Ce qu'il y a de plus cruel avec l'IA, ce n'est pas qu'elle ne donne pas de réponses aux pauvres.
C'est tout le contraire : elle donne des réponses à tout le monde.
Elle fournit aux étudiants des structures de dissertations, aux employés des modèles d'e-mails, aux entrepreneurs des plans d'affaires, aux citoyens ordinaires des explications juridiques, des conseils en investissement, des plans de carrière. Pour la première fois, les réponses sont si bon marché, si abondantes, si... convaincantes.
Mais c'est justement là que le bât blesse : lorsque les réponses sont accessibles à tous, ce qui devient vraiment rare, ce ne sont plus les réponses elles-mêmes, mais la capacité à les juger.
Les nouveaux pauvres en information ne sont pas ceux qui sont exclus de l'IA, mais ceux qui, ayant déjà obtenu des réponses, n'ont ni la capacité de les évaluer, ni les conditions pour les transformer en véritables opportunités.

I. La fracture informationnelle à l'ère de l'IA
À l'ère d'Internet, les pauvres en information étaient ceux exclus du réseau. La solution semblait claire : installer des connexions, démocratiser l'accès aux équipements, améliorer le taux d'alphabétisation. À l'ère des moteurs de recherche, c'était un peu plus complexe : il fallait savoir formuler des mots-clés, sélectionner ses sources, évaluer leur crédibilité, et idéalement maîtriser un peu l'anglais. Mais le seuil était visible et quantifiable.
À l'ère de l'IA, la fracture informationnelle a une structure totalement différente.
Les grands modèles de langage ne sont pas des moteurs de recherche ; ils génèrent directement des conclusions pour vous. Vous n'avez plus besoin d'"aller chercher" la réponse – elle vous est servie, organisée en paragraphes fluides, étapes claires, sur un ton assuré. En apparence, le seuil est considérablement abaissé. Mais cette structure cache une réalité froide : lorsque les réponses deviennent bon marché, les erreurs le deviennent aussi ; et la capacité à déterminer si "cette réponse est crédible", elle, devient plus rare et plus précieuse que jamais.
Historiquement, chaque diffusion d'une technologie universelle suit la même logique : la nouvelle technologie récompense d'abord ceux qui possèdent déjà le capital complémentaire. L'imprimerie a d'abord profité aux lettrés ; l'ordinateur, à ceux qui maîtrisaient les logiciels bureautiques et la programmation ; Internet, à ceux dotés de bonnes compétences en anglais et en recherche. Le capital complémentaire de l'IA comprend le niveau d'éducation, l'expertise, l'esprit critique, l'autorisation organisationnelle, la capacité à payer, et la qualité la plus difficile à quantifier – le jugement.
Les nouvelles technologies récompensent rarement en premier ceux qui en ont le plus besoin. Elles récompensent généralement en premier ceux qui savent le mieux les utiliser.
II. Ce qui divise d'abord, c'est l'accès à l'IA
La première faille d'inégalité est tracée avant même que vous n'ouvriez l'application.
