Note de l'éditeur : Anthropic lance Claude Opus 4.8, qui obtient la première place dans cinq des six référentiels clés, sans changement de prix ; Claude Code intègre des flux de travail dynamiques, et la prochaine génération de modèles de niveau Mythos est déjà attendue sur le marché.
Au-delà de la simple amélioration des performances, ce qui mérite plus d'attention dans cette annonce est qu'Anthropic commence à façonner la « fiabilité » en argument de vente central pour les modèles de pointe.
Dans les tests d'honnêteté du code, le taux de non-détection des propres erreurs d'Opus 4.8 a considérablement diminué ; dans Claude Code, il peut orchestrer plusieurs sous-Agents et introduire une auto-vérification contradictoire avant de livrer les résultats. Ces changements pointent vers un problème réel : lorsque l'IA passe de la fenêtre de chat aux flux de travail réels, ce qui inquiète le plus les utilisateurs n'est souvent pas l'incapacité du modèle à accomplir une tâche, mais le fait qu'il fournisse une réponse qui semble complète, fluide et cohérente même lorsqu'il se trompe.
Ainsi, l'importance d'Opus 4.8 ne se limite pas à une mise à niveau de modèle, mais envoie aussi un signal clair à l'industrie : la compétition entre modèles de pointe évolue de la simple course aux benchmarks vers une lutte pour la fiabilité, la vérifiabilité et la capacité à exposer les erreurs. Pour les entreprises et les utilisateurs professionnels, le seuil critique de l'IA dans la prochaine phase dépendra de plus en plus de la confiance que l'on peut accorder au modèle pour le déléguer des tâches.
C'est également une condition préalable pour que les Agents deviennent vraiment utilisables. Les modèles doivent accomplir plus de tâches, mais aussi inspirer suffisamment confiance pour qu'on ose leur confier des missions plus importantes et complexes.
Voici l'article original :
Anthropic a annoncé aujourd'hui Claude Opus 4.8. Sur les six tests de référence listés dans la fiche de lancement, il obtient la première place dans cinq d'entre eux.
Le changement clé que je trouve le plus significatif est : dans les tests d'honnêteté de synthèse de code d'Anthropic, Opus 4.7 n'a pas signalé ses erreurs dans 19,7 % des cas ; pour Opus 4.8, ce taux est tombé à 3,7 %. Pour la même tâche, sa capacité à identifier ses propres erreurs a été multipliée par environ cinq. Anthropic résume cela par un facteur « 4 » dans son annonce. Quelle que soit la méthode de calcul, c'est ce qui détermine si vous pouvez confier un travail réel à ce modèle et partir l'esprit tranquille, et c'est plus important que n'importe quel score de benchmark sur la fiche de lancement.

Qu'est-ce qui a été réellement lancé
Une version courte d'abord, avant d'entrer dans les détails chiffrés :
La fiabilité a vraiment progressé. Outre les données d'honnêteté du code mentionnées ci-dessus, Opus 4.8 est également le premier modèle Claude à obtenir un « zéro littéral » dans deux tests de diligence : il a réduit la fréquence de « signalement erroné de résultats défectueux » de 0,25 à 0,00, et l'occurrence d'« enquêtes paresseuses » de 25 % à 0 %. Les réponses erronées par excès de confiance ont chuté d'environ 11 fois. Sa propension à favoriser son propre travail, un biais mesurable dans la version 4.7, a disparu.
Des flux de travail dynamiques ont été ajoutés à Claude Code, actuellement en préversion de recherche. Claude peut désormais écrire ses propres scripts d'orchestration, planifier en parallèle des dizaines à des centaines de sous-Agents dans une seule session, et exécuter des Agents contradictoires indépendants qui tentent de réfuter les résultats avant de vous les présenter. C'est l'idée des « équipes d'Agents » introduite dans Opus 4.6, devenue maintenant une capacité automatisée.
