Un coup de tonnerre dans le monde de l'IA !
Anthropic lance un avertissement à toute l'humanité : arrêtez les recherches sur l'IA !
Les données internes d'Anthropic montrent que l'IA accélère le développement de l'IA, et le chemin vers l'auto-amélioration récursive est peut-être apparu.
Autrement dit, l'IA se rapproche d'un point critique où elle pourra « se construire elle-même ».
Ce processus est plus rapide que prévu par Anthropic, qui appelle donc à ralentir ou à suspendre la recherche en IA.
Pendant ce temps, Yann Dubois, responsable de l'équipe de post-entraînement chez OpenAI, apporte une perspective plus microscopique mais tout aussi réfléchie dans une récente interview :
L'évolution de l'IA n'est pas un soudain hack, mais un dépassement du seuil de qualification !
Dans cette dernière interview, il révèle plusieurs perspectives internes :
La croissance des capacités de l'IA est linéaire et continue, mais l'« utilité » ressentie par l'utilisateur est discrète et saccadée.
Car avant d'atteindre un certain « seuil de fiabilité », l'IA n'est qu'un jouet qui fait des tours ; une fois ce point franchi, elle devient un employé à qui l'on peut confier du travail, et elle commence à s'auto-accélérer.

OpenAI a franchi ce seuil vers décembre dernier.

De plus, Yann Dubois avance une affirmation contre-intuitive : la construction de l'IA ressemble plus à un « artisanat (Craft) » qu'à une « science ».
Cette observation est puissante : dans ce domaine qui met tant l'accent sur la puissance de calcul brute, ce qui finit par l'emporter est une « intuition/inspiration » proche de l'alchimie.
Il évoque aussi les « bénéfices de l'IA du dernier kilomètre ».
Si nous gelions tous les modèles maintenant, en nous contentant de développer des applications verticales (Harness), nous pourrions déjà réaliser l'AGI.
Le goulot d'étranglement n'est pas dans le cerveau du modèle, mais dans les « autorisations, connexions et données ». Cela jette un seau d'eau froide sur les développeurs qui hésitent, tout en indiquant où se trouve le filon.
Le seuil de fiabilité franchi, l'IA s'auto-accélère
Ces dernières semaines, le monde de l'IA a été agité : sortie de GPT-5.5, Claude Mythos également disponible.
Surtout dans la cybersécurité et les agents IA écrivant du code, les progrès donnent l'impression d'avancer à pas de géant, comme si l'IA avait « fait un grand bond ».
La vision de Dubois est plus tranchante : l'amélioration des capacités est en fait assez continue. L'impression d'être propulsé par une fusée vient de la présence d'un « seuil de fiabilité ».
Avant de franchir ce seuil, l'IA ressemble à un stagiaire brillant mais casse-cou : elle peut écrire, calculer, proposer des idées, mais on n'ose pas lui confier une tâche en profondeur.
Après avoir franchi ce seuil, on ose la laisser « vraiment travailler ».

Il estime qu'OpenAI a franchi cette ligne vers « décembre dernier », ce qui a donné lieu à cette « transition en escalier » ressentie de l'extérieur.
Le deuxième facteur est plus stimulant : lorsque le modèle est suffisamment bon, il accélère à son tour la recherche et le développement.
C'est ce qui inquiète le plus Anthropic.
