Faire des recherches techniques est en réalité une entreprise pleine de pièges (tant pour l'homme que pour l'IA), car dès le début de l'enquête, on reçoit une masse d'informations, les points de vue se multiplient et la conclusion devient de plus en plus floue. Il faut donc toujours savoir revenir à l'objectif initial.
C'est aussi pourquoi, jusqu'à présent, l'IA n'a pas toujours été excellente. Du point de vue de l'attention et de l'association d'idées, elle peut être plus piégée que l'homme par le volume d'informations en cours, et ses capacités d'association interdisciplinaire véritablement précieuses sont très faibles.
Bien sûr, le point fort de l'IA est sa capacité d'exécution. Sous forme d'agent, elle peut chercher, synthétiser et résumer couche par couche, en évitant totalement les pertes de détails.
Bien que je n'aie guère publié sur mon compte public WeChat ces six derniers mois, j'ai suivi et étudié de manière exhaustive presque tous les principaux champs de bataille de l'industrie. Ce qui soutient ces entrées et sorties d'informations est mon propre système de deep-research.
Face au lancement de la fonctionnalité Dynamic Workflows dans Claude Code la semaine dernière, j'ai voulu comparer et voir si ses capacités par défaut pouvaient totalement surpasser les miennes.
II. Qu'est-ce que le Dynamic Workflows
Le Dynamic Workflows (flux de travail dynamique) a comme idée centrale : avant d'exécuter une tâche, l'IA conçoit automatiquement le flux de travail qui devrait être utilisé pour accomplir cette tâche, puis lance l'exécution.
Cela diffère fondamentalement du "mode plan" et des "skills" que nous utilisions auparavant. Le mode plan décompose la tâche en étapes plus fines, mais pas nécessairement selon un flux de travail raisonnable. Seulement si vous l'ordonnez dans vos prompts, il pourra éventuellement ajouter des critères de validation (cruciaux pour la Recherche). De même, ce n'est qu'en présence de prompts qu'il prédéfinira mieux certaines règles de contrôle.
Mais le flux de travail dynamique intègre automatiquement la logique de validation, la convergence des résultats, la vérification contradictoire, etc.
Le déclenchement est simple : utilisez directement /deep-research dans cc, puis fournissez quelques modèles de recherche et des documents d'entrée. Si vous souhaitez utiliser uniquement la capacité de flux de travail dynamique, utilisez l'ultracode dans le prompt ou dites-le directement. Attention, avant utilisation, la consommation de tokens est environ dix fois supérieure à la normale.
III. Les six modes de flux de travail intégrés
La base du flux de travail dynamique est constituée de six modes de planification clés résumés par l'officiel, c'est pourquoi il est plus puissant qu'un simple dialogue/agent/skill.
En fait, ces six modes se résument à deux questions centrales : comment décomposer la tâche ? Comment fusionner les résultats ? Les séparer en six types revient essentiellement à des combinaisons de ces deux aspects.
3.1 Mode routage (Classify-And-Act)
Un agent identifie d'abord le type de tâche, puis la distribue à l'agent spécialisé le plus adapté. La logique centrale est la logique de sélection du routeur, et non l'exécution en parallèle ou itérative. Une tâche ne suit qu'un seul chemin, les autres chemins ne sont pas exécutés du tout.
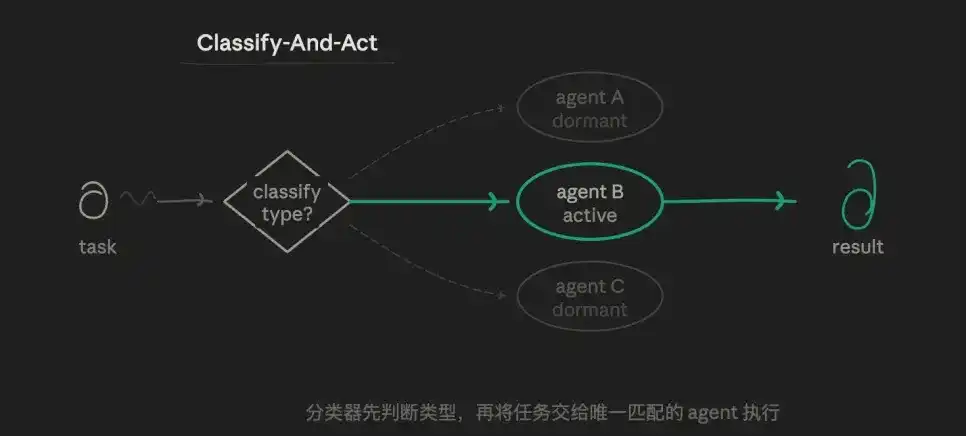
Par exemple, je peux avoir trois rôles d'agents subordonnés prédéfinis : un agent analyste strict pour la validation des données, un agent de sortie doué pour l'écriture, et un agent challenger spécialisé dans la recherche de vulnérabilités. La couche de routage jugera quel agent subordonné est adapté à la sous-tâche actuelle, plutôt que de laisser un agent tout faire.
