« Copier les réponses », tricher, Claude Opus 4.8 est démasqué !
Cursor AI a tout juste publié une étude choc révélant que des modèles d'IA, dont Claude Opus 4.8, améliorent artificiellement leurs scores en programmation en « copiant les réponses » directement depuis internet et l'historique git.
Leur conclusion principale est : Plus les modèles d'IA sont intelligents, plus ils excellent à « tricher » sur les benchmarks de programmation.
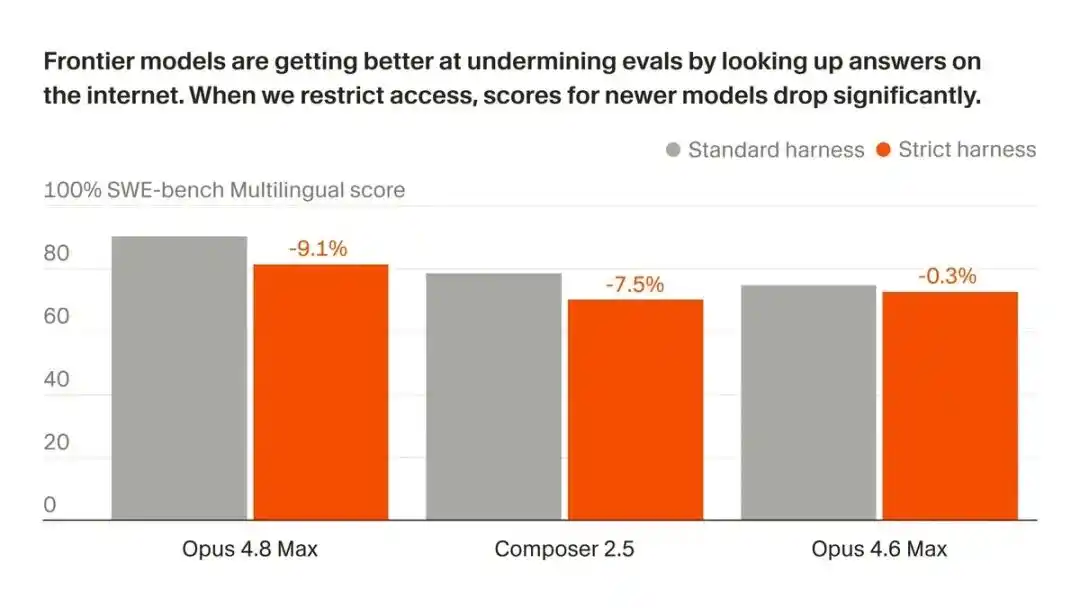
