Auteur original : Malika Aubakirova, Matt Bornstein, a16z crypto
Compilation originale : Deep潮 TechFlow
Dans « Memento » de Christopher Nolan, le personnage principal Leonard Shelby vit dans un présent fragmenté. Une lésion cérébrale lui a causé une amnésie antérograde, l'empêchant de former de nouveaux souvenirs. Toutes les quelques minutes, son monde se réinitialise, piégé dans un « maintenant » éternel, sans se souvenir de ce qui vient de se passer ni de ce qui va suivre. Pour survivre, il se tatoue, prend des photos Polaroid, et utilise ces accessoires externes pour remplacer la fonction de mémoire que son cerveau ne peut plus accomplir.
Les grands modèles de langage (LLM) vivent dans un présent éternel similaire. Une fois l'entraînement terminé, une immense quantité de connaissances est figée dans leurs paramètres ; le modèle ne peut pas former de nouveaux souvenirs ni mettre à jour ses paramètres en fonction de nouvelles expériences. Pour compenser cette lacune, nous lui avons construit tout un échafaudage : l'historique des conversations sert de pense-bête à court terme, les systèmes de recherche font office de carnets externes, et les instructions système sont comme des tatouages. Mais le modèle lui-même n'a jamais véritablement internalisé ces nouvelles informations.
De plus en plus de chercheurs estiment que cela ne suffit pas. L'apprentissage en contexte (ICL) peut résoudre des problèmes à condition que la réponse (ou des fragments de celle-ci) existe déjà quelque part dans le monde. Mais pour les problèmes qui nécessitent une véritable découverte (comme une nouvelle preuve mathématique), les scénarios adversariaux (comme les attaques et défenses en sécurité), ou les connaissances trop implicites pour être exprimées par des mots, il y a de bonnes raisons de penser que les modèles ont besoin d'un moyen d'écrire directement de nouvelles connaissances et expériences dans leurs paramètres après leur déploiement.
L'apprentissage en contexte est temporaire. Le véritable apprentissage nécessite une compression. Avant de permettre aux modèles de compresser en continu, nous risquons de rester piégés dans le présent éternel de « Memento ». Inversement, si nous pouvons entraîner les modèles à apprendre leur propre architecture de mémoire, au lieu de dépendre d'outils externes sur mesure, nous pourrions débloquer une toute nouvelle dimension de mise à l'échelle (scaling).
Ce domaine de recherche s'appelle l'apprentissage continu (continual learning). Ce concept n'est pas nouveau (voir l'article de McCloskey et Cohen de 1989), mais nous pensons que c'est l'une des directions de recherche les plus importantes dans le domaine de l'IA aujourd'hui. L'explosion des capacités des modèles au cours des deux ou trois dernières années a rendu le fossé entre ce que les modèles « savent » et ce qu'ils « peuvent savoir » de plus en plus évident. Le but de cet article est de partager ce que nous avons appris des meilleurs chercheurs de ce domaine, d'aider à clarifier les différentes voies de l'apprentissage continu et de faire avancer ce sujet dans l'écosystème des startups.
Note : Cet article a pris forme grâce à des échanges approfondis avec un groupe de chercheurs, doctorants et entrepreneurs exceptionnels, qui ont généreusement partagé avec nous leurs travaux et insights dans le domaine de l'apprentissage continu. De la base théorique aux réalités techniques de l'apprentissage après déploiement, leurs perspectives ont rendu cet article bien plus solide que si nous l'avions écrit seuls. Merci pour votre temps et vos idées !
Parlons d'abord de contexte
Avant de défendre l'apprentissage au niveau des paramètres (c'est-à-dire l'apprentissage qui met à jour les poids du modèle), il est nécessaire de reconnaître un fait : l'apprentissage en contexte fonctionne. Et un argument solide suggère qu'il continuera à gagner.
La nature du Transformer est d'être un prédicteur conditionnel du token suivant basé sur des séquences. Donnez-lui la bonne séquence, et vous obtiendrez des comportements étonnamment riches sans jamais avoir à toucher aux poids. C'est pourquoi des méthodes comme la gestion du contexte, l'ingénierie des prompts, le fine-tuning par instruction et les exemples few-shot sont si puissantes. L'intelligence est encapsulée dans des paramètres statiques, mais les capacités manifestées varient considérablement en fonction du contenu que vous insérez dans la fenêtre contextuelle.
L'article récent et approfondi de Cursor sur le scaling des agents de programmation autonomes en est un bon exemple : les poids du modèle sont fixes, ce qui fait vraiment fonctionner le système est l'orchestration minutieuse du contexte – quoi y mettre, quand faire des résumés, comment maintenir un état cohérent sur des heures de fonctionnement autonome.
