Par | Silicon Base Star
Le célèbre running gag de Sam Altman s'est cette fois réalisé pour tout le monde.
L'année dernière, en faisant la promotion du GPT-5, le PDG d'OpenAI a prononcé une phrase qui a ensuite été détournée sur tout Internet : "Cette sensation, c'est comme voir une explosion atomique, des vertiges et s'effondrer." Depuis, à chaque fois que le milieu de l'IA sort un nouveau produit accompagné de textes exagérés, ce gag est ressorti et moqué sans cesse.

Mais avant-hier tard dans la nuit, ce n'était pas Altman qui était étourdi et effondré. Cette fois, c'était tous les utilisateurs qui regardaient leur écran en attendant qu'OpenAI joue sa carte.
Altman, comme à son habitude, a fait mystérieux et a posté un tweet : "Nous avons préparé quelque chose d'amusant."
À trois heures du matin, GPT-Image 2 est arrivé. Le monde mondial de l'IA a directement explosé.
"Images are a language, not decoration."
C'est la première phrase qu'OpenAI a écrite sur la page de publication. Traduite, cela signifie une seule chose : à partir d'aujourd'hui, l'image n'est plus une décoration, elle est elle-même un langage. C'est une déclaration de saut générationnel lancée à toute l'industrie de la vision par ordinateur.
Pendant toute l'année dernière, le dessin par IA était encore coincé dans le bourbier esthétique du "est-ce que ça ressemble". Dès l'apparition de GPT-Image 2, le bouton de basculement a été actionné — la génération d'images par IA entre officiellement dans l'examen intellectuel du "est-ce que la logique est correcte".
La précision de ce modèle n'est pas exagérée de la qualifier de "terrifiante".
Il a atteint la première place du classement de génération d'images à partir de texte et d'édition d'images d'Artificial Analysis, et ses performances en situation réelle sont écrasantes.
La sensation est la même que lorsque Seedance 2.0 est arrivé dans le domaine de la génération vidéo, il n'est plus depuis longtemps un outil d'assistance pour les humains, il définit de nouvelles normes industrielles.
Note : Les images de cet article sont toutes générées par GPT-Image 2, le contenu des images est purement fictif.
