Par | AI Lettres
Google s'inquiète vraiment.
Juste avant, des informations sont arrivées, indiquant que le cofondateur de Google, Sergey Brin, a relancé le "mode fondateur", supervisant personnellement et formant une "équipe d'assaut" d'élite, s'efforçant de rattraper Anthropic et d'autres concurrents sur des capacités clés comme la programmation IA et les agents autonomes de Gemini.
Ensuite, Google a annoncé tard dans la nuit une mise à jour majeure, lançant une nouvelle génération d'agents de recherche autonomes basés sur le modèle Gemini 3.1 Pro : Deep Research et Deep Research Max.
Non seulement les capacités de raisonnement sous-jacentes du modèle ont été renforcées, mais l'agent de recherche autonome est également poussé vers une évolution de niveau entreprise et de plateforme de développement, via l'ouverture d'API, le support des données privées, les tâches asynchrones en arrière-plan, etc., tentant de prendre l'initiative dans ce scénario à haute valeur qu'est l'"outil de recherche/analyse IA", pour répondre à la concurrence d'OpenAI (Hermes), Perplexity et autres.

Ces deux agents permettent pour la première fois aux développeurs, via un seul appel API, de fusionner les données du réseau ouvert avec les informations propriétaires des entreprises, et de générer nativement des graphiques et des infographies dans les rapports de recherche, tout en pouvant se connecter à n'importe quelle source de données tierce via le Model Context Protocol (MCP).