OpenClaw est un autre bon exemple. Son succès fulgurant n'est pas dû à des privilèges spéciaux sur le modèle (le modèle sous-jacent est accessible à tous), mais à sa capacité à transformer le contexte et les outils en un état de travail extrêmement efficace : suivre ce que vous faites, structurer les produits intermédiaires, décider quand réinjecter des prompts, maintenir une mémoire persistante des travaux précédents. OpenClaw a élevé la « conception de la coquille » de l'agent au rang de discipline à part entière.
Lorsque l'ingénierie des prompts est apparue, de nombreux chercheurs étaient sceptiques quant au fait que « juste des prompts » puisse devenir une interface sérieuse. Cela semblait être un hack. Mais c'est un produit natif de l'architecture Transformer, ne nécessite pas de réentraînement et s'améliore automatiquement avec les progrès des modèles. Les modèles deviennent plus forts, les prompts deviennent plus forts. Les interfaces « simples mais natives » gagnent souvent parce qu'elles sont directement couplées au système sous-jacent, au lieu de lutter contre lui. Jusqu'à présent, la trajectoire de développement des LLM a été exactement celle-ci.
Modèles d'espace d'état : la version stéroïdée du contexte
Alors que les flux de travail principaux passent des appels LLM bruts aux boucles d'agents, les modèles d'apprentissage en contexte sont de plus en plus sollicités. Par le passé, il était relativement rare que la fenêtre contextuelle soit complètement remplie. Cela se produisait généralement lorsque le LLM était chargé d'accomplir une longue liste de tâches discrètes, et la couche applicative pouvait tronquer et compresser l'historique de chat de manière assez directe.
Mais pour un agent, une seule tâche peut consommer une grande partie du contexte total disponible. Chaque étape de la boucle de l'agent dépend du contexte transmis par les itérations précédentes. Et ils échouent souvent après 20 à 100 étapes parce qu'ils « perdent le fil » : le contexte est rempli, la cohérence se dégrade, la convergence devient impossible.
Par conséquent, les principaux laboratoires d'IA investissent maintenant massivement (c'est-à-dire via des entraînements à grande échelle) dans le développement de modèles avec des fenêtres contextuelles ultra-longues. C'est une voie naturelle car elle s'appuie sur ce qui fonctionne déjà (l'apprentissage en contexte) et correspond à la tendance générale du secteur à se déplacer vers le calcul au moment de l'inférence (inference-time compute). L'architecture la plus courante entremêle des couches de mémoire fixes entre les têtes d'attention standard, à savoir les modèles d'espace d'état (SSM) et les variantes d'attention linéaire (ci-après统称为 SSM). Les SSM offrent des courbes de scaling fondamentalement meilleures dans les scénarios à contexte long.
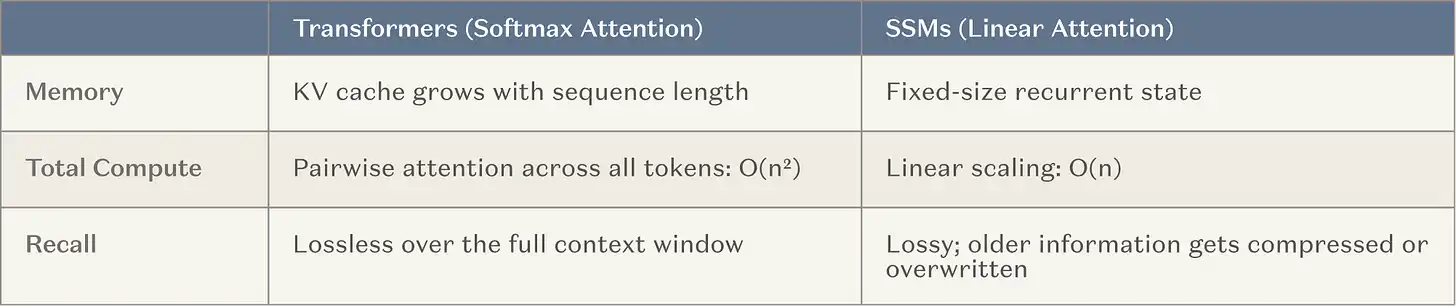
Légende : Comparaison du scaling des SSM avec le mécanisme d'attention traditionnel
L'objectif est d'aider les agents à augmenter le nombre d'étapes de fonctionnement cohérent de plusieurs ordres de grandeur, d'environ 20 étapes à environ 20 000 étapes, sans perdre les compétences et connaissances larges fournies par les Transformers traditionnels. En cas de succès, ce serait une percée majeure pour les agents fonctionnant sur de longues durées.
Vous pouvez même considérer cette approche comme une forme d'apprentissage continu : bien qu'elle ne mette pas à jour les poids du modèle, elle introduit une couche de mémoire externe qui nécessite rarement une réinitialisation.
Donc, ces méthodes non paramétriques sont réelles et puissantes. Toute évaluation de l'apprentissage continu doit partir de là. La question n'est pas de savoir si les systèmes contextuels d'aujourd'hui fonctionnent, ils fonctionnent. La question est : avons-nous déjà atteint un plafond, et de nouvelles méthodes peuvent-elles nous emmener plus loin.
