Auteur : Wang Jianshuo
Le 6 mars 2023, peu après la sortie de ChatGPT et avant même celle de GPT-4, j'ai participé avec Sarah à une interview sur ChatGPT – la troisième édition des "Traders' Talk" (Le podcast "Explications simples sur ChatGPT" est publié, bienvenue à l'écoute).
À cette époque, ChatGPT venait tout juste de sortir, et très peu de personnes l'avaient réellement utilisé. Cette interview de trois heures est restée longtemps en tête de la catégorie ChatGPT sur XiaoYuZhou. J'y avais lancé une vingtaine de jugements et de prédictions d'un seul coup, basés uniquement sur l'intuition et des informations limitées, sans vraiment de données. La transcription complète de cette interview est d'ailleurs toujours sur le compte public.
Nous sommes maintenant fin mai 2026, trois ans se sont écoulés, et l'IA a pris une forme inimaginable à l'époque.
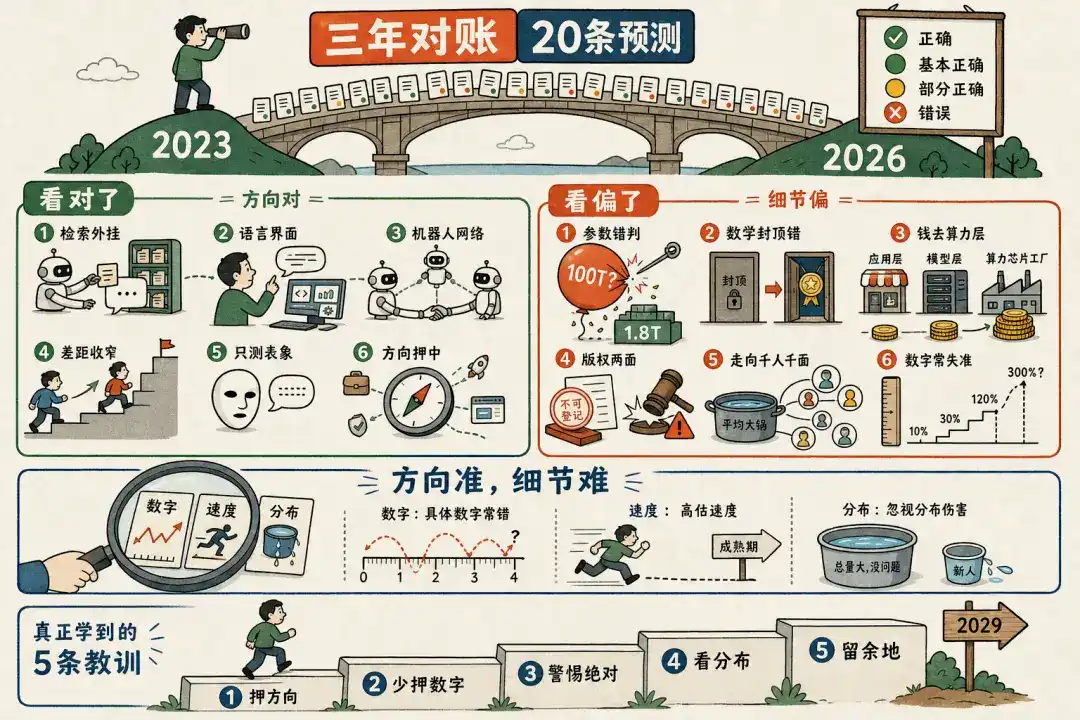
Je veux faire une chose : reprendre ces vingt points un par un et les confronter objectivement avec les dernières données disponibles aujourd'hui. Voir clairement comment le monde a évolué en trois ans, et voir clairement quels étaient mes points justes et mes erreurs de l'époque.
