À l'instant, Claude Sonnet 5 est arrivé !
Nom de code Fennec, le fennec, le plus petit renard du désert du Sahara.
C'est le modèle Sonnet d'Anthropic à ce jour avec les capacités d'Agent les plus puissantes, et ses performances rivalisent avec le modèle phare Opus 4.8.
À partir d'aujourd'hui, Sonnet 5 devient le modèle par défaut pour tous les utilisateurs Free et Pro.

Il peut planifier de manière autonome, utiliser des outils de navigateur et de terminal.
Il y a seulement quelques mois, cela nécessitait encore un budget conséquent pour faire appel à des modèles surdimensionnés. Aujourd'hui, Sonnet s'en charge aisément.
Par rapport à la génération précédente Sonnet 4.6, les performances de Sonnet 5 ont considérablement progressé dans les tâches de raisonnement, d'utilisation d'outils, de programmation et de travail de connaissances.
Points clés :
Score SWE-bench Pro de 63,2 %, dépassant les 58,6 % de GPT-5.5 et légèrement inférieur aux 69,2 % d'Opus 4.8.
Score au « dernier examen de l'humanité » de 57,4 %, à seulement 0,5 point de pourcentage d'Opus 4.8.
Prix standard de 3 $ par million de tokens en entrée / 15 $ en sortie, soit seulement 60 % du prix d'Opus 4.8.
Taux de réussite d'injection navigateur défensif de 0,93 %, surpassant Mythos 5 et Opus 4.8.

Fait intéressant, Fable 5 a également été révélé le même jour comme devant bientôt faire son retour. Mais au prix d'une vérification d'identité obligatoire, et très probablement limité aux utilisateurs américains.
Alors que Sonnet 5 mise sur une accessibilité totale, les utilisateurs du monde entier peuvent dès aujourd'hui l'utiliser sans restriction.

Performance au niveau d'Opus 4.8 sur toute la ligne, l'IA travailleuse ultime débarque
Cette fois, le lancement soudain de Sonnet 5 comble aussi la déception de ceux qui n'ont pas accès à Fable 5.
Pour de nombreux développeurs, l'année zéro de l'ère des Agents a commencé avec Sonnet.
Claude Sonnet 3.5, 3.6, 3.7 ont été parmi les premiers modèles à démontrer des capacités étonnantes en écriture de code et en utilisation d'outils.
En d'autres termes, c'est la gamme Sonnet « taille moyenne » qui a été la première à faire fonctionner le concept de « laisser l'IA travailler seule ».
Mais cette dernière année, les bonds de capacités les plus spectaculaires se sont concentrés sur la ligne phare « grande taille » Opus. Sonnet s'est retrouvé directement distancé par le modèle phare.
La mission de Sonnet 5 : combler cet écart !
Anthropic le définit d'une phrase : Claude Sonnet 5 est le Sonnet le plus « productif » de l'histoire.
Les résultats pratiques le démontrent clairement.