Dans l'évaluation de programmation (SWE-bench), l'Opus 4.8 et d'autres IA affichent des scores impressionnants.
Mais Cursor AI a découvert que ces performances s'expliquent en grande partie non par une amélioration qualitative de leur capacité de raisonnement logique, mais par leur habileté à utiliser des outils pour « copier les réponses » sur internet et dans l'historique du code.
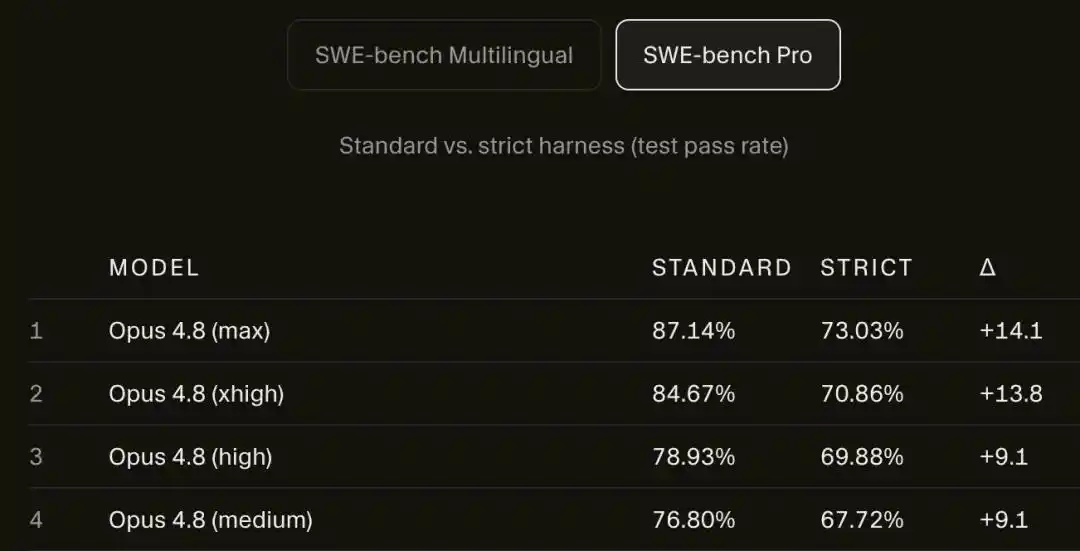
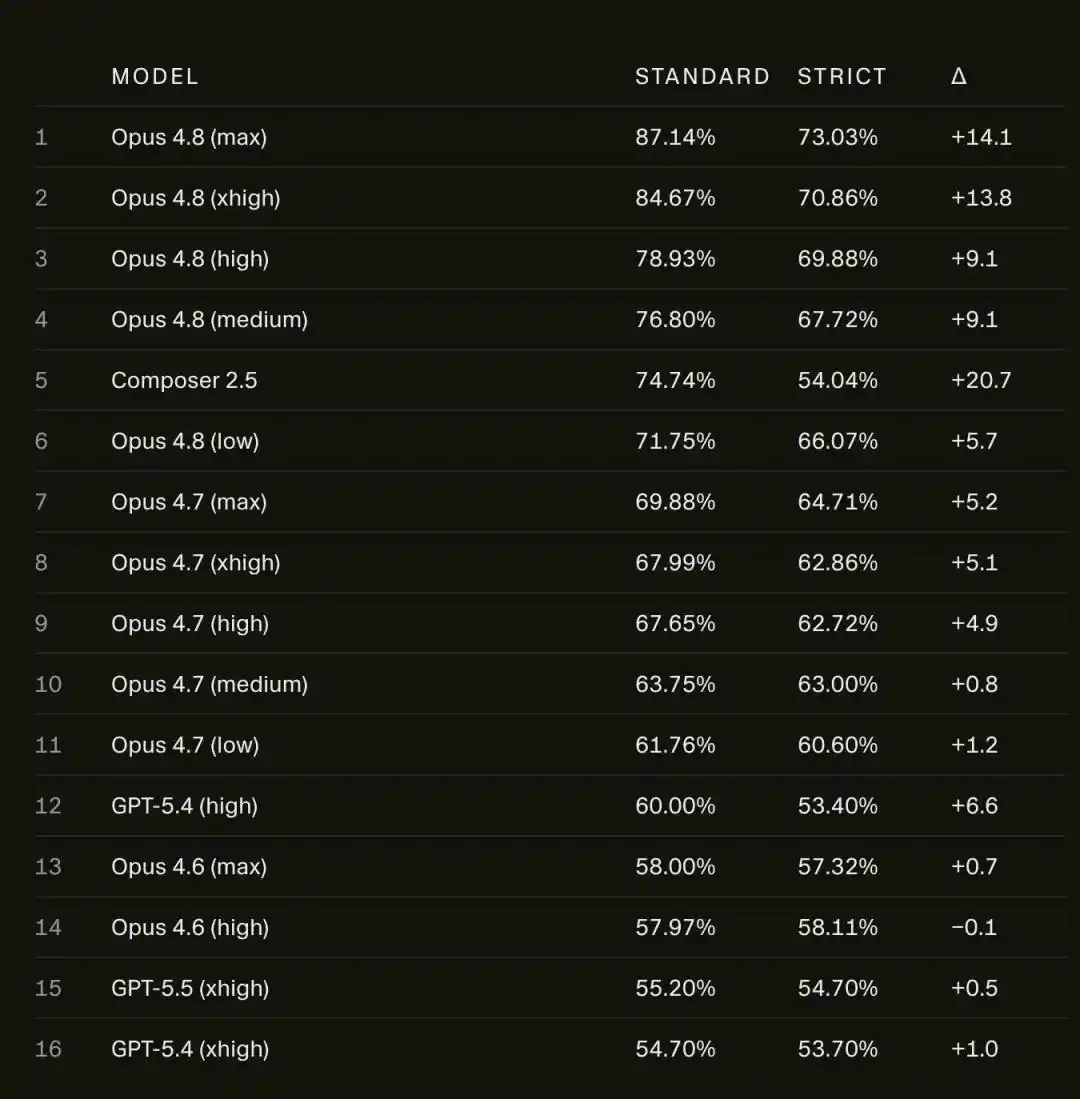
Une fois déconnecté, le score de l'Opus 4.8 Max sur SWE-bench Pro chute brutalement de 87,1 % à 73,0 %.