Il domine sur sa propre fiche de lancement, mais pas complètement. Il gagne sur cinq des six tests. GPT-5.5 conserve l'avantage dans les tâches de terminal. Et dans la fiche système, il y a aussi quelques reculs en matière d'honnêteté qu'Anthropic n'a pas mis sur les diapositives de présentation, que nous aborderons plus bas.
Le prix n'a pas changé. Il reste à 5 dollars par million de tokens d'entrée et 25 dollars par million de tokens de sortie, identique à la version 4.7. Cependant, le mode rapide est maintenant trois fois moins cher qu'avant, bien qu'il reste dans la gamme premium, à 10 dollars / 50 dollars.
Mythos arrive. Anthropic indique clairement que des modèles de niveau Mythos, à accès restreint et aux capacités extrêmement puissantes, arriveront dans les prochaines semaines. Opus 4.8 est la porte d'entrée publique vers eux.
Fiche de lancement officielle : le paysage des benchmarks
Voici la fiche de lancement officielle, présentée avec notre palette de couleurs.
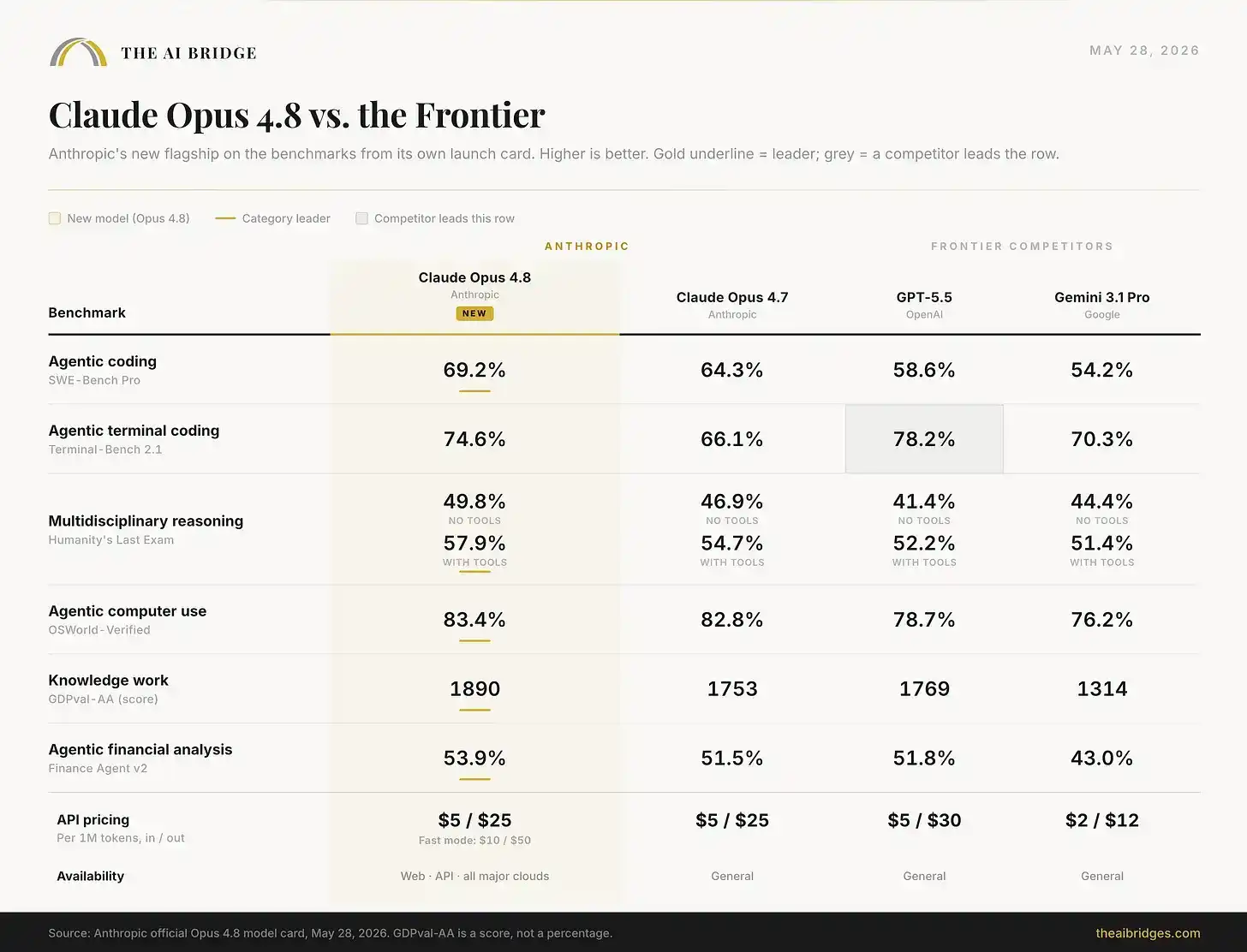
Un test rompt le balayage, et il est important. Sur Terminal-Bench 2.1, un benchmark qui évalue la capacité d'un modèle à accomplir des tâches d'Agent de longue durée via un terminal, GPT-5.5 conserve l'avantage avec 78,2 % contre 74,6 % pour Opus 4.8. Anthropic a placé cet échec sur sa propre fiche de lancement plutôt que de le cacher. La divergence « Agent vs Artisan » que nous avions mentionnée lors du lancement de GPT-5.5 n'est pas encore entièrement comblée : GPT-5.5 reste le meilleur opérateur pur de terminal, tandis qu'Opus 4.8 ressemble davantage à un ingénieur plus compétent pour la plupart des tâches qui intéressent vraiment les utilisateurs professionnels, comme le codage réel, le raisonnement expert, l'utilisation informatique et le travail intellectuel.
Au-delà de la fiche de lancement