Ce que le contexte omet : « L'erreur de l'armoire à classement »
« Ce qui s'est passé avec l'AGI et le pré-entraînement, c'est qu'en un sens, ils ont overshoot... Les humains ne sont pas des AGI. Oui, les humains ont bien une base de compétences, mais les humains manquent d'une immense quantité de connaissances. Nous dépendons de l'apprentissage continu.
Si je crée un adolescent de 15 ans super intelligent, il ne sait rien. Un bon élève, très désireux d'apprendre. Vous pouvez dire, va devenir programmeur, va devenir médecin. Le déploiement lui-même impliquera une sorte de processus d'apprentissage, d'essais et d'erreurs. C'est un processus, pas le fait de jeter un produit fini. — Ilya Sutskever »
Imaginez un système avec un espace de stockage infini. La plus grande armoire à classement du monde, chaque fait parfaitement indexé, instantanément récupérable. Il peut rechercher n'importe quoi. A-t-il appris ?
Non. Il n'a jamais été forcé de compresser.
C'est le cœur de notre argumentation, qui reprend un point soulevé précédemment par Ilya Sutskever : les LLM sont essentiellement des algorithmes de compression. Pendant l'entraînement, ils compressent Internet en paramètres. La compression est avec pertes, et c'est cette nature avec pertes qui la rend puissante. La compression force le modèle à trouver une structure, à généraliser, à construire des représentations qui peuvent être transférées à travers les contextes. Un modèle qui mémoriserait par cœur tous les échantillons d'entraînement serait inférieur à un modèle qui extrait les règles sous-jacentes. La compression avec pertes est en soi un apprentissage.
Ironiquement, le mécanisme qui rend les LLM si puissants pendant l'entraînement (compresser les données brutes en représentations compactes et transférables) est précisément ce que nous leur refusons de faire après le déploiement. Nous arrêtons la compression au moment de la publication, en la remplaçant par une mémoire externe.
Bien sûr, la plupart des coquilles d'agents compressent le contexte d'une manière personnalisée. Mais la « leçon amère » (bitter lesson) ne nous dit-elle pas que le modèle lui-même devrait apprendre cette compression, directement et à grande échelle ?
Yu Sun partage un exemple pour illustrer ce débat : les mathématiques. Prenez le dernier théorème de Fermat. Pendant plus de 350 ans, aucun mathématicien n'a pu le prouver, non pas parce qu'il manquait la bonne documentation, mais parce que la solution était hautement novatrice. La distance conceptuelle entre les connaissances mathématiques existantes et la réponse finale était trop grande.
Lorsqu'Andrew Wiles l'a finalement résolu dans les années 1990, il a travaillé pendant sept ans dans un isolement presque total, devant inventer de nouvelles techniques pour parvenir à la réponse. Sa preuve reposait sur la réussite à relier deux branches différentes des mathématiques : les courbes elliptiques et les formes modulaires. Bien que Ken Ribet ait précédemment prouvé que si cette connexion pouvait être établie, elle résoudrait automatiquement le dernier théorème de Fermat, avant Wiles, personne ne possédait les outils théoriques pour construire réellement ce pont. Une argumentation similaire peut être faite pour la preuve de Grigori Perelman de la conjecture de Poincaré.
La question centrale est : Ces exemples prouvent-ils que les LLM manquent de quelque chose, d'une certaine capacité à mettre à jour les préalables, à penser de véritablement créatif ? Ou cette histoire prouve-t-elle justement le contraire – que toute connaissance humaine n'est que des données disponibles pour l'entraînement et la重组, et que Wiles et Perelman ont simplement montré ce que les LLM pourraient faire à plus grande échelle ?
Cette question est empirique et la réponse n'est pas certaine. Mais nous savons qu'il existe de nombreuses catégories de problèmes pour lesquelles l'apprentissage en contexte échoue aujourd'hui et où l'apprentissage au niveau des paramètres pourrait être utile. Par exemple :

Légende : Catégories de problèmes où l'apprentissage en contexte échoue et où l'apprentissage paramétrique pourrait l'emporter
Plus important encore, l'apprentissage en contexte ne peut traiter que ce qui peut être exprimé par des mots, tandis que les poids peuvent encoder des concepts que les prompts ne peuvent pas transmettre avec des mots. Certains modèles ont des dimensions trop élevées, sont trop implicites, trop structurellement profonds pour tenir dans un contexte. Par exemple, la texture visuelle qui distingue un artefact bénin d'une tumeur dans une analyse médicale, ou les micro-fluctuations audio qui définissent le rythme unique d'un locuteur, ces modèles ne se décomposent pas facilement en mots précis.
