Une facture de 500 millions de dollars en un mois !
Ces derniers jours, le monde de la technologie a été secoué par une énorme bévue. Selon Axios, une entreprise aurait accumulé une facture de 500 millions de dollars sur Claude en seulement un mois !
La raison est à la fois cocasse et désolante : la direction, en ouvrant l'accès à Claude aux employés, a oublié de fixer une limite d'utilisation.

En réalité, cette entreprise est loin d'être la seule victime de factures d'IA astronomiques.
En avril dernier, un utilisateur de Google Cloud a reçu une facture de 18 000 dollars après qu'une clé API, laissée publiquement accessible dans un service, a été détournée. Le budget initial n'était que de 7 dollars.

Cet utilisateur malchanceux s'appelle Jesse Davies, un consultant en IA australien et fondateur d'Agentic Labs. Il avait pourtant mis en place deux garde-fous pour son compte Google Cloud : une alerte budgétaire à 10 dollars australiens (environ 7 USD) et un plafond de dépenses strict de 1 400 dollars.
Selon Tom's Hardware, des attaquants ont découvert un service Cloud Run qu'il avait publié depuis AI Studio quelques mois plus tôt et ont envoyé plus de 60 000 requêtes. Les deux protections ont été inefficaces : le calcul de la facture ayant un décalage, le système n'a pu réagir à temps et le montant avait déjà grimpé à 18 000 dollars.
Mi-mai, Peter Steinberger, fondateur du projet open source OpenClaw, a partagé sur X une capture d'écran : une facture d'API OpenAI de 1,3 million de dollars sur 30 jours.
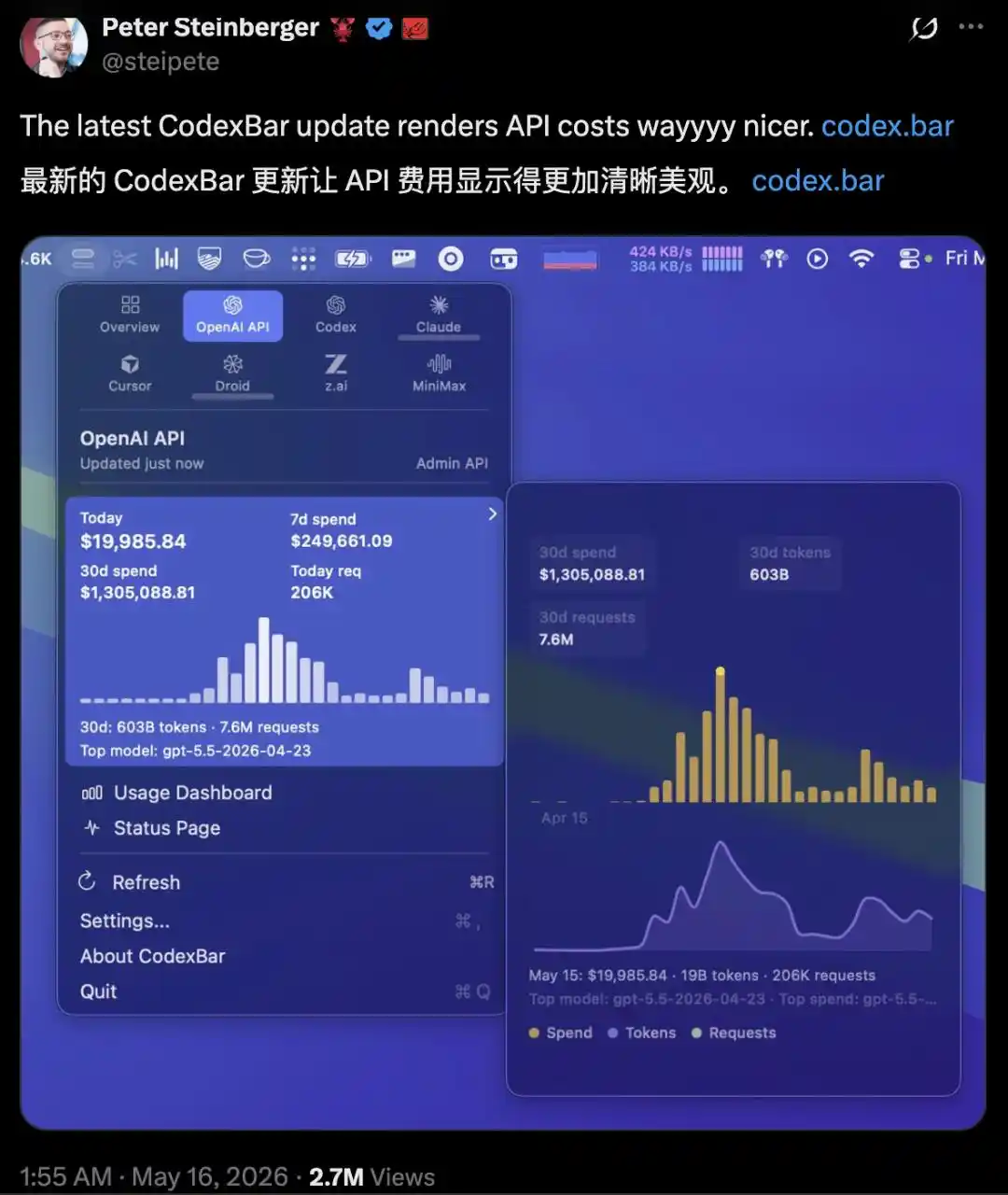
Son équipe ne compte que trois personnes, mais ils dirigeaient 100 agents Codex fonctionnant en parallèle : en 30 jours, ils ont consommé 603 milliards de Tokens et effectué 7,6 millions de requêtes. Heureusement pour lui, ces 1,3 million de dollars n'étaient pas à sa charge.
Steinberger ayant rejoint OpenAI en février dernier, ces 1,3 million de dollars ont été considérés comme une expérience interne :