Pour essayer d'être aussi neutre que possible, j'ai cette fois-ci confié cette vérification à une IA : j'ai soumis la transcription de l'interview à un workflow, qui a fait appel à 41 agents Opus 4.8 pour d'abord détailler les vingt jugements, puis rechercher individuellement les données les plus récentes, vérifier chaque point, et enfin noter le Wang Jianshuo d'il y a trois ans. Ces agents ont mis environ 20 minutes, brûlé 1,4 million de tokens (environ 35 dollars) et généré le rapport ci-dessous. Les jugements viennent d'eux, pas de moi. La date de référence est fixée à mai 2026.
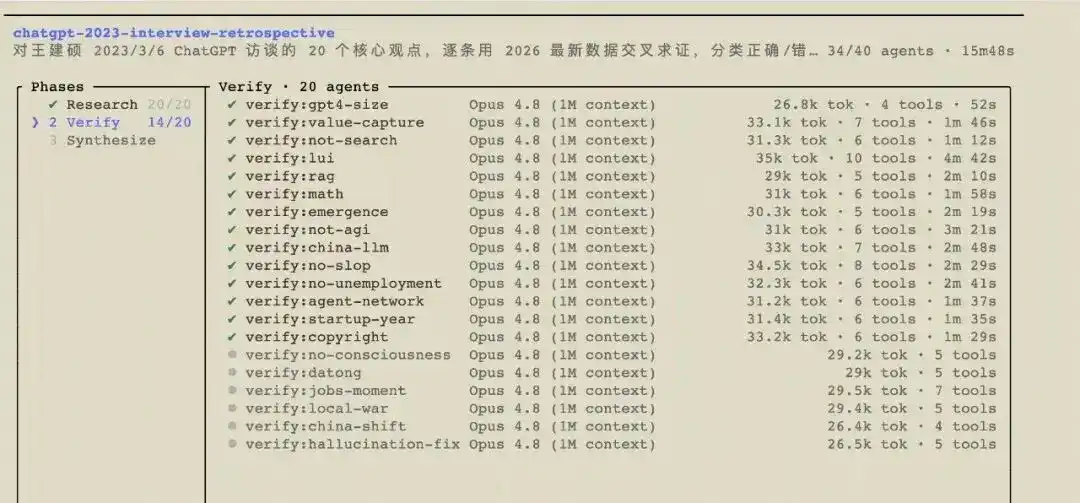
I. Tableau des scores
Symboles de jugement : ✅ Correct · 🟢 Essentiellement correct · 🟡 Partiellement correct · ❌ Erroné
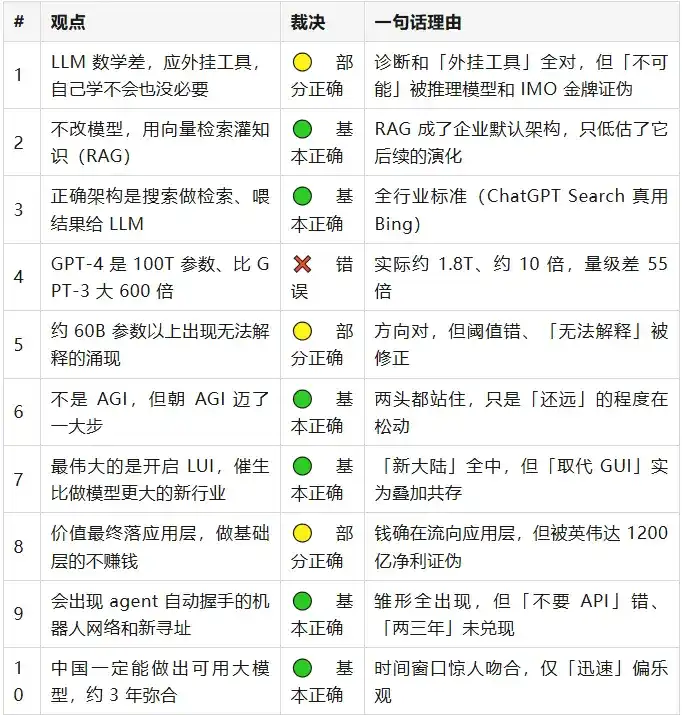
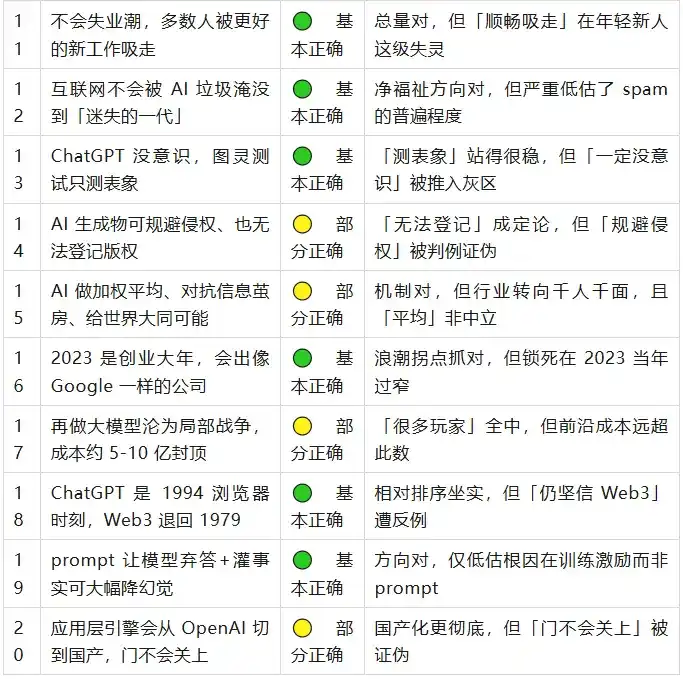
Globalement, les grandes lignes de Wang Jianshuo de l'époque tiennent la route, une seule est franchement erronée – avoir donné 100T de paramètres pour GPT-4. Mais le diable est dans les détails : derrière presque chaque point « correct », se cache une queue d'imprécision. Sur les vingt points, aucun n'est purement « encore incertain », trois ans sont suffisamment longs pour que la plupart des choses aient pris une direction. Parlons-en plus en détail par groupe.
II. Ceux qu'il a vus juste
Le point commun de ce groupe est : la direction, le mécanisme, et même le rythme temporel de ses jugements d'alors sont corrects, les erreurs ne portent que sur le « degré » et la « formulation absolue ».
RAG et architecture de recherche (Points 2, 3)
