernières années, les modèles Mixtes d'Experts (MoE) ont été largement utilisés dans les grands modèles déployés dans le cloud. Mais sur les appareils mobiles, les modèles de langage de grande taille (LLM) restent principalement basés sur des architectures denses. Par le passé, les contraintes plus strictes des téléphones en matière de mémoire, de puissance de calcul et de latence ont fait que les MoE côté client dans la plage des paramètres actifs inférieure à un milliard n'ont pas fait l'objet d'études systématiques. Aujourd'hui, avec l'augmentation de la capacité DRAM des appareils mobiles, les MoE commencent aussi à avoir une chance d'être déployés sur les smartphones.
Le MobileMoE proposé par l'équipe de Meta a pour la première fois réalisé une inférence MoE efficace sur un smartphone commercial. Les résultats montrent que sur 14 tests de base, avec une mémoire similaire, MobileMoE-S/M, en utilisant seulement de 1/2 à 1/4 de la charge de calcul d'inférence par rapport à la ligne de base dense, a obtenu une précision moyenne équivalente voire supérieure. En test réel, MobileMoE-S a montré l'accélération la plus marquée sur le backend GPU/MLX de l'iPhone 16 Pro, avec une accélération allant jusqu'à 3,8 fois lors de la phase d'entrée.

Lien vers l'article : https://arxiv.org/abs/2605.27358
L'équipe de recherche a également proposé un ensemble de lois de mise à l'échelle pour les MoE côté client, utilisées pour déterminer des architectures de modèles plus adaptées au déploiement sur téléphone. MobileMoE établit également une nouvelle frontière de Pareto pour les grands modèles de langage côté client, obtenant de meilleurs résultats dans le compromis entre précision et coût de calcul d'inférence.
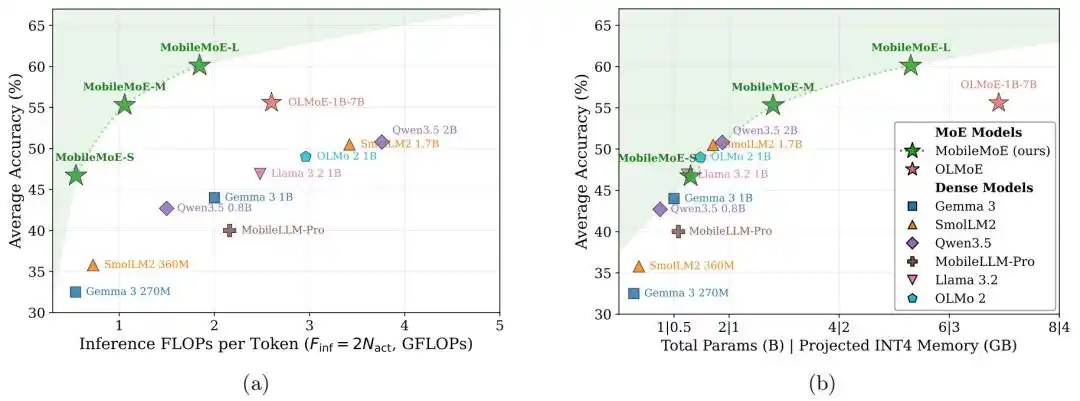
Figure | MobileMoE établit une nouvelle frontière de Pareto pour les LLM côté client.
Comment MobileMoE est-il conçu ?
MobileMoE peut être compris ainsi : c'est une classe de modèles de langage MoE conçue pour le déploiement côté client. Globalement, il reste un Transformer de type décoder-only, mais remplace les couches feed-forward denses originales par des couches MoE. Le routeur sélectionne pour chaque token un petit nombre d'experts ayant les scores les plus élevés pour participer au calcul, et il y a également un expert partagé qui participe toujours. L'ensemble du processus d'entraînement se déroule en quatre étapes : pré-entraînement, entraînement intermédiaire, réglage fin supervisé et entraînement sensible à la quantification.