tester les limites de la programmation par IA si l'on ignore le coût des Tokens. Il a ajouté que ce résultat provenait du mode « Fast Mode » de Codex (facturation élevée), et qu'en le désactivant, le coût serait d'environ 300 000 dollars.
Un peu plus tôt, Praveen Neppalli Naga, le CTO d'Uber, avait également admis à The Information que l'entreprise avait déjà épuisé son budget annuel pour Claude Code en avril, et leur COO a publiquement déclaré que les coûts de l'IA devenaient de plus en plus « difficiles à justifier ».
500 millions, 1,3 million, 18 000 dollars – bien que les montants diffèrent de plusieurs ordres de grandeur, ils pointent tous vers le même fait :
À l'ère des agents intelligents, une clé incontrôlée, une armée d'agents fonctionnant 24h/24, un compte sans limite définie : n'importe lequel de ces facteurs peut faire exploser votre facture de Tokens en une nuit.
Pourquoi les factures d'IA explosent-elles ?
La réponse se trouve principalement dans l'évolution des modes de facturation.
Depuis avril dernier, OpenAI a commencé à passer d'un modèle d'abonnement mensuel à une facturation basée sur la consommation de Tokens.
Le 2 avril, la facturation de Codex est passée d'une estimation par messages à un alignement sur la consommation de Tokens : les Tokens d'entrée, de cache d'entrée et de sortie sont désormais facturés séparément. Le 23 avril, cette règle a été étendue à tous les forfaits Enterprise, Edu, Health, et Gov : la remise invisible incluse dans l'abonnement mensuel a été supprimée.
GitHub a rapidement emboîté le pas, annonçant officiellement que tous les forfaits Copilot passeront à une facturation à l'usage à partir du 1er juin 2026. L'ancienne logique des requêtes premium est abandonnée, remplacée par des crédits IA, calculés sur la consommation réelle de Tokens d'entrée, de sortie et de cache, en fonction des tarifs API de chaque modèle.

GitHub a expliqué les raisons de ce changement :
Actuellement, une question rapide en chat et une tâche de codage autonome de plusieurs heures coûtent le même prix à l'utilisateur. GitHub a longtemps subventionné les utilisateurs effectuant des tâches intensives, mais ce modèle n'est plus viable.