> En 2023, Wang Jianshuo disait : La méthode principale pour résoudre la connaissance et les hallucinations n'est pas de modifier le modèle, mais d'utiliser la recherche vectorielle pour injecter des connaissances comme des « antisèches » ; l'architecture correcte est celle où un moteur de recherche effectue la recherche et passe les résultats au LLM.
C'est le standard de fait aujourd'hui pour tous les produits d'IA. Le RAG est devenu l'architecture par défaut de l'IA en entreprise, OpenAI, Google, Anthropic l'ont tous intégré comme capacité de plateforme ; ChatGPT Search est littéralement « d'abord indexer et rechercher avec Bing, passer les résultats à GPT, puis générer des réponses avec références ». Google AI Overviews utilise le "grounding" pour atteindre environ 2 milliards d'utilisateurs actifs mensuels, Perplexity, une entreprise basée uniquement sur cette architecture, a vu sa valorisation atteindre environ 200 milliards de dollars.
À une époque où GPT-4 n'était pas sorti et où l'industrie pariait par défaut sur « l'injection de connaissances par fine-tuning », il a parié sur « ne pas toucher aux paramètres du modèle, recherche externe », le mécanisme et le timing étaient bons.
Pour être honnête : il envisageait une « recherche statique ponctuelle », mais la réalité est plus complexe – le contexte long, le GraphRAG, la recherche agentique sont venus le renforcer. Le débat de 2026 « Le RAG est mort » prouve précisément que la direction générale n'est pas morte, il rejette le « RAG naïf ponctuel », et conclut à un passage à une recherche hybride, pas à un retour au changement de paramètres du modèle. Autre point : le terme RAG a été introduit dans un article de Meta en 2020, ce n'est pas lui qui l'a inventé – il a juste parié au bon moment qu'il deviendrait la norme.