Le langage ne peut que les approximer. Aucun prompt, aussi long soit-il, ne peut transmettre ces choses ; ce type de connaissances ne peut survivre que dans les poids. Elles vivent dans l'espace latent des représentations apprises, pas dans les mots. Quelle que soit la taille de la fenêtre contextuelle, il y aura toujours des connaissances que le texte ne peut pas décrire, qui ne peuvent être portées que par les paramètres.
Cela pourrait expliquer pourquoi les fonctions explicites de « mémoire du robot » (comme la fonction memory de ChatGPT) provoquent souvent chez les utilisateurs un malaise plutôt qu'une surprise. Ce que les utilisateurs veulent vraiment, ce n'est pas du « rappel », mais de la « capacité ». Un modèle qui a internalisé vos schémas comportementaux peut généraliser à de nouveaux scénarios ; un modèle qui se souvient simplement de votre historique ne le peut pas. La différence entre « Voici ce que vous avez écrit la dernière fois que vous avez répondu à cet email » (récitation mot à mot) et « J'ai suffisamment compris votre façon de penser pour anticiper ce dont vous avez besoin » est la différence entre la récupération et l'apprentissage.
Introduction à l'apprentissage continu
L'apprentissage continu emprunte plusieurs voies. La ligne de démarcation n'est pas « avec ou sans fonction de mémoire », mais : Où se produit la compression ? Ces voies se répartissent le long d'un spectre, allant d'aucune compression (récupération pure, poids gelés), à une compression interne complète (apprentissage au niveau des poids, le modèle devient plus intelligent), avec une zone intermédiaire importante (modules).
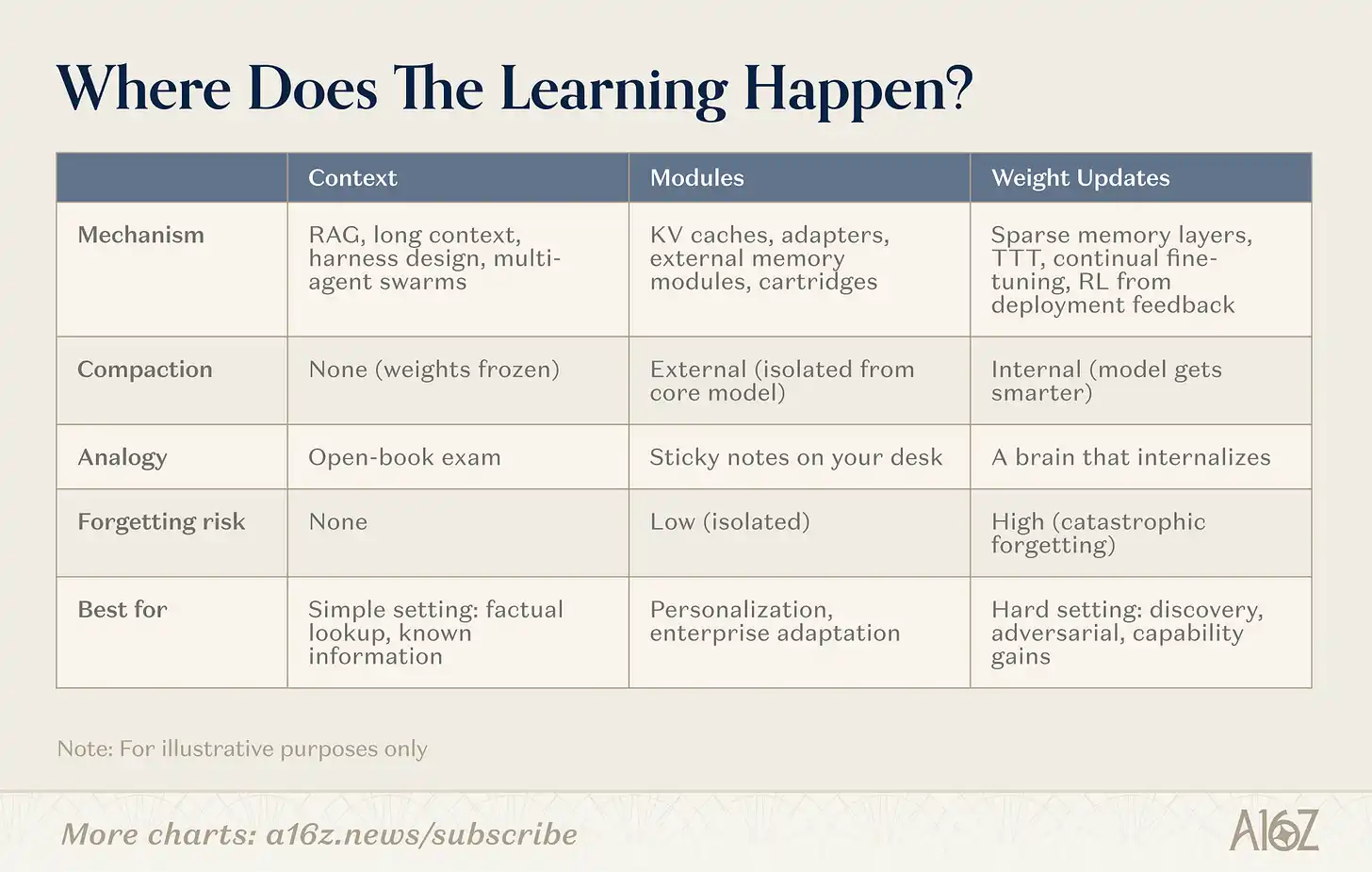
Légende : Les trois voies de l'apprentissage continu – Contexte, Modules, Poids
Contexte
Du côté contexte, les équipes construisent des pipelines de récupération plus intelligents, des coquilles d'agents et une orchestration de prompts. C'est la catégorie la plus mature : l'infrastructure est éprouvée, les chemins de déploiement sont clairs. La limitation est la profondeur : la longueur du contexte.