Ces deux agents sont désormais disponibles en version d'aperçu public via les forfaits payants de l'API Gemini, accessibles via l'API Interactions que Google a lancée pour la première fois en décembre 2025.
Oui, ces nouveaux agents ne sont actuellement utilisables que via l'API, les utilisateurs ordinaires de l'application Gemini n'y ont pas accès, même s'ils sont abonnés payants. Voyant les nouvelles de la mise à jour mais ne pouvant pas l'utiliser, certains utilisateurs se plaignent avec amertume : "Google, pour une raison quelconque, continue de punir nous, les utilisateurs abonnés Pro de l'application Gemini..."

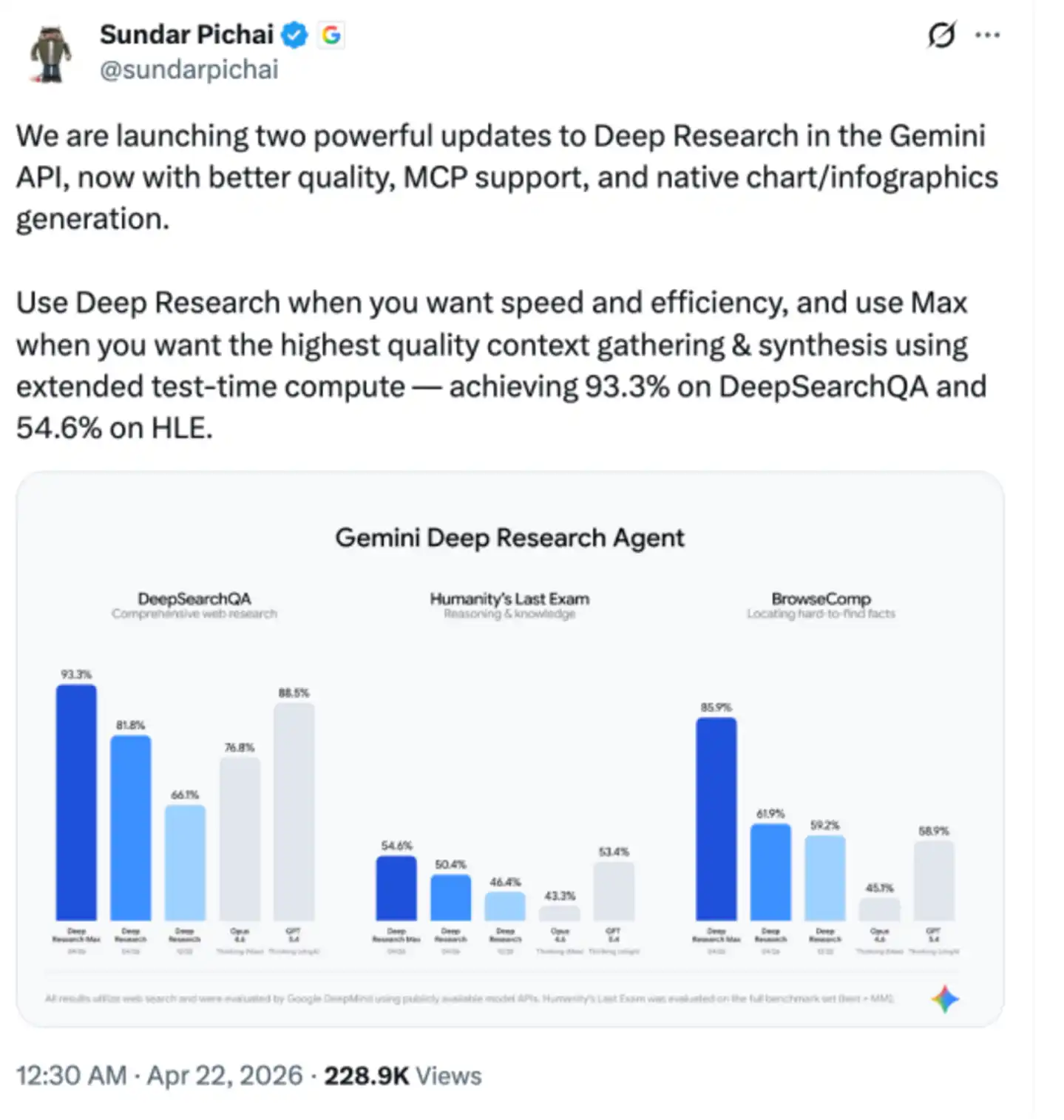
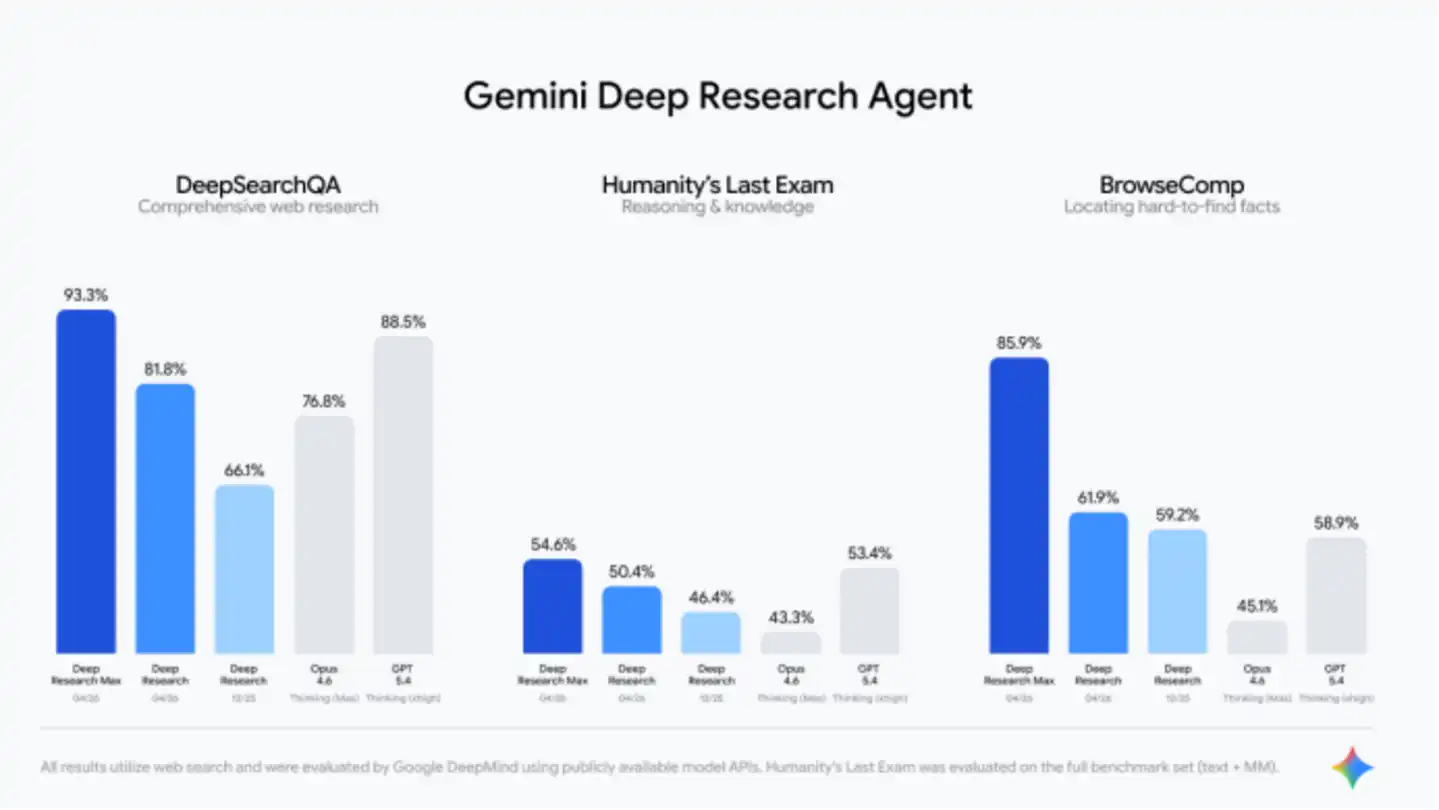
Le PDG de Google, Sundar Pichai, est également descendu personnellement sur X pour faire sa promotion : "Quand vous avez besoin de vitesse et d'efficacité, utilisez Deep Research ; quand vous recherchez la collecte et la synthèse de contexte de la plus haute qualité, utilisez la version Max — elle atteint des scores de 93,3 % sur DeepSearchQA et 54,6 % sur HLE grâce à un calcul étendu au moment des tests."