LUI est un nouveau continent (Point 7)
> En 2023, Wang Jianshuo disait : Le plus grand de ChatGPT n'est pas l'AIGC, mais d'avoir ouvert la voie à la LUI (Interface Utilisateur en Langage Naturel), qui va restructurer l'interaction homme-machine comme l'a fait la GUI, et créer une nouvelle industrie bien plus grande que celle des « grands modèles » eux-mêmes.
La partie « nouveau continent » est presque entièrement correcte. Le langage naturel est devenu la couche d'interaction dominante pour le grand public (ChatGPT, 900 millions d'utilisateurs actifs par semaine), et a fait émerger une industrie nouvelle et indépendante – les agents, les agents de codage, la couche protocolaire se sont tous réalisés. La phrase la plus concrète « bien plus grande que celle des modèles eux-mêmes » a été fortement confirmée : le protocole MCP est devenu le « standard du système d'exploitation » de l'ère LUI, adopté massivement par OpenAI, Google, Microsoft en 2025, transféré à la Linux Foundation fin 2025 ; Claude Code à lui seul a atteint environ 2,5 milliards de dollars de revenus annualisés.
Mais il a utilisé des formulations fortes comme « restructurer, remplacer la GUI », et trois ans plus tard, c'est une superposition et coexistence, pas un remplacement. Trois contre-exemples sont solides : un rapport du MIT montre que 95% des projets pilotes d'IA générative en entreprise n'ont pas de ROI mesurable ; les agents d'utilisation informatique opérant directement sur l'interface n'atteignent que 78% sur les ensembles de test avec les meilleurs modèles, à peine au niveau de la référence humaine ; les périphériques purement vocaux sans écran ont presque tous échoué (Humane Pin a définitivement fermé en 2025). Une formulation plus précise serait : la LUI est une nouvelle couche d'interaction superposée à la GUI.
Réseau d'agents et nouveau système d'adressage (Point 9)
> En 2023, Wang Jianshuo disait : Dans environ dix ans, un « réseau d'agents » apparaîtra – les agents utiliseront le langage naturel pour établir des connexions automatiques, s'appeler mutuellement, sans besoin d'API traditionnelles ; un tout nouveau système d'adressage de type nom de domaine naîtra. Ce système « pourra être achevé en deux ou trois ans ».
La direction est étonnamment juste. Le MCP, A2A (donné à la Linux Foundation, soutenu par plus de 150 organisations) résout l'inter-appel d'agents ; l'Agent Network Protocol, basé directement sur le DID du W3C, vise un « adressage d'agents sans autorité centrale », avec pour objectif un « réseau collaboratif de milliards d'agents » – c'est hautement similaire à son « tout nouveau système de noms de domaine ».
Deux corrections : premièrement, « plus besoin d'API » ne tient pas, les protocoles dominants ont un schéma structuré en couche basse, essentiellement une standardisation au-dessus des API ; deuxièmement, « achevé en deux ou trois ans » ne s'est pas réalisé, les données de Gartner montrent qu'en 2026, seulement environ 17% des organisations ont réellement déployé des agents. Il est intéressant de noter qu'à l'époque, il avait en fait hiérarchisé son propos – la forme embryonnaire « deux ou trois ans », la maturité « environ dix ans ». Le rythme de la forme embryonnaire était très juste, le cycle de maturité est bien de l'ordre de la décennie. En séparant les deux niveaux, la qualité de ce point est plus élevée qu'il n'y paraît.
La Chine pourra certainement produire des grands modèles utilisables (Points 10, 20)
> En 2023, Wang Jianshuo disait : La Chine pourra certainement produire des grands modèles utilisables, l'écart avec le haut de gamme se comblera rapidement, en environ trois ans (analogie avec le navigateur Red Flag rattrapant Netscape).
