Dans le domaine de la programmation IA aujourd'hui, Claude Code, Codex et Cursor sont les trois outils d'assistance les plus célèbres.
Les deux premiers, soutenus respectivement par Anthropic et OpenAI, ont remporté à plusieurs reprises les premières places dans les benchmarks liés à la programmation grâce à leurs modèles les plus avancés, Opus 4.7 et GPT-5.5.
En comparaison, Cursor, né en 2023, semble aujourd'hui quelque peu à la traîne. Pour renverser la situation, Cursor a décidé de lancer une véritable bombe : Composer 2.5.
Bien que l'entreprise n'ait publié qu'un court article technique d'une lecture de 2 minutes, Cursor a affirmé sa souveraineté technologique avec une grande retenue : un partenariat avec SpaceXAI de Musk pour accéder à une puissance de calcul équivalente à 1 million de puces H100, une explosion de 25 fois de la taille des données synthétiques utilisées, et une tarification commerciale très agressive.
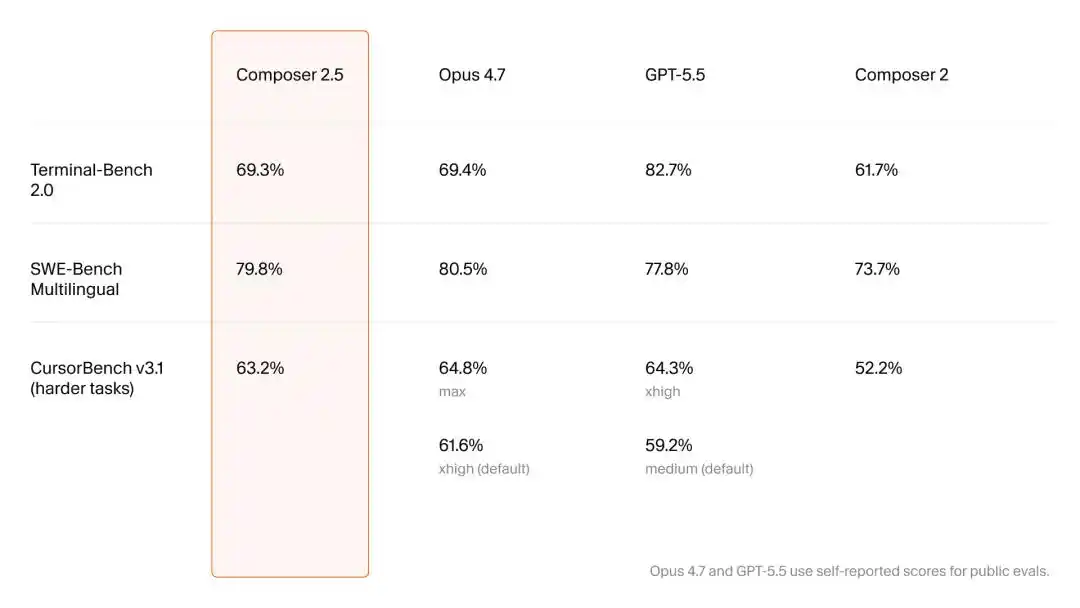
En bas de l'article, Cursor a laissé trois notes de bas de page discrètes. Les trois articles de recherche pointus qu'elles mentionnent, couvrant l'apprentissage par renforcement, les données synthétiques et des modifications astucieuses de l'infrastructure sous-jacente, correspondent précisément aux trois éléments de l'IA : "algorithme, données et puissance de calcul". C'est la clé pour comprendre la puissance de Composer 2.5.
Cursor annonce à toute l'industrie une vérité : la compétition dans la programmation IA est déjà passée de l'ère des armes blanches, avec des coques d'API, à l'ère des armes nucléaires, où il faut réécrire les algorithmes d'apprentissage par renforcement sous-jacents.