01 L'éveil du moteur de pensée
Autrefois, la première norme pour juger si un modèle d'image était bon était de savoir s'il ressemblait à une vraie personne, s'il ressemblait à un objet de référence.
Devant ce monstre qu'est GPT-Image 2, ce standard est dépassé. Totalement dépassé.
Le point de percée le plus central du nouveau modèle est ici : c'est un modèle d'image qui prend en charge un mode de pensée.
Qu'est-ce que cela signifie ? Après que l'utilisateur ait saisi l'invite, le modèle ne se contente plus de supprimer le bruit, de concaténer des pixels. Il effectue d'abord une modélisation de la pensée en arrière-plan, puis se met à dessiner.
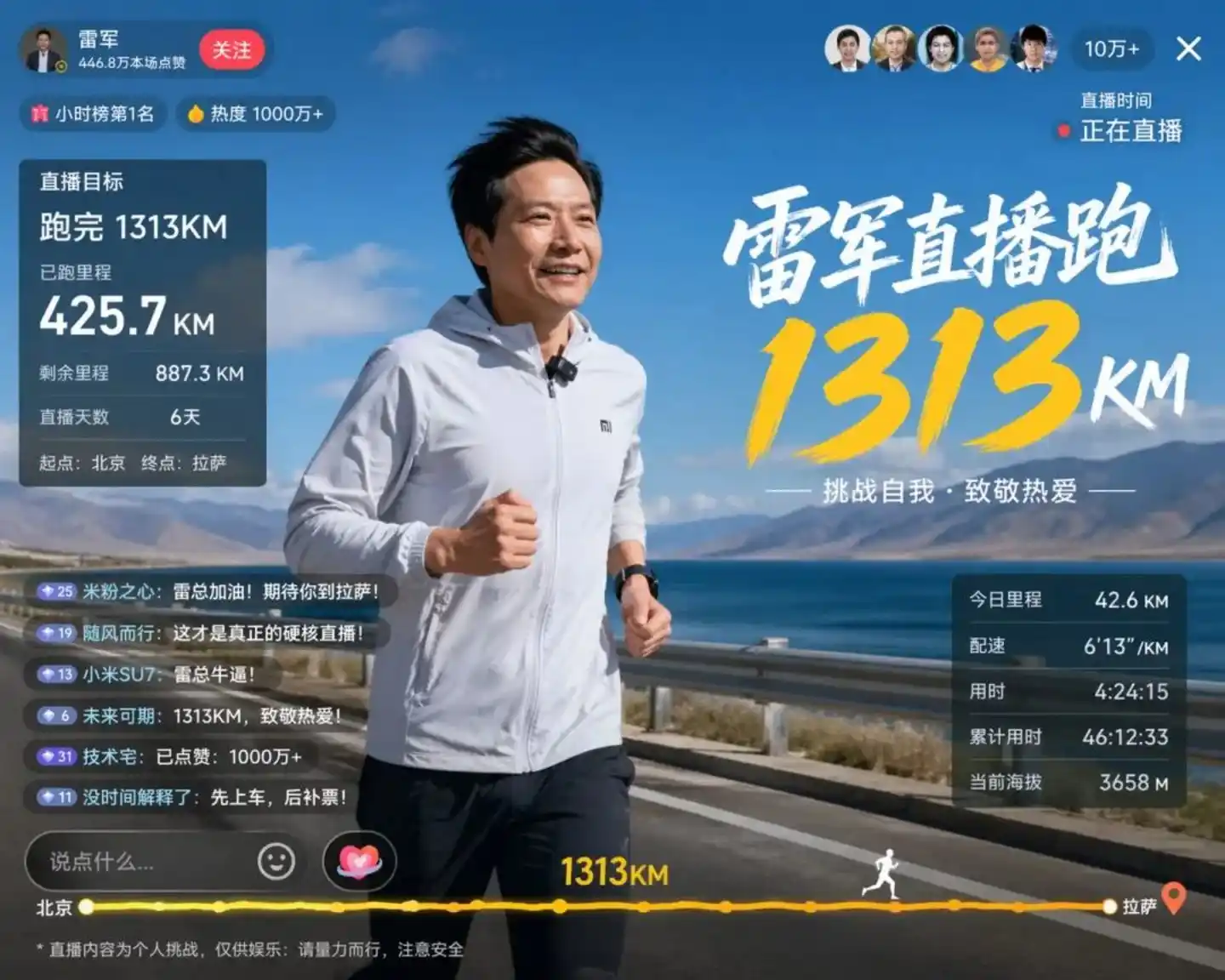
Une image de test divulguée par la communauté Linux.do illustre le mieux le problème. Le modèle a simulé une scène de Lei Jun courant en direct :
Source de l'image : https://cdn3.linux.do/original/4X/0/f/3/0f37c8bc968e3d563cc6100d8e7f80ee305661ff.jpeg
Cette image a fait frémir de nombreux développeurs. Les traits du visage de M. Lei sont restitués avec une précision — comme sur une photo — l'image affiche clairement : objectif du direct 1313 km, distance déjà parcourue 425,7 km, distance restante 887,3 km. Plus fort encore, l'altitude actuelle indique 3658 m.
Que représente 3658 m ? De Pékin à Lhassa, l'altitude typique lorsqu'on entre dans la région tibétaine est précisément ce chiffre.
Aux yeux des humains, ce n'est qu'une simple addition et soustraction et du bon sens géographique. Mais réfléchissez : pour un modèle d'image, qu'est-ce que signifie l'unification triple de la logique mathématique + du bon sens géographique + des normes UI ?
La conclusion est directe : avant de générer le premier pixel, GPT-Image 2 a déjà effectué un cycle de raisonnement. Il a compris la signification de "distance", compris la relation logique des additions et soustractions, et aussi compris les caractéristiques visuelles des régions de haute altitude.
Ce n'est pas du dessin. C'est de la pensée.
02 Du jouet à l'outil de production
Face à cette capacité, l'attitude de tout le monde envers les modèles d'image doit changer.