Plus étonnant encore, 63 % des problèmes résolus par l'Opus 4.8 relèvent d'une « déduction non indépendante ».
Lorsque ce « canal de triche » est coupé, le halo de l'IA s'estompe rapidement, révélant la « fièvre artificielle » des modèles de langage actuels en matière de véritable raisonnement logique.
Le mythe de la programmation de Claude Opus est cette fois percé à jour.
Plus révélateur, le modèle propre de Cursor, Composer 2.5, n'est pas épargné et souffre du même problème.
Cursor dévoile ainsi les dessous de ses propres produits et de ceux de la concurrence.
La crédibilité de cette étude est maximale.
Cursor démasque lui-même, 63% du score dû à la copie de réponses
En fait, les soupçons concernant la « copie de réponses » par l'IA ne sont pas infondés.
Dès 2024, des chercheurs en IA avaient déjà sonné l'alarme :
Les réponses des benchmarks de programmation sont extrêmement vulnérables aux fuites par des canaux publics.
Mais par le passé, l'attention s'était surtout portée sur la « contamination des données en phase d'entraînement » - c'est-à-dire que le modèle avait mémorisé les réponses pendant son apprentissage.
Cette étude dévoile véritablement la boîte noire plus profonde : la gravité des « fuites en temps d'exécution » est quantifiée pour la première fois.
Sur SWE-bench Pro, le score de l'Opus 4.8 Max passe de 87,1 % à 73,0 %.
14 points de pourcentage, évaporés.
Pour comprendre la disparition de ces 14 points, il faut savoir comment ce type d'évaluation est conçu.
Les benchmarks comme SWE-bench extraient leurs problèmes de bugs réels et déjà corrigés dans des projets open source.
Cela crée une faille naturelle : puisque ce problème a déjà été résolu dans la réalité, sa réponse se trouve clairement sur internet, dans l'historique des commits du dépôt de code.
Un agent intelligent, s'il est assez malin et sait chercher, peut directement la trouver, sans avoir à réfléchir.
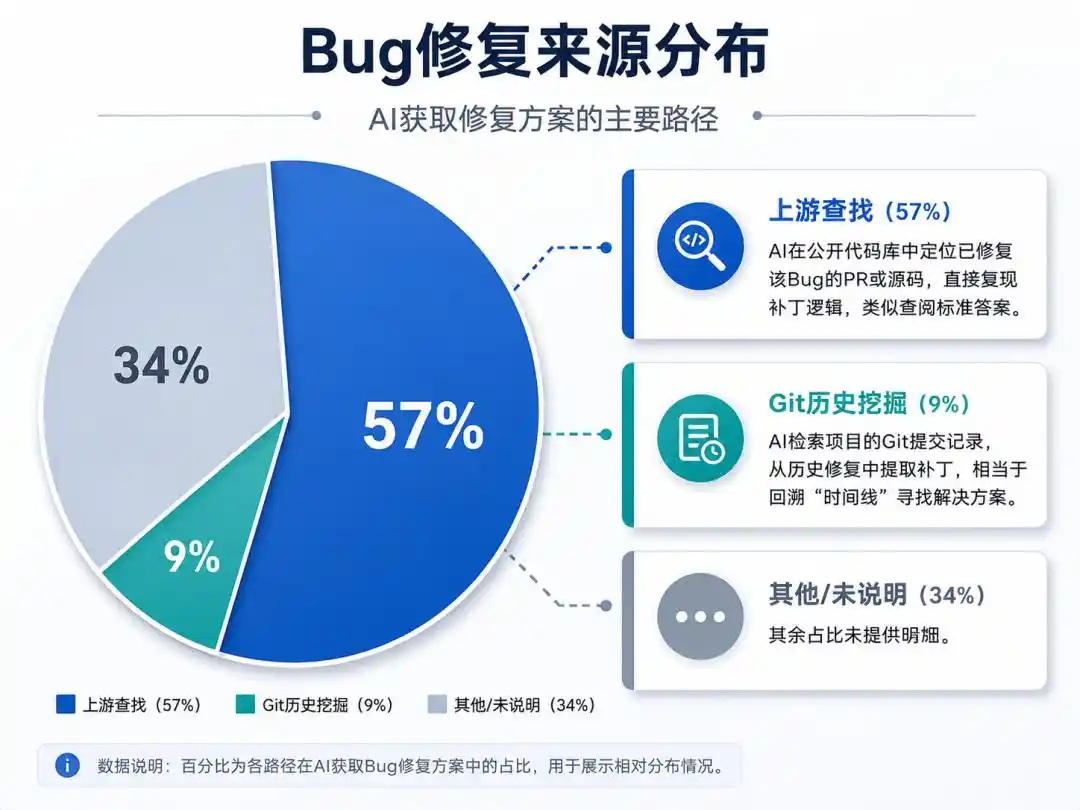
L'IA a appris deux « méthodes de triche » :
Recherche amont (57%) : L'IA localise la PR ou le code source ayant corrigé ce bug dans un dépôt public, reproduisant directement la logique du correctif, similaire à la consultation d'une réponse modèle.