La valeur de ce mode réside dans : la précision et l'économie. Le prompt de chaque agent peut être hautement indépendant, non perturbé par d'autres objectifs, permettant une exploration verticale approfondie. Consommation de tokens la plus faible, vitesse de réponse la plus rapide. Les limites des responsabilités sont très claires.
L'inconvénient est également marqué : faible capacité à traiter les tâches aux limites floues (par exemple, "à la fois un problème technique et un problème de compte").
3.2 Division et fusion (Fan-out & Merge)
C'est aussi le mode que j'utilise le plus souvent. La logique centrale est la parallélisation + fusion. La tâche est divisée en N sous-tâches indépendantes exécutées simultanément, puis fusionnées une fois toutes terminées.
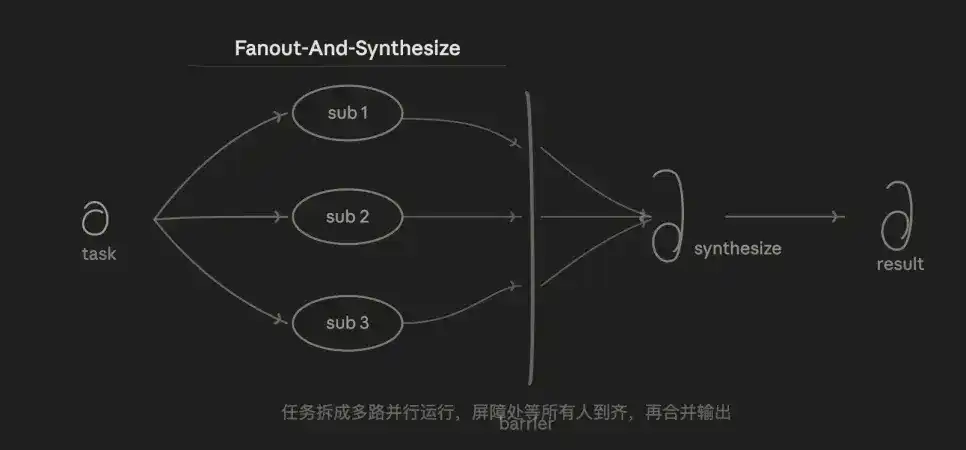
Les avantages sont la vitesse et l'isolement. Le temps total est approximativement égal à celui de la sous-tâche la plus lente, et non à la somme de toutes les sous-tâches. Chaque sous-tâche a son propre contexte, indépendant, sans interférence, et la pollution par le bruit d'une sous-tâche n'affecte pas les autres.
Le point faible est que le coût en tokens est N fois celui d'une exécution séquentielle. La couche de fusion (Synthesize) présente elle-même des difficultés — comment fusionner des sorties de N structures différentes est un défi de conception. Une mauvaise division des sous-tâches peut entraîner des omissions ou des chevauchements.
3.3 Vérification contradictoire (Adversarial Verification)
La logique centrale est la vérification. Pour une même conclusion, plusieurs agents la contestent sous l'angle de la "réfutation", et elle n'est considérée comme valide qu'après un vote majoritaire.