Le timing est étonnamment juste. L'AI Index 2026 de Stanford montre que l'écart mesuré entre les meilleurs modèles chinois et américains est passé de 17,5–31,6 points de pourcentage en mai 2023, à 2,7% ; alors que l'investissement privé en IA aux États-Unis est environ 23 fois supérieur à celui de la Chine – une convergence réalisée avec des investissements bien moindres. DeepSeek, Qwen, Kimi, GLM sont devenus des acteurs mondiaux majeurs, l'écosystème open source est même en avance.
Mais le mot « rapidement » était un peu optimiste – la véritable maturité est arrivée environ 14 mois plus tard, pas en « quelques mois ». Et il s'agit de rattraper l'utilisabilité, pas de définir la frontière : début 2026, aucun modèle chinois n'a encore dépassé l'OpenAI o3. Sur le point 20, son erreur est flagrante : le jugement « une fois la porte ouverte, elle ne se refermera pas » a été directement contredit par OpenAI coupant activement l'API à la Chine en juillet 2024, la porte a été fermée par le fournisseur ; le Wenxin Yiyan qu'il citait comme leader a en fait décroché, ceux qui ont pris le relais étaient les DeepSeek, Doubao, Qianwen, insignifiants à l'époque.
Pas de conscience, le test de Turing ne teste que l'apparence (Point 13)
> En 2023, Wang Jianshuo disait : ChatGPT n'a pas de conscience, c'est du « parleur sans intention, auditeur avec sensibilité », de l'autosuggestion ; le test de Turing teste en fait « s'il vous fait croire qu'il en a », pas s'il en a vraiment.
Le jugement central « tester l'apparence » tient très bien, et a même été confirmé de manière ironique par une expérience : en 2025, lors d'un test de Turing de l'UC San Diego, GPT-4.5, sous une instruction « incarner un personnage », a été jugé humain à 73%, plus que les humains réels, mais uniquement grâce à des techniques de jeu d'acteur – c'est la meilleure illustration de « ne tester que si cela vous fait croire qu'il en a ».
Il faut ajouter : l'affirmation absolue « la machine n'a certainement pas de conscience » est devenue une zone grise en trois ans. Anthropic a créé un poste de recherche sur le « bien-être des modèles », donne une probabilité de conscience d'environ 15-20%, et a ajouté à Claude une fonction pour « mettre fin activement aux dialogues abusifs ». Cela a transformé « absolument pas » en « faible probabilité mais non exclue ». Cependant, tout cela est basé sur « possible, devrions supposer » et non « prouvé », le noyau n'est pas renversé, mais le ton d'alors était trop catégorique.
Autres points vus juste (Points 6, 11, 12, 16, 18, 19)
- Pas l'AGI mais un grand pas en avant
: Les deux aspects tiennent. Altman lui-même à l'ère GPT-5 dit toujours « pas l'AGI, manque d'apprentissage continu » ; en même temps, médailles IMO, ARC-AGI passant de près de zéro à 85%, « un grand pas en avant » est incontestable. - Pas de vague de chômage
: En avril 2026, le taux de chômage américain était seulement de 4,3%. L'angle mort est la « distribution » – une étude de Stanford montre que ce sont précisément les jeunes débutants de 22-25 ans au premier échelon de l'échelle professionnelle qui sont touchés, le mécanisme « d'absorption fluide » a dysfonctionné pour eux. - Pas d'engloutissement par les déchets d'IA
: La direction du bien-être net est juste, mais il a gravement sous-estimé l'ampleur – le contenu généré par IA représente environ 52% des nouvelles pages web, « AI slop » est devenu le mot de l'année. - Grande année pour les startups
: Le point d'inflexion de la vague est bien ciblé, xAI (fondée en mars 2023) atteint une valorisation de 2300 milliards. Mais il a restreint « les grandes entreprises » à celles de 2023, ce qui est trop étroit – les vraies entreprises de l'ordre du billion comme OpenAI, Anthropic ont été fondées plus tôt. - Moment navigateur 1994
: L'ordre de grandeur relatif est confirmé, OpenAI a vraiment lancé le navigateur Atlas en 2025, transformant la métaphore en réalité littérale. Seulement, la diffusion de ChatGPT a été plus forte que celle des navigateurs, la métaphore était prudente. - Le prompt avec faits réduit les hallucinations
: La direction est confirmée, GPT-5 hors ligne sans recherche a un taux d'hallucination qui atteint 47%, confirmant par contraste que les « faits » sont une variable clé. Il a juste sous-estimé que la cause profonde est dans l'incitation à l'entraînement, pas dans le prompt.