Avant l'essor des agents IA, les coûts du chat et de l'auto-complétion étaient similaires, et l'abonnement mensuel suffisait.
Avec l'avènement des agents intelligents, une seule tâche peut s'exécuter pendant des heures, modifiant des bases de code entières. L'écart de coût entre les utilisateurs intensifs et légers peut atteindre plusieurs ordres de grandeur. Face à cet écart, le modèle forfaitaire s'effondre.
Cette annonce a provoqué un tollé sur Reddit et X.
Un développeur sous le pseudo JBusu a partagé une capture d'écran de sa facture, qualifiant le nouveau tarif de « blague ». Ses frais mensuels, auparavant de 28,12 dollars, passeraient à 746,01 dollars avec le nouveau système. Il a décidé de se désabonner, déclarant : « À ce prix-là, louer mon propre serveur cloud serait moins cher. »
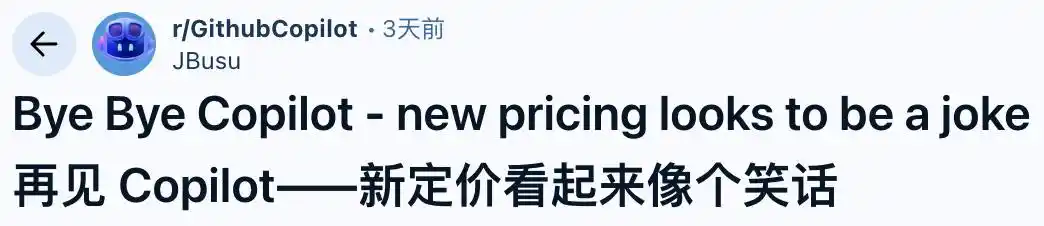
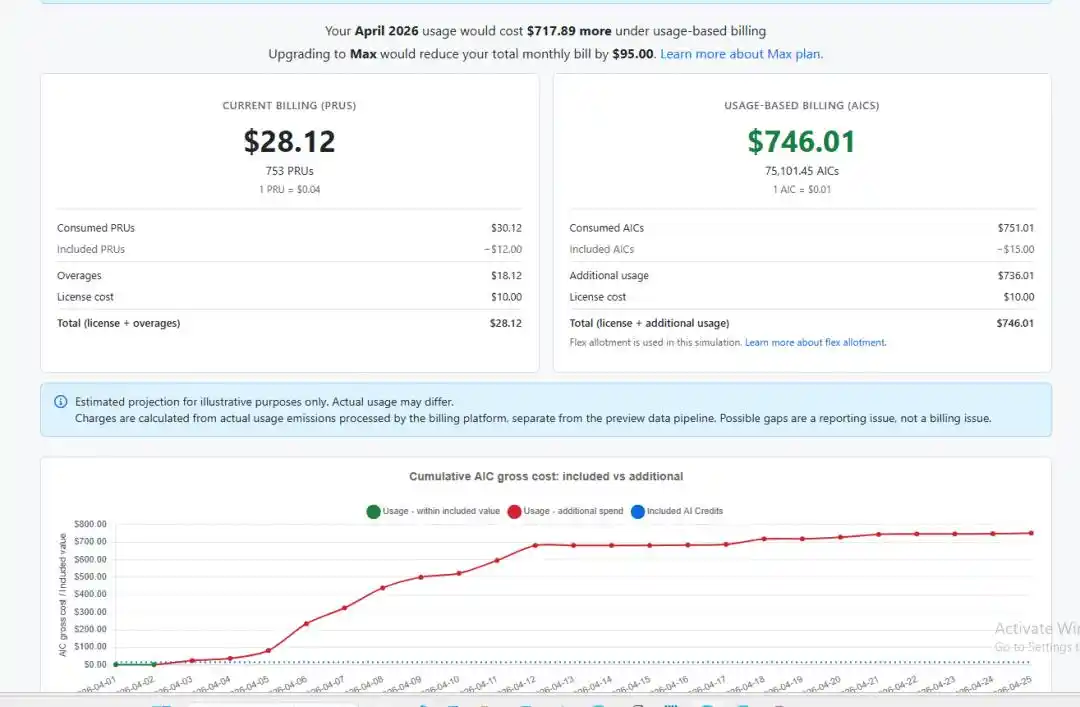
Un autre utilisateur a partagé une capture d'écran encore plus choquante, où les frais sont passés de 50 à 3000 dollars. Il a exprimé son incrédulité face à une tarification si « déraisonnable », demandant : « Y a-t-il encore des gens qui vont rester abonnés ? »
Cependant, certains utilisateurs chevronnés de Copilot ont contre-argumenté : ces factures extrêmes proviennent probablement de « vibe-coders » (codeurs à l'instinct) qui gaspillent les Tokens sans compter, et ne représentent pas une utilisation normale.
