Auteur : Yanhua
Antonio Gullí est directeur de l'ingénierie chez Google. Il a écrit un livre de 453 pages, dans lequel il décompose le développement d'Agents IA en 21 modèles de conception.
Mais ceci n'est pas une critique de livre. Mon intention en lisant ce livre était très spécifique : j'ai écrit sur le Harness Engineering, sur les leçons tirées des difficultés rencontrées avec Clawdbot, sur cet article "L'Agent IA n'est pas magique" qui décrit sept tournants, du simple brûlage de tokens à une véritable utilité. Après chaque écriture, une question restait en suspens : y avait-il une logique sous-jacente réutilisable derrière tout cela ?
Ce livre m'a donné la réponse, et de manière plus profonde que je ne l'imaginais.
Ce que vous écrivez n'est peut-être pas du tout un Agent
Le jugement le plus sévère du livre se cache dans le prologue.
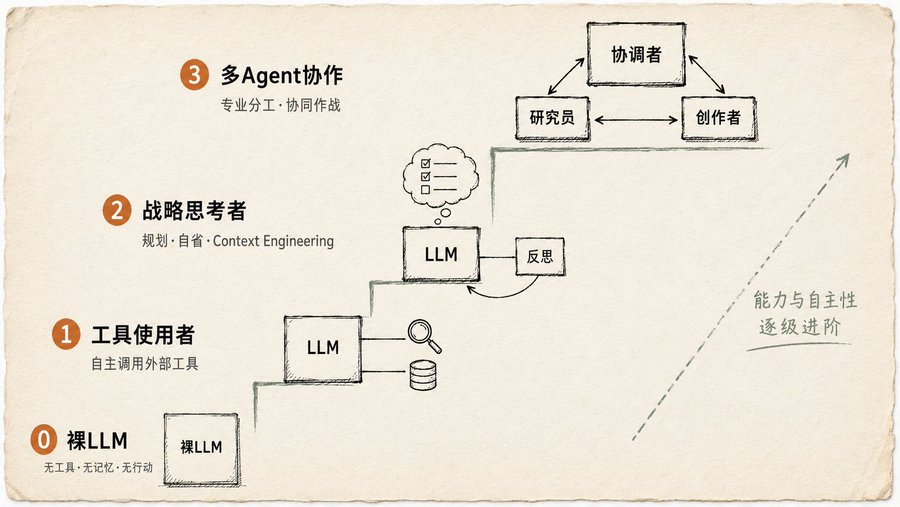
L'"IA" que la plupart des gens utilisent n'est que du Niveau 0 : un LLM nu, sans outils, sans mémoire, incapable d'agir. Vous lui demandez quel est le meilleur film aux Oscars 2025, il devine. Le livre est très clair : Les choses du Niveau 0 ne sont pas des Agents.
C'est en montant que l'on trouve de vrais Agents :
-
Niveau 1 : Utilisateur d'outils
L'Agent commence à utiliser des outils : recherche, API, base de données. Mais il ne s'agit pas seulement de "pouvoir appeler une interface", il doit aussi juger lui-même quand l'appeler, quoi appeler et comment utiliser le résultat. Le livre donne un exemple très concret : l'utilisateur demande "Qu'y a-t-il de nouveau comme séries ?", l'Agent réalise lui-même que cette information n'est pas dans ses données d'entraînement, appelle activement l'outil de recherche pour la trouver, puis synthétise le résultat. L'étape clé est la "prise de conscience par lui-même". Ce n'est pas un humain qui lui dit "Va chercher", c'est lui qui juge avoir besoin de chercher. Cette capacité de jugement est le seuil du Niveau 1.
-
Niveau 2 : Penseur stratégique
Deux choses supplémentaires : la planification et l'Ingénierie de Contexte. Le livre définit l'Ingénierie de Contexte : il ne s'agit pas d'empiler des informations, mais de sélectionner, couper et empaqueter soigneusement le contexte. L'exemple est excellent : l'utilisateur veut trouver un café entre deux lieux. L'Agent appelle d'abord un outil de cartographie pour obtenir un tas de données, puis décide lui-même que "la prochaine étape ne nécessite que les noms de rues", il réduit la sortie de la carte à une courte liste, puis la donne à un outil de recherche local. À chaque étape, il réduit le bruit informationnel.