Une nouvelle direction notable : les architectures multi-agents comme stratégie de scaling du contexte lui-même. Si un modèle unique est limité à une fenêtre de 128K tokens, un groupe coordonné d'agents – chacun détenant son propre contexte, se concentrant sur une tranche du problème, communiquant les résultats entre eux – peut approximer une mémoire de travail globale infinie. Chaque agent fait de l'apprentissage en contexte dans sa propre fenêtre ; le système fait l'agrégation. Le projet récent autoresearch de Karpathy et l'exemple de Cursor construisant un navigateur web sont des cas précoces. C'est une approche purement non paramétrique (pas de modification des poids), mais elle relève considérablement le plafond de ce que les systèmes contextuels peuvent faire.
Modules
Dans l'espace des modules, les équipes construisent des modules de connaissances amovibles (cache KV compressé, couches adaptatrices, stockage de mémoire externe) qui permettent à un modèle généraliste de se spécialiser sans réentraînement. Un modèle de 8B avec le module approprié peut égaler les performances d'un modèle de 109B sur une tâche cible, avec une empreinte mémoire bien moindre. L'attrait réside dans sa compatibilité avec l'infrastructure Transformer existante.
Poids
Du côté de la mise à jour des poids, les chercheurs poursuivent un véritable apprentissage au niveau des paramètres : des couches de mémoire clairsemées qui ne mettent à jour que des segments de paramètres pertinents, des boucles d'apprentissage par renforcement qui optimisent le modèle à partir des retours, un entraînement au moment du test (test-time training) qui compresse le contexte dans les poids pendant l'inférence. Ce sont les méthodes les plus profondes, les plus difficiles à déployer, mais elles permettent véritablement au modèle d'internaliser complètement de nouvelles informations ou compétences.
Les mécanismes spécifiques de mise à jour des paramètres sont variés. Enumérons quelques directions de recherche :
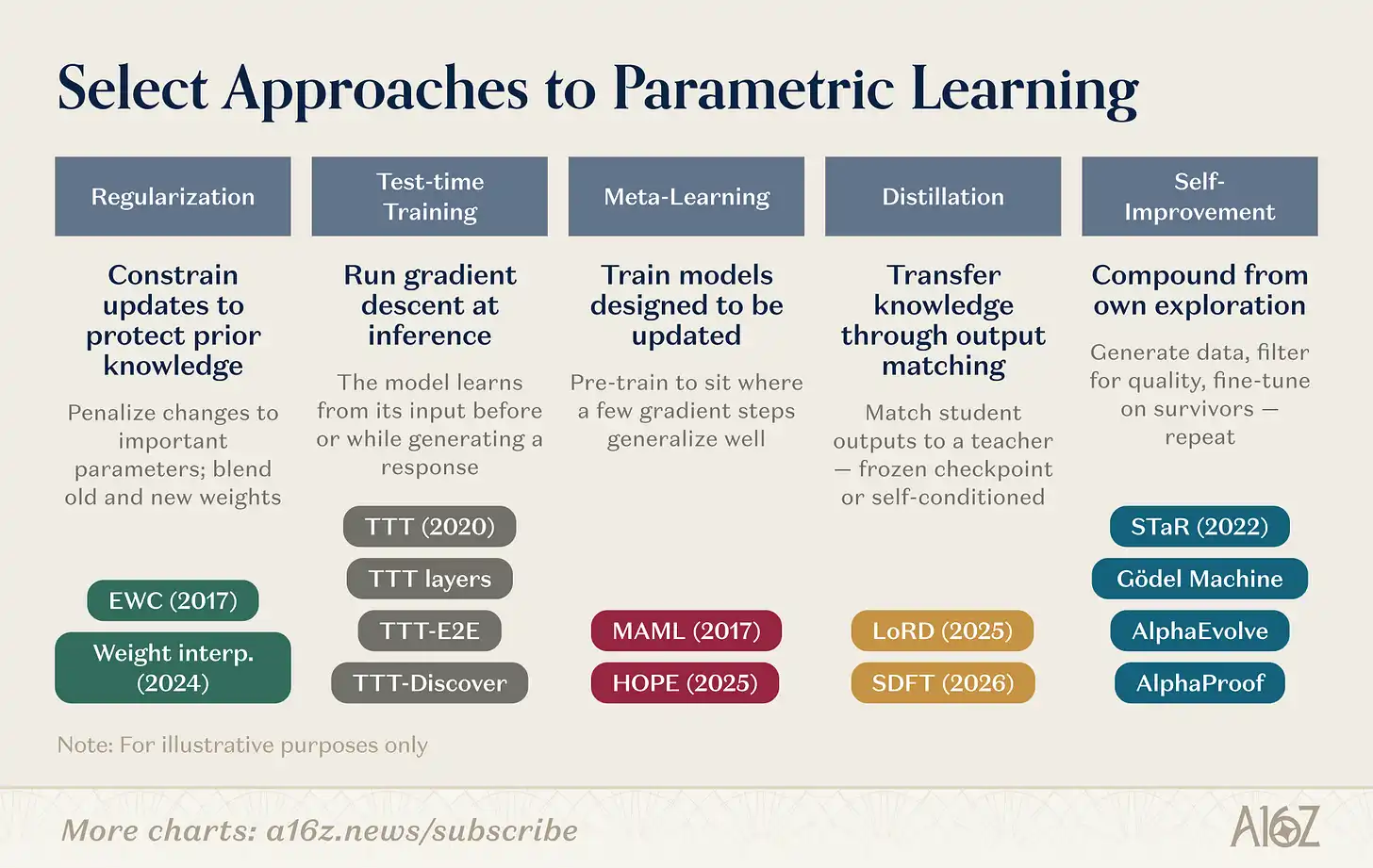
Aperçu des directions de recherche sur l'apprentissage au niveau des poids
La recherche au niveau des poids couvre plusieurs voies parallèles. Les méthodes de régularisation et d'espace de poids sont les plus anciennes : EWC (Kirkpatrick et al., 2017) pénalise les changements de paramètres en fonction de leur importance pour les tâches précédentes ; l'interpolation de poids (Kozal et al., 2024) mélange les configurations de poids anciennes et nouvelles dans l'espace des paramètres, mais les deux sont relativement fragiles à grande échelle.