III. Ceux qu'il a vus faux ou de travers
GPT-4 a 100T de paramètres (Point 4) – Totalement faux
> En 2023, Wang Jianshuo disait : (Rumeur) GPT-4 a 100T de paramètres, environ 600 fois plus que les 175B de GPT-3.
Les deux chiffres sont faux. GPT-3 fait 175B, la meilleure estimation fuite en juillet 2023 est que GPT-4 fait environ 1,8T, MoE avec 16 experts, seulement environ 10 fois. 100T diffère de la réalité d'un facteur 55. La seule source du « 100T » est une citation de seconde main approximative du PDG de Cerebras en 2021, Sam Altman avait dès janvier 2023 qualifié ce tableau comparatif de « complete bullshit » en face.
Il avait marqué ses propos avec « rumeur », indiquant l'incertitude. Plus profondément, le cadre lui-même « mesurer les générations par un multiple des paramètres » est devenu obsolète : OpenAI avec GPT-4.5, GPT-5 ne publie plus le nombre de paramètres. C'est le seul point vraiment faux à la fois sur les chiffres et sur la perspective.
Mathématiques des LLM (Point 1) – Diagnostic correct, conclusion définitive erronée
> En 2023, Wang Jianshuo disait : Les faiblesses en maths des LLM sont intrinsèques, leur faire apprendre les maths par eux-mêmes est à la fois impossible et inutile, la bonne approche est d'ajouter des outils externes.
Le « diagnostic et la voie des outils » sont entièrement corrects – la cause profonde est bien que la génération token par token rend les retenues peu fiables (un article de 2025 a confirmé précisément l'intuition du « dernier chiffre souvent correct, celui du milieu souvent faux ») ; l'amélioration par des outils externes est également énorme (o4-mini avec Python atteint 99,5% à l'AIME 2025).
L'erreur est dans les termes définitifs « impossible, inutile ». « Impossible » est infirmé – en juillet 2025, Gemini Deep Think et des modèles OpenAI ont obtenu des médailles d'or à l'IMO en utilisant uniquement le langage naturel, sans outils. Le tournant clé est l'apparition des « modèles de raisonnement » en 2024-2025, impossible à prévoir en mars 2023 – donc pour ce point, il faut juger avec bienveillance la direction, et non critiquer le timing.
Captation de la valeur (Point 8) – Pari gagné à moitié, l'affirmation centrale est contraire
> En 2023, Wang Jianshuo disait : La valeur finira par se situer au niveau applicatif, les entreprises pionnières de la couche fondamentale (les faiseurs de modèles) ne seront pas nécessairement rentables à la fin.
L'argent commence effectivement à affluer vers la couche applicative (Cursor a atteint 2 milliards de revenus annualisés en trois ans) – c'est à moitié juste. Mais « les faiseurs de la couche fondamentale ne sont pas rentables » est directement infirmé par NVIDIA : bénéfice net FY2026 environ 1200 milliards de dollars, valorisation > 5000 milliards, c'est le seul acteur du marché clairement très rentable. Alors que la couche des modèles, qu'il sous-entendait gagnante (OpenAI prévoit une perte d'environ 14 milliards en 2026), ressemble plutôt à sa description de « couche fondamentale brûlant de l'argent sans en gagner ».