Ce n'est depuis longtemps plus un jouet avec lequel vous dessinez des avatars ou faites des fonds d'écran. Il a franchi d'un coup le seuil de "utilisable" pour foncer directement dans l'intervalle de "pratique" — un outil qui peut être jeté directement dans un scénario commercial pour travailler.
Prenons la conception d'affiches. L'esthétique de composition de GPT-Image 2, le traitement de la lumière et de l'ombre, la maîtrise de l'identité de marque, ont sans aucun doute atteint un niveau que la grande majorité des designers humains ordinaires ont du mal à égaler.

Source de l'image : https://cdn3.linux.do/original/4X/7/a/1/7a12ccd6b745be5ad8828eb0ac225d218fb43cbc.jpeg
Dans la société humaine, engager un graphiste senior pour concevoir une affiche de niveau commercial, les coûts de communication, les coûts de temps et la rémunération de conception de plus de mille yuans sont souvent un fardeau lourd pour les petites et moyennes entreprises.
Cependant, avec GPT-Image 2, même si le résultat n'est pas satisfaisant et nécessite des dizaines d'ajustements, le coût ne sera que de quelques dollars.
Dans des domaines comme la conception d'affiches, le matériel marketing, les illustrations, ce dont les utilisateurs se soucient n'est fondamentalement pas du "réalisme", mais du "est-ce que c'est beau, est-ce que c'est précis". Précisément pour cette raison, l'efficacité de remplacement de l'IA est dévastatrice.
Dans la documentation développeur mise à jour simultanément, un détail excitant est caché : dans les exemples de code, model: "gpt-5.4" apparaît fréquemment.
Le mode de pensée combiné au modèle phare, cette combinaison suggère une chose : GPT-Image 2 n'est en aucun cas un produit isolé. Il est le terminal visuel conçu pour la prochaine génération de grands modèles de langage.
Grâce au nouveau Responses API, le processus de génération d'images interagira aussi naturellement qu'une discussion avec un grand modèle de langage. Le modèle a ajouté une fonction permettant des modifications en dialogue tour par tour, après la fin de la première génération, l'utilisateur peut proposer diverses instructions qui feraient monter la tension artérielle du designer de la partie B : "Assombrissez un peu plus le fond." "Déplacez le logo de quelques pixels sur le côté."