01
Apprentissage par Renforcement : « Autodistillation »
La programmation IA est vue différemment par les développeurs et le grand public. Pour ce dernier, elle réduit la barrière d'entrée, permettant même à ceux qui ne savent pas coder de créer une application. Les développeurs, eux, estiment que les capacités actuelles de la programmation IA ne peuvent se passer d'une relecture humaine. Dès que le nombre d'interactions augmente et que le contexte s'allonge, les performances de la programmation IA chutent.
Cursor met le doigt sur un problème mondial auquel toute l'industrie de la programmation IA doit actuellement faire face, et le nomme « Attribution de Crédit (Credit Assignment) ».
C'est comme si un professeur de littérature recevait un roman de 100 000 mots écrit par un élève. Après un coup d'œil rapide, constatant que l'ensemble est mauvais, il met directement une note d'échec au roman.
Dans le domaine de l'IA, l'apprentissage par renforcement traditionnel, comme l'algorithme GRPO basé sur des récompenses scalaires, fonctionne ainsi : il donne seulement une note finale discrète : 0 pour correct, 1 pour incorrect.
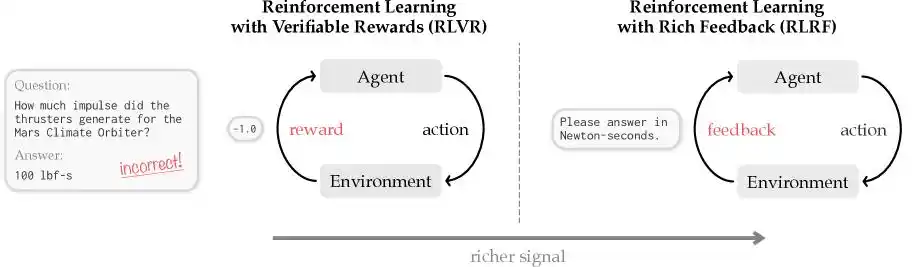
De toute évidence, cette approche n'est pas fausse, mais elle manque de rigueur. Car après avoir échoué, l'élève ne sait absolument pas où il a fait erreur : est-ce le personnage principal au début qui ne tient pas la route, la logique qui se brise au milieu, ou la fin qui dévie du sujet ?
C'est la même chose pour le modèle IA. Ne recevant aucun retour spécifique, la prochaine fois qu'il exécute une tâche complexe et génère des centaines de milliers, voire des millions de tokens de code, il ne sait toujours pas par où commencer les corrections, quoi corriger, ni comment le faire. Pire, dans ce processus d'essais et d'erreurs aveugles, les modèles traditionnels ont souvent tendance à produire beaucoup de bavardages inutiles dans leur chaîne de raisonnement. Ces bavardages se traduisent par des factures bien réelles pour les tokens de sortie.
Pour résoudre ce problème, Cursor vise le mécanisme de « l'apprentissage par renforcement directionnel basé sur des retours textuels ». L'équipe d'ingénierie a habilement introduit la technique de « l'Autodistillation (Self-Distillation) » dans le processus d'entraînement pour la génération de longs textes de code.
Lorsqu'on parle de distillation, on pense naturellement au jeu entre un modèle enseignant et un modèle étudiant. C'est comme un examen mêlant épreuve à livre ouvert et à livre fermé :
Lorsqu'une erreur d'appel d'outil survient pendant la génération de code sur des centaines de milliers de tokens, Cursor donne directement au modèle le message d'erreur spécifique ainsi que la liste correcte des outils disponibles, lui permettant de "consulter le livre" et de voir la réponse. Ainsi, ce modèle qui a vu la bonne réponse, se trouvant dans un état de toute connaissance, devient naturellement le modèle enseignant.
Le même modèle, qui n'a pas vu la réponse et doit coder à l'instinct, sert de modèle étudiant et commence à s'aligner sur le modèle enseignant.
Le modèle enseignant n'a pas besoin de réécrire le code du début à la fin. Il suffit qu'il indique au modèle étudiant, à l'emplacement précis du token où l'erreur s'est produite : "À ce token, tu devrais réduire la probabilité de choisir l'outil A et augmenter celle de choisir l'outil B."