Il n'a pas distingué « la couche fondamentale de calcul » de « la couche fondamentale de modèles », ni « les revenus » du « profit ». En 2026, la valeur est capturée de manière plus extrême par la couche de calcul qu'en 2023, pas transférée vers la couche applicative. À ajouter : ce sont les fournisseurs de cloud achetant les puces qui perdent de l'argent, pas NVIDIA qui les vend – c'est le décalage de son analogie de la « construction excessive des chemins de fer ».
Droits d'auteur (Point 14) – L'enregistrement correct, l'évitement de l'infraction erroné
> En 2023, Wang Jianshuo disait : Le contenu généré par IA pourrait contourner le droit d'auteur (protection de l'expression, pas de l'idée) ; les productions pourraient à la fois ne pas être des infractions et ne pouvoir être enregistrées.
« Ne pouvoir être enregistré » est devenu un fait juridique établi (en 2025, le US Copyright Office a indiqué clairement qu'« une simple saisie de prompt ne suffit pas à revendiquer la paternité »). Mais « contourner l'infraction » est clairement faux : les tribunaux ont répété que si la sortie d'IA est substantiellement similaire à l'œuvre originale, elle constitue toujours une infraction ; Anthropic a conclu un accord de 1,5 milliard de dollars pour des données d'entraînement contrefaites, la plus grande indemnisation pour violation de droits d'auteur de l'histoire des États-Unis. L'IA n'a pas « contourné » le droit d'auteur, elle en a payé le prix le plus élevé de l'histoire.
Monde uni (Point 15) – Mécanisme correct, tendance parée à l'envers
> En 2023, Wang Jianshuo disait : ChatGPT fait une « moyenne pondérée » des opinions humaines, pourrait contrer les chambres d'écho de type TikTok, offre une possibilité de « monde uni ».
Le niveau du mécanisme est correct – plusieurs études en 2025 ont confirmé que les LLM poussent les opinions vers la majorité, sous-estimant systématiquement les minorités. Mais le jugement social est parié à l'envers : son propre ajout « du moins pour l'instant ce n'est pas personnalisé » a été renversé en trois ans – OpenAI a rendu la mémoire inter-dialogues et la personnalisation des capacités par défaut à partir d'avril 2025, l'IA va rapidement vers la personnalisation. Plus crucial encore, il a imaginé la « moyenne pondérée » comme une médiane neutre mondiale, mais les tests montrent qu'il s'agit d'un décalage directionnel, avec en plus de la complaisance, qui peut être utilisé pour manipuler activement les positions – cela pointe vers « créer de nouvelles chambres d'écho », pas « dissoudre la polarisation ».
Guerres locales et coûts (Point 17) – Qualitatif entièrement juste, quantitatif infirmé
> En 2023, Wang Jianshuo disait : Faire des grands modèles va rapidement devenir des « guerres locales », le coût est connu (environ 5-10 milliards de dollars plafond en évitant les détours), de nombreux acteurs vont entrer.
La direction qualitative est étonnamment juste – afflux massif de joueurs, commoditisation rapide, l'open source rattrape le privé, tout s'est réalisé. Mais le chiffre dur « 5-10 milliards plafond » est faux aux deux extrémités : l'extrémité de pointe est gravement sous-estimée (niveau GPT-5 en 2026 à 2-5 milliards de dollars d'entraînement, plus des datacenters à milliards et le Stargate à 5000 milliards) ; l'extrémité de la réplication est surestimée (DeepSeek a réduit le coût marginal d'entraînement au niveau du million de dollars). Le « coût » d'un même modèle peut varier d'un facteur 200 selon l'acception, mais il n'est pas dans l'intervalle qu'il a donné.
Capacités émergentes (Point 5) – Direction correcte, chiffres et délimitation erronés
> En 2023, Wang Jianshuo disait : Au-dessus d'environ 60B de paramètres apparaissent des capacités nouvelles, absentes des données d'entraînement et inexplicables par les chercheurs.