Ces demandes de modification interactive en temps réel sont précisément la partie la plus fastidieuse et la plus éprouvante pour la patience du travail quotidien des designers. Maintenant, résolu.
03 L'apogée du rendu du chinois
Bien que GPT-Image 2 soit un modèle étranger, les utilisateurs chinois l'ont acclamé à l'unisson.
La raison est unique : son support des caractères chinois est pratiquement parfait.
Dans les images de test retournées par la communauté, vous pouvez voir la scène célèbre du débat entre Luo Yonghao et Wang Ziru :
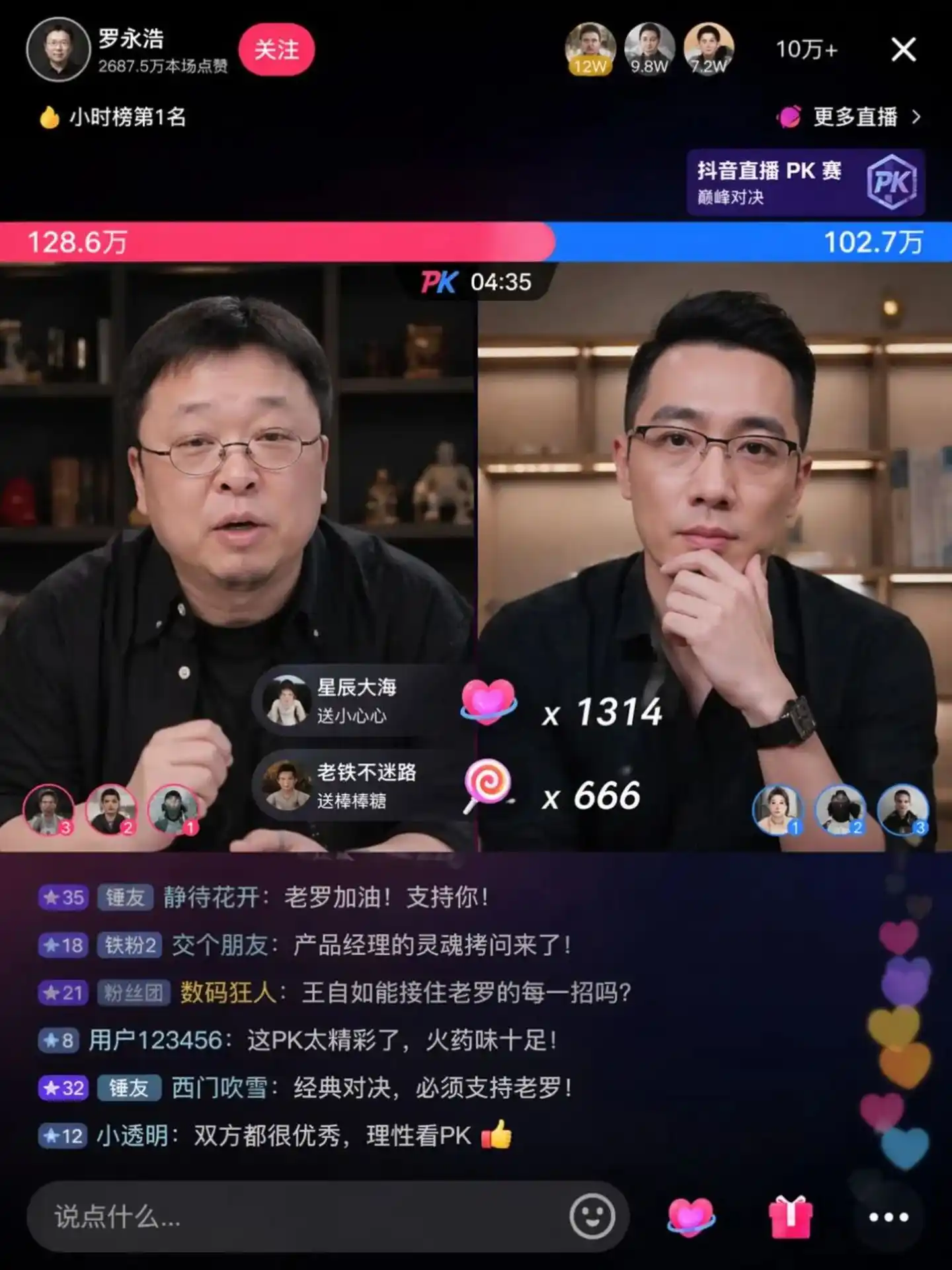
Source de l'image : https://cdn3.linux.do/original/4X/0/9/7/097ed46991d2464442aebc6b1076a292cc839fec.jpeg
On peut voir Elon Musk vendant en direct du Lao Gan Ma :

Source de l'image : https://cdn3.linux.do/original/4X/2/f/a/2fa77cf040e6337643829df4ec5ca6467d2866b2.jpeg
Même une ordonnance écrite par un médecin :

Source de l'image : https://cdn3.linux.do/original/4X/9/f/f/9ffeab83675648b43116cd0763f6c8b560611ae6.jpeg
Le texte dans ces images n'est plus ces "pseudo-caractères chinois" de travers, mal assemblés, mais des maquettes de conception matures, dotées de charme calligraphique, d'un sens des niveaux de police et d'un art de la mise en page.
Manifestement, OpenAI a injecté une quantité massive d'images de corpus en chinois dans l'ensemble d'entraînement, effectuant un entraînement intensif ciblé.
Comparé au modèle précédent, la puissance de GPT-Image 2 s'exprime de manière encore plus淋漓尽致 (limpide).
Dans les tests comparatifs, le modèle précédent version 1.5 pouvait bien dessiner quelque chose qui ressemble à une recette, mais en regardant de près, le texte était presque entièrement du charabia.

Source de l'image : https://cdn3.linux.do/optimized/4X/2/b/3/2b38f3c1a134515d564f07f81661c0bd9578c6b9_2_750x750.jpeg
Mais la même recette générée par GPT-Image 2 a montré une clarté du texte et une esthétique ayant fait une percée里程碑 (historique).