Il y a 18 mois, l'objectif de Google Deep Research était d'aider les étudiants à éviter d'être submergés par une multitude d'onglets de navigateur. Aujourd'hui, Google espère qu'il pourra remplacer le travail de recherche de base des analystes juniors en banque d'investissement.
L'écart entre ces deux objectifs — et la capacité de cette technologie à réellement combler cet écart — déterminera si l'agent de recherche autonome deviendra un produit transformateur dans le domaine des logiciels d'entreprise, ou simplement une autre démonstration d'IA brillante dans les benchmarks mais décevante en réunion.
Deux versions, adaptées à différentes charges de travail
La version standard Deep Research a une latence plus faible et un coût plus bas, adaptée aux scénarios où la vitesse prime.
Deep Research Max priorise la profondeur plutôt que la vitesse. Cet agent effectue un raisonnement approfondi, une recherche et une itération via un calcul étendu au moment des tests (extended test-time compute), pour finalement générer un rapport.
Google note que les flux de travail asynchrones en arrière-plan sont son scénario d'utilisation idéal, par exemple via une tâche planifiée (cron job) exécutée la nuit, livrant le lendemain matin un rapport complet de due diligence à l'équipe d'analystes.
Dans ses propres benchmarks, Deep Research Max a réalisé des progrès significatifs dans les tâches de récupération et de raisonnement. L'agent est capable d'obtenir des informations à partir de plus de sources que les versions précédentes, et de capturer des nuances subtiles que les anciens modèles négligeaient facilement.
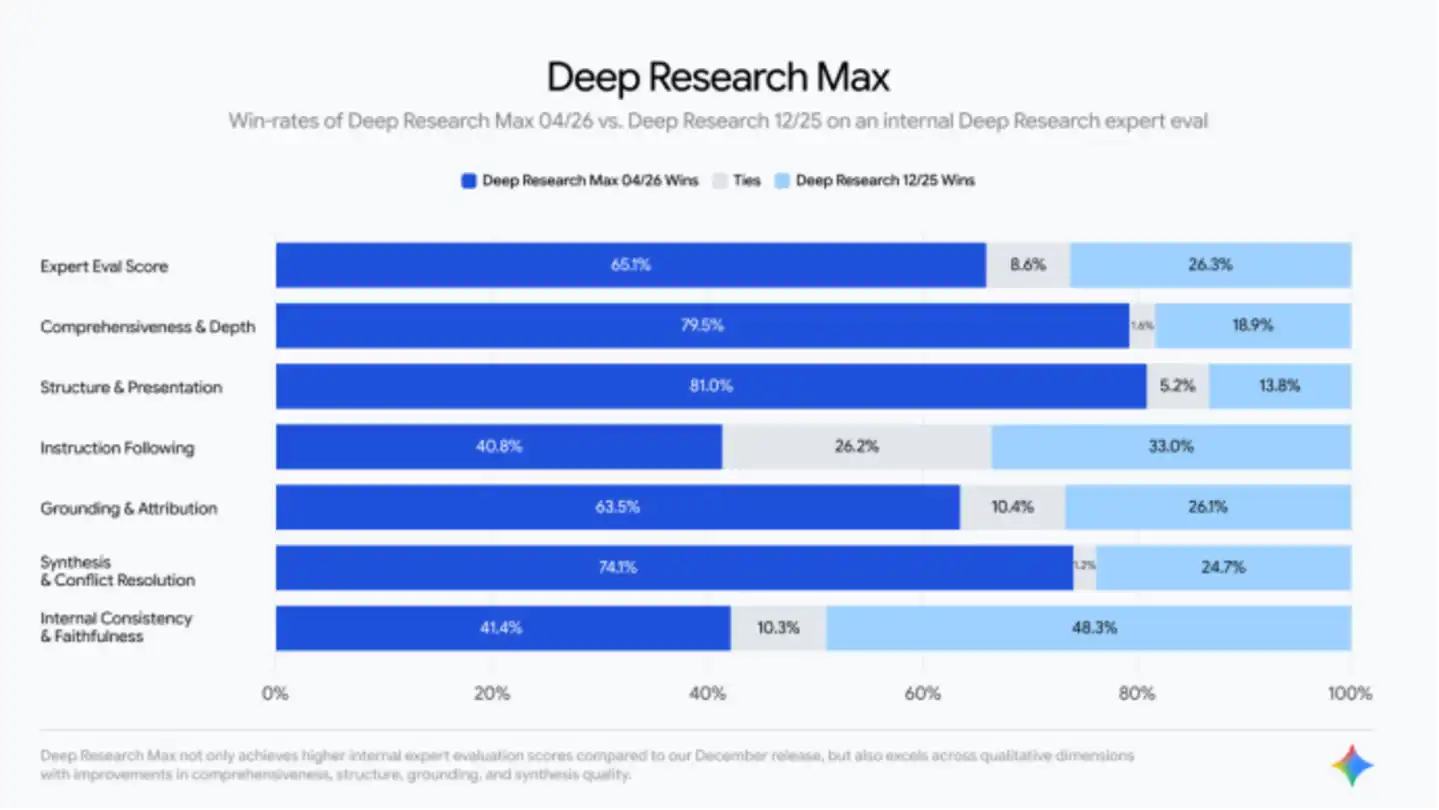
Google a également fourni une comparaison avec les concurrents.
Cependant, la comparaison avec GPT-5.4 d'OpenAI et Opus 4.6 d'Anthropic n'est pas tout à fait équitable. GPT-5.4 excelle dans la recherche autonome sur le web, mais n'est pas spécialement optimisé pour la recherche approfondie. Pour cela, OpenAI fournit son propre agent DR, qui est passé à GPT-5.2 et non GPT-5.4 après la mise à jour de février. Le modèle de recherche le plus puissant d'OpenAI est en fait GPT-5.4 Pro, mais Google ne l'a visiblement pas inclus dans le champ de comparaison.