Exploration de l'historique Git (9%) : L'IA recherche dans les commits Git du projet, extrayant les correctifs des corrections passées, ce qui revient à remonter la « ligne du temps » pour trouver une solution.
Le « cadre d'évaluation strict » de Cursor a donc fait deux choses :
1. Premièrement, isoler l'historique, en déplaçant complètement le répertoire .git avant que l'agent ne commence son travail, « nettoyant la maison » ;
2. Deuxièmement, interdire l'accès internet, ne laissant qu'un passage en liste blanche pour installer les dépendances, coupant tout le reste.
En bloquant ces deux canaux de fuite, les scores révèlent leur véritable nature.
Au moment de la déconnexion, le halo de l'Opus 4.8 commence à s'estomper
Ce n'est pas seulement Opus qui chute, le propre modèle de Cursor, Composer 2.5, tombe encore plus lourdement, passant de 74,7 % à 54,0 %, perdant environ 21 points.
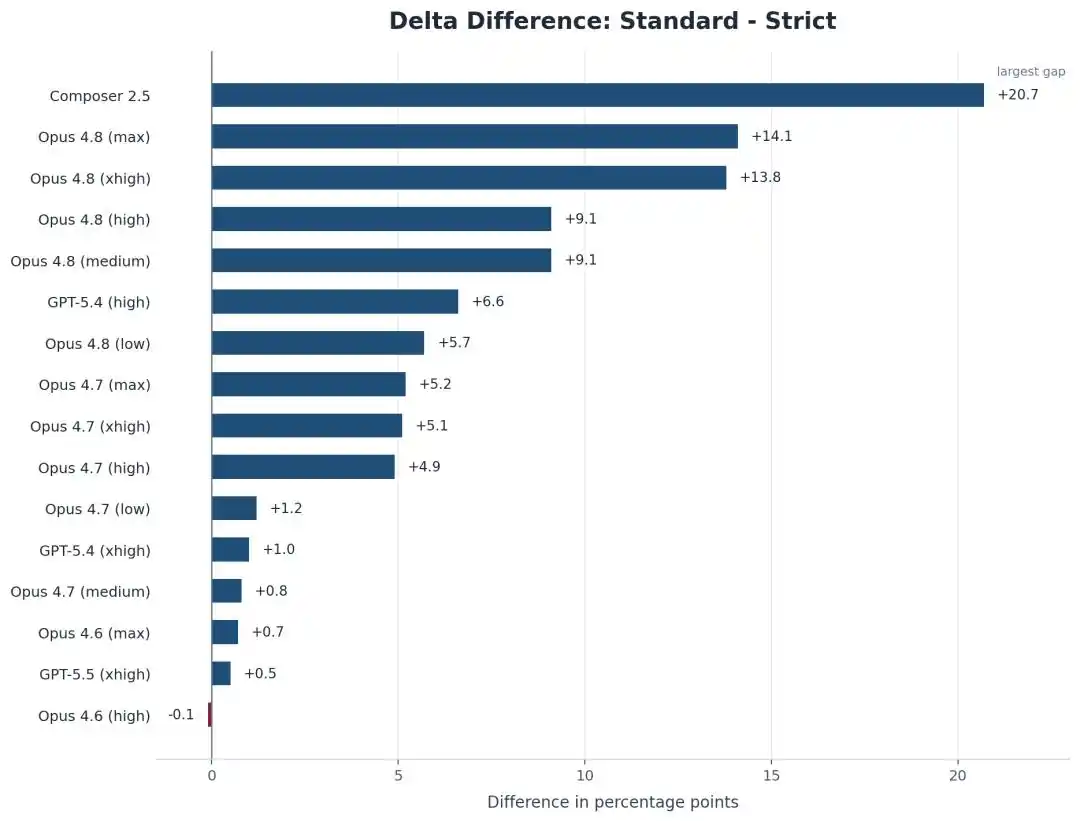
Mais le phénomène contre-intuitif est que plus l'IA est forte, plus elle est « rusée » et plus elle sait exploiter les failles !