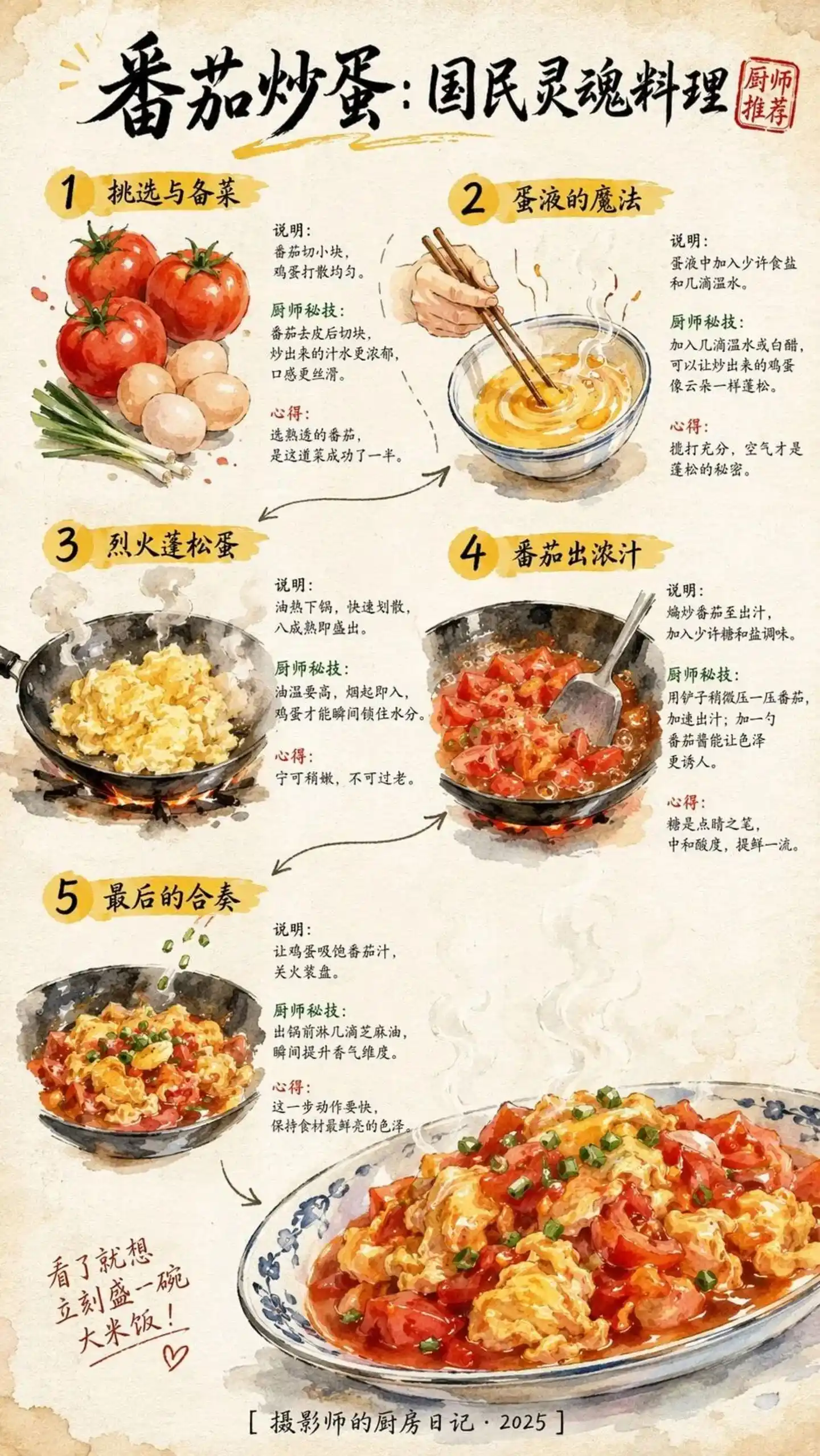
Source de l'image : https://cdn3.linux.do/original/4X/0/2/5/02513b10135d824ccb1c22bd0c7eb441f1e34455.jpeg
Pour une invite de plus de cent caractères chinois, les cinq étapes sont encore clairement visibles, la cohérence texte-image est satisfaisante. Ce n'est pas seulement une image, c'est aussi un plan opérationnel reproductible.