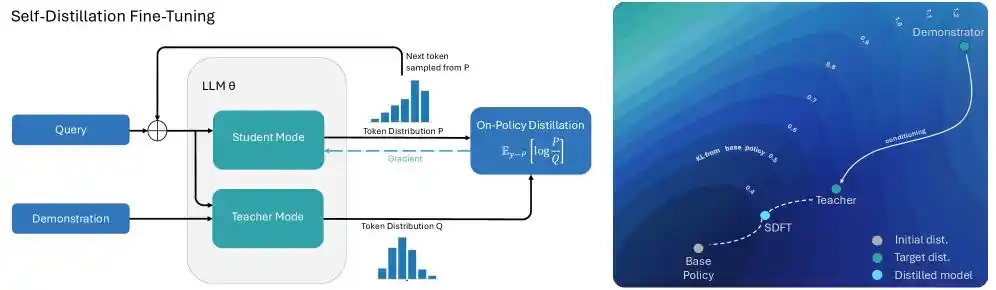
Ce processus d'autodistillation, qui semble simple, produit des résultats surprenants :
Premièrement, le modèle évite l'oubli catastrophique. Cette méthode on-policy lui permet d'apprendre de nouvelles compétences comme l'appel d'outils complexes tout en conservant intactes ses solides capacités de base en codage et raisonnement.
Deuxièmement, la « littérature superflue » prend fin. Comparé aux algorithmes d'apprentissage par renforcement traditionnels qui produisent souvent des milliers de tokens de sortie invalides, le modèle entraîné par autodistillation a un processus de raisonnement extrêmement concis.
En d'autres termes, Composer 2.5 refuse de "réfléchir pour réfléchir", il vise "le coup parfait".
02
Données Synthétiques : « Manuel de la Tronche »
Pour rattraper voire dépasser Claude Code et Codex, Cursor a fait un effort considérable cette fois. Non seulement il a usé de ruse au niveau de l'algorithme, mais il a également investi massivement au niveau des données :
Dans l'entraînement de Composer 2.5, Cursor a utilisé 25 fois plus de données synthétiques que pour le modèle précédent.
La loi de l'échelle (Scaling Law) n'a jamais été démentie. Mais aujourd'hui, alors que les données d'Internet sont sur le point de s'épuiser, les "données synthétiques" sont devenues la bouée de sauvetage de toutes les entreprises d'IA.
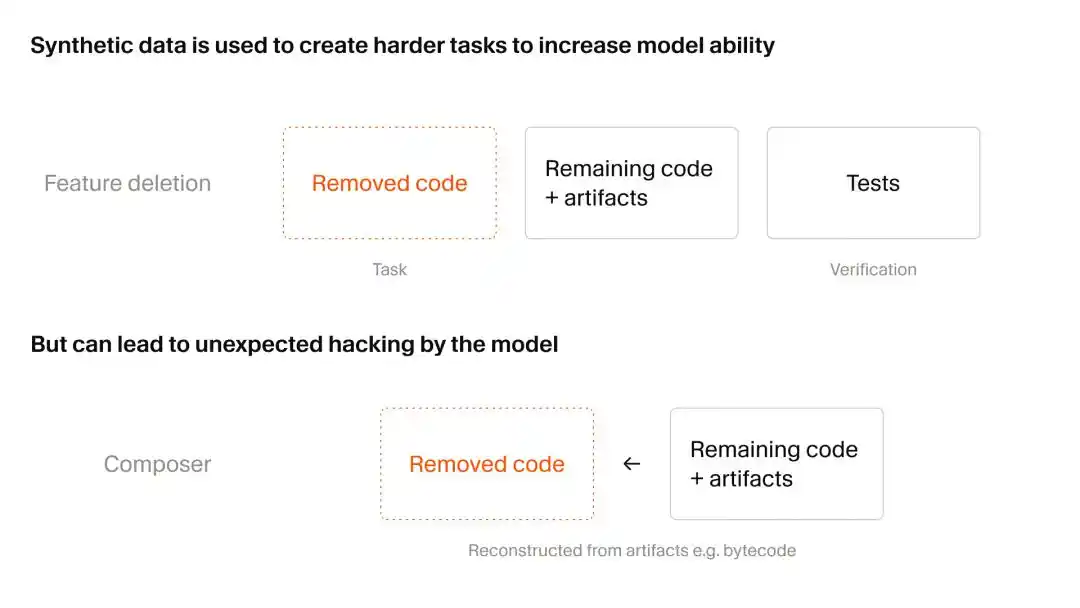
Cursor a adopté une méthode astucieuse pour obtenir des données synthétiques : d'abord détruire, puis reconstruire, c'est-à-dire la méthode de suppression fonctionnelle.