L'intuition directionnelle est valable, mais deux formulations ne tiennent pas : premièrement, il n'y a pas de seuil unique « 60B » – le seuil réel pour la chaîne de pensée est d'environ 100B, différentes capacités émergent à des échelles diverses entre 13B et 540B ; deuxièmement, l'« inexplicable » a été remis en question fin 2023 par un article NeurIPS – beaucoup de « mutations » sont des illusions dues au choix des métriques d'évaluation, avec des courbes lisses et prévisibles avec des métriques continues. Pour être juste, à l'époque, il rapportait le récit absolument dominant, ce qui peut être corrigé c'est de prendre « 60B » comme un seuil dur et « inexplicable » comme une conclusion qualitative.
IV. Regard après trois ans, quelques principes
Après avoir vérifié point par point, en prenant du recul, ces vingt jugements de Wang Jianshuo cachent des principes plus dignes d'être retenus que n'importe quel point individuel.
I. La direction est bien plus fiable que les chiffres et les degrés. Sur les vingt points, tous ceux qui jugent des mécanismes et des directions (RAG, LUI, réseau d'agents, test de Turing) sont presque tous justes ; tous ceux qui donnent des chiffres précis ou des formulations définitives (100T paramètres, seuil 60B, coût 5-10 milliards, maths « impossibles ») sont presque tous faux. Pour un domaine qui évolue rapidement, pariez sur la direction, le mécanisme, moins sur les chiffres précis, et méfiez-vous des mots qui ferment toute possibilité comme « impossible, certainement, plafond, absolument aucun » – ce sont des zones à haut risque de se tromper avec le temps.
II. En termes de temps, il a tendance à surestimer la vitesse, à sous-estimer l'ampleur. Là où il dit « rapidement, achevé en deux ou trois ans », la période de maturité est généralement plus longue ; mais il sous-estime le plafond des bonds de capacité – les maths peuvent passer de « impossibles » à des médailles d'or à l'IMO, les coûts de pointe peuvent augmenter à des niveaux inimaginables à l'époque. En un mot : trop optimiste à court terme, trop conservateur à long terme.
III. L'erreur la plus insidieuse revient systématiquement sur la « distribution ». Ce n'est pas une erreur de direction, mais de ne regarder que le total, en ignorant la distribution. « Pas de vague de chômage » est juste, mais les dommages sont concentrés sur les jeunes débutants ; « La valeur se situe au niveau applicatif » est juste à moitié, mais ne distingue pas la couche de calcul et la couche des modèles. Le total est juste, masquant un désastre de distribution – c'est la leçon la plus importante à retenir.
IV. Les endroits où il laissait de la marge tiennent tous le coup trois ans plus tard. « Rumeur », « du moins pour l'instant », « réduire considérablement plutôt qu'éliminer », « forme embryonnaire deux ou trois ans, maturité environ dix ans » – tous les jugements qui à l'époque avaient des qualificatifs, des niveaux, sont plus solides aujourd'hui. Au contraire, les phrases absolues sorties sans réflexion sont les plus susceptibles de se retourner. L'honnêteté de la prédiction est à moitié dans l'audace de dire, et à moitié dans l'audace d'indiquer sa propre incertitude.
V. Certaines questions, trois ans ne suffisent pas. À qui revient finalement la valeur, l'émergence est-elle un vrai changement, la machine a-t-elle une once de conscience, le contexte long va-t-il manger le RAG – ces débats d'alors, en 2026, sont toujours des débats. Savoir distinguer « ce qui a déjà une réponse » de « ce qui doit encore attendre » est plus important que de se précipiter pour tirer des conclusions sur tout.
Il y a trois ans, Wang Jianshuo, guidé par l'intuition dans le brouillard d'avant GPT-4, a pointé vingt directions. Aujourd'hui, après vérification, la phrase la plus importante à retenir est peut-être : voir les grandes directions n'est pas si difficile, le difficile est d'admettre qu'on a pris à la légère, encore et encore, les chiffres, la vitesse et la distribution. Ces vingt vérifications, plutôt que de noter le passé, servent plutôt à établir quelques règles pour les trois prochaines années. Dans trois ans, en 2029, nous reviendrons les vérifier.