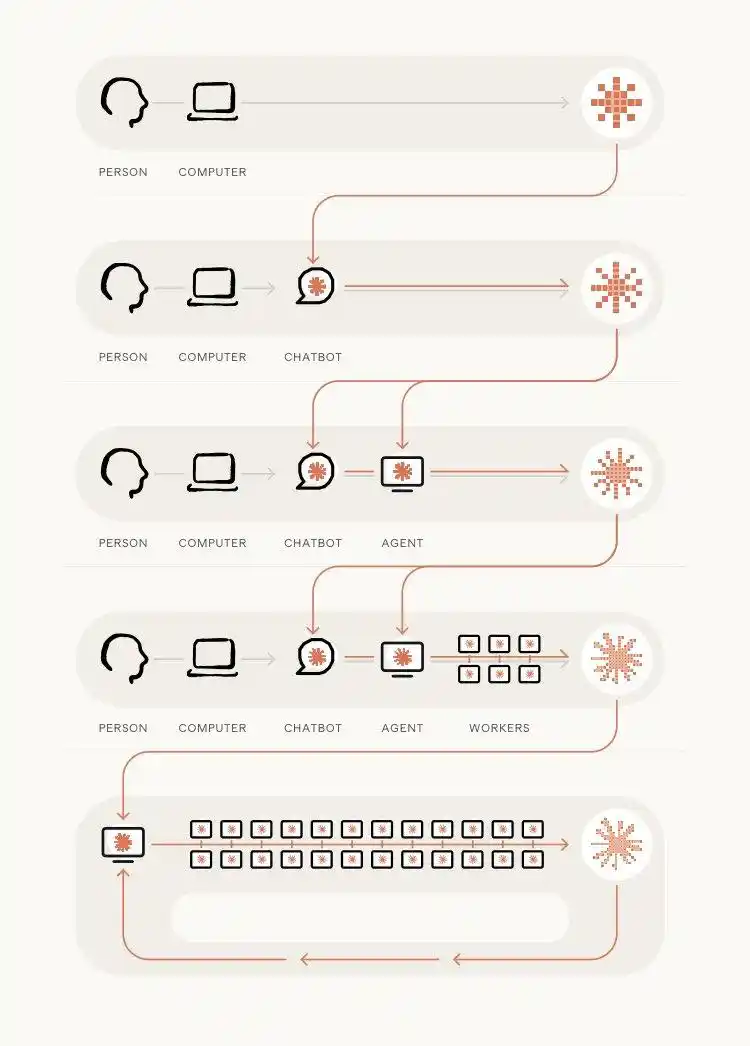
Dubois mentionne que, surtout dans les scénarios de programmation, les chercheurs écrivent du code quotidiennement. Lorsque le modèle devient plus puissant, c'est comme si toute l'équipe avait un partenaire qui ne dort jamais – capable d'aider les chercheurs à mettre en place la chaîne d'outils et de nourrir l'IA par l'IA lors de l'entraînement de la prochaine génération de modèles.
Une fois que cette boucle d'accélération se met en marche, elle tourne de plus en plus vite. Il n'est pas surprenant que les derniers mois soient « de plus en plus intenses ».
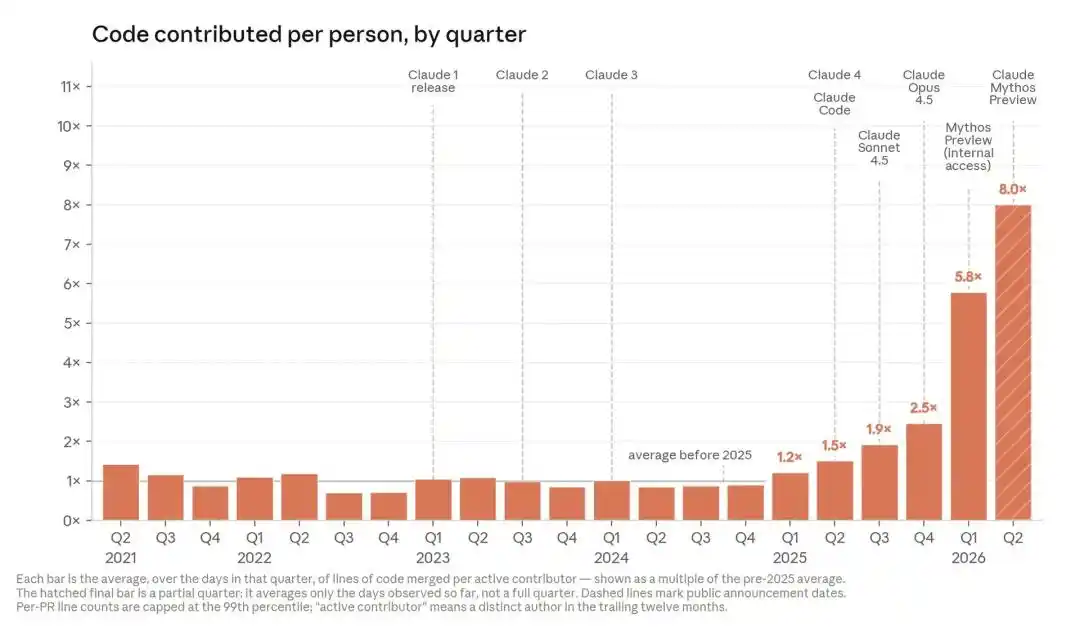
Cela s'est aussi produit chez Anthropic : au deuxième trimestre 2026, le nombre de lignes de code contribuées par personne et par trimestre était déjà 8 fois supérieur à celui du premier trimestre 2024.