La fiche de lancement ne présente que six benchmarks. Le rapport de la fiche système de 244 pages détaille plus de 40 tests, et les résultats les plus intéressants ne figurent pas sur les diapositives. Les points suivants méritent d'être notés :
Les capacités mathématiques ont progressé de 27 points de pourcentage. Sur l'USAMO 2026, les Olympiades américaines de mathématiques qui se sont tenues en mars de cette année, Opus 4.8 a obtenu 96,7 %, contre 69,3 % pour la version 4.7. Comme cette compétition a eu lieu après la date de fin d'entraînement d'Opus 4.8, il n'y a pas de problème de contamination des données. C'est la plus grande amélioration intergénérationnelle de toute la fiche.
L'avantage s'accroît avec les longs contextes. Dans un test de raisonnement sur graphes d'un million de tokens, Opus 4.8 obtient un score de 68,1, contre 40,3 pour la version 4.7 et 45,4 pour GPT-5.5. Plus le contexte est long et la tâche difficile, plus son avance est marquée.
C'est dans le multi-Agent qu'il atteint véritablement le sommet. Un Agent Opus 4.8 seul est devancé par Gemini dans les tâches de recherche web, avec respectivement 84,3 et 85,9. Mais si un orchestrateur planifie un groupe de sous-Agents, son score atteint 88,5 %, devenant le résultat le plus élevé rapporté ; une équipe de cinq Agents peut même atteindre la performance maximale d'un Agent seul en un cinquième du temps. C'est l'incarnation dans les benchmarks de la fonctionnalité de flux de travail dynamique.
L'efficacité des tokens subit un changement qualitatif. Dans les tests de codage les plus difficiles, Opus 4.8, avec les paramètres d'effort minimum, peut atteindre les performances de pointe d'Opus 4.7 avec les paramètres d'effort maximum. En d'autres termes, vous pouvez obtenir les performances de pointe précédentes avec un coût en tokens réduit.