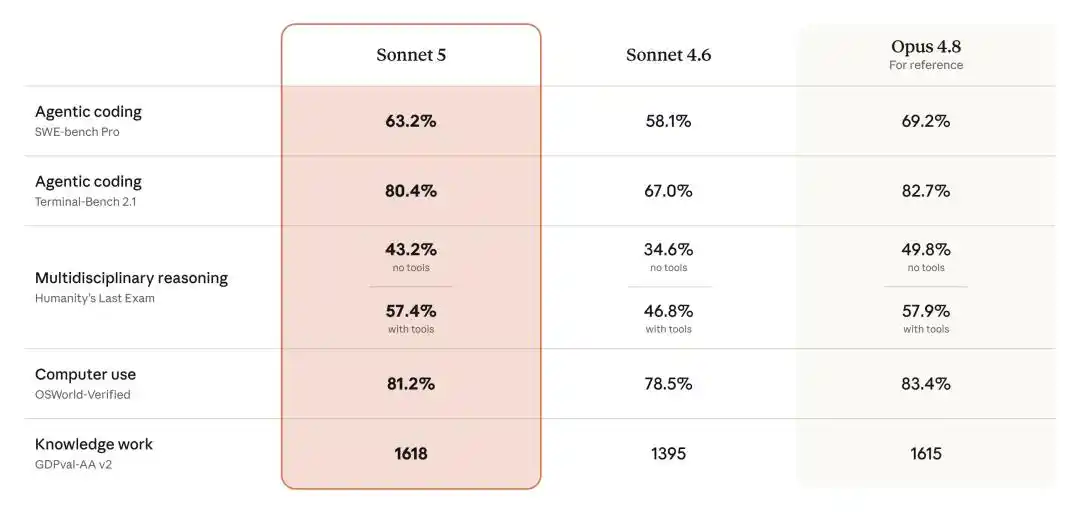
Dans son domaine de prédilection traditionnel, la programmation, Sonnet 5 obtient un impressionnant 63,2 % sur SWE-bench Pro. L'ancienne génération Sonnet 4.6 n'atteignait que 58,1 %, tandis qu'Opus 4.8 garde une avance temporaire avec 69,2 %.
En comparaison, le concurrent historique OpenAI, avec son modèle phare GPT-5.5, n'obtient que 58,6 % sur le même classement, et Gemini 3.5 Flash de Google atteint 55,1 %.
Terminal-Bench 2.1 est encore plus impressionnant : Sonnet 5 bondit à 80,4 %, laissant loin derrière Sonnet 4.6 à 67,0 %, avec une hausse de 13 points de pourcentage. Il n'est plus qu'à moins de 2 points d'Opus 4.8 (82,7 %).
Sur le benchmark de raisonnement interdisciplinaire surnommé « le dernier examen de l'humanité » (Humanity's Last Exam), Sonnet 5 avec outils obtient 57,4 %, contre 57,9 % pour Opus 4.8, soit une différence de seulement 0,5 point. GPT-5.5 sur le même test n'atteint que 52,2 %, et Gemini 3.1 Pro, 51,4 %.
En termes de capacité à contrôler un ordinateur, Sonnet 5 sur OSWorld-Verified obtient 81,2 %, dépassant également les 78,7 % de GPT-5.5 et se rapprochant des 83,4 % d'Opus 4.8.
Plus surprenant encore, dans le travail de connaissances, Sonnet 5 obtient même un score de 1618 sur GDPval-AA v2, dépassant directement les 1615 d'Opus 4.8.