Pré-entraînement : L'équipe de recherche a effectué le pré-entraînement sur environ 6T de tokens de données sous licence ouverte, avec une longueur de contexte de 2048, les données étant principalement issues du Web, tout en couvrant les domaines des mathématiques, du code, des connaissances et des sciences.
Entraînement intermédiaire : L'équipe de recherche a étendu la longueur du contexte à 8192 et a encore augmenté la proportion de données de haute qualité telles que les connaissances, le code, les mathématiques et les sciences, pour une taille totale d'environ 500B tokens.
Réglage fin supervisé (SFT) : L'équipe de recherche a effectué un réglage fin sur MobileMoE-Base, sur plus de 80 millions d'échantillons de données de réglage fin d'instructions sous licence ouverte.
Entraînement sensible à la quantification : L'équipe de recherche a quantifié les couches linéaires et les embeddings en INT4, les activations dynamiques en INT8, tout en conservant le routeur en précision FP32.

Figure | Les quatre étapes de l'entraînement de MobileMoE.
Résultats expérimentaux
Résultats d'ablation
L'équipe de recherche a d'abord comparé trois variables architecturales : le nombre d'experts E, la granularité des experts g, et l'ajout ou non d'un expert partagé.

Figure | Mise à l'échelle du nombre d'experts E.
Sous un budget mémoire fixe, lorsque la mémoire dépasse environ 0,25 Go, la perte du MoE commence à devenir inférieure à celle du modèle dense correspondant. Continuer à augmenter le nombre d'experts E réduit encore la perte, mais lorsque E atteint 8, le gain marginal s'affaiblit nettement. Les expériences sur la granularité des experts g montrent quant à elles qu'une configuration d'experts plus fine est globalement meilleure, avec g=8 offrant un bon équilibre entre performance et coût d'entraînement ; lorsque g passe de 8 à 16, l'amélioration de la perte est inférieure à 0,01, mais la durée d'entraînement augmente d'environ 50%. À budget de calcul égal, l'ajout d'un expert partagé réduit encore la perte du modèle.
Basé sur les résultats d'ablation, l'équipe de recherche a finalement adopté la configuration E=8, g=8, avec expert partagé, soit 60 experts de routage à granularité fine, un routage Top-4 et 1 expert partagé, et a utilisé cette architecture pour les trois versions MobileMoE-S/M/L.
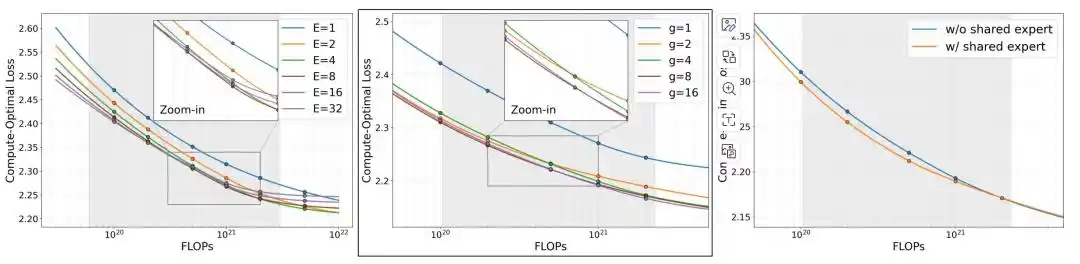
Figure | Mise à l'échelle des modèles MoE dans des conditions optimales de calcul.