Selon les données d'OpenAI, GPT-5.4 Pro peut atteindre un score maximum de 89,3 % sur le benchmark de recherche d'agents BrowseComp, tandis que GPT-5.4 obtient 82,7 %.
Sur la base de son propre rapport, Opus 4.6 d'Anthropic obtient un score sur BrowseComp supérieur à celui présenté par Google, spécifiquement 84 %. Ce score a été obtenu avec la fonction de raisonnement désactivée, le modèle performant mieux que le paramètre de raisonnement intensif utilisé par Google dans les benchmarks API.
Ces écarts proviennent probablement de différences dans les méthodes de test — que le modèle soit évalué via l'API brute ou encapsulé dans la propre chaîne d'outils de chaque laboratoire. Les données de Google ne sont pas nécessairement erronées, mais méritent une interprétation prudente. Quoi qu'il en soit, leur mode de présentation manque de transparence suffisante.
Support MCP
La fonctionnalité la plus impactante de cette version est peut-être l'ajout du support du Model Context Protocol (MCP). Cette fonction transforme Deep Research d'un outil de recherche web puissant en quelque chose de plus proche d'un "analyste de données universel".
MCP est une norme ouverte émergente pour connecter les modèles d'IA à des sources de données externes. Il permet à Deep Research d'interroger en toute sécurité des bases de données privées, des bibliothèques de documents internes et des services de données tiers spécialisés — tout au long du processus, les informations sensibles ne quittent pas leur environnement d'origine.
En pratique, cela signifie qu'un fonds de couverture peut simultanément pointer Deep Research vers sa base de données interne de flux de transactions et son terminal de données financières, puis demander à l'agent de combiner les deux avec des informations publiques provenant du web pour générer des insights synthétiques.
Google a révélé qu'il travaille activement avec des entreprises comme FactSet, S&P et PitchBook pour concevoir conjointement leurs serveurs MCP, indiquant clairement que Google cherche une intégration profonde avec les fournisseurs de données sur lesquels s'appuient quotidiennement Wall Street et le secteur financier au sens large.