La troisième force motrice vient de la « transformation et de la mise à niveau » de l'apprentissage par renforcement (RL).
Au début, des modèles de raisonnement comme o1 se concentraient sur des tâches à « récompense vérifiable » – problèmes mathématiques, concours de programmation – car le vrai/faux est clair et la récompense facile à définir.
Mais au cours de la dernière année, ils ont migré ces outils perfectionnés en compétition vers des scénarios de travail plus réels et plus flous : ils n'optimisent plus seulement les « problèmes à réponse unique », mais « ce que les utilisateurs trouvent vraiment utile ».
En un mot : ils évoluent d'un candidat qui passe des examens vers un travailleur du monde professionnel.
L'ingénieur IA n'est pas un scientifique, l'IA est « élevée »
Mais une fois dans le monde réel, les problèmes surviennent : comment améliorer la fiabilité ?
Dubois donne un « modèle de probabilité » très simple :
Étant donné que beaucoup de systèmes sont maintenant des agents IA (agentic), vous pouvez penser grossièrement qu'« il y a une certaine probabilité de faire une erreur toutes les deux minutes » ; plus le temps d'exécution est long, plus la probabilité que la réponse finale échoue est élevée.
Ainsi, « améliorer la fiabilité » consiste essentiellement à réduire continuellement ce « taux d'erreur toutes les deux minutes ».
C'est la pierre d'achoppement inhérente des agents IA.

Cela explique aussi pourquoi Dubois dit que la construction de l'IA ressemble plus à un « travail artisanal », pas à une « expérience scientifique » comme dans les manuels.
Le processus réel est souvent : d'abord, créer quelque chose en s'appuyant sur l'expérience, l'intuition, les essais et erreurs répétés, avec même un côté « alchimique » ; quand cela fonctionne vraiment, on revient ensuite ajouter des explications et des méthodologies plus scientifiques.
Il mentionne aussi un petit épisode révélateur –
Lorsque ChatGPT a annoncé publiquement avoir utilisé du RL, sa première réaction a été « trop complexe, la fine-tuning supervisé (SFT) suffit », ce qui était exactement l'idée qu'il voulait vérifier en créant Alpaca à Stanford.

Mais les faits ont montré plus tard qu'une fois que la taille du modèle dépasse un certain niveau, le RL commence vraiment à « devenir utile soudainement », mais à un coût non négligeable – échantillonner de nombreuses réponses, juger lesquelles sont correctes ou non, cela nécessite beaucoup de puissance de calcul et d'ingénierie système.
Le Harness dans des domaines verticaux atteint déjà l'AGI
En parlant de « faire entrer l'IA dans la réalité », impossible d'éviter le mot préféré récemment dans le monde des startups : Harness (système d'orchestration).