Il y a une phrase dans le livre que j'ai relue plusieurs fois : "Pour que l'IA atteigne sa précision maximale, il faut lui donner un contexte court, concentré et puissant." L'Ingénierie de Contexte sert précisément à cela.
À ce niveau, l'Agent peut aussi réfléchir sur lui-même. Après avoir terminé son travail, il le revoit, identifie les problèmes et les corrige lui-même. J'en parlerai plus en détail plus tard.
-
Niveau 3 : Collaboration multi-Agents
La position du livre est claire : ne cherchez pas toujours à créer un super agent polyvalent. La vraie approche fiable est de construire une équipe : Agent chef de projet + Agent chercheur + Agent designer + Agent rédacteur. L'exemple donné dans le livre est le lancement d'un nouveau produit : un "Agent chef de projet" coordonne, distribue les tâches à un "Agent recherche marketing", un "Agent conception produit", un "Agent marketing". La clé est la communication : comment les Agents s'échangent les données, synchronisent leur état, gèrent les conflits. Ce chapitre dessine six topologies de communication, de l'Agent simple au plus flexible, avec pour chacune des explications sur les scénarios appropriés.
Après avoir parcouru ces quatre niveaux, j'ai soudain compris pourquoi tant de gens disent "Mon Agent ne fonctionne pas bien". Le modèle n'est pas le problème, le problème est que vous l'utilisez comme un chatbot, il n'a peut-être même pas atteint le Niveau 1.
Ingénierie de Contexte : le concept le plus sous-estimé du livre
J'ai écrit un article sur le Harness Engineering, qui disait que la conception de la piste est plus importante que la puissance du moteur. En lisant ce livre, j'ai réalisé que l'Ingénierie de Contexte est la projection du Harness Engineering au niveau du prompt.
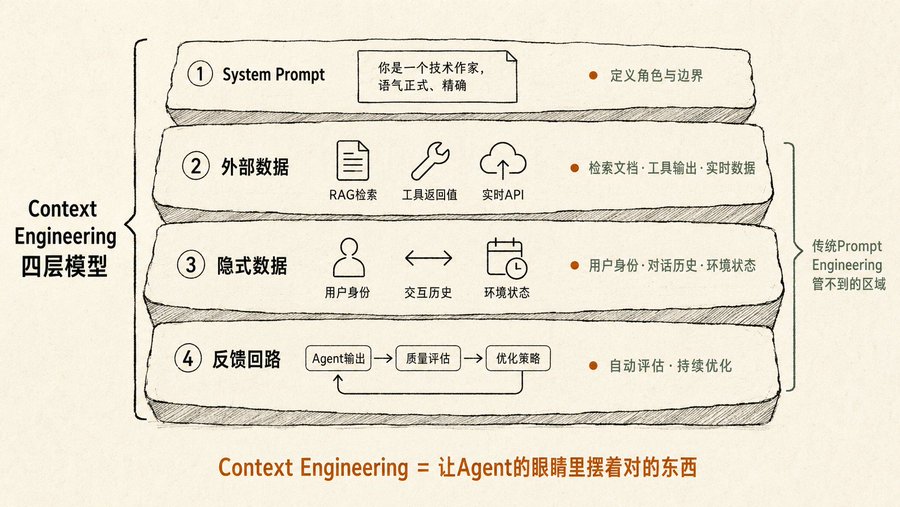
Le Prompt Engineering traditionnel ne se soucie que de "comment vous demandez". L'Ingénierie de Contexte du livre gère "ce que l'Agent a devant les yeux avant de demander". Elle comprend quatre couches d'information :
-
Première couche, le system prompt. Définit qui est l'Agent, son ton, ses limites. La plupart des gens n'écrivent que cela.
-
Deuxième couche, les données externes. Les documents récupérés par RAG, les valeurs de retour des appels d'outils, les données d'API en temps réel. C'est là où la plupart des gens se bloquent : ils savent qu'il faut nourrir avec des données, mais ne savent pas comment le faire sans submerger le modèle.
-
Troisième couche, les données implicites. L'identité de l'utilisateur, l'historique des interactions, l'état de l'environnement. Ce que vous ne dites pas explicitement mais que l'Agent devrait savoir. Par exemple, si vous dites à l'Agent "Aide-moi à envoyer un e-mail à John pour confirmer la réunion de demain", il devrait savoir quelle est la réunion de demain dans votre calendrier, quelle est votre relation avec John.