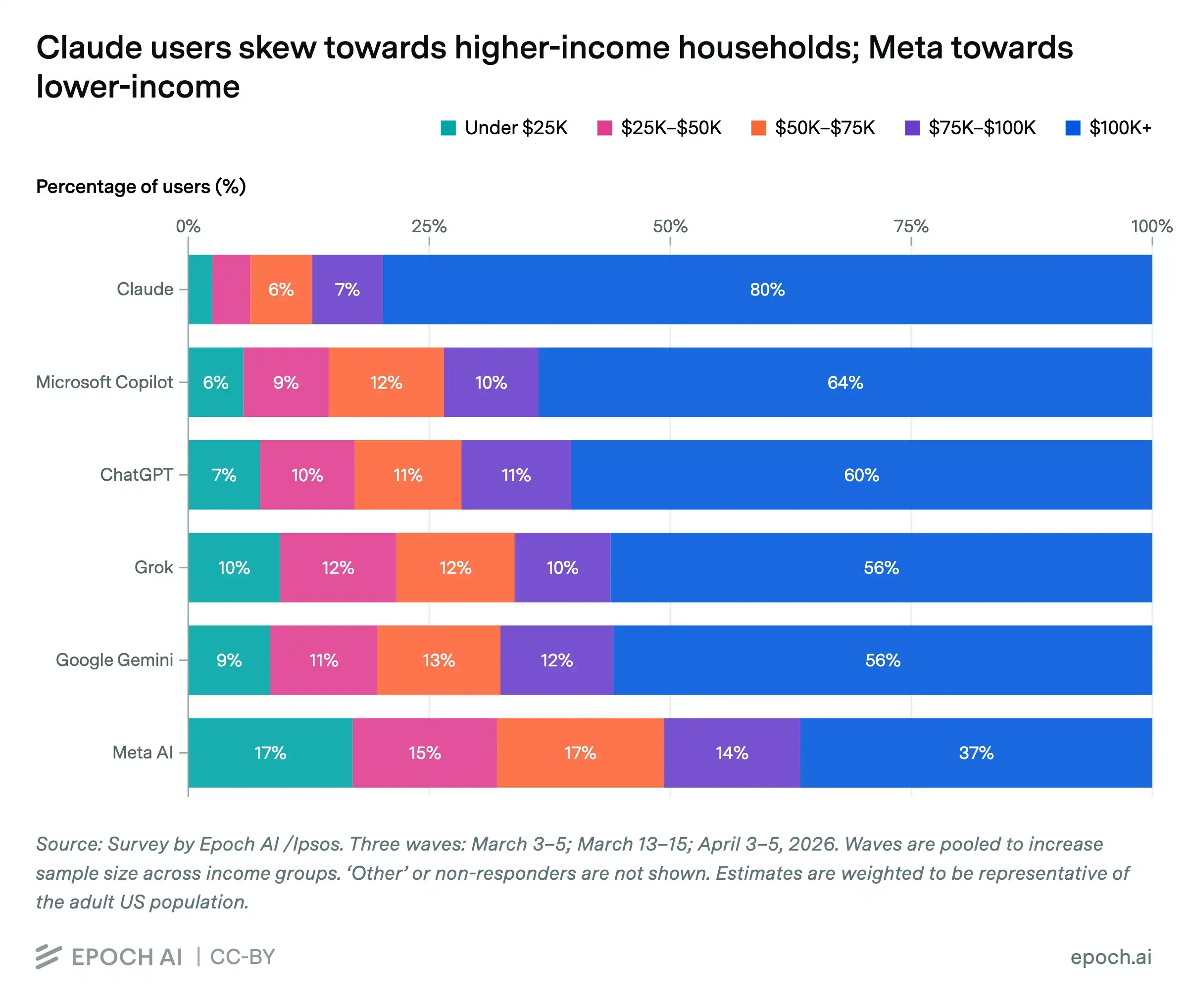
En avril 2026, le centre de recherche Epoch AI et l'institut de sondage Ipsos ont publié une enquête auprès d'environ 5 000 adultes américains. Trois vagues de questionnaires posaient une question en apparence simple : la semaine dernière, quels services d'IA avez-vous utilisés ? Mais les réponses ne révèlent pas de simples préférences produits, mais une cartographie tissée de revenus, de points d'entrée et de distribution.
Parmi les utilisateurs actifs hebdomadaires de Claude, environ 80 % proviennent de foyers gagnant plus de 100 000 dollars par an ; parmi les utilisateurs de Meta AI, cette proportion n'est que de 37 %. Inversement, environ 32 % des utilisateurs de Meta AI proviennent de foyers gagnant moins de 50 000 dollars par an, contre seulement 7 % pour les utilisateurs de Claude.
Ces chiffres sont importants, non parce qu'ils prouvent que "les riches utilisent l'IA haut de gamme, les pauvres l'IA gratuite". C'est la lecture la plus superficielle. Il est plus pertinent de se demander : pourquoi différentes personnes rencontrent-elles différentes IA dans leur vie quotidienne ?
Une personne demande à une IA de lui suggérer un dîner avec les restes dans son frigo, d'éclaircir l'arrière-plan d'une photo, de reformuler un SMS de manière plus appropriée. Une autre demande à une IA de synthétiser des entretiens clients, de comparer des devis fournisseurs, d'identifier les hypothèses faibles d'un rapport. Tous deux font appel à la même technologie. Mais un usage s'arrête à la commodité, l'autre s'insère dans une boucle de revenus, de postes et de pouvoir de négociation.