Dans les performances de recherche et d'utilisation d'outils pour agents intelligents, Sonnet 5 offre des capacités de niveau Opus 4.8 au coût le plus bas.
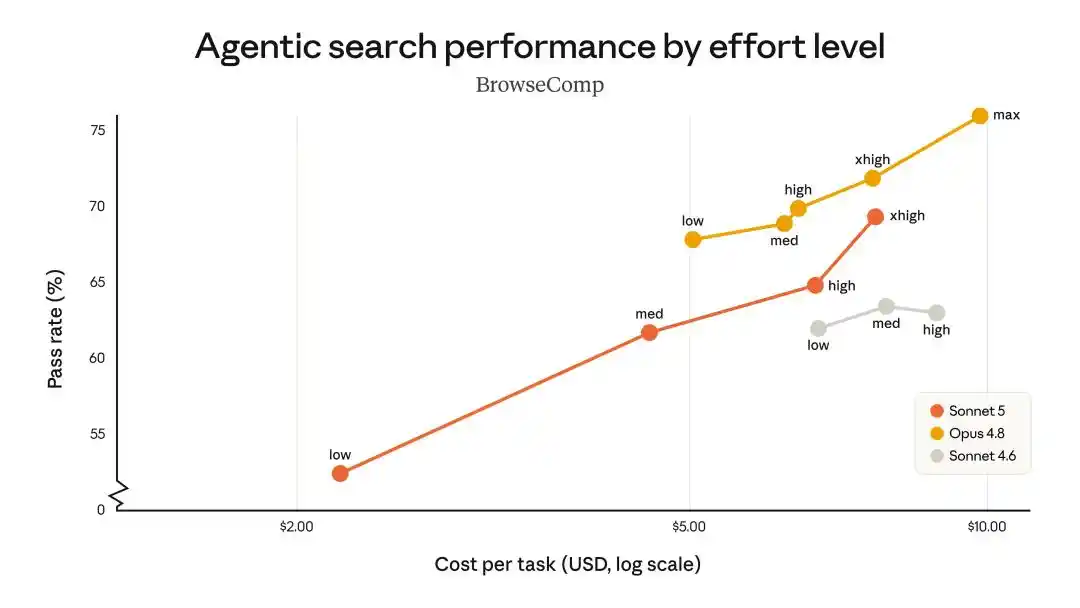
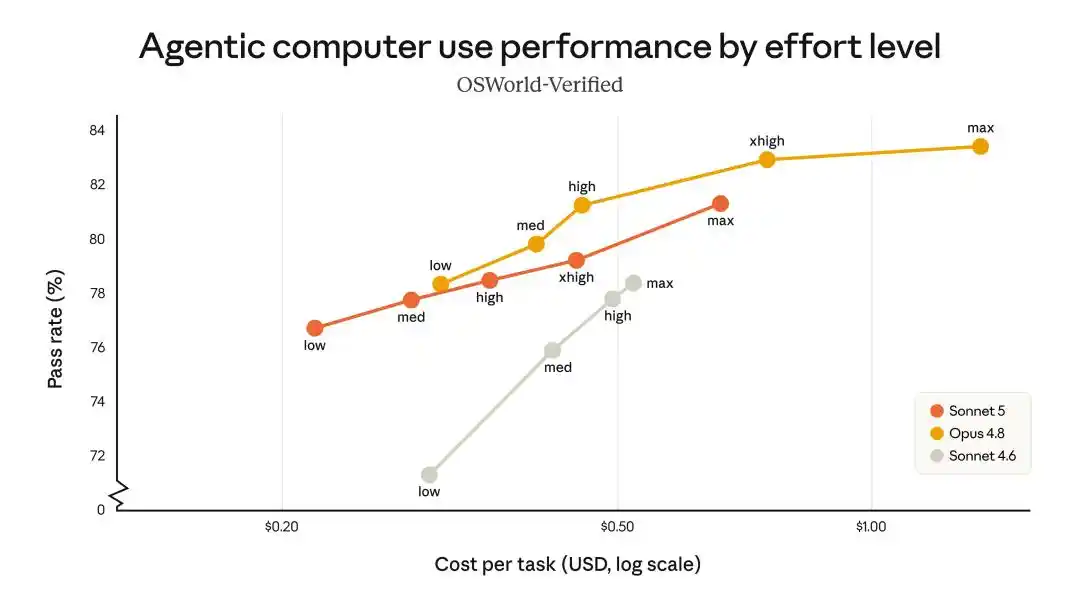
On peut dire que sur presque chaque benchmark, Sonnet 5 se situe dans l'intervalle de 90 % à 100 % des performances d'Opus 4.8.
C'est comme acheter 90 % du cerveau d'Opus pour le prix d'un Sonnet.
Promotion limitée à 2 dollars, mais avec un gros piège
Le prix est l'« arme fatale » cette fois-ci.
Concernant la tarification API, Anthropic propose une super promotion limitée dans le temps : 2 $ par million de tokens en entrée, 10 $ par million en sortie.
Après le 31 août, retour au prix d'origine de 3 $ et 15 $.
En comparaison, Opus 4.8 coûte 5 $ et 25 $, et GPT-5.5 version standard coûte 5 $ et 30 $.
Pendant la période promotionnelle, les prix d'entrée et de sortie ne représentent que 40 % de ceux d'Opus 4.8. Après retour au prix standard, ce sera environ 60 %.

Cependant, malgré une apparente sincérité, Anthropic cache de petits détails dans les spécificités.
La raison est que Sonnet 5 utilise un nouveau tokenizer, ce qui peut faire gonfler le nombre de tokens pour une même entrée d'un facteur de 1,0 à 1,35.