-
Quatrième couche, la boucle de rétroaction. Après chaque sortie de l'Agent, évaluer automatiquement la qualité, ajuster la stratégie de contexte suivante. Le livre appelle cela "l'optimisation automatisée du contexte", l'outil Vertex AI Prompt Optimizer de Google est une mise en œuvre technique de cette idée.
En lisant cela, je me suis souvenu de mon article "L'Agent IA n'est pas magique", où une expérience disait "votre Agent a besoin de règles, et de beaucoup de règles". En y repensant maintenant, ces règles étaient essentiellement une version manuelle de l'Ingénierie de Contexte, que le livre a systématisée.
Réflexion : deux Agents valent vraiment mieux qu'un
C'est le Pattern qui a le plus de valeur pratique pour moi dans tout le livre.
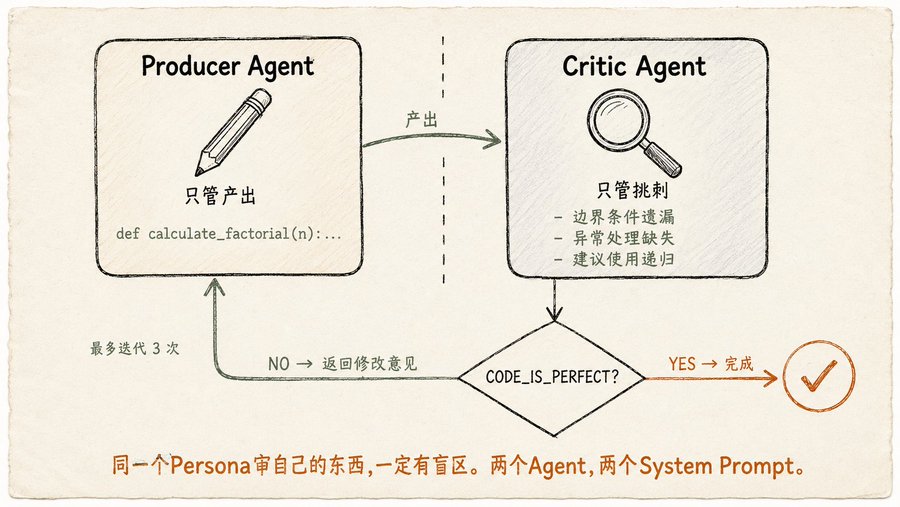
Le cœur de la Réflexion est simple : après avoir fait son travail, l'Agent le revoit lui-même, identifie les problèmes et les corrige. Mais la mise en œuvre doit être réfléchie. Le livre dit clairement : Le Producteur et le Critique doivent être deux Agents différents, avec des system prompts différents. La même persona revoyant son propre travail aura forcément des angles morts. Si vous demandez au même LLM d'écrire du code puis de réviser le code qu'il a écrit, il dira très probablement "c'est bon".
Le livre donne un exemple de code complet.
-
Le prompt du Producteur est "Vous êtes un développeur Python, écrivez une fonction pour calculer la factorielle, gérez les conditions limites et les exceptions".
-
Le prompt du Critique est "Vous êtes un ingénieur senior pointilleux, examinez le code ligne par ligne, vérifiez les bugs, le style, les conditions limites manquantes, les points d'amélioration. Si parfait, sortez
CODE_IS_PERFECT, sinon listez tous les problèmes". -
Puis une boucle for : Producteur écrit le code → Critique le révise → Producteur modifie selon les commentaires → Critique révise à nouveau → jusqu'à ce que le Critique dise
CODE_IS_PERFECTou qu'un nombre maximum d'itérations soit atteint.
C'est aussi simple que cela. Mais le livre rappelle un problème de coût souvent négligé : chaque cycle de réflexion est un nouvel appel LLM, plus d'itérations coûtent plus cher. Et à mesure que l'historique de la conversation gonfle, la fenêtre de contexte est remplie par les versions précédentes et les critiques, réduisant l'espace de raisonnement réellement disponible. La meilleure pratique pour la Réflexion est donc : fixer un nombre maximum d'itérations raisonnable (le livre utilise 3), s'arrêter dès que le Critique est satisfait, ne pas chercher la perfection.
L'utilité va bien au-delà de l'écriture de code. Écrire des articles, faire des plans, résumer des documents, résoudre des problèmes logiques, le modèle Producteur-Critique s'applique à tout. Le livre liste sept scénarios d'application, la logique centrale est la même : produire d'abord, réviser ensuite, corriger.