La différence ne réside pas seulement chez l'utilisateur, mais aussi dans le point d'entrée. Pour utiliser Claude, il faut une démarche active : rechercher, comparer les produits, comprendre les différences de capacités, choisir de payer, puis intégrer l'outil dans son flux de travail – chaque étape fait le tri. Le chemin d'accès à Meta AI est presque inverse : il est intégré à une plateforme sociale, gratuit, à faible friction, l'utilisateur le rencontre souvent passivement en scrollant, en envoyant des messages ou en regardant des photos.
Ce n'est pas un marché du goût, c'est un marché de la distribution. L'utilisateur semble choisir l'outil, mais le prix et le point d'entrée de l'outil choisissent aussi l'utilisateur.
Source : epoch.ai
III. Ce qui divise ensuite, c'est le contexte d'utilisation de l'IA
Même si vous trouvez un bon outil d'IA, une seconde divergence vous attend au sein de l'entreprise.
Dans un bureau ordinaire, l'arrivée de l'IA se présente rarement sous la forme d'un "avis de licenciement". Elle commence par prendre en charge les comptes rendus de réunion, les brouillons d'e-mails, la mise en forme de tableaux, le classement des clients et les premières ébauches de rapports. Pour les managers, cette automatisation libère du temps pour faire des jugements ; pour les nouveaux arrivants et les employés de base, cette automatisation retire précisément les tâches par lesquelles ils prouvaient leur valeur, s'exerçaient au jugement, et accédaient à des responsabilités plus élevées.
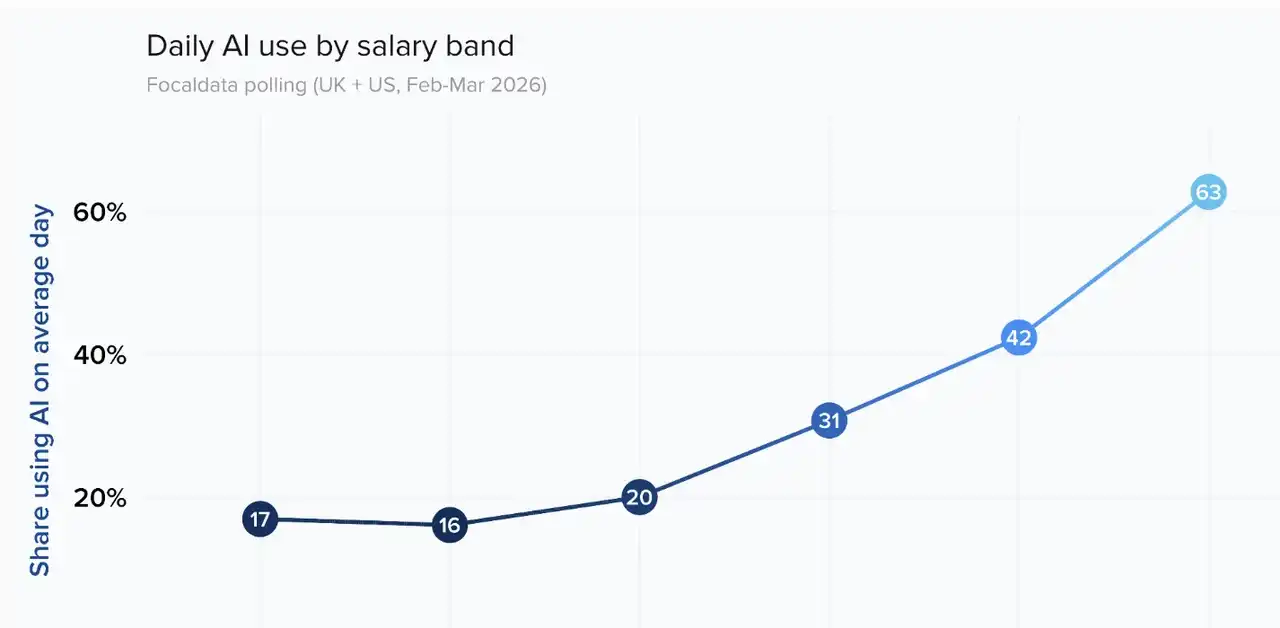
Les données sont plus froides que ce constat : l'enquête de suivi de l'utilisation de l'IA dans la main-d'œuvre menée par le Financial Times avec un institut de recherche (février-mars 2026, couvrant plus de 4 000 répondants au Royaume-Uni et aux États-Unis) montre que 63 % des salariés de la tranche de rémunération la plus élevée utilisent l'IA lors d'une journée de travail normale, contre seulement 17 % et 16 % pour les deux tranches les plus basses. Ce n'est pas une pente douce, c'est une falaise.