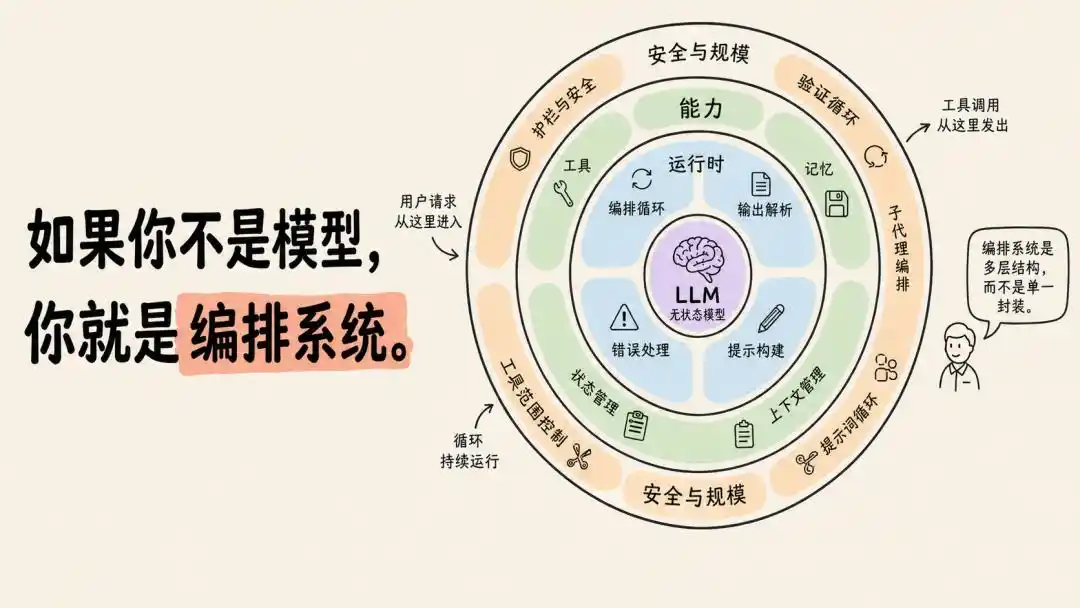
Certains le considèrent comme le « squelette externe » de l'agent IA, d'autres soupçonnent qu'il sera tôt ou tard « digéré » par le modèle.
L'attitude de Dubois est réaliste :
À court terme, un Harness pour un scénario vertical est très précieux, pouvant faire passer la fiabilité de 80% à 85%.
Mais à condition d'accepter que le modèle continue de s'améliorer et que le Harness doit être constamment réajusté.
Essayer de créer un « Harness universel » stable à long terme et applicable partout, il pense que c'est fondamentalement infaisable.
Il lance même un jugement très « provocateur » : si aujourd'hui nous « gelions » les modèles existants, en nous concentrant uniquement sur l'affinage du Harness et en l'entraînant autour de lui, de nombreuses personnes dans de nombreux domaines pourraient « ressentir clairement la saveur d'une intelligence artificielle générale (AGI) ».
Le dernier kilomètre
Mais ce qui excite et préoccupe vraiment Dubois, c'est la difficulté persistante de « l'apprentissage continu (continual learning) ».
Il y a trois ans, lorsque ChatGPT est devenu populaire, lui et ses amis ont même sérieusement discuté de créer une startup pour la mémoire personnalisée et l'apprentissage continu.
À l'époque, ils pensaient qu'« OpenAI résoudrait cela dans les 6 mois », donc ils ne l'ont pas fait ; trois ans plus tard, il travaille chez OpenAI et constate que le problème n'est toujours pas vraiment résolu.
Le dilemme actuel du modèle est le suivant : le premier jour dans une entreprise, il peut être plus utile que la plupart des nouveaux employés (point de départ élevé) ; mais ensuite, il reste essentiellement « tel quel », car il n'apprend pas à mieux vous connaître et à devenir plus efficace dans un environnement spécifique.
La courbe d'apprentissage humaine est ascendante, celle de l'IA a tendance à s'aplatir.
Transformer la courbe de l'IA de « plate » en « continuellement ascendante » est, selon Dubois, l'un des problèmes les plus importants à venir.
Alors, les startups ont-elles encore de la place pour faire des applications verticales ?
La réponse de Dubois est nette : non seulement oui, mais la place est grande.
Car le véritable goulot d'étranglement n'est souvent pas « le modèle est-il assez intelligent », mais le dernier kilomètre – comment donner les autorisations, comment connecter les données, comment ouvrir les connecteurs, comment s'intégrer dans des processus métiers spécifiques.

Les grands modèles peuvent voler haut dans le ciel, s'ils ne touchent pas terre, ils ne sont que des feux d'artifice ; les ramener sur le sol, leur donner les bonnes clés, ouvrir les bonnes portes, c'est en fait le travail pénible et fastidieux le plus précieux.
Références :
https://x.com/Potatoloogs/status/2062494654885749126
https://www.youtube.com/watch?v=DhD1zZ8w8Mw&t=3s
Cet article provient du compte public WeChat "新智元" (Xin Zhi Yuan), auteur : ASI启示录