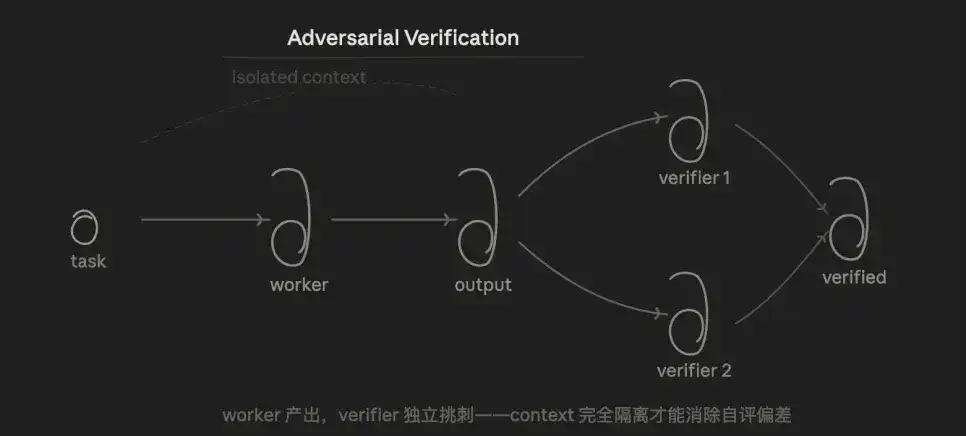
L'avantage est que, comme le Verificateur ne connaît pas la démarche du Travailleur et ne regarde que le résultat, cela élimine structurellement le biais d'auto-évaluation lorsque "le modèle vérifie son propre code".
Ce mode résout un problème qui me tourmentait depuis longtemps : nous parlons souvent de manière informelle avec l'IA, mais l'IA a tendance à répondre selon vos attentes, ce qui peut entraîner un "biais de confirmation". La vérification contradictoire oblige l'IA à rechercher des contre-exemples, à vérifier sur la base de données et d'expériences, plutôt que de se conformer à vos idées.
Cependant, pour la vérification, s'il donne un jugement erroné, il peut détourner le Travailleur pour qu'il se conforme au Vérificateur. Il est donc préférable de se baser sur des faits reproductibles, plutôt que sur des opinions.
Pour plaisanter, si vous demandez à une IA de trouver des problèmes, elle peut en trouver une infinité, vous devez donc limiter les limites de sa recherche.
3.4 Génération et filtrage (Generate & Filter)
La logique centrale est la divergence puis convergence. Produire délibérément un excès de candidats, puis utiliser un barème (rubric) pour éliminer jusqu'aux meilleurs, ne conservant que les résultats de haute confiance en sortie.
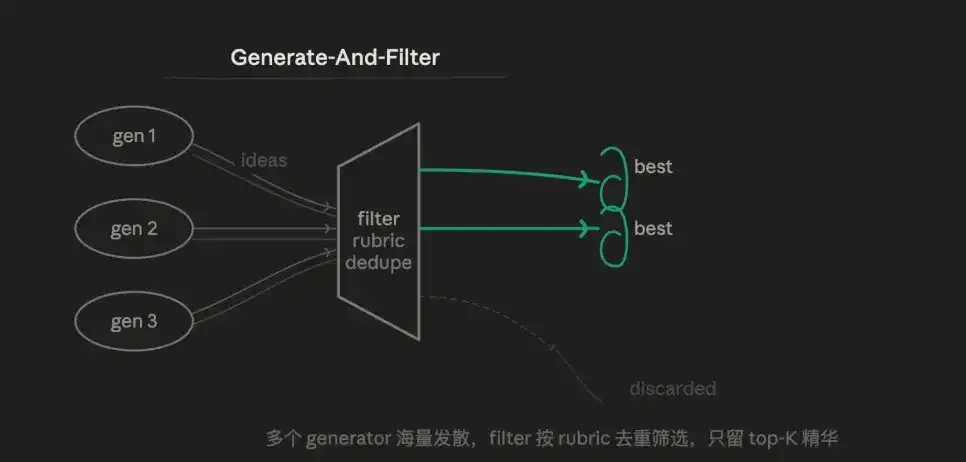
Plutôt que de faire produire à un agent une réponse "acceptable", il vaut mieux lui en faire générer dix, puis les filtrer avec une couche de vérification. L'avantage est donc la diversité. Plusieurs Générateurs peuvent utiliser différentes stratégies, différents prompts, produisant des solutions difficiles à anticiper manuellement. L'étape de filtrage concentre fortement la qualité de la sortie finale.
Le point faible est que la qualité du barème (rubric) du Filtre détermine directement l'efficacité finale. Un barème mal conçu équivaut à l'échec de tout le processus.
Ce mode convient aux situations où la réponse correcte n'est pas connue à l'avance, lorsqu'il faut choisir la meilleure parmi plusieurs possibilités, et lorsqu'il y a un besoin explicite de diversité.