La découverte la plus cruciale concerne les facteurs déterminants. L'analyse de régression de cette enquête révèle que l'influence du salaire sur le taux d'utilisation de l'IA disparaît presque après contrôle des autres variables – ce qui joue réellement, ce sont quatre facteurs : l'âge, l'ancienneté, le secteur d'activité et la formation. Et c'est l'effet de la formation qui est le plus important : dans une entreprise ayant fourni une formation formelle à l'IA, le taux d'utilisation quotidien moyen des employés est supérieur de 37 points de pourcentage à celui d'une entreprise similaire sans formation. Même un simple accompagnement informel entraîne une augmentation de 24 points.
Cependant, la réalité est la suivante : début 2026, seuls 14 % des employés déclarent avoir reçu une formation formelle à l'IA de la part de leur employeur, et deux tiers n'ont reçu aucune forme de formation.
La formation à l'IA n'est pas un problème technique, c'est un problème de répartition. Celui qui est choisi pour recevoir la formation est autorisé à entrer sur la voie de la croissance de la productivité ; celui qui ne l'est pas, l'outil n'est pour lui qu'une icône à l'écran qu'il n'a pas l'autorisation d'ouvrir.
L'IA est une application côté consommateur, mais une autorisation côté lieu de travail. Et les autorisations n'ont jamais été réparties de manière égale.
Source : Focaldata
IV. Ce qui finit par diviser, c'est la capacité à juger l'IA
C'est la divergence la plus subtile, et la plus fondamentale.
Imaginez un jeune diplômé qui entre dans un cabinet de conseil. Il utilise l'IA pour générer une première ébauche d'analyse sectorielle, bien structurée, riche en données, au ton assuré. Son supérieur – qui a dix ans d'expérience dans le secteur – y jette un coup d'œil et pointe du doigt que deux des sources de données citées ont des failles méthodologiques, et que le raisonnement de cause à effet de la troisième conclusion est problématique. Le supérieur n'a pas plus travaillé que lui, mais il possède cette base solide – savoir où les erreurs se cachent facilement, savoir quelle fluidité est authentique et quelle fluidité n'est que de la poudre aux yeux.
C'est précisément la signification réelle de cette découverte contre-intuitive des données de l'enquête professionnelle : les plus grands utilisateurs de l'IA au travail ne sont pas les employés les plus jeunes, mais ceux qui sont déjà en poste depuis 2 à 10 ans. La relation entre le taux d'utilisation de l'IA et l'ancienneté reste significative même après contrôle de l'âge. Ce n'est pas que les jeunes ne veulent pas l'utiliser, c'est que la valeur de l'IA dépend énormément de la capacité de jugement préexistante de l'utilisateur.
L'expérience est le capital complémentaire le plus important pour l'IA, et l'expérience ne peut pas être souscrite par abonnement.
L'IA a réduit le coût de "sembler comprendre", sans réduire au même niveau le coût de "comprendre vraiment". Il y a même une conséquence plus dangereuse : plus l'utilisateur manque de base solide, plus il est susceptible d'accepter sans critique la production de l'IA ; et plus il l'accepte sans critique, moins son jugement a de chances de se développer. Lorsqu'un agent effectue le jugement pour vous, vous consommez de l'intelligence, vous ne l'accumulez pas.
Le prix Nobel d'économie et professeur au MIT, Daron Acemoglu, n'y va pas par quatre chemins : l'utilisation d'outils d'IA nécessite un certain niveau d'éducation, de pensée abstraite, de capacité quantitative et de familiarité avec la technologie. "Il est presque certain que l'IA va augmenter les inégalités", affirme-t-il.