Un vétéran a commenté : « Je l'utilise toute la journée et je dépasse rarement mon quota à la fin du mois. Il est difficile de croire que cela soit dû à une différence de complexité du travail. » Un autre a été plus direct : « Certains veulent juste un développement en mode YOLO entièrement automatisé, laissant l'IA tourner librement. Éliminer ce gaspillage est une bonne chose pour les autres. »
Une chose doit être claire : GitHub n'a pas supprimé l'abonnement mensuel, le prix de l'abonnement de base reste inchangé. Ce qui change vraiment, c'est que l'utilisation supplémentaire, les tâches d'agents intelligents et les appels aux modèles plus coûteux entrent désormais dans la facturation à l'usage.
Les plus touchés sont les utilisateurs intensifs d'agents qui utilisent Copilot pour des tâches en chaîne longue.
Le classement saboté par ses propres utilisateurs
La fin de la forfaitisation mensuelle est due d'un côté à un changement des règles de facturation par les plateformes, et de l'autre à une consommation effrénée par les utilisateurs d'IA eux-mêmes.
En mai, Business Insider a rapporté qu'Amazon avait mis hors ligne un classement interne de l'utilisation de l'IA nommé KiroRank.
Le rapport, citant des sources informées, indique que ce classement a encouragé une méthode de travail étrange : certains employés, pour grimper dans le classement, consommaient des Tokens sur des tâches ne résolvant aucun problème réel, uniquement pour améliorer leur position.

Après la révélation de l'affaire, Dave Treadwell, vice-président senior d'Amazon, a directement interpellé tous les employés : « N'utilisez pas l'IA pour utiliser l'IA. Utilisez-la pour résoudre les problèmes des clients, résoudre les problèmes métier, pour innover. »
Cette affaire, bien qu'absurde, n'est guère surprenante. Lorsque « brûler des Tokens » permet de figurer dans un classement, les employés se mettent naturellement à brûler des Tokens.
La Silicon Valley a même donné un nom à ce phénomène : Token maxxing (pousser les Tokens à l'extrême), assimilant la consommation à la productivité.
Le rapport d'Axios mentionne également qu'un CTO a découvert que des employés utilisaient les modèles d'IA les plus avancés et coûteux pour des tâches simples comme vérifier la météo ou rédiger des e-mails courants, faisant grimper la facture en silence.
KiroRank n'était pas un outil officiel d'évaluation d'Amazon, mais un outil informel créé spontanément par des employés. Cependant, il a clairement exposé une loi classique du management : lorsqu'un KPI est mal défini, les gens trouvent les moyens les plus astucieux pour le contourner.
Assimiler la « quantité utilisée » à la « qualité du travail effectué » – c'est précisément la racine institutionnelle du gaspillage actuel de l'IA.
Ceux qui comptent les Tokens sont déjà en train de gagner de l'argent
L'autre face de l'anxiété liée aux factures de Tokens, c'est que certains en ont discrètement fait une affaire.
Première voie : rassasier l'IA avec du contexte.
Glean est justement l'entreprise d'Arvind. Elle propose un assistant de travail IA pour les entreprises : unifier les connaissances dispersées dans toute l'entreprise pour que l'IA des employés ait directement accès au contexte, sans avoir à fouiller partout. L'IA fait moins de détours, et consomme donc moins de Tokens.