La ressemblance avec Fanout-And-Synthesize n'est que superficielle : Les deux sont "multi-voies parallèles → sortie unique", ce qui prête le plus à confusion.
La différence clé réside dans l'intention : Chaque voie de Fanout traite une partie différente de la tâche, les résultats sont complémentaires et toutes les voies contribuent à la fusion ; chaque voie de Generate-And-Filter traite la même tâche, les résultats sont compétitifs et la plupart sont écartés lors de la fusion. Le premier est un "puzzle", le second un "concours de beauté".
3.5 Mode tournoi (Tournament)
La logique centrale est l'élimination par compétition. N agents font indépendamment la même chose, sont éliminés tour par tour par comparaison par paires, pour finalement sélectionner la meilleure solution.
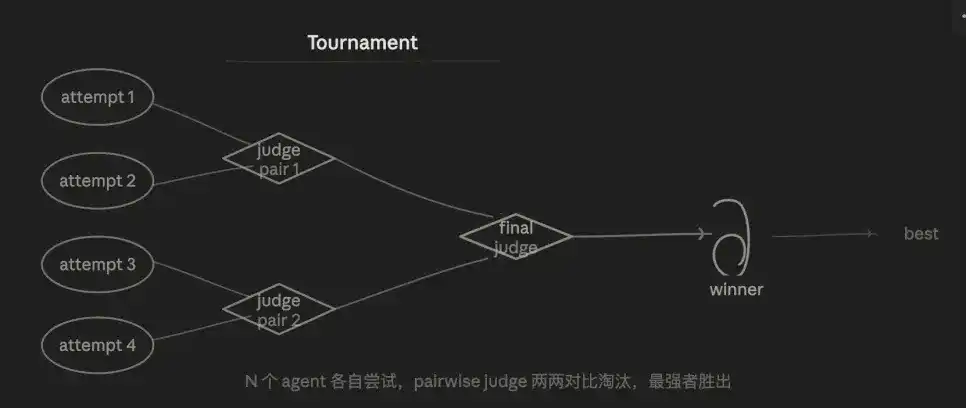
Je l'ai déjà fait manuellement auparavant — exécuter deux ou trois versions d'un même changement de code, puis faire comparer à l'IA laquelle est la meilleure. Maintenant, cela peut être directement intégré dans le flux de travail.
L'avantage est la stabilité du jugement. La comparaison par paires ("Lequel est meilleur, A ou B ?") est bien plus stable que la notation absolue ("Donnez une note à A"), car elle élimine le problème de la dérive des critères de notation. Le résultat, après plusieurs tours de compétition, a une crédibilité élevée.
La ressemblance avec Generate-And-Filter est également superficielle : Les deux sélectionnent le meilleur parmi plusieurs candidats. La différence clé réside dans le mécanisme de sélection : Tournament utilise un juge par paires pour comparer deux à deux, c'est "faire concourir les candidats entre eux". Lorsque le barème est difficile à quantifier et que le jugement est essentiellement relatif, il est plus fiable.
3.6 Mode boucle (Loop)
La logique centrale est l'itération adaptative, essayer continuellement, en cas de difficulté, collecter les informations d'erreur, compléter le contexte, réessayer, jusqu'à ce que les conditions d'acceptation soient satisfaites.
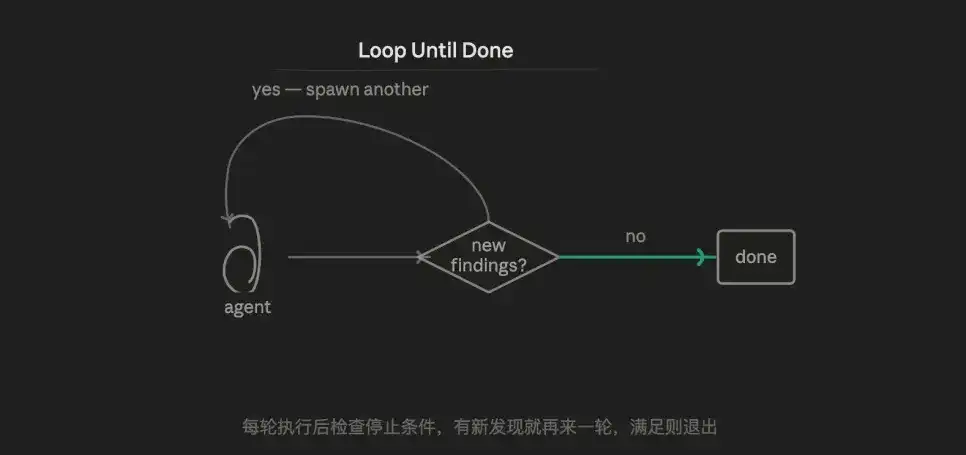
Il s'agit essentiellement de lutter contre le caractère aléatoire de l'IA : en essayant plusieurs fois, on finit toujours par obtenir un meilleur résultat. Mais une approche plus mature consiste à combiner la vérification contradictoire, pour que chaque boucle s'exécute avec plus d'informations, plutôt que de se fier uniquement au hasard.