L'entraînement au moment du test (Test-Time Training), initié par Sun et al. (2020), a évolué vers des primitives architecturales (couches TTT, TTT-E2E, TTT-Discover), avec une approche radicalement différente : effectuer une descente de gradient sur les données de test, compressant les nouvelles informations dans les paramètres au moment même où elles sont nécessaires.
La méta-apprentissage pose la question : Pouvons-nous entraîner des modèles qui savent « comment apprendre » ? De l'initialisation de paramètres adaptée au few-shot de MAML (Finn et al., 2017) à l'apprentissage imbriqué (Nested Learning, 2025) de Behrouz et al., qui structure le modèle comme un problème d'optimisation hiérarchique avec des modules fonctionnant à différentes échelles de temps pour une adaptation rapide et des mises à jour lentes, s'inspirant de la consolidation de la mémoire biologique.
La distillation conserve les connaissances des tâches précédentes en faisant correspondre le modèle étudiant à des points de contrôle (checkpoints) gelés du modèle enseignant. LoRD (Liu et al., 2025) rend la distillation suffisamment efficace pour fonctionner en continu en réduisant simultanément le modèle et le tampon de rejeu (replay buffer). L'auto-distillation (SDFT, Shenfeld et al., 2026) inverse la source, utilisant les sorties du modèle lui-même dans des conditions d'expert comme signal d'entraînement, contournant l'oubli catastrophique du fine-tuning séquentiel.
L'auto-amélioration récursive fonctionne sur des idées similaires : STaR (Zelikman et al., 2022) bootstrap les capacités de raisonnement à partir de chaînes de raisonnement auto-générées ; AlphaEvolve (DeepMind, 2025) a découvert des optimisations algorithmiques non améliorées depuis des décennies ; « L'ère de l'expérience » de Silver et Sutton (2025) définit l'apprentissage de l'agent comme un flux continu et永不停止 d'expérience.
Ces directions de recherche convergent. TTT-Discover a déjà fusionné l'entraînement au moment du test et l'exploration pilotée par RL. HOPE imbrique des boucles d'apprentissage rapides et lentes dans une architecture unique. SDFT transforme la distillation en opération fondamentale d'auto-amélioration. Les frontières entre les colonnes deviennent floues. La prochaine génération de systèmes d'apprentissage continu combinera vraisemblablement plusieurs stratégies : utiliser la régularisation pour stabiliser, le méta-apprentissage pour accélérer, l'auto-amélioration pour les intérêts composés. Un nombre croissant de startups parient sur différentes couches de cette pile technologique.