Ce mécanisme a permis aux revenus annuels de Glean de tripler en 15 mois, dépassant les 300 millions de dollars, avec des clients comme Databricks, Reddit, Samsung.
Deuxième voie : répartir les tâches entre les bons modèles.
C'est ce que fait la startup Factory AI, spécialisée dans le routage de modèles : elle attribue automatiquement chaque tâche au modèle le plus approprié, les tâches simples aux modèles bon marché, les tâches complexes aux modèles haut de gamme. Arvind l'a aussi mentionné : un routage correct peut réduire les coûts par 10.
Ces deux voies convergent vers le même objectif : faire travailler l'IA, mais sans la laisser gaspiller.
La recherche académique pose également les bases de cette transition.

https://arxiv.org/pdf/2604.22750
Un article arXiv d'avril 2026 a, pour la première fois, systématiquement décomposé comment les tâches de codage par agent intelligent consomment de l'argent.
Conclusion 1 : La consommation de Tokens des tâches d'agents intelligents peut être jusqu'à mille fois supérieure à celle du raisonnement de code standard ou des conversations de code, la principale cause de l'augmentation des coûts étant les Tokens d'entrée.
Conclusion 2 : L'exécution multiple de la même tâche peut entraîner des différences de consommation de Tokens allant jusqu'à 30 fois.
Conclusion 3 : Une consommation de Tokens plus élevée n'entraîne pas nécessairement une plus grande précision. La précision atteint souvent son maximum à un coût moyen – brûler plus d'argent au-delà n'apporte pas d'amélioration supplémentaire, l'effet sature.
L'article a également constaté que même les modèles de pointe ne parviennent pas à prédire combien de Tokens ils vont consommer, sous-estimant généralement le coût réel.
Vous pensez que dépenser plus permet d'accomplir plus. En réalité, l'argent est dépensé, le travail n'est pas forcément meilleur, et le budget est imprévisible.
Quand la facture d'IA commence à rattraper le coût de la main-d'œuvre
« C'est la première fois de ma carrière que je vois le coût de la technologie commencer à égaler celui de la main-d'œuvre. »