C'est là que les nouveaux pauvres en information prennent forme : ils ne sont pas ceux qui n'ont pas d'IA, mais ceux qui ont l'IA, l'accès, les réponses, mais manquent de l'entraînement pour les juger ; qui ont l'outil, le contexte, mais pas l'autorisation de transformer la production de l'outil en opportunité ; qui consomment de l'intelligence quotidiennement, sans jamais en avoir accumulé.
V. Les limites de l'effet d'égalisation
Mais la relation de l'IA avec les inégalités n'a pas qu'une seule face, celle d'élargir les écarts.
De multiples études expérimentales ont montré qu'en conditions contrôlées, l'IA a tendance à améliorer davantage les performances des personnes les moins qualifiées – qu'il s'agisse d'employés de centre d'appels, de rédacteurs débutants ou de consultants juniors. Cela n'est pas difficile à comprendre : les experts de haut niveau tirent un gain marginal limité de l'IA ; pour une personne qui n'a jamais pu se payer des services professionnels, comprendre un contrat pour la première fois grâce à l'IA est en soi un bond qualitatif.
Mais il faut souligner une distinction cruciale ici : les études expérimentales mesurent "l'amélioration après utilisation", tandis que les données réelles mesurent "qui utilise réellement", "qui est autorisé à utiliser", "qui peut transformer les résultats en opportunités après utilisation". Les deux ensembles de données ne mentent pas, ils mesurent des choses totalement différentes.
Une technologie peut réduire les écarts en laboratoire, tout en les augmentant dans le monde réel – si son adoption est inégale, si les contextes d'application sont inégaux, si le jugement lui-même est inégal.
L'IA possède des caractéristiques techniques égalisatrices, mais elle fonctionne dans une structure sociale inégalitaire. Ces deux affirmations sont simultanément vraies, et c'est cela qui donne sa forme réelle au problème.
VI. La technologie se démocratise, les bénéfices n'arrivent pas simultanément
Chaque génération a tendance à croire que la technologie universelle de son époque brisera l'ancien ordre.
Après l'apparition de l'imprimerie, les lettrés en ont profité les premiers pendant des siècles. Au début de la démocratisation de l'ordinateur, il a amplifié les capacités de ceux qui savaient déjà utiliser les logiciels bureautiques et coder. Les premiers bénéfices d'Internet sont allés à ceux qui maîtrisaient l'anglais, la recherche, et avaient le temps et la motivation pour en tirer profit. À chaque vague technologique, la voix disant "cette fois, c'est différent" a été forte, et les divergences structurelles ont souvent mis des décennies à devenir lentement visibles.
La divergence liée à l'IA pourrait être plus rapide, la fourche plus profonde. Car elle n'affecte pas un type de tâche spécifique, mais presque tous les travaux reposant sur le jugement et le langage. Et ce sont précisément les capacités les plus difficiles à standardiser et à redistribuer.
Certains pensent que l'écart finira par se réduire. L'historien de l'économie et professeur à l'Oxford Internet Institute, Carl Benedikt Frey, défend cette vision, s'appuyant sur l'histoire : l'inégalité induite par la démocratisation de l'ordinateur s'est progressivement estompée après quelques décennies, avec la baisse des seuils d'utilisation. L'analogie n'est pas dénuée de sens.
Le problème, c'est que même en acceptant cette analogie historique optimiste, Frey lui-même reconnaît une condition limitante clé : "Cela dépend du temps nécessaire pour que l'écart se comble. S'il faut dix ou vingt ans, c'est plus inquiétant."
Dix ou vingt ans, ce n'est pas une échelle de temps que l'on peut attendre tranquillement – surtout pour ceux qui, pendant cette période, doivent trouver un emploi, négocier leur salaire, accumuler de l'expérience.
Conclusion
Nous vivons un moment historique singulier : pour la première fois, nous disposons d'une technologie qui donne à chacun l'impression de devenir plus intelligent.
Cette impression est souvent le point d'arrivée.
Le problème, c'est qu'à une époque où les vainqueurs et les vaincus sont réellement déterminés par le jugement, prendre cette impression pour un aboutissement pourrait être l'erreur la plus coûteuse.