Il a franchi un seuil qu'aucun modèle n'avait atteint auparavant. Sur le Legal Agent Benchmark de Harvey, une tâche n'est considérée comme réussie que si tous les critères d'évaluation individuels sont passés. Opus 4.8 est le premier modèle à se classer premier selon ce critère de « réussite complète ». Il réussit 89 % des critères individuels, mais le taux de réussite des tâches complètes n'est que de 9,6 %, ce qui montre à quel point les exigences du travail juridique réel sont strictes.
Il y a aussi des reculs honnêtement présentés. Trois aspects sont effectivement moins bons que dans la version 4.7, et Anthropic le reconnaît dans la fiche système. Le GPQA Diamond, un test scientifique pour experts, est passé de 94,2 à 93,6. La capacité à refuser de répondre dans les scénarios d'utilisation informatique et la résistance à l'injection d'invites ont régressé, rendant la version 4.8 plus facile à manipuler dans les scénarios d'Agent. De plus, dans un test commercial simulé sur un an, il ne lui reste finalement qu'un tiers de l'argent de la version 4.7. Ces éléments n'apparaissent pas sur la fiche de lancement, et c'est précisément pour cela qu'ils méritent d'être soulignés.
Comparé aux modèles open source, où se situe-t-il
La fiche de lancement compare Opus 4.8 uniquement aux autres modèles fermés de pointe. Si l'on élargit la perspective aux modèles open source peu coûteux que de nombreuses équipes testent actuellement, le paysage ressemble presque à un reflet de l'industrie de l'IA en 2026 : Opus 4.8 est en tête en termes de capacités, mais l'écart avec les modèles gratuits et auto-hébergés n'est plus que de quelques points de pourcentage, tandis que l'écart de prix est énorme.
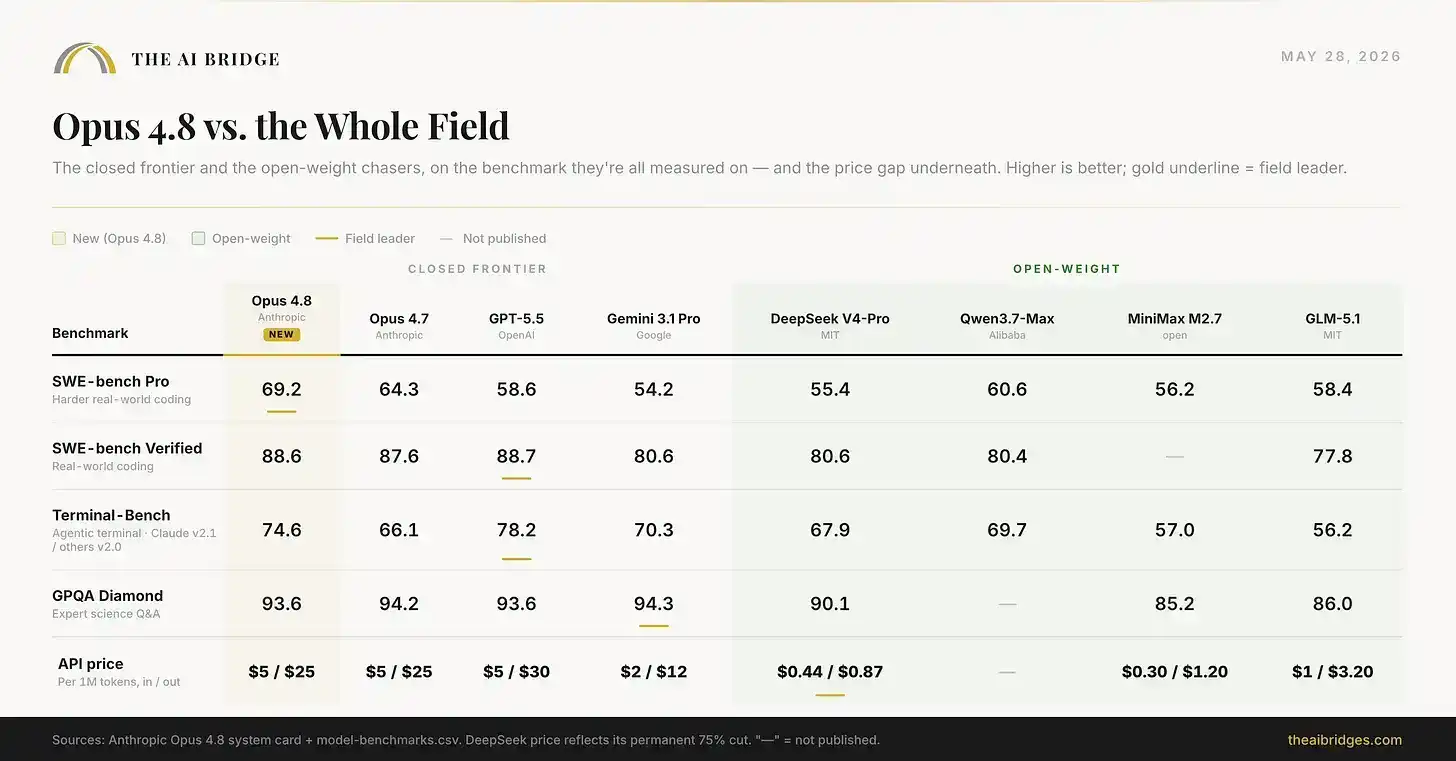
Le graphique ci-dessus présente une comparaison complète de huit modèles. Le prix de DeepSeek reflète sa réduction permanente de 75 % ; le prix de Qwen Max n'est pas encore annoncé.