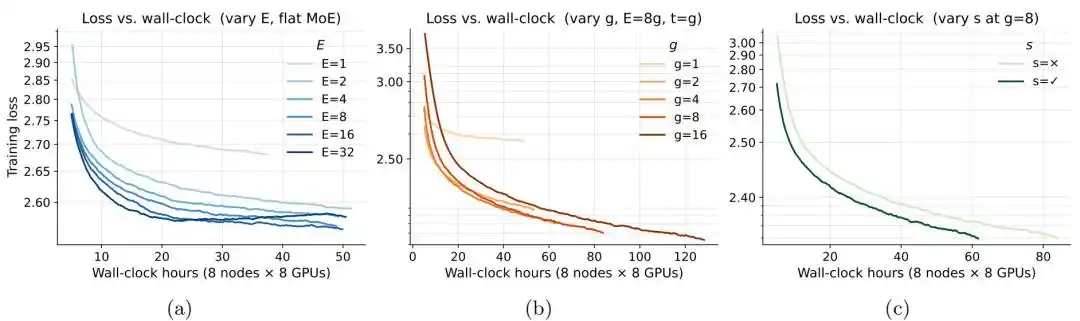
Figure | Efficacité de l'entraînement de l'architecture MoE.
Évaluation sur 14 tests de base : Établir une nouvelle frontière de Pareto côté client
L'équipe de recherche a comparé MobileMoE avec Gemma 3, SmolLM2, Qwen3.5, OLMo 2, OLMoE-1B-7B et d'autres modèles, en les réévaluant dans un cadre unifié sur cinq catégories totalisant 14 tests de base : raisonnement de bon sens, connaissances, sciences, lecture et raisonnement.
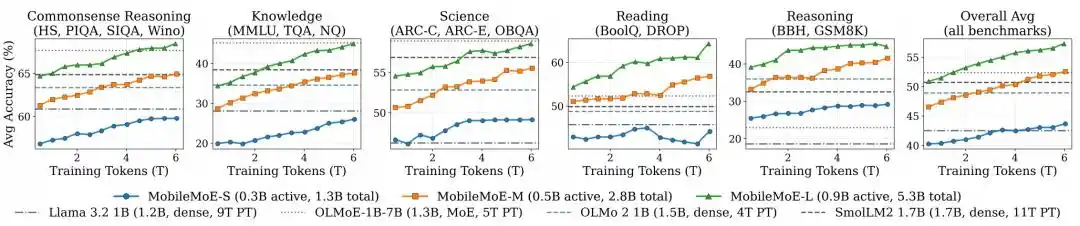
Figure | Trajectoire de pré-entraînement de MobileMoE.
Les résultats de comparaison des modèles Base montrent que MobileMoE-M a un score moyen supérieur à Qwen3.5 2B, et MobileMoE-L a un score moyen supérieur à OLMoE-1B-7B, tout en nécessitant une taille de modèle plus petite ; l'équipe de recherche mentionne également que la version Base de MobileMoE-L a déjà un score moyen supérieur à la version Instruct de OLMoE-1B-7B. En termes de volume d'entraînement, MobileMoE utilise environ 6T de tokens de pré-entraînement, soit moins que les 9T de Llama 3.2 1B et les 11T de SmolLM2 1.7B. Dans la comparaison globale des modèles après réglage fin d'instructions, la précision moyenne de MobileMoE-M est déjà proche de celle de OLMoE-1B-7B, mais avec environ 60% de paramètres actifs et totaux en moins.

Figure | Comparaison des modèles MobileMoE-Base.
Évaluations avancées : Avantage plus marqué sur les tâches de code et de mathématiques
Dans les évaluations avancées après réglage fin d'instructions, MobileMoE se distingue davantage sur les tâches de code et de mathématiques. Prenons l'exemple de MobileMoE-L : ses scores moyens dans les deux catégories de tests (code et mathématiques) sont supérieurs à ceux de Qwen3.5 2B et OLMoE- 1B-7B. Cependant, l'équipe de recherche mentionne aussi que, en termes de capacité de suivi d'instructions et de raisonnement sur les connaissances, Qwen3.5 2B reste plus performant.