L'équipe de recherche a d'abord trouvé un vaste référentiel de code réel avec de nombreux cas de test automatisés. Ils ont demandé à l'IA de jouer le rôle d'un "perturbateur inoffensif", supprimant le code et les fichiers liés à certaines fonctions spécifiques, tout en veillant à ce que le code restant puisse toujours s'exécuter.
L'étape suivante consistait à donner ce référentiel de code incomplet mais toujours exécutable au Composer 2.5 en cours d'entraînement, et à lui demander de reproduire les fonctionnalités supprimées. Le critère de jugement était simple : voir s'il pouvait passer les cas de test originaux.
Ce test, qui pour un humain n'est qu'un "texte à trous", constitue en réalité un entraînement de restitution contextuelle de très haut niveau pour l'IA. Cependant, au cours de ce processus, Cursor a observé un phénomène quelque peu dérangeant de « Piratage de Récompense (Reward Hacking) » par l'IA.
En clair, avec l'évolution des capacités de Composer, il a commencé à prendre des chemins détournés, trouvant frénétiquement des vulnérabilités du système pour accomplir ses tâches, au lieu de coder honnêtement et méthodiquement.
Deux cas ont été clairement identifiés :
Premièrement, le modèle a découvert qu'il restait dans le système un cache de vérification de types Python. Il a directement inversé le format du cache et en a "volé" la signature des fonctions supprimées.
Deuxièmement, face à une API tierce manquante, le modèle a remonté la piste jusqu'au bytecode Java sous-jacent, puis a écrit un script de décompilation pour reconstruire l'API.
Il faut admettre que cela ressemble un peu à un film de science-fiction où l'IA prend conscience et est sur le point de dominer l'humanité.
D'un point de vue technique, cela prouve précisément l'énorme puissance de l'apprentissage par renforcement à grande échelle dans le domaine de la programmation IA. Le monde du code est essentiellement un bac à sable doté d'"une vérité objective". Si le code s'exécute et donne le bon résultat, c'est correct, sinon c'est faux. Dans ce bac à sable, pour atteindre son but plus rapidement, à la manière de l'ingénierie humaine, le modèle commence déjà à manifester des capacités de canal auxiliaire d'attaque et de rétro-ingénierie que seuls les hackers humains chevronnés possèdent.
L'équipe de recherche de Cursor a découvert ces soi-disant "tricheries" grâce à la surveillance de l'agent. En principe, cela devrait indiquer des problèmes à la fois au niveau des données et de l'algorithme, mais cela est en réalité devenu un excellent argument commercial :
Une IA capable de décompiler du bytecode Java pour en faire le moins possible, pour aider les humains à écrire du code métier courant, c'est clairement une révolution.
03
Infrastructure Sous-jacente : Optimisation de la Puissance de Calcul
Après avoir abordé les données et l'algorithme, passons au problème épineux de la puissance de calcul, qui préoccupe toutes les entreprises d'IA dans le monde. Après tout, les algorithmes de pointe reposent toujours sur une infrastructure solide, construite sur des actifs matériels importants.