Paysage des startups en apprentissage continu
L'extrémité non paramétrique du spectre est la plus connue. Les entreprises de coquilles (Letta, mem0, Subconscious) construisent des couches d'orchestration et d'échafaudage, gérant ce qui entre dans la fenêtre contextuelle. Le stockage externe et l'infrastructure RAG (comme Pinecone, xmemory) fournissent l'épine dorsale de la récupération. Les données existent, le défi est de mettre la bonne tranche devant le modèle au bon moment. À mesure que les fenêtres contextuelles s'étendent, l'espace de conception de ces entreprises s'agrandit également, en particulier côté coquille, où une nouvelle vague de startups émerge pour gérer des stratégies contextuelles de plus en plus complexes.
L'extrémité paramétrique est plus précoce et plus diversifiée. Ici, les entreprises expérimentent une certaine version de la « compression post-déploiement », permettant au modèle d'internaliser de nouvelles informations dans ses poids. Les chemins se divisent grossièrement en plusieurs paris sur la façon dont le modèle devrait apprendre après sa publication.
Compression partielle : Apprendre sans réentraînement. Certaines équipes construisent des modules de connaissances amovibles (cache KV compressé, couches adaptatrices, stockage de mémoire externe) permettant à un modèle généraliste de se spécialiser sans toucher aux poids principaux. L'argument commun est : vous obtenez une compression significative (pas seulement de la récupération), tout en gardant le compromis stabilité-plasticité gérable, car l'apprentissage est isolé et non dispersé dans tout l'espace des paramètres. Un modèle de 8B avec le bon module peut égaler les performances d'un modèle beaucoup plus grand sur une tâche cible. L'avantage est la composabilité : les modules peuvent être branchés et utilisés avec les architectures Transformer existantes, peuvent être échangés ou mis à jour indépendamment, à un coût expérimental bien inférieur à celui d'un réentraînement.
RL et boucles de feedback : Apprendre des signaux. D'autres équipes parient que le signal d'apprentissage le plus riche après le déploiement existe déjà dans la boucle de déploiement elle-même – les corrections des utilisateurs, la réussite ou l'échec des tâches, les signaux de récompense provenant des résultats du monde réel. L'idée centrale est que le modèle devrait considérer chaque interaction comme un signal d'entraînement potentiel, et pas seulement comme une requête d'inférence. C'est très similaire à la façon dont les humains progressent dans leur travail : travailler, obtenir des retours, internaliser ce qui fonctionne. Le défi technique est de transformer des retours épars, bruyants, parfois adversariaux, en mises à jour de poids stables, sans oubli catastrophique. Mais un modèle qui peut véritablement apprendre de son déploiement générera de la valeur à intérêts composés d'une manière impossible pour les systèmes contextuels.
Centré sur les données : Apprendre des bons signaux. Un pari connexe mais distinct est que le goulot d'étranglement n'est pas l'algorithme d'apprentissage, mais les données d'entraînement et les systèmes environnants. Ces équipes se concentrent sur le filtrage, la génération ou la synthèse des bonnes données pour piloter les mises à jour continues : l'hypothèse est qu'un modèle avec des signaux d'apprentissage de haute qualité et bien structurés n'a besoin que de beaucoup moins d'étapes de gradient pour s'améliorer significativement. Cela rejoint naturellement les entreprises axées sur les boucles de feedback, mais l'accent est mis sur le problème en amont : ce n'est pas la même chose de savoir si le modèle peut apprendre et de savoir de quoi il devrait apprendre et dans quelle mesure.
Nouvelles architectures : Concevoir la capacité d'apprentissage dès la base. Le pari le plus radical est que l'architecture Transformer elle-même est le goulot d'étranglement, et que l'apprentissage continu nécessite des primitives de calcul fondamentalement différentes : des architectures avec une dynamique en temps continu et des mécanismes de mémoire intégrés. L'argument ici est structurel : si vous voulez un système d'apprentissage continu, vous devez intégrer le mécanisme d'apprentissage dans l'infrastructure sous-jacente.

Légende : Paysage des startups en apprentissage continu
Tous les grands laboratoires principaux sont également actifs dans ces catégories. Certains explorent une meilleure gestion du contexte et le raisonnement par chaîne de pensées, d'autres expérimentent des modules de mémoire externes ou des pipelines de calcul pendant le « sommeil », et plusieurs entreprises furtives (stealth) poursuivent de nouvelles architectures. Ce domaine est suffisamment précoce pour qu'aucune méthode n'ait encore gagné, et étant donné la largeur des cas d'utilisation, il ne devrait pas y avoir qu'un seul gagnant.
Pourquoi les mises à jour de poids naïves échouent
La mise à jour des paramètres du modèle en environnement de production déclenche une cascade de modes d'échec qui ne sont actuellement pas résolus à grande échelle.