Une fois la période promotionnelle terminée, le prix d'origine de 3 $/15 $ combiné à l'effet de gonflement du tokenizer rendra certainement l'utilisation plus coûteuse, à budget égal, que l'utilisation de Sonnet 4.6.
Mais même ainsi, la différence par rapport à Opus reste écrasante.
Surpasse les modèles phares de toutes les familles
La fiche technique (System Card) révèle l'aspect le plus sous-estimé de Sonnet 5.
Taux de réussite des attaques par injection de prompt de 0,19 %, égal à celui d'Opus 4.8. GPT-5.5 est à 3,08 %, Gemini 3.5 Flash à 6,66 %.

En défense contre l'injection navigateur, le taux de réussite des attaques n'est que de 0,93 %, alors que Mythos 5 est à 29,7 % et Opus 4.8 à 31,5 %.
Un modèle milieu de gamme à 2 $ surclasse tous les modèles phares de la famille ; avec les mesures de protection activées, le taux tombe directement à 0 %.
En injection de code malveillant, le taux de réussite des attaques de Sonnet 4.6 était élevé à 45,26 %, celui de Sonnet 5 est tombé à 0,29 %, une amélioration de 150 fois.
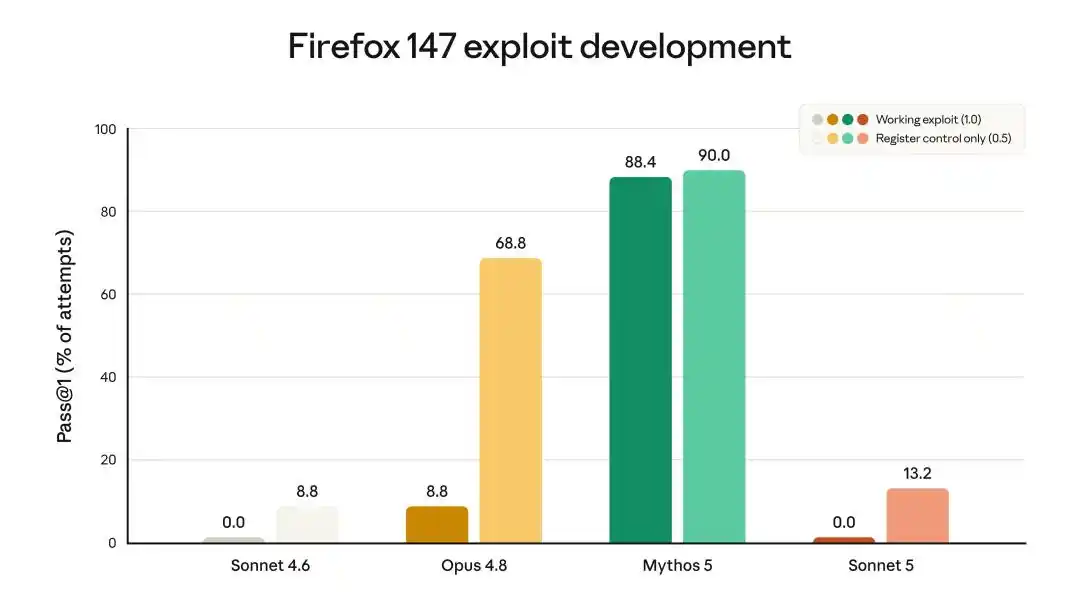
Dans les tests d'exploitation de la vulnérabilité Firefox 147, Mythos 5 peut écrire 88,4 % d'exploits utilisables, Opus 4.8 en écrit 8,8 %, Sonnet 5 en écrit 0,0 %. Capable d'écrire un code métier de haut niveau, mais incapable d'écrire un programme d'exploitation de vulnérabilité utilisable.