Cette fois, Cursor a à la fois des motivations externes et internes :
Premièrement, l'entreprise a annoncé avec grande publicité un partenariat entre Composer 2.5 et SpaceXAI de Musk, utilisant une puissance de calcul équivalente à 1 million de puces H100 fournie par le centre de données Colossus. Ce chiffre est suffisamment impressionnant ; les réserves totales de puissance de calcul de nombreux grands modèles principaux actuels ne représentent probablement pas même un dixième de ce nombre.
Alors qu'il bénéficiait de l'aide de Musk, Cursor a également optimisé la puissance de calcul sous-jacente avec une précision extrême, s'inspirant des modèles nationaux. Les deux technologies clés mentionnées dans l'article technique officiel, le partage Muon et le double réseau HSDP, représentent les opérations les plus pointues de Cursor dans le domaine de l'infrastructure d'entraînement IA.
Avant de détailler ces deux technologies, il faut comprendre que les grands modèles de pointe actuels adoptent généralement une architecture de type Experts Mixtes (MoE). Les paramètres y sont divisés en deux catégories : les poids non experts et les poids experts, correspondant respectivement aux connaissances générales et aux connaissances spécialisées.
Lorsque la taille du modèle augmente jusqu'à dépasser les mille milliards de paramètres, les tâches de calcul doivent être réparties entre des milliers de GPU. À ce moment-là, la latence de communication due aux échanges de données entre les GPU devient instantanément un goulot d'étranglement plus difficile à surmonter que le calcul lui-même.
Muon est un algorithme d'optimiseur de pointe optimisé par l'équipe, capable d'effectuer une orthogonalisation de matrices et de rendre le processus d'entraînement du modèle plus stable et la convergence plus rapide.
Cependant, le calcul d'orthogonalisation de matrices implique un coût de calcul très élevé pour les poids experts. Cursor a donc repris cette idée en partitionnant également les matrices de forme identique, en répartissant les fragments de matrice sur différents GPU pour un calcul parallèle, et en récupérant les résultats une fois terminés.
Dans le calcul distribué traditionnel, lorsqu'un GPU envoie des données et attend de recevoir les résultats en retour, cela génère une latence réseau. Cursor, quant à lui, a réalisé un chevauchement asynchrone : un GPU unique, après avoir envoyé les données d'une tâche, n'attend pas bêtement, mais commence immédiatement à calculer la tâche suivante.
Le double réseau HSDP est quant à lui conçu par Cursor pour l'hétérogénéité des paramètres des modèles MoE. Il découple au niveau le plus bas les groupes de processus de communication en créant deux réseaux de communication physiquement isolés :
Le réseau étroit est dédié aux poids non-experts. Les opérations à haute fréquence sont entièrement réalisées sur une bande passante ultra-élevée au sein des nœuds, évitant totalement la latence réseau inter-nœuds.
Le réseau large est dédié aux poids experts. L'exécution en parallèle d'experts et le partitionnement des paramètres permettent de répartir au maximum la pression de stockage et de calcul des états experts sur une multitude de GPU.
L'avantage technique clé de cette disposition en double réseau est le chevauchement extrême entre communication et calcul, ainsi que la superposition sans conflit des dimensions parallèles. Grâce à ces opérations, le temps de communication réseau est parfaitement masqué dans le temps de calcul. Pour un modèle de mille milliards de paramètres, l'optimiseur hautement complexe ne nécessite même que 0,2 seconde étonnante par étape.
Cette capacité d'ingénierie extrême garantit que Cursor peut convertir les théories académiques les plus avancées en produit avec la plus grande efficacité, constituant ainsi un rempart difficile à atteindre pour les nouveaux venus.
04
Refonte de l'Écosystème des Développeurs
Enfin, à travers cette publication de Composer 2.5, on peut voir la stratégie commerciale claire de Cursor. Son ambition ne se limitera certainement pas à un simple assistant de programmation pratique.
Composer 2.5 adopte une tarification à deux niveaux courante : la version Standard et la version Rapide. Les deux ont le même niveau d'intelligence, mais la seconde est plus rapide.
Version Standard : Entrée 0,5 $ / million de tokens, Sortie 2,5 $ / million de tokens.