Multi-Agent : plus complexe n'est pas toujours mieux
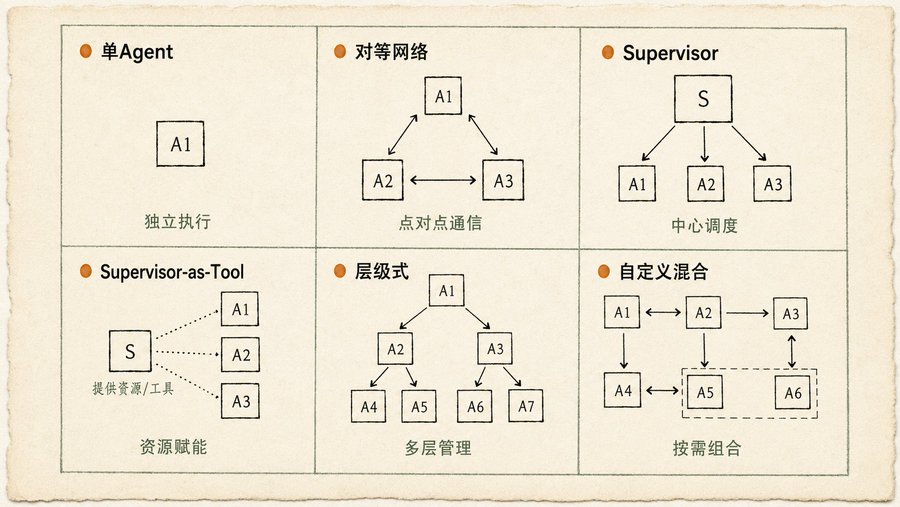
Dans le chapitre sur la Collaboration Multi-Agent, ce que j'ai préféré, ce sont les six diagrammes de topologie de communication. Beaucoup commencent directement par des structures complexes, mais en réalité trois types suffisent pour la plupart des scénarios :
-
Agent unique (exécution indépendante) : La tâche peut être décomposée en sous-problèmes indépendants, chaque Agent s'occupe du sien. Simple, facile à maintenir.
-
Réseau pair-à-pair (Peer-to-Peer) : Les Agents communiquent directement entre eux, sans nœud de contrôle central. Décentralisé, tolérant aux pannes, si un Agent tombe, cela n'affecte pas l'ensemble. Mais le coût de coordination est élevé, risque de désordre.
-
Superviseur (ordonnancement central) : Un Agent Superviseur gère un groupe d'Agents Travailleurs. Il attribue les tâches, collecte les résultats, résout les conflits. Hiérarchie claire, facile à gérer. Mais le Superviseur est un point de défaillance unique et un goulot d'étranglement en termes de performance.
Les trois autres types (Superviseur-comme-Outil, hiérarchique, hybride personnalisé) sont des variantes et combinaisons des trois premiers. Le livre est très pragmatique : La topologie dont vous avez besoin dépend de la complexité de votre tâche. Plus la tâche est fragmentée, plus le coût de communication est élevé, et à un certain point, le mode Superviseur devient plus efficace que le mode hiérarchique.
Ce que je retiens, c'est que beaucoup de gens passent 80% de leur temps sur les protocoles de communication lorsqu'ils construisent un système Multi-Agent, en oubliant de se poser une question plus fondamentale : cette tâche a-t-elle vraiment besoin de plusieurs Agents ? Le livre est clair, un Agent unique de Niveau 2 avec Réflexion est souvent suffisant. Le Niveau 3 est pour les scénarios qu'un Agent unique ne peut vraiment pas gérer.