C'est ce qu'a déclaré le CEO de Glean, Arvind Jain, le 29 mai dernier lors d'une interview avec la journaliste Deirdre Bosa de CNBC.
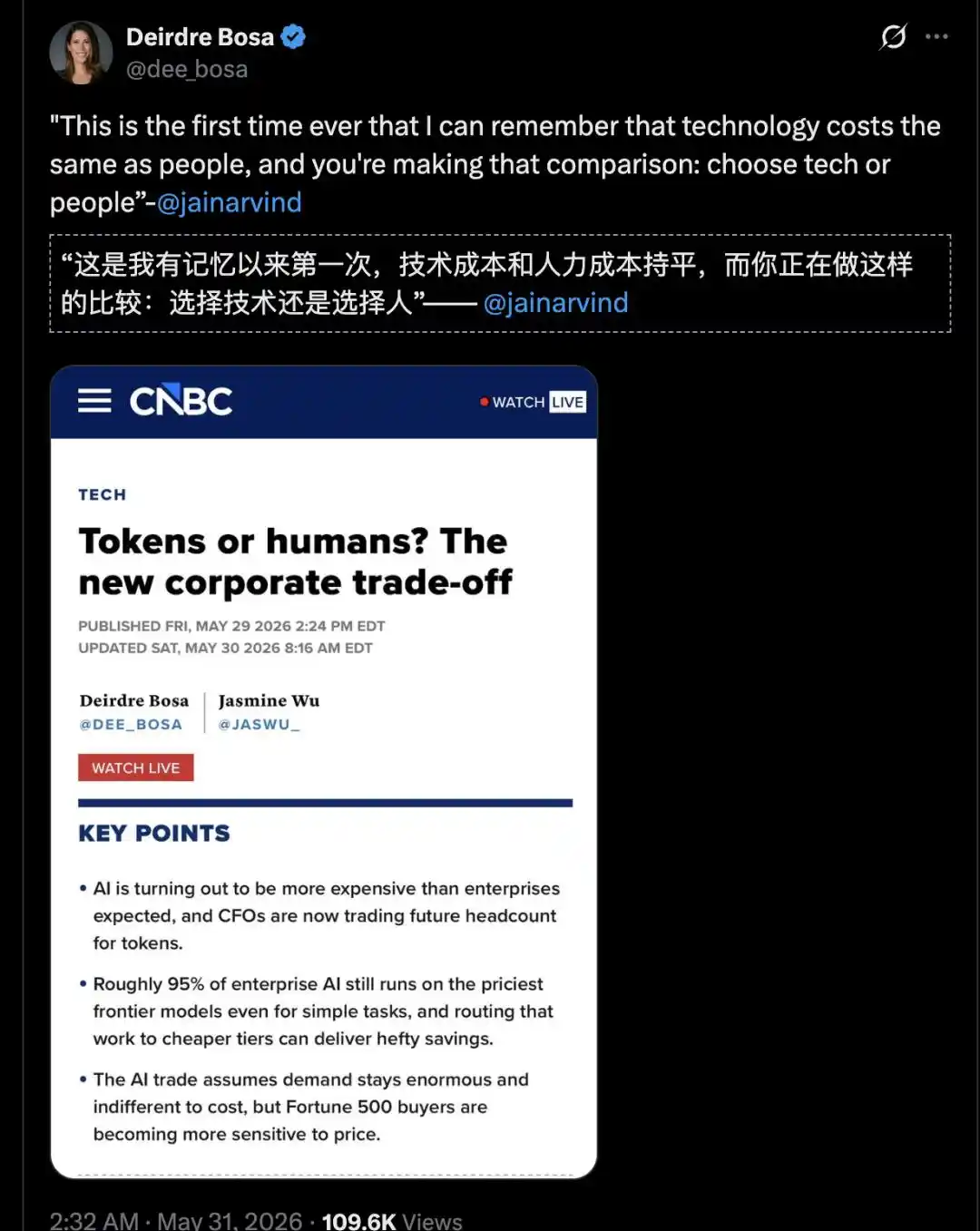
Les observations de Bryan Catanzaro, vice-président de l'apprentissage profond appliqué chez Nvidia, confirment également ce point.
Il a mentionné dans un entretien avec Axios : pour son équipe, le coût de la puissance de calcul dépasse de loin les salaires des employés.
Un phénomène similaire émerge dans plusieurs entreprises : de Glean, qui vend de l'IA pour les entreprises, à Nvidia, qui vend la puissance de calcul pour l'IA, en passant par Uber, qui utilise l'IA, tous réévaluent cette équation.
Selon Arvind, historiquement, la technologie ne représentait qu'une petite partie des coûts globaux d'une entreprise, mais désormais le coût de l'IA peut rivaliser avec la masse salariale. Le budget annuel dédié à l'IA dans de nombreuses entreprises est souvent épuisé en un ou deux mois.

Au cours de la dernière année, le taux d'utilisation de l'IA était un indicateur vénéré : plus on l'utilise, plus on est avancé ; brûler des Tokens, c'est embrasser l'avenir. Aujourd'hui, de nombreuses entreprises commencent à réfléchir à cette question simple : qu'obtient-on en échange de tous ces Tokens brûlés ?
C'est précisément à ce moment que la fenêtre d'utilisation gratuite ou forfaitaire illimitée se referme.
Désormais, la question qui se pose à tous les développeurs est la suivante : comment optimiser chaque centime pour que chaque Token délivre sa valeur maximale.
Les futurs gagnants seront sans aucun doute ceux qui apprendront les premiers à compter leurs Tokens.
Références :
https://x.com/dee_bosa/status/2060791500049613306%20
https://www.cnbc.com/2026/05/29/-tokens-or-humans-the-new-corporate-trade-off.html%20
https://www.axios.com/2026/05/28/ai-spending-roi-enterprise-costs%20
https://www.businessinsider.com/amazon-ai-leaderboard-tokenmaxxing-2026-5
Cet article provient du compte WeChat public « 新智元 », auteur : ASI启示录