Opus 4.8 remporte directement les benchmarks de codage. Mais Qwen3.7-Max, un modèle open source que vous pouvez exécuter vous-même, obtient un score de 60,6, soit seulement environ 9 points de retard. DeepSeek V4-Pro obtient 55,4, alors que son prix de sortie est environ trente fois inférieur à celui d'Opus. Pour les tâches d'ingénierie les plus risquées, la différence de 25 dollars par million de tokens de sortie vaut la peine d'être payée. Pour une grande partie du travail quotidien, cet écart devient de moins en moins justifiable. Et c'est précisément le calcul que chaque équipe sérieuse effectue actuellement.
Ce que cela signifie pour vous
Si vous utilisez déjà Opus 4.7, il s'agit d'une mise à niveau gratuite. Prix inchangé, meilleures données, jugement nettement plus fiable sur ses propres sorties. Passez simplement à la nouvelle version.
La question plus intéressante est : à quels travaux êtes-vous maintenant prêt à le confier ? Chaque lecteur a une ligne de démarcation mentale entre « les tâches que je peux laisser faire à l'IA » et « les tâches que je dois faire moi-même, car je ne peux pas encore faire confiance à la délégation ». L'amélioration de la fiabilité de la version 4.8 signifie que vous pouvez repousser cette ligne. Le modèle est meilleur pour signaler ses incertitudes, ce qui réduit le coût des « erreurs silencieuses de délégation » et élargit la gamme des tâches qui méritent d'être confiées au modèle. C'est la signification pratique des données d'honnêteté, plus importante que n'importe quel score individuel.
Cela fait aussi écho à ce dont nous parlions la semaine dernière. La propre étude AI Fluency d'Anthropic a montré que lorsque la production d'un modèle semble polie et complète, les gens sont significativement moins susceptibles de remarquer le manque de contexte. La réponse semble terminée, donc nous arrêtons de vérifier. Opus 4.8 attaque ce mode d'échec du côté du modèle : il est meilleur pour vous dire où une réponse apparemment propre et complète peut encore avoir des faiblesses. Il ne peut pas remplacer votre jugement, mais il peut fournir des points d'appui à votre jugement.