Cependant, cela soulève aussi une question technique intéressante : le modèle d'image a-t-il vraiment complètement résolu le problème du charabia ?
Mon jugement est : probablement pas.
La génération de tokens par un grand modèle de langage repose sur la logique sémantique. La phase d'apprentissage par renforcement se base sur des probabilités, plus le corpus de haute qualité est important, plus la logique est raisonnable. Mais l'essence d'un modèle d'image reste la génération de pixels. La relation logique entre les pixels et la relation logique entre les mots sont totalement différentes.
En d'autres termes, aussi puissant soit GPT-Image 2, il n'a pas vraiment "compris" les règles de l'écriture. Il a juste mémorisé par cœur l'apparence des textes au niveau pixel.
Une image de pourparlers commerciaux avec Ultraman expose ce point : les grandes inscriptions "Mengniu" et "Wanglaoji" sur les deux cartons de boissons sont écrites parfaitement, mais les petits caractères en dessous sont encore des blocs de couleur flous.

Source de l'image : https://cdn3.linux.do/original/4X/d/7/c/d7c4fb063202bcbf56b9ca0623aa0ce6fc26e542.jpeg
Dans le paradigme technologique actuel, la logique de génération est toujours "arrangement par pixels", loin du "rendu par caractère" qui en est essentiellement différent. Le charabia dans les détails extrêmement fins pourrait ne jamais être complètement éradiqué.
Mais cela dit, pour plus de 90 % des scénarios d'application commerciale, c'est déjà suffisant.
04 Défauts et limites pas encore divins
Même s'il est déjà assis sur le trône de numéro un mondial, GPT-Image 2 a aussi son côté maladroit.
Lors des tests, il a été constaté qu'en raison du mode de pensée qui appelle une recherche en ligne et effectue une déduction logique, lors du traitement de tâches fictives extrêmement complexes, le modèle peut occasionnellement tomber dans un cercle vicieux logique — après avoir réfléchi pendant près de 40 minutes, il est toujours incapable de répondre.
Dans le même temps, la résolution 2K voire 4K annoncée par l'API implique une consommation de tokens extrêmement élevée et une latence.
Pour l'utilisateur ordinaire, comment trouver un équilibre entre la qualité d'image ultime et la vitesse de réponse est un cours obligatoire dans l'utilisation future.
Dans le domaine technique, une capacité puissante est toujours une arme à double tranchant.
Que ce soit les modèles d'image ou les modèles vidéo, ils doivent inévitablement faire face au défi éthique de la contrefaçon profonde.
Dans la plupart des cas de test actuels, l'IA génère des personnalités connues, mais si elles sont remplacées par des personnes ordinaires ayant publié des photos sur diverses plateformes sociales, sans connaître la personne, il est déjà extrêmement difficile de distinguer le vrai du faux.
À part le charabia occasionnel en arrière-plan qui pourrait trahir l'IA, le corps humain lui-même n'a plus aucune faille.
Par conséquent, les domaines qui devaient autrefois être réalisés par de vraies personnes font face à une crise de confiance sans précédent.
La sortie de GPT-Image 2 a fait passer les modèles de génération d'images du jouet à l'outil de production.
Autrefois, les gens utilisaient l'IA pour fournir de l'inspiration, mais désormais l'IA commence à tenter de prendre en charge l'ensemble du processus, de la conception, du calcul, de la mise en page au produit fini.
Pour les professionnels du design, c'est une époque pleine de FOMO (Peur de Manquer Quelque Chose).
Mais pour ceux qui savent utiliser les outils, qui possèdent une esthétique produit et une pensée logique, c'est aussi la meilleure des époques.
Les images commencent à apprendre à penser, le texte n'est plus le bruit des pixels.
Les gens ne sont peut-être plus qu'à un pas de ce point de singularité visuelle où ce que l'on pense devient ce que l'on obtient.