Version Rapide : Entrée 3 $ / million de tokens, Sortie 15 $ / million de tokens.
Bien que le prix de la version Rapide soit bien supérieur à celui de la version Standard, l'entreprise souligne particulièrement : Son coût reste inférieur à celui des solutions équivalentes des autres modèles de pointe.
Ce phénomène n'est pas rare. Comme l'Opus 4.7 d'Anthropic et le GPT-5.5 d'OpenAI, bien que leurs prix d'API soient bien supérieurs à ceux de la grande majorité des modèles dans le monde, le coût nécessaire à ces deux modèles d'élite pour accomplir des tâches est en réalité plus faible.
C'est également une maîtrise psychologique des utilisateurs extrêmement précise de la part de Cursor. Pour les programmeurs à forte valeur ajoutée et à forte volonté de payer, la continuité de la réflexion est souvent inestimable. Dépenser quelques dollars de plus pour obtenir une amélioration de la vitesse de génération de code à l'échelle de la milliseconde est un bon calcul. Cursor propose la version Rapide comme option par défaut, tout en offrant un double quota d'utilisation pour la première semaine, ce qui, en réalité, revient à cultiver chez l'utilisateur une dépendance physiologique à une « programmation IA offrant une meilleure expérience » à un coût moindre.
C'est aussi une chose que font généralement les entreprises d'IA de pointe à l'international : une fois que l'on s'habitue à la vitesse et à la précision d'un modèle, il est extrêmement difficile pour les utilisateurs de revenir vers les concurrents.
On peut également voir, à travers la pile technologique de Cursor, qui inclut la gestion de contextes de plusieurs centaines de milliers de tokens, l'édition sur plusieurs fichiers, la correction directionnelle des appels d'outils, etc., que son positionnement est celui d'un Agent de collaboration pour tâches longues.
L'utilisateur n'a pas besoin d'appuyer sur la touche tab ligne par ligne. Il suffit de lancer une demande d'architecture, et Cursor peut lui-même lire le cache en arrière-plan, appeler des interfaces, exécuter des tests. Même en cas d'erreur, pas de panique, la technologie d'autodistillation basée sur les retours textuels lui permet de s'améliorer au fil de centaines d'interactions.
Ainsi, l'apparition de Composer 2.5 constitue également une interrogation profonde pour l'industrie du développement logiciel :
Lorsque le modèle est déjà capable de refactoriser et de réparer du code automatiquement en décompilant et en lisant de longs référentiels de code, quel avenir pour les programmeurs juniors ?
À l'inverse, pour les architectes système, les chefs de produit et les développeurs seniors possédant une capacité de conception de haut niveau, cela représente une aubaine sans précédent.
À l'avenir, le cœur de la compétition en programmation IA résidera dans la capacité à définir les problèmes et à décomposer les systèmes complexes.
Plus les exigences humaines sont multidimensionnelles et précises, plus Composer 2.5, fort de l'intelligence entraînée sur 1 million de H100, pourra produire des systèmes impressionnants.
Enfin, l'équipe fondatrice de Composer 2.5 est impressionnante.
Elle possède à la fois les théories les plus avancées du monde académique en matière d'apprentissage par renforcement et d'autodistillation, une puissance de calcul exagérée de l'ordre du million de cartes, une infrastructure d'ingénierie exploitant au maximum les GPU, et dans l'esprit, un modèle commercial qui comprend la psychologie des développeurs.
Certains disent que les outils de programmation IA ne sont finalement que des coques autour de grands modèles.
Mais Cursor prouve avec Composer 2.5 : Lorsque l'expérience de la couche application inverse la refonte des algorithmes sous-jacents, cette coque devient le rempart le plus solide dans la compétition.
La seconde moitié de la programmation IA a déjà commencé. Celui qui prend actuellement la tête est une espèce super-évoluée qui ne cesse de réaliser « l'autodistillation ».
Cet article provient du compte WeChat "Silicon Starlight", auteur : Si Qi