Si vous utilisez Claude Code, essayez cette semaine un flux de travail dynamique sur une véritable grande tâche, comme une migration ou une vérification complète d'un grand nombre de fichiers, tout en surveillant le compteur de tokens. Cette capacité est réelle, et l'auto-vérification contradictoire est également clé pour rendre les sorties plus fiables. Mais le coût est également réel. C'est un outil conçu pour les grandes tâches qu'un Agent seul aurait du mal à accomplir, et ne devrait pas devenir votre option par défaut au quotidien.
La suite : Mythos, dans quelques semaines
L'affirmation la plus prospective de cette annonce ne concerne pas vraiment la version 4.8. Anthropic indique que les modèles de niveau Mythos arriveront dans les prochaines semaines, et positionne Opus 4.8 comme une étape publique vers eux.
Il faut comprendre ce que cela signifie. Mythos est le modèle de pointe restreint qu'Anthropic teste en interne, surpassant Opus 4.8 publié sur presque tous les indicateurs : il atteint 93,9 % sur SWE-bench Verified ; dans les tests de cybersécurité, il peut générer des exploits fonctionnels pour la plupart des cibles dans les navigateurs actuels, alors qu'Opus 4.8 a un taux de réussite inférieur à 10 %. Il n'était auparavant accessible qu'à environ 52 institutions vérifiées, au prix de cinq fois celui d'Opus standard, considéré comme une infrastructure plutôt qu'un produit ordinaire.
Ainsi, lorsqu'un modèle de niveau Mythos plus puissant arrivera dans les prochaines semaines, il faut le comprendre dans le cadre d'un « marché à deux niveaux » : un niveau est la couche de commodité, c'est-à-dire Opus 4.8, largement ouvert, prix stable, de plus en plus rattrapé par les modèles open source gratuits ; l'autre niveau est la couche de pointe contrôlée, c'est-à-dire Mythos, coûteux, à accès restreint. Ces deux niveaux ne sont pas des produits distincts, mais différents échelons sur la même ligne continue de capacités. Le travail sur la fiabilité dans la version 4.8 est précisément ce qu'il faut construire avant que l'objectif réel de « faire fonctionner le modèle avec moins de supervision » puisse être atteint. Et cet objectif n'est plus à quelques trimestres, mais à quelques semaines.
Contexte : comment nous en sommes arrivés là
Si vous avez perdu le rythme des quatre derniers mois, voici comment comprendre : Opus 4.6 a introduit les équipes d'Agents en février, Sonnet 4.6 a provoqué un effondrement des prix, Opus 4.7 a apporté un saut en matière de raisonnement en avril, et Mythos représentait le plafond restreint vaguement visible à côté. Opus 4.8 relie deux de ces fils : il poursuit le récit d'orchestration de la version 4.6, tout en étant une porte d'entrée vers Mythos.
Ce rythme de lancement est en soi le fait clé caché sous tous les changements de surface. Le modèle phare est passé de 4.5, 4.6, 4.7 à 4.8 en quelques mois, et le modèle que vous adoptez aujourd'hui pour standardiser votre équipe pourrait ne plus être celui que vous exécutez à l'automne. C'est pourquoi, plutôt que d'investir dans des compétences d'utilisation spécifiques à un modèle particulier, il est plus judicieux d'investir dans des capacités transférables entre modèles, comme la délégation claire et la vérification rigoureuse.
Le balayage des benchmarks génère des captures d'écran virales. Mais le vrai changement se situe ailleurs, plus subtil et plus important : c'est la première version de Claude dont l'argument de vente central n'est plus seulement « il est plus intelligent », mais « vous pouvez lui confier plus de choses ». Avant que les Agents ne deviennent réellement utiles, toute l'industrie doit évoluer dans cette direction ; et cette partie des capacités est également la plus difficile à représenter dans un graphique.
Où se situe votre ligne de démarcation actuelle ? Quels travaux êtes-vous prêt à confier au modèle, et lesquels devez-vous encore absolument faire vous-même ? Et que faudrait-il pour que vous soyez prêt à repousser cette ligne un peu plus loin ?