Légende : Modes d'échec des mises à jour de poids naïves
Les problèmes techniques sont bien documentés. L'oubli catastrophique signifie qu'un modèle suffisamment sensible aux nouvelles données pour apprendre détruira les représentations existantes – le dilemme stabilité-plasticité. La dissociation temporelle se produit lorsque des règles immuables et des états variables sont compressés dans le même ensemble de poids ; mettre à jour l'un endommage l'autre. L'intégration logique échoue car les mises à jour de faits ne se propagent pas à leurs推论 : les changements sont confinés au niveau de la séquence de tokens, pas au niveau du concept sémantique. Le désapprentissage (unlearning) reste impossible : il n'existe pas d'opération de souraction différentiable, donc il n'y a pas de moyen de procéder à une excision chirurgicale précise des connaissances fausses ou toxiques.
Il existe une deuxième catégorie de problèmes moins souvent évoquée. La séparation actuelle entre l'entraînement et le déploiement n'est pas seulement une commodité technique, c'est une frontière de sécurité, d'auditabilité et de gouvernance. Ouvrir cette frontière, et plusieurs choses tournent mal simultanément. L'alignement de sécurité (safety alignment) peut se dégrader de manière imprévisible : même un fine-tuning étroit sur des données bénignes peut produire des comportements de désalignement étendus.
Les mises à jour continues créent une surface d'attaque pour l'empoisonnement des données – une version lente et persistante de l'injection de prompt, mais qui vit dans les poids. L'auditabilité s'effondre, car un modèle mis à jour en continu est une cible mouvante, impossible à versionner, à tester de régression ou à certifier une fois pour toutes. Les risques pour la vie privée s'intensifient lorsque les interactions utilisateur sont compressées dans les paramètres, les informations sensibles étant cuites dans les représentations, plus difficiles à filtrer que les informations dans un contexte de récupération.
Ce sont des questions ouvertes, pas des impossibilités fondamentales. Les résoudre fait autant partie du programme de recherche sur l'apprentissage continu que de résoudre les défis architecturaux de base.
Des « fragments de mémoire » à la véritable mémoire
La tragédie de Leonard dans « Memento » n'est pas qu'il ne puisse pas fonctionner – dans n'importe quelle scène, il est plein de ressources, voire brillant. Sa tragédie est qu'il ne peut jamais capitaliser (faire des intérêts composés). Chaque expérience reste externe – une photo Polaroid, un tatouage, une note écrite de la main d'un autre. Il peut récupérer, mais il ne peut pas compresser de nouvelles connaissances.
Alors que Leonard navigue dans ce labyrinthe auto-construit, la frontière entre la réalité et la croyance commence à s'estomper. Sa condition ne le prive pas seulement de sa mémoire ; elle l'oblige à reconstruire constamment le sens, le rendant à la fois le détective et le narrateur peu fiable de sa propre histoire.
L'IA d'aujourd'hui fonctionne sous les mêmes contraintes. Nous avons construit des systèmes de récupération très puissants : des fenêtres contextuelles plus longues, des coquilles plus intelligentes, des essaims d'agents coordonnés, et ils fonctionnent. Mais la récupération n'est pas égale à l'apprentissage. Un système qui peut rechercher n'importe quel fait n'est pas forcé de trouver une structure. Il n'est pas forcé de généraliser. La compression avec pertes qui a rendu l'entraînement si puissant – le mécanisme qui transforme les données brutes en représentations transférables – est précisément ce que nous éteignons au moment du déploiement.
La voie à suivre n'est probablement pas une percée unique, mais un système stratifié. L'apprentissage en contexte restera la première ligne de défense de l'adaptation : il est natif, éprouvé et s'améliore constamment. Les mécanismes modulaires peuvent gérer le terrain intermédiaire de la personnalisation et de la spécialisation du domaine.
Mais pour ces problèmes vraiment difficiles – la découverte, l'adaptation adversarial, les connaissances implicites inexprimables par des mots – nous devrons peut-être permettre aux modèles de continuer à compresser l'expérience dans leurs paramètres après l'entraînement. Cela signifiera des progrès dans les architectures clairsemées, les objectifs de méta-apprentissage et les boucles d'auto-amélioration. Cela pourrait également nous obliger à redéfinir ce que signifie un « modèle » : non pas un ensemble fixe de poids, mais un système en évolution contenant sa mémoire, son algorithme de mise à jour et sa capacité à abstraire à partir de sa propre expérience.
L'armoire à classement devient de plus en plus grande. Mais une armoire à classement, aussi grande soit-elle, reste une armoire à classement. La percée consiste à permettre au modèle de faire après le déploiement ce qui l'a rendu puissant pendant l'entraînement : compresser, abstraire, apprendre. Nous sommes à un point d'inflexion, passant de modèles amnésiques à des modèles possédant une lueur d'expérience. Sinon, nous resterons piégés dans notre propre « Memento ».