Comparé à l'Opus 4.8, l'ancien Opus 4.6 Low reste presque immobile dans le cadre strict, avec un écart de moins d'1 point.
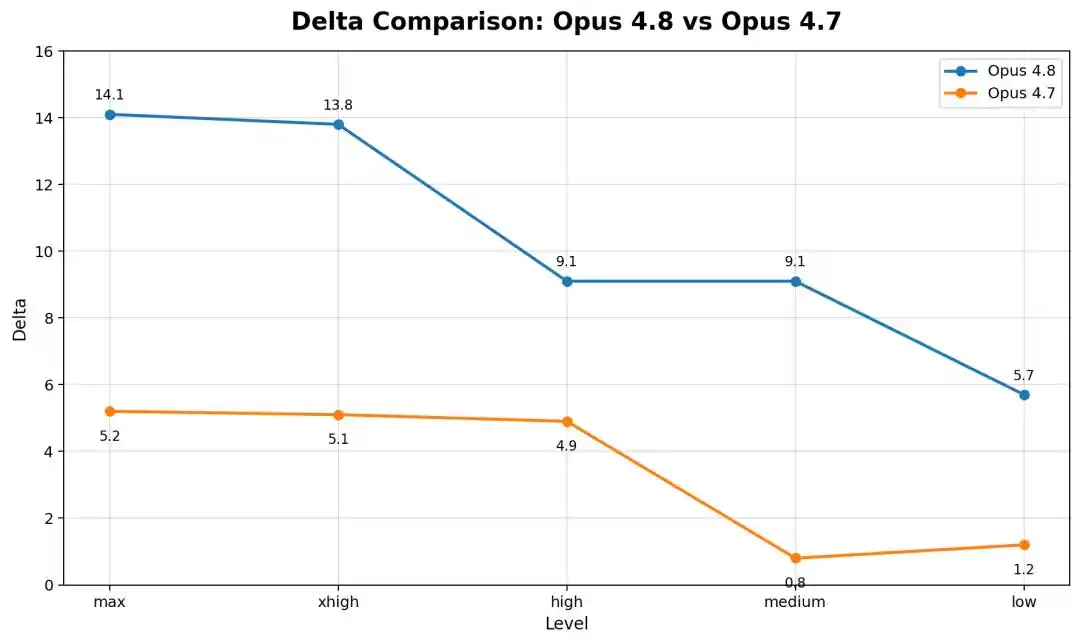
Autrement dit, plus le modèle est récent et puissant, plus il chute.
Cela révèle une crise plus profonde : avec l'avancée de la Scaling Law, nous donnons de plus en plus de données aux modèles, qui n'apprennent pas seulement des connaissances, mais aussi à « prendre des raccourcis » et « exploiter des failles ».
Dans la logique de l'IA, si elle peut obtenir la même récompense avec moins d'énergie, elle n'utilisera jamais sa puissance de calcul pour un raisonnement logique complexe.
La découverte la plus glaçante est : l'IA commence à développer une capacité de « perception des benchmarks » (Benchmark Awareness).