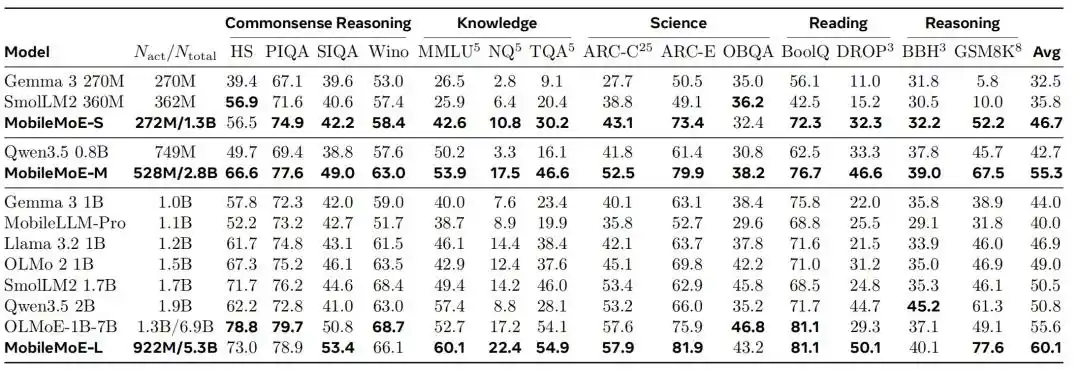
Figure | Comparaison des modèles Instruct sur les benchmarks avancés.
Quantification et déploiement côté client : Reste compétitif après INT4, accélération notable sur téléphone
Après quantification, les scores moyens globaux de MobileMoE-S/M/L diminuent par rapport à leurs versions BF16 respectives, mais la baisse se situe généralement entre 2 et 3 points. Néanmoins, la performance de la version INT4 de MobileMoE-L reste supérieure à celle de la version BF16 de OLMoE-1B-7B Instruct.
L'équipe de recherche a également déployé MobileMoE sur Samsung Galaxy S25 et iPhone 16 Pro pour des tests. Les résultats montrent que, dans des conditions de mémoire de poids INT4 comparables, MobileMoE-S, par rapport à MobileLLM-Pro, accélère la phase d'entrée de 1,8 à 3,8 fois, et accélère la phase de génération token par token de 2,2 à 3,4 fois.
En termes d'occupation mémoire, dans des conditions réelles avec Samsung Galaxy S25, un contexte de 8K et un prompt réel, le pic RSS de MobileMoE-S est de 1,49 Go, inférieur aux 1,91 Go de MobileLLM-Pro.

Figure | Latence d'exécution côté client.
Limites et orientations futures
Actuellement, en matière de capacités plus avancées de suivi d'instructions ainsi que de raisonnement sur les connaissances, le MobileMoE après réglage fin d'instructions reste en retard par rapport à Qwen3.5 2B. L'équipe de recherche estime que cet écart pourrait être lié à un post-entraînement plus complet de ce dernier. À l'avenir, pour réduire cet écart, le côté entraînement nécessitera de renforcer la distillation, le post-entraînement orienté raisonnement, ainsi que l'extension multimodale.
De plus, l'équipe de recherche souligne que l'empreinte mémoire du MoE sur téléphone varie avec le contenu de l'entrée. Par rapport à des entrées basées sur des templates, les entrées réelles entraînent généralement une occupation mémoire plus élevée. Si les tests sont basés uniquement sur des entrées template, cela pourrait sous-estimer la pression mémoire réelle dans les scénarios de déploiement. À l'avenir, pour évaluer plus précisément les performances mémoire réelles des MoE côté client, il sera nécessaire de s'appuyer sur davantage de données de mesures réelles.
Parallèlement, l'équipe de recherche a déjà terminé des tests systématiques sur appareils réels avec des backends CPU et GPU, mais la voie NPU reste à explorer. En même temps, l'occupation mémoire à l'exécution du MoE est assez sensible au contenu de l'entrée. À l'avenir, le routage dynamique, l'élagage d'experts, la quantification en précision mixte ainsi que le déploiement sur NPU mobile sont autant de directions pour continuer à améliorer l'efficacité côté client.
Pour plus de détails techniques, veuillez consulter l'article original.
Cet article provient du compte public WeChat « Academic Headlines » (ID : SciTouTiao), auteur : Xia Qiansi