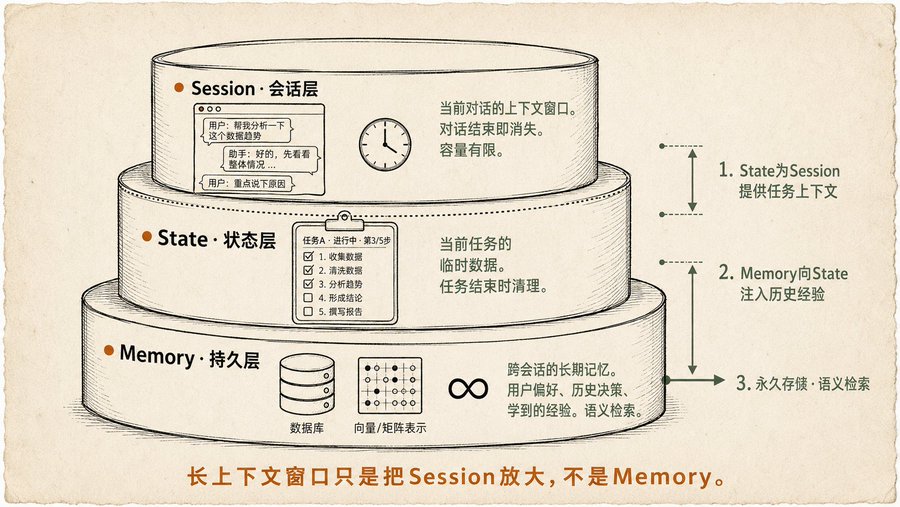
Modèle de Mémoire à trois couches, je l'avais entrevu mais sans le nommer
Le chapitre sur la Mémoire est celui avec lequel je me suis le plus senti en phase, car lorsque j'ai écrit les deux articles sur Obsidian + Claude, je réfléchissais constamment à une question : comment la mémoire d'un Agent devrait-elle être stratifiée ?
Le livre donne la réponse :
-
Session (couche conversation) : La fenêtre de contexte de la conversation en cours, c'est la mémoire la plus courte, elle disparaît à la fin de la conversation. Les modèles à long contexte ne font qu'agrandir cette fenêtre, mais elle reste essentiellement temporaire, et chaque raisonnement doit traiter toute la fenêtre, ce qui est coûteux et lent.
-
État (couche d'état) : Données temporaires pendant l'exécution de la tâche en cours. Par exemple "quelle tâche est en cours", "où en est-elle", "quelles données intermédiaires ont été générées". Plus longue que la Session, mais nettoyée à la fin de la tâche. Le livre donne un exemple complet avec le mécanisme State de Google ADK.
-
Mémoire (couche persistante) : Mémoire à long terme, entre sessions, entre tâches. Préférences de l'utilisateur, expériences acquises, décisions historiques importantes, stockées dans une base de données ou un index vectoriel, avec recherche sémantique. Le livre souligne un point important : la Mémoire ne consiste pas seulement à stocker, il faut aussi concevoir toute une stratégie de "quoi stocker, quand stocker, comment récupérer". Trop de stockage crée du bruit, pas assez n'est pas suffisant.
Dans mon article sur Clawdbot, je mentionnais le "fichier d'état" et les "documents de l'espace de travail", c'était essentiellement une fabrication manuelle des couches État et Mémoire, le livre a cadré cette pratique.
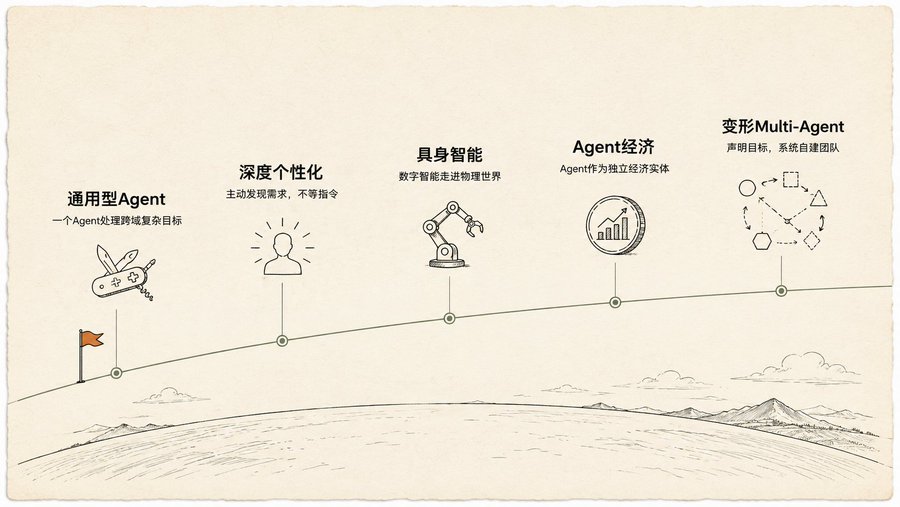
Cinq hypothèses, la cinquième est la plus incroyable
À la fin du livre, cinq hypothèses sur l'avenir des Agents sont mentionnées, les quatre premières sont dans un cadre de projection raisonnable : les Agents généraux passent de l'écriture de code à la gestion de projets, la personnalisation profonde découvre activement vos besoins, l'intelligence incarnée sort des écrans dans le monde physique, les Agents deviennent des entités économiques indépendantes.