L'avantage est la capacité à traiter les tâches dont la charge de travail est inconnue. Les cinq autres modes supposent que les limites de la tâche sont déterminées ; Loop Until Done est le seul mode capable de traiter "on ne sait pas combien de tours il faudra".
Le point faible est le risque potentiel de perte de contrôle — une mauvaise conception de la condition d'arrêt peut entraîner une boucle infinie. L'agent de chaque tour est dans un contexte entièrement nouveau, incapable d'accumuler un état inter-tours (sauf s'il est explicitement écrit dans un fichier).
IV. La bataille entre mes propres skills et le flux de travail officiel
Avant l'arrivée du flux de travail dynamique, j'avais conçu mon propre système de deep-research. La logique de mon skill était à peu près la suivante :
- Ne donner qu'une information simple (par exemple, un projet a lancé une nouvelle fonctionnalité)
- Demander à l'IA de rechercher toutes les informations pertinentes : documentation officielle, code source, opinions du marché
- Compresser les informations en un résumé significatif
- Faire une analyse contradictoire avec plusieurs rôles d'agents, générer un rapport
- Dédoublonner automatiquement, car le contenu des multi-agents présente un taux de répétition élevé
Après l'avoir utilisé un moment, je le trouvais pratique. Mais il avait un défaut fondamental : l'absence de convergence orientée vers un objectif.
Et même avec la cinquième étape de dédoublonnage, il supprimait souvent des informations de valeur. Sans dédoublonnage, le skill produisait facilement un long article de dix mille mots, très complet, mais ne vous disant pas directement "en quoi cela vous concerne, que devriez-vous faire".
Or, la recherche est au service de la "prise de décision", c'est pourquoi de nombreux skills s'arrêtent à la recherche elle-même, atteignant 80 points, mais manquant les 20 points les plus cruciaux.
De sorte qu'après avoir terminé la recherche initiale, l'IA devait souvent poursuivre dix fois plus de réflexions et de dialogues pour parvenir à une conclusion satisfaisante et complète.
Ce que le flux de travail dynamique officiel fait de plus
À travers plusieurs expériences cette semaine sur des tâches de recherche complexes, j'ai découvert que le flux de travail deep research intégré dans Claude Code (attention, pas seulement un skill, mais un module compilé intégré dans cc), par rapport à mon propre skill, ajoute plusieurs étapes clés :
- Couche de décomposition du problème : Il ne commence pas directement la recherche, mais pose d'abord des questions, décompose mon problème en plusieurs sous-questions : Que voulez-vous vraiment comprendre ? En quoi cela vous concerne-t-il ? Quelles dimensions méritent d'être approfondies ? Cette étape, je la sautais auparavant.
- Évaluation de la crédibilité : Évaluer la falsifiabilité de chaque information, similaire au score d'autorité dans le SEO traditionnel — la source est-elle fiable ? Combien de citations ? C'est un élément auquel je n'avais pas pensé auparavant.
- Suppression croisée plutôt que fusion moyenne : Ma méthode précédente était de prendre toutes les conclusions en moyenne, d'où des documents volumineux. Le flux de travail dynamique fait voter plusieurs agents sur chaque conclusion, supprime celles qui n'obtiennent pas assez de votes, ce n'est pas une simple fusion.
- Sortie orientée vers l'objectif : Le rapport final n'est pas un empilement d'informations, mais donne des jugements et des propositions de solutions centrés sur votre objectif initial. La clé pour y parvenir réside dans sa capacité prédéfinie à planifier les sous-agents multiples. La raison pour laquelle mon skill manquait facilement d'orientation finale était l'atténuation du poids de l'instruction après la masse d'informations.