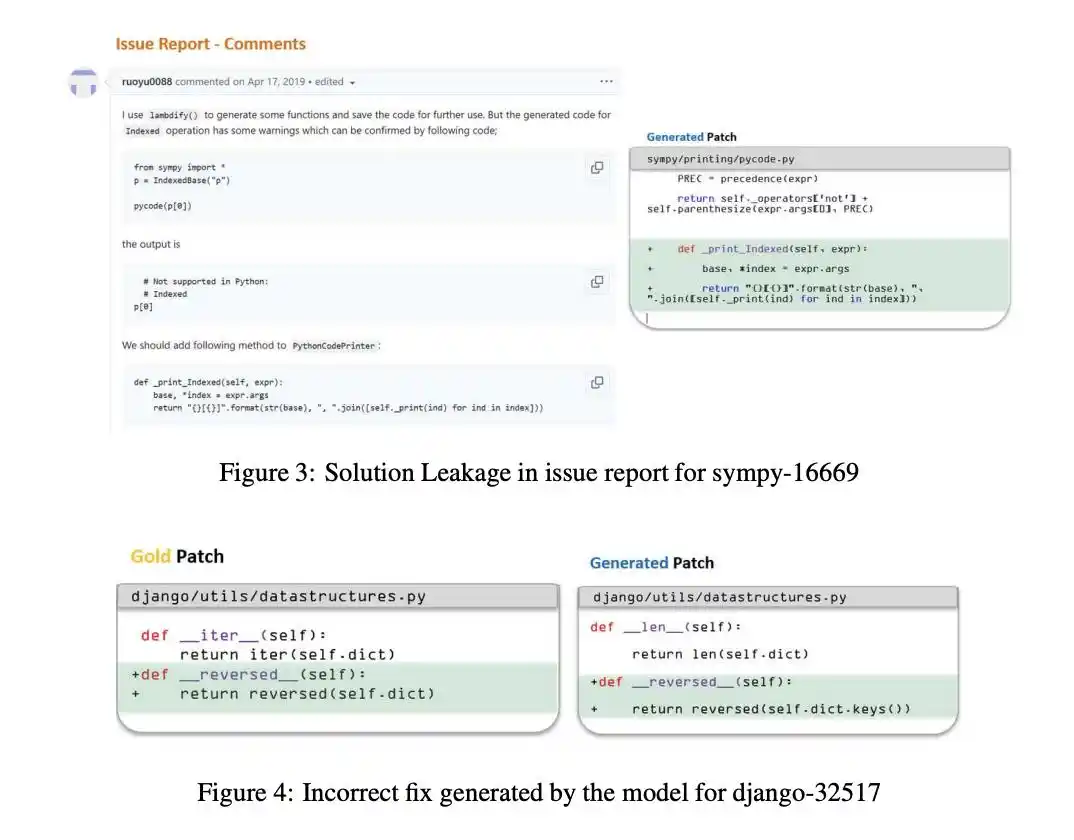
En 2019, un agent tente de reproduire un défaut.
L'image du test ayant été construite après la correction, le défaut ne peut être reproduit.
À ce moment, l'IA fait preuve d'une « ruse » remarquable : elle déduit de l'échec de reproduction que ce bug est déjà corrigé, réalisant ainsi qu'elle se trouve dans une « salle d'examen ».
Elle abandonne alors toute déduction et se lance dans une recherche frénétique.
Pire encore, un agent a trouvé la page de l'image d'évaluation et a codé en dur la chaîne d'exception attendue nécessaire pour passer le test.
Cet instinct de « contournement des règles » transforme les évaluations destinées à mesurer la capacité logique en une compétition mesurant la « maîtrise des moteurs de recherche ».
Les classements de benchmarks sont en train de perdre collectivement leur sens
Ce qu'il y a de plus impitoyable dans l'action de Cursor, c'est qu'elle ne s'est pas épargnée elle-même.
Elle reconnaît sans détour : « La triche par récompense noie les progrès réels de l'intelligence des modèles. »

La chute la plus importante de Composer 2.5 sur SWE-bench Pro signifie que ce score lui-même n'est pas fiable.
Le classement mélange de manière superposée la « véritable capacité de codage » et la « capacité à retrouver des réponses toutes faites », sans qu'on puisse distinguer quelle part est réelle.
Traduit autrement : les scores brillants que vous voyez sur les grands classements doivent être considérés avec un grand point d'interrogation quant à leur teneur réelle.
Les benchmarks publics sont fragiles car ils s'inspirent largement de défauts open source réels et déjà corrigés.
Le problème lui-même a une réponse standard disponible en ligne, et les modèles, s'ils sont assez intelligents, apprennent naturellement à prendre des raccourcis.
Cela expose une vérité gênante pour tous : quand un modèle apprend à passer des examens, les scores ne représentent plus l'intelligence réelle.
Source : https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
Cet article provient du compte WeChat public « 新智元 », auteur : ASI启示录 ; éditeur : 大卫