La cinquième m'a laissé stupéfait : Multi-Agent transformable.
Vous déclarez uniquement un objectif, par exemple "créer une entreprise de commerce électronique de café de spécialité". Le système décide automatiquement : d'abord créer un "Agent recherche de marché" et un "Agent marque". Après avoir exécuté un tour de données, il juge lui-même que l'Agent marque n'est plus nécessaire, le divise en trois nouveaux : "Agent conception de logo", "Agent création de site", "Agent chaîne d'approvisionnement". Si l'Agent création de site devient un goulot d'étranglement, le système en clone automatiquement trois en parallèle pour travailler simultanément sur différentes pages. Tout au long du processus, le système optimise automatiquement et continuellement le prompt de chaque Agent, réorganisant constamment l'architecture de l'équipe.
Le livre appelle cela un "système multi-Agents auto-transformable et piloté par objectifs". Il n'exécute pas le plan que vous avez écrit, il génère son propre plan, l'ajuste lui-même, réorganise lui-même l'équipe d'exécution.
Cela me rappelle AutoResearch de Karpathy : écrire un program.md, définir les objectifs, les métriques, les limites, appuyer sur "Démarrer". L'humain est en dehors de la boucle. Mais ce livre va encore plus loin : même la façon dont l'équipe d'Agents est formée et réorganisée est laissée au système. L'humain ne fait que déclarer "ce qu'il veut".
Trois actions que vous pouvez mettre en œuvre immédiatement
Après avoir lu ce livre, j'ai trois actions que je peux immédiatement mettre en œuvre :
-
Première, ajoutez un Critique à votre Agent actuel. Que vous utilisiez Claude Code, CrewAI ou votre propre framework, ajoutez une étape à votre workflow existant : faites qu'un autre Agent (avec un system prompt différent) révise la sortie de l'étape précédente. Génération de code + revue de code, rédaction d'article + vérification des faits, élaboration de plan + évaluation de la faisabilité. Un appel LLM de plus, mais souvent un doublement de l'amélioration de la qualité. Le modèle Producteur-Critique du livre est prêt à l'emploi.
-
Deuxième, commencez à faire de l'Ingénierie de Contexte, pas seulement du Prompt Engineering. Revenez aux fichiers d'instructions que vous écrivez pour votre Agent. S'ils ne contiennent que des règles du type "comment faire", sans le contexte du type "quel environnement il affronte", ajoutez-le. Dites à l'Agent dans quel projet il se trouve, quelles décisions il a prises auparavant, quelles sont les préférences de l'utilisateur. Le chapitre sur l'Ingénierie de Contexte et votre
AGENTS.mdsont deux façons de dire la même chose. -
Troisième, ne vous précipitez pas vers le Multi-Agent. Amenez d'abord votre Agent unique au Niveau 2 : avec outils, Réflexion, Mémoire. Le livre insiste : un Agent unique de Niveau 2 avec Producteur-Critique et Ingénierie de Contexte couvre la grande majorité des scénarios réels. Le Niveau 3 est pour les tâches véritablement interdisciplinaires, multi-étapes, nécessitant une division parallèle du travail. Le problème de la plupart des gens n'est pas de ne pas avoir assez d'Agents, c'est de ne pas avoir bien réglé un seul Agent.
Ce livre fait 453 pages, publié par Springer en 2025. Les exemples de code couvrent LangChain/LangGraph, Google ADK, CrewAI, OpenAI API. La préface est écrite par le VP de l'IA chez Google Cloud, et il y a une recommandation du CIO de Goldman Sachs, étonnamment agréable à lire.
Mais la raison pour laquelle je le recommande n'est pas son "exhaustivité". C'est qu'après l'avoir lu, vous réalisez une chose : les problèmes que vous avez rencontrés avec les Agents ces six derniers mois, quelqu'un les a déjà organisés en modèles. Vous n'avez plus besoin de réinventer la Réflexion, de deviner comment stratifier la Mémoire, d'expérimenter quelle topologie de communication utiliser pour le Multi-Agent.
Quelqu'un a dessiné la carte à votre place, il ne reste plus qu'à marcher.
Utilisez-vous un Agent IA pour le développement ? À quel Niveau se trouve votre Agent actuel ?