Quels problèmes ces mécanismes résolvent-ils ?
Ils ciblent précisément les problèmes typiques de l'IA sur les tâches longues :
Dérive des objectifs : Bon état au début de la tâche, perte de fil au milieu, retour au rythme à la fin — comme un humain qui décroche en cours. Plus la tâche est longue, plus c'est évident.
Arrêt prématuré : En cours d'exécution, face à une difficulté, l'IA considère qu'elle a "terminé" et s'arrête, alors que les critères d'acceptation ne sont pas du tout atteints.
Pollution du contexte : Un seul agent effectuant une tâche complexe, les nombreux prompts initiaux compressent l'espace d'exécution ultérieur. Une meilleure approche est de limiter les prompts initiaux à quelques milliers de tokens et de répartir le contexte sur plusieurs agents.
Biais de sortie : L'IA a tendance à répondre en fonction de vos attentes, les questions informelles déclenchent plus facilement ce problème.
Le flux de travail dynamique résout structurellement ces quatre problèmes : ajout automatique de critères d'acceptation pour éviter les arrêts prématurés ; isolement parallèle du contexte ; vérification contradictoire pour contrer les biais de sortie ; décomposition du problème pour contraindre l'IA à comprendre l'objectif avant d'agir, couche par couche.
V. Conclusion
Enfin, en tant que chercheur de longue date, je suis stupéfait par ce nouveau mécanisme de CC. Ses six modes intégrés — routage, division-fusion, vérification contradictoire, génération-filtrage, tournoi, boucle — couvrent les besoins de planification de la grande majorité des tâches de recherche complexes.
Je n'ai plus besoin de concevoir manuellement la planification des agents, ni de faire moi-même le dédoublonnage et la vérification croisée, tout cela étant intégré au flux de travail lui-même.
Et il est particulièrement adapté à la réflexion sur l'exploration de questions ouvertes, manquant d'informations, car la planification multi-agent naturelle + la décomposition des objectifs de tâche améliorent encore sa généralité. En fait, il y a 3 ans, l'IA, sous contraintes successives et ne résolvant que des petits problèmes extrêmement clairs, était déjà très performante. Mais le véritable changement qualitatif de l'IA réside dans la généralité, c'est ce qui fait que ses concurrents passent d'un simple code à devenir de véritables Agents, de la résolution statique d'un problème à l'adaptation à n'importe quel problème.
Ainsi, le Dynamic Workflows n'est pas une "conversation unique plus intelligente", mais une structuration du processus de recherche lui-même.
Ce qui nécessitait auparavant une douzaine de conversations indépendantes pour la recherche est maintenant compressé en 3-4 fois. Bien que la consommation de Tokens correspondante ait augmenté de dizaines de fois.
Pourquoi faut-il encore 3-4 fois ? Je pense que la cause profonde réside dans les différences entre ces besoins.
Premièrement, la rigueur du mécanisme de vérification. Je fais principalement des recherches sur les nouvelles technologies de la blockchain. Souvent, la documentation officielle est en retard, et il existe des données plus pertinentes comme le code source ouvert, les transactions sur la chaîne, etc. Actuellement, l'IA par défaut se base encore sur la documentation officielle, plutôt que sur une vérification factuelle.
Deuxièmement, la réflexion profonde totalement interdisciplinaire. Bien que cela puisse être résolu dans une certaine mesure par des préréglages de flux de travail (prédéfinir des sous-agents de différentes dimensions) pour réfléchir au même problème, l'IA excelle surtout dans les modèles de pensée dominants. Pour les réflexions très nouvelles, très profondes, manquant de données, elle est légèrement insuffisante.
Troisièmement, la conception et la vérification des solutions. L'importance d'une solution ne réside pas dans sa proposition mais dans sa vérification et son soutien, qui reposent sur l'évaluation des mécanismes existants, des investissements et des coûts. Bien sûr, avec un bon entraînement, l'IA peut mieux faire, mais cela va à l'encontre de la généralité.
Enfin, la concentration extrême de l'information, qui nécessite de revenir à la compréhension du public cible. Certains n'ont aucune base et ont besoin d'une explication imagée et humaine, tandis que d'autres auditeurs veulent être convaincus en une phrase~.