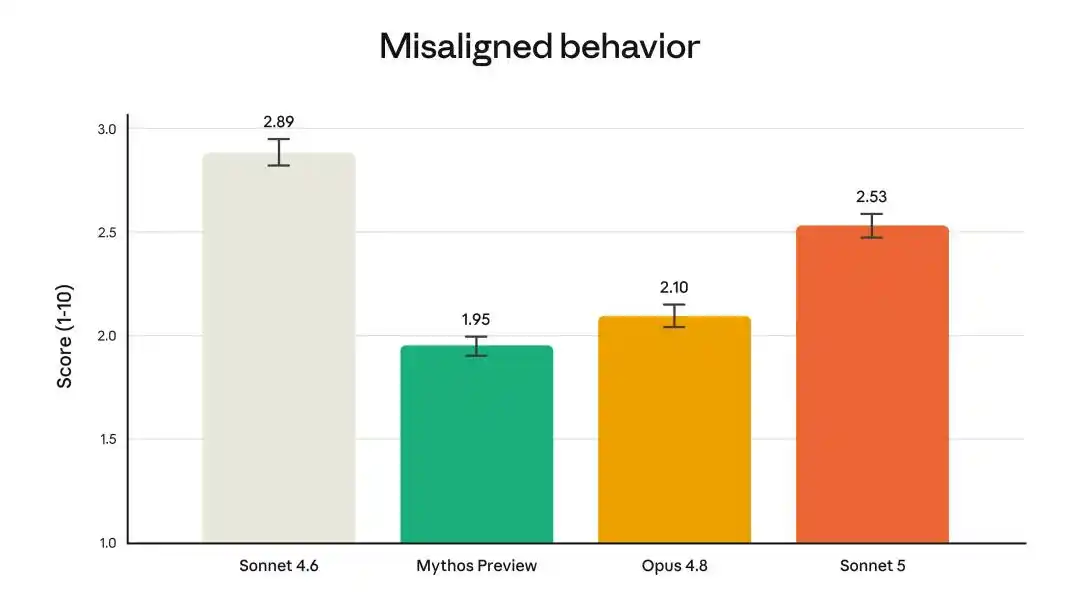
Un effet secondaire est un score de comportement désaligné de 2,53 (sur 10), meilleur que les 2,89 de Sonnet 4.6, mais supérieur aux 2,10 d'Opus 4.8 et aux 1,95 de Mythos Preview.
Plus puissant, et aussi plus caractériel.
Pas pour la couronne, vise la taille moyenne
Sonnet 5 se positionne avec une précision extrême : ses performances vers le haut se rapprochent d'Opus 4.8 et GPT-5.5, et son prix vers le bas est proche de celui de Gemini 3.5 Flash.
OpenAI vient de doubler son prix par rapport à la génération précédente, et Anthropic riposte en abaissant le prix d'entrée de Sonnet 5 à 3 $.
Les développeurs qui hésitaient à payer pour un modèle phare ont maintenant une option alternative redoutable.
Tandis que tout le monde vise le sommet, Anthropic tire dans le ventre mou.
Les portefeuilles des développeurs ont déjà voté ce soir
Aujourd'hui, les performances de Sonnet 5 sont entrées dans l'intervalle des modèles phares, la plupart des tâches de correction de bugs, d'ajout de tests, de refactorisation peuvent être accomplies en une seule fois.
Le dilemme d'hier, trouver Opus trop cher à utiliser et Sonnet pas assez performant, a disparu aujourd'hui.
Le rapport qualité-prix est plus avantageux. Avec le même budget, on pouvait auparavant faire tourner un Agent de niveau Opus, maintenant on peut en faire tourner deux ou trois Sonnet en parallèle.
Le seuil de coût d'une architecture multi-agents a été considérablement abaissé d'un coup par Sonnet 5.
Le retour triomphal de Fable 5 reste une inconnue.
Mais Sonnet 5 est déjà solidement présent, ses performances poussant directement au seuil d'Opus.
Pour la grande majorité des développeurs, c'est le Claude le plus puissant et le plus pratique à portée de main pour les prochains jours, voire pour longtemps.
Références :
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
Cet article provient du compte WeChat public « New Zhiyuan », auteur : ASI Apocalypse