Selon l'article de blog rédigé par les chefs de produit de Google DeepMind, Lukas Haas et Srinivas Tadepalli, l'objectif est "permettre aux clients communs d'intégrer leurs produits de données financières dans des flux de travail pilotés par Deep Research, et en exploitant son univers massif de données, de collecter du contexte à la vitesse de l'éclair, réalisant ainsi un bond en avant en matière de productivité."
Cette fonctionnalité répond directement à l'un des points douloureux les plus tenaces de l'adoption de l'IA par les entreprises : l'énorme écart entre les informations que le modèle peut trouver sur l'internet ouvert et les informations réellement nécessaires à la prise de décision de l'organisation. Auparavant, combler cet écart nécessitait un important travail d'ingénierie sur mesure.
Le support MCP, combiné aux capacités de navigation autonome et de raisonnement de Deep Research, simplifie la majeure partie de cette complexité en une simple configuration. Les développeurs peuvent maintenant faire en sorte que Deep Research utilise simultanément la recherche Google, des serveurs MCP distants, le contexte URL, l'exécution de code et la recherche de fichiers — ou désactiver complètement l'accès au web et effectuer des recherches uniquement sur des données personnalisées.
Le système prend également en charge les entrées multimodales, y compris les PDF, CSV, images, audio et vidéo, à utiliser comme contexte (grounding context).
Graphiques natifs
La deuxième fonctionnalité majeure est la génération native de graphiques et d'infographies.
Les versions précédentes de Deep Research ne pouvaient générer que des rapports en texte brut. Si l'utilisateur avait besoin de visualisations, il devait exporter les données et créer lui-même les graphiques. Cette lacune affaiblissait considérablement le positionnement "d'automatisation de bout en bout".
Désormais, la nouvelle génération d'agents peut intégrer nativement dans les rapports des graphiques et des infographies de haute qualité, rendant dynamiquement des ensembles de données complexes en HTML ou dans le format Nano Banana de Google, les intégrant directement dans la narration analytique.
Pour les utilisateurs entreprises — en particulier dans les secteurs financiers et de conseil qui ont besoin de produire des résultats directement livrables aux parties prenantes — cette fonctionnalité transforme Deep Research d'un outil "d'accélération de la phase de recherche" en un outil capable de générer un produit d'analyse proche du produit final.
De plus, combinée à la nouvelle fonction de planification collaborative (permettant aux utilisateurs de examiner, guider et optimiser le plan de recherche de l'agent avant l'exécution), ainsi qu'à la sortie en flux continu en temps réel des étapes de raisonnement intermédiaires, le nouveau système offre aux développeurs un contrôle granulaire sur la portée de l'enquête, tout en maintenant un haut degré de transparence requis par les industries réglementées.
Deep Research devient une partie de l'"infrastructure" que Google fournit aux entreprises
L'article de blog officiel de Google indique clairement que lorsque les développeurs utilisent l'agent Deep Research pour construire, ils appellent "la même infrastructure de recherche autonome qui alimente plusieurs produits populaires de Google (comme l'application Gemini, NotebookLM, Google Search et Google Finance)". Cela suggère que les agents fournis via l'API ne sont pas des versions simplifiées de la version interne de Google, mais le même système, offrant des services à l'échelle de la plateforme.
Ce processus d'évolution a été extrêmement rapide.
Google a lancé Deep Research pour la première fois dans l'application Gemini en décembre 2024, en tant que fonctionnalité B2C, alors propulsé par Gemini 1.5 Pro. Google l'a décrit comme un assistant de recherche IA personnel, capable de synthétiser les informations du web en quelques minutes, aidant les utilisateurs à économiser des heures de travail.
En mars 2025, Google a mis à niveau Deep Research en utilisant Gemini 2.0 Flash Thinking Experimental et l'a ouvert à l'essai pour tous. Ensuite, il est passé à Gemini 2.5 Pro Experimental, Google rapportant que les évaluateurs le préféraient à plus de 2 contre 1 par rapport aux concurrents.
Décembre 2025 a été un tournant important, Google lançant l'API Interactions, fournissant pour la première fois Deep Research de manière programmatique, propulsé par Gemini 3 Pro, et publiant simultanément le benchmark open source DeepSearchQA.
Le modèle sous-jacent qui pilote cette amélioration est Gemini 3.1 Pro, publié le 19 février 2026. Il a réalisé un bond en avant significatif dans les capacités de raisonnement de base : sur le benchmark ARC-AGI-2 évaluant la capacité des modèles à résoudre de nouveaux modes logiques, 3.1 Pro a obtenu un score de 77,1 %, plus du double de celui de Gemini 3 Pro.






